 |


■後藤弘茂のWeekly海外ニュース■KhronosがGDCでGPUやCell B.E.をサポートするOpenCLのデモを公開 |
●OpenCLの実装テストのスタートは5月
世界中のゲーム開発者が集まるカンファレンス「GDC (Game Developers Conference)」でKhronos Groupは、ヘテロジニアスな並列コンピューティングのためのプログラミング言語である「OpenCL」のオーバービューのセッションを行なった。
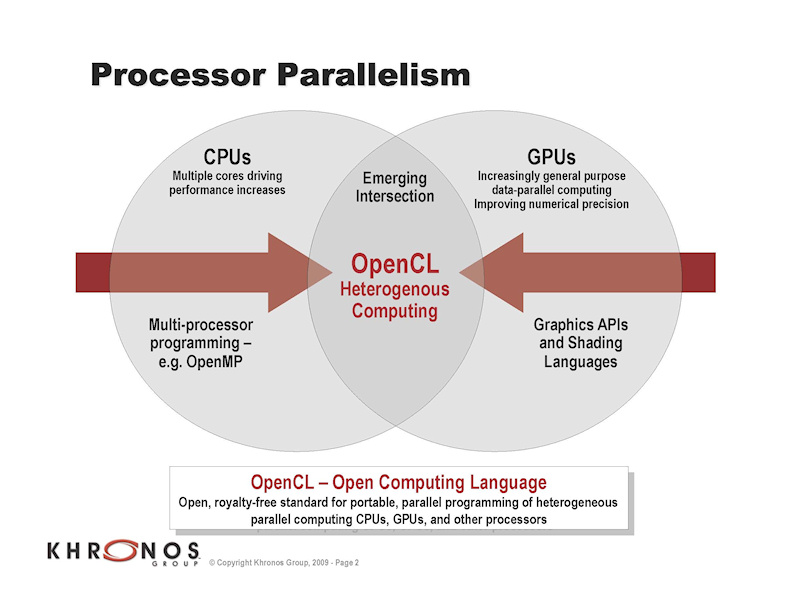
OpenCLは、NVIDIAの「C for CUDA (OpenCLもCUDAのランタイムに落とし込むため、従来の拡張CをベースにしたCUDAはC for CUDAと呼ぶようになった)」のように、GPUを汎用コンピューティングに使うことができるプログラミング言語だ。しかし、NVIDIA独自のC for CUDAとは異なり、クロスプラットフォームのプログラミング環境となっている。OpenCLでは、NVIDIAやAMD(ATI)のGPUだけでなく、マルチコアCPUやCell Broadband Engine(Cell B.E.)といった多様なプロセッサ(Larrabeeも含まれると推測される)をカバーする。最大の特徴は、GPU型のデータ並列モデルに対応したことだが、同時にマルチコアCPUなどのタスク並列モデルもサポートする。
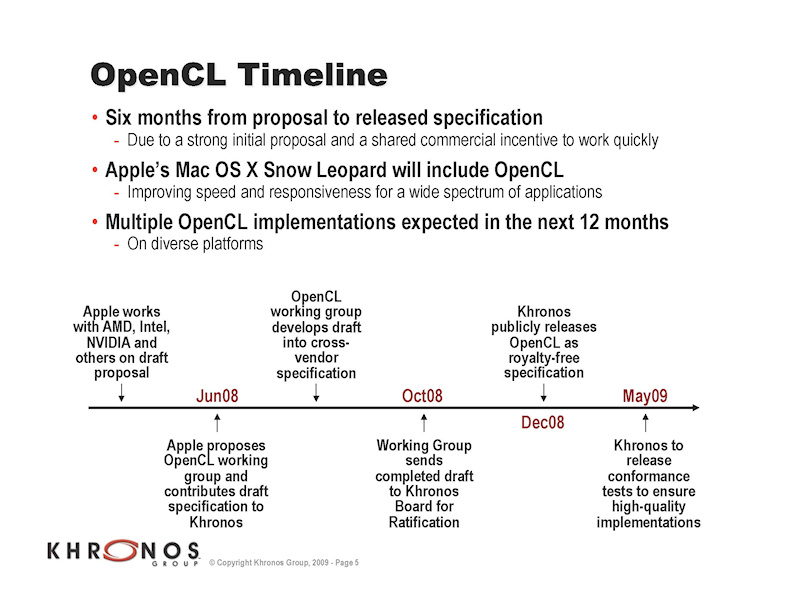
今回のセッションでは、まずKhronosは、OpenCLのロードマップのアップデートを行ない、OpenCLの実装のカギとなる「コンフォーマンステスト」のリリースが当初予定の2月から5月にずれたことを明確にした。
OpenCLをサポートする各ベンダーは、Khronosからリリースされるコンフォーマンステストをベースにテストを行なって、実装を完成させて行くことになる。そのため、OpenCLが各デバイスで走るように実装が完成するのは、コンフォーマンステストのリリースからしばらく後となる。言ってみれば、コンフォーマンステストは、スタートのスタートであり、Khronosでは今後12カ月間の間に各社からの実装が登場すると予測している。
GDCのセッションでの基本的な内容は、Khronosが昨年(2008年)12月のSIGGRAPH AsiaでのOpenCLのスペック発表時に行なった内容とそれほど変わらない。初期の実装の上でのデモとしては、EAによる布シミュレーションが公開された。このデモは、NVIDIAのGPUとAMD(旧ATI)のGPU、そしてAMDのマルチコアCPUそれぞれの上で走っていた。
 |
 |
 |
| ヘテロジニアスコンピューティングを実現するOpenCL | OpenCLの商業的目標 | OpenCL作業部会の会員 |
 |
 |
| OpenCLの予定 | OpenCLとKhronosのエコシステム |
