 |


■後藤弘茂のWeekly海外ニュース■未来に強く過去に弱いIntelのLarrabee |
●転換したCPUが抱えた3つのチャレンジ
2004年の早い時期にIntelは、巨大コアのCPU「Tejas(テハス)」をキャンセル、同じく巨大コアだったと推定される最初のプランの「Nehalem(ネハーレン)」の設計方針を修正した。ほぼ同じ時期にAMDはK8後継のCPU「K9」の開発を中止している。振り返れば、2004年がx86系CPUのアーキテクチャの転換点だった。
x86の2大メーカーの軌道修正は、2002年から2003年頃に明瞭になったCPUコアのシングルスレッド性能向上の停滞と、停滞の原因であるCPU消費電力の急上昇の結果だ。2002年の時点で、シングルスレッドのシーケンシャルコードの性能を上げることが難しいことが明瞭になった。そのために、CPUベンダーは、マルチコア化とベクタ演算の強化によって性能を上げる方向に転じた。
2003~2004年にかけてIntelとAMDの両者はそうした認識に立って、路線の変更を行なった。TejasとK9のキャンセルはその象徴だ。そして、3~4年を経た2007~2008年にかけて、変更した方向性がより明瞭に打ち出された。今後は、この路線に沿ったCPUアーキテクチャが次々に花開くことになると予想される。
しかし、CPUメーカーの下した決断は3つの新しい問題を生み出した。
(1)は、既存のコードを速く走らせるというこれまでのCPU進化から外れたことによって、ソフトウェアの「フリーランチ」が終わってしまったこと。CPUの性能を引き出してもらうためには、今後のソフトウェアに、マルチスレッド化とベクタ最適化を求めなくてはならない。そのための、プログラミングモデルや言語、あるいはコンパイラ技術の確立と普及が必要となる。
(2)は、マルチコア化とベクタ化で上がるコンピューティングパフォーマンスに見合う、メモリテクノロジの不在。DDR4は事実上白紙に戻り、コモディティDRAMの転送レートの向上のペースは、CPU性能の向上に追いつかない。そのため、メモリがCPU性能の足を引っ張る可能性が強まってきた。
(3)は、データ並列を追求して汎用性を高めてきたGPUという新しいライバルの出現。CPUの進化のコースが、プログラマブル化するGPUの進化の方向と近づいてしまったため、CPUは部分的にはGPUと戦わなくてはならなくなった。CPUとGPUが近づく、あるいは融合する流れの中で、CPUメーカーは自社の製品の特徴と位置づけを再定義しなければならなくなった。
ここでポイントは、汎用的なデータ並列コンピューティングだけの問題ではないことだ。クライアントコンピュータでは、グラフィックス性能自体が重要となったため、将来のCPUはグラフィックス性能と効率でもGPUと競争しなければならない。グラフィックスをCPUのアプリケーションとして取り込む必要があると言い換えてもいい。
