
|
Spring Processor Forum 2005レポート
~さまざまなDSP搭載プロセッサ(その1)
カンファレンス会期:5月17日~18日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
Cellのレポートでも触れた通り、ここのところの組み込みプロセッサのトレンドは“General Purpose Processor+DSP”の組み合わせである。端的に言えば、負荷の重い処理はDSPに実施させることで高スループットと低消費電力、低コストを実現し、全体の制御やOSの実装などDSPに向いてない処理は汎用プロセッサでカバーすることで柔軟性を持たせようという方針である。
このDSP+汎用プロセッサという組み合わせは、例えばここ数年のHDDのコントローラは例外なくこのパターンになっている。そんなわけで、全体の発表を通してこの汎用プロセッサ+DSPの組み合わせの製品をいくつかご紹介したい。
●MIPS32 24KE
 |
| MIPS Technology, Engineering ManagerのChinh Tran氏 |
このところあまり元気が無いMIPS Technology。ローエンドからはARMに追い立てられ、ハイエンドにはPowerPCが進出してくるという板挟みにあって、最近では次第に適用事例が減りつつあるというつらい立場にある。そうした中で今回MIPSはDSPを搭載した「MIPS32 24KE」を発表した。
実は2004年のFall Processor Forumで、MIPSは「MIPS DSP ASE」(DSP Application-Specific Extension)を発表している。この時発表された内容はまだ概略というか、DSP ASEを搭載することでいくつかのアプリケーションでは大幅に性能が向上する(と見込まれる)ことをもっぱらアナウンスしただけに終わったが、今回はもう少し踏み込んだ内容となっている。
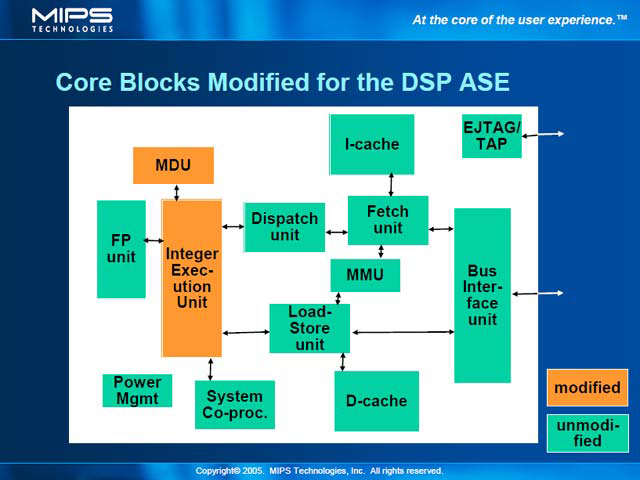
まず基本的なDSP ASEのポジションを明確にしておこう。RISC、つまりMIPS32コアはそのままに、DSP ASEの持つ演算機能のみを統合したのが今回の24KE Coreということになっている。ここでMIPSが特に強調したのは、このDSP ASEの搭載は既存のMIPS32コアを最大限に活かす設計になっていることだ。
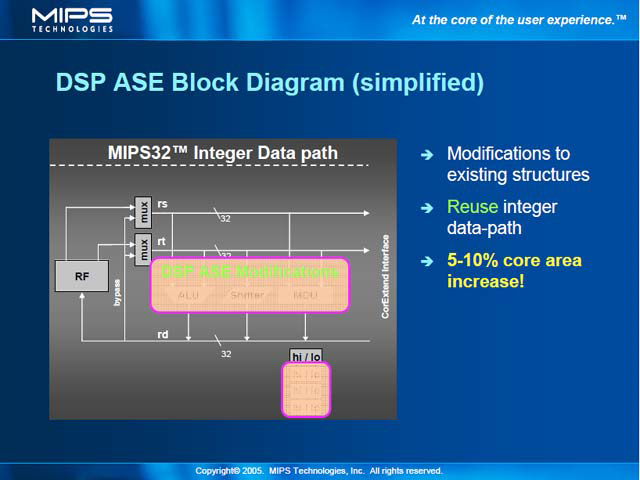