●ミドルウェアの土台となるOpenCL
いよいよ秒読み状態に入ったOpenCLだが、これで、クロスプラットフォームのGPUや高スループットCPU向け汎用アプリケーションがどんどん書けるようになるかというと、そう簡単な話でもない。それは、OpenCLの性格が、C for CUDAなどとはかなり異なるからだ。
通常、クロスプラットフォームのポータブルなプログラミングモデルを構築しようとすると、コンパイラや厚い抽象レイヤーで、ハードウェアの差異が見えないようにカバーする。ローレベルのハードウェアには一切触らせずに、抽象化するのが一般的な手法だ。それに対して、OpenCLのアプローチは、逆にハードウェアの差異をプログラマから見えるようにする。OpenCLは、本質的にはローレベルのハードウェアAPI的な性格を持っている。
例えば、OpenCLでは、同じGPUでも、ターゲットのハードのコンピュートコアの数からワークグループのサイズの上限、メモリ階層の種類や量など、詳細な特性の違いの情報を得ることができる。メモリ階層やワークグループは言語の中でモデル化されているため、ハードの特性に合わせることができる。
そのため、OpenCLでは、特定のプラットフォームにゴリゴリに最適化したコードを書くことができる。これは、クロスプラットフォームのポータブルなコードという理念とは反するように見えるが、ポータビリティはプログラマに委ねられる。このあたりのアプローチはOpenGLと似通ったところがある。
こうした特性もあって、OpenCLはC for CUDAと較べると抽象化の度合いが薄い。コーディングしようとすると、C for CUDAよりもコードが煩雑になる。この違いは、OpenCLとC for CUDAでは目指しているところが異なるためだ。
OpenCLのモデルでは、ハードウェアを厚く抽象化するようなミドルウェアは、OpenCLの上に構築される。OpenCLはそうしたミドルウェアを書きやすいように、極力ローレベルアクセスが可能なように作られている。つまり、どちらかと言えば、ミドルウェアの土台となるがOpenCLという位置づけだ。これは、より高いレベルの言語でアプリケーションを書くことを主眼としたC for CUDAと位置づけがずれている。
こうした性格から、OpenCLは幅広く使われるためには、OpenCLの上でのミドルウェアやツールが充実することが必要となる。OpenCLは、それ単体で充足するプログラミング環境というよりむしろ、ミドルウェアなどの踏み台として新しいプログラミングフレームワークの基礎となる部分だ。
ミドルウェア側にしてみると、いったんOpenCLに落とし込めば、一応、クロスプラットフォームでデバイスを選ばず走らせることができる。なおかつ、各ターゲットデバイスに最適化させて、パフォーマンスを引き出すことができる。そのための環境を統一的に整えたことが、OpenCLの大きなポイントだ。また、この手法では、コンパイラやランタイムの負担を軽くすることができるため、現状では現実的と言えるかもしれない。
