 |


■後藤弘茂のWeekly海外ニュース■階層化こそがNehalem MAの特徴 |
●電力効率の面で優れるSMT
Intelは来週、上海で開催する技術カンファレンス「Intel Developer Forum(IDF)」で、次期CPU「Nehalem(ネハーレン)」のマイクロアーキテクチャの概要を明らかにする見込みだ。Nehalemについては、前回のIDFで、CPUコア以外のインターフェイス回りと命令セットについてはある程度明らかにされた。しかし、CPUコア自体の拡張については、Intelは秘したままだった。今回のIDFでは、いよいよNehalemの内面が公開される。そのIDFに先立って、IntelはNehalemの概要の大まかな概要などを明らかにした。
Nehalemマイクロアーキテクチャのハイライトは、CPUコアにHyper-Threadingと同じSMT(Simultaneous Multithreading)技術を実装したことだ。Nehalemでは、各CPUコアが、2スレッドを同時並行実行できる。Intelによると、SMT技術を加えたのは、「SMTが最も消費電力当たりのパフォーマンスが優れたフィーチャだから」という。Nehalemでは、単にパフォーマンスを高めるのではなく、ハイパフォーマンスかつ電力効率のいいマイクロアーキテクチャにすることが目的だった。SMTは、その鍵となる技術だという。
SMTが電力効率で有効というのは、以前から指摘されていた。例えば、IBMは2005年のCPUカンファレンス「Hotchips」のチュートリアルで、SMTは20%近いパフォーマンス向上を、24%の電力アップで実現できる、電力効率が高い技術だと説明した。現在、最新のパフォーマンスCPUの多くはSMTあるいは何らかのマルチスレッディング技術を実装するが、その理由の1つは、電力効率の面で有利であるためだ。
 |
| SMTはパフォーマンスと電力効率を強化する |
 |
| SMTのパワー効率についての結論 |
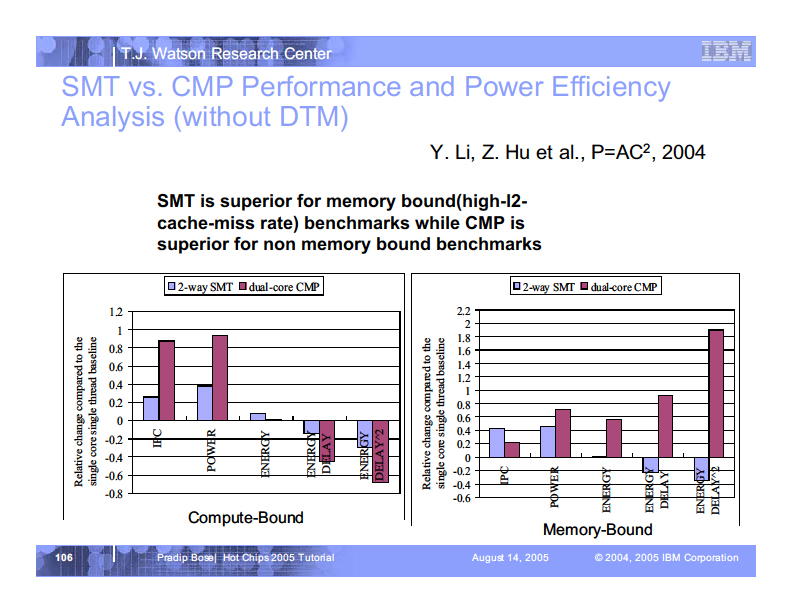 |
| SMT VS CMP |
アウトオブオーダ実行型のCPUの場合、元々、さまざまなリソースがアウトオブオーダ実行のために多重化されているため、SMTを低コストに実装しやすいと言われている。例えば、SMTでは2つのスレッドそれぞれにレジスタが必要になる。しかし、アウトオブオーダ実行CPUでは、レジスタ競合を避けるために論理レジスタより多くの物理レジスタを実装しているため、それをSMTにも転用できる。追加ハードウェアが少なくてすむ分、電力消費も抑えやすい。
もっとも、SMTを効率よく実行するためには、やはりある程度はレジスタなどのリソースの増強は行なわなければならないだろう。それを示唆するのが、Nehalemのマイクロアーキテクチャ上の命令ウインドウとスケジューラの増強だ。
