 |


■後藤弘茂のWeekly海外ニュース■Intel NehalemとAMD FUSION
|
●CPUに統合するGPUコアを汎用には使わないIntel
Intelは、Nehalem世代のCPUにGPUコアを統合する。統合するGPUコアは、Intelの内蔵グラフィックスになると推測される。Intelが高スループットコンピューティング向けに開発している「Larrabee(ララビー)」は、少なくとも最初のフェイズでは統合しない。
Intelの内蔵グラフィックスは、ハードウェア的にはユニファイドシェーダ構成となっており、実際にはDirectX 10もサポートが可能だ。G965系の「GMA X3000」は8個のプログラマブルな汎用シェーダプロセッサコア「Execution Units (EU)」で構成されていた。
G965は90nmプロセスで128平方mmのダイ(半導体本体)だった。このうち70%程度をGPUコアが占めていたとすると、45nmプロセスではおそらく20~30平方mm程度のサイズに縮小するはずだ。もしかすると、EUの個数をさらに増やすかもしれない。実際、2008年のデスクトップチップセット「EagleLake(イーグルレイク)」では、EUの個数は10個になる。CPUへの統合時にも、バランス的には、10数個のEUを搭載すると考えるのが自然だろう。コア周波数も引き上げることが可能なはずで、理論上のGPUコアパフォーマンスは現行より上がるだろう。
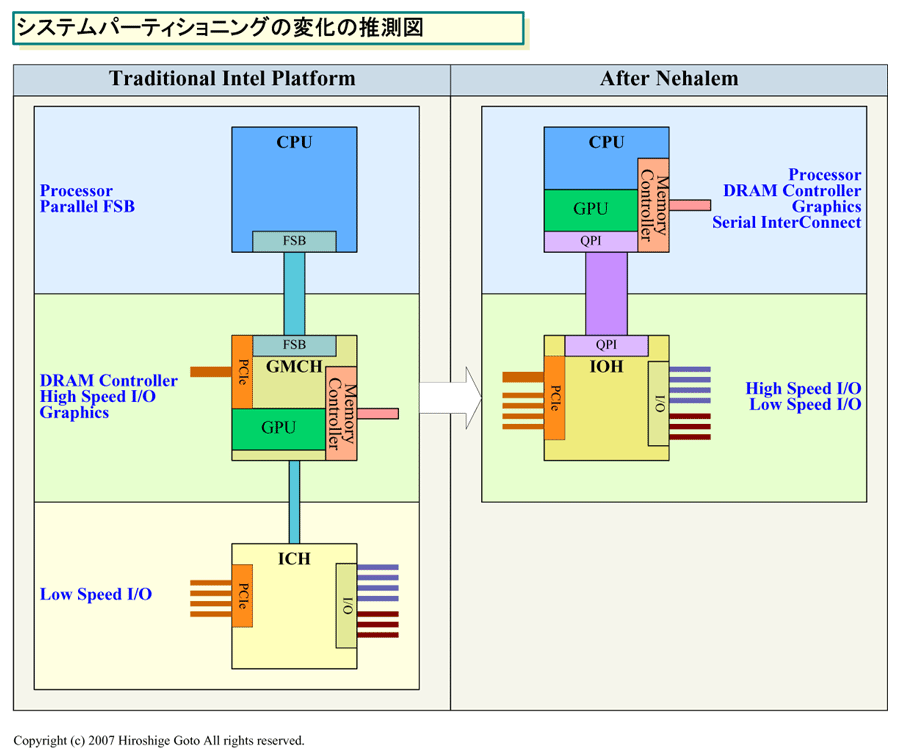 |
| システムパーティショニングの変化の推測図 (別ウィンドウで開きます) ※PDF版はこちら |
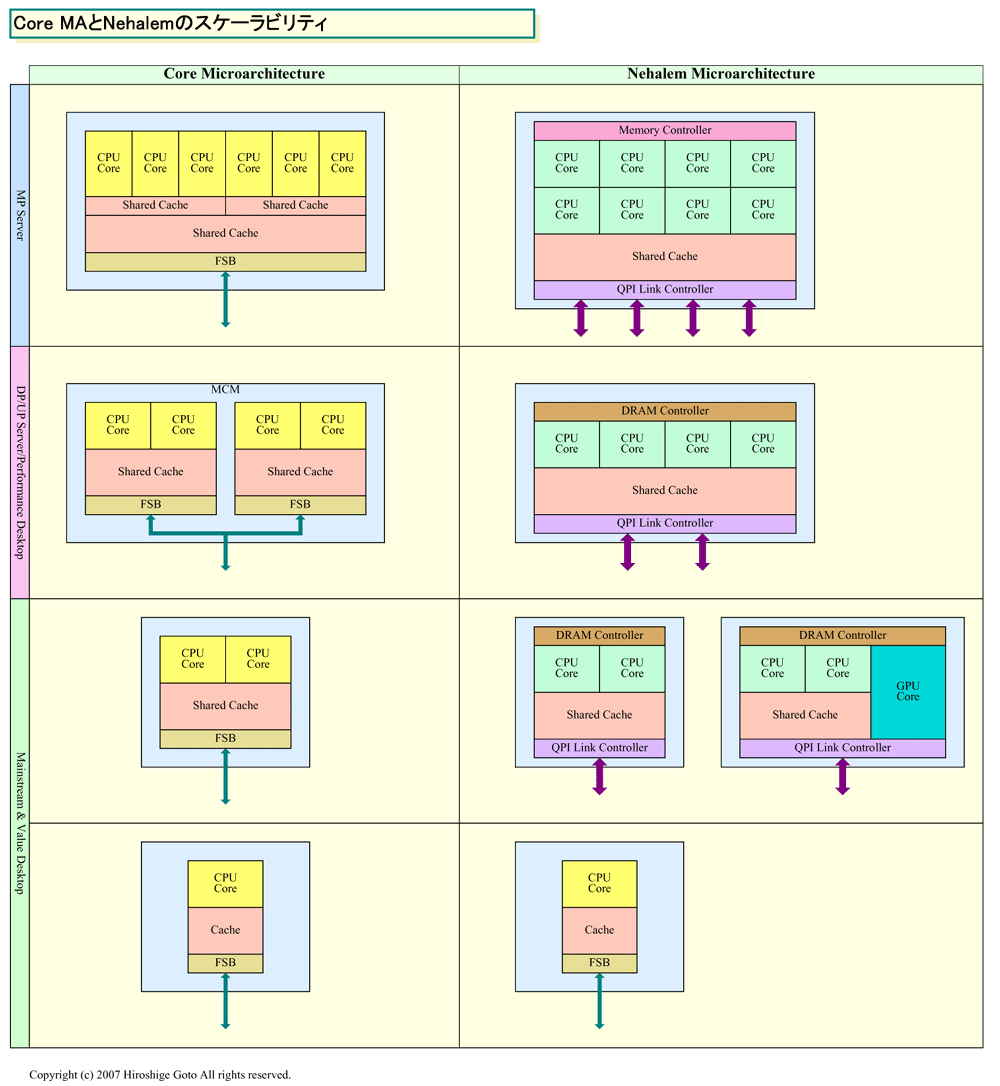 |
| Core MAとNehalemのスケーラビリティ (別ウィンドウで開きます) ※PDF版はこちら |
一見すると、AMDの「FUSION」プロセッサと同じ路線に見えるIntelのGPU統合CPU。しかし、その方向性は大きく異なっている。AMDは、GPUベースのデータ並列プロセッサコアを、グラフィックスだけでなく多様な処理を行なうことができる演算リソースとして積極的に使おうとしている。それに対して、Intelは、当面は統合GPUコアを、グラフィックス以外の用途に汎用に使うことは考えていない。単純に、グラフィックスをCPUに統合するという話だ。
 |
| Stephen L. Smith(スティーブ・L・スミス)氏 |
IntelのStephen L. Smith(スティーブ・L・スミス)氏(Vice President, Director, Digital Enterprise Group Operations, Intel)は、次のように説明する。
「我々は、プログラマブルグラフィックス(ハード)を持っている。そして、グラフィックスドライバを書くことを通じて、グラフィックスのような特定用途に向けたアクセラレータ上でプログラムを書くことがどのくらい難しいかも、理解している。
