 |


■後藤弘茂のWeekly海外ニュース■Intelヒルズボロが開発するCPUアーキテクチャの方向性 |
●Larrabeeは将来のIntelメインストリームCPUの先駆け
Intelにとって「Larrabee(ララビ)」の重要性は、Larrabeeという製品自体にあるのではない。Larrabeeが、Intelの今後のCPUのアーキテクチャの方向性を示している点にある。Larrabeeの核の部分は、x86の新しい命令拡張である「Larrabee新命令(Larrabee New Instructions:LNI)」と、CPUコアネットワークだ。そして、こうしたLarrabeeの核の部分は、Intelの将来のメインストリームCPUの技術の先駆けとなっている。
なぜなら、PC&サーバー向けのメインストリームのCPUも、この先は、「データレベルの並列性(DLP:Data-Level Parallelism)」と「スレッドレベルの並列性(TLP:Thread-Level Parallelism)」を高める以外の道はないからだ。そのためのアーキテクチャを開発して、それを試験ビークル的に載せたのがLarrabeeだと考えることもできる。
従って、Larrabeeについては、製品だけを取って、その成否を占っても意味がない。製品としてのLarrabeeが成功するかどうかも重要かもしれないが、真の重要性はLarrabeeからIntelの将来CPUの姿が垣間見えることにある。Larrabeeから推測できる、Intelの次々世代アーキテクチャの成否こそが重要だ。
もっとも、正確に言えば、Intelの1/3が考える将来CPUアーキテクチャなのかも知れない。なぜなら、Intelにはx86系CPUを開発するチームが3つあり、Larrabeeとその命令セットはその1つに属しているからだ。
