 |


■後藤弘茂のWeekly海外ニュース■Intelの次期CPUインターコネクト「QPI」 |
●システムアーキテクチャを刷新するQPI
IntelのIA-32系次期マイクロアーキテクチャ「Nehalem(ネハーレン)」と、次期IA-64「Tukwila(タックウイラ)」からは、システムアーキテクチャが一新される。その要となるのが、新しいインターコネクト「QuickPath Interconnect(QPI)」だ。
QPIは、従来のIntel CPUのFSB(Front Side Bus)に代わる、高速インターコネクトだ。アーキテクチャ的には、完全に一新される。従来のIntelのFSBは、最高で1Gtps台の転送レートで、GTL+信号方式でインターフェイス幅の広い、双方向(bidirectional)の共有バスだった。それに対して、QuickPath Interconnect(QPI)は、数Gtps台の転送レートで、ディファレンシャル(差動)信号方式で、インターフェイス幅の狭い、片方向(unidirectional)のポイントツーポイント(Point to Point)型リンクとなる。
QPIの最初の世代は、最高6.4Gtpsの転送レートで提供される。従来のFSBの最高1.6Gtps(FSB 1600)の4倍の転送レートだ。実効バス幅は片方向16bitsなので、1リンクのQPIの帯域は25.6GB/sec。これは、FSB 1,600MHzの12.8GB/secの2倍、FSB 1,333MHzの10.7GB/secの約2.5倍となる。QPIでは、インターコネクトの帯域が一気に倍増するだけではない。CPU同士が直接続されるため、スケーラブルに低レイテンシで柔軟なマルチプロセッサ構成が実現できる。
QPIは、Intel CPUにとって大きなインパクトを与える。特に、これまで、システムアーキテクチャ面でAMDにリードされていたサーバープラットフォームで、Intelの最大の武器となりうる。QPIは、何がこれまでのFSBと違うのか。
●QPIは、実はシリアルではない
