 |


■後藤弘茂のWeekly海外ニュース■Penrynの1.5倍のCPUコアを持つ次世代CPU「Nehalem」 |
●アーキテクチャを刷新したNehalem
 |
| Stephen L. Smith氏 |
Intelが来年(2008年)後半に投入する、次期CPUマイクロアーキテクチャ「Nehalem(ネハーレン)」。今回のIDFでは、マイクロアーキテクチャの詳細はほとんど公開されなかった。しかし、いくつかのヒントは与えられた。
IntelのStephen L. Smith(スティーブ・L・スミス)氏(Vice President, Director, Digital Enterprise Group Operations, Intel)は、ブリーフィングで次のように語った。
「Nehalemは4イシュー(命令発行)マシーンで、Core 2の4ワイド(=イシュー)マシーンの上に構築されている。しかし、抜本的に異なっており、より高機能になっている」
Intelは、Core 2系のCore Microarchitecture(Core MA)から、命令発行の幅を4イシューに拡張した。Core MA以前のIntel CPUは、いずれも3イシューのマイクロアーキテクチャだった。NehalemはCore MAの4イシューアーキテクチャを引き継ぐ。
 |
| Patrick(Pat) P. Gelsinger氏 |
では、NehalemのCPUコアは、Core MAをベースとして多少の拡張を加えただけのものなのだろうか。それについて、Nehalemの設計チームを含むDigital Enterprise Groupを率いるPatrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)は、次のように語る。
「マイクロアーキテクチャ拡張の詳細については、まだ公開できない。公開できない理由の1つは、(ライバル企業との)競争上から、もう1つは、まだ中間地点でPenrynすら製品発表していないからだ。Nehalemについては、次のIDFで多くを公開する。ただし、Nehalemに大きな拡張が加わったことだけは言える。なぜなら、Nehalemはチックタックモデルのタックであり、完全な新マイクロアーキテクチャだからだ。
内部マイクロアーキテクチャはもちろん変更した。メモリ階層も変えた、重要な新命令実行機能もマシンに加えた、アーキテクチャのパイプライニングも再編成した。また、公表した通り、ネイティブクアッドコア設計で、オクタコア設計版も控えている。CPU内部の非コア部分ではオンチップネットワークを大きく変えた。もちろん、メモリコントローラとQuickPath Interconnect(QPI)の内蔵も新しい。全てが完全に新設計だ。
Nehalemには多くの素晴らしい機能が搭載されている。まだ言えないが、素晴らしいアーキテクチャであることを信じて欲しい」
