 |


■後藤弘茂のWeekly海外ニュース■CPUとGPUの境界がなくなる時代が始まる2009年のプロセッサ |
●HPCを征するNVIDIAを追撃するAMDとIntel
NVIDIAはGPUベースのスーパーコンピュータへ。同社のプログラミングフレームワーク「CUDA」によるGPUコンピューティング戦略は、プロセッシングパフォーマンスを求めるコミュニティに浸透しつつある。NVIDIAはCUDA発表以来、大学の研究所など「HPC(High Performance Computing)」系のユーザーを積極的に開拓した。その結果、NVIDIAアーキテクチャは、プロセッシングパフォーマンスに飢えたHPCコミュニティの支持を集めることに成功した。
NVIDIAは、先月開催されたスーパーコンピュータのカンファレンス「SC08(Supercomputing '08)」では、GPUベースのスーパーコンピュータを強く打ち出した。実際に、東京工業大学では、同大学の学術国際情報センター(GSIC)のスーパーコンピューティングシステム「TSUBAME」に680のTesla GPUを統合。ヘテロジニアス(Heterogeneous:異種混合)システムで77.48TFROPSを達成した。
 |
 |
 |
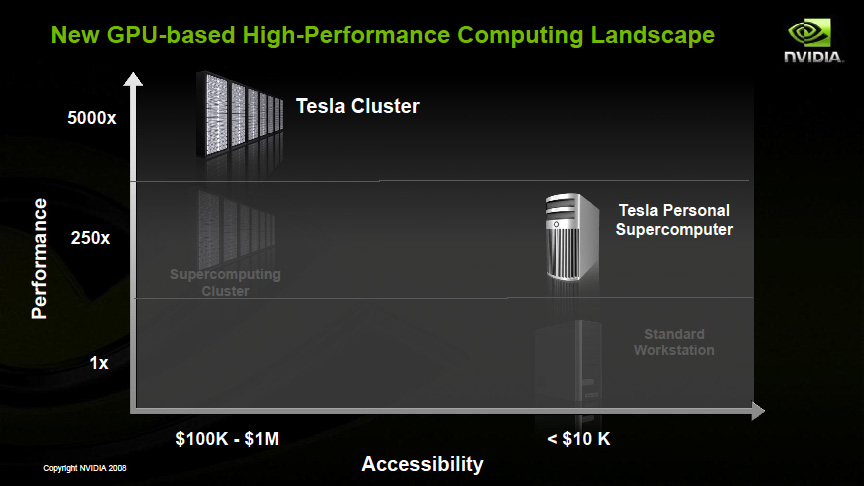 |
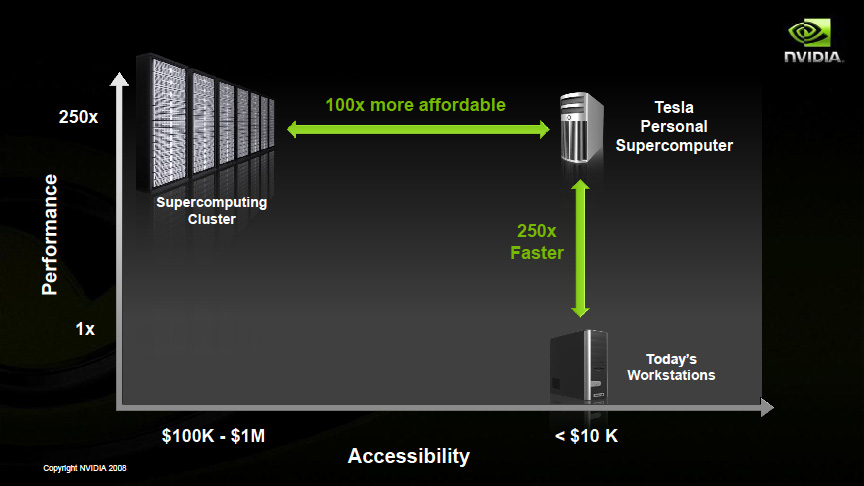
| Telsaによる小型スーパーコンピュータ | |
HPCを切り開くNVIDIAに対して、AMD(旧ATI)はGPUで汎用コンピューティングを実現するためのプログラミングフレームワークの構築で大きく後れを取った。ATIベースのハードウェアでは、CをベースにしたCUDAのような高級言語ベースの環境の整備が遅れたため、過去1年はNVIDIAの独走を許してしまった。しかし、AMDも、先日ようやく高級言語ベースのフレームワークと新SDK「ATI Stream SDK 1.3」を発表。これで、CUDAに対抗できるだけの土台を揃えることができた。