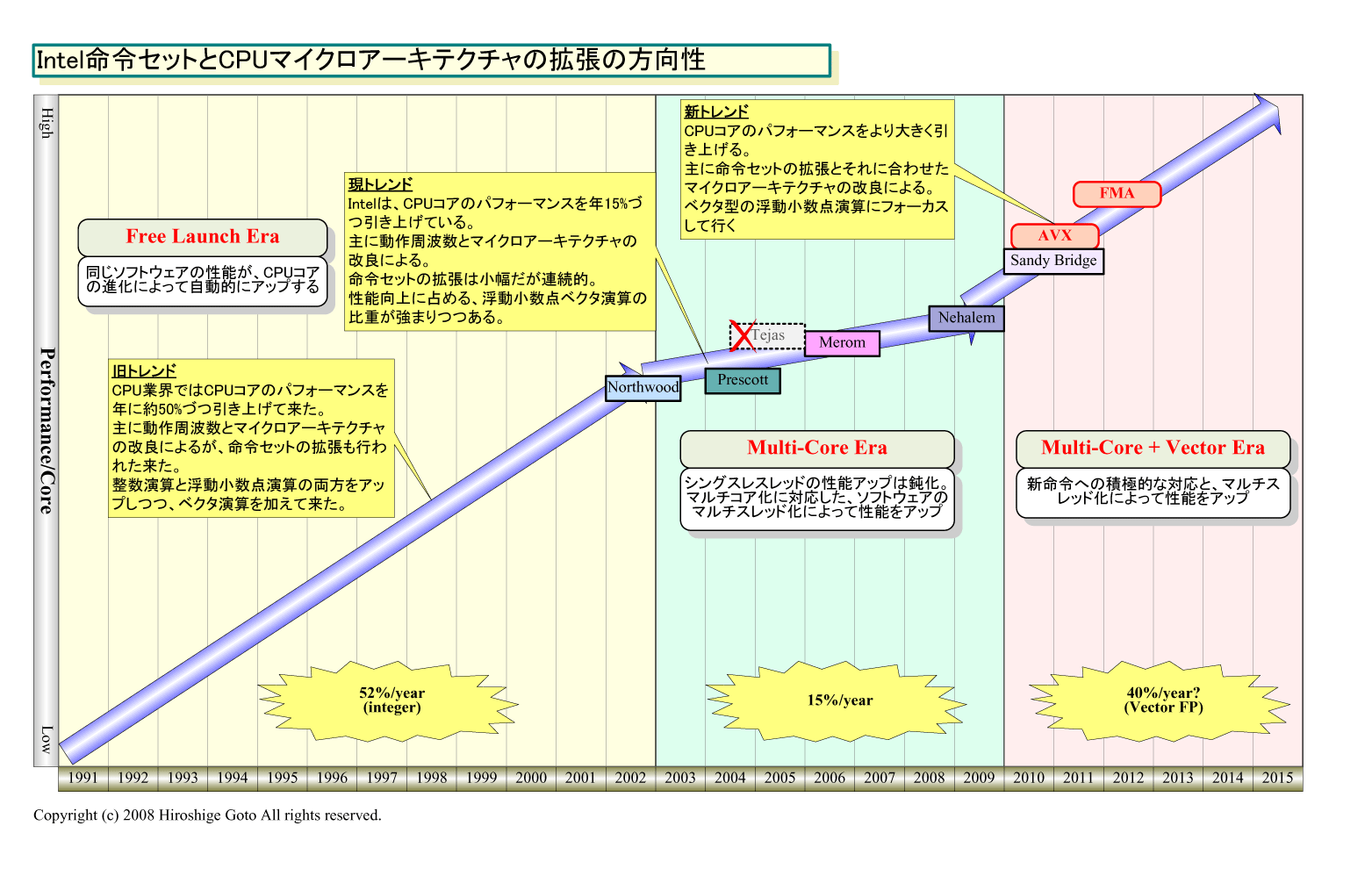 |
| Intel命令セットとCPUアーキテクチャの方向性 (別ウィンドウで開きます) ※PDF版はこちら |
●急展開が進む2009年のCPUを巡る環境
来年(2009年)以降のCPU&GPUを巡る状況が興味深いのは、こうした潮流に対応した技術の開発や競争の激化が顕著になるからだ。
プログラミングでは、マルチスレッドからデータ並列へと流れが動いている。データ並列向けのクロスベンダの“ローレベル高級言語”である「OpenCL」が、記録的な速さで策定された。並列処理と相性がいい関数型言語の“プチブーム”もある(「Haskell」が最近の流れだが、手続き型言語の牙城であるMicrosoftですら「F#」を出した)。一方、メモリ問題では、中期的な解決となりうるシリコン貫通ビアのメモリのダイ(半導体本体)スタッキングやその類似技術が視界に入る。そして、対GPUでは、CPU側からGPUと同じ土俵で戦う「Larrabee(ララビ)」が見えてくる。
プログラミングの部分は、実は、このストーリの核の部分であり、根底からの変化となるため非常に重要だ。しかし、ハードウェアコミュニティ側からは見えにくい、“向う岸”の戦いとなっている。メモリの件は、純粋にベンダー間の技術と経済の話で、動向としては非常に重要だが、ユーザー側にとっては直接的な変化ではない。表面に出る激しい戦いとなるのは、GPUとCPUの戦い(=技術クロスオーバー)だろう。
CPUとGPUの戦いは、両者にとって生存理由を賭けた戦いである。CPUが、マルチコア化とベクタ演算強化あるいはGPUコアの統合化によってGPUの領域を侵すと、最終的にGPUの存在理由はなくなってしまう。そのシナリオの到達点では、グラフィックス専用ハードウェアはPCの中に存在しなくなり、グラフィックス性能を上げるには、より高性能なCPUを載せる、CPUをより多く載せるようになる。
逆に、GPUがCPUの伸びようとする領域を占めてしまうと、主客の立場は逆転する。並列コンピューティングが力を発揮するアプリケーションは全てGPUで走るようになる。CPUに求められるのは限られたシーケンシャルコードの性能だけになり、ヘビーなCPUは不要となり、Atom系の軽量なCPUが主流になってしまう。
AMDがATI Technologiesを求めた理由の1つは、技術者がトップ陣を占める同社に、こうした未来が明瞭に見えたためだろう。両方を押さえてしまえば、どっちへ転んでも問題はない。スマートにCPUとGPUを融合させれば、両陣営を押さえることができる。
