
MicroProcessor Forum 2007レポート
画像処理向けReconfigurable Processor
 |
| IPFlex創立者にして、同社取締役兼CTOの佐藤友美氏 |
会期:5月21日~23日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
Reconfigurable Processorは、定期的に話題に上るものである。MPFでもさまざまな製品が何度となく紹介されているし、量産状態に入ったものでも、有名どころでは東芝のMePとか(関連記事参照)米ElixentのET1などがあるし、NECも2002年にDRP(Dynamic Reconfigurable Processor)と呼ばれるReconfigurable Processorを発表、2002年のMPFでも講演を行なっている。
実はこのReconfigurable Processorのマーケットでそれなりに知名度が高いのが、日本のIPFlexである。さらに今回は米Stretchも新アーキテクチャをここに持ってきており、Session 4(Video & Graphics Multicore Architecture)で並んで講演が行なわれた。そんなわけでこの2つをまとめてご紹介したい。
●IPFlex DAPDNA-IMX
さて、最初の講演はIPFlexの佐藤友美氏によるDAPDNA-IMXの紹介である。内容に入る前に、簡単に製品の説明をしておく。
IPFlexは佐藤氏が独自のReconfigurable Processorを作るために作った会社、といっても過言ではない。もともとDAP(Digital Application Processor)と呼ばれる32bit RISCコアとDNA(Distributed Network Architecture)と呼ばれるReconfigurable Processor Array Elementを組み合わせたものがDAPDNAという製品になるわけだ。
このDAPDNAシリーズ、最初の製品は2002年に出荷を開始したDAPDNA-HPで、これに続き2004年には性能を強化したDAPDNA-IIをリリースしている。これに続くのが、2006年にサンプル出荷を開始したDAPDNA-IMSで、これはDAPDNA-IIを画像に特化処理に特化した形で内部を変更した、いわば派生型である。
今回発表されたDAPDNA-IMXは、このDAPDNA-IMSの後継製品に相当する。画像処理に特化、というのは扱えるデータ幅を最大16bitに限ったことを指す。もちろんフルカラーの演算であれば、フルカラーだと24bitとかαチャンネルを入れて32bitという数字になるわけだが、DAPDNAがターゲットとしているマーケットは画像処理などであり、なので8~12bit/pixelのモノクロ映像とか、カラー映像でもRGBではなくYUVで、そのYだけを扱うといった具合だ。最近のCPUとはまたちょっと違った世界の話であり、こうしたケースでは32bitをフルに使う事はほとんどない。むしろ16bitにして演算コアを小型化し、その分コアの数を増やしたほうが並列度が上がる、というわけだ。2005年におけるロードマップでは、次のようになっていた。
・DAPDNA-II: 90nmプロセス、166MHz駆動、376個のPE(Processor Element)
・DAPDNA-IMS: 90nmプロセス、200MHz以上で駆動、より多くの16bit化したPE
・DAPDNA-IMX: 65nmプロセス、250MHz以上で駆動、さらに多い16bit化したPE
実際今回発表されたDAPDNA-IMXを見るとプロセスこそ90nmのままであるが、DAPは266MHz駆動のものがデュアル、DNAは955個ものPEが266MHzで動くという事になっており、おおむねロードマップが守られている事がわかる。