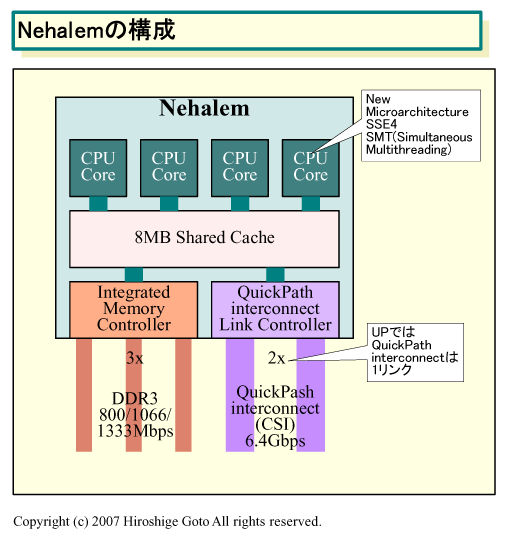 |
| Nehalemの構成 ※別ウィンドウで開きます PDF版はこちら |
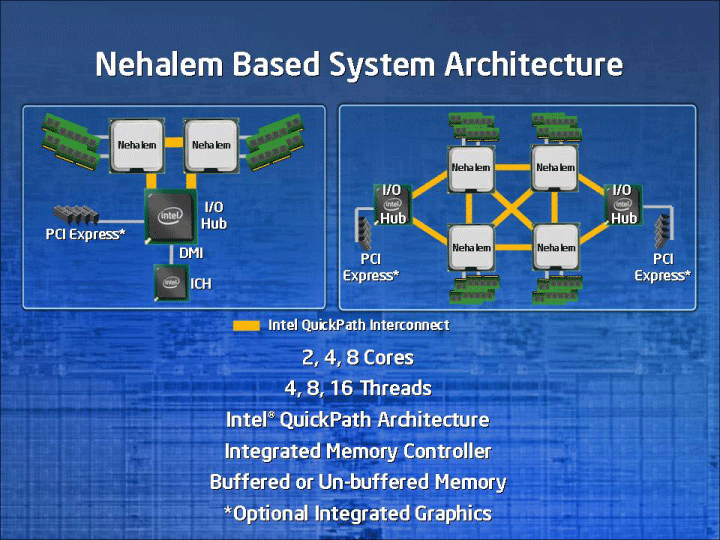 |
| Nahalemの基本アーキテクチャ ※別ウィンドウで開きます |
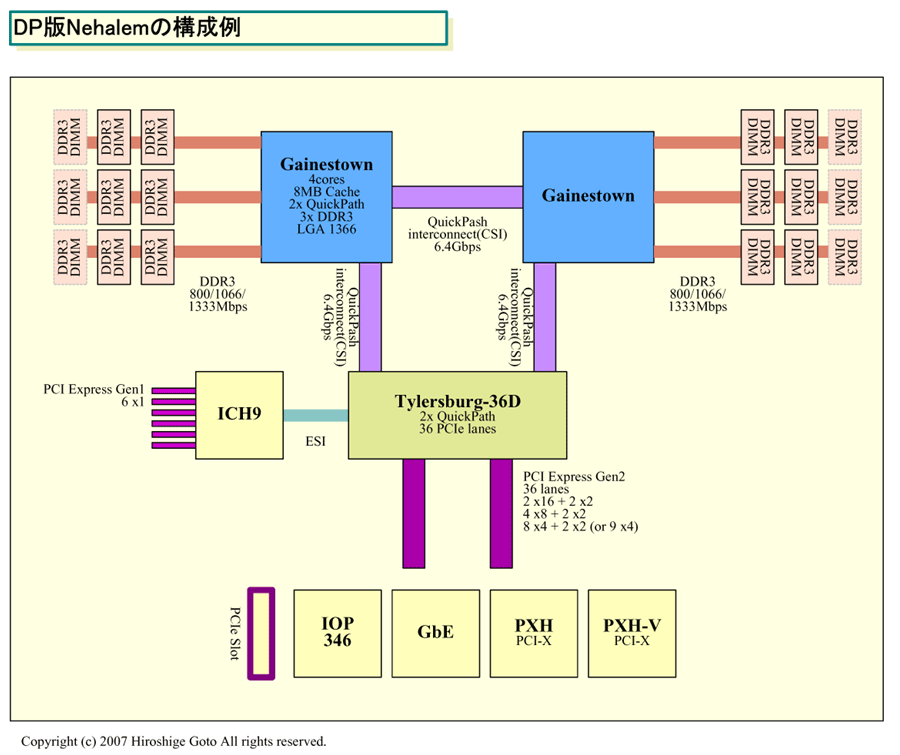 |
| DP版Nehalemの構成例 ※別ウィンドウで開きます PDF版はこちら |
●NehalemのCPUコアサイズはPenrynの1.5倍
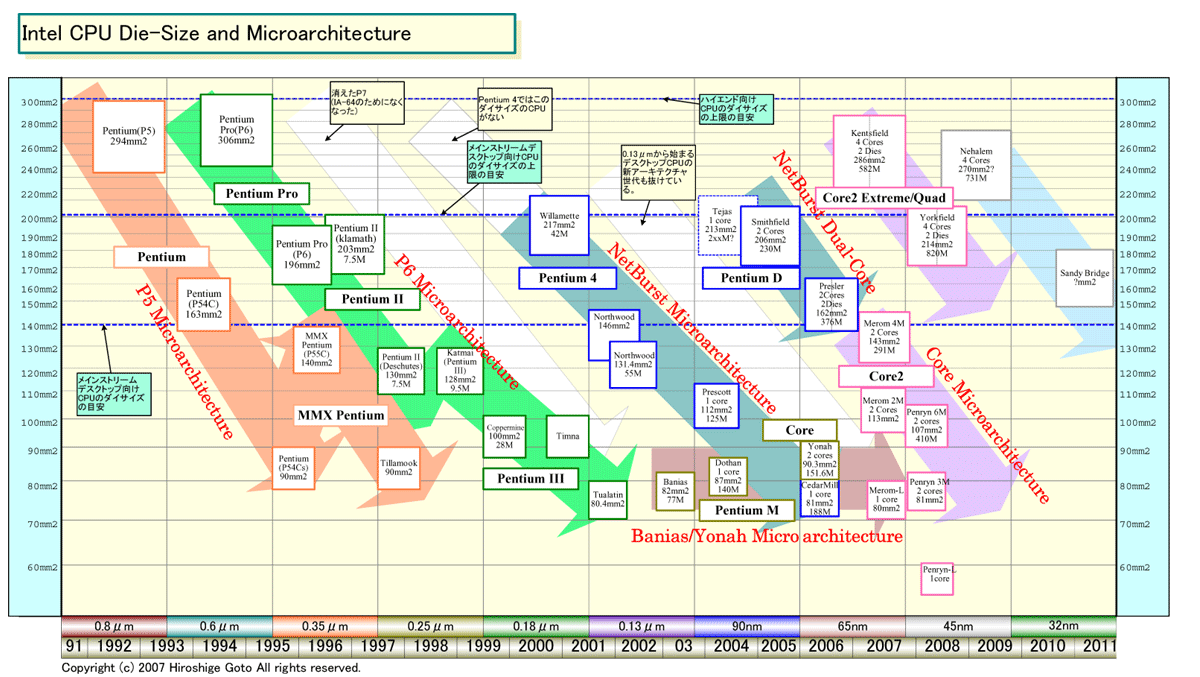
実際に、NehalemとPenrynのダイ(半導体本体)を比べると、CPUコアに大きな違いがあることが明瞭にわかる。下の図は、Nehalemのダイを約270平方mmと推定、Penrynのダイとほぼ同縮尺にして比較したものだ。見ての通り、Nehalemの方が約2.5倍のダイサイズとなっている。そして、その中のCPUコア部分を比較すると、NehalemのCPUコアはPenrynのCPUコアに対して、約1.5倍の面積となっていることがわかる。これは、CPUコアにかなり大幅な拡張が加えられたことを意味している。
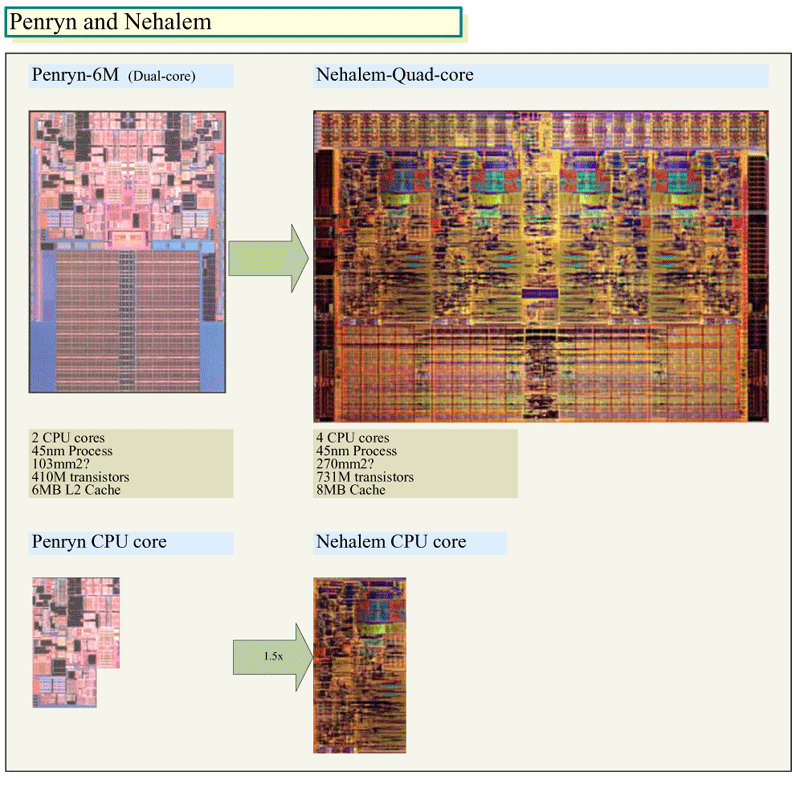 |
| PenrynとNehalemのダイ比較 ※別ウィンドウで開きます PDF版はこちら |
もともと、Core MAのCPUコアは、65nmのMerom(メロン)で19M(1,900万)と、比較的コンパクトにできていた。単純計算では、NehalemのCPUコアは30M(3,000万)程度のトランジスタ数になると推定される。簡単に言えば、IntelはNehalemでは、CPUコアを小さく止めて拡張は抑え、その代わりCPUコア数を増やしてスレッド並列性を高めるという方策は採らなかったことになる。スレッド並列性も高めるが、CPUコア自体も強化する路線だ。
Intelには、Nehalemでマイクロアーキテクチャを刷新し、大きく拡張しなければならない理由がある。Intelの内部では現在、2つのCPU設計チームがPC&サーバー向けCPUの開発で競争している。1つは、オレゴン州ヒルズボロ(Hillsboro)にいる開発チームで、Digital Enterprise Groupに属しており、Pentium III(P6)やPentium 4(NetBurst)アーキテクチャを開発した。もう1つは、イスラエルにいるチームで、Mobility Groupに属しており、Pentium M(Banias)やCore Microarchitecture(Core MA)を開発した。
