 |


■後藤弘茂のWeekly海外ニュース■正式発表されたLarrabeeアーキテクチャ |
●Intel幹部がIDFでLarrabeeを紹介
 |
| Larrabeeを紹介するPat Gelsinger氏(右)とLarry Seiler氏(左) |
Intelは、8月19日から米サンフランシスコで開催している技術カンファレンス「Intel Developer Forum (IDF)」で、スループットコンピューティング向けの新CPU「Larrabee (ララビー)」のアーキテクチャ概要を発表した。Larrabeeについては、2週間前に行なわれたコンピュータグラフィックスカンファレンス「SIGGRAPH」で、論文発表とプレゼンテーションが行なわれた。しかし、Intelのトップエグゼクティブが公式にLarrabeeアーキテクチャを発表するのはIDFが初めてとなる。
ただし、Larrabee自体についてのIDFでの発表内容は、SIGGRAPHでの発表からの追加情報はほとんどない。また、Intelは、IDFでLarrabeeアーキテクチャのアウトラインは明かしたものの、Larrabeeの製品計画などについての詳細は公式にはアナウンスしなかった。「当社の副社長が語ったのは、最初のLarrabee搭載製品が2009年遅くから2010年に登場するということ。それが現在話ができる全て」(Larry Seiler氏, Senior Principal Engineer - Graphics System Architect, Intel)というコメントだけだ。
IDFのキーノートスピーチでは、Digital Enterprise Groupを指揮するIntelのPatrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)が、3つのトピックスの1つとしてLarrabeeを取り上げた。Larrabeeは新設のVisual Computing Groupの管轄だが、開発を行なったのはDigital Enterprise Groupの下にあるオレゴン州ヒルズボロの開発センターだと言われている。Gelsinger氏は「LarrabeeはISVコミュニティに大きな興奮と関心を呼び起こしている」と謳った。
しかし、キーノートには、Larrabeeのモノの姿はなく、実チップはもとよりエミュレーションによるデモも行なわれなかった。つまり、製品絡みの話は、IDFにおいても、ほぼ一切でなかった。Intelは、現在のフェイズは、Larrabeeアーキテクチャを知らしめる段階であり、製品のプロモーションを行なう段階ではないと判断しているという。
 |
| Larrabee全体のブロックダイヤグラム |
 |
| LarrabeeのCPUコアとベクタユニットのブロックダイヤグラム |
●グラフィックス業界から人材を集めたIntel
