
|
Spring Processor Forum 2006レポート
高性能DSPに対する2つのアプローチ
 |
会期:5月15日~17日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
無事にSPF2006は幕を閉じたが、まだ全然Embedded周りのレポートが終わっていないので、もう少しお付き合いいただければ、と思う。
初日の“Advances in DSP Engines”では、Element CXIとFreescaleが極めて好対照なアーキテクチャをそれぞれ発表したので、これをまとめてご報告したい。
●Freescale SC3400/MSC8144
Freescaleは今回SC3400、第五世代のStarCoreを気合を入れて発表した。どのあたりに気合が入っているかというと、SC3400そのものをZvika Rozenshein氏(写真01)が、これを使ったMulticore DSPをOdi Dahan氏(写真02)がそれぞれ別セッションで発表するというあたりである。
普通この手の話であれば、1人のスピーカーがまず前半でSC3400そのものを、後半でこれを使った応用製品を示すのが普通で、場合によってはスピーカーが変わることもあるが、2セッションに分かれるのはちょっと珍しい。
 |
 |
| 【写真01】Director, DSP Cores and Platforms, Freescale SemiconductorのZvika Rozenshein氏 | 【写真02】Chief Architect, DSP SoC Design, Freescale Semiconductor, IsraelのOdi Dahan氏 |
さて、そのSC3400である。FreescaleはStarCore LLCからライセンスを受けて利用するが、StarCore LLC自体は元々Motolora Semiconductor(現Freecale Semiconductor)とLucent Technology(現Agere System)が共同出資する形で作られたものだから、そういう意味ではFreescaleに極めて近いポジションにある。実際Rozenshein氏もしばしば“Our starcore……”という表現をしていた。
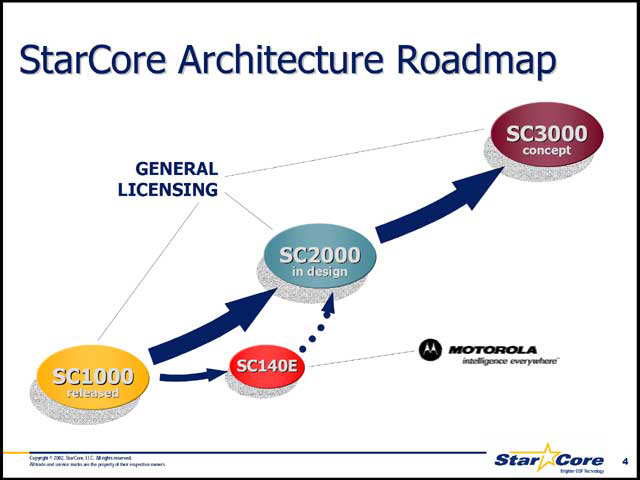