しかし、Intelのアプローチは違った。Intelは、CPUアーキテクチャを発展させることで、未来を掴もうとした。同社の戦いは、まずLarrabeeという製品の形で始まる。
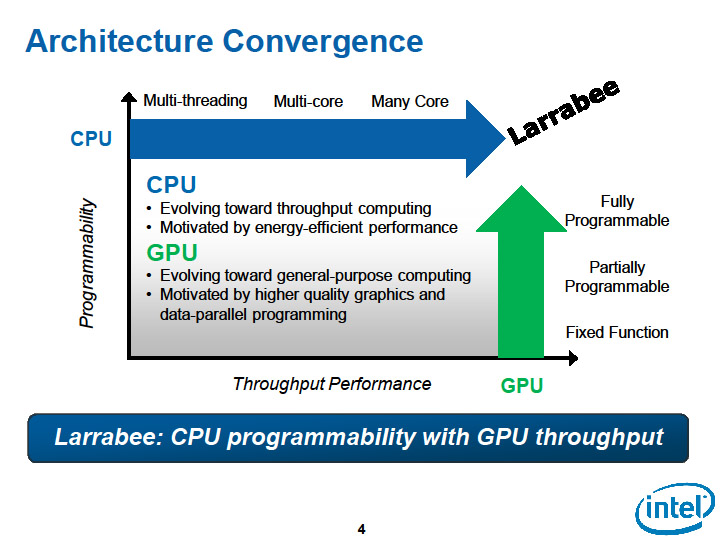 |
| LarrabeeとGPUのそれぞれのアプローチ |
●漸進的なGPUと飛躍するLarrabee
GPUの強味は、グラフィックスから汎用コンピューティングへとアプローチしていること。この特徴は、同時にGPUの弱味でもあるが、今のところはプラスに働いている。
(1)まず、GPUではグラフィックスというアプリケーションと市場がはっきり見えている。(2)グラフィックス用として製品をインストールドベースを広げ、大量出荷で開発費を償却し低コスト化ができる。(3)CPUのタスクよりずっと重いグラフィックス向けとしてコンピューティングパフォーマンスを引き上げ続ける必然性がある。(4)並列処理が容易なグラフィックスに向けたアーキテクチャを、他のデータ並列が有効なアプリケーションに広げやすい。
こうした利点を背景に急伸してきたGPUに対抗するため、IntelはLarrabeeをグラフィックス製品として投入する選択を行なった(HPC向けにも出す)。グラフィックス製品としてGPUと競争して市場を獲得しつつ、汎用アプリケーションも獲得して行く戦略だ。しかし、短期的には、Intelのこの決断は、苦しい戦いを同社に強いることになるだろう。Larrabeeは、既存のグラフィックスアプリケーションでは、GPUに勝てない可能性があるからだ。
このことは、Larrabeeのアーキテクチャが稚拙であることを意味してはいるわけではない。Larrabeeは、ソフトウェアレンダリング化する未来のグラフィックスでは、優れた性能と柔軟性を発揮できる可能性が高い。しかし、既存のグラフィックスでは、GPUに勝てるだけのパフォーマンス効率を達成できない可能性がある。特に、Larrabeeはテクスチャヘビーな今どきのゲームグラフィックスなどでは弱いケースが出てくる。そのため、スタート期にはLarrabeeの戦いは、難しいものになるかも知れない。
グラフィックスをターゲットとしたプロセッサ開発で非常に難しいのは、グラフィックスアプリケーションの進化を予測してアーキテクチャを開発することだ。これは、伝統的な固定ハードウェアのグラフィックスアーキテクチャから発達してきたGPUを見るとよくわかる。
GPUは、既存グラフィックスの性能を落とさないように、なおかつ、将来のグラフィックスで性能を発揮できるように、微妙なバランスを取って設計されている。先へと振りすぎると、より保守的な設計をとったライバルに、現行アプリケーションの性能で負けてしまう。そして、問題はプログラム性と柔軟性を増すことが、必ず固定的な処理の効率を削る方へ働いてしまうことだ。固定ハードウェアの方が、プログラマブルハードウェアより効率が高いため、これは必然的だ。
