 |


■後藤弘茂のWeekly海外ニュース■SilverthorneのパフォーマンスはDothan以上 |
●小さなCPUコアを高速に回すのがSilverthorneのアイデア
Intelの超低消費電力CPU「Silverthorne(シルバーソーン)」のターゲットは明瞭だ。ScorpionのようなARM系の高パフォーマンスCPUより高いパフォーマンスレンジを、リーズナブルなパフォーマンス/消費電力で実現する。それによって、PCと携帯電話の狭間にあるUMPC(Ultra Mobile PC)やMID(Mobile Internet Device)といったモバイル機器のCPU(携帯電話側の表現ではアプリケーションプロセッサ)の座を得ることだ。Silverthorneを含む「LPIA(Low Power Intel Architecture)」系CPUと、その派生プロセッサ群は、このほかにもさまざまな市場をターゲットにしている。しかし、主戦場である携帯デバイスでは、ARMが仮想敵だ。
そこで、IntelはSilverthorneの設計で重視したことは、PC向けCPUのローエンドに位置するLPIA版と同等以上のパフォーマンスを、より低いTDP(Thermal Design Power:熱設計消費電力)と平均消費電力で実現することだった。PC向けCPUのLPIA版では、トランジスタ数の多いファットなCPUコアを低電圧で低周波数で動作させている。対するSilverthorneの基本的な発想は、トランジスタ数の少ないCPUコアを低電圧のまま、組み込みCPUとしては高い周波数で動作させ、その結果としてPC向けCPUよりはるかに高いパフォーマンス/消費電力を実現することだ。Silverthorneは1.86GHzで市場に登場する予定だ。1.86GHzはPC向け通常電圧版CPUと比較すると低い。しかし、1GHz以下駆動がほとんどの携帯機器組み込みプロセッサの中では非常に高い。
Intelは、現在、LPIAとして90nmプロセス版Pentium M「Dothan(ドタン)」をベースにした「A100/A110(Stealey:スティーリィ)」を提供している。Stealeyは、Dothanを600~800MHzで動作させ、TDPを3Wにまで落とした(従来のULV(超低電圧)版Pentium Mは5.5Wが下限)。