もともとは、デスクトップ&サーバー向けCPUはオレゴンで開発していた。しかし、低消費電力コアの開発で遅れたために、モバイル向けに開発していたCore MAを、デスクトップ&サーバーにも拡張したという経緯がある。Nehalemは、ヒルズボロ開発としてはNetBurst以来のマイクロアーキテクチャ改革となる。2004年~2006年にかけて計画されていた、ヒルズボロ開発のNetBurst拡張「Tejas(テハス)」と、オリジナルプランのNehalemはキャンセルとなっている。Core MAはその代わりとして据えられた。
つまり、形としてはヒルズボロのつまずきを、イスラエルのアーキテクチャが救ったことになる。そのため、あるIntel関係者は「今では、開発チームとして、ヒルズボロとイスラエルは同格に並んでいる。Gelsinger氏は、Nehalemでヒルズボロの開発力を示さなくてはならない立場にある」と語る。
 |
| Intel CPU Die-Size and Microarchitecture ※別ウィンドウで開きます PDF版はこちら |
●NetBurstのHyper-Threadingから発展
ヒルズボロがNehalemで新たに加えた新要素の1つは「SMT(Simultaneous Multithreading)」だ。NehalemはHyper-Threadingと同様のSMT技術を搭載し、1個の物理CPUコアが2スレッドを並列実行できる。論理スレッド数は、各CPUコア当たり2スレッドとなる。Gelsinger氏はNehalemのSMTについて次のように説明する。
「SMTは非常にエレガントな設計だ。ワークロードがスレッド化されていれば、非常に優れたリソースシェアリングができる。もちろんSMTの実装は簡単ではない。AMDがまだ実現できていないことが、難しさを実証している。
しかし、いったん実装できれば、(2Wayの)SMTではゼロから最大30~40%のパフォーマンス向上が得られる。場合によっては向上はゼロかもしれないが、条件がよければ40%になるかもしれない。4~5%の設計サイズの増加で、それだけのパフォーマンス向上が得られることは、いいトレードオフだ」
数%の実装コストで最大40%のパフォーマンスゲインは、Hyper-Threadingの時のストーリーと共通している。このことから、NehalemのSMTが、NetBurstのHyper-Threadingと似通っていることがわかる。また、Gelsinger氏は、今春の来日時に次のように語っていた。
「我々は、Pentium 4のHyper-Threadingから多くを学んだ。そのため、Nehalem(のSMT)は、(NetBurstのSMTに対して)同等かより優れたものになると考えている。Nehalemでは(NetBurstと比べて)より短いパイプラインであるため、スレッド間の遷移がより素早くなる」
