
MicroProcessor Forum 2007レポート
非凡なプロセッサたち
 |
| Engineering DirectorのVidya Rajagopalan氏。氏は以前はMIPS64 20Kcの製品ラインの責任者も勤めていた。前職はDECでAlpha 21064/21164の開発に携わっていたとか |
会期:5月21日~23日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
筆者の最後のMPFレポートは、恒例の「変なもの」だ。常識的な発想なのにインプリメントが非凡なMIPS32 74K、それと非凡な発想に非凡なインプリメントが兼ね備えられたParimics IPE/PPEのレポートをお届けしたい。
●MIPS32 74K
2005年にDSP搭載のMIPS32 24KEを発表、2006年2月にはMultiThread対応のMIPS32 34Kを発表したMIPS Technologiesだが、今回は新たなコアであるMIPS32 74Kの発表を行なった。
MIPSの場合、DSPの統合とかMultiThreadingの搭載などで総合性能を引き上げるという方向性は以前から示していたが、CPUコアそのもののIPCを引き上げるための抜本的な変革といったものは特になされていなかった。ただ、競合製品が相次いでCPU性能を引き上げてゆく中で、そろそろ同社としてもCPU性能の引き上げは必須と考えたのであろう。IPCを50%引き上げる、という積極的な方針を打ち立てた(図2)。
ちょっと興味深いのは、ベースになるのがMIPS32 34Kではなく24KEなこと。まだMulti-ThreadingがMIPSのマーケットではそれほど広く利用されていないという事なのか、それとも後からMulti-Threading化するのは容易だからということかはちょっとわからない(あるいは両方かもしれない)が、ベースとなるのは24KEコアとなっている。意外なのは、0.13μmプロセスで400MHzが既に限界に達していたという話。tagとかregister fileはともかく、Pipeline stallのSignal伝達がリミットというのは、内部的に相当複雑な事をしていたのではないかと思う。
 |
 |
| 【図2】ただここでAMCCのように、特殊なプロセスを利用して動作周波数を引き上げるといったアプローチを取らなかったのは、個人的にはリーズナブルな選択だと思う | 【図3】もっとも0.13μmのStandard Processだと、400MHzあたりが普通に考えて上限だから、特にMIPS32のアーキテクチャがどうこう、という話ではないのかもしれないが。ただボトルネックになっているのが、普通に考え付くALU内部とかではなく、Cache/Register File/TLBといったものが主な要因というのは非常に興味深い |
さて、性能を上げるためにはIPCを上げるか動作周波数を上げるか、という話だが、これを両方狙おうとすると話はややこしい(図4)。パイプライン段数を増やすのは動作周波数を上げる常套手段として、パイプライン構成をどうするかが問題になる。最終的には非対称構成のOut-of-Orderを取る、という形にまとまったようだ。
ここで重視するのが消費電力あたりの性能ではなく、ダイサイズあたりの性能というところが、MIPSコアの使われ方を示唆しているとも言える。ただその結果として、90nmプロセスを飛ばして65nmプロセスに移り、しかも17段ものパイプラインになった、というのは正直理解が追いつかない(図5)。130nm→65nmまで飛べば、トランジスタそのものの性能がだいぶ上がってるはずで、何もパイプラインを倍以上まで増やさなくても対応できそうな気がするのだが。そのパイプラインの構成はこんな形だ(図6)。通常のALUとAGEN(アドレス生成)という2つのパイプラインに分割した形を取っている。