具体的に言えば、DSP ASEの搭載はIEUとMDUの変更のみで実現されている。IEUの内部では、ALUやMCUなどの演算部は変更を受けているが、データパス自体は共用する形になっている。この方式のメリットは、ダイサイズの増加を最小限に抑えられることだ。
 |
 |
 |
| DPSのうち、CISC命令フォーマットに関しては未サポートである。もっとも後述するように、MIPS32命令とシームレスに混在できそうなので、CISC命令をサポートする必要性はあまり無いというのも事実だろう | こちらはSPFのプレゼンテーションではなく、MIPS Technologyのサイトに掲載されている「業界標準MIPSアーキテクチャ上のデジタル信号処理機能」よりの抜粋 | こちらも同様 |
スライド「DSP ASE Block Diagram(simplified)」にもあるように、5~10%のダイサイズ増加で済んでいるので、DSP ASEを載せることで大幅にコストアップすることを避けられる。その反面、性能面では多少のデメリットもある。この構造はちょうどx86のALUとMMX(やSSE/SSE2/SSE3)の演算器が共用になっている構図に近い。
結果としてMIPS32コアとDSPコアは同時に動かせないし、仮に動かせたとしてもデータパスを共用している関係で、こちらがボトルネックになる可能性がある。要するに、DSP処理をオフローディングし、間にほかの事をやりながら待つという動作は非常に難しくなると想像される。
もっともプログラミングの面から見れば、こちらのほうが書きやすいのも事実だ。CellのSPEのように完全に分かれてしまうと、SPEは別スレッドにした上、スレッド同期やデータの同期をアプリケーション(なりOS)で行なわなければならない。対してこちらでは、DSP ASEの制御はMIPS32でシームレスに行なえそう(というかレジスタファイルを共用している時点で、命令発行の時点で両者はシンクロしていると想像される)だし、データももちろん共用できるから、既存のMIPS32環境からの移行は容易だろうし、これはMIPS Technologyの望む路線であったのだろうと想像される。
発表の中では、DSPユニットをいかに既存のALUと結合させるかについて色々言及があったが、こうした事柄は別のDSPコアを搭載してしまえば、それほど難しいものではない。ただMIPS TechnologyのビジネスはあくまでCPUのSoft coreの提供であるため、DSPコアを分けることによるダイサイズの増加はやはり受け入れられないのであろう。MDUなど、DSPコアをベースに作り直して、そこにMIPS32互換機能を入れたほうがおそらく速かったのではないかと想像されるが、あえてそういうことはしていないようだ。
 |
 |
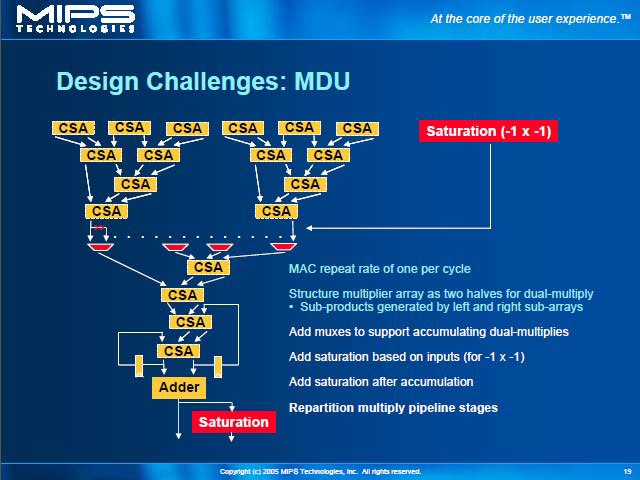 |