4月のIDFでは、IntelはLarrabeeを、まずグラフィックス市場向けに投入すると宣言した。その市場では、NVIDIAのGeForce GTX 200(GT200)やその後継、AMDのATI Radeon HD 4800(RV770)やその後継と真っ向からぶつかることになる。今回のIDFでは、Intelは若干トーンは弱めたものの、やはりグラフィックスアプリケーションに焦点をあてた説明を行なった。Larrabeeには、CPUとGPUのそれぞれのサイドのアーキテクトが関わったと言われているが、IDFで前面に出てきたのはグラフィックスサイドの人材だけだった。
ちなみに、Intelは、ビジュアルコンピューティングプロジェクトのために、グラフィックス業界中から人材を集めたようだ。LarrabeeのグラフィックスサイドのアーキテクトであるLarry Seiler氏(Senior Principal Engineer - Graphics System Architect, Intel)は元ATI Technologies。また、ビジュアルコンピューティングについての「Chalk Talk」(フリーディスカッションスタイルのセッション)には、NVIDIAでシェーディング言語「Cg」を作ったWilliam(Bill) R. Mark氏が登場した。Mark氏はNVIDIA後にテキサス大学オースティン校に移ったが、現在はIntelのリサーチセンターに所属しているという(Manager, Advanced Graphics Research Group, Intel)。
NVIDIAでCUDAの開発リードを努めるIan Buck氏は、Mark氏とスタンフォード大学でシェーディング言語の研究を行なった元同僚だった。同じく、スタンフォード大学のStanford Graphics Labの研究者で、現在はAMDのアーキテクトチームにいるMike Houston(マイク・ヒューストン)氏は、「結局、同じスタンフォードで研究していた仲間が、3社に分かれて似たようなことをしている」と笑う。
IntelがLarrabeeを、まずGPUとして販売するのは、コンシューマ向け製品として幅広く普及させるためだ。しかし、それは戦略の第一段階に過ぎない。Intelの最終的な狙いは、普及したLarrabeeの上で、グラフィックス以外の広汎な汎用的なアプリケーションを花開かせることにあると推測される。Intelの統合グラフィックスのアーキテクトで、10年前にIntelのディスクリートGPU「Intel 740」を開発したThomas Piazza氏(Intel Fellow)氏は、「Larrabeeは、この地上で最もGPGPUに適したマシンだ」と宣言。Larrabeeが他のGPUに対して決定的に有利に立つポイントが、汎用コンピューティングでの柔軟性にあることを明瞭にした。
●ソフトウェアの変化がプロセッサを変える
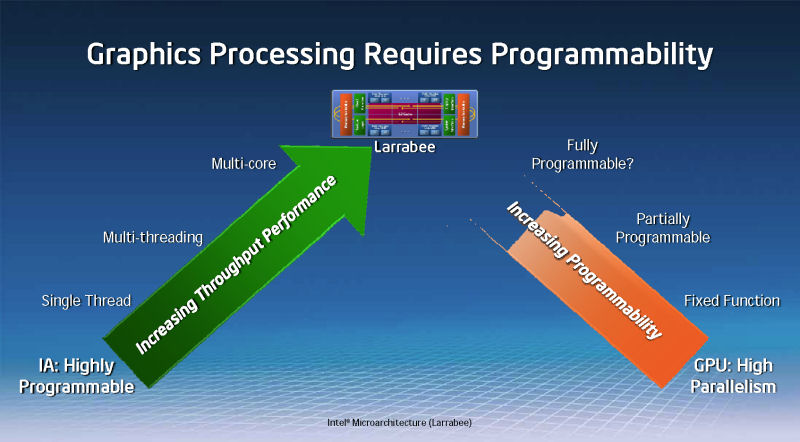
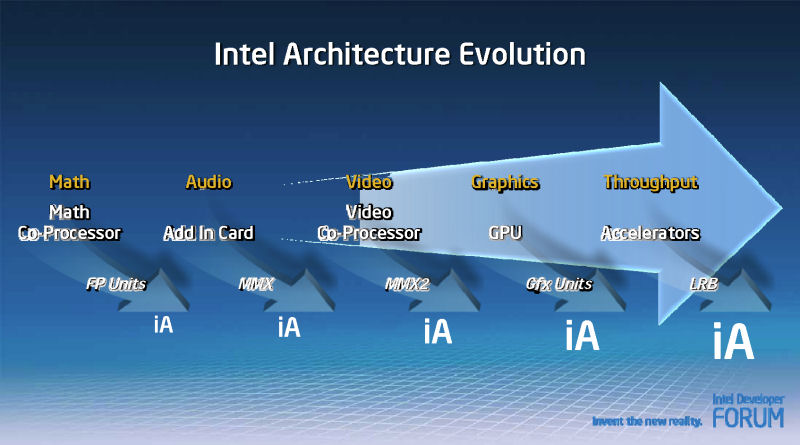
Intelは、IDFで、Larrabeeの背景にある、過去数年のGPUのプログラマブル化の流れを説明した。GPUは、DirectX 9世代以降、プログラム性を備えたプロセッサを搭載し、非グラフィックスの汎用的なアプリケーションを実行できるようになり始めた。そうしたGPUの進化は、汎用のシングルスレッド用プロセッサからマルチスレッド&スループットコンピューティングへと向かうCPUの進化と、ある地点で合致する。Larrabeeは、CPUとGPUの進化のちょうど中間地点に位置するというのがIntelの位置づけだ。