 |
 |
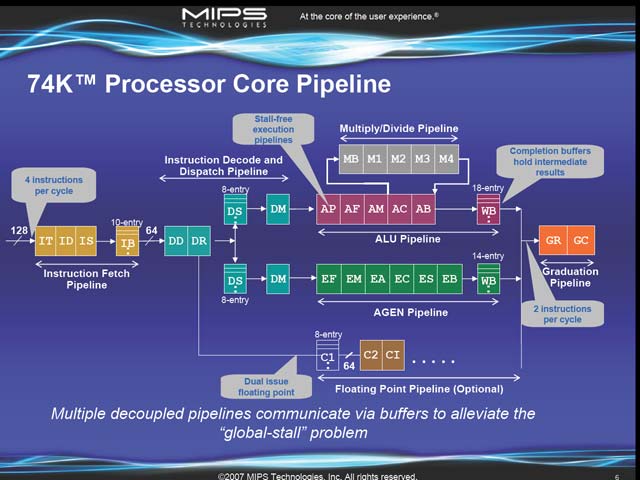 |
| 【図4】SymmetricとAsymmetricでそれほど性能が変わらない、というのはプログラムがそもそもSuper-Scalarに対応していないという話ではないかという気もするが。ただ互換性を重視すればこれは仕方が無い気もする | 【図5】最後の“Pipeline designed to be multi-threading friendly”が示すとおり、将来的にはMT AES(MIPSの提供するMulti-Threading Extention)対応製品が出てくるのであろう | 【図6】FPUもやはりDual Issueになっているあたりが面白い。ただMIPSは伝統的にFloating Pointはオプション扱いであり、この実装でも簡単に分割できるように、Integer Dispatcherの手前でPathが分かれている事がわかる |
 |
 |
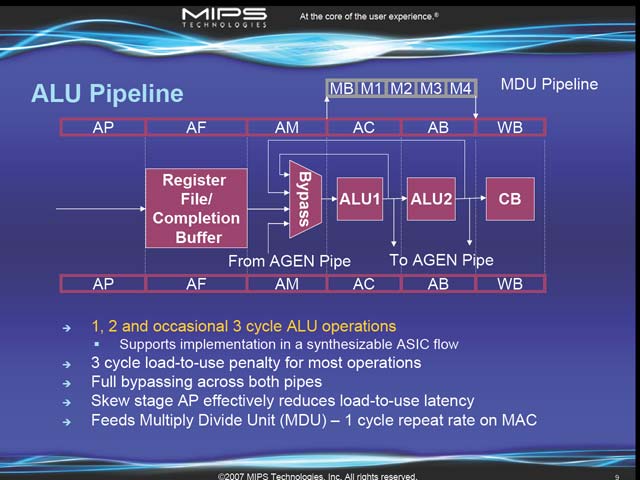 |
| 【図7】個人的には分岐予測が大変に気になる。256エントリのBHT(Branch History Table)が3つ用意され、この3つの間で多数決を行なって分岐アドレスを決めることで高い予測精度を保つという話だが、この3つがどういう具合に持ち方を変えているのかの説明は無かった。17段ものパイプラインともなると、ハザード時のペナルティが洒落にならないから、分岐予測に力を入れるのが普通なのだが…… | 【図8】Dispatch Windowが8エントリなのは、実装の問題という話だが、実際問題としてALU/AGEN共に1本しかPipeが無いのだから、8エントリで十分という気もする | 【図9】まぁ事実上パイプラインが1本しかないから、依存関係解消待ちがパイプライン中で発生することはありえないのだが。ところでRegister File Accessが問題だったはずなのに、ここでは1ステージで処理が終わっており、大丈夫なのかちょっと疑問。実質的には前段のAPステージも使って2Cycleで処理しているのかもしれない |
まずFetchは4段の構成になってる(図7)。L1キャッシュにSRAMを使えるよう、3Cycle分のDelayを見込んであり、ここから逆に4cycleという構成になっている。デコードとディスパッチは4段と、機能の割にはむしろシンプル(図8)と言っても良い。これに続くALUは、通常の演算で6段、Multiple/Dividerは9段という構成になっている(図9)。
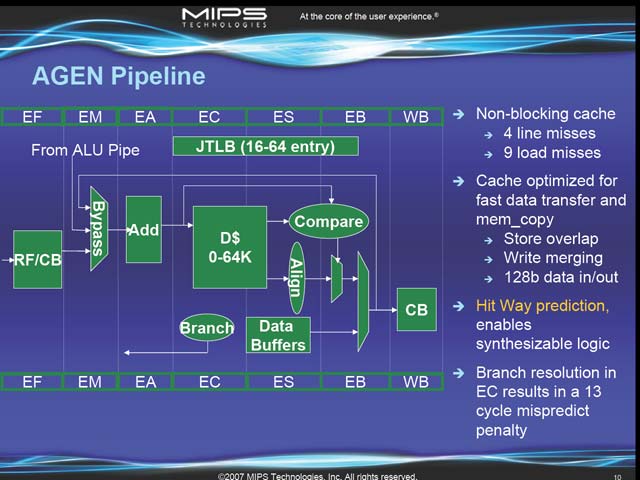
このパイプラインが特徴なのは、Stall-freeなこと。つまり、メモリアクセス待ちとか依存関係、あるいはPrediction Missなどが絶対に発生しないことを前提とした構成になっているのが特徴だ。ここをStall-Freeにしたからこそ、パイプラインが長くてもPipeline-Hazardの影響は少ないと踏んでいるのかもしれないが、ちょっと気になる部分だ。一方AGENパイプラインの方はもう少し複雑になる。Data Cacheへのアクセスがここに入るからで、結果として図10のような構造になっている。ところでこのAGENもStall-Freeにするための工夫が図11だが、目的はわかるものの、何かちょっと違う気がしなくも無い。Stall Freeをあきらめて、代わりにmicro-TLBなどでHit時の性能を高めた場合とのトータル性能を比較した上での決断であろう、とは想像できるのだが。