現在のIntelのCore Microarchitecture(Core MA)では、インフライトで制御できるuOPs(CPUの内部命令)の数は96個だが、Nehalemでは128個へと33%拡張される。パイプラインの中で制御できるuOPs数が増えるため、アウトオブオーダ実行できるuOPsの命令ウインドウが大きくなる。より多くのuOPsの中から並列実行できる組み合わせを抽出できるようになるため、原理的には並列性が上がり、IPC(instruction per cycle)が向上する。
インフライトuOPs数の強化は、NehalemがSMTを実装したことと関連していると考えられる。128個のインフライト制御命令ウインドウは、SMTの2つのスレッドで共有されると考えられる。Nehalemでは、SMTによって、並列に実行できるuOPsの組み合わせが増え、実行パイプラインを効率よく埋められるようになる。しかし、実行リソースを効率よく埋めるためには、やはり、より多くのuOPsをオンザフライで制御する必要がある。そう考えると、この拡張はマルチスレッド性能の向上につながる。
 |
| Nehalemにおける、Core MAの拡張 |
●マルチスレッドサポートの要トランザクショナルメモリは実装せず?
IntelはNehalemにおける、そのほかのアルゴリズム上の拡張例を2つ挙げた。
1つは、アンアライン(unaligned)キャッシュアクセス(不整列キャッシュアクセス)の高速化で、従来のCPUが苦手としてきた部分だ。これについては、具体的なアルゴリズムの実装は明らかにしなかった。しかし、Intelは、メディアアプリケーションでは、データが整列されていないケースがあり、キャッシュラインもまたがってしまうケースもあると指摘。Nehalemでは、そうしたケースでも、従来のCPUと較べるとずっと高いスループットでアクセスができると説明した。これは、よりメディアプロセッシングに向いた拡張が行なわれるSandy Bridgeでも重要となる機能だと推測される。
もう1つの例は、スレッド間の同期の高速化だ。CPUがマルチコア&マルチスレッド化するにつれて、スレッド同期の問題はクリティカルになる。「コアを増やすにつれて、優れたスケーラビリティを得るためには、同期ポイントのハンドルでアプリケーションを高速化しなければならない」とIntelは説明する。そのため、Nehalemでは、レガシーの同期プリミティブを高速化するハードウェアを加えたという。新命令を加えるのではなく、既存のLOCKとXCHG命令を使う同期を高速化するという。