3チームのうち1つはDigital Enterprise Groupに属する米オレゴン州ヒルズボロ(Hillsboro)の開発センターでPentium III/4やCore i7を開発した。2つ目はMobility Groupに属するイスラエルのハイファ(Haifa)の開発センターで、Pentium MやCore 2を開発した。最後が米テキサス州オースティンの開発センターでAtom系を開発している。このうちヒルズボロとハイファが2年置きにメインストリームx86 CPUアーキテクチャを開発する体制を取っている。
Larrabeeは3チームのうち、ヒルズボロ系の人材によって開発されている。面白いのは、製品だけでなく、命令セットアーキテクチャの拡張も、それぞれのチームに属していることだ。
 |
| Intel命令セットとCPUアーキテクチャ拡張の方向性 PDF版はこちら |
●ハイファのAVXとヒルズボロのLNI-2つの命令拡張
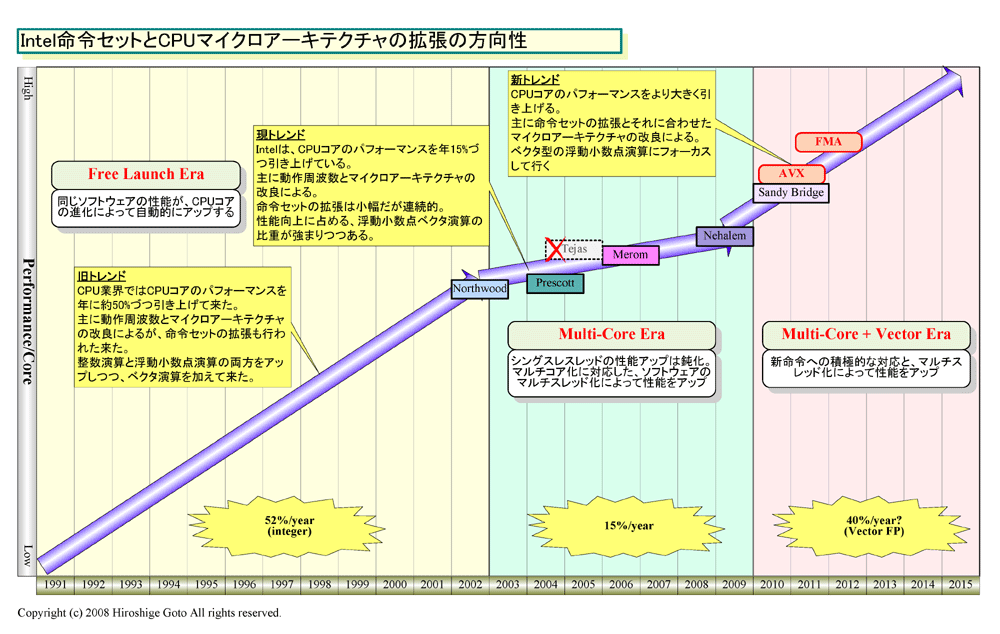
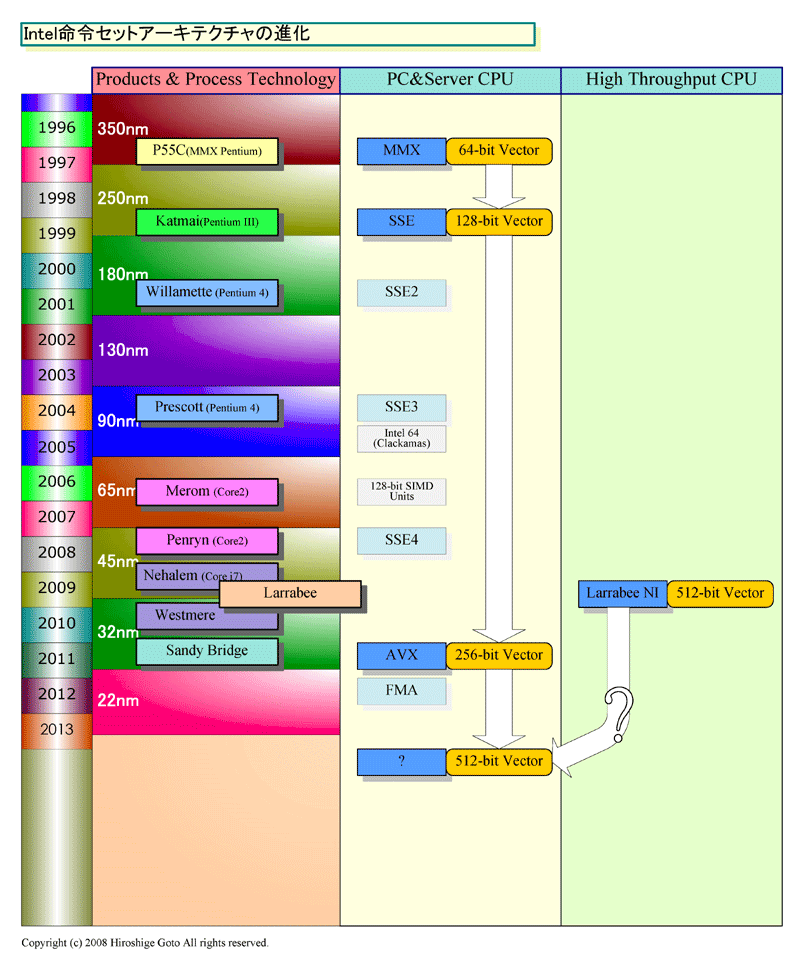
Intelは、2010年に新しいSIMD(Single Instruction, Multiple Data)命令拡張である「Intel Advanced Vector Extensions (Intel AVX)」を搭載したCPUを投入する。実装するCPUは、ハイファで開発している「Sandy Bridge(サンディブリッジ)」だが、命令拡張自体もハイファが主導したという。実際、Intel Developer Forum(IDF)でAVXの説明に登場した人物は、ほとんどがハイファのメンバーだった。つまり、Intelの命令セット拡張ロードマップ上にあるAVXは、ハイファで開発され、ハイファのCPUに実装される。
それに対して、「Larrabee新命令(Larrabee New Instructions:LNI)」はヒルズボロ系で開発された。もし、各命令セット拡張の実装が、その命令セットを開発したチームのCPUでなされるとしたら、LNIまたはその改良命令がIntelのメインストリームCPUに入ってくるのは、ヒルズボロがメインストリームCPUを開発するターンになるはずだ。と考えると、それは2012年以降の「Haswell(ハスウェル)」といったコードネームだけが知られているCPUか、その後継世代になってからとなる。つまり、Larrabeeは、2012年以降のIntel CPUのアーキテクチャを、部分的に垣間見せていることになる。