最後にReconfigurableについて。DNAは、PEが複数個で形成され、これが個別に動作することで演算を行なうが、このPE同士をどうつなぐか、PEに何をさせるか、といった事を瞬時に切り替えられるのがReconfigurableたるゆえんである。
DAPDNA-2の場合、Configuration Memoryと呼ばれる構成情報を4バンク分持っており、これを切り替える事により1クロックでDNAの動作が切り替えられる仕組みだ。
さて前提知識はこんなところで十分だろう。今回発表されたDAPDNA-IMXは、従来と同様に富士通の90nmプロセスで製造される(図2)。消費電力などは発表されていないが、かつてのDAPDNA-IIも数Wのオーダーだったことを考えると、劇的に大きくなってはいないと思われる。
DAPそのものは相変わらず5段のパイプラインを持つRISCの模様だ。全体の内部構成は図3のような具合で、BSUが128bit/266MHzとかなり広帯域になっているのがわかる。従来のDAPDNA-IIと比較すると、DAP側にあったDirect I/O(DAPDNA同士を接続する外部インターフェイス)が省かれているのが特徴的だ。
 |
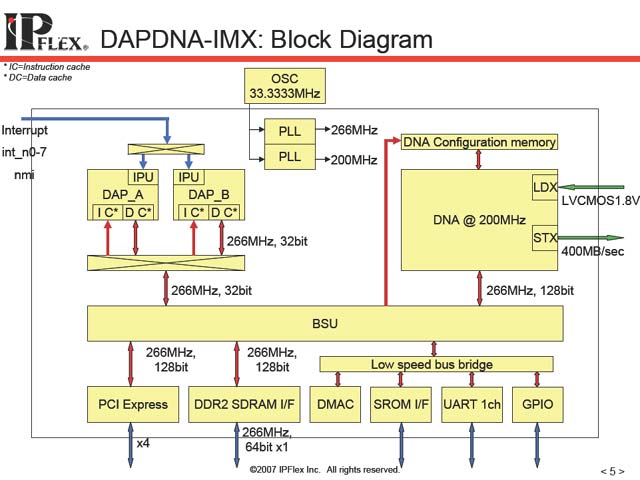 |
| 【図2】ただし高速I/Oを追加したり、メモリがDDR2になったりするなどの違いはあるので、数Wですむとも考えにくいが | 【図3】BSUにDNAやPCI Express/DDR2はいずれも128bit幅で繋がっているのに、DAPは相変わらず32bitのまま、という割り切りがちょっと面白い。128bit幅にすると、相応にDAPの性能を上げねばならず、そこまでの必要性がないということなのだろうが |
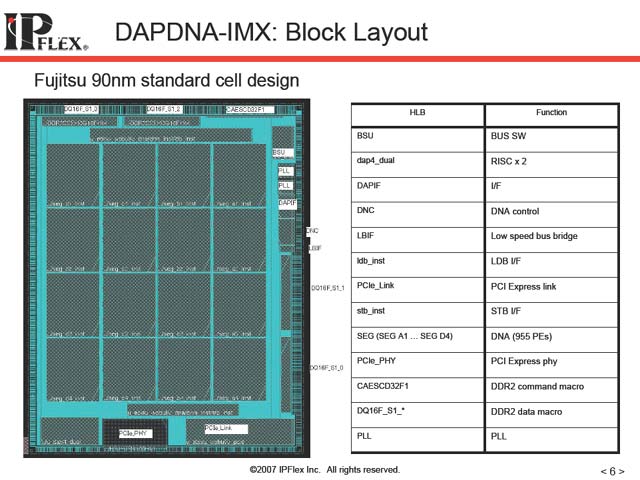
図4がDAPDNA-IMXの内部構成である。中央に巨大なDNAの塊が用意され、周辺I/OやDAPは周囲に追いやられている。DNAが16のセグメントに分かれているのは、さすがに955ものPEをまとめて接続するのは組み合わせが膨大になりすぎるから、という話である。これは単に実装のみならず、これを利用してのアプリケーションの設計にも大きく影響してくる。
そこでこれを16のセグメントに分け、かつセグメント同士をつなぐInterconnectを別に用意する形になっている。これにより設計の複雑さがだいぶ軽減され、後述するDataflowベースのツールでも取り扱える範囲に収まっている。
各セグメントの中は図5のような具合だ。PEはALU/Delay/Memoryの3種類が用意され、各々の役割を交換することはできない。この3種類の組み合わせ方を自由に変えて、必要な処理を行なうというわけだ。そのPEの内訳を示したのが図6である。さまざまなPEが混在する形で配されているのがわかる。
 |
 |
 |
| 【図4】DAP×2はコアの左下の小さな長方形。その横にPCI ExpressのPHYとMACが並ぶ。いかにDAPが小さいか(orDNAが大きいか)がわかる | 【図5】厳密に言うともう1種類、Counter PEがあるが、このプレゼンでは省かれている | 【図6】DLH/DLVというPEが、セグメント間で通信を行なうためのもの。また上辺にはメモリからのロードを行なうLDBが、底辺にはメモリへの書き込みを行なうSTBが配される。こうしたものを除いた、純粋に計算だけを行なうPEでいえば600個という計算になる |
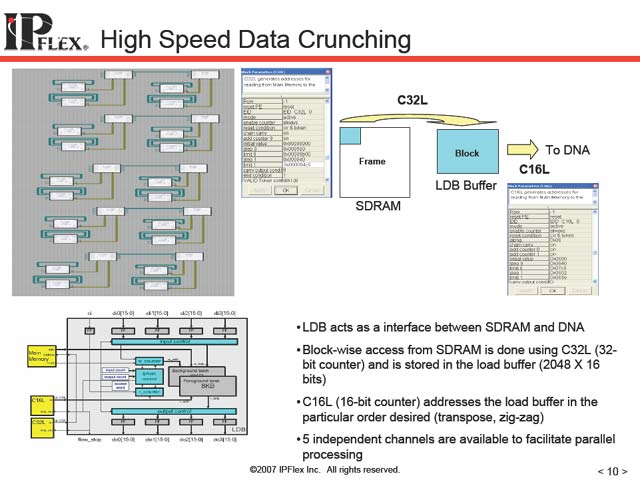
これを使う場合、(先に触れたように)まず各セグメントの構成をDNAにロードしてやり、ついでデータをロードする必要がある。これを担うのがDAPであるが、転送そのものはDNAのもつLDBが行なう形になる(図7)。
