

 |
|
どこまでもどこまでも高クロック化に向けて最適化されたCPU。それがPentium 4だ。
米サンノゼで、8月22~24日に開催された「Intel Developer Forum(IDF)」で、IntelはPentium 4のアーキテクチャのインプリメンテーションをさらに明かした。徐々に詳細が明らかになりつつあるそのアーキテクチャからは、想像以上に高クロックに向けてチューンされたスピードデーモンの姿が見えてきた。
 |
これまで、Pentium 4はパイプラインを非常に細分化していることが説明されていたが、今回は、キャッシュの構成やパイプラインの各ステージの構成も高クロックに最適化されていることが判明した。簡単に言えば、極めて小さいが高速なL1キャッシュを搭載した。
例えば、Pentium 4のL1データキャッシュの容量は8KBと小さい反面、ロードレイテンシは2クロックと短い。これをほかのCPUと比較すると、キャッシュサイズは、Pentium IIIの16KBの半分、Athlonの64KBのなんと8分の1に過ぎない。しかし、レイテンシはPentium IIIやAthlonの3クロックより小さい。L1のレイテンシの1クロックの差は、かなり性能に与える影響が大きい。
Pentium 4のL1キャッシュがこうした構成になったのは、高クロック駆動と低レイテンシを両立させるために容量を抑えたからだと思われる。通常、キャッシュ容量が増えると高クロック時にレイテンシを短く保つことは難しくなる。「0.18μm版Pentium 4(Willamette:ウイラメット)」のターゲットクロックは2GHzだと見られ、2GHz時の2クロックは実時間で1nsとなる。1nsでロードするとなると、8KBが限界と判断したのではないだろうか。また、Pentium 4では、L1データキャッシュからのデータスペキュレーション、つまりデータの投機的なロードも行なう。どういったアルゴリズムで実現しているのかは不明だが、ミススペキュレイトしないでうまく実行できれば、ロードレイテンシは隠蔽される。
Pentium 4のL1データキャッシュは、ピーク帯域も44.8GB/sec(1.4GHz時)と非常に高い。1クロック当たり256ビットのアクセスとなる。ただし、これは1クロックに、128ビットのロードとストアの2アクセスを同時に実行できるためで、64ビット×4アクセスを並列に行なえるわけではなさそうだ。128ビットロード/ストアなのは、SSE/SSE2命令で128ビット幅のデータタイプが増えたためと見られる。キャッシュの構成は4wayセットアソシエイティブで64バイトキャッシュラインだ。
また、Pentium 4のL1命令キャッシュに当たる「トレースキャッシュ(Execution Trace Cache)」も、容量は“最大12KB”だとIntelは明かした。通常、汎用CPUでは命令キャッシュとデータキャッシュの量はバランスを取るため、トレースキャッシュの物理的な容量もおそらく8KBだと予想される。最大12KBというのは、コードの中のトレース(実行されるパス)をたどり不要なコードを削除するためだと思われる。つまり、通常の命令キャッシュなら12KB必要な量のコードを、トレースキャッシュ方式を採って不要コードを除去したことで8KBに入れ込めるようになったという意味である可能性が高い。ダイ(半導体本体)写真を見ると、トレースキャッシュの面積はかなり大きいが、これはトレースキャッシュのSRAMセルの構造がL2と異なるためかもしれない。
L2キャッシュは256KB。構成は4wayセットアソシエイティブで128バイトキャッシュライン。1ラインが128バイトなのは、64バイト単位のピースを2つ1キャッシュラインに納めているためだ。帯域はL1データキャッシュと同じ44.8 GB/sec(1.4GHz時)。これは、L2の帯域としては極めて広い。
また、帯域から逆算すると、L2キャッシュのインターフェイス幅はおそらく256ビットだと思われる。これは、L2キャッシュ統合版Athlon(Thunderbird:サンダーバード)の64ビット幅インターフェイスより大幅に広い。だが、AthlonはL1キャッシュが128KBと非常に大きいため、L1ミスの頻度はPentium 4より原理的にかなり低くなる。そのため、L2アクセスに必要な帯域も小さくてすむため、64ビット幅だから単純に不利になるというわけではない。
こうして見ると、Pentium 4とAthlonは、キャッシュに関して対照的な発想を持つCPUであることがわかる。つまり、Pentium 4の「極小容量/低レイテンシL1+高帯域L2」の組み合わせ対、Athlonの「大容量/長レイテンシL1+低帯域L2」の組み合わせということだ。これは、どちらが優れているということではなく、デザインチョイスの問題だ。しかし、Pentium 4のL1は異常に容量が小さいため、高クロックへの追従が容易だと想像できる。というより、高クロック化への執念が、L1を極少容量にするという特異なデザインを選択させたと思われる。