NVIDIAに後れを取ったAMDは、GPUのストリームコンピューティングではコンシューマ用途を強調する。HPCへの戦略の強化も行なうが、ビデオエンコードソフトの無償提供といった目立つ手を打って来たのはコンシューマ分野だった。HPCの世界である程度の成功を収めたNVIDIAに対抗するには、まだ花開く前のコンシューマ市場の掘り起こしに力を向けるのが有利と判断したと推測される。様子見状態だったコンシューマアプリケーションでなら、完全に互角に戦うことができるからだ。
 |
 |
 |
 |
| ATIのStream SDKの提供 | |
こうしたGPUベンダーの動きに呼応して、言語&ツールのコミュニティも急ピッチで対応を進めている。今年(2008年)中盤からは、各プロセッサを横断的にカバーする言語環境の開発が熾烈なレースに入った。OpenGLを策定するKhronos Groupは、データ並列コンピューティングをターゲットにしたプログラミング技術「OpenCL」を急ピッチで策定中。同グループはOpenCL構想の発表後に「規格策定のレコード記録を作る」(Neil Trevett氏, Chairman, Khronos Group)と豪語している。一方、Microsoftは8月にDirectX 11に含めると発表した汎用コンピューティング向けシェーダステージ「DirectX Compute Shader」を前倒しでDirectX10世代でリリースするとWinHECで発表した。
こうして見ると、GPUを汎用コンピューティングで利用するムーブメントには、慌ただしい動きがあることがわかる。水面下では、業界関係者がラッシュで開発や策定を行なっている。来年(2009年)には、こうしたGPU側の動きに、さらに、「Larrabee(ララビ)」を擁するIntelが加わる。ハードとソフトのどちらも、来年に向けて、全てが雪崩を打って動きつつある。
●CPUとGPU、グラフィックスと他のタスクの区別がなくなる
GPUの汎用コンピューティングでの利用。いや、IntelのLarrabeeを控えた現状では、これは正確な表現ではない。「データ並列偏重型のプロセッサを、より汎用的なアプリケーションで使うこと」は、コンピュータの世界の最重要なテーマとなりつつある。
今の段階では、まだ、GPUやLarrabeeといった特殊なプロセッサを、限られた用途に広げようとする動きにしか見えないかもしれない。アプリケーションもHPC分野でなければ、ビデオエンコードなど限られたものしか見えない。