グラフィックスコントローラを、他の機能に使うことは、コンセプト的にはありうる。しかし、(グラフィックスハード上で)プログラムを書くことができるプログラマの数は非常に少ない。これは、グラフィックスドライバを書いている人数を考えてみればよくわかる。
その経験から、ラージセットの問題に対する、高並列コンピューティングを実現するためには、もっと汎用的でもっと柔軟なアプローチを見つけ出すことが必要だと考えた。そのアプローチこそが、Larrabeeで描いているものだ。
Larrabeeでは、我々は、世界の全てのデベロッパがプログラムの書き方を知っているIA(x86系命令セットアーキテクチャ)の利点を生かすことが、よりよいソリューションだと判断した。より柔軟で、プログラムの書き方を簡単に理解できて、業界のインフラを利用できるアーキテクチャを実現するつもりだ。今後、いくらかの特殊なアプリケーションはGPU上で走るようになるだろう。しかし、我々は別なアプローチを取る」
●GPGPUは失敗すると見るIntel幹部
GPUコアはPCに必須のグラフィックスタスクのため。汎用の高スループットコンピューティング向けには、別アーキテクチャ(現状ではLarrabee)をもたらす。将来的には、それがGPUコアを置き換える可能性もある。これが、現在のIntelのGPUコンピューティングに対する基本的な姿勢だ。
 |
| Patrick(Pat) P. Gelsinger氏 |
このスタンスは、デスクトップ&サーバーを擁するDigital Enterprise Groupでは一貫している。Digital Enterprise Groupを率いるPatrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)は、次のように語る。
「GPUのリソースを命令セットとして利用できるようにする試みも行なわれている。AMDのCTM(Close to the Metal)、NVIDIAのCUDA(Compute Unified Device Architecture)などで、有望なアプローチと見られている。しかし、我々は、これらのプログラミングモデルはうまく行かないと考えている。
なぜなら、プログラミングモデルが、非常に使い勝手が悪く、データタイプや命令フローも(通常のCPUとは)異なっており、キャッシュのコヒーレンシも保たれないからだ。非常に、汚いプログラミングモデルで、我々はこれらのモデルが失敗すると考えている。
Intelとしては、今後も、一貫した(CPU)命令セットの拡張をアーキテクチャに盛り込み続けて行く。その上で、アクセラレーションモデルは、『QuickAssist』のアプローチでサポートする。QuickAssistでは、ドライバインターフェイスモデルを通じて、アクセラレータ(上のプログラム)をCPUの命令セットから明瞭に分離する。その上で、(CPUとアクセラレータ間で)データの送受信をサポートする」
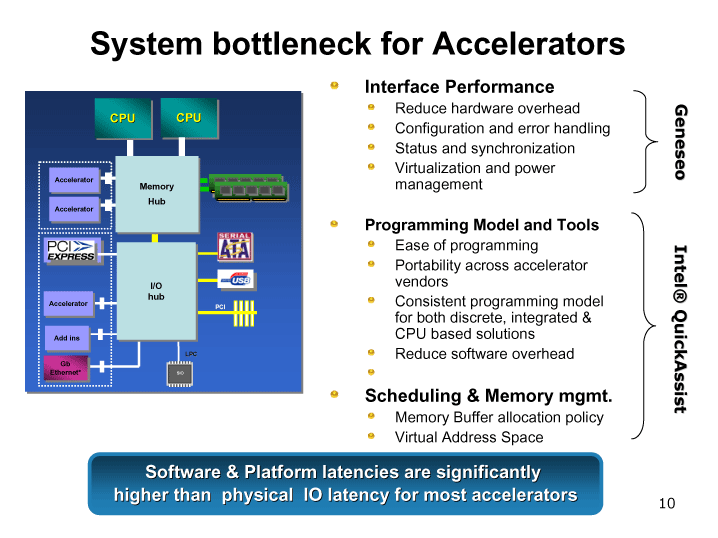 |
| アクセラレータのボトルネック (別ウィンドウで開きます) |
 |