 |
 |
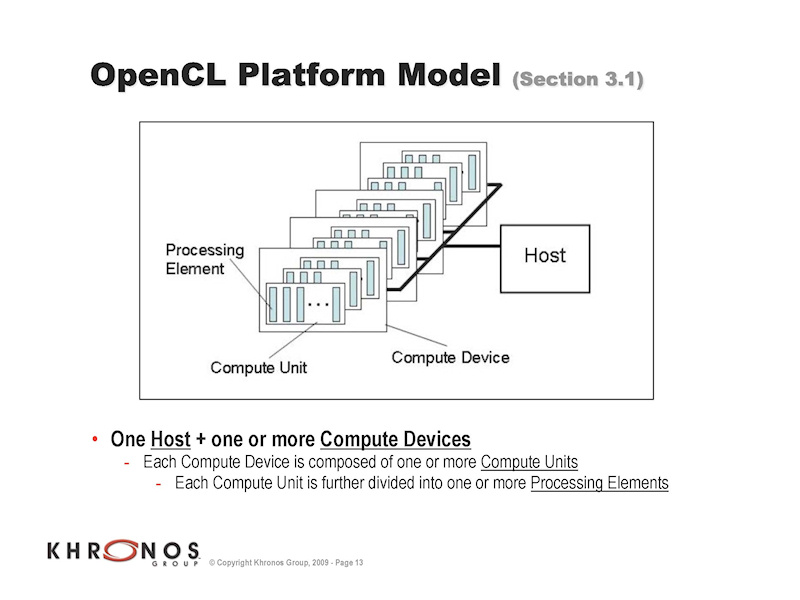 |
| OpenCLの設計要求 | OpenCLの概要 | OpenCLのプラットフォームモデル |
 |
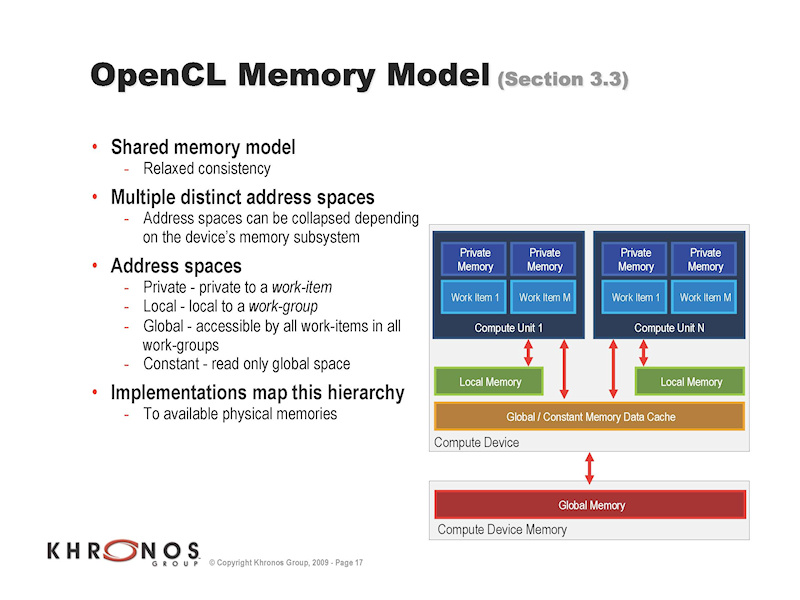 |
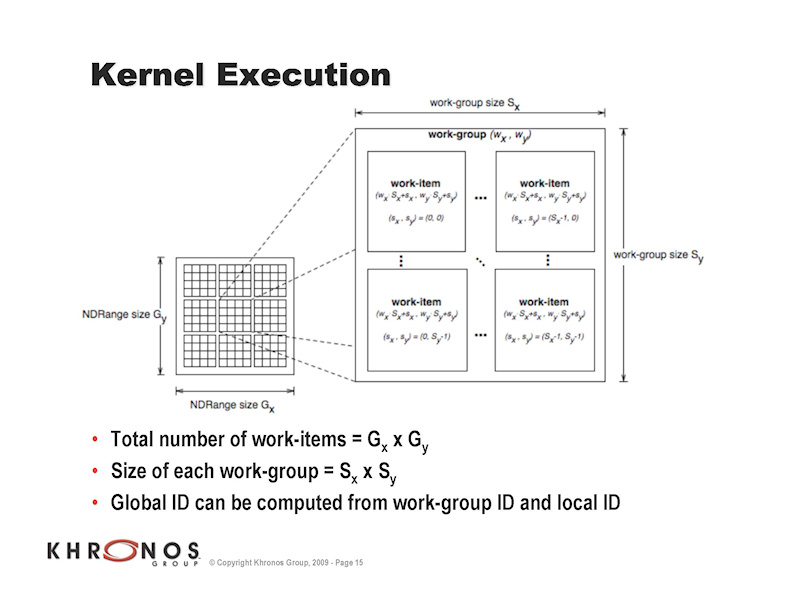
| カーネル実行 | OpenCLのメモリモデル |
●AMDは遅れを巻き返せるOpenCLに注力
GDCでのOpenCLのセッションには、AMDからは、元スタンフォード大学のStanford Graphics Labの研究者だったMike Houston(マイク・ヒューストン)氏が登場した。Houston氏は、スタンフォード大学のストリームプログラミング言語「Brook」の開発チームの主要スタッフの1人だった。その当時の同僚だったIan Buck氏は、NVIDIAでCUDA開発のリーダとなった。
つまり、NVIDIAの中でCUDAのリーダーに相当する経歴の人物が、AMDでOpenCLを担当している(AMDはBROOK+もサポートする)。ちなみに、OpenCLで取り入れられたプロセッサのメモリ階層のモデル化は、Houston氏が研究していた「Sequoia (セコイア)」プロジェクトに近い(Houston氏もOpenCL策定に参加している)。GDCでは、Houston氏のほかにも、AMD GPUのローレベルソフトウェアの部隊のスタッフが勢揃いしており、AMDがOpenCLを非常に重視していることが伺えた。
AMDがOpenCLを重視するのは、これがAMDにおけるGPUの汎用利用のカギを握るプログラミングモデルになると考えているからだ。AMDにとってGPUの汎用利用が非常に重要であるのは、同社が2011年以降には、CPUにGPUコアを初めとしたさまざまなエンジンを統合する計画でいるからだ。そのモデルを成功させるには、堅固なプログラミングモデルを確立する必要がある。
AMDがNVIDIAにGPUの汎用利用の分野で劣勢なのは、NVIDIAがGPUハードウェアだけでなくプログラミングフレームワークも包括的に提供していたのに対して、AMDは非常に粗野な環境しか提供できていなかったためだ。旧ATI Technologiesは、GPUの汎用利用のためのプログラミングフレームワークの構築でNVIDIAに遅れをとった。そして、ATIがAMDと合併した後の混乱で、さらに遅れが蓄積され、NVIDIAに対して完全に周回遅れとなった。
しかし、OpenCLは、この状況をひっくり返すことができる。どのハードの上でも走るOpenCLの元では、立場上は全てのプロセッサベンダが同じスタートラインに来るからだ。これまでは、GPUハードの性能ではなく、プログラミングフレームワーク込みの環境で比較されていた。しかし、OpenCL以降は、同じプログラミングフレームワークの下で、ハードウェアの優劣(厳密に言えばランタイムとドライバの優劣も反映される)で比較されるようになる。