QPIは、ディファレンシャル信号(Differential Signaling)でデバイス同士をポイントツーポイントで接続することで、高速伝送を実現している。ディファレンシャル信号では、2本のペアになった信号線を使い、位相の反転した信号を送る。そのため、1本の信号線だけで伝送する場合と較べると、ノイズに強く高速データ伝送が可能だ。これは、PCI Expressなどと共通した、高速伝送の王道のアプローチだ。
QPIは“シリアルバス”と言われてきたが、厳密にはそうではない。シリアルバスかどうかのチェックポイントが、「エンベデッドクロック(Embedded Clock)方式」か否かにあるとすれば、QPIはシリアルバスには入らない。QPIは、エンベデッドクロックではないからだ。
PCI Expressなどのシリアルインターフェイスが、クロック信号をデータ信号に埋め込むエンベデッドクロック方式を採るのに対して、QPIではクロックは別な信号リンクで伝送する。図のように、1リンク片方向につきディファレンシャル方式のフォワーデッドクロック信号が1ペア付帯する。この点は、典型的なシリアルインターコネクトであるPCI Expressとの決定的な違いとなっている。
こうしたQPIのアプローチは、AMDの現行のHyperTransportによく似ている。HyperTransportも、狭い幅のリンク毎にクロック信号を伝送しているからだ。ちなみに、コンシューマにとって馴染みの深い高速CPUを見ると、PLAYSTATION 3(PS3)のCell Broadband Engine(Cell B.E.)とXbox 360のXCPU(Xenon)のどちらも、ある程度似通ったインターコネクトを備えている。エンベデッドクロックではなく、クロック信号線を使うディファレンシャル信号方式のポイントツーポイント型のインターコネクトだ。
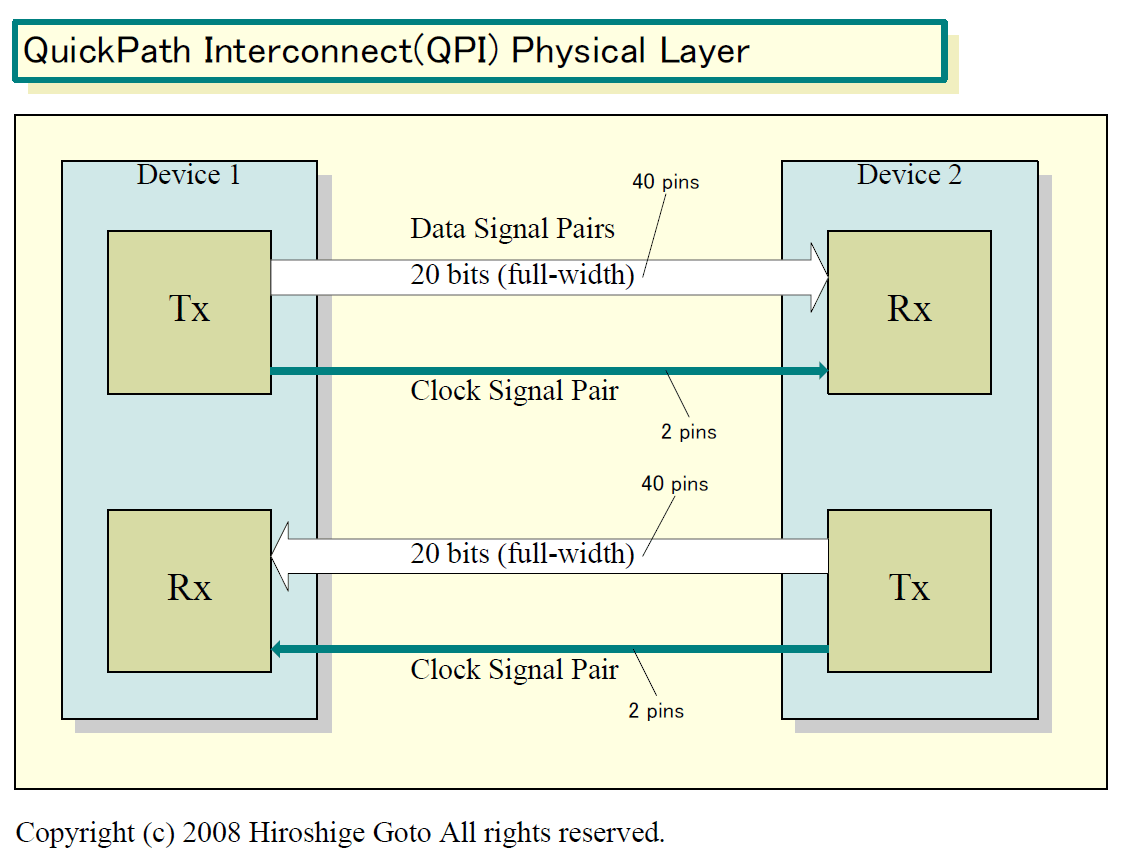 |
| QuickPath Interconnect(QPI) Physical Layer PDF版はこちら |
●レイテンシと帯域のバランスを取った結果