 |
| GPUは進化とともに演算効率が向上 |
 |
| グラフィックス処理にはプログラマビリティが必要 |
 |
| グラフィックスレンダリングパイプラインの歴史 PDF版はこちら |
GPUは演算だけに特化しているため、マルチスレッドの浮動小数点演算パフォーマンスは極めて高い。現在のGPUは、同時期のCPUに対して、約10倍の浮動小数点演算能力を備える。Larrabeeの狙いもそれで、汎用CPUの10倍の演算能力を実現することにある。その演算能力を使って何をするのか。Intelは“RMS”と呼ばれる「Recognition (認識)」、「Mining (分析&抽出)」、「Synthesis (合成)」といった新しいタイプのアプリケーションが花開くと説明する。LarrabeeのようなメニイコアCPUは、そのために必要だというのがIntelの認識だ。Intelは、科学技術計算のような特殊な分野だけでなく、一般アプリケーションやマンマシンインターフェイスも、RMSを取り入れることで変わって行くと考えている。この認識は、CPU業界に共通したもので、他のCPUメーカーもほぼ同じビジョンを描いている。そして、Intelの出した最初の解答がLarrabeeだったわけだ。
Larrabeeのポイントは、CPUの柔軟性やプログラム性の利点を保ちながら、GPUに匹敵するスループットコンピューティング向けプロセッサを作ることにある。Intelは、LarrabeeのCPUコアは、PC向けCPUほど高いシングルスレッド性能は持たないが、OSを走らせるには充分な機能を備えていると説明する。「Larrabeeコアは非常に高機能で、ほとんどどんなコードも走らせることができる」とBill Mark氏は語る。
●ポータブルなLarrabeeのベクタ演算ユニット
また、IntelはLarrabeeの設計に際して、伝統的なCPUのスタイルを取るスカラ演算パイプと、GPUスタイルのベクタ演算パイプを注意深く分離した設計を採った。Larrabeeのスカラ演算パイプは、Pentiumをベースにしており、In-Order実行デュアルイシューのパイプラインを持つ。つまり、Larrabeeは、Pentium相当CPUに、強力なベクタ演算ユニットを加えた構造となっている。スカラコアだけでプログラムするなら、x86プログラミングの経験者にとっては、挙動がよくわかっているCPUに過ぎない。そして、ベクタ演算パイプ部分は、現在のLarrabeeスカラコアとは異なるコアに組み合わせることも可能な仕組みに見える。
Gelsinger氏は、Larrabeeのベクタ演算パイプがポータブルであり、異なるCPUコア(スカラパイプ)と組み合わせることが可能であることを認めた。Larrabeeは、SSEのようなx86命令のSIMD拡張の新しいバージョンとして見ることもできるという。Larrabee命令のマッピングスペースが、既存の命令とオーバーラップしていない限り、Larrabeeベクタパイプを移植することができる。このことは、Larrabeeが独立したプロジェクトではなく、IntelのSIMD命令セット拡張の一連の流れの中にあり、もしLarrabee自体が失敗しても、その資産は活かされる可能性があることを意味している。