しかし、このことは、IntelがNehalemではハードウェアトランザクショナルメモリ(Transactional Memory)を実装しないことを示唆している。トランザクショナルメモリでは、従来の方法でのロックと同期の必要をなくすからだ。
トランザクショナルメモリでは、メモリをロックする代わりに、データをいったんプールし、トランザクション単位で処理をまとめてメモリに渡す(Commit)ことで、スレッド間の並列処理を可能にする。コミットの前に、トランザクション間のコンフリクトを検知して、衝突した場合にはトランザクションをリスタートさせる。例外がほとんど起こらないことを前提とした、小さな範囲でのスレッドの投機的な実行とも言える。Intelは、以前のIDFで、同期するスレッド数が多くなると、トランザクショナルメモリの利点が強まると説明。ソフトウェア実装でも、8スレッドの処理ではロック方式に対して圧倒的に有利になることをデモした。
トランザクショナルメモリの研究では、IntelとSun Microsystemsが積極的で、これまでも2社がカンファレンスなどで研究成果を発表して来た。Sunは、次期サーバーCPUでハードウェアトランザクショナルメモリを実装する。しかし、Intelは8スレッド以上ではトランザクショナルメモリが有利と説明しながらも、8スレッドを同時に走らせることができるNehalemにハードウェアトランザクショナルメモリを実装しないと推測される。とはいえ、トランザクショナルメモリがこの問題についての解であることは間違いがなさそうだ。Nehalemがレガシーの同期機能を高速化しただけだとすれば、この点でのNehalemはまだ中間地点に過ぎないことになる。
 |
| Nehalem MAはダイナミックにスケーラブルで、革新的なデザイン |
●階層化がNehalemを貫くフィロソフィ
Nehalemでは、アルゴリズム以外の面も強化された。1つは、CPUのシングルスレッドパフォーマンス向上の鍵となる、分岐予測精度(Branch Prediction)の向上だ。
そのため、Nehalemでは、ブランチプレディクタを2階層化した。「セカンドレベルのブランチプレディクタは、非常にフットプリントの大きなコードでも、分岐ヒストリのキャプチャを可能にする。現在の小さなブランチプレディクタ(のバッファ)では、コードフットプリントが大きいと、全てのヒストリは納め切れない。しかし、セカンドレベルプレディクタを加えることで、より大きなヒストリで予測ができるようになる。これは、データベースのようなアプリケーションで利点がある」とIntelは説明する。