さて、こんな形でDNAを動かすとどの程度高速か、という事に疑問に対する答えの1つがこの図8の数字だ。DAPを使うと0.33秒ほどかかる処理が、DNAでは1.5msほどで完了する。実に285倍ものスピード、ということになるが、何しろDAPそのものがそれほど高速とは言えないコアだから、実力としてはやや疑問が残らざるを得ない。
 |
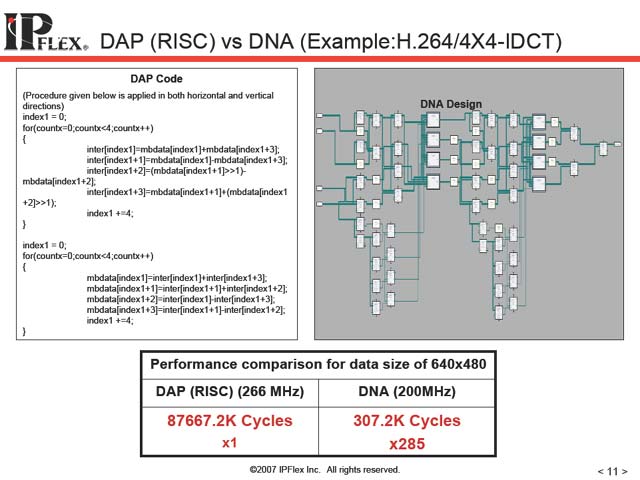 |
| 【図7】なのでDAPは各LDBにロードを行なう指示をまず出す、ということになる(というか、LDBにロードを行なわせるような指示の入ったConfigurationをDNAにロードする、というべきか) | 【図8】H.264のデコードを想定した4×4ピクセルのIDCTの処理での比較。この程度だと、DNAには負荷が軽すぎる気がしなくもない |
そこで、もう少し一般的なコアを使っての比較を行なったのが図9、10である。DAPDNA-2が最初に説明した、2004年に登場したもので、右端が今回のDAPDNA-IMXでのスコアになる。いくつかの画像処理を行なった結果であるが、汎用プロセッサと比較して100倍以上高速な結果になる場合もあることが示されており、またDAPDNA-2と比較してもPEの数を増やしたこともあってか、大きく性能向上が図れるケースがあることが示された。
 |
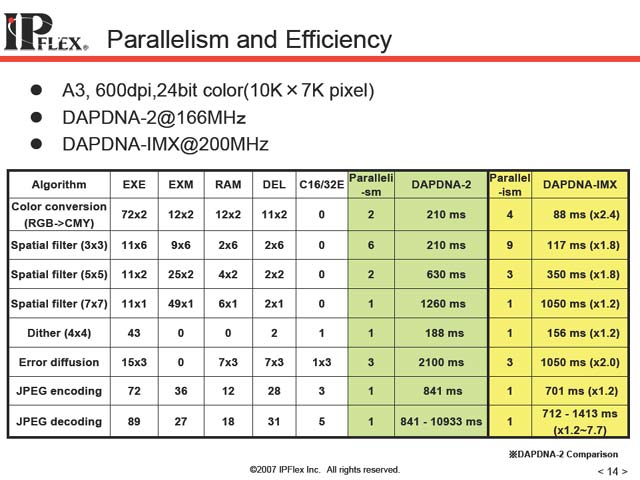 |
| 【図9】これはカラースキャナあたりの処理へのインプリメント例と思われる。意外に誤差拡散の性能がそれほど大きく向上しないのがちょっと面白い。JPEGのデコードが振るわないのは、パラレルで実行できる要素がそれほど多くないためと思われる | 【図10】DAPDNA同士の比較。すべてのケースでParallelismが向上するわけでもないのは仕方ないところだろう |
次に示されたのはこのDNAのプログラミング方法。以前DAPDNA-IIの時にはDNA Designerと呼ばれるGUIエディタとMATLIB/Simulinkを使ってのDesign/Buildがサポートされているという話だったが、今回はこれに関しては触れられず、もう少しコンサバティブな方法が紹介された。
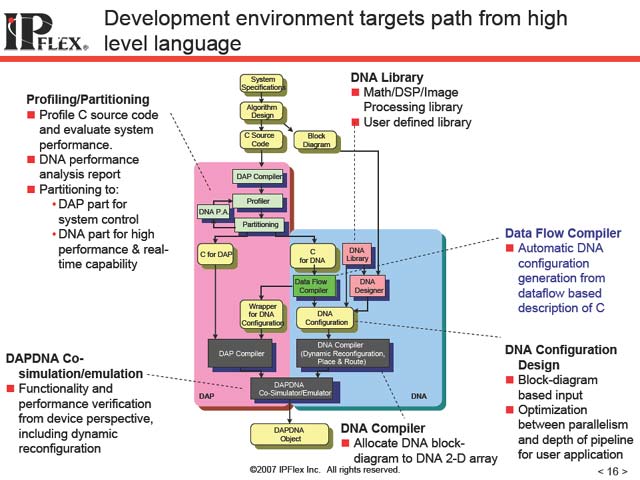
これはDataflow-Cと呼ばれる、同社が独自に提供するコンパイラである。DAPの側にはDAP Compilerが提供されており、まずはこれでDAP側のプログラムを普通に作成する。これと平行してDNA側のプログラムをDataflow-Cで開発、その結果をマージする形でプログラムが完成する(図11)という仕組みだ。そもそもDNA自体が、データの流れを記述する形でプログラミングするというスキームを採用しており(図12)、Dataflow-Cは名前の通りこのデータの流れを記述できるような仕組みを取り入れたものになっていると考えれば良い。
 |
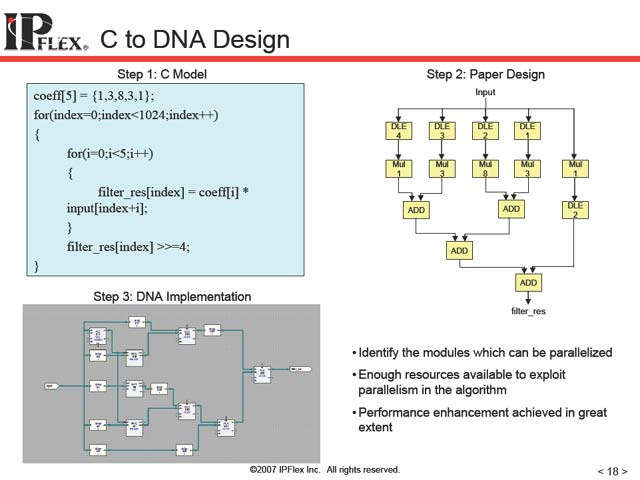 |
| 【図11】DAP Compilerは、以前はGCCベースのものとの事だった。一方Dataflow-Cの方は英Celoxicaの提供するHandel-Cを利用しているという話を以前うかがった事がある | 【図12】Step1は別にDataflow-Cとは関係ない、非常に一般的なCにおける処理の記述。これをPallarelにモデリングし、DNAのインプリメントに落とし込む過程を説明したもの |
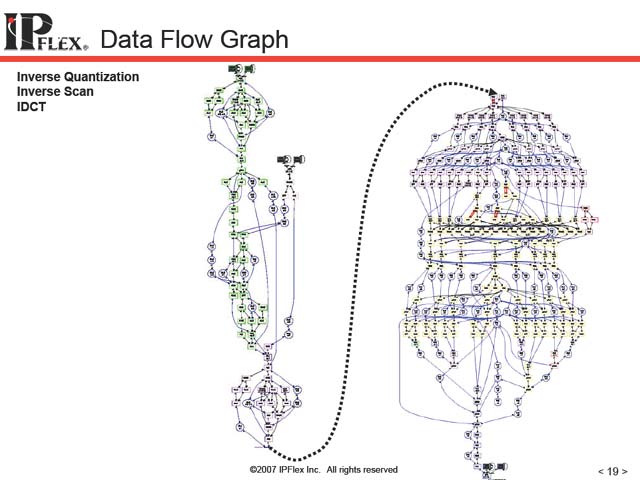
このDataflow、たとえばJPEGやMPEGでおなじみIQuantize→Inverse Scan→IDCTという流れを見てみると実に興味深い(図14)。あちこちに律速段階ができるのは仕方ないとして(これはもともとのアルゴリズムに起因するから避けられない)、IDCTは猛烈に高速化できそうな一方、IQuantizeとかInverse Scanではそれほど大きな期待ができないことがわかる。先に図9でJPEGのデコードがそれほど高速でない結果が示されたが、これを見れば理解しやすい。