しかし、CPUメーカーであるIntelにそうした発想はない。そのため、Larrabeeでは、ダイヤルを思い切り回して、プログラム性と柔軟性にフォーカスした。Intelにしてみれば、CPU屋の利点を出せるのは、こうしたアプローチであり、GPUと同じものを作っても仕方がない。Intelにも、選択肢がなかったと言える。
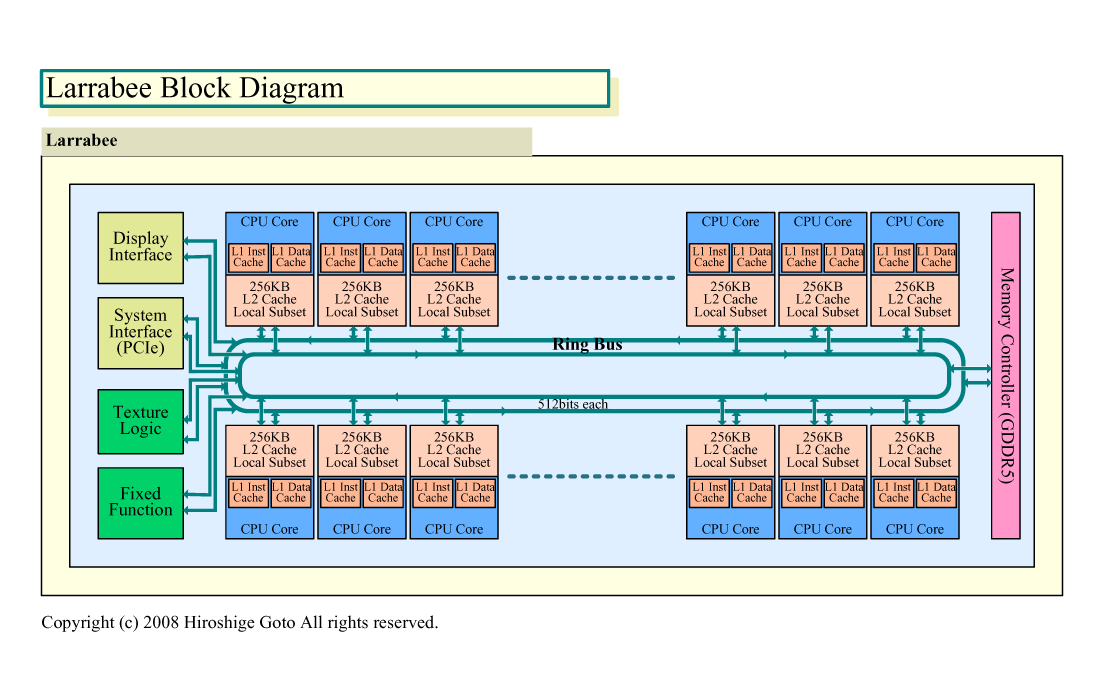 |
| Larrabeeのブロックダイアグラム (別ウィンドウで開きます) ※PDF版はこちら |
●未来に向かうか過去を振り返るかが難しいポイント
いずれにせよ、Intelが取ったのは、グラフィックスハードウェアとしてはラディカルな手法だった。Larrabeeは、既存のグラフィックスAPIもサポートするが、そのアーキテクチャの真価が発揮されるのは、APIを取っ払ってダイレクトにレンダリングエンジンを書くようなアプローチの場合だ。この半年間で、ソフトウェアレンダリングのアプローチを何人もの業界関係者が語るようになり、現実味も帯びている。しかし、ラディカルな変化であることは間違いがなく、すぐに移行が行なわれるわけではなさそうだ。
こうした状況で、Larrabeeは登場時点では、既存のグラフィックスアプリケーションでの性能を競わなくてはならない。その場合、Larrabeeの非GPU的なアプローチが、パフォーマンス効率の障害となる可能性がある。
Larrabeeの基本の発想は次のようなものだと推定される。(1)データ並列とスレッド/タスク並列のバランスを取りつつ、従来CPUより1桁高い高スループットを狙う。(2)グラフィックスに特化したユニットや構造は最小限にとどめて柔軟性を高める。(3)PC&サーバー向けのCPUコアにも、場合によっては実装が可能なアーキテクチャを取る。(4)メモリ帯域が高コストでネックとなるため、キャッシュメモリでデータの局所性をできるだけ利用する。
対する、GPUのアプローチは次のようになる。(1)より効率の高いデータ並列に思い切り振ったアーキテクチャを取る。(2)グラフィックスでの効率性を高めるため、グラフィックスに特化したユニットや構造はある程度残す。(3)PC&サーバーのCPUへのアーキテクチャ的な統合は、全く(NVIDIA)、あるいは、ほとんど(現状のATI)考慮しない。(4)データの局所性の利用はスクラッチパッドメモリで限定的に止め、コストを犠牲にしてもメモリ帯域を広げる。