Intelは、以前からSilverthorneのパフォーマンスレベルが、Stealeyと同等かそれ以上になると説明していた。2月3日~7日(米国時間)にかけてサンフランシスコで開催された「ISSCC(IEEE International Solid-State Circuits Conference) 2008」で明らかになったSilverthorneのアーキテクチャを概観すると、どうやってこの性能レベルを達成するのか、その謎の一部が解けてくる。
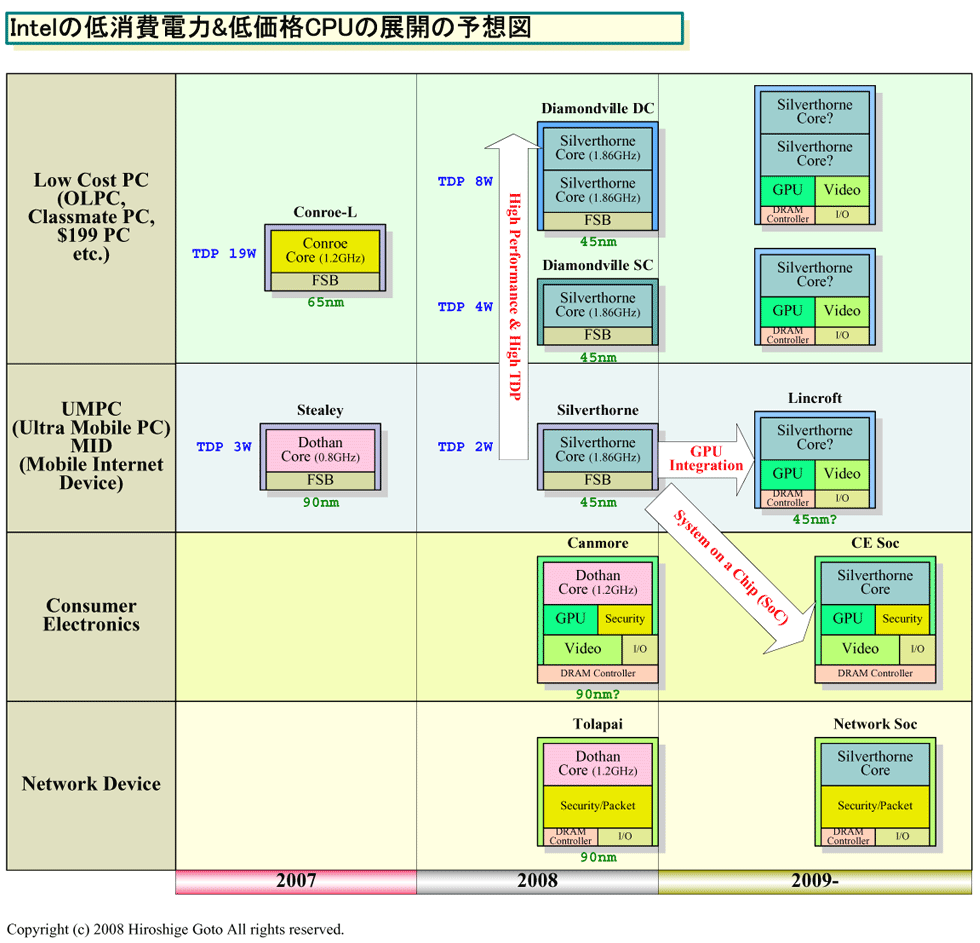 |
| Silverthorneの派生 (※別ウィンドウで開きます) PDF版はこちら |
●DothanベースのStealeyと同等以上のパフォーマンス
Intelは顧客に対して、Silverthorne 1.86GHzのパフォーマンスをStealey 800MHzと較べた場合、シングルスレッド時には10%程度高く、マルチスレッドでは最大40%も高くなると説明しているという。これは、整数演算と浮動小数点演算の両方について言えるという。
簡単に言えば、SilverthorneはPC向けCPUの1/2の規模のCPUコアを、2倍以上の周波数で動作させることで、ほぼ同等のシングルスレッド性能を達成している。小さなCPUコアを速く動かしてパフォーマンスを上げる発想だ。加えて、ハードウェアマルチスレッディングにより、マルチスレッド性能をブーストしている。マルチスレッドでパフォーマンスを稼ぐ、どちらかと言うとメディアアプリケーションに向いた設計のCPUだ。
ちなみに、IntelはSilverthorneのCPUコアが、Core Microarchitecture(Core MA)の1/4の規模だとISSCC時に説明しているが、ダイ面積を比較すると1/2程度だ。トランジスタ数を考えてもCore MAのCPUコアは19M(1,900万)なので、その1/2の10M(1,000万)程度がSilverthorneコアとして妥当なサイズだろう。10Mを切ると、CPUコアの規模としてはかなり難しくなる。そのため、IntelがCore MAに対してSilverthorneのCPUコアが1/4と説明しているのは、デュアルコアCPUに対しての比率だと推定される。いずれにせよ、Silverthorneのコアが、PC向けCPUより格段に小さいことだけは確かだ。