NehalemのSMTが、NetBurstのHyper-Threadingの拡張であることが伺える。後段の説明は、SMTではなくパイプラインのスレッド切り替えの話になっているが、ここからは、NehalemがCore MA同様に浅いパイプライン構造であることがわかる。
●PCソフトウェア環境のワークロードを考慮した2wayのSMT
SMTでは2スレッド以上の並列化も可能だ。しかし、IntelはNehalemでは2way以上のSMTは実装しない。Hyper-Threadingと同様に、最大2スレッドまでのSMTに止めた。その理由についてGelsinger氏は次のように説明する。
「3~4wayにした場合には、パフォーマンスは(2way)より向上するだろうが、設計の複雑度はずっと増してしまう。3~4wayのSMTを単一のCPUコアのリソースに加えても、増える複雑度の割に目覚ましい性能向上は得られない。2Way SMTは、複雑性とパフォーマンスのいいバランスで、非常にパワー効率がいい、最適なマイクロアーキテクチャだ」
しかし、サーバー系CPUでは、3way以上のハードウェアマルチスレッディングを実装したCPUも登場している。例えば、Sun MicrosystemsのNiagara 2では1コア当たり8wayのマルチスレッディングをサポートする。それに対して、Gelsinger氏は、最適化するワークロードによって、最適なマルチスレッディングの実装も異なると説明する。
「Sunが実装したのはSMTではなく、イベントでスレッドをスイッチする“Switch-on Event Multi-Threading (SoEMT)”だ。実装は大きく異なる。我々のSMTでは、パイプラインを通じて(2つのスレッド間で)完全にリソースを共有する。それに対して、彼らの実装では、スレッド群をパイプラインに送り込み、異なるスレッドのステイトをトラックし続ける。
高度にスレッド化されたワークロードに対しては、Niagaraの設計はかなりエレガントだ。Niagaraは、そうした高スレッド化(ソフトウェア)環境に対して最適化した設計がなされている。一方、スレッド化の度合いのレンジが広いさまざまなワークロードに対しては、我々のSMTの方が利点がある。我々は、スレッド度の低い(ソフトウェア)環境と、高い環境の間でのバランスにより最適化した設計を行なっている。例えば、NehalemとNiagaraを比べた場合には、シングルスレッド性能では大きな差ができるはずだ。多分、5倍くらいのパフォーマンスデルタの差ができると思う。
Niagara自身は、さまざまな面で非常に優れた設計だ。小さなCPUコアにSoEMTメカニズムを実装した極めて並列度の高いアレイで、彼らの目指すワークロードでは、リーズナブルなパフォーマンストレードオフが得られる。しかし、我々とは設計ポイントが大きく異なっている」
