 |


■後藤弘茂のWeekly海外ニュース■MIMDのLarrabeeとSIMDのGPUの戦い |
●MIMD構成でキャッシュ階層を備えるLarrabee
 |
| Justin R. Rattner(ジャスティン・R・ラトナー)氏 |
Intelは、メニイコアタイプの高スループットプロセッサである「Larrabee(ララビー)」で、個々のプロセッサコアが個別の命令を実行するMIMD(Multiple Instruction, Multiple Data)型の構成を採用する。「LarrabeeはMIMDマシンであり、コンベンショナルなキャッシュ階層を持つ。この2点がGPUと異なる」とIntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Senior Fellow, Corporate Technology Group兼CTO, Intel)は語る。
それに対して、現在のGPUのほとんどは、多くのシェーダプロセッサコアをバンドルして、1個の命令ユニットで制御するラージSIMD(Single Instruction, Multiple Data)型の構成を取っている。SIMD構成されるシェーダプロセッサの数は4から多い場合には数十コアにのぼる。現在のユニファイドシェーダ型GPUは、NVIDIAとAMD(旧ATI)のどちらもラージSIMDマシンとなっている。
そのため、アーキテクチャ上の構図としては、SIMD GPU対MIMD Larrabeeの戦いとなる。これは、ハイパフォーマンスコンピューティング(HPC)の世界で繰り広げられた、SIMD(ベクタ)と、MIMD(マルチプロセッサ)のどちらのアプローチが優れているかの論争を彷彿とさせる。システムレベルのSIMD対MIMDの構図が、今度はオンチップレベルで繰り返されるわけだ。
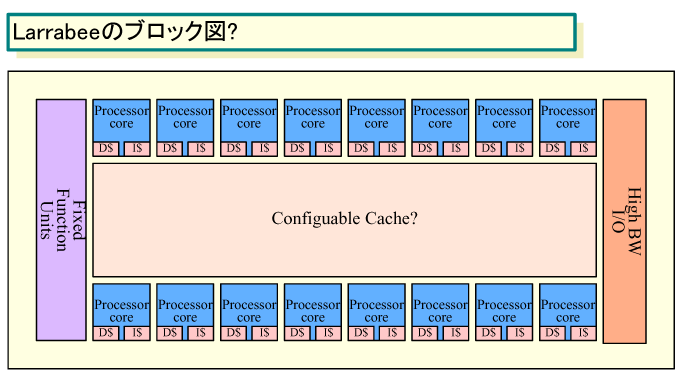 |
| Larrabeeのブロック図? (別ウィンドウで開きます) ※PDF版はこちら |
 |
| IAのプログラム性と並列性により高スループットコンピューティングをもたらす |
SIMDとMIMD、両アプローチにはそれぞれ利点と難点がある。一般に、MIMD型の方が柔軟性が高いが、SIMD型の方がベクタ演算のため効率が高い。SIMDの場合は、プロセッサの制御が容易になるため、トランジスタ数当たりの理論上のパフォーマンスを高くしやすい。しかし、MIMDなら、大きなベクタに構成することが難しいタスクも効率的にこなすことができる。各スレッドがタイトに同期している場合はSIMDの方が有利だが、逆に命令フローが条件分岐などで異なるパスに分かれる場合にはMIMDの方が効率的になる。SIMDの場合は、ベクタの中で分岐パスが異なる場合には、両方のパスを実行するなどのムダが生じてしまうからだ。
プログラミング面では、SIMD GPUでは演算アレイの実際のベクタ長が隠蔽されていて、自動的にセットアップソフトウェアによってベクタ化が行なわれるため、プログラマ側がベクタ長を意識する必要がない。プログラムを書く側は、1つのデータエレメントのためのプログラムを書くと、自動的に多数のデータエレメントに対して並列化される。だが、その反面、ランタイムソフトウェアによるセットアップに膨大な時間かかってしまう。
グラフィックス処理では、データ間の処理に依存性がなく、膨大な演算性能が求められるため自然とラージSIMDへと向かった。それに対して、Larrabeeでは、グラフィックスのようなデータ並列処理もMIMD上で行なうが、より柔軟に多様な処理をカバーすることを目指すためにMIMDを採用したと見られる。もっとも、Larrabeeも、MIMD構成の各プロセッサコアの中は、比較的ショートなSIMDの構成となっていると見られる。