そのStarCore、現在は第四世代までの製品がラインナップされている。第一世代がSC1000(SC100と当時は呼ばれていた)ファミリー、第二世代がSC1200/1400ファミリー、第三、第四世代がSC2200/2400ファミリーとなっており、今回発表されるSC3400は第五世代に相当する。
そもそもStarCoreシリーズの特徴はVLIWを利用したアーキテクチャというもので、最初のSC1000(SC1200/1400のベースとなるコア)は16bit固定小数点演算のみのVLIWで、やはり命令長も16bit+Prefixに抑えられるという独自の構造だった。パイプラインは5段程度で、最大6命令/サイクルの性能を発揮。プロセスにもよるが300MHz程度で動作した(StarCore LLCの“Product Performance”に、もう少し細かい数字が出ている)。もっとも、SC1200/1400の後継であるSC2000シリーズに関しては、それを搭載した製品がほとんど無い、という現状がある。
例えば写真03はMicroProcessor ForumでやはりRozenshein氏が発表した“StarCore SC140e Core-Platform Architecture”というプレゼンテーションのものだが、SC2000と並行してSC1000を拡張したSC140eというコアを発表している。このSC140eはというと、基本的にはSC140のマイナーチェンジといった趣で(写真04)、実際Freescale自体はSC2000ファミリーを自社のディスクリートチップのラインナップに入れていない(写真05)。
 |
 |
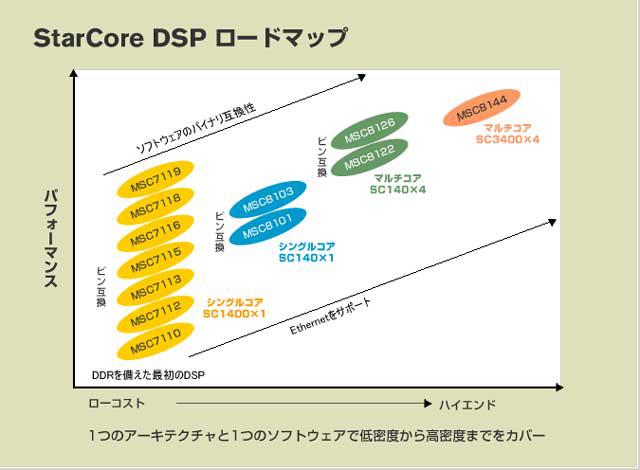 |
| 【写真03】発表当時のRozenshein氏の肩書きはDSP Platforms Development Center, SPS, Motorola, Inc.であった | 【写真04】ソフトウェアのバイナリコンパチビリティは確保したまま、内部パイプラインの見直しやキャッシュ構造の変更などで性能を上げた、というのが大まかな説明として良いだろう | 【写真05】「現在の」FreescaleのDSPコアの製品ラインナップ。こちらのページに示されているものである |