だが、実際には、データ並列の活用は、限られたハードの限られたアプリケーションへの展開ではない。なぜなら、近い将来には、PC&サーバー向けCPUでもデータ並列が重要な要素となるからだ。今後のプロセッサの進化のポイントは「データレベルの並列性(DLP:Data-Level Parallelism)」にあり、PC向けの汎用的なCPUの将来もデータ並列型のプロセッシングを強化する方向にある。IntelもAMDも次の世代のCPUからはベクタ命令拡張を行なって行く。GPUやLarrabeeのようなDLPを活用したスループット重視のプロセッサは先触れであり、そのフィーチャの一部はPC&サーバー向けCPUにも、時間差で取り入れられて行くと見られる。
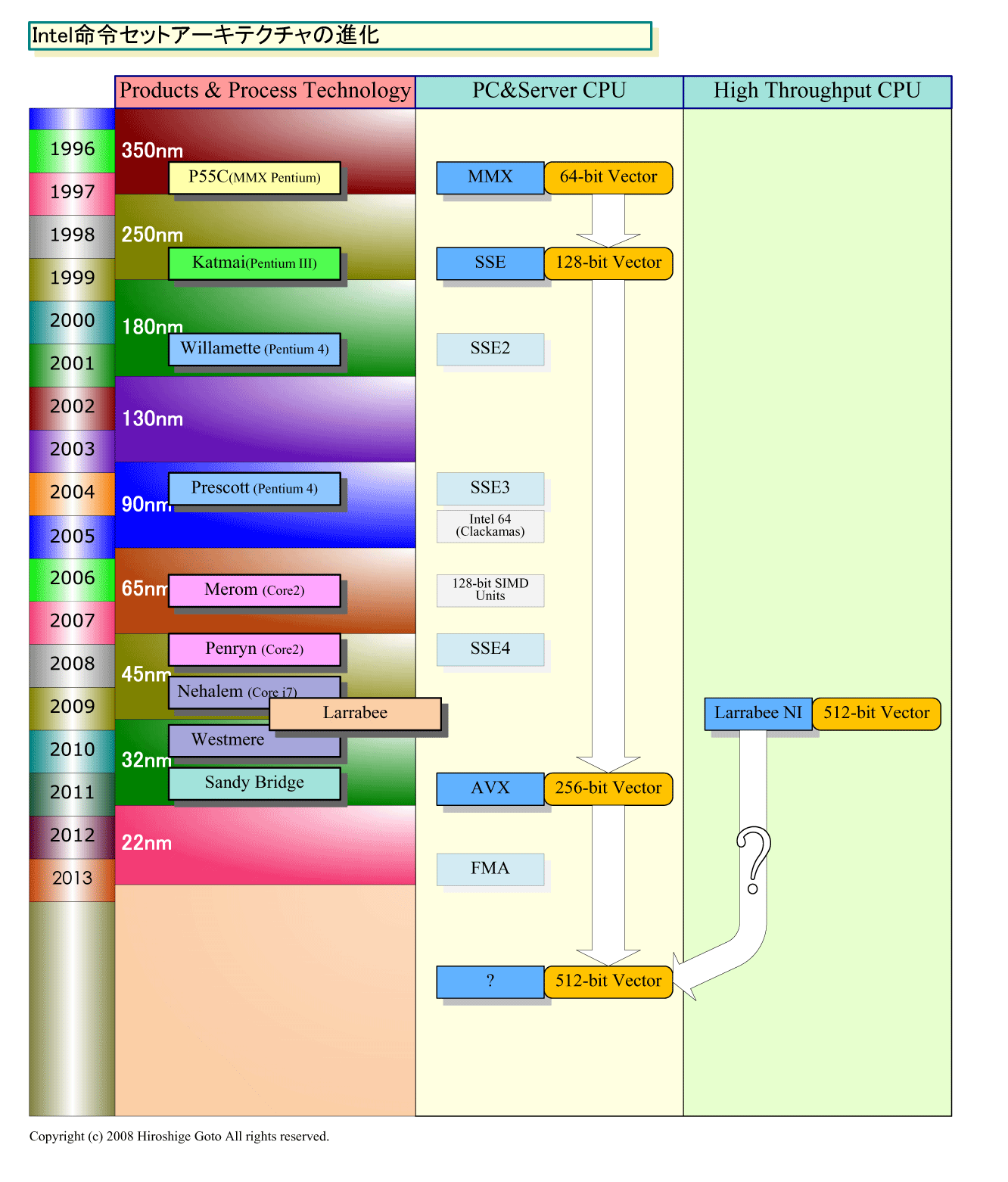 |
| CPU命令セットアーキテクチャの進化 ※別ウィンドウで開きます (PDF版はこちら) |
こうした変化の先に待っているのは、CPUとGPUの区別がなくなる未来だ。今は、GPUのようにデータ並列に特化したプロセッサと、データ並列の面は極めて限られているCPUとに分化している。しかし、PCの主役である、この2種類のプロセッサは、近い将来にアーキテクチャ上の同じポイントに近づいて行く。GPUは、プログラム性とアーキテクチャ上の柔軟性を高めつつある。一方、CPUは、GPUと同じようにベクタ演算を強化して、多くのコアを載せつつある。最終的には両者とも、ベクタ演算が強いプログラマブルなプロセッサコアを多数載せたアーキテクチャになるだろう。
結果として、CPUとGPUのアーキテクチャ境界は曖昧になる。CPUはデータ並列を強化したものと、汎用性の強いものといった分化へと向かっており、最もラディカルな部分はGPUにより近づく。下の図は2009年時点でのアーキテクチャを抽象化したものだが、この先に進むと下の2つは境界が曖昧になって行くと考えられる。
最終的にCPUとGPUの差異は、データ並列にどの程度の重点を置くかという程度になってしまうかもしれない。CPU型とGPU型のプロセッサのハイブリッド混合も考えられるため、両者の区別は完全に意味がなくなってしまうだろう。ある意味では、GPUはなくなる。少なくとも専用ハードウェアとしては。