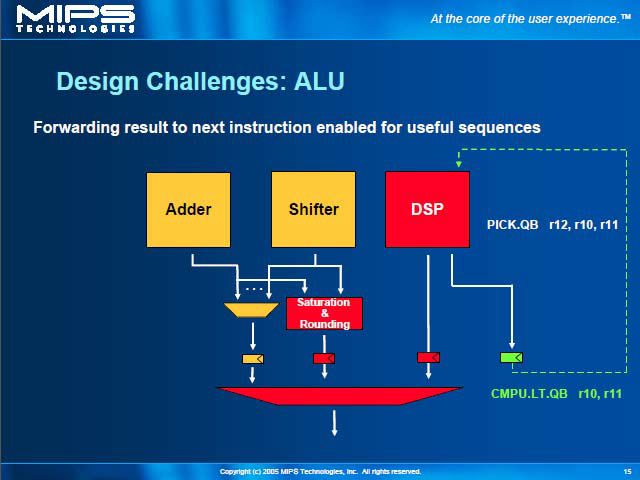
| ALUに関しては、既存の演算器にSaturation/Roundingユニットを加える形で、DSP ASEの機能の一部を既存の演算器で実現していることがわかる | MDUとは Multiply-Divide Unit、つまり乗除算ユニットのこと。行列の内積(Dot-Product)の計算をサポートすると、通常のSIMD演算よりももう少し凝った処理が必要になる | 大規模なMDUの処理の例。こうした複雑な計算の各段で乗算とSaturationの処理を行ないながら、高速にループを廻してデータを畳み込んでゆく必要があり、既存のMDUでは到底実現できないため、結果として大幅に手を入れることになったと思われる |
さてこの24KEは、4種類のコアのラインナップが用意されている。このあたりは既存の24Kファミリーが
「24Kc」:ベースとなるコア
「24Kf」:24Kc+FPU
「24Kc Pro」:24Kc+CorExtend
「24Kf Pro」:24Kf+CorExtend
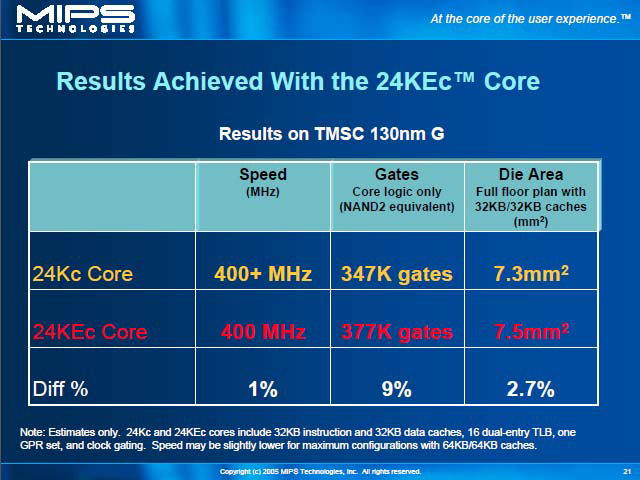
となっていることに倣っており、わかりやすい。で、この24KEファミリーのサイズだが、スライド「Results Achieved With the 24KEc Core」に示すように、ほとんどダイサイズに変化が無いのがわかる。
性能は、既存の24Kcと比べると、24KEでは動作クロックが上げられないのが目下の問題だが、MIPS32コアの性能は同一で、DSP ASEでは最大800MMACSの演算性能を発揮できる。このDSP ASEを使うことにより、特定の処理に関しては倍近くまで性能が上がることが示された。ただ、たかだか2倍というのは、DSPを使ったにしては控えめな結果であるが、これは上述した通りDSPコアとMIPS32コアが並行して動かないことと無縁ではないだろう。
 |
 |
 |
| CorExtendは「ユーザー独自の命令を拡張できる」機能。Verilog RTLなどを使って、ユーザーが勝手に新規の命令を追加、処理させることができる | 同じTSMCの0.13μmスタンダードプロセスを使った場合、多少動作クロックは落ち、ゲート数は9%ほど増えるものの、ダイサイズは(キャッシュを込みにしても)2%程度の差でしかない | 24Kは多くのファウンダリで生産されているから、一般論として0.13μmプロセスならば400MHz以上で動作するということ。Dhrystone値は、MIPS32 24Kコアでは1.44MIPS/MHzに達するという値から算出された推定値であろう |