理由は明瞭で、小さくシンプルなCPUコアの方が電力効率が高いからだ。CPU設計の有名な経験則に、同じプロセス技術でシングルコアCPUのダイサイズ(=トランジスタ数)を2~3倍に増やしても、整数演算パフォーマンスはその平方根(約1.4~1.7倍)程度にしか伸びないというものがある。Intelはこれを『ポラックの法則(Pollack's Rule)』(LawではなくRule)と呼んでいる。この法則に従うと、CPUコアがCore MAの1/2の規模のSilverthorneは、整数演算パフォーマンスは0.7倍に下がる。しかし、CPUコア部分の消費電力は半分の0.5倍に下がるため、パフォーマンス/消費電力とパフォーマンス/ダイは1.4倍に上がることになる。
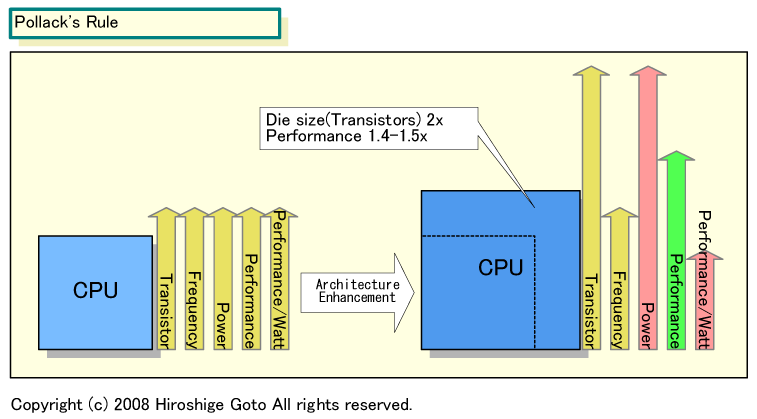 |
| ポラックの法則 (※別ウィンドウで開きます) |
では、絶対パフォーマンスの低下分は、どうカバーするのか。それは周波数の向上で補うというのが、Intelの戦略だ。無理なく周波数を引き上げることで、電力効率を落とさずにパフォーマンスをアップさせ、PC向けCPUのLPIA版と同レベルに持って行くという発想と思われる。
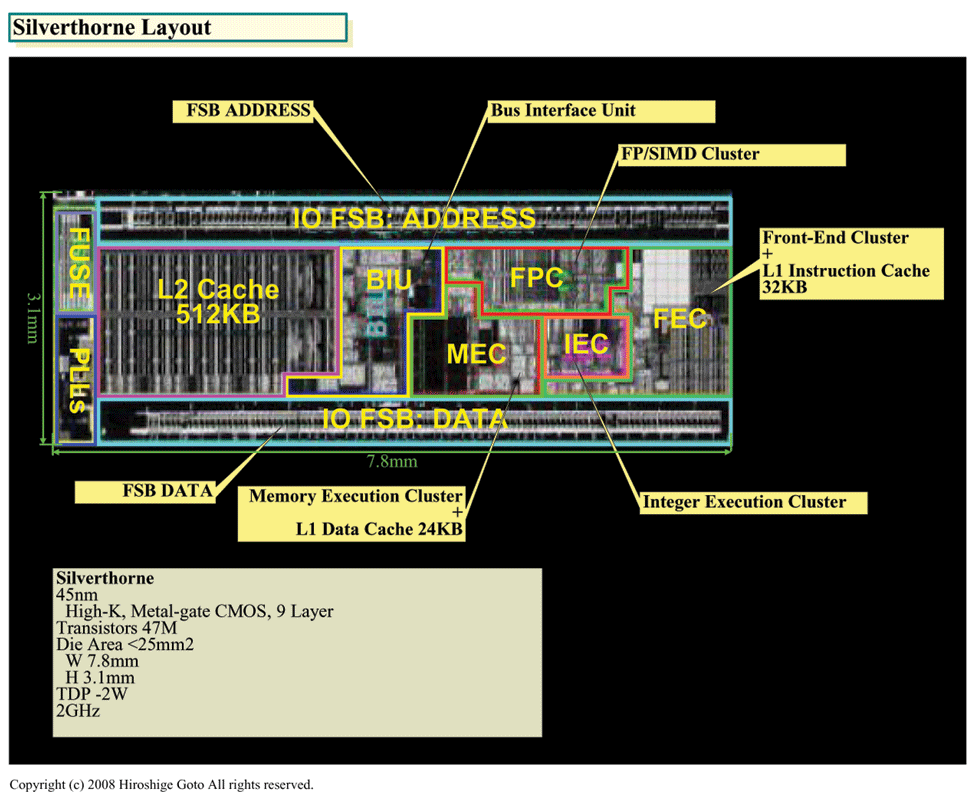 |
| Silverthorneレイアウト (※別ウィンドウで開きます) PDF版はこちら |
●マルチスレッディングでパフォーマンスが向上
ちなみに、IntelがSilverthorneで、シングルスレッド性能を上げることにトランジスタを費やさず、マルチスレッド性能向上に振り向けたのも、同じ電力効率性の理由からだ。シングルスレッド性能を上げようとすると、費やすトランジスタ数当たりのパフォーマンス向上の幅が小さい。つまり効率が悪い。それに対して、マルチスレッド性能を上げる方が、電力効率は良くなる。
特に、Silverthorneの場合は、マルチスレッディングによって実行パイプを埋められるという利点がある。Silverthorneのマイクロアーキテクチャは、デュアルイシューでインオーダ実行だ。命令ユニットは2命令を同時に実行ユニット群に対して発行(イシュー)できる。実行パイプラインも、整数演算系と浮動小数点演算系それぞれに2本ずつ用意されている。