SMTと比べて実装が容易なSoEMTで、スレッド並列度を上げるという手もある。しかし、SoEMTでは、SMTのように異なるスレッドの命令を1サイクルに混在させて実行することでCPUリソースの活用度を上げることはできない。SMTは、スレッド並列性が低いソフトウェア環境でも、命令レベルの並列性の高いCPUコアの活用度を上げて、全体のスループットを高めることができる。つまり、モバイルを含めたクライアントPCのソフトウェア環境を考えると、2way SMTを、命令並列性の高いファットなCPUコアに実装することが有利というのがIntelの判断だ。
●64-bitへの最適化が行なわれたNehalem
SMTはNehalemの新機能だが、Gelsinger氏の説明通りだとすると、CPUコア設計へのインパクトは4~5%のダイの増加に留まる。NehalemのCPUコアの大型化の理由のほとんどは、SMTの実装にないことは明らかだ。
マイクロアーキテクチャ面で、NehalemがCore MAと明瞭に異なる点の1つは、64-bitモードだ。Core MAは、内部の設計を見る限り、32-bitモードを中心に設計を行ない、64-bitモードは付け加えた感が強い。特に、フロントエンドの命令フェッチからデコードにかけては、32-bitにより最適化されており、64-bitへの最適化のためには明らかに拡張が必要だ。これは、もともと、Core MAがモバイル用CPUマイクロアーキテクチャとして開発がスタートされたことと無関係ではないだろう。
それに対して、Nehalemでは、デスクトップ&サーバーCPUを担当して来たIntelのオレゴンチームが担当している。そのため、64-bitモードへは完全な最適化が図られるという。
「(Nehalemでは)全ては64-bitだ。32-bitももちろんサポートするが、64-bitに最適化されている」(Gelsinger氏)
このことは、パイプライン全体の中でフロントエンドが大きく改良されていることを伺わせる。またGelsinger氏は、Nehalemではリパイプライニングしたと語っており、パイプライン構造がCore MAとは異なっている可能性は高い。また、Nehalemから加わるApplication Targeted Accelerator(ATA)命令の実行ユニットも、ある程度のダイを占めるだろう。
ちなみにAMDは、GPU統合までを見据えた、AMDバージョンの“SSE5”命令の追加の計画を明かした。AMDは、最終的には、GPUコア側の実行ユニットを、SSE5やそれ以降で追加する命令などを通じて、CPUプログラム上からシームレスに使えるようにする。AMDのこうしたSSE命令拡張ヴィジョンに対して、Gelsinger氏は次のように答える。