ちなみに、ブランチプレディクタの階層化は、かつてPentium III/Pentium 4のアーキテクトの1人だったAndy Glew氏が、以前から主張していた。Glew氏は一時、AMDのアーキテクトチーム「AMD Architecture Review Board (ARB)」に加わっていたが、階層化ブランチプレディクタは、その際に、AMDのK10に採用を提案して、AMDに蹴られたと説明していたフィーチャの1つだ。Glew氏は、現在はIntelに戻っている。このほか、Nehalemでは、return命令で戻るポインタをバッファするReturn Stack Buffer (RSB)は、リネーム機能が追加され、予測ミスを減らしたという。
また、Nehalemでは、物理メモリアドレスをキャッシュする「Translation Lookaside Buffer (TLB)」も階層化される。「セカンドレベルTLB階層を導入するのは、アプリケーションが大きくなるにつれて、全体のパフォーマンスでTLBを大きくすることが重要になるからだ」という。Nehalemでは、セカンドレベルの512エントリのTLBが追加される。
 |
| 拡張されたキャッシュサブシステム |
Nehalemでは、キャッシュがさらに階層化され、短レイテンシで小さいL2と長レイテンシで大きなL3に分かれた。L2を256KBと小さなCPUコア占有キャッシュとしたことで、L2アクセスレイテンシはこれまでの10数サイクルから、10サイクル以下に減ったと推測される。その一方で、おそらく20サイクル以上と低速だが大容量のL3によって、フットプリントの大きなアプリケーションもカバーできる。
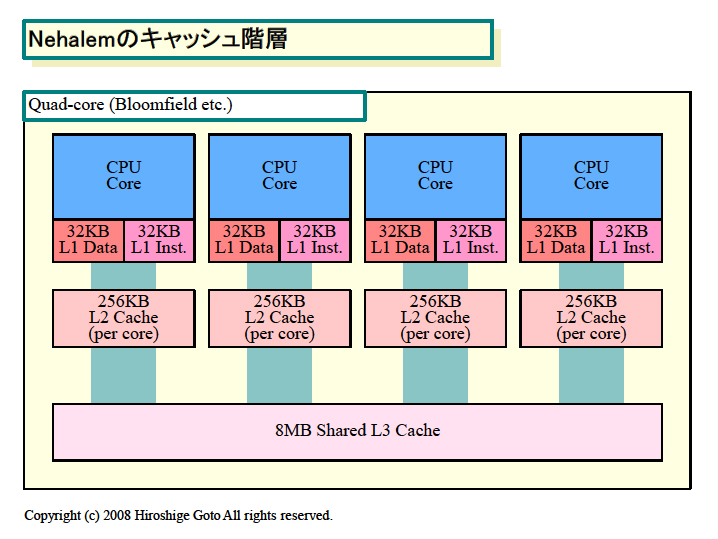 |
| Nehalemのキャッシュ階層 |
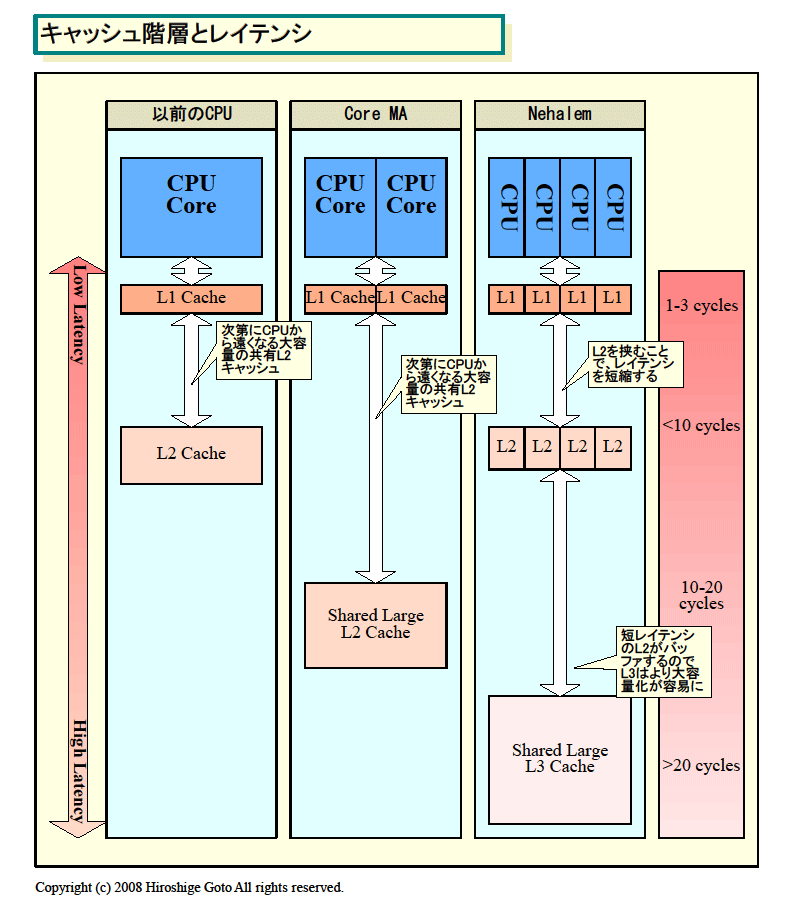 |
| キャッシュ階層とレイテンシ
PDF版はこちら |
Nehalemでは、こうしたキャッシュ階層化と似たような階層化が、ブランチプレディクタやTLBといったマイクロアーキテクチャのいたるところで行なわれていることがわかる。その意味では、階層化がNehalemマイクロアーキテクチャの特徴とも言える。
こうして見ると、SMT以外のNehalemの拡張の多くは、有効性は高いものの、比較的小さなテクニックに見える。NehalemはIntelが暖めていたテクニックの集大成とも言えそうだが、どちらかと言うと、冒険は避けて、小さな改良でパフォーマンスを上げることができるテクニックに集中したように見える。
もちろん、このほかにも、IDFで初発表する大きな拡張が、まだ隠されている可能性はある。しかし、Nehalemでは、CPUコアを大手術するよりも、むしろシステムアーキテクチャを変えることでパフォーマンスの飛躍を図った可能性の方が高そうだ。このことは、IntelがNehalemをどのように設計したか、という問題と密接に関わっている。
●Nehalemはフロムスクラッチ設計か?