この構成の場合、シングルスレッド実行だと、連続する命令同士に依存性がなく、リソースも競合しない場合しか並列に実行できない。それに対して、Silverthorneは、実行ユニット群に対して2命令を発行する際に、スレッドスケジューリングを行なっている。発行する2命令を、1つのスレッドから選ぶことも、2つのスレッドから1命令ずつ選ぶこともできる。
そのため、例えば、1スレッドから1命令しか発行できない場合、もう1つの命令発行スロットに、もう1つのスレッドの命令を発行できると推測される。Silverthorneでは、シングルスレッド実行ではCPUリソースがムダに空いてしまうサイクルを、2スレッド実行によって埋めることができる。マルチスレッディングは、メモリレイテンシの隠蔽にも効果がある。しかし、SMT(Simultaneous Multithreading)であるSilverthorneのマルチスレッディングの場合は、パイプラインの充填も重要な要素だ。
IntelのISSCCの論文によると、Silverthorneのマルチスレッディングは、電力を15%増したが、パフォーマンスは約30%もブーストされたという。この数値のままなら、マルチスレッド化によって、パフォーマンス/消費電力がさらに向上したことになる。
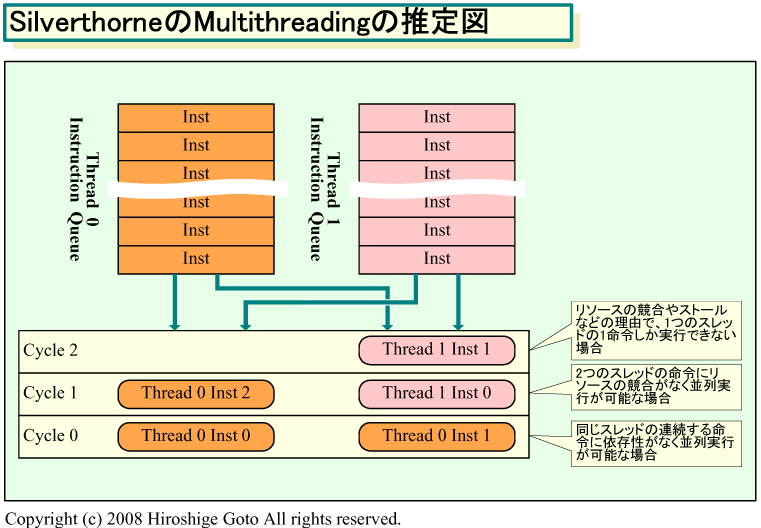 |
| Silverthorneのマルチスレッディングの推定図 (※別ウィンドウで開きます) |
●浮動小数点演算の伸びを考慮したマイクロアーキテクチャ
小さなCPUコアを速く動かす。Silverthorneの設計のこの特徴は、さまざまなことを示唆している。まず明瞭なことは、Intelが携帯機器でも、将来は浮動小数点演算パフォーマンスが重要となると考えていること。
一般論では、インオーダ実行でパイプライン段数を増やすと、動作周波数は上がるが、整数演算性能が相対的に上がりにくくなる。分岐予測ミスのペナルティが大きくなり、動作周波数が上がる分だけメモリロード待ちでストールするサイクルも増えるからだ。もちろん、マルチスレッド化によってメモリロード待ちのストールによるムダは、ある程度カバーされる。しかし、シングルスレッドの整数演算性能は上がらない。