 |
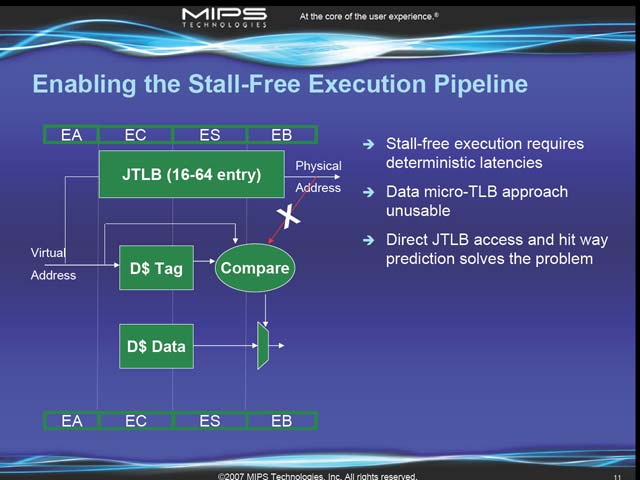 |
| 【図10】Data Cacheへ事実上2Cycleでアクセスできているように見えるのがちょっと謎。ただ、Line missで4Cycle、Load Missで9Cycleというのは、構造を考えれば妥当な数字だと思う | 【図11】この方式は当たれば大きいが外れると悲惨な事になる気がする |
結果として、Fetchで4段、Decode/Dispatchで4段、Executeで6段、WriteBackで3段の合計17段という長大なパイプラインに仕上がったわけだが、そこまでしてもOut-Of-Orderを導入した理由をまとめたのが図12だ。あくまでSynthesizable coreであることに拘り、プロセスを選ばないという条件で設計すると、これが最適な解になるという話で、これはある程度わからなくもない。
ただ、最近のプロセッサが性能とのトレードオフである程度ファウンダリやプロセスを選ぶ方向にあり、ただマーケットがそれを許容する方向で動いている事を考えると、こうした間口を広く取る解が適切なのかはにわかに判断しがたい。
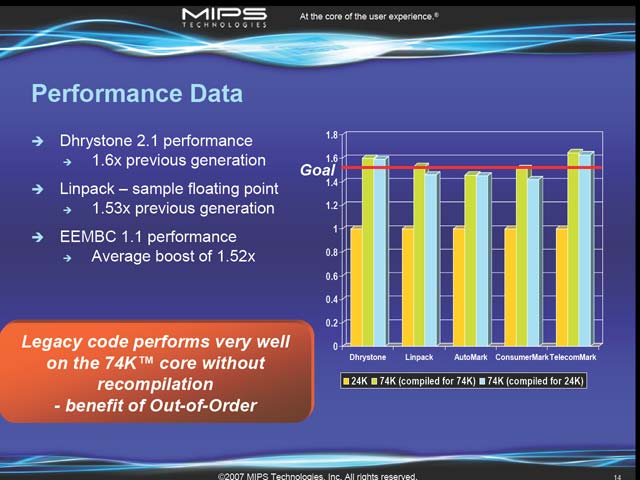
図13には性能比較が、図14では実際に製造した場合のパラメータがそれぞれ示されているが、いずれも目標とされる水準に達している事が示されている。その意味では常識的な発想に常識的な結果がついてきた、上手く行なった例になるわけだが、そのインプリメントがあまり常識的と言えないのがMIPS32 74Kシリーズという事になるだろう。
 |
 |
 |
| 【図12】Out-of-Orderが原理的にはLatency-Tolerantなのは間違いない。ただ、これで遮蔽できるLatencyはそれほど大きくなく、だからこそ多くのプロセッサが更なるLatency-Tolerantを求めてMulti-Threadingに走っている事を考えると、本命なのは74Kの後に登場するMT ASE搭載プロセッサなのかもしれない | 【図13】MIPS32 24Kコアとの比較。74K向けにコンパイルし直した場合とし直さない場合で性能差はごく僅か、というのは構成を考えれば妥当だろう。ただ今後、例えばALUがDual-Issueとかになったらまた話は変わってくるかもしれないが。ところでEEMBC 1.1のスコアだが、どのテストなのかが不明だ。EEMBCでVersion 1.1なものにはAutoBench(自動車)/ConsumerBench(コンシューマ機器)/Networking(Networking)/OABench(OA Application)/TeleBench(Telecommunication)がある。MIPSのUsage Modelを考えるとConsumerBenchかTeleBenchあたりだと思うのだが、今回そのあたりは明確にされなかった | 【図14】32KBのInst/Data Cacheまで込みで2.5平方mmで収まり、1.8 DMIPS/MHz、1GHzオーバーなのは立派といえる。性能や消費電力もさることながら、元になったMIPS32 24Kcのコアが、130nmプロセスでは7.3平方mm。対して65nmプロセスを使う74Kcで1.7平方mmだから、これを単純に130nm換算すると6.8平方mm相当になるわけで、ダイエリアの縮小にも成功している。実際にはトランジスタのサイズと配線のサイズの比が変わるから、これはあまりに単純過ぎる比較だが、無駄に大きくなったりはしていないことが推察できる |