GPUでの汎用コンピューティングがOpenCLでリセットになって、ここからスタートするのなら、AMDは原理的には不利なくNVIDIAと戦えることになる。また、同じプログラミングモデルの下で、内部アーキテクチャが異なるプロセッサを作って競うというスタイルは、x86 CPUメーカーであるAMDにとって馴染みやすい。
●OpenCLと自社版CをCUDAプラットフォーム上で共存させるNVIDIA
では、OpenCLはC for CUDAで先行するNVIDIAにとって、やっかいなシロモノかというと、意外とそうでもない。まず、OpenCLでGPU上での汎用コンピューティング自体が広まるなら、GPUベンダーであるNVIDIAにとっても利は大きい。
また、現状のC for CUDAとOpenCLでは、位置付けがずれる。OpenCLがミドルウェアの土台としての色彩が濃いローレベルAPIであるのに対して、C for CUDAの方が抽象化の度合いが高くアプリケーションを書きやすい(最適化は置いておけば)。そのため、当面は棲み分けができる。
さらに、C for CUDAでのNVIDIAのリードもそれなりに活きる。OpenCLであってもCであっても、CUDAアーキテクチャの上では同じ中間コード(PTX)にいったん落とし込まれて同じCUDAランタイムで走る。ランタイムとその中のリアルタイムコンパイラの技術的な蓄積はそのまま活きる。
また、C for CUDAでのNVIDIA GPUでの最適化の技法もOpenCLでのコーディングに反映できる。実際、C for CUDAとOpenCLは、基本的なアプローチは似通っており、同じNVIDIAハードウェアに対する最適化のアプローチは、C for CUDAでもOpenCLでも似通ったものになるだろう。また、NVIDIAは、C for CUDA上のライブラリですら、OpenCL側からアクセスできるようになるかもしれないと言う。
同じプログラミングモデルの下で、純粋にGPUでの汎用アプリケーションの性能で勝負できることもNVIDIAにとって利点だ。これまでは、同じアプリケーションの同じコードが走るわけではないため、汎用コンピューティングの性能の比較が難しかった。しかし、これからは同じコードの実行性能を競うことができる。NVIDIAは、AMDより汎用アプリケーションへの最適化にリソースを割いてきた。同じコードが走るのなら、その優位性が性能差として表に現れる可能性がある。
実際、GDCのOpenCLのセッションでも、NVIDIAはAMDと交替で仕様の説明を行ない、積極的に関わっていることを示した。また、OpenCLのSIGGRAPH Asiaでの発表では、NVIDIAきってのGPGPUのエバンジェリストMark Harris氏が登場して発表を行なった。NVIDIAの戦略は、C for CUDAでのリードを活かしつつ、OpenCLも育てて、両方の橋渡しをうまくやるというあたりだろう。