ところでこのプログラミングを、先のDataflow-CなどによるDFCデザインツールを使った場合と、ハンドオプティマイズした場合を比較したのが図14だ。性能に関しては明らかにハンドオプティマイズをした方が高速化可能だし、PEも効率的に利用できる。それはいいのだが、開発期間を比較すると倍では利かない、というあたりがこの手のデバイスのプログラミングの難しさを物語っている。佐藤氏はこれをトレードオフだと語っていたが、実際まさしくわかりやすいトレードオフの関係にあると言える。
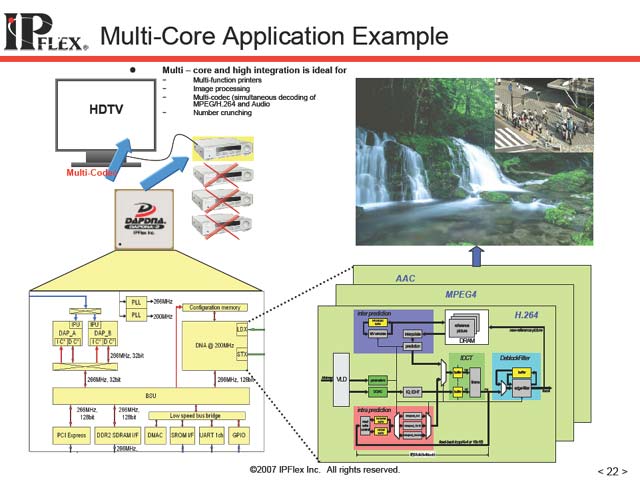
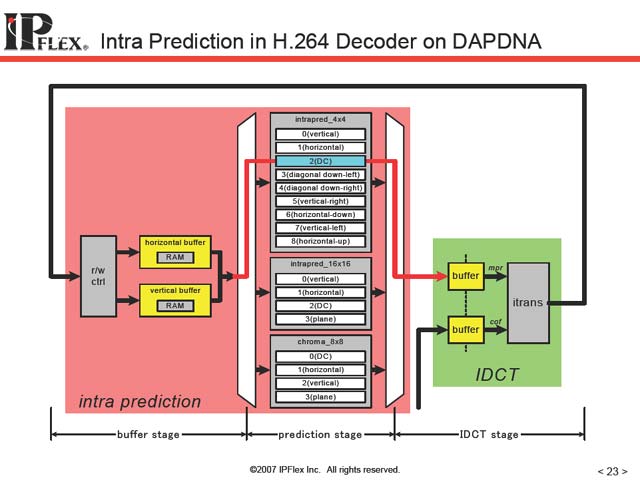
ついで佐藤氏は「Reconfigurable Processorは死んだなどとよく言われるが」などと前置きしながら、実際のアプリケーションへの展開例を挙げ、商用製品に次第に入り込みつつあることを示した(図15,16)。最後に設計上のチャレンジとして4つの項目を挙げて、同氏の講演は終わった(図17~20)。
 |
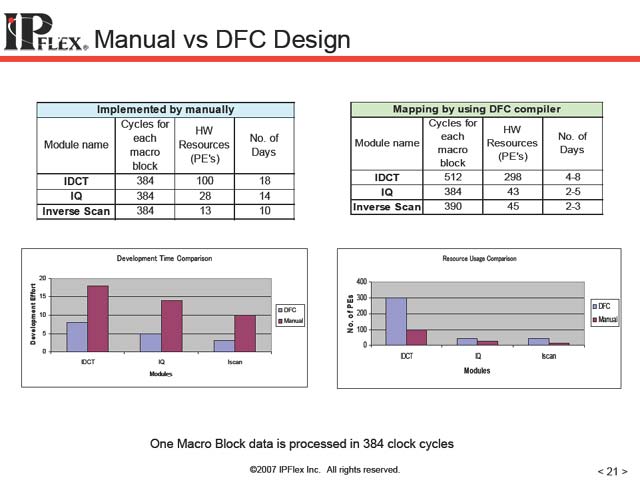 |
| 【図13】並列度が低いと、DNAは単に200MHzで動くプロセッサでしかなく、かつそれほど多機能というわけでないから、汎用プロセッサに比べて性能が激しく落ちる事は避けがたい。このディスアドバンテージと、逆にIDCTの様にうまくマッチングした場合のアドバンテージが相殺する形になっているのが図9の結果、という事だろう | 【図14】こうなると、最初からハンドオプティマイズで開発というのは論外な事が判る。現実的なのは、まずDFCツールを使って全体を構成し、ついでボトルネックになっている箇所を順次ハンドオプティマイズという手法だろう |
 |
 |
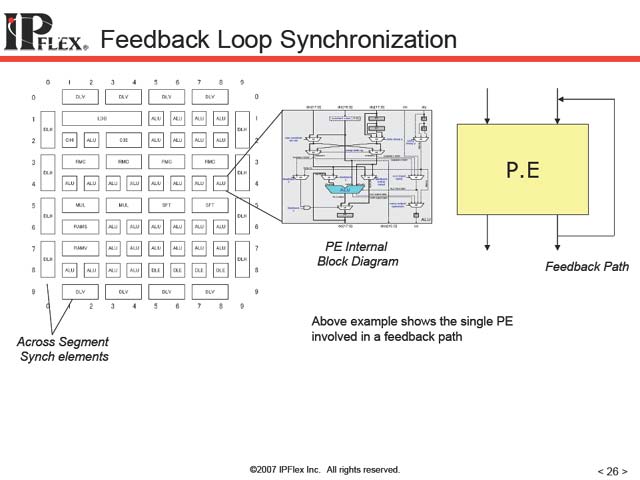 |
| 【図15】HDTVのSTBの例。DAPDNAを使うことで、同時にH.264 Streamを4本扱えるという例。今評価中という話であった | 【図16】H.264の場合、ブロックサイズ自身が複数種類存在する。そこで、ブロック毎に最適化した回路を用意しておき、これをデータにあわせて瞬時に切り替えるといった形で異なるブロックサイズのストリームをデコードするという例 | 【図17】Feedback Loopをいかに作るかが最初のチャレンジ。PEそのものにはFeedback Loopがないし、PE相互をつなぐInterconnectにもこうしたものはない。これをいかに構成するかがちょっとした問題だったのだそうな。Feedbackを必要とする要件は少なくないし、だからといって画一的なFeedback Pathを全てのALU PEに入れれば済むという話でもないだろう |
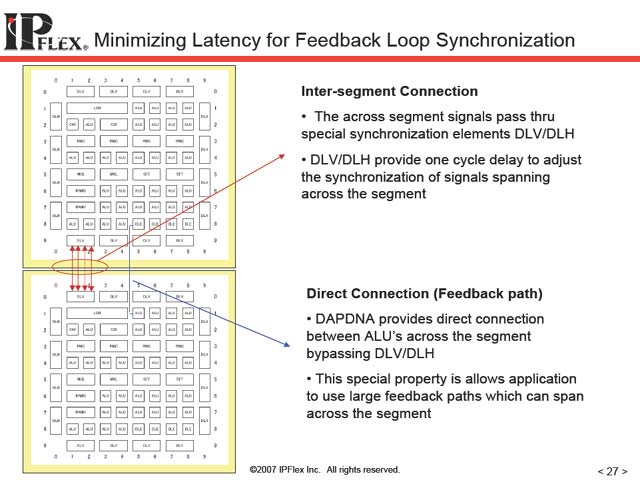 |
 |
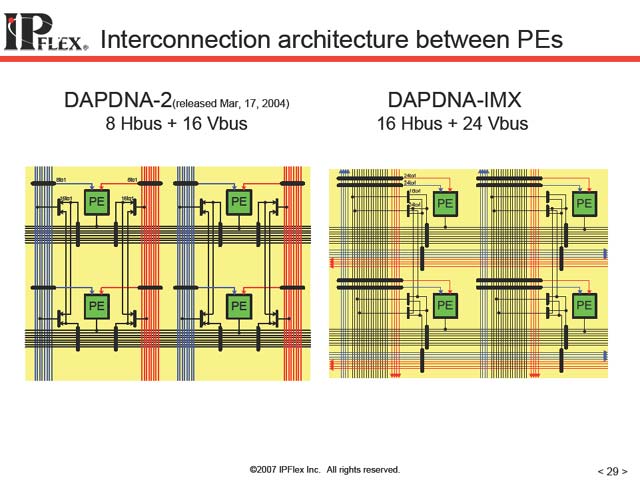 |
| 【図18】上でも説明したが、DNAは全体を16のセグメントに分け、相互をDLV/DLHでつないでいる。どうしても高速な接続が必要な場合には、図17の解であるFeedback専用パスを使ってPU間を接続することになるが、今度はFeedback Pathとして使えるパスがその分減る事になる | 【図19】PE間のInterconnectの仕組み。柔軟性を確保するためには縦横にある程度の本数が必要だし、事実DAPDNA-IMXのInterconnectはDAPDNA-IIに比べて大幅に強化されているが、それでも接続にある程度制約が出ることは避けられない。これ以上増やすと今度はダイの肥大化や、それにともなう遅延の増加になるわけで、これもまたトレードオフである | 【図20】Interconnectの比較。あるいは当初のロードマップの通り65nmプロセスで実現していれば、もっとInterconnectの数は増やせたのかもしれない。機会があればこのあたりを聞いてみたいところだ |