こうした眼で見ると、来年(2009年)以降のIntel CPUの命令セットアーキテクチャの乖離の事情も推測ができる。2010年には、Intelのメインストリームx86 CPUは256-bitベクタのAVX命令拡張、ハイスループットCPUは512-bitベクタのLNI拡張と分かれてしまう。いささか分裂症気味に、ベクタ拡張だけで2つの系統が平行する異常な事態になる。しかし、これが、Intelの2つの開発センター間の競い合いの結果だとすれば、状況が見えてくる。
Intelの中で、製品としてのLarrabeeをハンドルしている新設のVisual Computing Groupにしてみれば、メインのx86 CPUの命令セット拡張もLNIに揃えてもらえた方がずっとありがたい。拡張命令セット部分は一貫性が出るため、Larrabeeの浸透がずっと楽になるからだ。もし、Intelがそうした戦略を取っていれば、製品としてのLarrabeeの位置づけと戦略は、もっとずっとすっきりしたものになっていたろう。しかし、今の製品計画では、Larrabeeは、x86の鬼っ子的な存在になりかねない。こうした“ズレ”に、巨艦Intelの部門ごとの戦略の違いが見えるようだ。
ちなみに、ヒルズボロのトップであるPatrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)は、「我々はSSEに続く、長期に渡る命令セット拡張のロードマップを持っている」と、暗にAVXだけではない計画があることを示唆していた。今考えれば、これは、AVXの後にLNIがあることを念頭に置いた発言だったかもしれない。
 |
| Intel命令セットアーキテクチャの進化 PDF版はこちら |
●幅広いx86 CPUコアにLNIを実装できるように配慮