 |
| Intelアーキテクチャの進化 |
また、今回のIDFでは、Larrabeeのソフトウェア処理が、これまで分かっていた以上に全体にわたっていることが明らかになった。IntelのグラフィックスフェローであるTom Piazza氏は、Shop Talkで、Larrabeeのタスクスケジューリングは完全にソフトウェアで行なわれることを明確にした。現在のDirectX 10 GPUでは、ユニファイドシェーダのタスクスケジューリングはハードウェアで行なわれる。Single Program, Multiple Data(SPMD)実行から、パイプラインの制御、個々のプロセッサクラスタ内でのロードバランシングまで、ハードウェアが管理するスタイルが一般的だ。それに対して、Larrabeeはこうしたスケジューリングの全てがソフトウェアで制御される。
こうしたスタイルも、Larrabeeコアの中のベクタユニットをポータブルにしている。また、スケジューリングの柔軟性は、さまざまな可能性を秘めている。例えば、現在のGPUは、同じSIMDグループの中で条件分岐が発生して個々のレーンでの実行パスが分かれた場合には、プログラム全体の実行パスが長くなってしまう。しかし、Larrabeeの構造なら、分岐によってSIMDグループを再編成して実行パスを短くするといった、現在のベクタマシンで研究されているようなアプローチを実装することもできる。
●Intelは新言語拡張「Ct」をLarrabeeのために準備
Intelは、IDFで、データ並列コンピューティングを支えるソフトウェアスタックとコンパイラである「Ct」とLarrabeeの関係も明らかにした。Ctは「C for Throughput Computing」の意味で、Intelが研究を行なっているC++のデータ並列コンピューティング向け拡張だ。ラフに言えば、NVIDIAによるC言語のデータ並列コンピューティング向け拡張である「CUDA (クーダ:compute unified device architecture)」とある程度似たような役割を果たす。データ並列ハードウェアの複雑性を隠蔽して、簡単に多数のコアの上でプログラムできるようにする。
CUDAと同じように、簡単な構文で、指定したデータ列に対する並列プロセッシングを、ターゲットのプロセッサとそのベクタユニットに合わせて自動的に展開する。シェーダプログラムのように、1データ要素に対するプログラムを自動的に並列化する「Single Program, Multiple Data(SPMD)」ではないが、ハードに合わせて自動的に並列化する点はSPMDモデルと同じだ。
CtはSSE系命令だけでなく、Sandy Bridgeの新ベクタ命令「Intel Advanced Vector Extensions (Intel AVX)」、Larrabeeの新ベクタ命令「Larrabee New Instructions(LNI)」、さらに将来の命令もサポートする。IDFでは、Core 2やLarrabeeだけでなく、例えば、AVXを実装した汎用CPUコアとLarrabee CPUコアのハイブリッド構成のようなCPUにも対応できると説明された。