 |
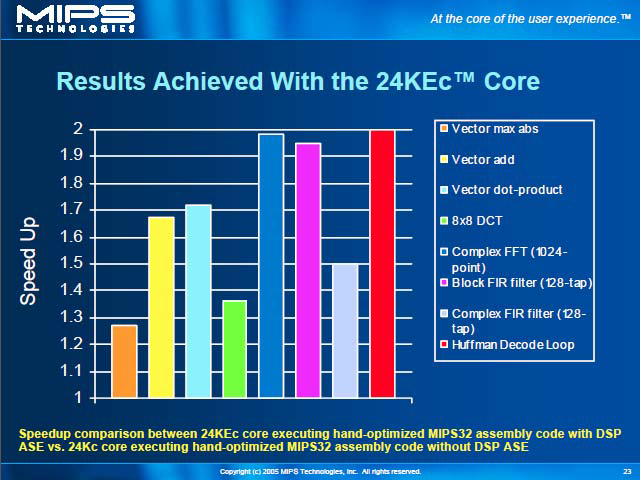 |
| TSMC 0.13μmのG(General Purpose)プロセスでの試作の結果として400MHz動作したという話で、今後は他のファウンダリでの試作も行なわれてゆくと思われる。MACは1クロックあたり2回の演算が可能なことから、400MHzで800MMACSとなる | まだライブラリ群の整備は不十分なためか、テストルーチンはHand Optimizedとなっている。このあたりは今後の課題だろう |
この方式の欠点は、今後の性能改善のヘッドルームがあまり無いことだろう。今回の構造ではDSPコアを複数持たせ、オフローディングで実行させることは非常に難しい。MIPS32コア側もアウトオブオーダー構造に仕立て、ALUとDSPをSuperScalar式に並べればこれらは可能になる。だが、そこまでしなくともそこそこの性能が出るというのがMIPS32の利点であるから、これをやったら逆に回路規模が大きくなりすぎてしまい、むしろ商品価値を損ねることになりかねない。
このあたりをどうするのか、は現状見えてこないが、それでもMIPSコアですらDSPの搭載が必要、というあたりが今の組み込みプロセッサのトレンドを示しているとも言えよう。
●OptimoDEとNEON
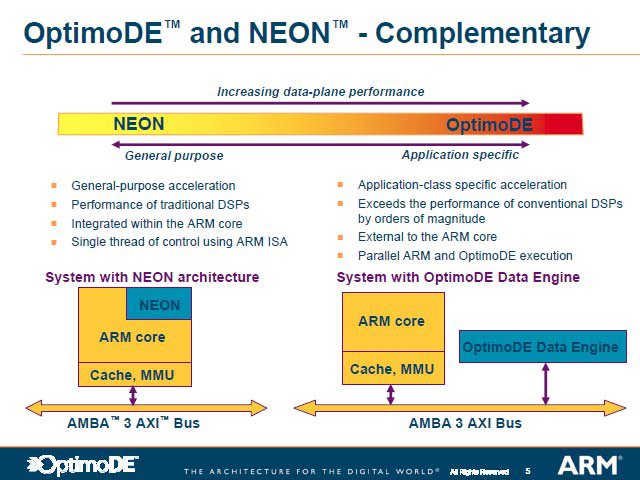
MIPSの不調と対を成すように好調なARM。ARMは2004年春のEPF2004で「OptimoDE」を、同年秋のFPF2004では「NEON」をそれぞれ発表しており、GPP+DSPのソリューションをすぐに提供できる準備ができている。この両者はどう違うのか? という話だが、
OptimoDE:ARMコアとAXI Busで接続される、Outboundな構造。ちょうどCellのSPEのような形になる。こちらはアプリケーションに特化した形でチューニングすることが可能
NEON:ARM Coreと一体になった形で、ちょうどMIPSのDSP ASEとよく似た構造になっている。プロセッサコアからInboundで処理を実行させられるもので、汎用DSPコアとして機能する
という具合に分けることが可能だ。アプリケーション開発者としては、ちょっとしたDSP向きルーチンを高速化させたいときにはNEONを、本格的にチューニングする場合はOptimoDEを使うという形で使い分けを図ることになるだろう。
さて、今回のSPFではGeneral SessionでOptimoDEを使ったポータブルメディアプレーヤーの実現例、Sound SessionではNEONを使っての(やはり)メディアプレーヤーの実現例がそれぞれ示されたので、簡単に触れておきたいと思う。