「我々はSSE4以降のSSE命令のロードマップを持っている。その概要は、来年公開するだろう。AMDが言うところのSSE5に、我々が追従するつもりはない。これまで、我々はSSE4への明瞭な道筋を示して来ており、それに対する業界の対応姿勢もいい。それに対して、AMDは、我々のSSE4に完全互換ですらない」
 |
| ISAの革新は続く ※別ウィンドウで開きます |
●Core MA同様に浅いパイプラインのNehalem
NehalemはCore MAと差別化される一方で、強い共通性も持つと推測される。まず、前出の発言でわかるようにNehalemは、NetBurst系の深いパイプラインによる高周波数設計は採用しない。これは、パフォーマンス/消費電力にフォーカスした現在のIntel CPUでは当然の方向だ。パイプラインを深くすると、電力消費の大きなラッチ回路が増えて、電力消費が増えてしまうからだ。
 |
| Justin R. Rattner氏 |
ヒルズボロの前のマイクロアーキテクチャであるNetBurstでは、x86命令を単純な内部命令uOPs(マイクロオペレーション)に分解した。それに対して、Banias以降のイスラエル系マイクロアーキテクチャでは、内部命令の粒度を大きく保つuOPsフュージョンを採用し、Core MAではさらにx86命令同士を融合させるMacroフュージョンを採用した。CISC(Complex Instruction Set Computer)であるx86の強みを、ある程度CPU内部のパイプラインにももたらすというのが、イスラエル系マイクロアーキテクチャの特徴だ。そして、それは、Nehalemにも継承されると見られる。例えば、IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Senior Fellow, Corporate Technology Group/CTO, Intel)は以前次のように答えていた。
「我々が電力効率を向上させるために、BaniasからMerom、さらに、それ以降(のCPUマイクロアーキテクチャ)で継続して行なっているのは、よりuOPsフュージョンを適用することだ」
uOPsフュージョンを進化させることは、現在のIntelマイクロアーキテクチャの基本路線だと考えられる。そのため、Nehalemでも、Core MAのuOPsフュージョンとMacroフュージョンは継承されるだろう。
ただし、MacroフュージョンをCore MA以上に発展させることは、若干難しいかもしれない。Core MAのMacroフュージョンは、「COMPARE」と「CONDITIONAL-JUMP」の2つのx86命令の連続を融合させる。Intelの論文でも、これがもっともuOPsフュージョンに適した組み合わせだと指摘されている。Macroフュージョンをそれ以上に広げようとすると、現状では実装コスト面で現実的ではないかもしれない。
●Nehalemではトレースキャッシュはどうなる?