●Stretch S6 Family
IPFlex同様に、Reconfigurable Processorを提供しているのが米Stretchだ。
Stretchは、MPFで第2世代の製品となるS6 Familyのアーキテクチャを発表した(図21)。さてそのStretchの考え方も、IPFlexとよく似ている。特定の処理を高速化するのに、CPU+DSPという組み合わせが効果的というのは、ARMやMIPSなどがこぞってDSPコアを標準化していることからもよくわかる。これに加えてDSPだけを集積化するという組み合わせ(FreescaleのMSC8144などこの最たるものだろう)もありえるし、あるいはDSPにFPGAを組み合わせて高速化するなんていうアプローチにも可能性があるのは、IntelがFPGAにFSB Licensingを提供し始めたことでも理解できると思う。ただ、どのアプローチにも当然一長一短があるわけで、使い分けが難しい事になる。こうしたものを全てカバーするのがReconfigurable、というわけだ(図22)。
 |
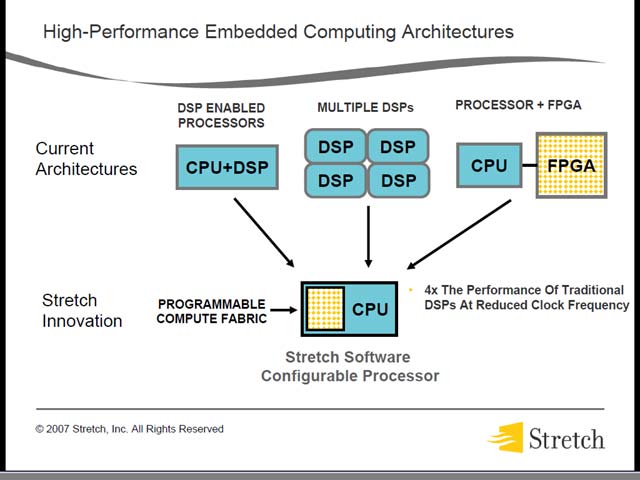 |
| Vice President of MarketingのRobert K. Beachler氏 | 【図22】この主張そのものは、それほど目新しくはない。StretchのみならずさまざまなReconfigurableを提供するベンダーは同じ事を言っている |
そのReconfigurableだが、ターゲットアプリケーションが異なると当然扱うべきデータが変わってくる。従来のStretchのS5はビデオ処理に加えてWiMAXなどの信号処理用途に使われる汎用のものであったが、S6はビデオ処理などに特化したものになったという(図23)。
そのS6 Familyの内容という事になるが、基本構成は図24に示す通りだ。汎用プロセッサとしてはXtensa LXを採用し、この中にISEFという形でReconfigurable Processorを搭載する。更に、これとは別に特定用途向けアクセラレータを搭載し、これらと強力な周辺I/Oを統合する形になる。
 |
 |
| 【図23】このあたりは、IPFlexとよく似た話になっているのがわかる | 【図24】Xtensa LXというのは、tensilicaの提供する、VLIWベースのCPU。内部構成をユーザーが自由にカスタマイズして作成することが可能であり、デザイン後はASICのみならずFPGAでも動かすことが可能となっている |
このCPUにXtensaとかARCのARC 600/700といったコアを採用するのは、この手の製品ではおなじみの手法で、むしろIPFlexのようにスクラッチでCPUを起こすほうが例外と言える。VLIWの命令セットとは言え、開発ツール類もtensilicaから提供されるから、使う上で何か問題になるという事は考えにくい。
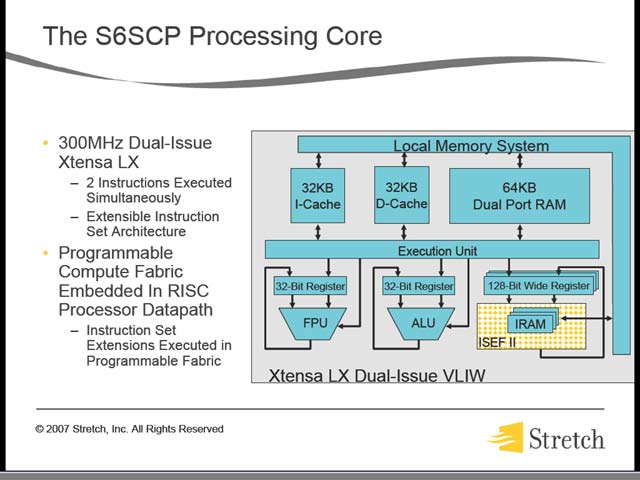
そのCPUの内部構成は図25のようになっている。命令デコードまでのパイプラインは完全にCPUとISEF(Instruction Set Extension Fabric)IIと共用する形で、構造的にはARMにおけるNEON Technologyに近い。そのISEFIIはというと、これもこれでちょっと面白い(図25)。“Primary Uni-Directional Data Flow”とある通り、Feedback Pathなどはまるで考えていないことがわかる。