一方、パイプラインの深化によって、浮動小数点演算のパフォーマンスは上がりやすくなる。分岐の少ない浮動小数点演算中心のコードは、データさえ順調にフィードされていれば、周波数の向上に応じて性能が上がるからだ。この原則に従うとSilverthorneは、浮動小数点演算を重視した設計ということになる。
もっとも、実際には、Silverthorneの整数演算と浮動小数点演算の性能は、それぞれStealeyをちょっと超えた程度。特に浮動小数点演算が伸びているわけではない。その理由は、Silverthorneでは、コストの高い(=トランジスタ数を食う)浮動小数点演算ユニットの設計を抑えているためだと推定される。小さくて比較的低性能な浮動小数点演算ユニットを速く回すことで、Stealeyと同レベルの浮動小数点演算性能を得ていると考えればつじつまが合う。
だが、Silverthorneの基本設計が、高周波数であることは、将来的な拡張の可能性を示唆している。将来の発展系CPUコアで、浮動小数点演算ユニットを強化した場合には、周波数の高いSilverthorneの基本アーキテクチャのおかげで、パフォーマンスが大きく伸びるだろう。
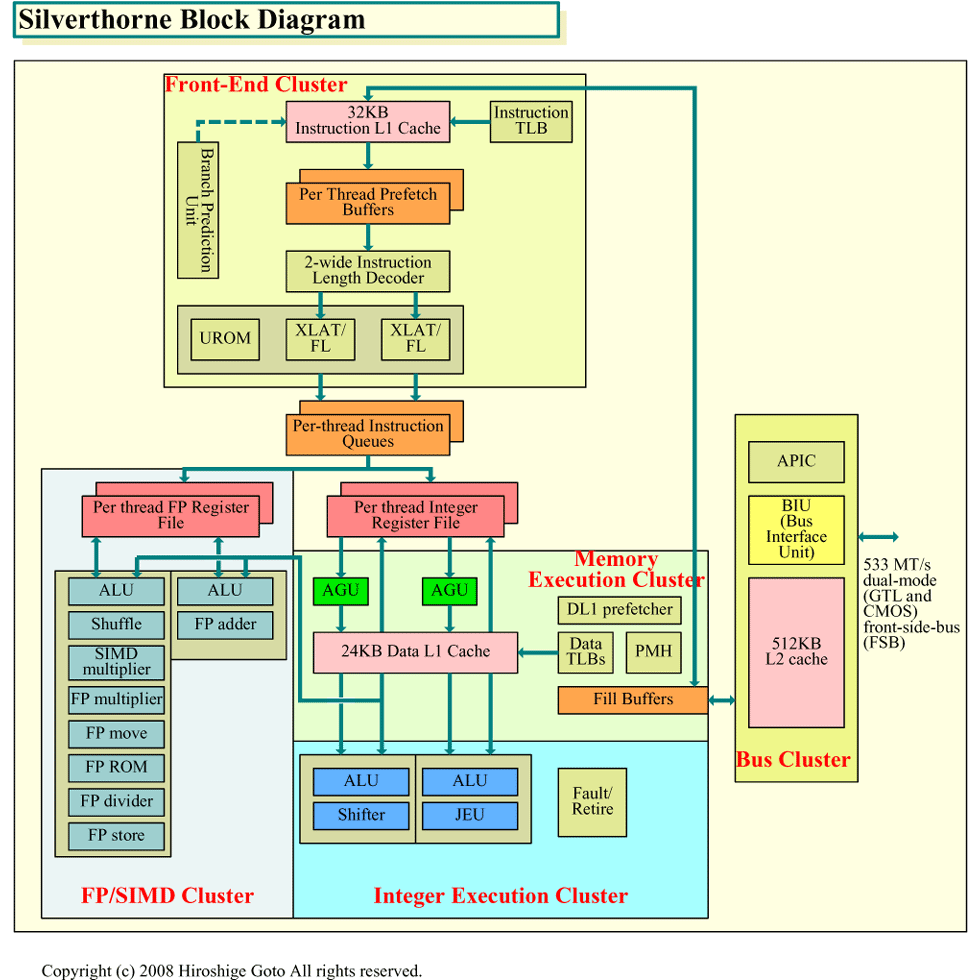 |
| Silverthorneのブロックダイヤグラム (※別ウィンドウで開きます) PDF版はこちら |
●低速だが電力消費の小さなトランジスタを採用
Silverthorneは、1サイクル実行で可能な限り高い周波数を狙うパイプライン構成となっている。パイプラインは16ステージで、Pentium M系の13ステージより長く見えるが、SilverthorneのパイプラインにはL1データキャッシュアクセスの3ステージが挟み込まれている。
データキャッシュアクセスを加えたのは、x86の「Load-Op-Store(ロード-実行-ストア)」型オペレーションをそのまま実行することに最適化しているためだ。実行ステージの前にデータロードを挟み込んだ構成とすることで、データロード待ちのストールをなくす。
このアプローチは、x86系のCPUでは比較的ポピュラーで、Centaur Technologyの「C7」や、古くはCyrixの「6x86」もこの手法を採っていた。キャッシュアクセス以外のパイプライン段数は、SilverthorneもPentium Mも変わらない。しかし、インオーダ実行のSilverthorneの方が、よりシンプルであり、各ステージのロジックが少なくて済む。つまり、Core MAやPentium Mと較べると、Silverthorneはパイプラインの全長で必要なゲート数が少ない。それを同じ程度のステージに切っているため、Silverthorneは無理なく高周波数化できる。