OptimoDE自体は、(以前の記事にも書いたが)元はAdelante Technologiesが開発した独自のDSPコアで、VLIWスタイルの命令セットを持つものである。この点では、既存のARMとは全く異なるアーキテクチャであり、それゆえコアに統合できなかったという面もあるのだが、それよりもデータパスをアプリケーションに最適化することで、汎用コアよりも性能/消費電力比をより高くすることが可能になるというのがOptimoDEの特徴であり、これを可能にするためにはCPUコアに統合しないほうがチューニングしやすい、という面がある。
 |
 |
 |
| 前半のセッションの発表を行なったARM, Data Engines Division ManagerのSteve Steel氏 | ここではNEONとOptimoDEは排他利用に見えなくもないが、もちろんそんなことはなく、両者を同時に使うことが可能 | OptimoDEの主要な特徴。基本的には昨年のEPFの記事で触れた以上の話はない |
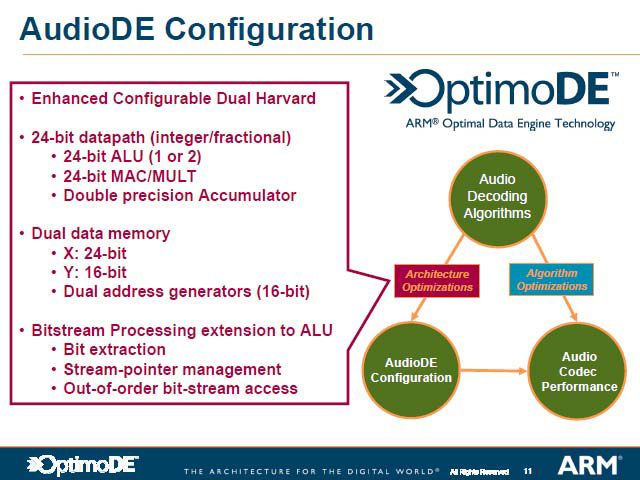
実際今回発表されたAudioDEは、OptimoDEを使ってMP3などの音楽フォーマットのデコードを行なう、ポータブルメディアプレーヤーためのソリューションを構成した例である。この例では、“Reference DSP code”(これは何だ? という話はQ&Aセッションで出たが、回答はなかった。おそらくベタで構成したOptimoDEでの結果ではないかと思う)と比較して、メモリサイズや消費電力を大幅に削減できるというのがARMの主張であった。
 |
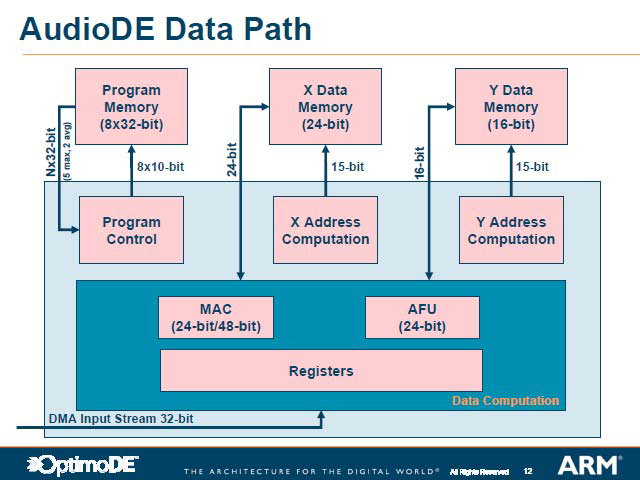 |
| MP3のデコーダの構成例。実数部24bit、虚数部16bitというデータ長はESPICOの分析に基づいたアルゴリズムの産物だが、普通はこんなサイズのデータパスは無いから、16bitパスと32bitパスを併用するか、32bitパスを全部使ってしまうが、これは無駄な消費電力増加に繋がることになる。OptimoDEを使うと、これが避けられる | より詳細な内部データパス。単にデータパスをちょうどの幅にするのみならず、MACやAFUの性能が高く、消費電力も低いことが大きく寄与しているが、それよりも専用ハードウェアと同レベルの最適化を施せる、という点が大きなメリット |