ただ、SC2000自体はStarCore LLCからIPの形で提供されており、これのライセンスを受けているベンダーもあるから、使用例が無いわけではないが、Freescale自体はSC1000ファミリーをマルチチップで搭載する形でパフォーマンスを上げる方向に行っていた。
以上が前提となる話で、ここからがSC3400に特化した話となる。SC3400は第五世代のStarCoreになり、アーキテクチャ自体は前年のFPF2005で発表されており、今回はこれを実装した初めての製品、という位置付けのものである。このSC3400の特徴を一言で表せば、「高速動作による高スループット確保」ということになる。
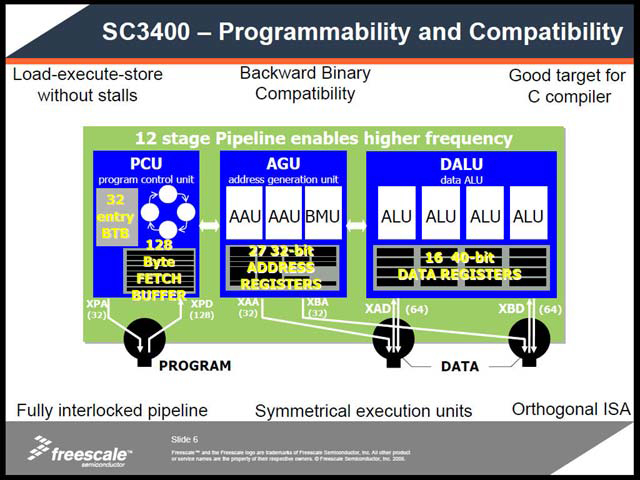
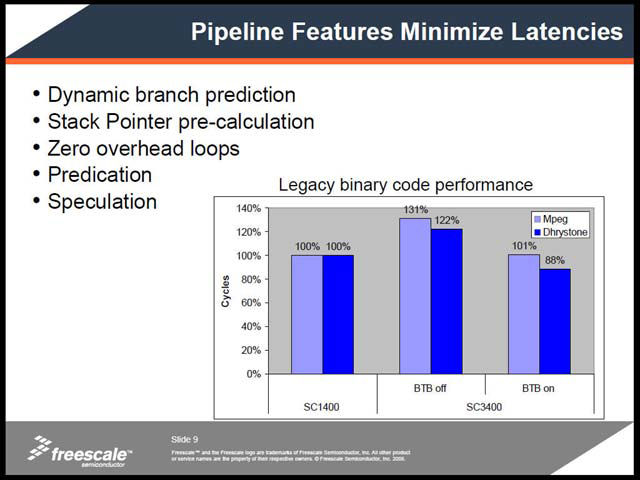
実際製品は1GHzで動作するが、これを実現するためにパイプラインは12段と、ちょっとしたMPU並になっている(写真06)。ところが深いパイプラインは分岐によるペナルティが大きい。これをカバーするために、動的分岐予測を始めとするパイプラインストール防止メカニズムを実装してフォローアップをする(写真07)。
今回の講演の中にはパイプラインの詳細が無かったので、前年のFPF2005で発表された“StarCore V5 Architecture”(発表者はCTO & VP Engineering, StarCore LLCのAmnon Rom氏)の講演からちょっと持ってくると、基本的にはFetch/Decode/AddressGeneration/Executeの各ステージを細分化していることがわかる(写真08)。
 |
 |
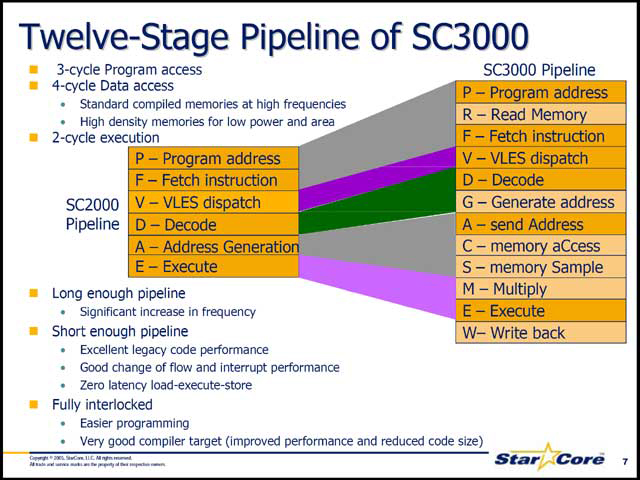 |
| 【写真06】内部構造の詳細。パイプラインそのものは後述するが、BTBやPrefetch付きのPCUと、2種類3個のAGU、それと2セットのALUがDual構成のDALUから構成される | 【写真07】これはBTBの効果を比較したもの。SC1400とSC3400を同じ動作周波数で実行した場合、BTB無しだとSC3400は余分にサイクル数を必要とするが、BTBによりSC1400と同等かそれ以下のサイクル数で処理ができるようになる | 【写真08】“VLES dispatch”というのは、StarCoreの特徴であるVLES(variable length execution set)の解釈のこと。