●Parimics IPE/PPE
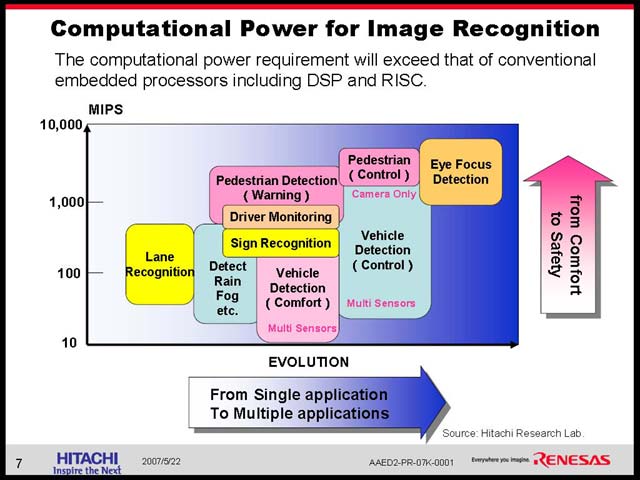
さて、今回のMPFの中の白眉(?)と個人的に感じたのがParimicsのIPE/PPEという画像処理プロセッサ。ターゲットとなるのは、超高速画像分析だ。画像処理、というレベルで言えば最近のGPUは恐ろしく高性能なのは誰もが知っていることだが、分析を行なえるような機能はない(図16)。その分析とは何か? という実例は、ルネサステクノロジの講演の中にも出てきた。この例ではあくまでもDriver-Assistに機能を限定した話だが、Parimicsのターゲットは完全自律運転だったそうで(図17)、それは確かに難易度が高いターゲットだ。こうしたターゲット、つまり自律運転などを目的とした画像解析に関して、上位層に関してはそれなりに解があるが下位層には解がなく、ここに向けた製品がIPE/PPEということになる。
{kind=link}
 |
 |
| Parimics創立者で、同社副社長兼CTOのAxel Kloth氏。同社の設立は2002年のこと。同氏の経歴をみていると、HotRailのTechnical Advisory Boardsのメンバーなんて話まで出てきて非常に興味深い。しかもその後はMindspeed Technologiesだ。なんというか、MPFが格好の発表の場となりそうな製品ばかりを手がけてきたというわけだ | 【図16】画像分析をするためには、単に静止画の分析だけをしても駄目で、フレーム間の相関を初めとする、さまざまな処理が必要になる。大雑把に1,000倍以上という数字がでているが、ルネサステクノロジの講演の中でも、縦軸が対数になってるあたりから、こうした認識が一般的だとわかる |
 |
 |
| 【図17】ここに出てくるDARPA Grand Challengeとはこれの事。米国防高等研究事業局が主催する、定められたルートを完全自律式ロボットカーで走破するというもの。2004年に初めて実施されたが、この年の完走車は0。以後2005/2006年も実施され、今年は"2007 Urban Challenge"という名前で11月に開催される | 【図18】これはちょっと正確さに欠ける気がする。“Historycally Unsolved Problem”のエリアは、既にさまざまな処理の技法が確立されている。ただ問題は、自律運転を可能にするだけの画像解析に必要なスピードを到底実現できなかったことだ。DAPRA Grand Challengeに要求されるレベルはわからないが、ちょっと似たものに航空機のFBW(Fly-By-Wire)がある。最初に搭載された量産機はGeneral DynamicsのF-16と記憶しているが、この機体は負の安定性を持っており、これをFBWで常時補正する形で飛行が可能だった。これを可能にするため、FBWは数msオーダーで補正を掛けていた(最近もまだこのレベルなのか、は筆者は知らない。初期のF-16A/B Block 10における数字だ)。車の場合は負の安定性ということはないから、もっと補正周期は長くていいのかもしれないが、30fps程度で足りるとは思えない。実際、後のスライドでは10,000fpsとかいう数字が出てくるところを見ると、数ms未満のオーダーで補正を掛けている可能性もありそうだ。この短い周期でデータを取り込んで処理する方法が今までは無かった、というのが正しい表現だろう。逆に上位層は汎用プロセッサでも(処理性能的には)間に合うだろうが、自律運転というロジックはまだ未知の分野であり、処理技術が確立していないと考えるべきだ |