Intelは、Nehalemが基礎から新たに作られた“グラウンドアップ”マイクロアーキテクチャだと言いながら、“Core MAをベースにしている”とも説明する。矛盾しているようだが、Intelは最近になってこの疑問に答えた。
「基本的にはどちらも正しい。Nehalemでは、既存のCoreマイクロアーキテクチャのピースを取り入れており、その中で4ワイドのエグゼキューションエンジンは大きなパートを占めている。我々は、何年もかけて開発したマイクロアーキテクチャを活用する。しかし、その上に、Simultaneous Multithreading(SMT)のような大きな新フィーチャを被せている。そのため、(Nehalemの)全体の設計は基本的にはフロムスクラッチとなっている。
以上は(CPU)コアサイドの話だ。ほかの要素、我々がアンコア(Un-Core)と呼ぶ、CPUコア以外の部分については、完全に新しい設計となっている。例えば、L3キャッシュなどだ。そうしたブランドニューの要素は、フロムスクラッチ設計となっている。(Nehalemは)純粋にフロムスクラッチで設計したものと、既存の技術を顕著に拡張したものの組み合わせだが、全体で見ると、ほとんどフロムスクラッチだ」
この説明からすると、NehalemのCPUコアはCore MAをベースに、SMTなどの大きな拡張を加えて設計し直し、新設計のアンコア部分と組み合わせたものということになる。Core MAの「Micro-OPs Fusion/Macro-Fusion」や中庸なパイプライン段数といった基本的な手法は、そのまま継承されると推測される。だとすれば、表現はともかく、CPUコアのキーコンセプトはCore MAを継承していることになる。Intelは、以前にCore MAの命令をフュージョンさせるアプローチを継続して発展させると説明しており、Core MAがNehalemも含めた今後数世代のIntel CPUのベースになりそうだ。