 |
 |
 |
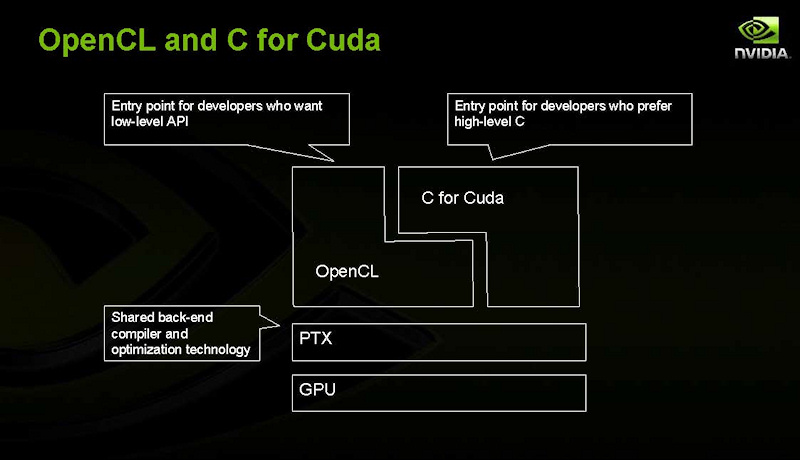
| C for CUDAの概要 | OpenCLとC for CUDAの違い | 両者のプログラミングモデルの違い |
●OpenCLと競合するMicrosoftのDirectX Compute Shader
OpenCLが当面競合するのはDirectX Compute Shaderだ。同じようにマルチプラットフォームの並列プログラミング言語であり、GPUを従来のグラフィックスパイプラインの外で使うことを主眼に置いているからだ。GDCでも、DirectX Compute Shaderを使ってNVIDIAとAMD双方のGPUで同じデモが走るところが実演された。
しかし、OpenCLとDirectX Compute Shaderは、見かけは競合するものの、より先まで展望した時の目的が大きく異なる。DirectX Compute Shaderは、どちらかといえば、グラフィックス処理との組み合わせで、ポストプロセッシングなどを行なうことをメインのターゲットとしている。DirectX Compute Shaderも、グラフィックスと絡ませない使い方はもちろんできる。しかし、発想の原点としては、グラフィックスAPIから、GPUの汎用的な利用へと走り出したのがDirectX Compute Shaderだ。
それに対して、OpenCLは、包括的なヘテロジニアスな並列プログラミング環境を確立することを最大の目的としている。OpenGLなどグラフィックスAPIとのインターオペラビリティも取るが、ゲームなどでグラフィックスと絡ませた使い方は、応用の一部に過ぎない。より幅広い分野で汎用的に使われるプログラミングプラットフォームを目指している。そのビジョンの中では、グラフィックスAPIであるOpenGLを最終的にはOpenCLのライブラリにしてしまうことすら展望している。GPUなどの汎用的な利用が第一にあるのがOpenCLだ。
OpenCLのこうした性格は、この規格を言い出したのがAppleであることも関係している。AppleはGPUのコンピューティングパフォーマンスを汎用に使いたいためにOpenCLを提案した。OpenCLの場合は出自が、グラフィックスやゲームサイドではなく、コンピューティングサイドだった。
とはいえ、GDCはゲーム開発の舞台であり、そこではDirectX Compute ShaderとOpenCLは真っ向から競合する。そして、DirectXは事実上PCとXbox 360ゲームのスタンダードであり、Khronosはやや不利な立場にある。組み込み系はともかくとして、PCやゲームコンソールでのゲーム市場ではKhronosは劣勢だ。OpenGL ES 2.0もPLAYSTATION 3(PS3)のグラフィックスAPIの決定打になるはずだったのが、浸透できていない。もっとも、OpenCLが本当に競合するのは、Microsoft内部のDirectX部隊ではなく、Microsoftの言語部隊の方になるだろう。