ただ、必要ならALU側に戻してFeedbackをかけることはできるだろうし、その際のペナルティそのものはIPFlexより小さい(何しろ同じ実行パイプラインの中にある)。また速度を上げるためにさまざまなテクニックが施されている事がわかる。
具体的な構造は図26に示す通りだが、こちらも全体を複数のブロックに分けているあたりはIPFlexにも通じる。面白いのはMultiplier。単体では8bit×16bitのみで、これをカスケード接続することで最大32bit×32bitまでの演算ができる、という仕組みだ。恐らく8bit×16bitというのは各Pixelに係数を掛けるような単純な処理用で、もう少し桁数と精度が必要な面倒な作業の場合にはカスケードで繋ぐといった使い方になるのだろうが、その数がそれほど多くない(全体で64個しかない)というあたりが、逆にCompute Arrayの機能そのものがそれほど高くないことをうかがわせる。
 |
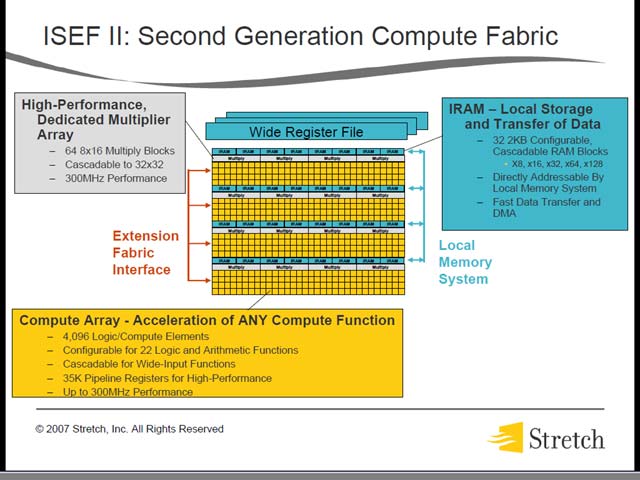 |
| 【図25】VLIWなのでALUとFPU、ISEFは当然同時に動くし、SuperScalarではないからSchedulerなどは無い。シンプルな構造で高いIPCが実現できる、というのがこの手のプロセッサで多く使われる理由だろう。どのみち新製品だから、命令の互換性を気にする必要が無いことも大きいとは思うが。この仕組みのお陰で、理論上はALU/FPUとISEFIIが同時に動くし、同期を取るレイテンシはIPFlexなどよりも遥かに少なくなる | 【図26】1/2 Silicon Footprintとか書いてあるところを見ると、こちらも扱えるデータサイズを32bit→16bitに削減したのではないかと想像される |
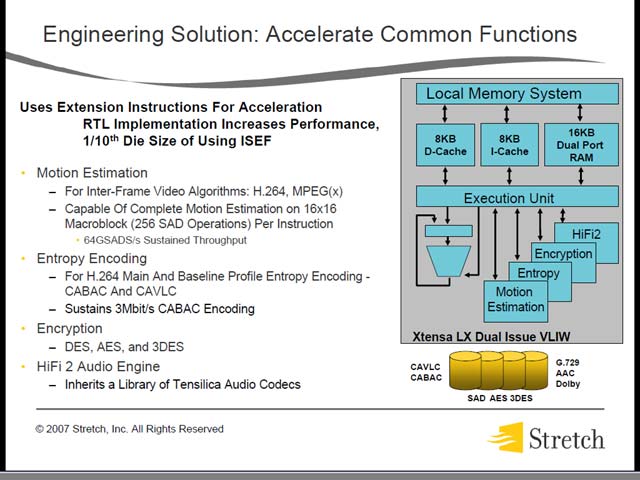
結果として、Reconfigurable Processor Arrayのみで完結できる処理はそれほど多くない事が想像される。それを補うのが、Special Acceleratorだ(図27)。Motion EstimationとかEntropy Encodingなど普通ならReconfigurable Processorに向いているはずの用途にすら専用アクセラレータが用意されているあたりからも、これが伺える。もっともここに関しては、ソフトウェアに関する見通しからくる割り切りもあるようだ(図28)。
 |
 |
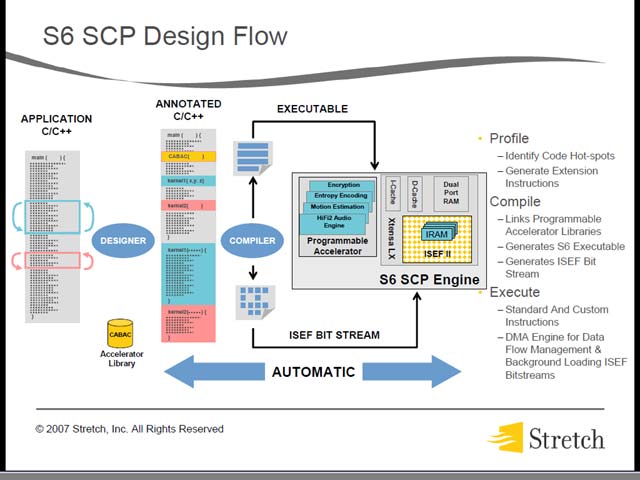 |
| 【図27】Multiplierは利用するトランジスタ数は(特に桁数が増えると)少なくないが、処理そのものは単純である。にもかかわらずこれを専用Element化する、というところから考えると、その他のCompute Arrayにしてもトランジスタ数はそれほど多くないだろうと想像される。恐らくPE単体で比べると、IPFlexのそれと比べて機能的に少ないか、もしくは能力が低いと思われる | 【図28】これらのアクセラレータまでが、ALU/FPU/ISEFII同様にExecution Pipelineの下にぶら下がるという構図は一種異様。VLIWの命令セットがどんなものになっているかを考えると、全体をフルに動かすシーンでなければ高効率を実現するのは難しい様に思う。もっともこれらのアクセラレータが同時に動くことは考えにくいから、VLIWの命令セットはALU+FPU+ISEFII+Accelerator という4命令構成で、そのAccelerator命令の先頭2bitでどのアクセラレータを使うか指定する、といった感じになっているのかもしれない。図29のところでも出てくるが、とにかくReconfigurable Processor Arrayのプログラミングでは、特に最適化は非常に問題になりやすい。なので、専用アクセラレータを併用することで面倒な処理はオフロードし、最適化を容易にするというのは現実的な解ではあるが、何か間違っている気もしなくはない | 【図29】特にReconfigurableのプログラミングは、自動化ツールでは最適化が難しいのはIPFlexの講演にも出てきた通り。にもかかわらず手動ツールが提供されないあたりは、はなから最適化をある程度あきらめてると看做すべきなのだろう。このあたり、DAPDNAとはあきらかに文化の違いを感じる |