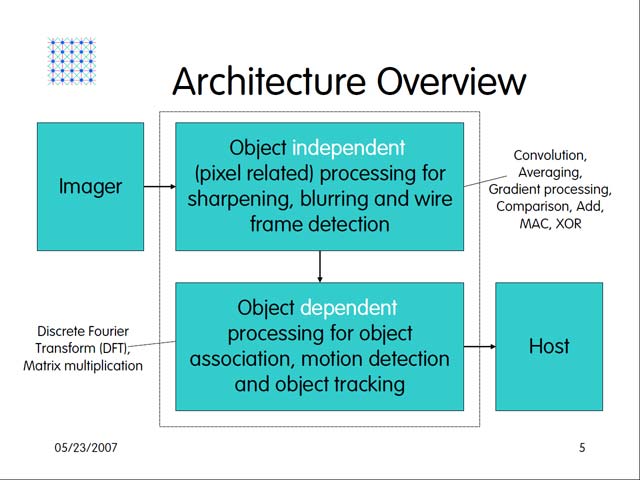
構造的にも、やはり2つに分かれることになる。入力された画像はまずObject independentな処理を行なうIPEで下処理され、この結果がObject dependな処理を行なうPPEで加工され、最終的にはObject Dataの形で出力される(図19)。そのIPEとEPPだが、Atomic Processing Engineと呼ばれる小さな処理エンジンが9つで1セットとなり、これがArray状に3次元的に接続される形で構築される。IPEは実に76,800個、PPEは内部に512個のプロセッサを集積しており、ある程度は数で勝負というのが基本的スタンスであることは間違いない。
ただ、数で勝負といっても、それがうまく協調して動作しなければ意味が無い。IPPに関しては、Atomic Processor同士の干渉を無くすようなTDM(Time Divided Multiplex:時分割多重)のinterconnectでこれを解消し、PPEは自動的にロードバランシングを行なうことでこれに対処している。具体的に、IPEがDRAMからデータを読み込んで処理する過程を示したのが図22のスライドショーだ。
 |
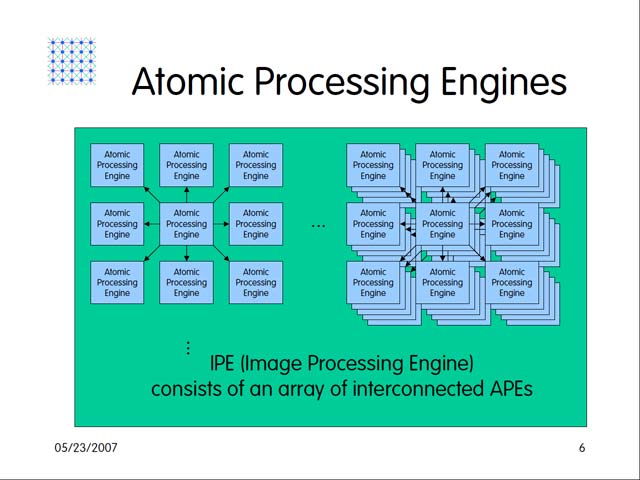 |
| 【図19】この図ではIPPとEPPが繋がっているように見えるが、実は別チップ | 【図20】実はこのあたりがいまいち良くわからない。この図を見る限り、あくまでも9プロセッサで一組なのだが、実際は縦横にもっと多数が協調できる仕組みになっているのかもしれない |
 |
 |
| 【図21】このIPPの説明は、どこかMIPS32 74KのStall-free pipelineを連想するものがある。ではIPPの場合、このNon-blocking性を確保するために何を犠牲にしたのだろうか? | 【図22】8回のデータ転送を、20cycleで実施している仕組み。メモリもまた二次元構成になっているのがちょっと面白い |
このAtomic Processorは非常にシンプルなRISC構成で(図23)、しかも多数のプロセッサの連携を考える必要が一切ない(図24)という、これだけ見ればプログラマにとって天国のような話だが、これがどこまで実現できているかは微妙な感じだ。
 |
 |
| 【図23】8086-typeというあたりで、トランジスタ数は数万個(8086は29,000個)と想像される。8086-typeのPrimitiveなRISCというと、台湾RDCのR2000(80186互換RISC。最近このシリーズは廃止され、周辺機器まで搭載したR8800シリーズに置き換わった)をつい連想しがちだが、別にIPPやEPPでx86命令が動くという意味ではない。IPPに外部メモリが不要というのは、処理が単純なので内部のバッファだけで処理が完結するという事だろう | 【図24】逆に言えば、こんな規模で集積されるプログラムの連携を人手で処理してたら、永遠にプログラミングが終わらない事になりかねない。ただ、だから「一切Parallelismに考慮しなくて良い」と言えるのかどうか? ProcessorがきわめてPrimitiveで、使えるリソースも限られているという状況で、複雑な画像処理(例えばエッジ強調なんてのもその1つだ)をプログラミングするのは、意外に難物な気がする。というのは、これらは隣接ピクセルとの差を比較するアルゴリズムになるわけで、普通は並列化をある程度考慮しないと無茶苦茶Blockingが起きやすくなるからだ |