Larrabeeの核となっているのは、x86の新しい拡張命令LNIと、CPUコア群やアンコア(CPUコア以外のブロック)を接続するチップ内ネットワークのアーキテクチャだ。LNIはより広いベクタプロセッシングによってDLPを高め、効率的にパフォーマンスを伸ばすためのもの。コアネットワークは、より多くのCPUコアを効率的に接続することで、TLPを高めるためのもの。LNIが将来のIntelのメインストリームCPUにとって必要となるように、コアネットワークもIntelの将来CPUにとって重要な要素となるだろう。
IntelのLarrabee開発チームは、Larrabeeのコアネットワークを検討するに当たって、まず、リングバスを使ったサーバー型インターコネクトからスタートした。Larrabeeのアーキテクチャを担当したIntelのDoug Carmean氏(Larrabee Chief Architect, Intel)によると、最初の試案は統合型のL2キャッシュを持ち、キャッシュと各CPUコアがリングバスで接続されたものだったという。しかし、このプランはLarrabeeアーキテクチャにうまく適合しないため、すぐに捨てられた。
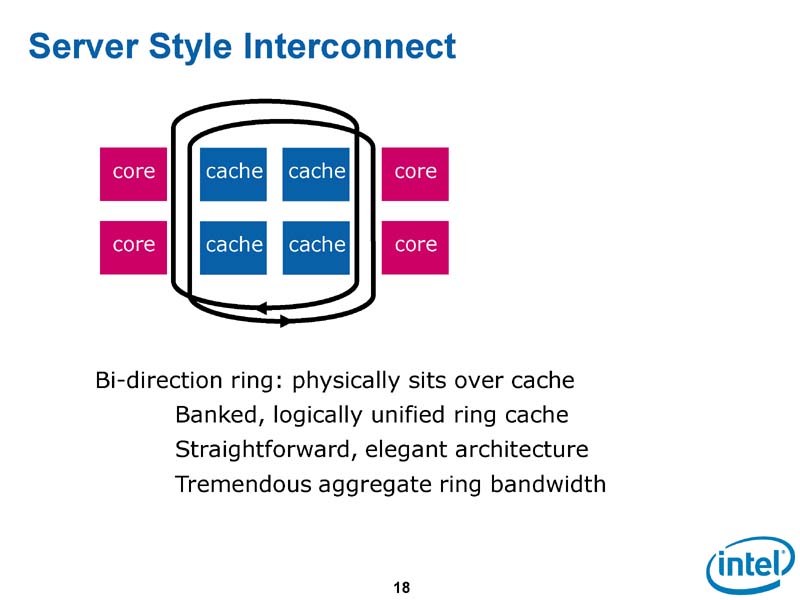 |
| サーバー型インターコネクト |
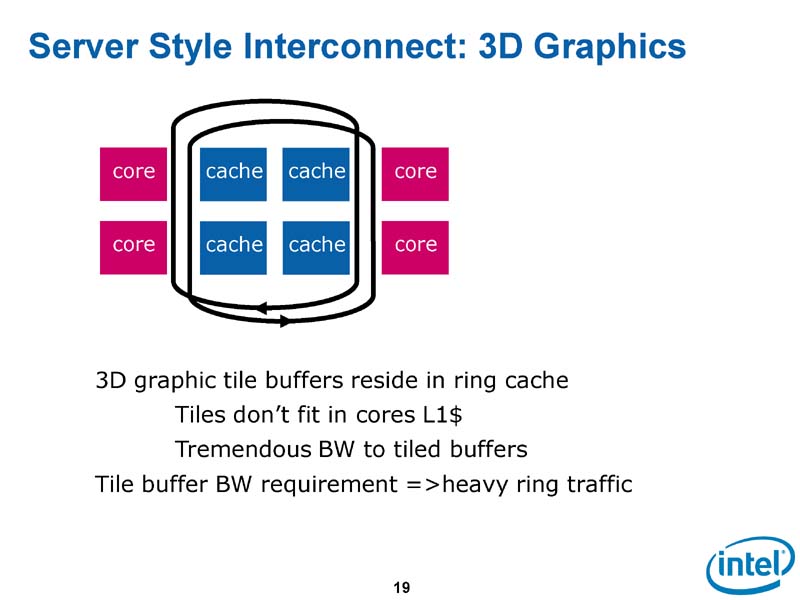 |
| サーバー型インターコネクトの3Dグラフィックス |
次のプランは、小容量のL2キャッシュを各CPUコア毎に分散する方式だった。このアーキテクチャは、L2キャッシュにピクセルデータを載せるLarrabeeにはうまく適合するが、問題もあった。それは、分散したL2キャッシュ間でコヒーレンシを保つ必要があることだった。
Intelは、LarrabeeのようなハイスループットCPUでも、キャッシュアーキテクチャを採用した。GPUが取っているような、明示的なアクセスが必要なスクラッチパッド型メモリのアーキテクチャは取らなかった。ハイスループットプロセッサが主なターゲットとするストリーム型のプロセッシングの場合、キャッシュはほぼ役に立たない。再利用しないデータがほとんどで、膨大なデータストリームが必要になるからだ。しかし、IntelはLNIでキャッシュ制御命令を増やすことで、キャッシュでもある程度ストリームに適した使い方ができるようにする。