最近のトレンドにあえて逆らった可変長実行セットを採用しており、これにより高効率な実行を可能にするというもの。詳細はこちらを参照。それにしても、VLESのDispatchが1clockで済むのはちょっと意外だった |
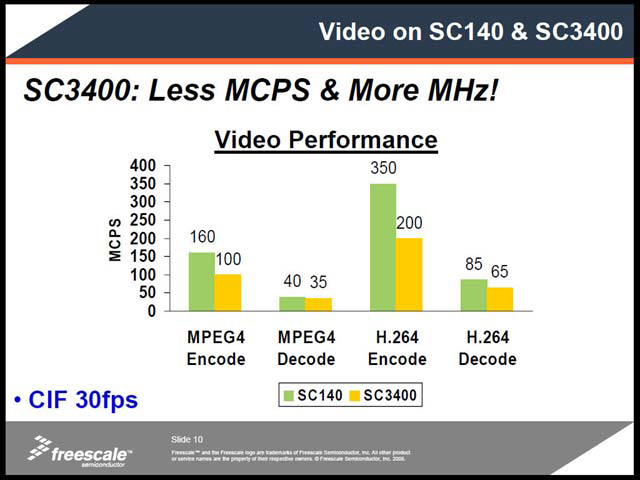
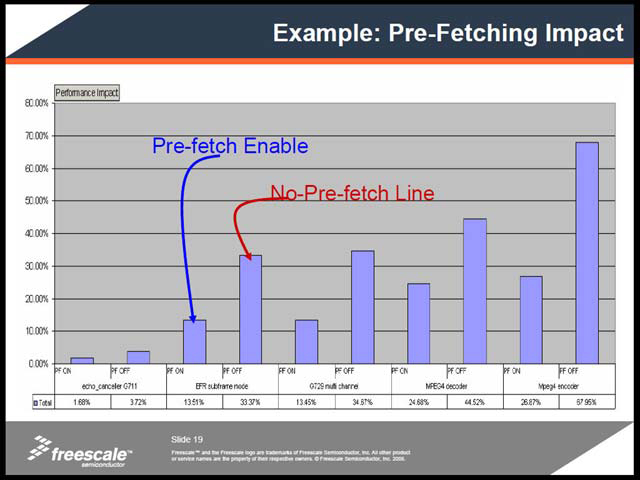
BTBに関しては、もう少し詳細な結果も掲載されていた(写真09)ほか、追加命令の詳細(写真10)なども示されている。もう1度Rozenshein氏のプレゼンテーションに戻ると、これらのパイプラインの強化や、新命令の利用などで、SC3400はSC140と比べて、同じ処理をするのに必要なサイクル数自体が減少していることが示された。また、SC3400上でPrefetchあり/なしでの性能を比較したのが写真12で、Prefetchにより待ち時間が大幅に減ることが示された。
 |
 |
| 【写真09】こちらもAmnon Rom氏のプレゼンテーションより。パイプラインが長くなった関係で、BTBミスの際のペナルティはより大きくなっているが、SC2000/3000は動的分岐予測を搭載することで、ミスの確率を減らしてトータル性能を上げていることがわかる | 【写真10】同じくAmnon Rom氏のプレゼンテーション。追加された命令は合計47で、その大半がOSサポートとSIMD演算関連、というのがちょっと特徴的である |
FreescaleではこのSC3400コアにMMUやキャッシュと周辺回路を集積したTitaniumというサブブロックを構成し、広く利用できるようにした(写真13)、というところまでがRozenshein氏の発表である。
 |
 |
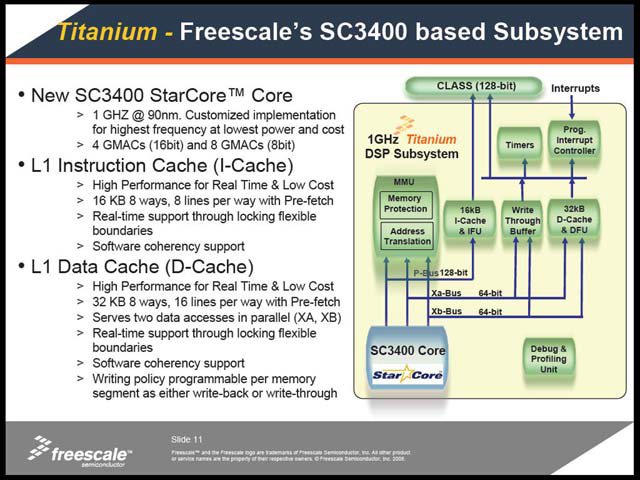 |
| 【写真11】MCPSはMega Cycles Per Secondの略。例えばCIF 30fpsという条件でH.264のエンコードを行なうのに、SC140では350MHz駆動でなければ間に合わないが、SC3400なら200MHz駆動で間に合うという計算 | 【写真12】VoIP関連アプリケーションやMPEG4のエンコード/デコードで、Prefetchあり/無しで処理の待ち(パイプラインストール)が全体の処理時間のどの程度になるか、を比較したもの。