Larrabeeにとってのハードルは、旧来のグラフィックスAPIとアプリケーションが、後者のGPUに最適化して発達して来たことにある。グラフィックスの未来はLarrabeeの方向にあり、将来のGPUもある程度似た方向へ向かうことは間違いがない。いったん伝統的なグラフィックスを離れて、例えば、ボリューメトリック(volumetric)やレイトレーシング(Ray Tracing)といった手法を使うとLarrabeeの利点が生きる。しかし、緒戦では過去を向いて戦わなければならない。
●グラフィックスパイプに最適化したGPUのデータパス
Larrabeeが、GPUとグラフィックスのパフォーマンス効率で戦う場合の困難にはさまざまな原因がある。一例を挙げると、データ転送のパスがある。
グラフィックスアプリケーションは、非対称なデータの流れが特徴だ。伝統的なグラフィックス処理では、上りの帯域を大きく食うのはテクスチャフェッチ。下りの帯域を食うのはピクセル打ち込みがあるラスターオペレーション(上りメモリ帯域も食う)。あとは頂点ストリームもあるが、メモリを圧迫するのは主に上に挙げた2つだ。グラフィックスに最適化されたGPUは、この特殊なデータの流れに合わせた構造を取っている。
具体的には、テクスチャフェッチのために、メモリ→テクスチャユニット→シェーダプロセッサと結んだ上り専用の広帯域パスを持つ。その一方で、パイプラインの最終段のいわゆるラスターオペレーションユニットは、広帯域のメモリコントローラと直結されていることが多い。NVIDIAのGeForce 8800/GTX 200(G80/GT200)とAMD(ATI)のRadeon HD 4000(RV7xx)は、どちらもこの構造を取っており、構成は非常に似通っている。GPUベンダーがこうした特殊な構造を取るのは、汎用的な内部バスは、グラフィックスでは非効率的だという判断からだ。
実際、AMD(ATI)は、一度は汎用度の高いリングバスをGPU内部バスに採用した。RADEON X1000(R5xx)世代では部分的にリングバスを、Radeon HD 2000(R6xx)世代では全面的にリングバスを採用した。シェーダプロセッサやラスターオペレーション、メモリコントローラは全てリングバスにぶら下がっていた。しかし、現行世代のR7xxでは、再び、GPU型の非対称のバスへと戻している。
AMD(ATI)でバスの設計を担当したアーキテクトFritz Kruger氏(Architect, AMD)によると、その理由は次のようなものだったという。
「リングバスがチップ上で大きな面積を取り、電力も食っていた。リングバスのトラフィックを分析したところ、90%がテクスチャのトランスファだと判明した。そこで、RV770では、テクスチャL2キャッシュをメモリコントローラに、L1キャッシュをSIMDコア(プロセッサクラスタ)に密接に接続した。2階層のキャッシュの間は、クロスバスイッチで結んでいる。テクスチャ転送をクロスバへと切り替えたことで、リングバスから90%のトラフィックがなくなった。そうしたら、最終的にリングバス自体が不要となってしまった(笑)」。