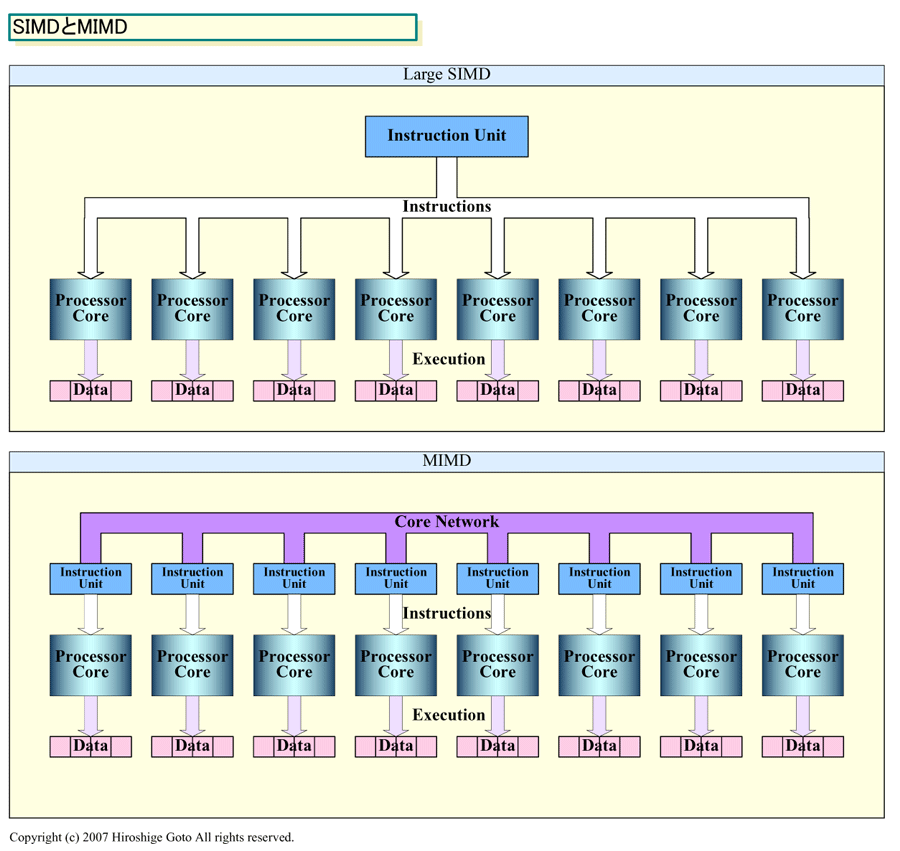 |
| SIMDとMIMD (別ウィンドウで開きます) ※PDF版はこちら |
ちなみに、Intelの場合は統合GPUコアもMIMD型だ。Intel Technology Journal(Volume 11 Issue 03)の記事「Accelerator Exoskeleton」を見ると、8個のEUが独立した構造になっており、さらに各コアの4way SIMDユニットが4ハードウェアスレッドコンテクストをサポートする構造となっている。柔軟性を第一に考える思想はGPUコアにも共通していると見られる。
また、GPUも、リード&ライト可能なローカルメモリを持つようになり始めたが、CPUのような一貫性と柔軟性のあるキャッシュメモリではない。こうした点を見ると、Larrabeeが目指しているのは、GPUの難点をカバーできるアプローチのようだ。ある意味で、GPUの弱点である部分を突いたのがLarrabeeと言えるかもしれない。
●似て非なるLarrabeeとFUSIONのアプローチ
 |
| Stephen L. Smith(スティーブ・L・スミス)氏 |
Intelは、LarrabeeのMIMD構成のプロセッサコアが、IA(x86系)命令セットと互換性を持つと説明している。IntelのStephen L. Smith(スティーブ・L・スミス)氏(Vice President, Director, Digital Enterprise Group Operations, Intel)は、「Larrabeeでは、我々は、世界の全てのデベロッパがプログラムの書き方を知っているIA(x86系命令セットアーキテクチャ)の利点を生かすことが、よりよいソリューションだと判断した。より柔軟で、プログラムの書き方を簡単に理解できて、業界のインフラを利用できるアーキテクチャを実現するつもりだ」と語る。高スループットのプロセッサに、IA命令セットを実装しようというのがLarrabeeのアイデアだ。
 |
| 利点増加と混乱の減少 |
それに対して、AMDも、GPUリソースをCPU側の命令セットからも利用できるようにするという。具体的には、AMDが発表したSSE5命令の一部は、CPUコアではなく、GPUコアに発行されて実行されるようになる。GPU自体にはx86系命令セットは実装しないが、x86系CPUコアから命令レベルでGPUコアにアクセスできるようにする。GPUコアに対しては、従来通りのドライバモデルでのアクセスも可能に保つ。
また、AMDは、ラージSIMDのGPUコアをそのまま汎用に使おうとは考えていない。最初のFUSIONはともかく、将来のFUSIONではGPUの演算リソースを、より小さなベクタに分解して行く。実際には、FUSIONのベクタ長はLarrabeeと同程度になるかもしれない。SIMDとMIMDの間での、最適なバランスを取ると、最終的には同じ結果になる可能性も高い。
こうして見ると、両者のアプローチは似たように見えるが、大きな違いがある。IntelのRattner氏は次のように説明する。
「我々が望んでいるのは、Intelアーキテクチャ(IA)の力でグラフィックスプログラミングを実現することだ。しかし、IAと言っても、データ並列アーキテクチャのパフォーマンスを実現する点に、Larrabeeのアーキテクチャ上の新しさがある。
