 |


■後藤弘茂のWeekly海外ニュース■CPUに統合できるLarrabeeアーキテクチャ |
●Larrabee新命令はLarrabee以外にも実装される?
 |
| パット・P・ゲルシンガー氏 |
IntelのメニイコアCPU「Larrabee(ララビー)」の実態は、IA-32(x86)の新しい命令拡張だ。MMXやSSEと同じ、IA-32/Intel 64アーキテクチャのベクタ演算拡張、最新バージョンが「Larrabee New Instruction(以下LNI)」となる。そして、Larrabee新命令の最初の実装事例で、高スループットに特化したメニイコア製品が、LarrabeeというCPUだ。
おそらく、IntelはLNIを、今回のLarrabeeだけでなく、幅広く実装して行くことを考えている。少なくとも、Intelの中でLarrabeeを推進する一派は、そうした構想を持っている。LNIは、おそらくIntelのIA-32/Intel 64命令セット拡張のロードマップの中に位置づけられており、Larrabeeという製品は、それを先取りした一製品だと推測される。将来は、IntelのPC&サーバー向けCPUにも、LNIは実装されて行くだろう。
その意味で、LarrabeeはIntel CPUの将来を映す鏡となる。現在のCore 2やCore i7(Nehalem:ネハーレン)の先にある、将来のPC&サーバー向け汎用CPUがどう進化するのか。Larrabeeは、2010年代中盤以降のIntel CPUの進化の方向性を示している。
LarrabeeとLNIのこうした関係を考える時に重要なポイントは、Larrabeeがホモジニアス(Homogeneous:均質)メニイコアである点だ。Larrabeeの「最初のターゲットとする市場はディスクリートグラフィックスアプリケーション」(Patrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group))で、ホストCPUとの組み合わせで使われる。しかし、Larrabee自体は、GPUとは異なり、必ずしもホストCPUを必要とはしない。Larrabeeは、ある程度のスカラ演算性能を持ち、単体でOSも走らせることができるCPUだ。
 |
| CPUアーキテクチャの方向と命令セット ※別ウィンドウで開きます (PDF版はこちら) |
 |
| CPU命令セットアーキテクチャの進化 ※別ウィンドウで開きます (PDF版はこちら) |
●ヘテロジニアスかホモジニアスかがポイント