「2カ月以内に(ソフトウェアの記述を済ませて)動かせるようにする」というコンセプトがこれを物語っている。これはIPFlexの時にも出てきた議論であり、TATの短縮というReconfigurable Processorの巨大な課題に対する1つのアプローチというか、割り切りなのだろう。このあたりは、開発工程にも見て取れる(図29)。
ALU+FPU+Reconfigurable+AcceleratorなんてVLIW命令セットをハンドアセンブルするのは論外だろうし、それとは別にReconfigurableへのプログラム(VLIWに含まれるのは、あくまでISEFII全体へのリクエストであって、各エレメントで何を実行するかは別にロードするのだろう)を記述する必要もある。そこで、普通にC/C++で命令をまとめて記述し、それを自動変換して実行環境を作るツールのみが提供される。当然こういうケースで最適化を狙うのは非常に難しいわけだが、逆にアクセラレータなどをうまく使えば最適化が不十分でも狙った性能を得られる、という割り切りがここから見て取れる。
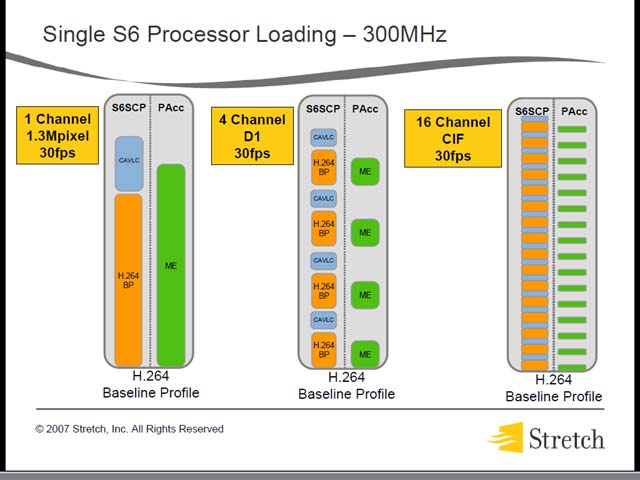
もっとも、それでも必要な性能は得られるとしている。図31はH.264のエンコードの性能比較である。S6単体ではせいぜいHDのH.264 Baseline Profileが1本リアルタイムでエンコードできる程度でしかない(図30)。面白いのは、図31では、その性能よりも、レイテンシや消費電力の低さを主にアピールしていることだ。
 |
 |
| 【図30】1.3Mbpsということは、D3(1,440×1,080)相当か、D4(1,280×720)相当であろう。D1(480i)が4本と同程度の負荷にあたるところから考えると、1,280×720あたりのInterlessかもしれない | 【図31】理論上1フレーム遅れは免れないし(さもないと動きベクトルの検出ができない)が、その後の1フレーム分で全処理をきっちり終わらせる、というあたりが見事である。消費電力については、MEをアクセラレータで実行している以上、これは納得できる数字だ。ただこうなると、MEの精度がどの程度なのかが逆に気になる部分ではある。相当に簡略化した検索をしていそうな気がする |
しかし、絶対性能そのものはそれほど高くないわけで、これをどう解決するか、というと、AIMを使ってS6シリーズを接続するというマルチチップ構成である(図32)。つまり数で勝負というわけだ。実際複数のプロセッサを接続した場合でも、データの流れはハードウェアで自動的に管理される。最大32プロセッサまでをサポートするが、これは「UMA方式を取る場合、32プロセッサがレイテンシの限界」という話であった。面白いのは、データのルーティングはハードウェア側で全てオフロードすることで、プログラムはDestinationだけ指定して送り出せば、勝手にルーティングしてくれるとの話だった(図33)。実際には、たとえば図34のような形でマルチプロセッサ構成をとるが、この際にうまく処理負荷が分散され、効果的に動作するという話だった。
 |
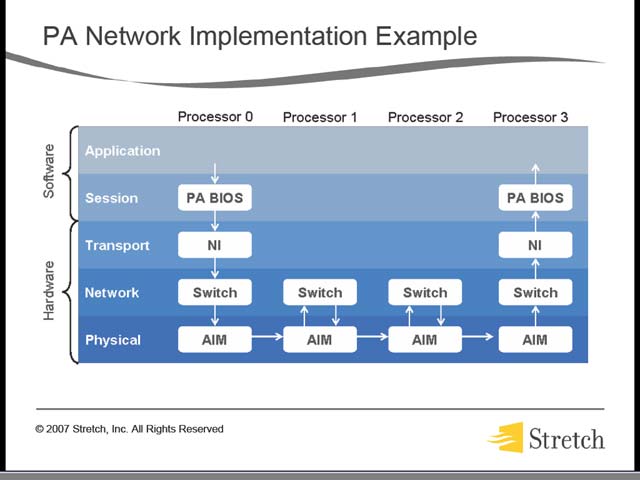 |
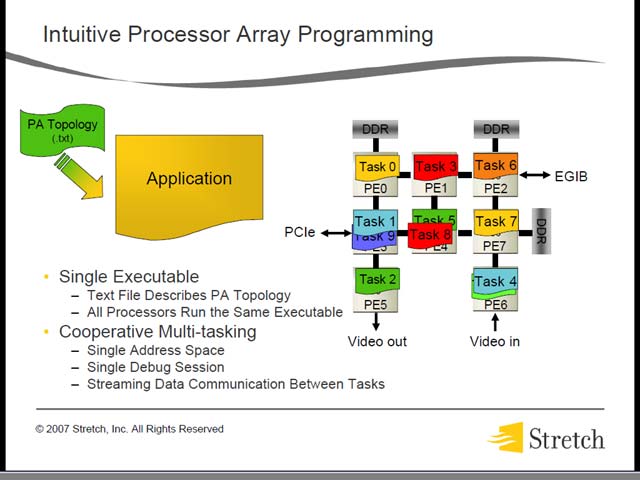 |