しかし、これはちょっと異例なアプローチだ。なぜなら、Core MAはIntelのMobility Groupに属するイスラエルのハイファ(Haifa)の開発センターで設計され、NehalemはIntelのDigital Enterprise Groupに属する米オレゴン州ヒルズボロ(Hillsboro)の開発センターで設計されているからだ。つまり、Core MAは開発センターの垣根を越えて継承されることになる。
Intelの主力CPU開発センターであるヒルズボロは、過去にPentium III(P6)やPentium 4(NetBurst)マイクロアーキテクチャをフロムスクラッチから開発して来た。押しも押されもせぬIntel随一のCPU開発センターであり、従来のパターンだと、ヒルズボロでCPU開発を行なう場合は、ゼロから開発をスタートし、既存のマイクロアーキテクチャは継承しない。既存マイクロアーキテクチャの派生品を開発するのは、Intelの中でも新興の開発センターであり、以前はハイファがその役を担っていた。
それが、今回は、大幅に拡張するとはいえ、ハイファ設計のCore MAを、ヒルズボロのNehalemが継承することになる。見方によっては、ハイファとヒルズボロの立場が逆転したとも言える。IntelのDigital Enterprise Groupが、Nehalem設計について、“基本的にはフロムスクラッチだ”と強調する理由は、このあたりにありそうだ。
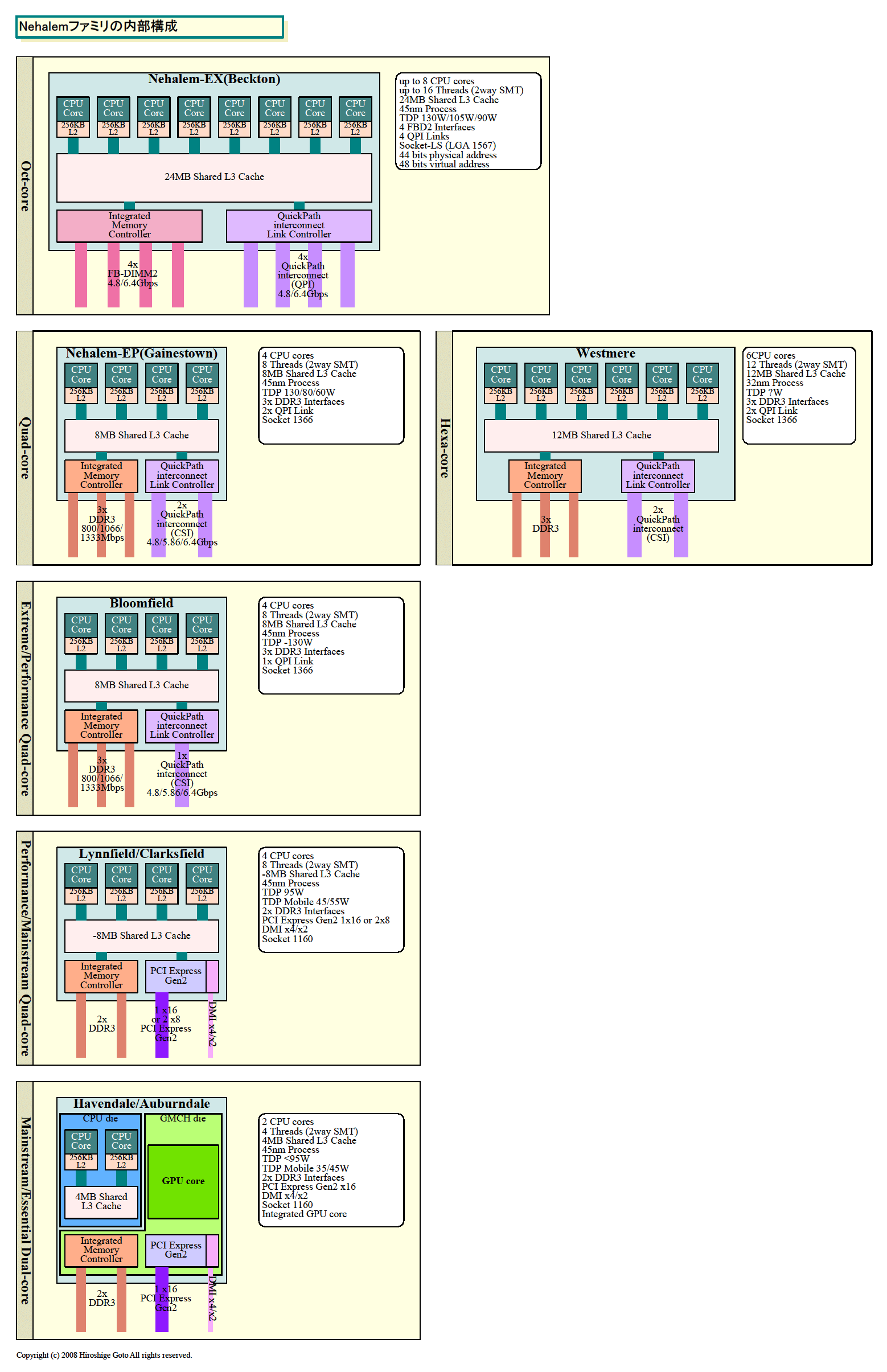 |
| Nehalemファミリの内部構成
PDF版はこちら |
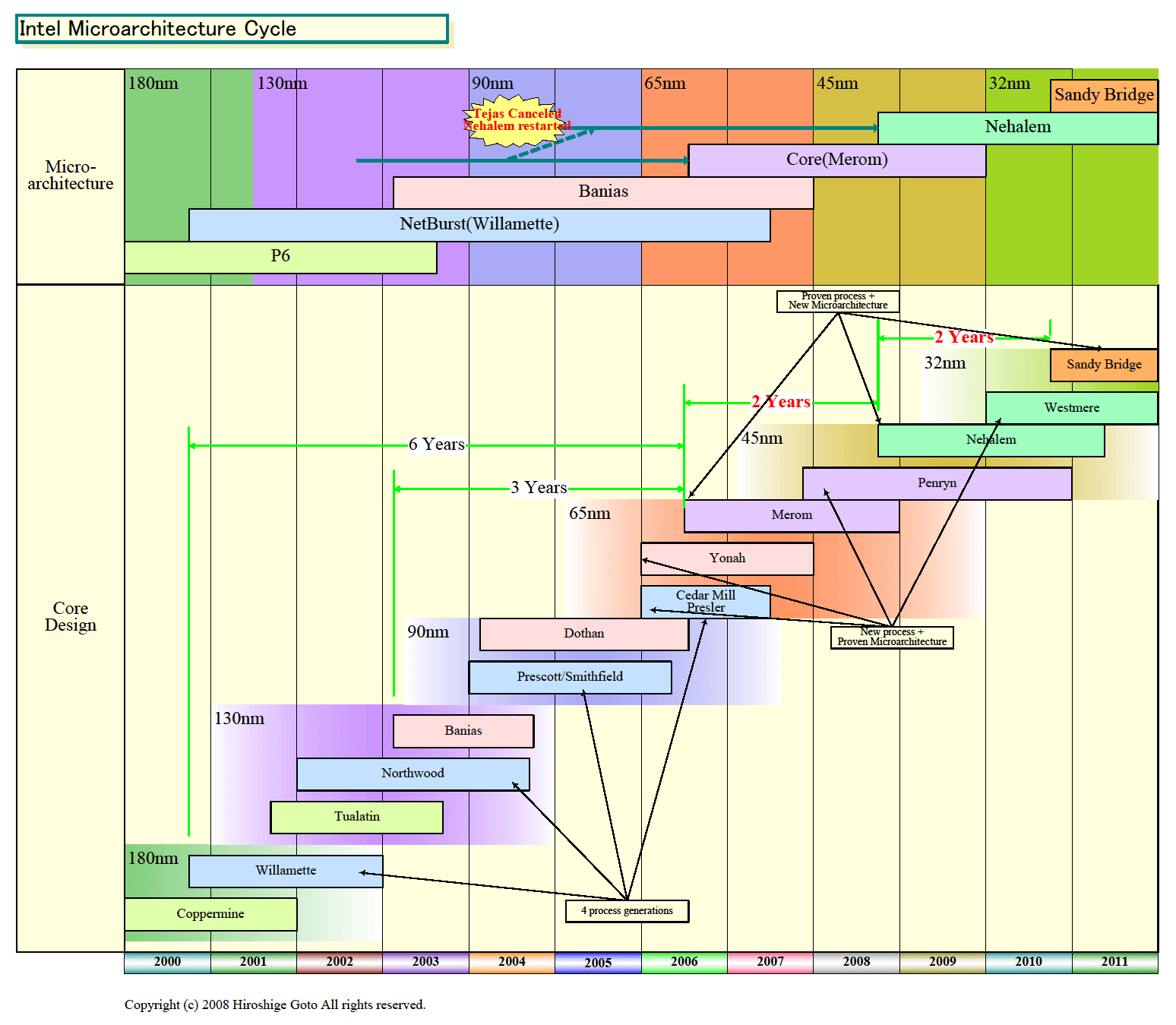 |
| CPUアーキテクチャのサイクル
PDF版はこちら |
●x86 CPUコアの肥大化がもたらす弊害
NehalemがCore MAをベースとしたことは、x86 CPU開発について重要なポイントを示唆している。1つは、CPU開発が、ますます時間と労力のかかるものになって来ているという点。もう1つは、CPU開発の焦点が、シングルスレッドの整数演算性能を向上させるためのマイクロアーキテクチャの拡張より、マルチスレッドと浮動小数点演算の性能の向上と、そのために必要なI/Oとメモリの拡張に焦点が移っていることだ。