CPUとして単体で使える程度のスカラ演算性能を備え、45nmプロセス世代で単チップとしてTFLOPSクラスの性能を目指す。Larrabeeのコンセプトはそこにある。その点では、CPUとしてある程度のスカラ演算性能を備え、90nm世代で単チップで1/4TFLOPSの性能を達成したCell B.E.とコンセプトはよく似ている。しかし、大きな違いもある。高い位置から見ると「ヘテロジニアス(Heterogeneous:異種混合)」か、「ホモジニアス(Homogeneous:均質)」か、という点が大きな違いとなる。
Cell B.E.によって、ヘテロジニアスマルチコアCPUがメインストリームコンピューティングで現実になった。ヘテロジニアスマルチコアという言葉は明確に定義されたものではないが、概念としては、次の要素が、1個のCPUの中に次の要素が含まれるものだったと言える。
- 異なるマイクロアーキテクチャのCliUコア
- 異なる命令セットアーキテクチャ(ISA)
- 異なる命令ストリーム
この3つがCell B.E.のようなヘテロジニアスマルチコアの特徴だった。Cell B.E.では、汎用のPPU(Power Processor Unit)と、ベクタ演算に最適化したSPU(Synergistic Processor Unit)の2種類のマイクロアーキテクチャのCPUコアを搭載。PPUにはPowerPC命令セットを、SPUには新規の命令セットを採用。OSやアプリケーションの中でも演算中心でないコードはPPUで、ベクタ演算中心のコードはSPUでと、命令ストリームを分ける必要があった。
こうした事情は、GPUコンピューティングも同様だ。NVIDIAのCUDA (クーダ:compute unified device architecture)の場合、1つのプログラムの中で、スカラコードはCPUで実行され、並列化が可能なコードだけがドライバを介してGPUにダウンロードされる。CPUとGPUによるヘテロジニアス環境が、現在のGPUコンピューティングだ。
Intelは、Larrabeeでこれらを全て転換した。Larrabeeでは、1個のCPUの中に次の要素を持つ。
- 単一のマイクロアーキテクチャのCPUコア
- 単一の命令セットアーキテクチャ
- 単一の命令ストリーム
Larrabeeの各CPUコアは、それぞれ同じ実装であり、同じ命令セットアーキテクチャとなっている。1個のCPUコアの中に、Pentiumベースのシンプルなスカラ演算ユニットと、16-wideの強力なベクタ演算ユニットが含まれる。ヘテロジニアスな結合は、CPUコアの中で行なわれており、単一の命令ストリームの中に、従来のIA-32命令と新しいベクタ命令の両方が含まれる。
Larrabeeも各CPUコアで異なる命令ストリーム(スレッド)を走らせる。しかし、命令ストリームをコードの種類やタスクによって分ける必要はない。普通のマルチコアCPUと同様に、単純にタスクをスレッドに分割すれば、均質なCPUコア群の上で走らせることができる。均質なIA-32コアでの、対称型マルチコアを、Intelが重視していることがわかる。