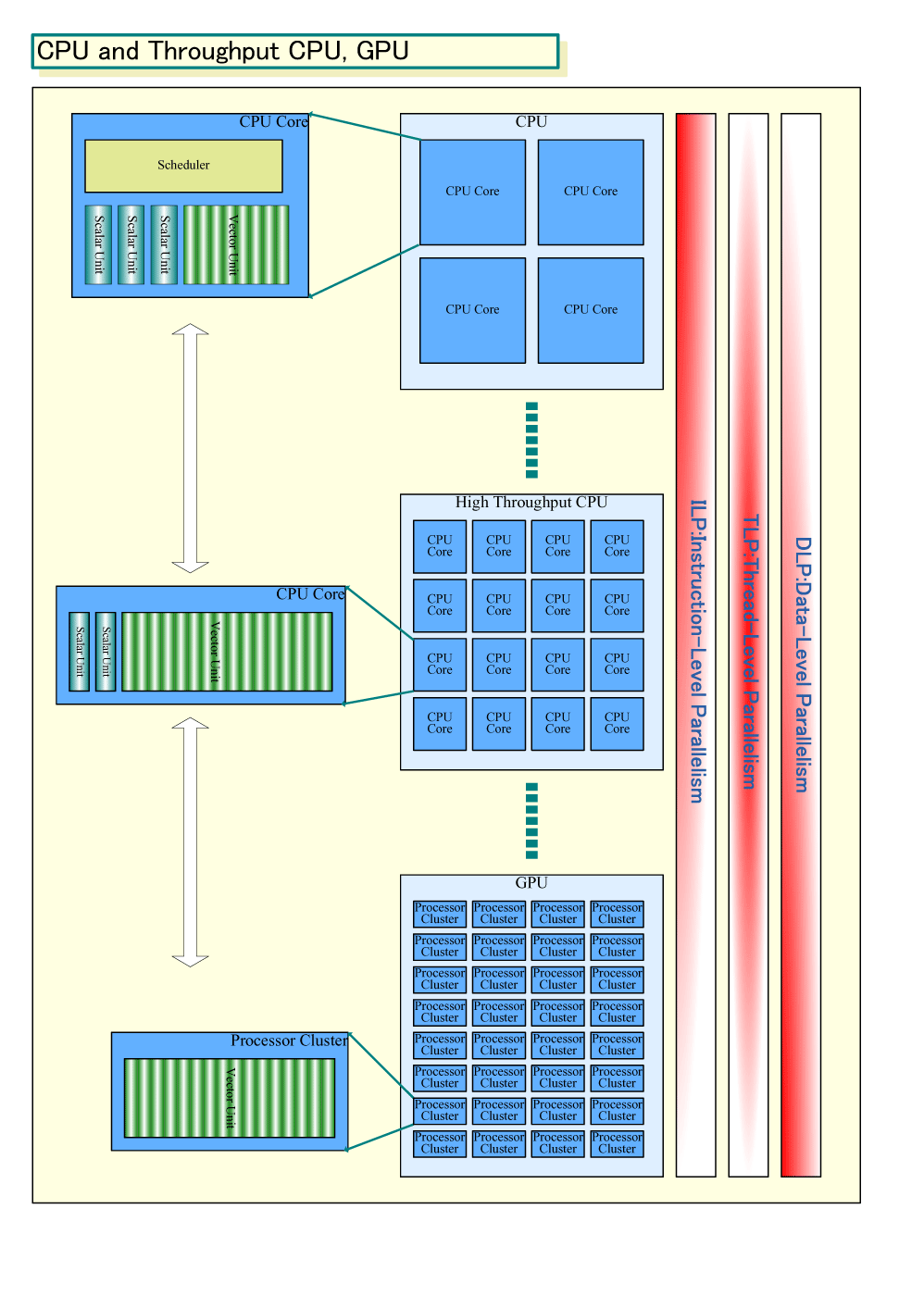 |
| CPUアーキテクチャの分化と共通化 ※別ウィンドウで開きます (PDF版はこちら) |
同様に、グラフィックスと他の汎用的なタスクの区別もなくなる。現在、PCでの3Dグラフィックスは特殊なタスクで、専用ハードウェアであるGPUでのみ実行される。特定のグラフィックスAPIを経由してのみハードウェアにアクセス可能で、グラフィックスAPIがGPUの機能も規定する。それに対して、その他の多くのタスクはCPUで実行され、ネイティブプログラムは直接CPUにアクセスすることが可能だ。
だが、CPUとGPUの境界があいまいになると、グラフィックスも普通のタスクの1つへと変わって行く可能性がある。プログラマブルなハードウェアにダイレクトにアクセスする道が開けるため、グラフィックスAPIに頼る必要がなくなるからだ。グラフィックスを全てCPUで処理していた昔に戻るわけだ。グラフィックス側から見れば、規定のグラフィックスAPIを経由したモデルから、ソフトウェアレンダリングへの移行となる。
これが浸透すると、最終的にDirect3DのようなグラフィックスAPIがなくなる。完全になくなるわけではないが、ゲームなどの3Dアプリケーションの全てがグラフィックスAPIを経由する形ではなくなるだろう。当然、グラフィックスAPIがハードウェアの機能を規定することもなくなる。Tim Sweeney氏(CEO, Founder, Epic Games)は「グラフィックスAPIを介さない新しい時代が来る」と語る。また、あるOpenCL関係者は「個人的な見解だが、最終的にはOpenCLがOpenGLを飲み込んでしまうと考えている。OpenGLはOpenCLから利用できるライブラリ群という位置づけになるだろう」と言う。
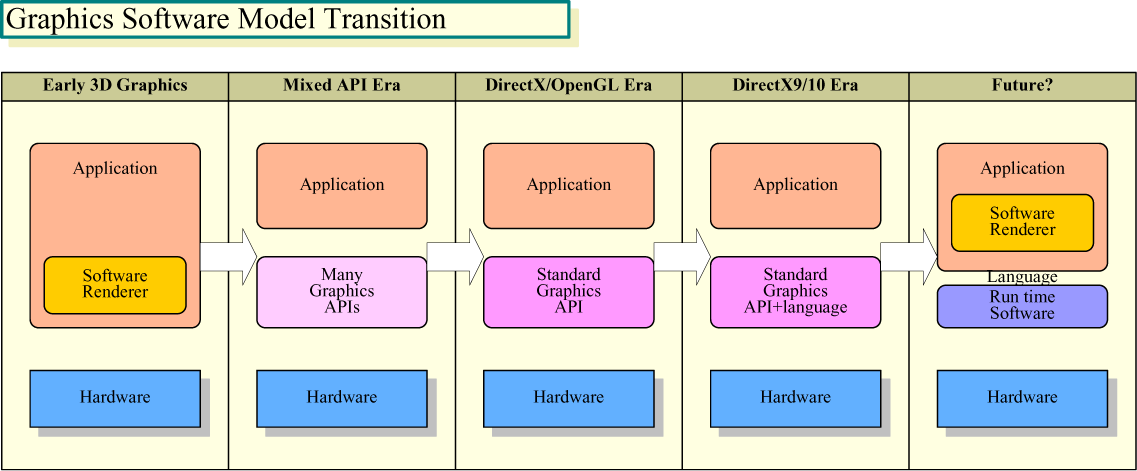 |
| グラフィックスソフトウェアモデルの変化 ※別ウィンドウで開きます (PDF版はこちら) |
●CPUの進化の方向がGPUの進化の方向と一致し始めた