ヒルズボロがNehalem開発に当たってCore MAをベースとしたのは、そうしなければ4年程度でCPUを開発することができないという事情があったと推定される。うまく働くマイクロアーキテクチャを開発するには、膨大な時間と労力が必要であり、開発期間も読めない。Core MAがうまくできていて高パフォーマンスを達成しているのなら、それを利用した方が得策と判断したと推測される。
特に、x86 CPUの場合は、レガシーが多く、CPU設計が複雑化しているため、1つのマイクロアーキテクチャを開発するのに時間がかかる。この問題は、IntelでPentium III/4などのメインアーキテクトを務めたBob Colwell(ボブ・コールウエル)氏が、2004年に米スタンフォード大学で行なった講演「Things CPU Architects Need To Think About」で指摘している。
Colwell氏によると、x86 CPUは、レガシーアーキテクチャを引きずったまま無理な拡張を重ねた結果、アーキテクチャ上の脆弱性が増しているという。例えば、正確なパフォーマンス分析ができる段階になって問題が発見されても、設計が進みすぎていて本質的な修正ができない。そのため、小手先の修正を加えるが、複雑さの上に複雑さを重ねることになり、別な問題を招いてしまい、泥沼状態となって開発が難航するという。
こうした背景を考えると、うまく働くマイクロアーキテクチャがあるなら、それを改良した方が効率的となる。下手に新しいマイクロアーキテクチャをゼロから作ろうとして開発段階でつまずく危険を冒すより、証明されたマイクロアーキテクチャを取る方が安全だ。そのため、最近ではCPUマイクロアーキテクチャの寿命は長くなりつつある。ベースとなるアイデアが同じで、インクリメンタルに拡張を加えて行くパターンとなる。AMDも、Phenom世代でK8マイクロアーキテクチャの基本は保ったまま拡張している。