これらの類似性は、おそらく偶然ではない。現状では、CPUのインターコネクトとして最適な方式を追求すると、結論はエンベデッドクロックを使わない方式になると推定される。それは、エンベデッドクロックにオーバヘッドとレイテンシがあるためだ。「8b/10b」エンコーディングなどの方式でクロックを埋め込むため、データ転送の5~25%がクロックで食われる。いわゆる、エンベデッドクロック効率(Embedded Clock Efficiency)問題で、回路規模も大きくなる。また、コントローラは、データに埋め込むクロックのデコードとエンコードを行なう必要があり、それはCPUにとって望ましくないレイテンシとなる。Intelがパラレル方式の現在のFSBにこだわっていた理由の1つは、レイテンシが短いことだった。
エンベデッドクロック方式では、ピン間の伝送タイミングのずれであるスキューが一切問題とならない。そのため、原理的にはより高速化が可能だ。しかし、現状のターゲット転送レートである10Gtps以下では、エンベデッドクロックにしなくても対応できるとCPUベンダーは判断しているのかもしれない。CPUバスのように、伝送距離が限られていて、接続されるデバイスも決まっている場合は、エンベデッドクロックを取らなくても高速化できると判断したと推測される。つまり、現在のターゲットの転送レートの範囲で、レイテンシとオーバヘッドを少なくすることを考えると、エンベデッドクロックは選択肢からはじかれるというわけだ。
ただし、HyperTransportは次のステップではエンベデッドクロックも視野に入れている。おそらく、業界全体の流れとしては、クロック信号を伴走させる方式でしばらくカバーし、次のステップで、より高速化が必要になった時にエンベデッドクロックに移行すると推測される。Intelは現行のQPIのまま、6.4Gtpsよりも高速にできると顧客に説明しており、10 Gtps前後程度まではこの方式を続けると推測される。
こうして見ると、QPIは、他のCPUと同様に、高転送レートと低レイテンシの間で、うまくバランスを取っていることがわかる。
| QPI vs. FSB | ||
|---|---|---|
| Intel FSB(Front Side Bus) | Intel QuickPath Interconnect(QPI) | |
| Topology | Shared Bus | Point to Point Link |