プロセッサの進化のポイントがデータ並列になったのは、必然的な流れでもある。一定の消費電力の枠内での「命令レベルの並列性(ILP:Instruction-Level Parallelism)」の向上が行き詰まったからだ。CPUは、パフォーマンスを上げるために、「スレッドレベルの並列性(TLP:Thread-Level Parallelism)」と「データレベルの並列性(DLP:Data-Level Parallelism)」を上げる方向へと大きく傾いた。具体的には、マルチコア化によるTLPの強化と、SSEとその後継の命令をサポートするベクタエンジンによるDLPの強化だ。消費電力とダイサイズ(半導体本体の面積)当たりの性能を上げるためには、ILPの強化は抑え、TLPとDLPに集中する必要がある。
マルチコア化はすでに数年前から始まっているが、タスク/スレッドの並列化で性能を向上できる幅は、アプリケーションによって限られる。そのため、必然的に、次の突破口はベクタプロセッシングによるDLPの向上となる。だからこそ、IntelもAMDも、今後のCPUアーキテクチャでのベクタ命令の拡張を強調する。現実的には、将来のCPUもILPとTLP、そしてDLPのバランスを取ることになるが、従来のCPUと較べるとDLPとTLPに大きく振られることは間違いがない。そして、DLPとTLPへと極端に振った切り込み部隊がGPUとLarrabeeだ。
GPUは、固定ハードウェアからプログラマブル化を進めた結果、汎用的なアプリケーションも視野に入れられるようになった。GPUベンダーがこうした構想を語り始めた4~5年前は、彼らはCPUがGPU的なデータ並列の追求はしないだろうと見ていた。しかし、CPUアーキテクチャの進化の方向が、スレッド並列に加えてデータ並列の追求になったことで、状況は大きく変わった。GPUが占めようとしていたデータ並列コンピューティングの分野は、CPUも乱入する主戦場となろうとしている。
●次のフェイズはプログラミングフレームワークの戦い
こうした状況で、データ並列をいかに使いやすくして普及させるかが重要なポイントとして浮かび上がってきた。これまでは、言ってみれば助走期間。本格的な戦いと普及は、ここから先になる。そして、データ並列への動きがしきい値を超える「ティッピングポイント(Tipping Point)」が来年から始まると業界関係者は見ている。