AMD(ATI)が下した判断は次のようなものだ。グラフィックスでは、汎用のリングバスで結ぶと、消費電力とダイサイズの面で効率が悪い。代わりに、テクスチャを上り専用のシンプルなクロスバスイッチに流し、ラスターオペレーションユニットをメモリコントローラに直結すれば、ずっと効率のいいチップになる。実際に、R7xx系はリングバスのR6xx系より相対的にチップサイズが小さく、効率がいい。NVIDIAとATIがともに同じ構成を取ったことは、この構造が、今のグラフィックスでは効率がいいことを示している。
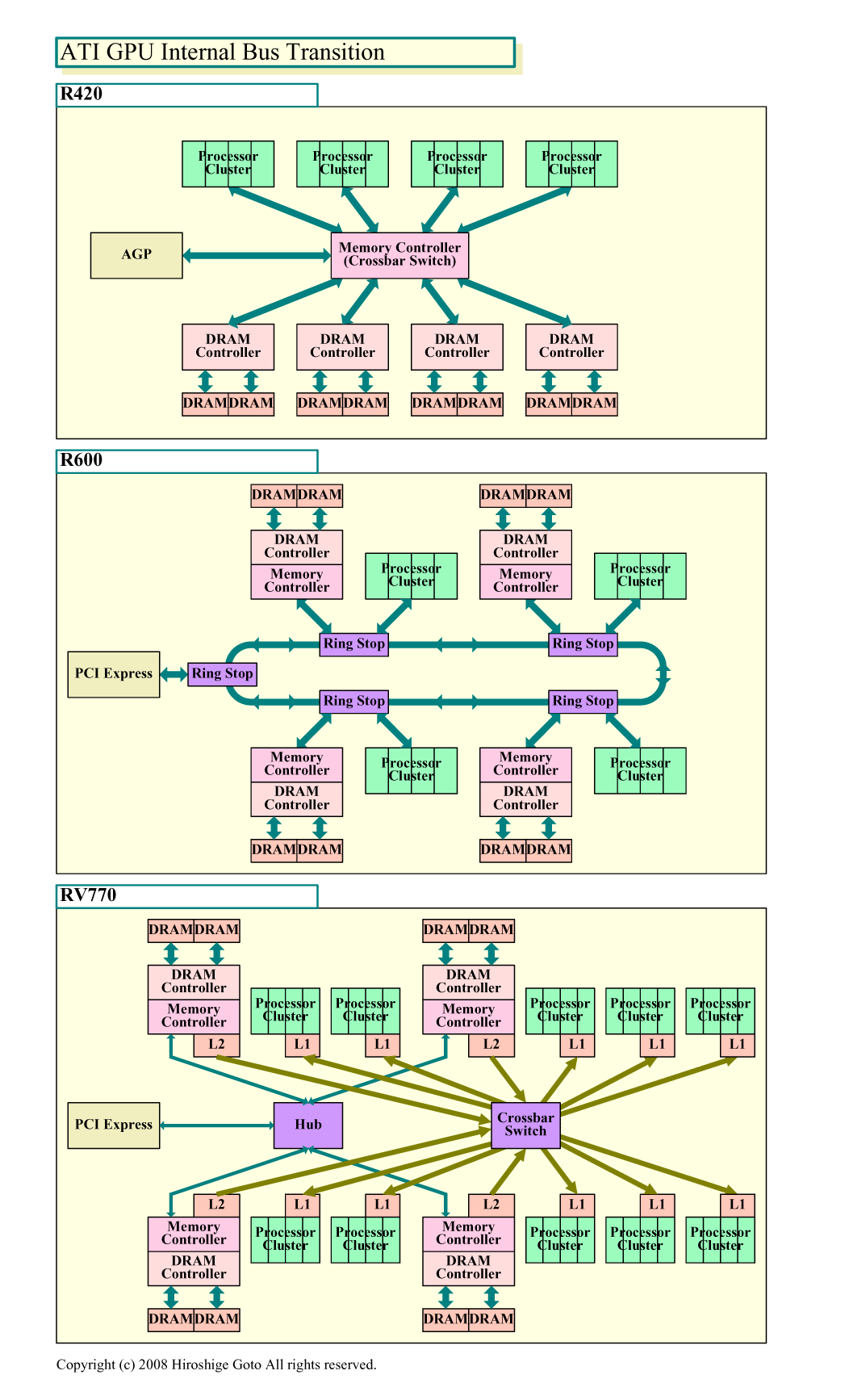 |
| R420~RV770の内部バス (別ウィンドウで開きます) ※PDF版はこちら |
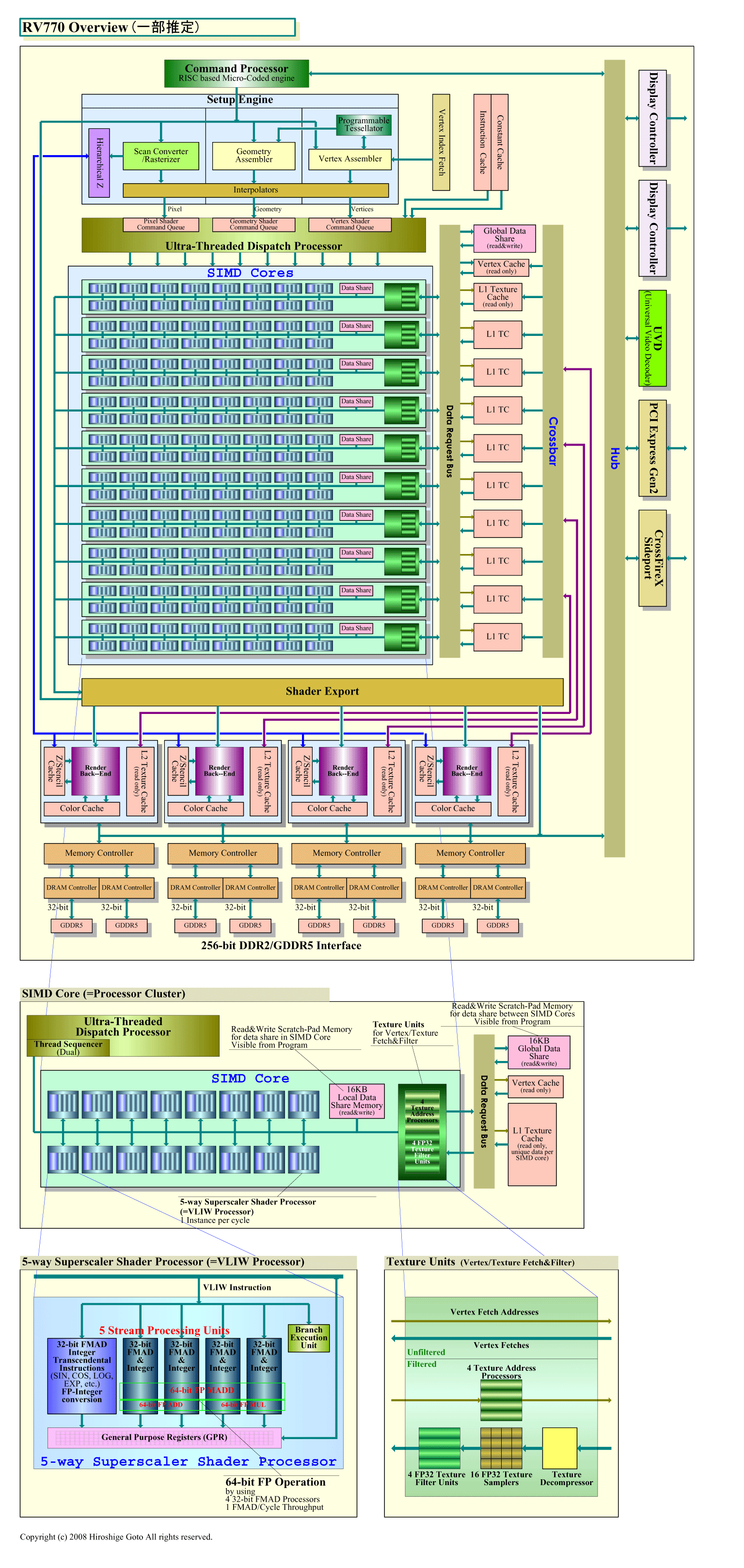 |
| RV770のオーバービュー (別ウィンドウで開きます) ※PDF版はこちら |
●タイリングでメモリアクセスのトラフィックを軽減
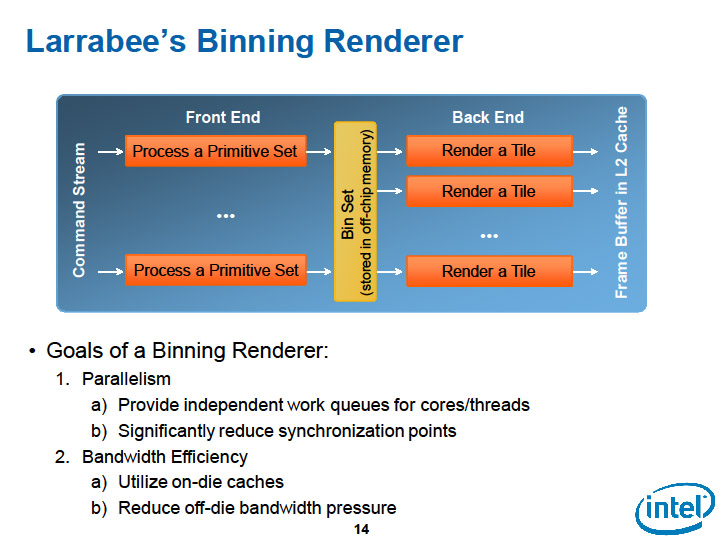
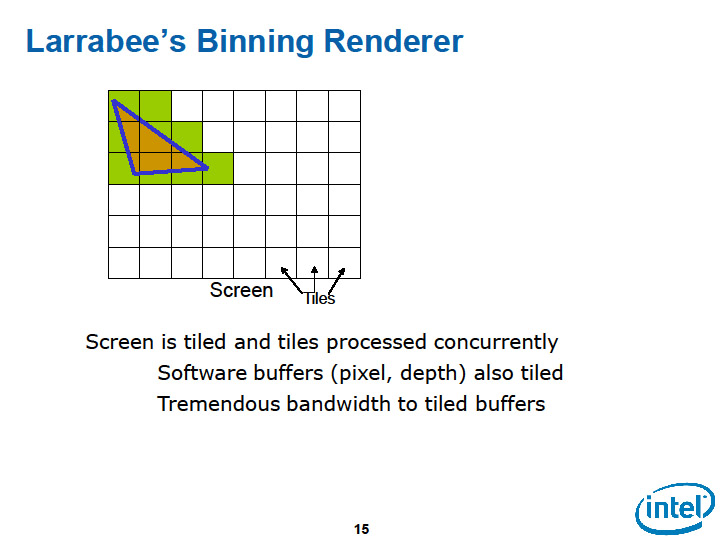
Larrabeeの場合は、GPUのようなグラフィックス処理に特化したデータパスは持たない。汎用的な双方向のリングバスで、CPUコアとテクスチャユニットとメモリコントローラの間を結ぶ。ラスターオペレーションを専用に行なうユニットも持たない。
そのため、GPUと同様にCPUコアから外部メモリに直接ピクセルを読み書きしようとすると、CPUコアとメモリコントローラを結ぶリングバスに負担をかけてしまう。そこで、Larrabeeでは、CPUコアとL2キャッシュをペアにして接続、タイリングアーキテクチャでL2キャッシュにピクセルのカラーやデプスデータを書き出すようにしている。
3Dグラフィックスは、データセットが巨大だが、タイルに分割すると、タイル間の依存性のないレンダリングジョブに分割することができる。Larrabeeは、この特徴をうまく使って、メモリアクセスのトラフィックをCPUコア-L2キャッシュ間に留める。ピクセルデータの参照と書き込みで生じるトラフィックは、リングバスには出ない。リングバス上には、原則的には最終段でマージされたピクセルデータを、フレームバッファメモリ領域に書き出す際のトラフィックしか生じない。そのため、Larrabeeのキャッシュ構成とタイリングの仕組みがうまく働けば、ラスターオペレーションの帯域の問題は解決することになる。