| Physical Bus Width(bits) | 64 | 20 |
| Data Transfer Width(bits) | 64 | 16 |
| Requires Side-band Signals | Yes | No |
| Total Number of Pins | 150 | 84 |
| Clock Per Bus | 1 | 1 |
| Embedded Clock | No | No |
| Bus Direction | Bi-directional | Uni-directional |
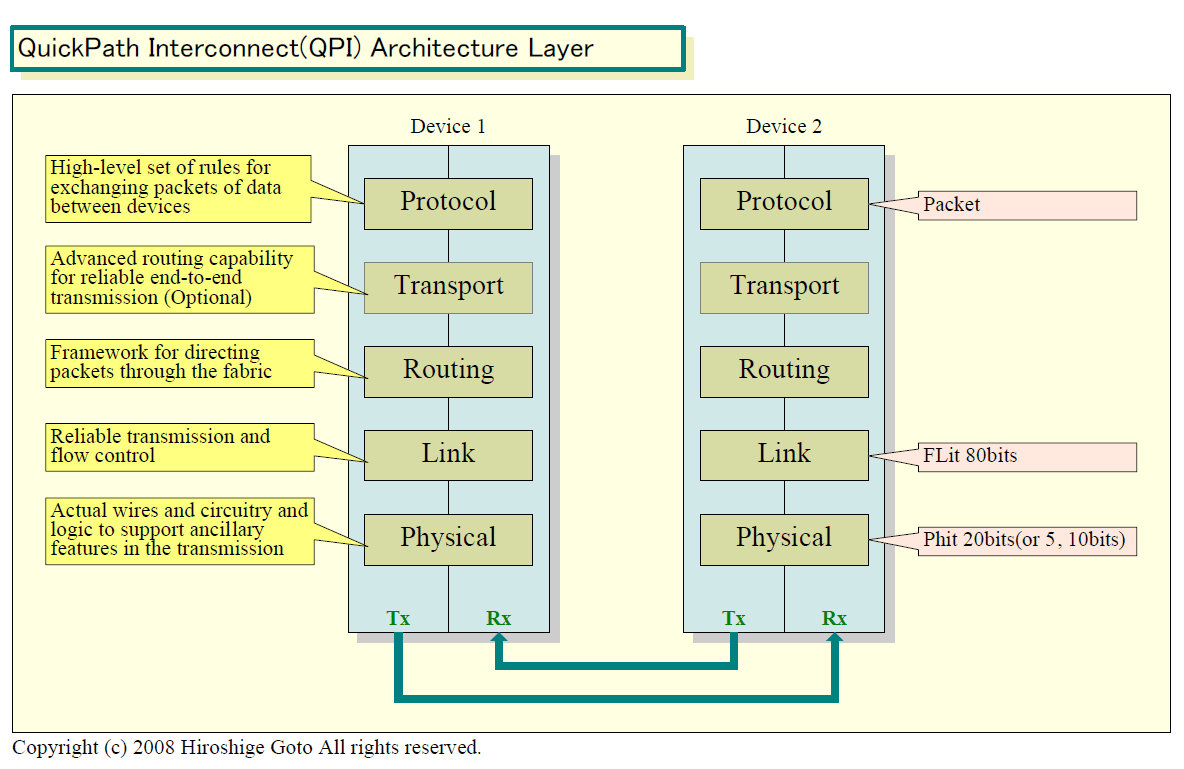
●5レイヤの階層構造アーキテクチャ
PCI ExpressやHyperTransportと同様に、QPIにも複数のインターフェイス幅の構成のリンクがある。3種類で、フル幅(full-width)リンクが20bits、ハーフ幅(half-width)が10bits、クオータ幅(quarter-width)が5bitsとなっている。CPUのインターコネクトとして標準的に使うのは、フル幅の20bitsだ。ローレベルのbits幅が2のべき乗になっていないのは、後述するオーバヘッドがあるためで、実際にはフル幅の20bitsレーンで伝送できるデータは16bits単位となる。
 |
| QuickPath Interconnect(QPI) Architecture Layer PDF版はこちら |
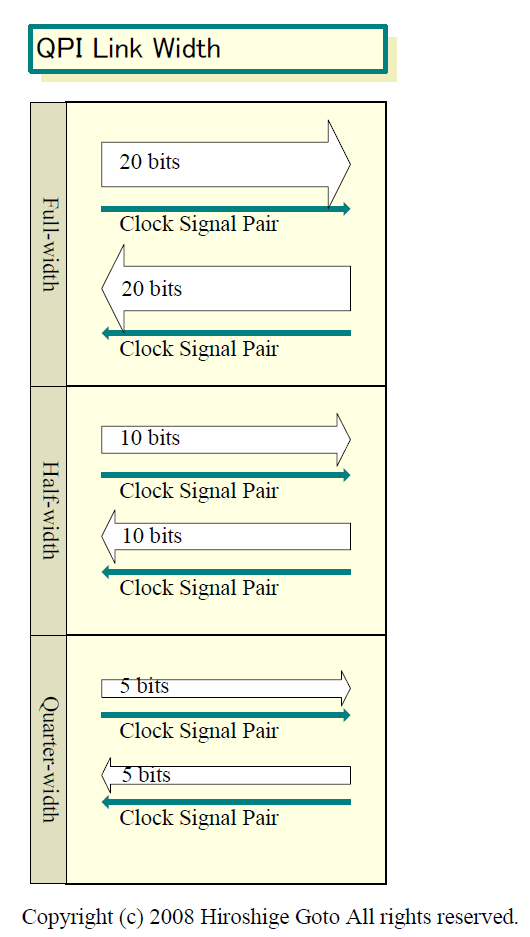 |
| QPI Link Width PDF版はこちら |
各データ信号がディファレンシャル信号方式で2ワイヤを使う。また、クロック信号も1ペアで2ワイヤを使う。そのため、フル幅の片方向で合計42ワイヤを必要とする。さらに、それが双方向で2倍になるため、フル幅で1リンクは84ピンとなる。従来のIntelの64bits幅のFSBの150ピンと較べて、ほぼ半減する。広インターフェイス幅の複雑な等長配線は大幅に緩和されることになる。