Intelがキャッシュアーキテクチャにこだわった理由は、ヒルズボロが描いていると想定される戦略を考えると明白だ。LNIをメインストリームのx86 CPUに実装する時に、キャッシュアーキテクチャを前提とした方が適合しやすいからだ。プログラムの一貫性も維持しやすい。しかし、そのために、Intelは多数のコアのメモリコヒーレンシの保持という課題を抱え込んだ。GPUやCell B.E.はコア間のコヒーレンシを取らないため、この問題を持たない。
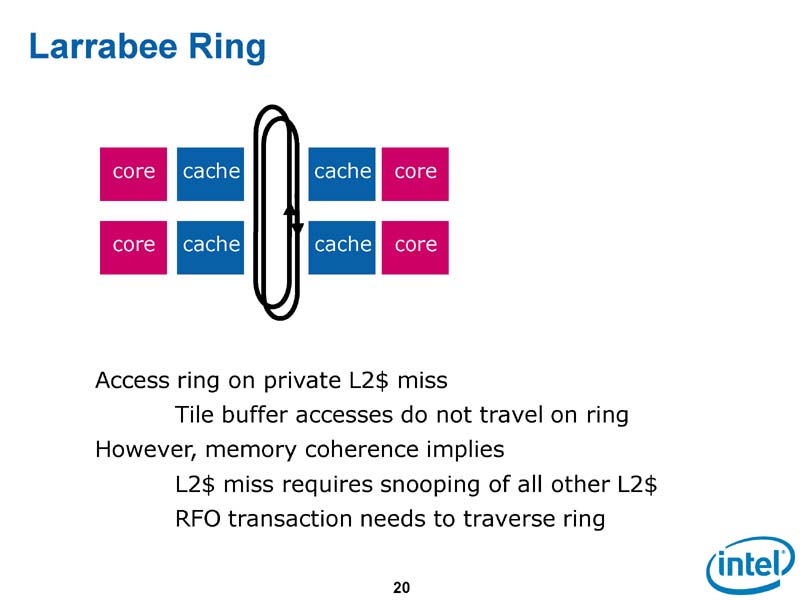 |
| キャッシュを中央に置くLarrabeeのリングバス |
●メニイコア時代のキャッシュアーキテクチャ
そこで、Carmean氏らアーキテクトチームが最初にチェックしたのは、キャッシュのタグディレクトリを集中的に設ける方法だった。
「最初に試みたのは、グローバルタグディレクトリ(Global Tag Directory)のブロックを加えることだった。このブロックは、基本的にはリングバス上の中央化したポイントで、リング上の全てのキャッシュのオーナーシップを管理する。実際には、全てのL2タグのハードコピーを保持する」(Carmean氏)。
ところが、この方式には大きな問題があった。それは、グローバルタグディレクトリが性能とスケーラビリティの制約となってしまうことだった。
「タグディレクトリは、リング上のホットスポットとなってしまう。ホットスポットはパフォーマンスペナルティとなる」とCarmean氏は言う。また、コア数が増えるにつれて、タグディレクトリへのアクセスはさらに集中するため、コア数のスケーラビリティも阻害してしまう。そこで解決策として考えたのは、タグディレクトリ自体を分散する方式だった。