●Larrabeeの実態はIA-32の新しい命令セット拡張
では、各Larrabee CPUコアの中での、スカラとベクタの結合はどうなっているのだろう。
Larrabee CPUコアの構造で目立つのは、Pentiumベースのスカラパイプラインはそのまま残しながら、16-wideベクタユニットを加えている点だ。ベクタユニットは、Larrabee CPUコアの中で、ある程度、独立した構造になっている。GPUのように、ベクタユニットだけの構成にはなっていない(NVIDIAアーキテクチャでも、各スカラコアはSIMD制御されおり、大きく見ればベクタ)。中核は普通のx86 CPUコアであり、Pentium世代までの命令は全て通る。ベクタパイプはx86 CPUコアの拡張に過ぎない。その意味では、Larrabeeとは、IA-32の新しい命令セット拡張に過ぎない。
Gelsinger氏は次のように語る。
「Larrabeeは『LNI』という新しい(IA-32アーキテクチャの)命令セット拡張だ、と言うこともできる。LNIは、汎用性がある完全な新命令セットだ。ベクタプロセッシングやスキャッタ/ギャザ、イレギュラデータ構造、といった全てを含む。非常に強力な命令セット拡張だ」
Larrabee CPUコアは、基本的にはPentiumベースのx86コアに、LNIのための実行ユニットを加えたものだ。しかし、LarrabeeのCPUコアがシンプルなIn-Order型コアであるのは、Larrabeeのアーキテクチャ上の制約ではない。LNI自体は、おそらく、ポータブルな命令セット拡張で、既存のIntelの命令セット拡張と競合しないと考えられる。
LNI自体は、他のタイプのCPUコアに実装することが可能であるはずだ。SSE命令を、SilverthorneからNehalemまで広いCPUマイクロアーキテクチャに実装できるのと同じように、IntelはLNIも幅広いCPUマイクロアーキテクチャに実装することができると考えられる。
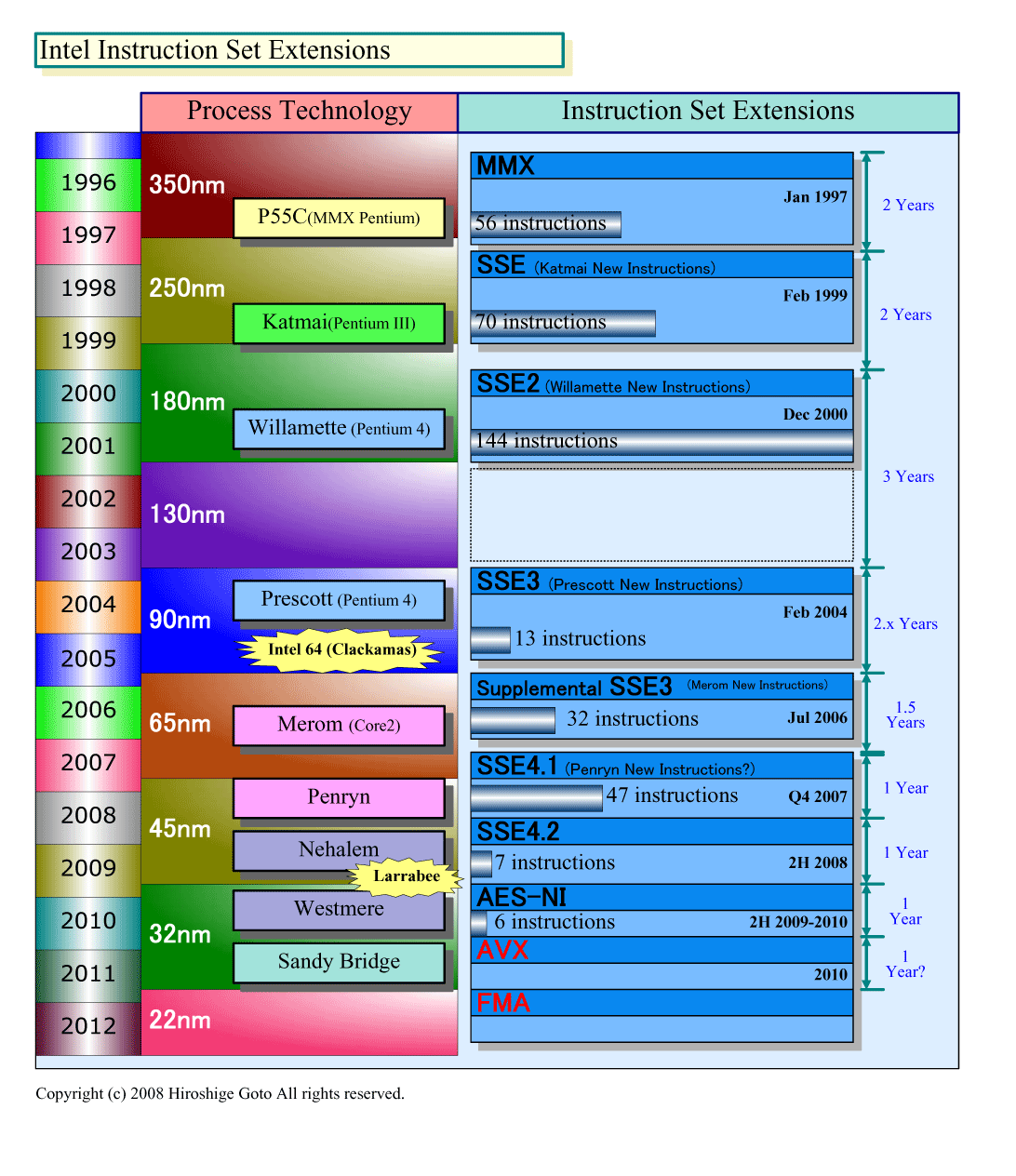 |
| プロセス技術の進化に伴う命令の拡張 ※別ウィンドウで開きます (PDF版はこちら) |
●グラフィックスアプリ向けにシンプルCPUコアを選択
なぜIntelは、Larrabeeの実装では、シンプルCPUコアを選んだのか。その点を、Gelsinger氏は次のように説明する。
「LNIを、大きなコアに実装できないアーキテクチャ上の理由はない。我々は、最初のLarrabeeの設計ポイントにおいて、小さなIn-Orderコアをベースに使うことを選んだ。いくつか理由があるが、もっとも重要な点は、単に、もっとコアを多くしたいというものだった。小さなコアなら、一定のシリコンバジェット(チップサイズ)の中でより多くのコアを搭載できる。