Core MAとNehalemの違いとして、もう1つ想定できることは「トレースキャッシュ」だ。NetBurstでは、x86命令デコーダが、L1命令キャッシュであるトレースキャッシュの前にあり、トレースキャッシュにはデコードしたuOPsを、命令パスをトレースして格納していた。この構造から、NetBurstではx86命令デコードの複雑性を、デコーダから下の実行パイプラインから隠蔽することができた。
しかし、その一方で難点もあった。NetBurstでは、トレースキャッシュをミスした場合には、1基の命令デコーダによるデコードからスタートしなければならなかった(Tejasではここが大きく改良される予定だった)。また、トレースキャッシュに格納したのはx86を分解したuOPsであるため、実命令数が膨れあがり、トレースキャッシュの実容量を肥大させてしまった。さらに、トレースキャッシュでトレースしていた実行パスは、デコーダが予測したトレースであり、実際に命令実行されたトレースではなかった。
そのため、もし、NehalemでIntelが、改良型トレースキャッシュを搭載するとしたら、次のようになると予想される。トレースキャッシュに格納するのは、x86のCISCの特性をある程度継承したMacroOPs(固定長だが複数オペレーションを含む)にして、キャッシュする実命令数を減らすだろう。また、キャッシュ構造を変えて、x86命令を格納するL1命令キャッシュと、MacroOPsを格納するトレースキャッシュの両方を持つかもしれない。実行パイプラインでの実行結果をベースに、バックグラウンドでトレース解析を行ない、繰り返し実行されるパスのトレースを、L1命令キャッシュとは別のトレースキャッシュに格納する方式だ。
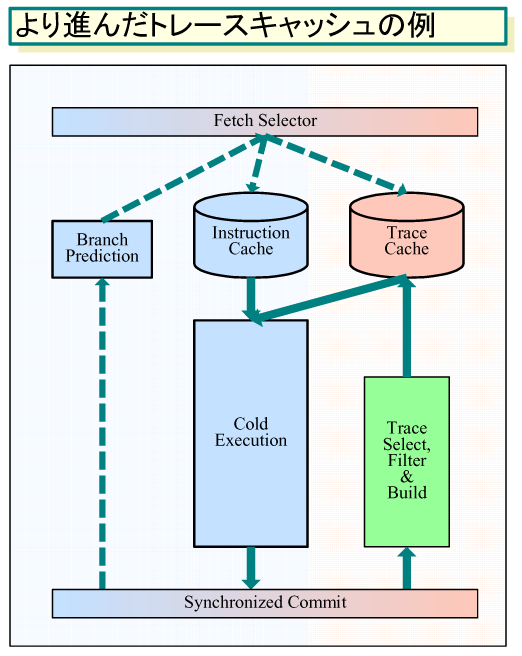 |
| より進んだトレースキャッシュの例 ※別ウィンドウで開きます PDF版はこちら |
これなら、NetBurstと異なり、格納されるのは実際に実行されたトレースとなる。また、全てのパスを納めるのではないため、再利用されないコードのMacroOPsでトレースキャッシュを溢れさせる心配はない。また、トレースキャッシュの中で、さらに大きなブロック単位での命令スケジューリングを行なうことができる。例えば、クリティカルパスのオペレーションをキャッシュ内で、トレースのできるだけ前の方に移動させることもできる。もっとアグレッシブにするなら、キャッシュ内で命令のSIMD化もできるかもしれない。
Gelsinger氏は、Nehalemにトレースキャッシュを搭載しているかどうかは「まだ明かせない」としている。しかし、トレースキャッシュを実装した実績のあるヒルズボロなら可能性はあるだろう。x86アーキテクチャの場合には、命令プリデコードとデコードが非常に複雑で、それを軽減するアプローチは有効だからだ。
●Nehalemのカギとなる3レベルのキャッシュ階層
トレースキャッシュについては、実際にはNehalemに入っているかどうかわからないが、Nehalemのポイントがキャッシュにあることは明らかだ。Nehalemは、CPUコアそれぞれにL1キャッシュを持つ他、共有キャッシュを持つ。これらの構造はどうなっているのだろう、またL3キャッシュはオンチップでCPUに搭載するのだろうか。
 |
| Glenn J. Hinton氏 |
Gelsinger氏は、Nehalemが専用L1と共有L2を備えると認めた。また、Glenn J. Hinton(グレン・J・ヒントン)氏(Intel Fellow, Digital Enterprise Group, Director, IA-32 Microarchitecture Development)は、IDFのFellow Shop Talkで、次のように語った。