QPIも他のインターコネクトと同様に階層化されたアーキテクチャを持っている。最下層の物理層(Physical layer)は、実際に伝送される信号を扱うレイヤで、伝送するユニットは20bitsの「Phit (Physical unit)」単位となる。20bitsというPhitのサイズはフル幅の場合で、ハーフ/クオータ幅だとそれぞれ5bitsと10 bitsとなる。
リンク層(Link layer)では、フロー制御やエラー訂正といった信頼性確保のための制御を行なう。CRCエラーディテクションやセルフヒーリングリンク(self-healing links)、クロックフェイルオーバー(clock fail-over)といった機能の制御だ。帯域を圧迫するRASフィーチャは、RASモード時にだけ提供される仕組みとなっている。
また、大規模なマルチプロセッサシステムで発生しがちなパケットのリソース競合によるデッドロックを回避するために、最大3つまでのバーチャルネットワーク機能も提供する。もっとも、バーチャルネットワーク機能については、旧DEC/CompaqのAlpha EV7(21364)のホワイトペーパーに、すでに同様の機能の実装の説明があった。ちなみに、Microprocessor ForumでEV7の発表を行なったJoel S. Emer氏は、現在はIntelのフェロー(Intel Fellow, Director, Microarchitecture Research, Enterprise Group)になっている。
リンク層で扱うデータサイズは80bitsの「Flit (Flow control unit)」単位だ。フル幅のQPIの場合は、20bitsのPhitで、4サイクルかけて1Flitを送る。80bitsのうち、実際のデータ本体は64bits分で、残りはヘッダーやエラー訂正などに使われる。例えば、各Flitにつき8bits CRCエラーディテクションが設定されている。そのため、20bitsレーンで伝送されるデータは計算上16bits分となる。
●ラウティング機能も実装
ラウティング層(Routing layer)は、パケットを他のデバイスに転送する場合のフレームワーク。3以上のデバイスがQPIで接続されている場合のラウティングを担当する。