その結果、我々はLarrabeeで素晴らしいバランスを実現できた。Larrabeeのダイ写真はまだ見せられないが、それを見れば、キャッシュとメモリ帯域、ベクタ帯域、テクスチャユニットが非常にいいバランスとなっていることがわかるだろう。
もし我々がLarrabeeにより大きな(CPU)コアを使っていたら、我々はグラフィックスタイプのアプリケーションに充分なだけのパフォーマンスに近づくことはできなかっただろう。グラフィックスは、我々のメインのターゲット市場なので、この選択はできなかった。だから、我々は、LNIの実装の最初のバージョンの事例では、小さなコアを選んだ。しかし、LNIは、それ以外のCPUコアにも実装できる」
LNIのコアをPentiumベースのシンプルコアにしたのは、アーキテクチャ上の理由ではなく、対象とするアプリのためだという。今回のLarrabeeはターゲットアプリがグラフィックスであるため、コア数を増やして演算性能を上げることに重点を置いたわけだ。もちろん、ベクタユニットを強化するからには、性能を劇的に上げられなければ意味がないわけで、その点では理にかなっている。しかし、IntelはLNIという新しい資産を、汎用のPC&サーバーCPUの拡張に使うこともできる。
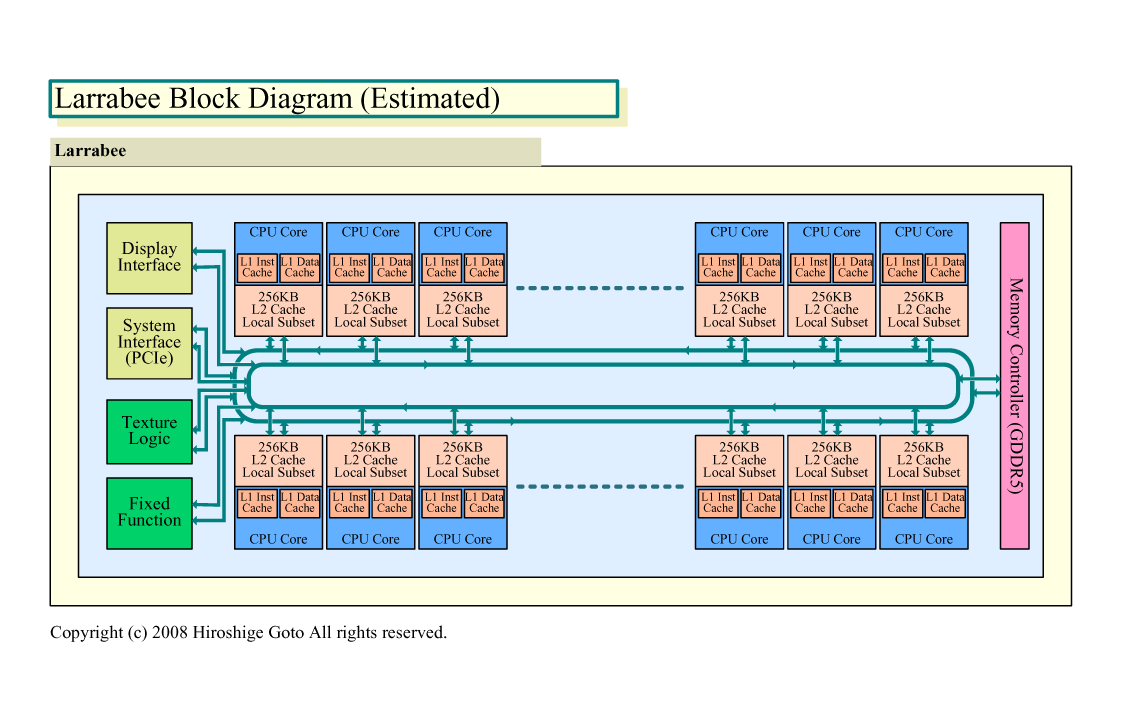 |
| Larrabee Block Diagram ※別ウィンドウで開きます (PDF版はこちら) |
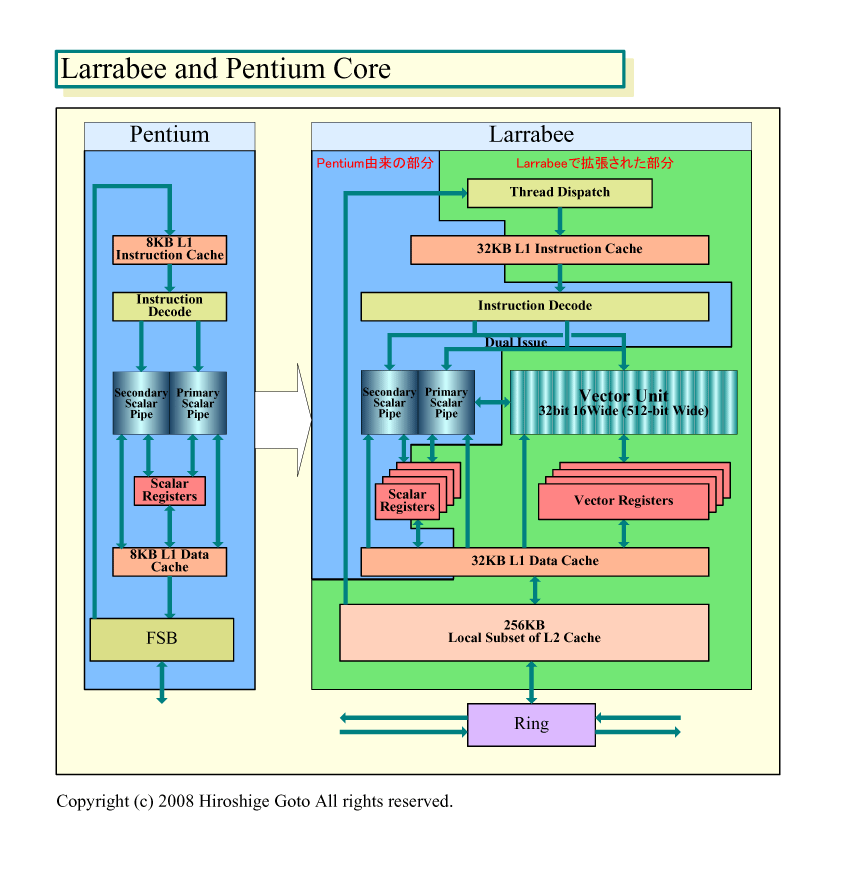 |
| Larrabee x86 Core Block DiagramとPentiumの比較 ※別ウィンドウで開きます (PDF版はこちら) |
●2つの方法があるLNIの汎用CPUへの統合
このことは、将来、IntelがLarrabeeアーキテクチャをPC向けCPUに統合するとしたら、どんな形で統合するのか、というポイントと深く関わってくる。
まず、Intelは、最初の世代の、Pentium型シンプルコアにLNIを実装したCPUコアを、そのまま、PC&サーバー向けの汎用CPUに組み込むことができる。その場合は、大型の汎用CPUコアはそのままで、Larrabee CPUコアをハイブリッドで組み合わせることになる。通常のコードはメインの汎用CPUコアで、特定の並列化アプリケーションのコードはサブのLarrabee CPUコアで実行するスタイルだ。CPUコア単位で役割分担を行う点は、Cell B.E.に似ている。1つのCPUの上に、異なるマイクロアーキテクチャのCPUコアが混在し、拡張が異なる命令セットアーキテクチャが併存し、命令ストリームも2種類に分かれるヘテロジニアスマルチコアだ。