さて、会場を仰天させたのはここからだ。まずIPEの構成だが、10,000fpsの処理が可能な代わりに、消費電力はフルロード時で100W近く(図25)。しかも実際にはこのIPP、複数を接続して使う事が考慮されている(図26)。ダイサイズは65nmプロセスを使っても400平方mmを越える代物(図27)。一方のPPEはAtomic Engineの数こそ少ないが、倍精度浮動小数点演算が可能になっており、倍精度で40GFlopsを安定して出せるとしている(図28)。こちらはさすがに複数チップを繋ぐことは考慮していないが(図29)、ダイサイズはそれでも264平方mmだから、小さいとは言いにくい(図30)。
とりあえず現状ではシミュレーションと物理設計までは完了したとしているが(図31)、DARPA Grand Challengeはともかく、一般的な用途には到底使えない。実際会場では「2つ合わせて200Wもの消費電力を費やし、しかも10,000fpsもの解析能力があるプロセッサで何やるんだ」という至極もっともな質問が飛び出した。
「200Wではない。IPPが4つにPPEなので、合計500Wだ」という更に斜め上の回答がまずあった上で、「我々は例えば医療機器分野に応用できないかと考えている。体内の血流とかをトラッキングするのは非常に大変な話で、データ量も多いし精度も必要だ。こうした分野ではこのチップが使える」とKloth氏は語っていた。果たして現実にこれが登場するかどうかは非常に微妙な感じで、Lower-performance向けの製品がむしろ先行するのかもしれない。
 |
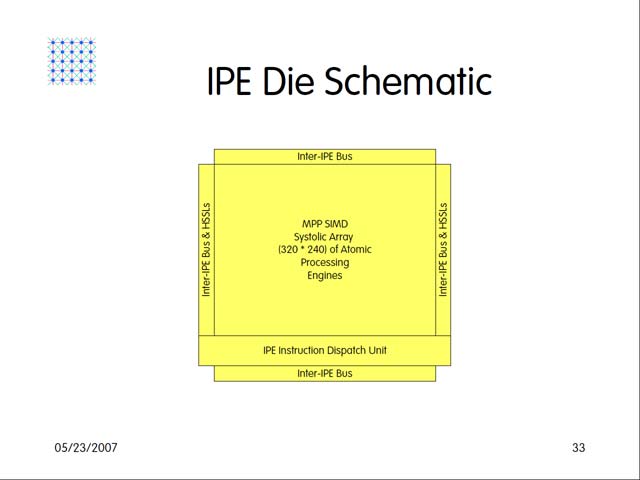 |
| 【図25】この数字もすごいが、5GB/secというI/Oスピードも強烈だ。これに入力できるカメラというのは、どんな代物なのだろう? | 【図26】ダイ中心部には76,800個のAtomic Processing Engineが並び、その4方をInter-PPE BusのI/O Padが取り囲むという、ちょっと怖い構成 |
 |
 |
 |
| 【図27】R600のダイサイズですら420平方mmで、しかもこれは80nmプロセスの話。65nmプロセスで400平方mmを越えるプロセッサはこれが初めてではないかと思う。Design ChallangeとしてまずAPEを最適化し、ついでサイズとInterconnectの最適化を図る必要があるとしているが、それにしても20億トランジスタとは……もっとも20億を76,800で割ると、たかだか26,000程度だ。他にもInterconnectやI/Oに割く分を考えると、APE1個あたりのトランジスタ数は20,000個弱といったあたりか? | 【図28】160 ObjectのMotion Vectorを10,000fpsで判断可能としているが、もはやこうなるとどう判断したものか | 【図29】ダイのほぼ半分はDFTや行列演算ユニットが占める。まぁ倍精度で40GFlopsといったら、その演算回路の面積は半端でないだろう。 |
 |
 |