このOptimoDEとは別に、後のセッションでARMはNEONに関する発表を行なった。こちらの発表を行なったのはARMでNEON Technologyのマーケティングの責任者であるTravis Lanier氏で、Steel氏とはポジションや責任範囲が異なることもあってか、微妙に言っていることに食い違いがあるが、それはさておくことにする。
スライド「Bridging the Performance Domains」は、前半のセッションで使用されたスライド「OptimoDE and NEON - Complementary」と近いプレゼンテーションだが、微妙に表現が異なるのが面白い。先には両者の違いが「General Purposeか、Application Specificか」としていたのに対し、こちらでは「Soft Approachか、Hard Approachか」で切り分けている。NEONは、簡単に特徴をまとめるとスライド「ARM NEON Technology」のようになる。MIPSのDSP ASEと異なり、レジスタファイルやパイプラインは分離されている。
 |
 |
| 下のほうを見ると、「Control planeか、Data planeか」で分けていたりして、要するにこの2つのDSP Solutionは色々な意味で対比していることだけはわかる | ベースはARM v5/v6のSIMD命令に近い(つまりOptimoDEのVLIWとは異なる)ものだが、データ長が64~128bitと長いのが特徴。また単精度浮動小数点(32bit)をサポートするのも特徴的だ |
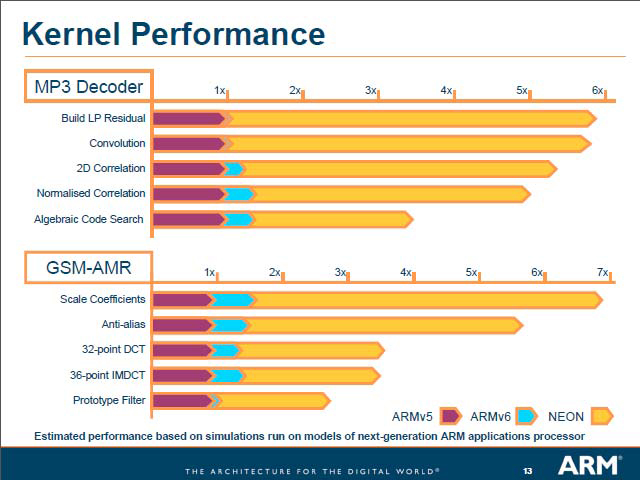
具体的にどんなインプリメントが可能か? という話は専門的過ぎるので割愛するが、例としてはMP3デコードとGMS AMR(3G携帯電話で利用される音声コーデック)をARM v5/v6/NEONで実装した場合の性能予測値が示されたが、ほとんどの処理で3倍以上の性能を示しており、DSPを使うべき処理を汎用プロセッサで処理してはいけない、ということが明確になっているとも言える。
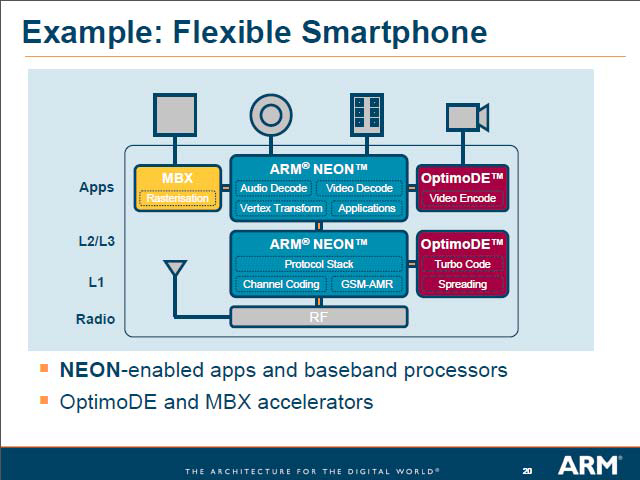
NEONはむしろ、(MIPS DSP ASE同様に)既存のシステムからの移行をなるべく容易にすることに配慮しているようで、アプリケーションから見ると完全にコプロセッサとして扱えるのがわかる。ただ、こうした方式だと性能面で不利になるのは先にMIPS DSP ASEの所で指摘した通り。実際ARMもやはりNEONだけでは力不足だと暗に認めているようで、NeonとOptimoDEを組み合わせたスマートフォンの例が出てきたりするあたり、両者を一番分けやすいのは性能なのかもしれない。
 |