これまで、CPUコアのマイクロアーキテクチャを刷新する原動力は、シングルスレッドの、特に整数演算性能の向上だった。しかし、コアマイクロアーキテクチャの改良によるシングルスレッド整数演算性能の向上カーブは鈍化している。現状では、そのために割かなければならないリソースを考えると、パフォーマンス/消費電力的に見合わなくなっているという。コンピュータ科学の研究者として有名なDavid A. Patterson(デヴィッド・A・パターソン)教授(University of California at Berkeley)は、カンファレンスや共著書「Computer Architecture Forth Edition」の中で、CPUがILPの壁「ILPウォール(ILP Wall)」に当たっていることを強調している。
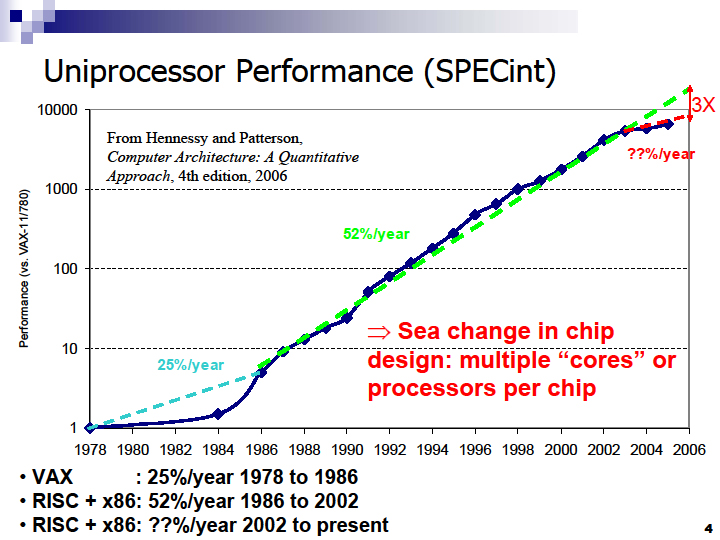 |
| Uniprocessorのパフォーマンスの向上 |
 |
| コンピューターのアーキテクチャにおける常識 |
それに対して、マルチコア&マルチスレッド化によるマルチスレッド&マルチタスク性能の向上と、浮動小数点演算の向上には、まだいくらでも余裕がある。また、現在のCPUでは、ボトルネックはCPUコアの中よりも外、メモリ階層とI/Oにあり、そちらを改良した方が性能に与えるインパクトが大きい。そのため、Nehalemでも、CPUコアの拡張のポイントの多くはマルチスレッド性能や、ノースブリッジ(GMCH)統合化によるメモリ性能の向上にスポットが当てられている。消費電力を抑えながら、オーバーオールの性能を上げるには、その方が効率的だからだ。おそらく、これは、今後のCPUのトレンドとなって行くだろう。
□関連記事
【3月21日】【海外】モバイルにもL3キャッシュをもたらすNehalem
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
(2008年3月28日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.