Ctは、CUDAと同様にターゲットプロセッサまたはそのホストCPU上にランタイムスタックが走り、JITコンパイラが各プロセッサのネイティブ命令に変換する。Ctの場合は、ターゲットのプロセッサのベクタ(SIMD)幅を抽象化するだけでなく、コア数、メモリモデル、キャッシュサイズなど、幅広い要素を隠蔽して自動的に最適化するとされている。CUDAよりハードウェアを抽象化し隠蔽する。そのため、ネイティブのパフォーマンスをよりよく引き出すためには、コンパイラのインテリジェンスが高くなければならない。
また、Intelは、LarrabeeについてはNative C/C++コンパイラも用意している。Native C/C++上では、ベクタ幅が露出しており、プログラマは16-Wideベクタを直接扱う。プログラムの難度は高いが、ダイレクトにプログラムすることで、スキルを積めばパフォーマンスを引き出すことができる。難しいが性能を出せる直接的プログラミングと、簡単だが間接的な自動並列化プログラミングモデルの2種類を用意する点が、直接的プログラミングを許さないGPUとの大きな違いとなっている。
 |
| LarrabeeはCPUと似たソフトウェアスタックを採用 |
 |
| ソフトウェアの機会とリスク |
 |
| Ctを広範囲に拡大 |
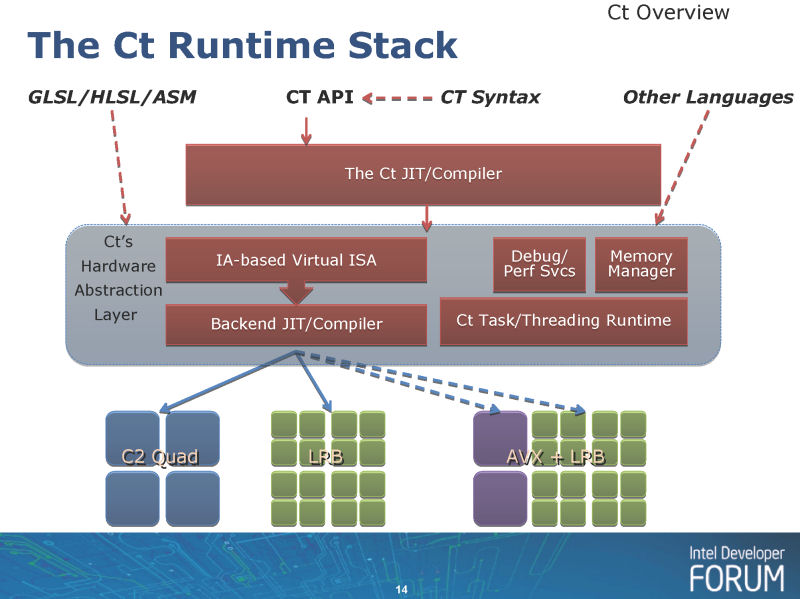 |
| Ctのランタイムスタック |
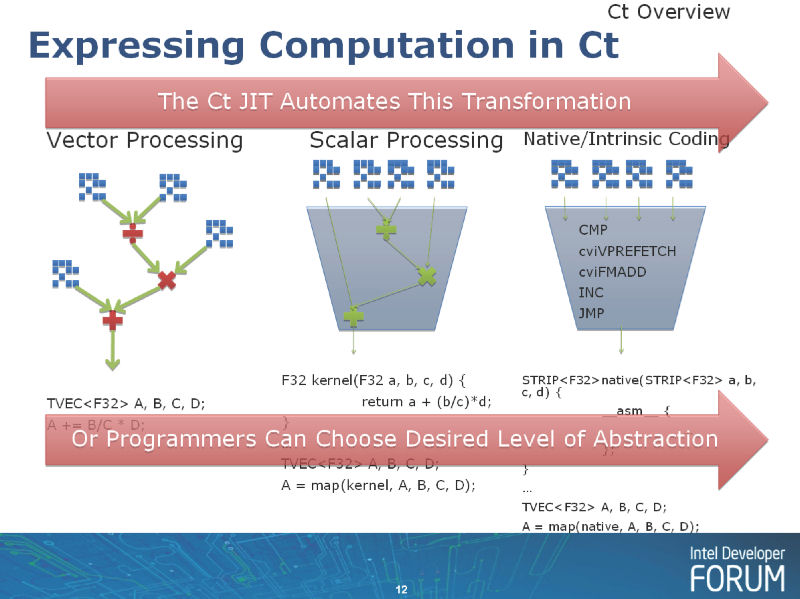 |
| Ctは2通りの手法が使える |
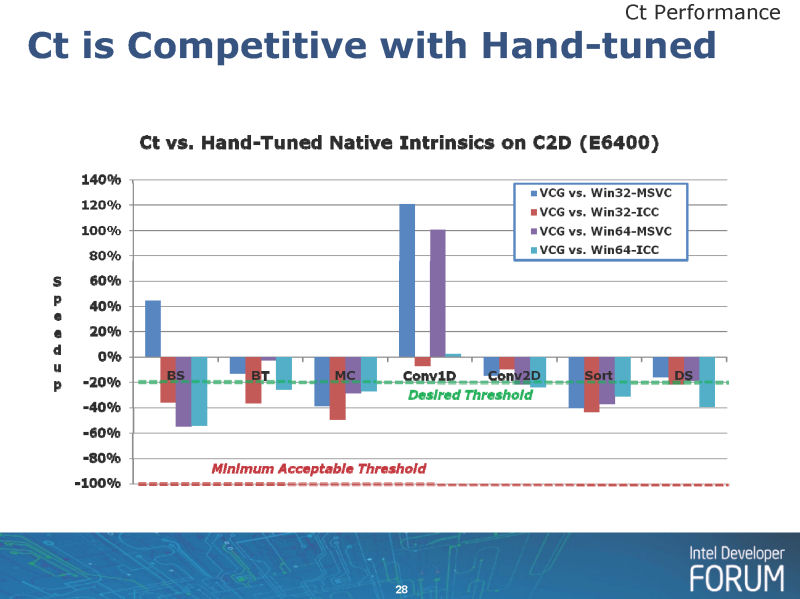 |
| 手動チューンと同じレベルの性能を実現 |
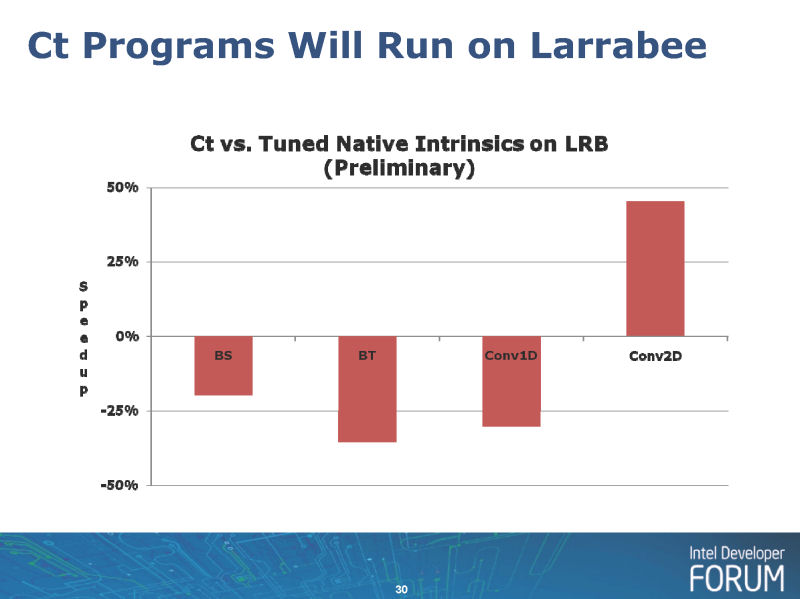 |
| CtのLarrabee上での性能 |
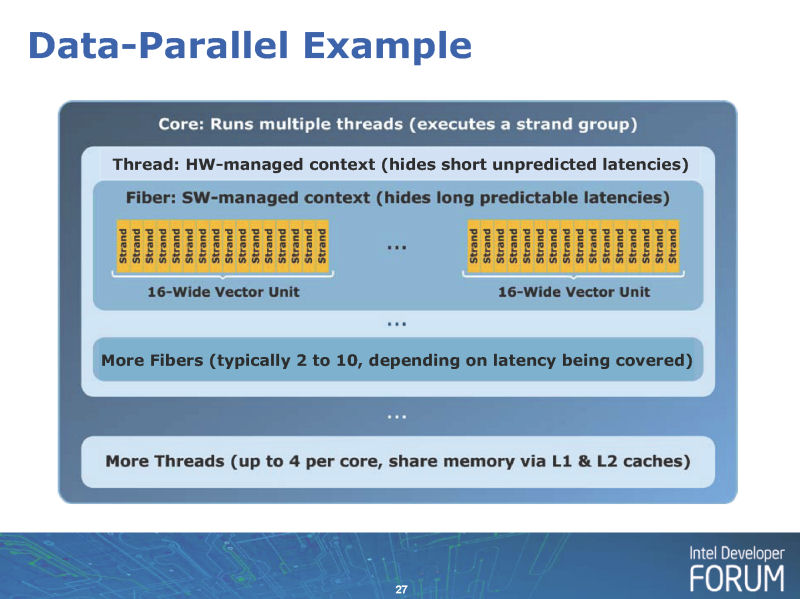 |
| データ並列の例 |
●オフラインレンダリングをさらにリアルタイムへと
Larrabeeの高い柔軟性は、GPUでは実現できなかったグラフィックス表現を可能にする。現在のGPUは、柔軟性を増したものの、依然としてさまざまな機能が制約されている。GPUは、シェーダプロセッサを搭載するようになり、オフラインレンダリングの世界の表現をどんどんリアルタイムグラフィックスに持ってきた。しかし、CPUで時間をかけて処理するオフラインレンダリングと完全に同レベルの品質は、まだ達成できない。今回Intelは、Larrabeeでは、オフラインレンダリングで実現しているような品質を実現可能になることを示した。