| 【図30】動作周波数が400MHzに上がっているあたりが、IPPとのもう1つの違い。それにしてもこちらは10億トランジスタだ。半分はキャッシュとData Dispatchに取られるとして、5億トランジスタを512個のAPEで費やしてるとすると、1 APEあたり100万トランジスタ弱。倍精度であることを考えれば、こんなものなのかもしれない | 【図31】60~100fps程度ならば、例えばIPEのAPEを1,000個程度に抑えられるだろうし、PPEも50個前後で済むだろう。そうするとPPEとIPEを合わせて、65nmで100平方mm以下に押さえ込むのはかなり現実的だろうし、もっと小さくできるかもしれない。無意味に高い性能はかえって使いにくいというのはCellの時にもあったが、今回は更に性能が上だ。よくこんなものを考え付いたなぁ、というのが筆者の偽らざる感想だ |
●最後に
 |
| IntelのBob Jackson氏。MPF 2001では“Future Intel Mobile PC Processors”なる講演を行なっており、Mobile Pentium 4とBaniasの話に触れていた。当時の肩書きは“Principal Engineer, Mobile Platform Group”。IDFで、Ultra Low Voltage Pentium IIIが登場したときに説明を行なったのが、やはりJackson氏だった |
以上で筆者のMPFレポートは終了だ。毎年、だんだん規模が小さくなる方向にあるMPFだが、遂に今年は米で年1回になってしまった。もともとは毎年秋にMPFが開催されており、ついで2003年からEPF(Embedded Processor Forum)が春に併催され、2005年からは春がSPF(Spring Processor Forum)、秋はFPF(Fall Processor Forum)に改称したが、今年は1回のみの開催ということで、再び名前がMPFに戻ってしまった。幸いMPF Japanは今月19日から開催されるが、ちょっと縮小傾向が止まらないのはさびしい限りだ。
終わりにちょっとだけ余談を。携帯機器向けの省電力プロセッサなどで、毎回質問に立ってコア電圧とTDPをしつこく聞いていたのがIntelのBob Jackson氏。「今は一体何やってるんです」と聞いたところ、案の定「初日にMark BohrがLow Power Mobile Processorの話してただろ。あれだよ」という返事。Low Power IA and Technology Groupに所属されているそうで、なるほどIntelはこのマーケットを真剣に考えているんだなぁ、としみじみ思った一幕だった。
□Microprocessor Forum 2007のホームページ(英文)
http://www.in-stat.com/mpf/07/
□関連記事
【2006年2月7日】MIPS、マルチスレッディング対応の32bitコアファミリを発表
http://pc.watch.impress.co.jp/docs/2006/0207/mips.htm
【2005年5月24日】【SPF】さまざまなDSP搭載プロセッサ(その1)
http://pc.watch.impress.co.jp/docs/2005/0524/spf05.htm
(2007年6月4日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 [email protected] お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.