このアーキテクチャの壁の1つは、もちろんL2キャッシュの256KBという狭さだ。タイルをこの狭い領域に納めなければならない。Intelは、32-bit depthと32-bit colorで128×128タイルなら、256KBのL2の半分しか占めないと説明している。しかし、レンダーターゲットが複数になった場合(MRT:Multiple Render Target)などでは、必要とするメモリ量が増えるために問題が発生するため調整が必要になる。
とはいえ、Larrabeeの構造では、タイリングの制約にさえ目を閉じれば、パイプライン最終段でのピクセル&Zの打ち込みと参照のトラフィックは問題がなくなることになる。となると、残る問題はテクスチャの上りトラフィックとなる。ここでは、局所性が低くキャッシュ(バッファ)効率の悪い膨大な上り方向のトラフィックをどう解決するかが焦点になる。
 |
 |
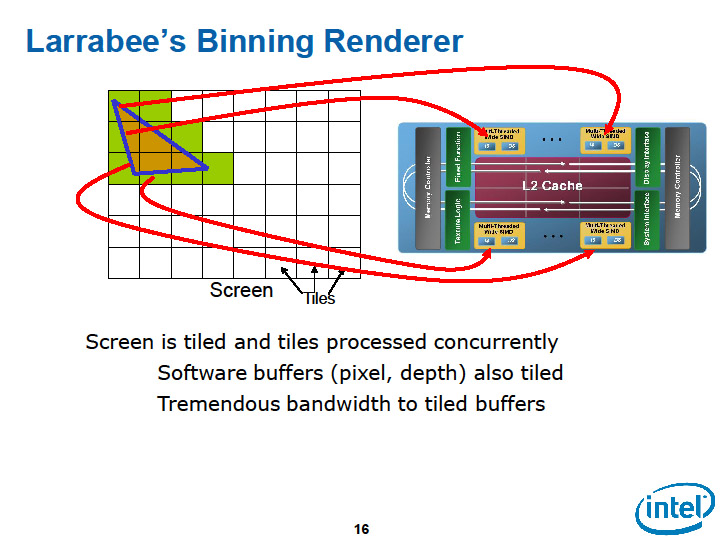 |
| Larrabeeはタイリングによりメモリアクセスのトラフィックを軽減する | ||
●テクスチャが多いとデータ転送が難しくなるLarrabee
GPUの場合は、まずメモリコントローラに付属して中容量のテクスチャキャッシュがあり、そこから広帯域の片方向クロスバスイッチでシェーダプロセッサクラスタへとキャッシュを転送している。プロセッサクラスタには、各クラスタ専用のテクスチャフィルタリングユニットがあり、ある程度の容量のテクスチャキャッシュが付属している。テクスチャフルタリングユニットとクラスタは広帯域バスで接続されている。
それに対して、Larrabeeでは、シェーディングを行なうCPUコアから独立してテクスチャユニットが存在する。他の処理と異なり、テクスチャフィルタリングだけはソフトウェアではなく、専用ハードウェアで行なっている。しかし、テクスチャユニットとCPUコア群はリングバスで結ばれているため、テクスチャのトラフィックはリングバスに流れるはずだ。リングバスを経由してテクスチャユニットにロードされ、フィルタリングを行なってから、各CPUコアにリングバスを経由して転送されると考えられる。
 |
| Larrabeeのテクスチャユニット |
Larrabeeのこのアーキテクチャの場合、AMD(ATI)のKruger氏が指摘したのと同じ問題が発生する。テクスチャのトラフィックでリングバスの帯域がムダに食われてしまい、パフォーマンス効率が落ちてしまう。こうして見ると、Larrabeeにとって、今時のゲームにあるような、テクスチャが重いアプリケーションは苦手である可能性が高い。少なくとも、効率の面では不利となる。