なぜなら、来年から再来年にかけてプレーヤーが全て揃い、熾烈な戦いが本格的に始まるからだ。揃うのは、LarrabeeやNVIDIAとAMDの次世代GPUといったプロセッサハードウェアだけではない。プログラミング環境やライブラリ、アプリケーションまで全ての層で急速な展開が進みつつある。この初動が重要となるのは、PCでのデータ並列コンピューティングでは、まだ何もスタンダードが決まっていないからだ。
PC向けCPUでは、x86命令セットが混戦を抜け出して独占的なインターフェイスとなった。x86命令をハードウェアまたはソフトウェアで実装しなければ、成功できなくなった。しかし、GPUにはスタンダードなネイティブ命令セットはなく、そもそもネイティブ命令自体を露出させないのが一般的だ。多様なハードウェアにアクセスする、多種多様なアプローチが入り乱れており単一の戸口がない。
例えば、NVIDIAとAMDは中間言語(ドライバのランタイムのAPI)までしか露出させないのに対して、Intelはネイティブ命令セットを公開する。NVIDIAのCUDAは中間言語へのコンパイラを用意して独自に拡張したCやFORTRANをサポートし、AMDはスタンフォード大学産まれの「Brook+」などを使い同様の環境を提供する。どちらもネイティブ命令セットは隠蔽するGPU型のアプローチを踏襲するが、高級言語に露出させるハードウェアアーキテクチャの深さはNVIDIAとAMDで異なる。
一方のIntelは、x86命令セットを拡張する「Larrabee新命令(Larrabee New Instructions:LNI)」を露出させ、さらに独自のスループット言語「Ct」も準備する。AMDも、以前のCTOインタビュでは、GPU機能にアクセスする命令は、x86の命令スペースに格納すると語っており、長期的にはIntelと似たようなアプローチへと移って行くと推測される。このモデルは、ベクタエンジンを多様なx86コアへ移植することを可能にする。
こうして異なるプログラミングモデルと異なる方言の言語拡張が増えて行くなかで、ハードウェアを大横断する形で、DirectX Compute ShaderとOpenCLが登場する。
OpenCLはかなり野心的で、CPUとGPUの両方を含めた全てのコンピュテーショナルリソースをプログラムできる環境を目指している。データ並列とタスク並列の両方のモデルをカバーし、メモリ階層も言語の中でモデル化する。ハードウェアの差異をローレベルのアブストラクションレイヤで吸収する構造だ。ハードウェアの抽象化をさらに高いレベルへと引き上げる試みだ。