当然低いほど高速ということになる | 【写真13】今回はこれに続き説明されたMSC8144が唯一の適用例だが、今後はこれを使ったシングルコアDSP製品や、あるいはIPの形での提供などもありえるだろう |
これを受けてDahan氏が発表したのは、MSC8144 Multicore DSP(写真14)である。ばっと見ただけでもかなりお化け構成なこのチップ、1GHzで動作するコア4つに128KBの共用命令L2キャッシュと512KBのデータL2キャッシュ、10MBのL3キャッシュ(Internal Memoryという呼び方になっている)が搭載され、間がNon-Blocking Fablicで接続されているという代物。おまけにQUICCエンジンやらRapid I/Oやらと周辺回路も豊富で、単独でDDRメモリコントローラが搭載、さらにはVirtual Interruptsまで入っており、もはや無いのはGPUだけといった趣である。
オンチップで3レベルのキャッシュを持つ製品も珍しいが、一応各キャッシュの目的は決まっており、Level 1と2は通常のキャッシュとして、Level 3がコア間のデータ交換用という趣だ(写真15)。ちなみにキャッシュの動かし方でちょっと面白いのは、コンサバティブな使い方(写真16)のほかに、キャッシュ間をDMA転送で動かすという使い方も可能なこと(写真17)。あまり類の無い実装である。
 |
 |
| 【写真14】ここまで入っていたら、普通は制御用に何らかのGPUを搭載しそうなものだが、それをあっさり切り捨てているのがいかにもというか。目的は各DSPコアの初期化や起動、割り込み制御などだが、初期化はともかく割り込み制御は低速なGPUを使うよりもVirtual Interrupt ManagerとDSPを組み合わせたほうが高速、という意思の現れだろうか | 【写真15】一応DDRコントローラがあるので、データ量が巨大な場合にはこれも使えるという話。ただデータL2キャッシュは25.6GB/sec、L3キャッシュでも6.4GB/secで繋がっているのに対し、DDRメモリコントローラは1.6GB/secとかなり見劣りしており、積極的に使うことを推奨しているとは思えない |
 |
 |
 |