これが実際のLarrabeeのスタイルで、各CPUコアがディストリビューテッドタグディレクトリを備える。リング上に分散したディレクトリのロケーションにアクセスするためにハッシュアドレスを使う。このスタイルでは、グローバルタグディレクトリのような1点集中が発生しないため、性能の制約がない。また、コアを増やす場合のスケーラビリティも高い。
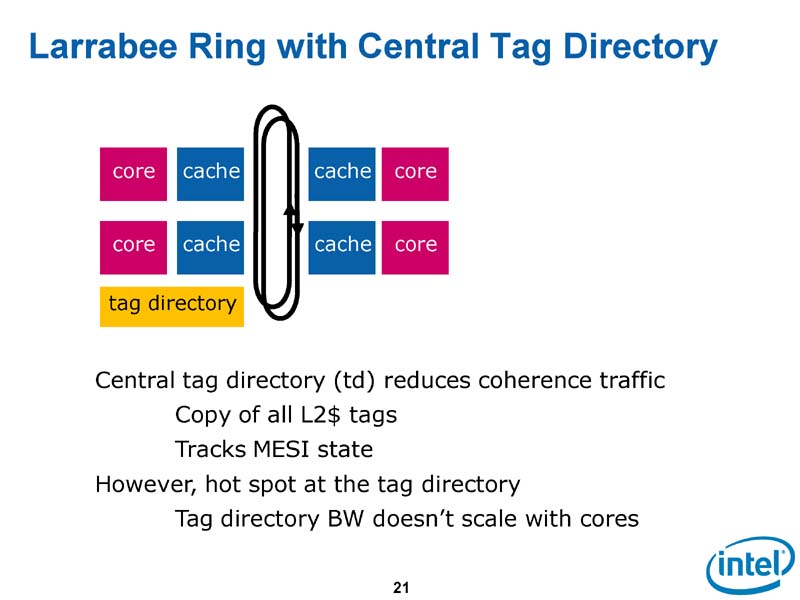 |
| タグディレクトリを足したもの |
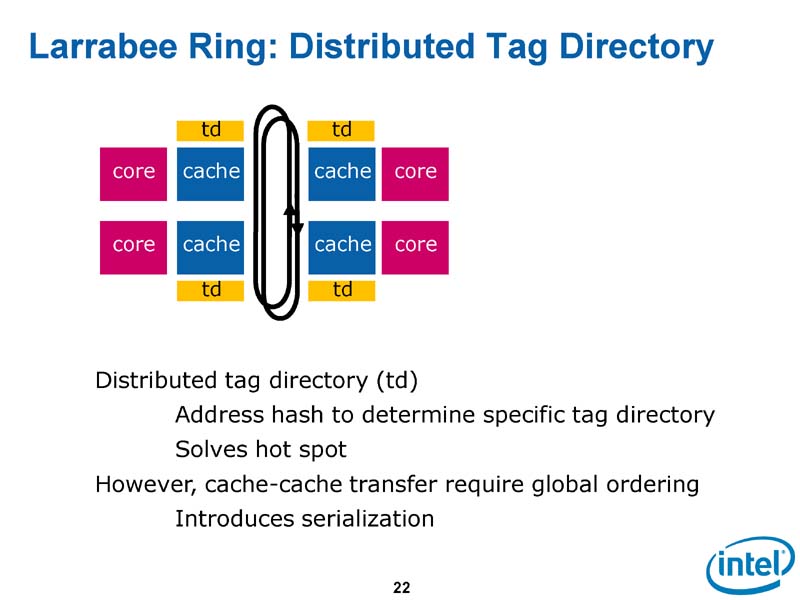 |
| それぞれのキャッシュにタグディレクトリを追加したもの |
さらにIntelはキャッシュ間のデータ転送のトラフィックを減らすために、キャッシュコヒーレンシプロトコルを拡張した。標準的な「MESI」にOwnedステイトを加えた「MOESI」プロトコルを実装した。キャッシュラインのオーナーシップをダイレクトに移行できるようにしたことで、トラフィックを軽減したという。
さらに将来のLarrabeeでは「ロックキャッシュ」を導入して、キャッシュラインのロックを可能にする。グラフィックスオペレーションで有効性が高いことがわかったためだとCarmean氏は説明する。
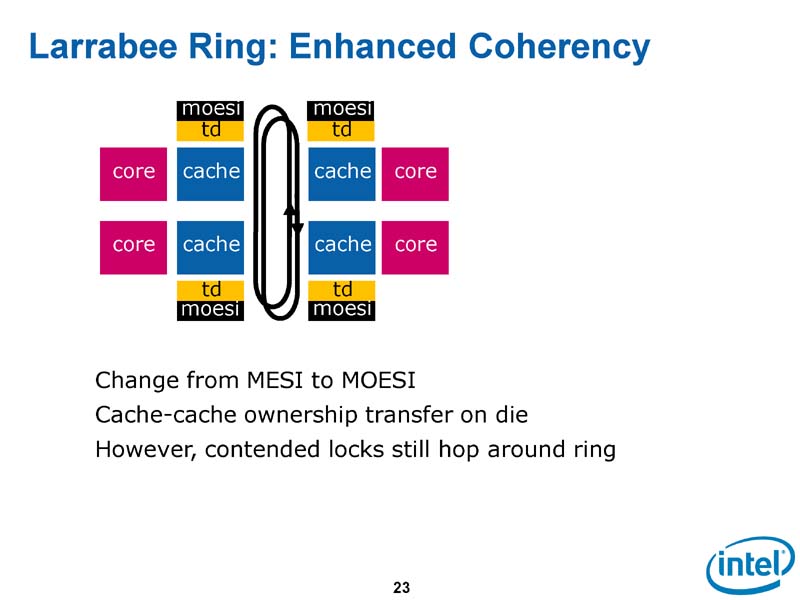 |
| MESIにOwnedステイトを加えたMOESIを追加したもの |
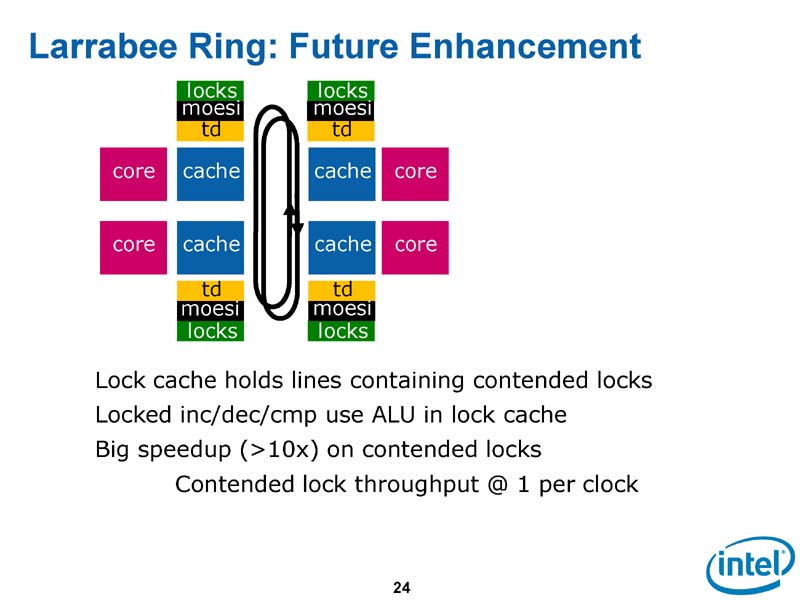 |
| 将来はロックキャッシュを導入 |
●CPUコアをスケーラブルに増やすことも可能
こうしたアーキテクチャ上の工夫によって、Larrabeeでは16コアまでのCPUコアを1ペアの双方向リングに接続できるという。SIGGRAPHの論文では16コアまでは1リングだが、それ以上の場合の拡張も可能だとされていた。
Carmean氏によると、16コア以上にはエクストラリング「Xring」を使うという。これは、複数のリング間を結ぶクロスオーバーポイントを加えることで、1ペア以上のリング構成をフレキシブルに可能にするものだ。「コア数の構成をよりスケーラブルにすることが可能で、Larrabeeアーキテクチャをもっとモジュラーにできる。また、物理的な配置の自由度も高める」とCarmean氏は言う。下の図では3つのリングが相互接続されることで、16コア以上のコアを構成している。