しかし、Larrabee型の拡張の場合は、すでに説明したように、他のタイプのCPUコアにLNIを実装することが比較的容易にできる。そのため、Intelは、PC&サーバー向けのCPUコアに、LNIを実装し、16-wideベクタユニットを統合することが可能だ。
Gelsinger氏は次のように語る。
「アーキテクチャ上は、どちら(Larrabeeコアを統合する方法とPC&サーバー向けCPUコアにLNIを実装する方法)も可能だ。Larrabeeで小さなコアを選んだのは、コア数を増やすためだ。我々が、LNIを、より大きなCPUコアの製品に加えることもできることは明白だ。
将来の方向性のステイトメントで明らかにしたように、我々は命令セットの大きな動きとしてベクタ命令を強化する方向へ向かっている。すでに、Sandy Bridge(サンディブリッジ)の一部としてAVX命令セット拡張で256-bit(ベクタ)を加えることをアナウンスした。Larrabeeは512-bit(ベクタ)なので、これ(AVX)が一種の、いい中間地点(SSEとLarrabeeの間の)であることがわかると思う。我々は、どこかの時点で、(PC&サーバー向けCPUも)512-bitベクタ拡張アーキテクチャへと移すだろう」
●汎用CPUコアのベクタ命令拡張の延長に見えるLNI
Gelsinger氏は、明言はしていないが、LNIを汎用的なCPUコアに実装する可能性を示唆している。Gelsinger氏のビューの中では、汎用のPC&サーバー向けCPUも、トレンドとしてはベクタ命令を強化する方向にあり、ベクタ幅を段階的に増やしている。その方向性からすれば、将来、512-bitベクタへと進むのは必然となる。
2010年の時点では、PC&サーバー向けCPUはAVXで256-bit幅ベクタ、ある程度限られた用途向けであるLarrabeeは512-bit幅ベクタと、同じIntel CPUでベクタ命令の実装は2つに分かれてしまう。しかし、Gelsinger氏は、AVXの256-bitはベクタ幅を広げて行く途中の中間地点であり、どこかのフェイズで512-bitベクタへと進むことになると示唆する。つまり、256-bitと512-bitのずれは、時間軸上のずれに過ぎず、PC&サーバー向けCPUもいつかは追いつくことになる。
そして、その時点で、Intelは512-bitベクタ命令としてLNIを持っており、それを、PC&サーバー向けCPUに実装することができる。LNIを、IA-32の拡張として定義したのなら、それを使わない手はないだろう。その場合、LNI(512-bitベクタ)は、MMX(64-bitベクタ)→SSE(128-bitベクタ)→AVX(256-bitベクタ)と続いてきた命令セット拡張の新しいバージョンとなる。逆を言えば、AVXの先の512-bitベクタを先取りしたのが、LNIを実装したLarrabeeというCPUなのかもしれない。