これはグラフィックスの場合だが、じつは汎用アプリケーションでもちょっと似たようなケースが出る場合がある。HPC(High Performance Computing)のような分野では、CPUコアへの上りのデータ量は多いが、下りは極端に小さい場合もある。そうしたアプリケーションでは、GPU型の非対称な構成の方が都合がよい可能性もある。データセットが極端に大きいとバッファも効かないため、メモリ帯域に頼るGPU的なアプローチでうまくワークすることになる。
また、Larrabeeの内部メモリは、PC&サーバー系CPUと同様にキャッシュメモリだが、HPCのような世界では、むしろ明示的に制御できる非キャッシュ型のスクラッチパッドのようなメモリが歓迎される場合も多い。再利用されないデータばかりだと、キャッシュは意味をなさないし、自分でデータを管理することでキャッシュミスをゼロにできるからだ。
こうして見ると、Larrabeeの利点は、従来型のCPUのプログラミングに慣れていて、なおかつ高スループットCPUを使いたいという領域にあることがわかってくる。この利点をフルに生かすには、本来はPC&サーバー向けCPUと、命令セットの実装を同期させた方がいい。つまり、Larrabee投入と前後して、Larrabeeと互換性のある命令セットあるいはLarrabee CPUコアそのものをPC&サーバー向けCPUにも実装すれば、話は簡単だ。ターゲットとするソフトウェア市場が動き始めて、Larrabeeという製品も浸透しやすい。
しかし、現実にはIntelはそれができない。以前の記事で書いたように、その理由はIntel内部の2つのCPU開発センター間の競合があるためかもしれない。いずれにせよ、PC&サーバーCPUと、命令セット拡張のズレが出てしまうことも、Larrabeeにとって障害だろう。
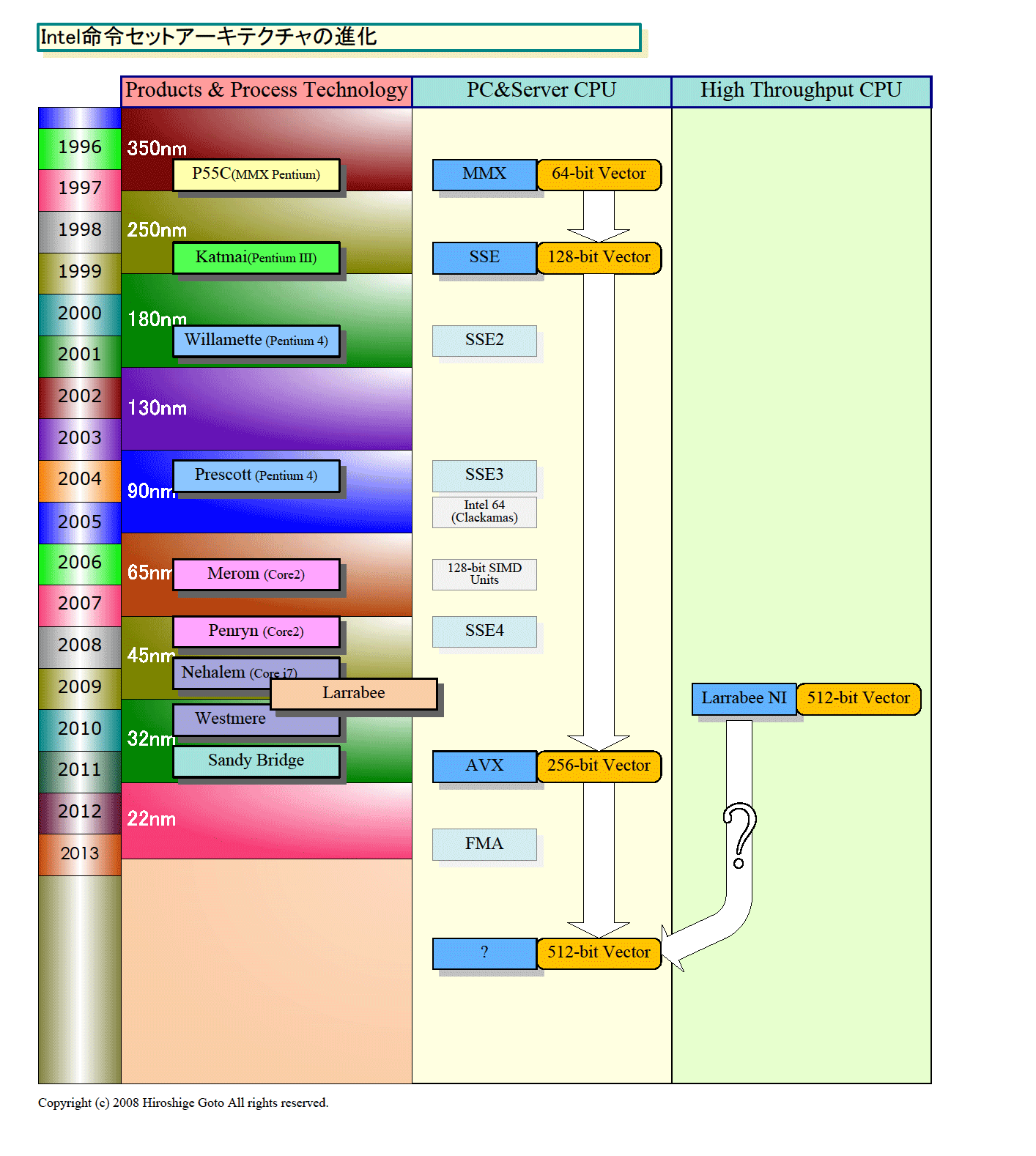 |
| CPU命令セットアーキテクチャの進化 (別ウィンドウで開きます) ※PDF版はこちら |
□関連記事
【12月17日】【海外】Intelヒルズボロが開発するCPUアーキテクチャの方向性
http://pc.watch.impress.co.jp/docs/2008/1217/kaigai481.htm
【11月25日】【海外】GPUとの違いが際立つLarrabeeキャッシュアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1125/kaigai477.htm
【11月11日】【海外】メモリ帯域をセーブするLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1111/kaigai475.htm
(2008年12月25日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.