 |
| 拡張性を持たせたLarrabeeのリングバス |
最初のLarrabeeはXringを持たないが、拡張された製品は持つようになる。それによって、Larrabeeの急激な進化が可能となるという。つまり、24コアや32コアといった製品を、基本のアーキテクチャを変えることなく、迅速に開発することができることになる。
Larrabeeのオンダイネットワークの構成は、IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Senior Fellow, Corporate Technology Group兼CTO, Intel)が以前に説明した、再構成可能なオンダイネットワークの実現にも向いている。
Rattner氏は、仮想マシン支援機能との組み合わせで、キャッシュコヒーレンシの維持を容易にする構想を語った。仮想マシンによってメモリはパーティショニングされるため、異なる仮想マシンを走らせるCPUコア間では、キャッシュの間でコヒーレンシを保つ必要がない。
そのため、同じ仮想マシンを走らせるCPUコアの間だけでコヒーレンシを保ち、仮想マシンが異なるCPUコアグループ間ではキャッシュを分離するというものだ。Larrabeeのディストリビューテッドタグのモデルは、こうしたアーキテクチャにも対応しやすいように見える。
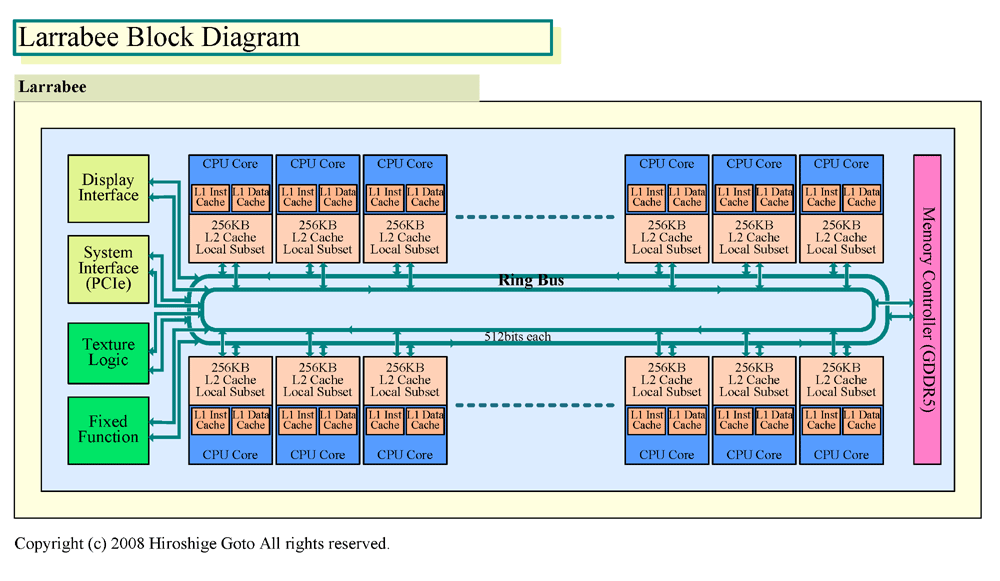 |
| Larrabeeのブロックダイヤグラム PDF版はこちら |
●将来のCPUに適用可能なLarrabeeの各要素
Larrabeeの命令拡張であるLNIは、Larrabeeのような小さなCPUコアに限定されたものではなく、PC&サーバー向けの大きなCPUコアにも実装可能だ。IntelのGelsinger氏は、LNIを汎用の大型CPUコアに実装可能であることを認めている。それと同様に、Larrabeeのコアネットワークも、PC&サーバー向けCPUに応用が可能だ。