トランスポート層(Transport layer)では、信頼性確保のための、より高度なラウティング機能を提供する。ただし、この層はアーキテクチャ上で定義されている段階で、最初の製品には実装されないという。
プロトコル層(Protocol layer)は、最上位のプロトコルをハンドリングする層。「MESI」プロトコルをモディファイしたキャッシュコヒーレントなどが含まれる。この層では、Flitを複数まとめたパケット単位で扱う。
QPIは、20 bits幅で16 bitsしか伝送しないのは効率が悪く見えるが、実際にはそうでもない。ラウティングなどが始めから組み込まれているため、サイドバンド信号(Side-band signal)が必要ない。RASフィーチャも備えている。
全体で見ると、QPIは機能面でもスケーラブルになっていることがわかる。ハイエンドには高度なRAS機能やラウティング機能を提供できるが、その一方で、そうした機能の実装は小さく止めることも可能になっている。例えば、クライアントPC向けCPUでは、ラウティング層のテーブルは最小にして、トランスポート層は省き、仮想チャネルバッファなども最小にするといった実装が考えられる。これは、QPIが、バリューCPUからハイエンドサーバーまでカバーしなければならないためだ。
●キャッシュコヒーレンシプロトコルも拡張
QPIでは、CPU同士を直接続する。そのため、従来のIntel CPUと比べると、柔軟に大規模なマルチプロセッサ構成が取れるようになった。そこで、Intelは、マルチプロセッサ時のパフォーマンスの鍵となる、キャッシュコヒーレンシにもQPIで改良を加えた。標準的なMESIプロトコルに拡張を加える形で実現している。
MESIでは、各キャッシュラインごとに、4つのステイト、「M(modified)」「E(exclusive)」「S(shared)」「I(invalid)」が設定される。QPIでは、この4つに加えて、新たにリードオンリフォワードステイト「F(forward)」が導入された。下のチャートを見るとわかるように、Fステイトでは、キャッシュラインはクリーン(書き換えられていない)で、書き換えることはできないが、フォワードはできる。