ちなみに、もうひとつのIntelの新CPUである「Itanium」のキャッシュもIDFで明かされた。L1データが16KBで2クロックレイテンシ、L2が96KBで6クロックレイテンシで、いずれも1クロックに2メモリオペレーションが可能となっている。CPU外付けのL3キャッシュは2MBまたは4MBで21クロックレイテンシだ。こうして見ると、小さくて低レイテンシのL1はIntel共通の方向性で、Pentium 4はそれが極端にまで行き着いたことがわかる。
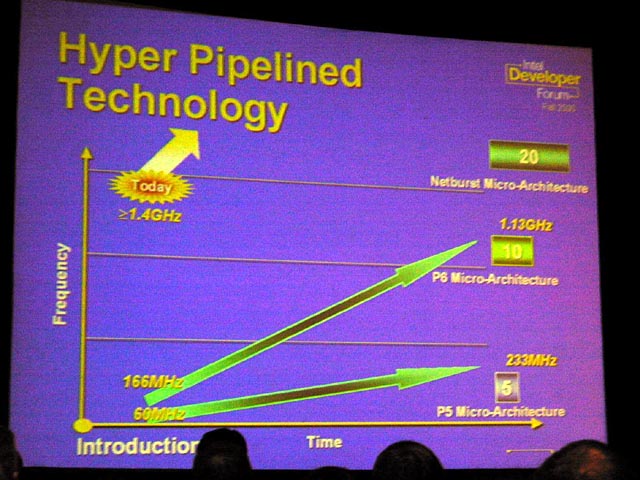
Pentium 4は、高クロック化のためにパイプライン段数をPentium IIIの2倍(L1ヒット時)に増やしている。パイプラインを細分化すると、1ステージのゲート数が減り、1ステージ当たりの遅延が減る。しかし、パイプラインを深くするとクロックは上がるが、性能を上げることは難しくなる。それは、パイプラインのステージ数が増えれば増えるほど、パイプラインが乱れた時のペナルティが大きくなるためだ。条件分岐命令で、分岐予測が外れた場合、MPUはそれまでの処理をすべてご破算にして、分岐先のフェッチから始めなくてはならない。パイプラインの段数が多ければ多いほど、失うサイクルは大きくなり、実効性能は下がる。
この問題を解決するため、Pentium 4では分岐予測機構を強化しなければならない。IDFの説明では、Pentium 4は4Kエントリのブランチターゲットバッファを備えるという。これは、Pentium IIIの512エントリの8倍だ。
そして、分岐予測精度はPentium IIIの3倍になったという。P6コア(Pentium Pro/II/III/CeleronのCPUコア)発表時の分岐予測精度は「90%以上」だったので、計算上Pentium 4の精度は96~7%ということになる。最先端CPUの多くが95%程度の分岐予測精度をうたっており、Pentium 4はそれを追い越したことになる。分岐予測精度は、1%上げるのも非常に難しいと言われているため、この通りならPentium 4の精度はかなり優秀だ。ただし、Intelは分岐予測のアルゴリズムに関しては「公開されたほかの予測機構よりも高い精度が立証された」としか説明しなかった。
また、IDFの技術セッションでは、Pentium 4のパイプラインの各ステージの概要の説明もあった。詳細はのちほど図入りでレポートするが、Pentium 4のパイプラインは将来の高クロック化を見込んで、異常なほど細分化されている。パイプラインの構成を見る限り、Pentium IIIの1.4倍増というクロックは、まだ余裕があるように見える。このコラムでは、Willametteの最高クロックを1.9~2GHz、「0.13μm版Pentium 4(Northwood:ノースウッド)」の最高クロックを3~3.2GHzと予想しているが、アーキテクチャ的には達成できると思われる。
このほか、今回のIDFでは、Pentium 4の汎用レジスタ数が128本であることも明かされた。ほかのx86互換CPUと同様に、x86命令の8本の論理レジスタをリネームしてマッピングする。また、Pentium 4ではリオーダーバッファ(ROB)を大幅に深くして、オンザフライで制御できる内部命令μOPs(ユーオプス)の数を126個に増やした。これは、Pentium IIIの40個(μOPs)やAthlonの72個(x86命令)よりも多い。また、オンザフライで制御できるロードは48個、ストアは24個だ。
(2000年8月25日)
[Reported by 後藤 弘茂]
Pentium III Pentium 4
周波数 1GHz 1.4GHz以上
整数演算
レイテンシ(単純命令) 1クロック 0.5クロック
遅延時間(単純命令) 1ns 0.36ns *
パイプライン
ミスプレディクト時 10段 20段
L1命令キャッシュ 16KB 最大12KB
L1データキャッシュ
ロードレイテンシ 3クロック 2クロック
サイズ 16KB 8KB
メモリ帯域 16GB/sec 44.8GB/sec *
1クロック当たり 128bits/cycle 256bits/cycle
L2キャッシュ
サイズ 256KB 256KB
アソシエイティビティ 8way 8way
キャッシュライン 32byte 128byte
メモリ帯域 16GB/sec 44.8GB/sec *
1クロック当たり 128bits/cycle 256bits/cycle
分岐予測
ブランチターゲット 512 4,092
予測精度 - Pentium IIIの3倍
インフライトで制御できるオペレーション数
命令 40 126
ロード 16 48
ストア 12 24
*印は全てPentium III 1GHzとPentium 4 1.4GHzの場合の数字
●膨大なL2キャッシュのメモリ帯域

●大幅に向上した分岐予測精度
●物理レジスタ数は128本
【PC Watchホームページ】
ウォッチ編集部内PC Watch担当pc-watch-info@impress.co.jp