つまり、IntelはLarrabee開発で得た経験をベースに、メインストリームCPUでも、CPUコア数が多くデータ並列性の高いCPUを作ることができる。その場合、CPUコアの全てまたは一部は、Larrabeeコアより大型でシングルスレッド性能が高いものになるだろうが、技術自体は転用ができる。
こうして見ると、Intelが、メインストリームのCPU製品で、今後、ベクタ演算性能を高め、スレッド/タスク並列性を高めるための基礎的な技術がLarrabeeでは実現されている。もし、Intelが2012年以降のCPUをそちらの方向へとさらに振るとしたら、すでに道は見えていることになる。
ただし、製品としてのLarrabeeの行方は、まだ微妙だ。Intelが、Larrabeeをハイパフォーマンスコンピューティング(HPC)分野だけでなく、グラフィックス製品としても普及させる戦略を取ったためだ。グラフィックスでは、Larrabeeは新境地を拓くことができる、GPUとは異なるレベルの柔軟性を持つ。だが、その一方で、既存グラフィックスに対しては弱点もあり、GPUに対抗できるかどうかは、まだわからない。
□関連記事
【11月25日】【海外】GPUとの違いが際立つLarrabeeキャッシュアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1125/kaigai477.htm
【11月11日】【海外】メモリ帯域をセーブするLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1111/kaigai475.htm
【10月17日】【海外】2010年以降のIntel CPUが見えてくるLarrabee新命令
http://pc.watch.impress.co.jp/docs/2008/1017/kaigai472.htm
(2008年12月17日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.