この無理なくというポイントは重要だ。例えば、Silverthorneは、45nmプロセスでも、PC向けCPUとはトランジスタがちょっと異なっている。PC向けCPUは、高速化のためにクリティカルパスなどには、チャネル長が短く高速だがリーク電流(Leakage)がやや多いトランジスタを使う。それに対して、Silverthorneでは、全てのトランジスタが、チャネル長が長く低速だがリーク電流が小さなタイプになっているという。
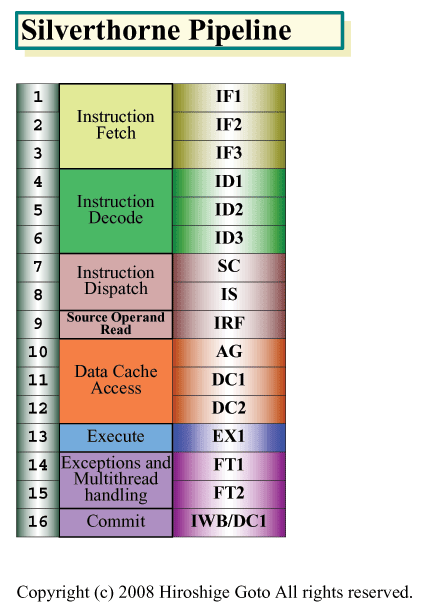 |
| Silverthorneパイプライン PDF版はこちら |
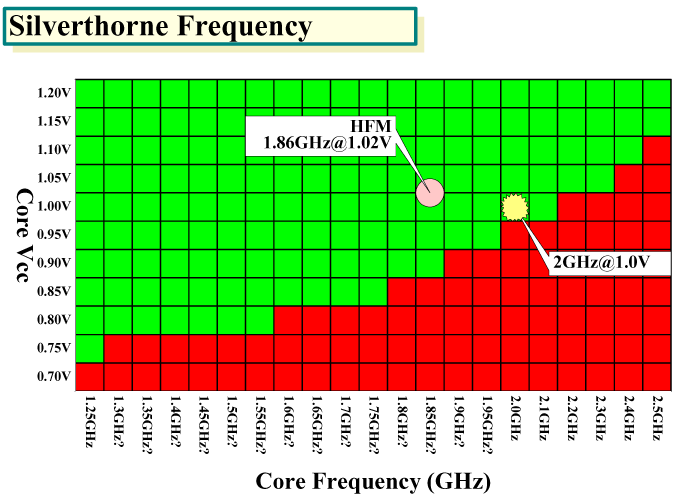 |
| Silverthorneの動作周波数 (※別ウィンドウで開きます) |
Silverthorneでは、トランジスタを高速にしなくても、低い電力と電圧で、そこそこの高周波数を達成できる。そのため、CPUコアが小さく、命令の並列性が低くても、一定のTDP枠の中でなら、PC向けCPUを上回るパフォーマンスを達成できる。それが、Silverthorneマイクロアーキテクチャの特徴だ。
□関連記事
【2月7日】【海外】これが超低消費電力「Silverthorne」の正体だ
http://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
【2月4日】【海外】IntelがいよいよSilverthorneとTukwilaの概要を発表へ
http://pc.watch.impress.co.jp/docs/2008/0204/kaigai415.htm
【2007年5月10日】【海外】デスクトップCPUと同じ仕様を載せた「Silverthorne」
http://pc.watch.impress.co.jp/docs/2007/0510/kaigai357.htm
(2008年2月18日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.