例えば、IDFではオフラインレンダリングで実装されているメソッド「A-Buffer」を、Larrabeeで使うことができると説明された。これは、ピクセルのカラー情報を書き込む際に、リンクするZレンジやカバレージのビットマスクといった情報も同時に書き込む手法だ。利点は重なり合うピクセルの順序を、正確なオーダーで表現できること。特に、半透過なピクセルを表現しようとすると、この機能は有用だ。Intelは、Chalk Talkで、全てがプログラマブルなLarrabeeではA-Bufferも実装できることを強調した。IDFでは、このほか、Irregular Z-Bufferなどのメソッドの実装も紹介された。
A-Bufferは、Microsoftも今後のDirectXに含める機能リストに挙げていた。Larrabeeはそれを先取りした形だが、これは、プログラマブルな柔軟性が、APIによる束縛からも解き放つことを意味している。従来のGPUは、グラフィックスAPI毎に新しいハードウェアアーキテクチャに刷新している。具体的には、DirectXの世代に合わせて、各社ともハードウェアアーキテクチャのメジャーチェンジを行なっている。それに対して、Larrabeeの場合は、ソフトウェアのアップデートだけで新APIに対応できる可能性が高い。例えば、MicrosoftがDirectX 12をリリースする時に、ソフトウェアアップデートで対応できるといった具合だ。
 |
| ソーティングなしの透過表現の例 |
 |
| ソーティングありの透過表現の例 |
 |
| 一般的シャドーマップのアルゴリズム |
 |
| イレギュラーZ-Bufferによる影の表現 |
 |
| フォグのある透過表現の例 |
 |
| シャドーマップとイレギュラーZ-Bufferの比較 |
●疑問符がつくLarrabeeの効率性
柔軟性の高いLarrabeeだが、疑問として残るのはGPUと同等以上のパフォーマンスを達成できるかどうかにある。IDFでも、その質問が何度も出たが、Intelは、注意深くLarrabeeとGPUのパフォーマンスを比較する言動を避けた。実際、Larrabeeと現行のDirectX 10世代GPUでは、プロセッサの柔軟性などに大きな違いがあるため、単純な比較は難しい。
Larrabeeにとって不利なのは、ソフトウェア処理による柔軟性は、効率性とのトレードオフにあることだ。一定の固定された処理を行なうなら、固定機能ハードウェアの方が、プログラマブルハードウェアよりも効率がいい。そのため、現在のGPUは、依然として一定の機能を固定ハードウェアで備えている。
Larrabeeの持つ柔軟性は、逆の面から見れば固定ハードウェアを省くことで、効率を犠牲にすることを意味している。そのため、Larrabeeは同時期のGPUに較べて、一定の電力当たりのパフォーマンスでは不利になる可能性がある。この場合、パフォーマンスと言っているのは、グラフィックス処理のパフォーマンスだ。もっとも、LarrabeeはGPUと異なり、グラフィックス処理でも、オンチップメモリによるデータの局所性をより多く利用できるため、単純に固定ユニットとプログラムユニットによる効率性だけでは、性能を推定できない。しかし、原理的に言えば、伝統的な3Dグラフィックスで、フルプログラマブルなプロセッサが、半固定機能のGPUを追い越すことは難しい。少なくとも、同レベルに立てても、引き離すことはできないだろう。