つまり、他のCPUからリード要求が来た場合には、すぐにキャッシュライン上のデータを送ることができる。この「MESIF」については、Intelが特許を出願したことで、少し前から存在が知られていた。この他、QPIではキャッシュスヌープにも低レイテンシの新しいタイプのビヘイビアもサポートしている。
| Cache line states | |||||
|---|---|---|---|---|---|
| state | clean/dirty | write | forward | transision to | |
| M | modified | Dirty | OK | OK | |
| E | exclusive | Clean | OK | OK | M,S,I,F |
| S | shared | Clean | No | No | I |
| I | invalid | - | No | No | |
| F | forward | Clean | No | OK | S,I |
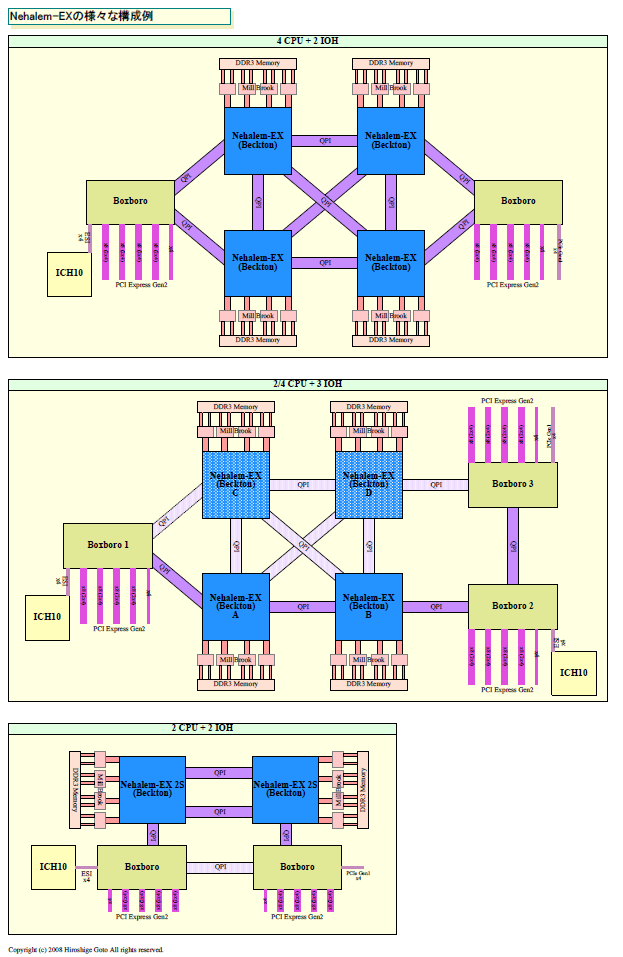 |
| Nehalem-EXのさまざまな構成例 PDF版はこちら |
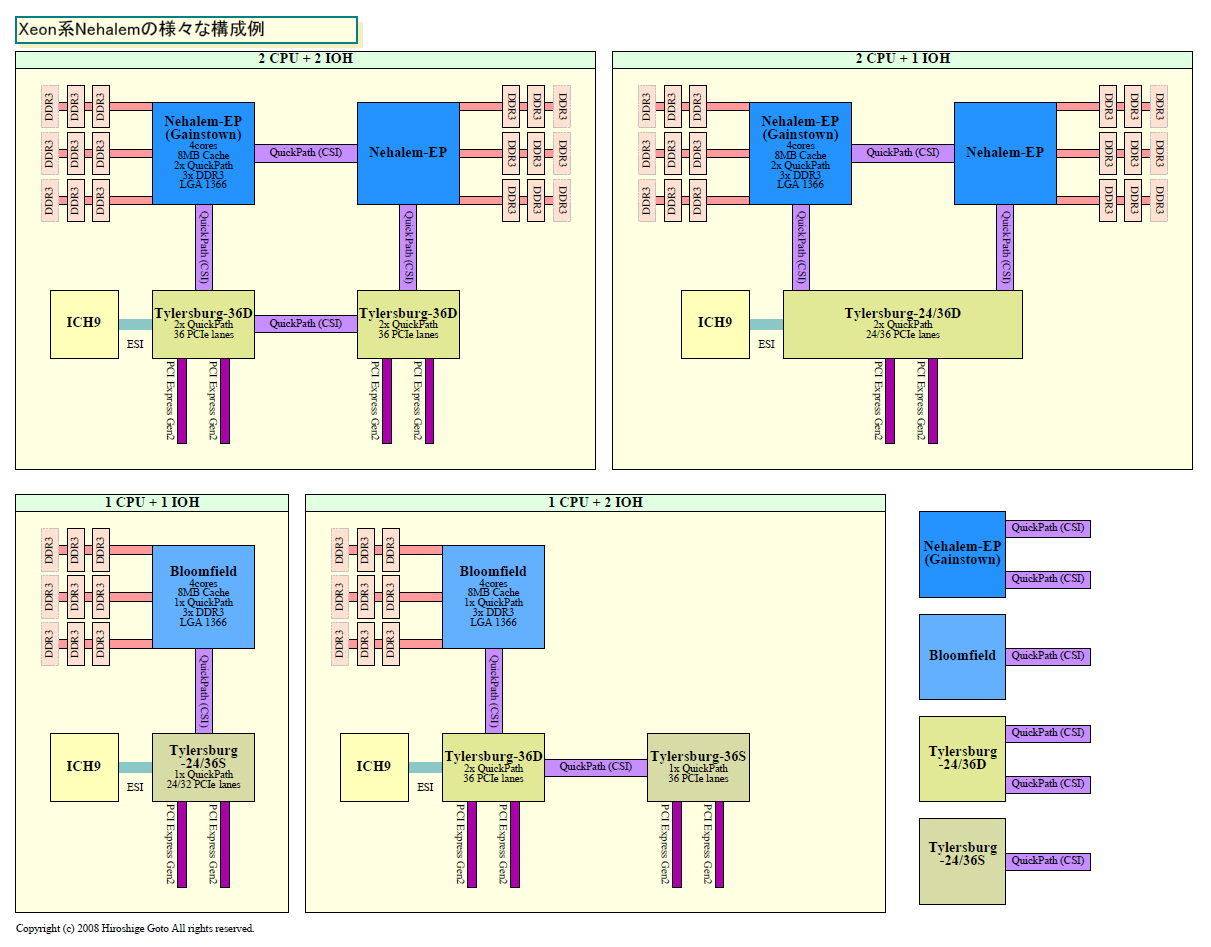 |
| Xeon系Nehalemのさまざまな構成例 PDF版はこちら |
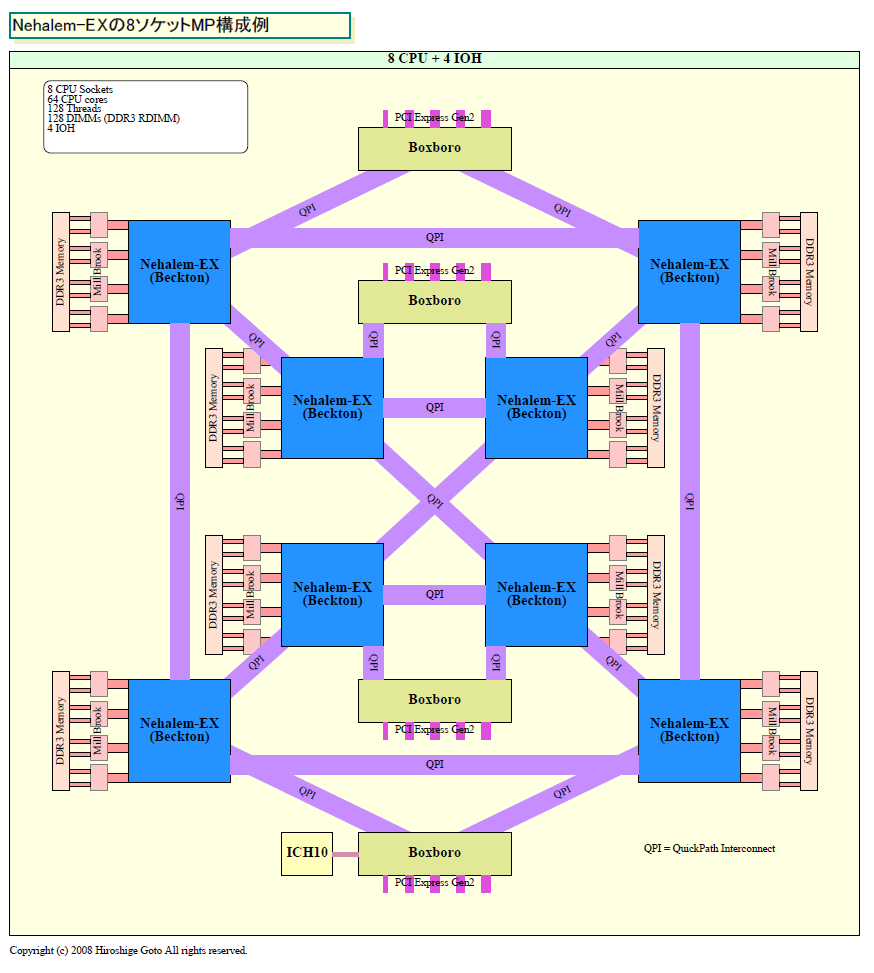 |
| Nehalem-EXの8ソケットMP構成例 PDF版はこちら |
□関連記事
【3月28日】【海外】階層化こそがNehalem MAの特徴
http://pc.watch.impress.co.jp/docs/2008/0328/kaigai429.htm
【3月21日】【海外】モバイルにもL3キャッシュをもたらすNehalem
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
(2008年3月31日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.