| 【図32】プロセッサ間接続のために4チャネルのAIMを用意しており、これで任意のトポロジーでS6ファミリーを接続できるという仕組み | 【図33】勿論これはシリーズで繋いだ場合なので、もっと少ないトポロジーを取ることも可能だ。実際は各プロセッサで処理を分担する形になるから、こんな風にデータを単に転送するということにはならないだろうが | 【図34】この例では、PE3/4/6が複数のTaskを実行することになるが、そこがReconfigurableのいいところで、Taskに合わせた処理の切り替えが高速なので、効率よく実行できるという話であった |
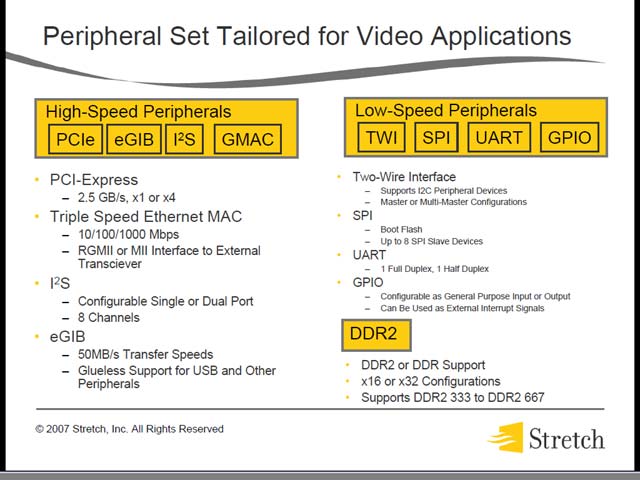
処理能力を活かすためには、当然I/O性能も引き上げる必要がある。このために、Quad Data Port(図35)を持つほか、High-Speed Peripheral/Low-Speed Peripheralや(図36)、強力なDMAコントローラもてんこ盛り(図37)となっている。
 |
 |
 |
| 【図35】一種の汎用I/Oポートだが、10bitモードを持つというあたりがちょっと独特である。4本全部を使えば32bitになるわけで、このあたりの柔軟性はさすが。ただWiMAXへの配慮はS6 Familyで必要なのかちょっと謎。S5 Familyからそのまま持ってきただけなのかもしれない | 【図36】eGIBとGMACを両方持つあたりが面白いのだが、Video EncoderにGMACが必要というケースはどの程度あるのだろう?特にMulti Processror構成では激しく不要な気もするのだが。メモリがDDR-333とDDR2-677の両対応が可能、というあたりが低価格向けを狙っているのが判って面白い | 【図37】これは筆者の経験からくる議論だが、トンでも系プロセッサは一般にDMAが異様に充実しているケースが多い。アプリケーションでの使われ方を整理しきれないとか、本来CPUで管理すべきところを集中管理しきれず、DMAを強化することでこれを補う(DMAを追加するのは簡単だ!)というのが主な理由だが、なんとなくS6にも同じ匂いを感じる |
こうしてみると、IPFlexのDAPDNA-IMXとStretch Inc.のS6 Familyは、共にReconfigurableと言いながら、設計方針がまるで違うことがわかる。
DAPDNAはいわばReconfigurable至上主義。全ての処理をReconfigurableで済ますことを念頭に、それに必要なサポートを周囲のロジックで行なうという方針だし、最適化すればマルチチップなど必要はないといわんばかりの割り切りも、ある種の清々しさを感じる。S6にとってReconfigurableはいわば添え物。一種のアクセラレータと看做している風すらある。これを補うためにその他のアクセラレータやMulti-Chip構成を用意している。当然用途は限られる(本当にVideoのEncode以外には使えない)が、その用途には低コスト(特にソフトウェア開発コストの低減)でソリューションを提供できる。どちらが良いという話ではないが、強いて言えばDAPDNAはいかにも日本的なプロセッサ、S6 Familyはいかにもアメリカ的なプロセッサだと感じた2つの講演だった。
□Microprocessor Forum 2007のホームページ(英文)
http://www.in-stat.com/mpf/07/
□関連記事
【2006年5月24日】【SPF】高性能DSPに対する2つのアプローチ
http://pc.watch.impress.co.jp/docs/2006/0524/spf06.htm
【2006年5月17日】【SPF】ARC Internationalと東芝が戦略的提携
http://pc.watch.impress.co.jp/docs/2006/0517/spf01.htm
(2007年5月29日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.