| IAのプログラム性と並列性により高スループットコンピューティングをもたらす |
Intelは、GPU型のプログラミングモデル、いわゆるGP(General-Purpose)GPUは、広く普及させることができないと考えている。そのため、GPUのネイティブ命令セットを露出させたり(CTM)、薄いトランスレーションレイヤで扱えるよう(CUDA)にしても、成功できるとは考えていない。オフチップ&オンチップのアクセラレータコアは、QuickAssistモデルを通じてサポートするが、それ以上には踏み込まない考えだ。ネイティブ命令セットでの、高スループットコンピューティングは、Larrabeeで実現するというのが今の戦略だ。
では、LarrabeeはGPUとどう違うのだろう。
●MIMDのLarrabee対SIMDのGPUの対決
GPUのプログラミングモデルの複雑さは、GPUの基本アーキテクチャから来ている部分も多い。現在のユニファイドシェーダ型GPUの多くに共通する特徴は、ラージSIMD(Single Instruction, Multiple Data)型マシンである点だ。GPUでは、4~32個といった多数のシェーダプロセッサコアが、同じ命令を実行する。単一の命令ユニットが、複数個のプロセッサを制御するSIMD型のベクタプロセッサがGPUだ。
それに対して、Larrabeeは個々のプロセッサコアが個別の命令を実行するMIMD(Multiple Instruction, Multiple Data)アプローチを取るという。通常のCPUのマルチコアと基本的には同じ構造と見られる。MIMDマシンの上でデータ並列コンピューティングを行なうのが、Larrabeeのアプローチだ。よりCell Broadband Engine(Cell B.E.)ライクと言ってもいい。もっとも、Larrabeeも、MIMD構成の各プロセッサコアの中は、比較的ショートなSIMDの構成となっていると見られる。
SIMD(ベクタ) GPUとMIMD Larrabeeという構図は、ハイパフォーマンスコンピューティング(HPC)の世界での、SIMD対MIMDの論争を思い起こさせる。AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は、GPUの台頭を、かつてベクタスパコンをマイクロプロセッサが打ち負かした時の逆の現象だと形容する。つまり、ラフに言えば、AMDは、SIMD型が効率的な時代が再びやってきたと考えている。
 |
| マイクロプロセッサとGPU、それぞれにおける逆転現象 (別ウィンドウで開きます) |
 |
| Justin R. Rattner(ジャスティン・R・ラトナー)氏 |
それに対して、IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Senior Fellow, Corporate Technology Group兼CTO, Intel)は、次のように語る。
「私も一種の既知感(デジャブ)を感じている(笑)。私は以前、ハイパフォーマンスコンピューティングの仕事をしていたが、そこでは常にMIMD対SIMDの論争があった。どちらのアーキテクチャが有効かが、論争された。