「Pentium 2/IIIまではキャッシュメモリをカートリッジに(CPUとは別チップで)載せていた。次のフェイズで我々はL2キャッシュをCPUの内部に納めた。CPUへの内蔵でキャッシュの量は1/2~4に減ったが、パフォーマンスは増大した。レイテンシが減り、帯域が拡大したからだ。
それ以降は、コスト面で見合うようになるとキャッシュを増大させてきた。現在、我々は数レベルのキャッシュ階層を持っている。Nehalemは3レベルのキャッシュ階層を持つ」
以上の点からわかることは、Nehalemが3レベルのキャッシュを持ち、それはおそらくオンチップに載せられていることだ。また、Intelはキャッシュ階層化がNehalemの“オプション”とも言っていない。サーバー/デスクトップ/モバイルでキャッシュのサイズが変わる可能性があると言っているが、キャッシュ階層が変わる可能性は1回も示唆していない。そのため、3レベルのキャッシュは、全てのNehalemに共通していると推測される。
これは示唆的だ。通常、L3へのキャッシュ階層化は、キャッシュ量が増大し、キャッシュアクセスのレイテンシが増大する場合に行なう。中容量でアクセスの速いL2と、大容量でやや遅いL3へと階層化するわけだ。また、AMDアーキテクチャでは、各CPUコアが占有L2を持つため、共有L3を備えることは理にかなっている。しかし、中途な容量のキャッシュを、単純に多階層化しても意味は薄い。そのため、Nehalemの場合は、従来とはキャッシュの階層化のアプローチが異なる可能性がある。
想定できるキャッシュ階層モデルの1つは、上で述べたように、L1命令キャッシュのさらに上位にトレースキャッシュを設ける可能性。この場合はトレースキャッシュをL0命令キャッシュとして数えることになる。
しかし、IntelはNehalemマイクロアーキテクチャが“複数レベルの共有キャッシュ”を持つと説明している。言葉通りに受け取ると、各CPU毎にL1があり、その他に共有のL2とL3を持つことになる。その場合に考えられることは、L2キャッシュに、より多くの情報を付加することだ。例えば、L2に取り込む段階で、キャッシュラインの内容を解析してより多くのタグ付けを行なうなら、その外側により単純なL3を備えることは理にかなう。もしかすると、L2とL3は物理的には同じキャッシュSRAMで、リコンフィギュラブルにエリアを分けて使い分けているのかもしれない。
実際にどうなっているかはまだわからない。しかし、Nehalemの3階層キャッシュがやや不自然なことは確かだ。
□関連記事
【9月20日】【海外】IntelがNehalemの概要を発表、実動デモも公開
http://pc.watch.impress.co.jp/docs/2007/0920/kaigai388.htm
【9月16日】【海外】いよいよベールを脱ぐIntelの次期CPU「Nehalem」
http://pc.watch.impress.co.jp/docs/2007/0916/kaigai386.htm
【4月4日】【海外】GPUコアを統合する次世代CPU「Nehalem」
http://pc.watch.impress.co.jp/docs/2007/0404/kaigai349.htm
【3月30日】【海外】Intelのマイクロアーキテクチャ改革「Nehalem」
http://pc.watch.impress.co.jp/docs/2007/0330/kaigai348.htm
(2007年9月27日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.