どうやってIA互換性を維持しながら、(データ並列アーキテクチャの)パフォーマンスを実現するか。その点についての基本的なアプローチに、我々とAMD/ATIとの違いがある。簡単に言えば、彼らは、CPU+GPUワールドを目指している。我々はCPUワールドに、膨大な浮動小数点演算機能を加えることを目指している」
つまり、AMDはGPUを、GPUとしての特性をできるだけ保持したまま、CPU側からうまく利用できるようにしようとしている。CPUにとってのサブプロセッサユニットであるGPUコア自体にIA命令セットは実装しない。考え方としてはコプロセッサに近い。それに対して、IntelはLarrabeeをCPUの進化形の1つと見なしている。IA CPUの進化形の1つとしてLarrabeeを捉えているため、LarrabeeプロセッサコアをIA命令セットベースにする。
●Larrabeeが次の大きな命令セット拡張
もちろん、Larrabeeでは命令セット自体も拡張する。少なくともIntelのDigital Enterprise Groupは、LarrabeeをIA命令セットの次のレベルの拡張と見なしている。Patrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)は、次のように語る。
「我々は、命令セットモデルは、アーキテクチャアプローチの本質的な部分であり一貫する必要があると考えている。Cell B.E.を始めとしたアプローチが成功していないのは、それらが命令セットの拡張に対する一貫した考え方を持っていないためだと考えている。
我々は、将来にわたって、命令セットをさらに拡張し続けることができると見ている。SSE4を発表したが、それ以降のSSEの定義も進めている。さらに、より大きな命令セットの拡張も、Larrabeeの一部として進めている。つまり、ILP(Instruction-Level Parallelism)を高めるだけでなく、新命令セットモデルにより、ベクタレベルの並列性を高めてゆく。来年(2008年)には、命令セットについてもっと詳細を明らかにできるだろう」
1つの命令セットアーキテクチャを、一貫して拡張して行く。それが、IA CPUのアーキテクトだったGelsinger氏の基本的なフィロソフィであり、今のIntelのCPU戦略の基本となっている。IA(x86系)でカバーできない領域は、IA-64が存在するが、少なくともメインストリームはIAでカバーし続ける。Larrabeeのような、大きな命令セットの革新も、その枠内に収めるというビジョンのようだ。
Cell B.E.を引き合いに出しているのは、もちろん、Cell B.E.のSPE(Synergistic Processor Element)の命令セットがPower準拠ではなく、独自の命令セットであるからだ。既存のPowerを継承発展させなかったこと、特殊なプログラミングモデルを採ったことが、Intelの視点からすると間違いだと指摘しているわけだ。もちろん、これはトレードオフで、既存の命令セットを継承する限り、制約も生じる。
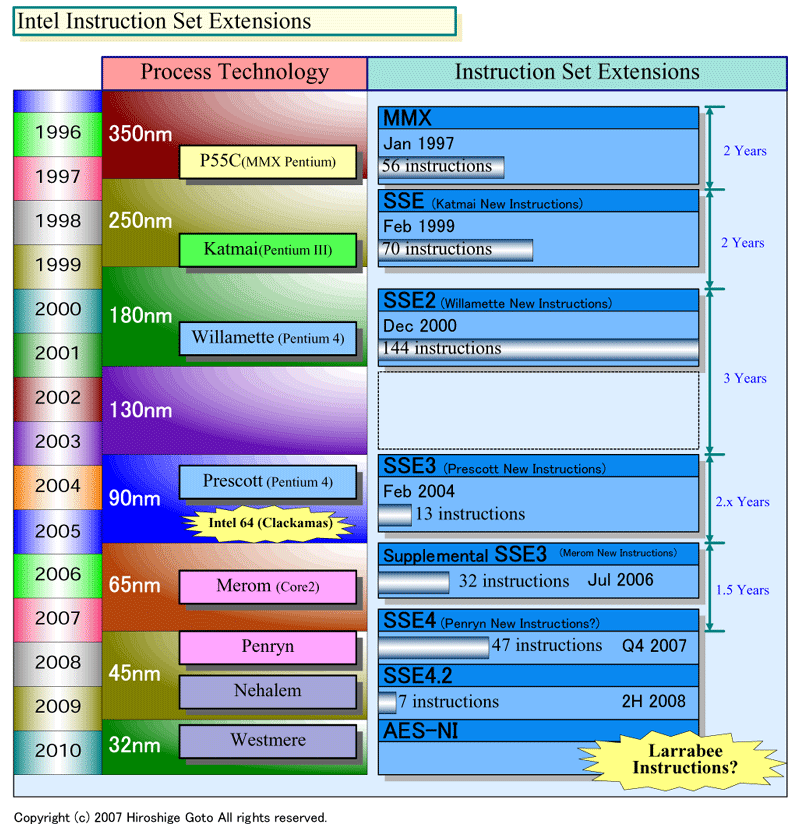 |
| Intel Extruction Set Extensions (別ウィンドウで開きます) ※PDF版はこちら |
●グラフィックス向けに投入される最初のLarrabee
IA命令セットでハイスループットコンピューティングを実現するLarrabee。しかし、Intelの、Larrabee計画の軸がしっかり定まっているかというと、そうでもない。一例を挙げれば、Intelは最初はLarrabeeをハイパフォーマンスコンピューティング(HPC)などの分野に投入すると言われていた。そのため、試験版を最初に少量出荷するという計画だった。しかし、現在のLarrabeeは、グラフィックスにフォーカスする計画へと変更されている。