我々が示したLarrabeeのダイアグラム図を見ればわかるとおり、LarrabeeはMIMDマシンだ。MIMDマシンに、コンベンショナルなキャッシュ階層を接続した構造となっている。そのため、非常にライトウエイトで低レイテンシなスレッド間コミュニケーションが、(プロセッサコア)アレイのどこからでも可能だ。
この構造は、今日のGPUとは大きく異なっている。GPUはSIMDマシンで、かなりの大きさ(のベクタ)で扱っている。MIMDマシン対SIMDマシンの話が繰り返されている。また、GPUは、(伝統的なキャッシュ階層も持たないため)スレッド間の(コミュニケーションの)レイテンシははるかに長い。
MIMDであり、コンベンショナルなキャッシュ階層を持つ。この2点がLarrabeeの違いとなる」
ここでRattner氏が言及しているダイアグラム図というのは、LarrabeeのチーフアーキテクトとしてIntel Technology Journalに紹介されていたDoug Carmean氏が、今年(2007年)始めにIntel Technical Lecture Seriesの1つとして行なった将来CPUアーキテクチャの講演で示された図だと推測される。その図を簡略化したのが下の図だ。階層化されたキャッシュを備え、各プロセッサコアが独立しているように見える。
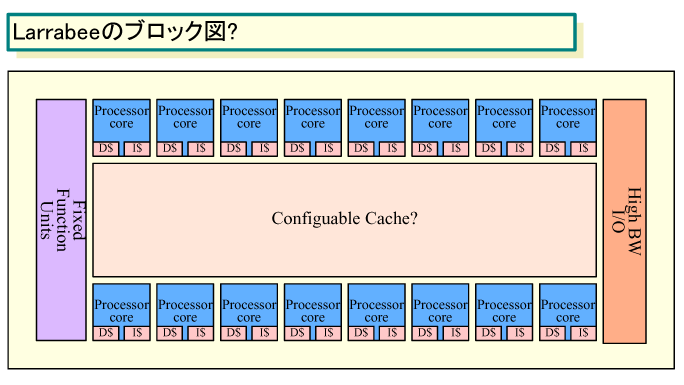 |
| Larrabeeのブロック図? (別ウィンドウで開きます) ※PDF版はこちら |
こうして見ると、LarrabeeとGPUの戦いは、クラスタ対ベクタスパコンの再来とも言える。メニイコア時代のCPUが狙うのは、かつてのHPCレベルの性能であり、アプリケーションも同様の方向となるため、これは当然かもしれない。
□関連記事
【10月5日】【海外】Intelが目指すNehalemでのGPUとCPUの統合
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
【6月18日】【海外】IntelのLarrabeeに対抗するAMDとNVIDIA
http://pc.watch.impress.co.jp/docs/2007/0618/kaigai365.htm
【6月11日】【海外】Intelが進める、32コアCPU「Larrabee」
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
【2月28日】【海外】GPU命令のx86体系への統合
http://pc.watch.impress.co.jp/docs/2007/0228/kaigai341.htm
【2月27日】【海外】CPUとGPUの統合プロセッサのチャレンジ
http://pc.watch.impress.co.jp/docs/2007/0227/kaigai340.htm
(2007年10月11日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.