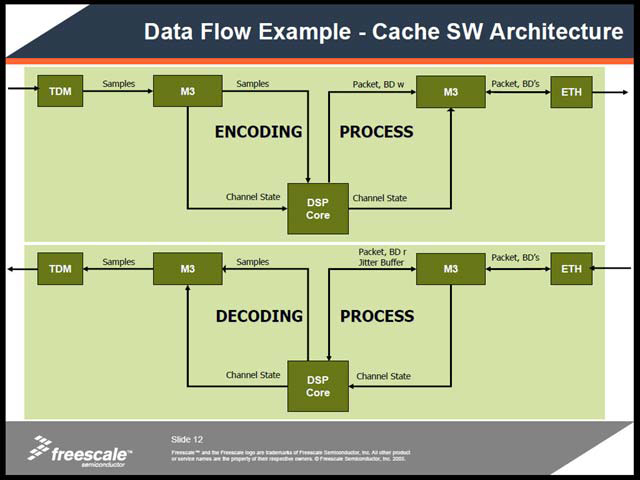
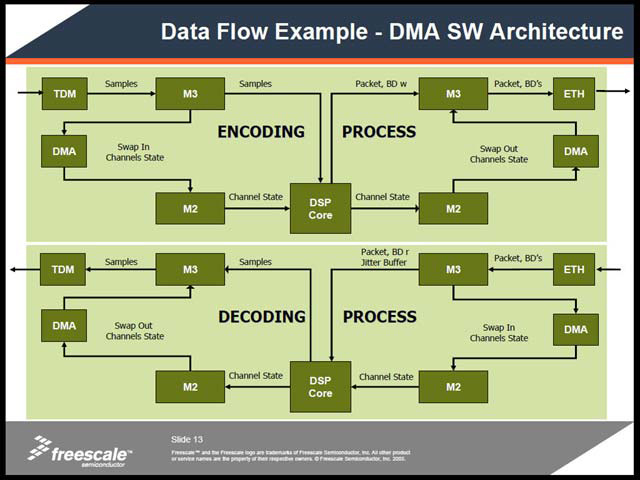
| 【写真16】上はTDMインターフェイスから入ってきたパケットデータを一旦L3キャッシュに格納し、ここからサンプリングをして処理した結果を再びL3キャッシュ経由でEthernetに送り出すという構図。下はその逆パターンである | 【写真17】同じ例であるが、データ量が多い場合はChannel StatusをL2キャッシュから取り込む/M2に書き出す方が効果的であり、この際にL2キャッシュとL3キャッシュ間をDMA転送でカバーする、という話。コアあたり128KB分のL2キャッシュをたとえば64KB×2に分け、ダブルバッファリングの技法を使うといった形だろうか? DSPの処理が多い場合は、これも効果的かもしれないが | 【写真18】これ1枚で、3Gの基地局のCodecが賄えてしまうという代物。実際にはAMRの処理だけではすまないので、ほかにもいろいろボードを追加することは必要だが、これまでだと2,000回線のAMRといえば下手するとラック半分位は占有していたから、大幅な省スペース化が可能になる |
では、これで何ができるか? という話である。写真13にも示されているが、StarCoreのデータ長は相変わらず16bitもしくは8bitなので、16bitで4GMAC/sec、8bitでは8GMAC/secという、単独でも十分お化けな性能で、これを4つ集積したMSC8144は16GMAC/secないし32GMAC/secといった途方もない数字が出てくる。が、実装例ではさらにこれを8つも集積したATACボード例が示された。
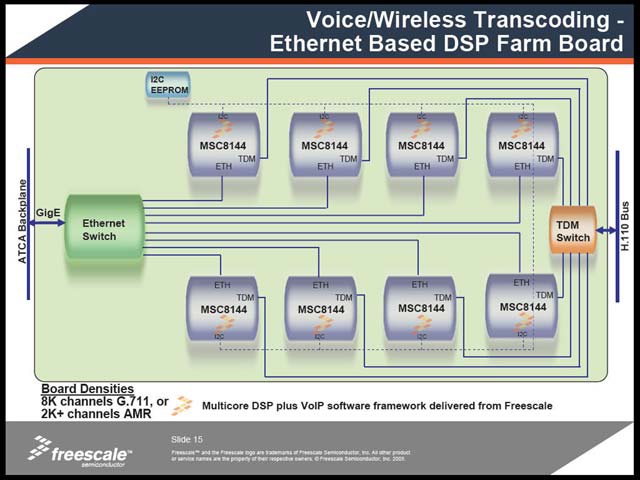
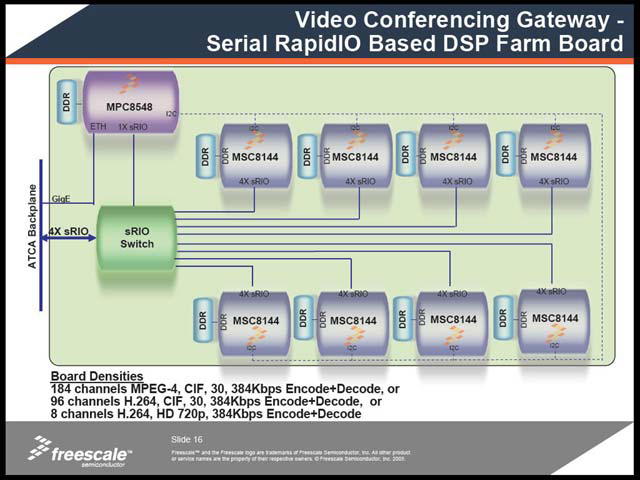
例えばVoice/Wireless Transcoding(写真19)では、これを使うことで8,192チャネルのG.711とか2,048チャネルのAMRのTranscodingが一気に行なえるという。あるいはVideo Conference System例(写真20)では、128回線分のMPEG-4のエンコード/デコードが可能になるとしている。あるいは最近話題のWiMAXについても、4ch分のベースバンド部の処理がMSC8144で可能になる、としている。