「Larrabeeは、広いレンジのコンピューティング問題を狙っている。スループットコンピューティング、ビジュアライゼーション、財務分析、HPCなどだ。しかし、今回発表したのは、最初の製品はグラフィックスになるということだ。ゴールは広いレンジのワークロードをカバーする製品群だが、最初の製品はグラフィックスだ」(Gelsinger氏)
この計画では、Larrabeeは、まず、NVIDIAやAMD/ATIのGPUと真っ向からぶつかることになる。グラフィックスにフォーカスしてアーキテクチャを最適化したGPUと、グラフィックスでぶつかることはリスキーに見える。単純にグラフィックスだけを処理するなら、ラージSIMD型の方が、トランジスタ数当たりの効率が良くなる可能性が高いからだ。
そのため、Intelは戦略的に、Larrabeeではグラフィックスプラスアルファを謳うと推測される。そこで符合するのは、Intelによる物理シミュレーションソフトウェアエンジンメーカーのHAVOKの買収だ。Intelが、物理シミュレーションなども効率的に実行できるハードとしてLarrabeeを押し出すとすれば、この買収も符合する。ただし、HAVOK自体は、Larrabeeのような高スレッド並列ハードウェアに向けた実装は得意ではないと言われる。
こうして全体を見ると、Intelにとって、グラフィックス用途のGPUコアの統合は最初のステップで、CPUとしての拡張を主眼に考えていることがよくわかる。そして、CPUとしての命令セット拡張の流れの上にLarrabeeがある。自然な流れとしては、将来的にはGPUコアではなく、Larrabee型のプロセッサコア群をCPUに統合し、グラフィックスタスクもそれにやらせることになるだろう。
しかし、Intelのこの戦略がうまく行くのかどうかは、まだわからない。ハイスループットプロセッサコアにIA命令セットを実装することの是非については、まだ結論が出ていない。プログラムしやすさによって犠牲になる部分が大きいと予想されるからだ。試金石は、最初のディスクリートLarrabeeとなるだろう。
□関連記事
【10月11日】【海外】Intel NehalemとAMD FUSION 両社のCPU+GPU統合の違い
http://pc.watch.impress.co.jp/docs/2007/1011/kaigai392.htm
【10月5日】【海外】Intelが目指すNehalemでのGPUとCPUの統合
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
【6月18日】【海外】IntelのLarrabeeに対抗するAMDとNVIDIA
http://pc.watch.impress.co.jp/docs/2007/0618/kaigai365.htm
【6月11日】【海外】Intelが進める、32コアCPU「Larrabee」
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
【2月28日】【海外】GPU命令のx86体系への統合
http://pc.watch.impress.co.jp/docs/2007/0228/kaigai341.htm
(2007年10月12日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.