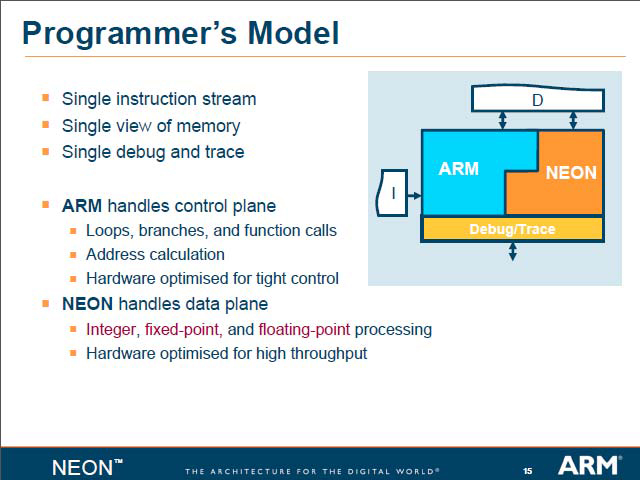 |
| これはあくまでARM v5を基準にした相対性能で、ではNEONならちゃんと使えるだけの性能が出るのか? とか消費電力はどうか? といった話はまた別の議論になる | Single instruction streamという時点で、オフローディングは不可能とわかる |
スライド「ARM Technology Spectrum」は、役割分担に応じたソリューションを示したものだが、NEONはプログラミングこそ容易なものの、性能面ではやはりOptimoDEに一歩劣ると見なしても良いのだろう。
マーケティング的な観点から見たNEONとOptimoDEの区別は大体わかったが、NEONからOptimoDEまでのギャップが非常に大きいのが現時点でのARMのラインナップの弱みだろうか。他のベンダーが付け入る隙があるとすれば、それは1つのアーキテクチャでスケーラブルに性能を上げられるGPP+DSPソリューションが、ARMには欠けていることだろう。
 |
 |
| MBXというのはPowerVRベースのグラフィックコアである | 面白いのはシングルCPUの下にMPCoreやマルチプロセッサが位置すること。つまり組み込みのシーンでは、ある程度マルチスレッド化が進んでいるものの、Critical Threadに関しては引き続きシングルCPUの性能を上げて行くほうがメリットが大きいとしているように読み取れる |
□SPF2005のホームページ(英文)
http://www.instat.com/spf/05/
□関連記事
【5月23日】Spring Processor Forum 2005レポート
~組み込みプロセッサとしてのCell
http://pc.watch.impress.co.jp/docs/2005/0523/spf04.htm
【5月18日】Spring Processor Forum 2005前日レポート
http://pc.watch.impress.co.jp/docs/2005/0518/spf01.htm
【2004年5月24日】大原雄介のEmbedded Processor Forum 2004レポート
ARMがDSP「OptimoDE」を提供
http://pc.watch.impress.co.jp/docs/2004/0524/epf03.htm
(2005年5月24日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c) 2005 Impress Corporation, an Impress Group company.All rights reserved.