 |
 |
| 【写真19】エンコードを例に取れば、ATACからSerial Rapid I/O経由で来た音声/動画をエンコードし、それを再びSerial Rapid I/O経由でMPC8548に戻し、ここからGigabit Ethernetに送り出すという仕組み。デコードは逆パターンである | 【写真20】これに関して既にソフトウェアが提供可能、といっているあたり、最初のターゲットはWiMAXの可能性が1番高いと見ているのだろう。実際、今は「とりあえず動くこと」が重要であって、WiMAXのサービスを検討しているキャリアやベンダーが一斉にこれの導入に走っても不思議ではない感じだ |
採用事例を見てもわかるとおり、SC3400やMSC8411は、明らかにコンシューマ向けというよりはビジネスのバックエンドに向けた製品と考えた方が無難で、その意味では従来のSC1400などとの棲み分けは非常に明白であるが、それにしてもパフォーマンス向上策に長パイプラインによる動作周波数向上を持ち込み、パイプらインストール/ハザード対策にキャッシュやBTB、Prefetchを導入するという、まるでPentium 4のような解を選ぶあたりが、DSPとGPUの境目が次第に見えなくなりつつあることを実感させる発表だった。
●Elemental Computing Overview
 |
| 【写真21】Director of TechnologyのPaul Master氏。どうでもいいが、会社紹介には“ElementCXI was founded in April 2004”とあり、プレゼンテーションの2枚目では“Founded in November 2004”となっていて、このレベルでマッチしていなかったりする |
これと全く逆の方向性を示したのが、ElementCXIの発表である(写真21)。同社は2004年4月に設立されたばかりのファブレス企業で、そもそも現在のところ公開されている製品は無い。ただし同社はCXI Architectureと呼ばれる全く新しいアーキテクチャを“Elemental Computing”という名称で今回発表したので、ちょっとご紹介したいと思う。