Intelが、PC&サーバー向けのCPUコア自体の中にLNIを実装する方法を採るなら、それはヘテロジニアス型の結合ではなくなる。単一のマイクロアーキテクチャのCPUコアに、単一の命令セットアーキテクチャ、単一の命令ストリームで統合できる。その分、CPUコア数は減り、生パフォーマンスは落ちることになる。同じLNIを実装しても、シンプルコアを多数搭載するLarrabeeとは、異なるタイプの製品になるだろう。
Intelは、LarrabeeをIA-32の拡張として作ったことで、汎用CPUとの融合でさまざまな選択肢を持てるようになった。例えば、もし、Intelがグラフィックスパフォーマンスを重視するなら、LNIを実装した大型汎用CPUコアと、同じくLNIを実装したシンプルコアの、2種類のCPUコアを載せたヘテロジニアスマルチコアCPUを作ることもできる。ランタイムを介して、グラフィックスコードはシンプルコアに割り振り、それ以外のコードは大型汎用コアに割り当てるといった使い方となるだろう。
整理すると、LNIという新拡張命令を使った、グラフィックスにも対応できる高スループットメニイコア製品がLarrabeeだ。しかし、LNI自体は、そうした製品以外にも応用が可能だ。より汎用的なCPUコアのベクタ演算性能を引き上げるためにも使うことができると考えられる。おそらく、IntelはIA-32/Intel 64アーキテクチャのベクタ拡張の長期のロードマップを持っており、LNIはそのマップ上にある。
□関連記事
【8月22日】【海外】正式発表されたLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
【8月19日】【海外】LarrabeeがPentiumをベースにしたのはなぜか
http://pc.watch.impress.co.jp/docs/2008/0819/kaigai460.htm
【8月11日】【海外】Cell B.E.と似て非なるLarrabeeの内部構造
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
【8月4日】【海外】ついにベールを脱いだIntelのCPU&GPUハイブリッド「Larrabee」
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
(2008年10月6日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.