Intelの戦略の矛盾点はここにある。ディスクリートグラフィックスを求めるユーザーは、高いグラフィックスパフォーマンスを求める。そこに浸透させるためには、絶対的なパフォーマンス優位を示す必要がある。まさに、そのために、GPUベンダーは熾烈なパフォーマンス競争を行なっている。それも、短ければ半年サイクルでハードウェアを更新して、パフォーマンスを競っている。チップの開発期間も、Intelと較べるとずっと短く、小回りが効く。例えば、Larrabeeが、リリース時にパフォーマンスでトップを取れたとしても、すぐにGPUベンダーに巻き返されてしまうだろう。Intelは、そうした苛烈な戦争に、洗練されたLarrabeeで突っ込もうとしている。
Larrabeeが、ある意味で“ソフトウェアGPU”である点も疑問を呼び起こす。Intelが、従来の統合グラフィックスでは決して優れたソフトウェアを提供できていなかったからだ。そのため、メニイコアCPU上にGPUをソフトウェアで実現するLarrabeeのクオリティには、まだ疑問符がついている。
とはいえ、GPUが汎用コンピューティングへと大きく舵を切り、グラフィックスAPIもDirectX 11でよりプログラマブルへと向かいつつある現在、Larrabeeの秘めた可能性は大きい。Larrabeeが最も力を発揮するのは、汎用コンピューティングや、プログラム性を増す今後のグラフィックスだからだ。しかし、Intelは、かなり注意深くLarrabeeのプロモートを行なわないと、そうした利点が理解されて成功につながらないだろう。
もし、IntelがLarrabeeをグラフィックスではなく、汎用的なコンピューティングのためのメニイコアCPU製品として紹介していたら。Larrabeeアーキテクチャはもっと好意的に注目されていた可能性がある。メニイコアCPUとしては、それなりに理解できる合理的な設計だからだ。
しかし、その場合には、IntelはLarrabeeをグラフィックス製品としてマスマーケットに浸透させることが難しい。結局、HPC市場など、ごく一部にだけしか浸透しない製品で終わってしまう可能性がある。Intelのマーケティング戦略としては、GPUと真っ向から戦い、叩かれながらも、グラフィックスとして浸透させるほかはない。そこに、Larrabeeの難しさがある。
□関連記事
【8月19日】【海外】LarrabeeがPentiumをベースにしたのはなぜか
http://pc.watch.impress.co.jp/docs/2008/0819/kaigai460.htm
【8月11日】【海外】Cell B.E.と似て非なるLarrabeeの内部構造
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
【8月4日】【海外】ついにベールを脱いだIntelのCPU&GPUハイブリッド「Larrabee」
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
(2008年8月22日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.