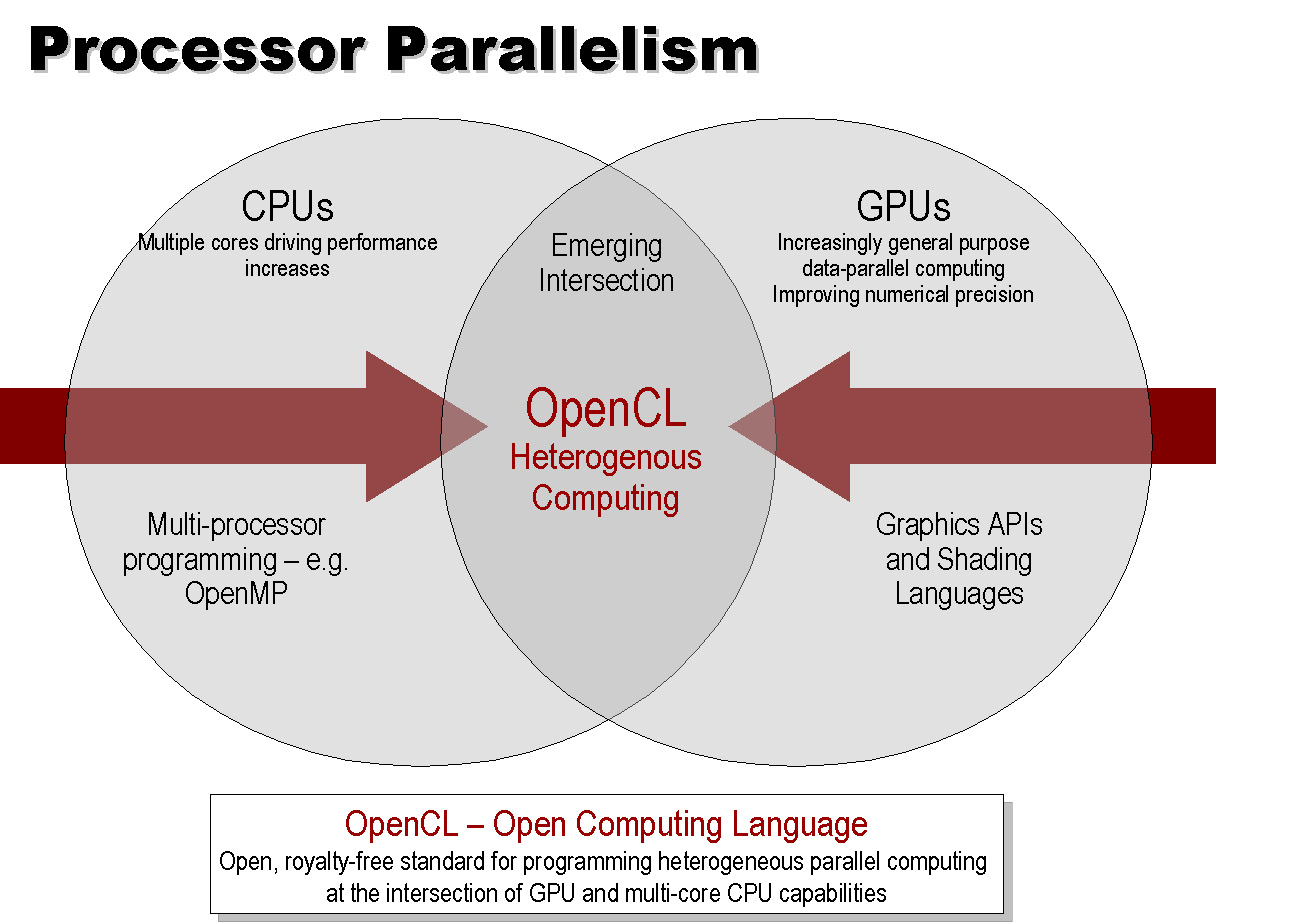 |
| OpenCLによるプログラミング |
こうした状況で、より多くのアプリケーションを、自分のアーキテクチャの上で花開かせることができたものが勝者に近づく。もちろん、ハードウェアに限らず、プログラミングフレームワークも同様だ。そして、そこで重要となるのはスピードだ。いち早くリリースし、プログラミングコミュニティに迅速に普及させ、スタンダードを狙う。だから、NVIDIAもAMDもIntelもMicrosoftもKhronosも急いでいる。
現在リードしているのは、明瞭にNVIDIAのCUDAだ。しかし、データ並列コンピューティングの利用自体が急速に展開するポイントにまだ達していないため、今後の展開はまだ予想がつかない。CUDAのモデルはハードウェアアーキテクチャをある程度露出させているため、マスに浸透させるには別な手段が必要だ。NVIDIA自体も、CUDAと、OpenCLのようなより抽象度の高いプログラミング技術が併存する余地があると説明している。
いずれにせよ、これからしばらくは、プロセッサの戦いの主戦場はデータ並列になりそうだ。2009年は、そこが注目ポイントとなる。
□関連記事
【11月25日】【海外】GPUとの違いが際立つLarrabeeキャッシュアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1125/kaigai477.htm
【7月16日】【海外】Larrabeeに追われるNVIDIAがGT200に施したGPGPU向け拡張
http://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
【7月2日】【海外】NVIDIAのGT200とAMDのRV770のどちらが優れているのか
http://pc.watch.impress.co.jp/docs/2008/0702/kaigai451.htm
(2008年12月2日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.