●Cell B.E.の影が薄いOpenCL
場所はゲーム開発者が集まるカンファレンスで、テーマは並列プログラミング言語であるにも関わらず、GDCでのOpenCLのセッションには欠けている顔ぶれがあった。それは、Cell B.E.陣営の姿だ。
OpenCLは、Cell B.E.にとっても、うまく使えればプログラミング環境の幅を広げる土台になりうる。デベロッパは、同じOpenCLで、GPUとCell B.E.(さらに加えるならマルチコアCPU)で共通に走らせるコードを書くことができるからだ。そして、GPUとCell B.E.を横断するミドルウェアも作ることができる。Cell B.E.にとってもベネフィットがあるように見える。
しかし、今のところCell B.E.陣営がOpenCLで活発に活動している形跡は見えない。OpenCLのスペックの初版のコントリビュータのリストを見ても、目立つのはAMDとNVIDIAのGPUベンダー(両社ともキーパースンの名前がある)と、CPUを抱えるIntel、言い出しっぺであるAppleなど。SCEからは、PS3のパラレルコンピューティングモデルのソフトウェア開発者であるJohn Bates氏の名前しか入っていなかった(IBMのCell B.E.関係者は何人か入っている)。SCEがOpenCLに今後どう取り組んで行くのか、まだ不鮮明だ。
ちなみに、コントリビュータのリストのIntelの名前も興味深い。Larrabeeのグラフィックス側のアーキテクトであるLarry Seiler氏や、IntelがLarrabeeのために買収したと言われるNeoptica(GPU向けの汎用プログラミングモデルを開発していた)出身の開発者の名前が連なっている。IntelがOpenCLをLarrabeeで走らせる気が満々なことは、このリストから伝わってくる。IntelはGDC最終日に、Larrabeeの命令セットを発表する予定だ。
□関連記事
【2008年12月25日】【海外】未来に強く過去に弱いIntelのLarrabee
http://pc.watch.impress.co.jp/docs/2008/1225/kaigai482.htm
【2008年12月2日】【海外】CPUとGPUの境界がなくなる時代が始まる2009年のプロセッサ
http://pc.watch.impress.co.jp/docs/2008/1202/kaigai478.htm
(2009年3月30日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2009 Impress Watch Corporation, an Impress Group company. All rights reserved.