同社のコンセプトは、まずMulti-Dimentional(ICレベル/アプリケーションレベル/アルゴリズムレベル/制御レベル)でスケーラビリティがあること、それと3R(Robustness, Resilience and Reliability:日本語にすれば抗堪性、回復性、信頼性だろうか)がキーで、価格/消費電力/パフォーマンスの観点で従来のSoCやASICを上回るのが目的だとしている。
このあたりはファブレス企業にはおなじみの文句であるが、スケーラビリティに関してはちょっと目を引く。実のところ、CXI Architectureはこれを実現するために考えられた(のか、ひょっとすると逆にCXI Architectureが最初にあり、ここからスケーラビリティが出てきたのかはわからないが)感があるからだ。
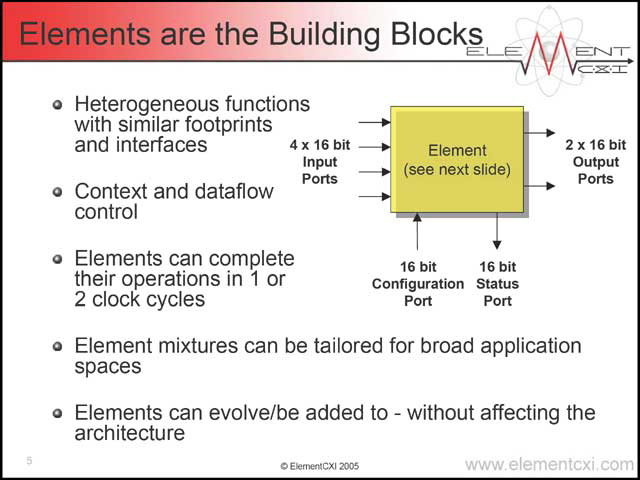
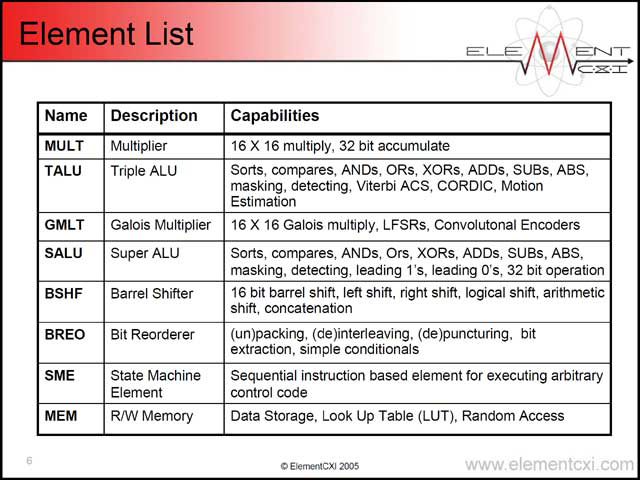
そのCXI Architecture、基本要素となるのはElementsと呼ばれる演算要素である(写真22)。扱えるのは32bit(これを16bit×2にパーティショニングできる)で、そのほかにConfiguration/Statusがそれぞれ16bitずつ用意される。Elementとして用意されるのは、写真23に示される8種類で、このほかにnanoQueueと呼ばれる要素が外部に用意される(写真24)。図からもわかるとおり、Element同士はnanoQueueを介して接続される。
 |
 |
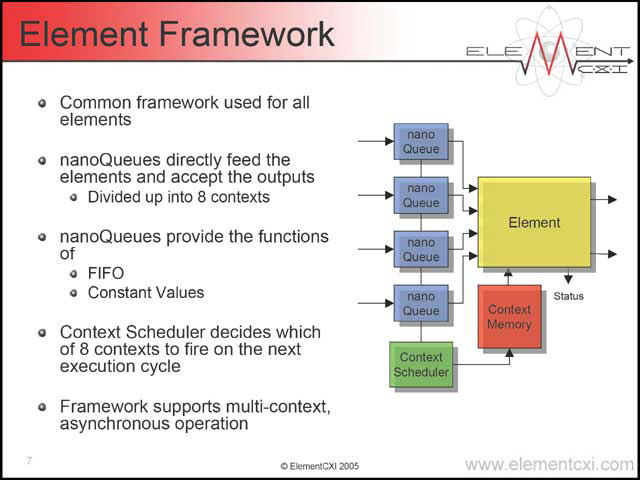 |
| 【写真22】これはまぁわかる。C=AXB、という単純な処理(Xは任意の演算)という話だからだ | 【写真23】Super ALUがちょっと面白い。0のロードなどはTALUに入りそうなものだからだ(逆にTALUで扱える演算もちょっと独特である)。ここから見てもわかる通り、演算はGPUというよりもDSPに近いものがある。ElementCXIの発表がDSPセッションに入るのも当然といえる | 【写真24】nanoQueueは結果として、単なるFIFOというよりはDividerとかRouterに近い働きをする。定数のロードにもnanoQueueを使うというのは、言われてみれば当然ではあるが、何となく違和感が |
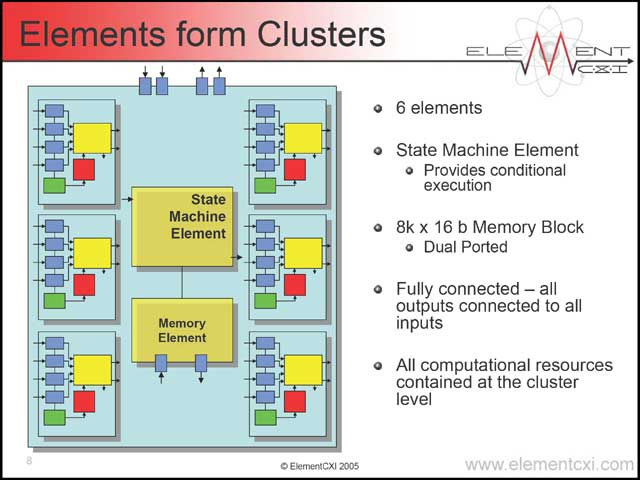
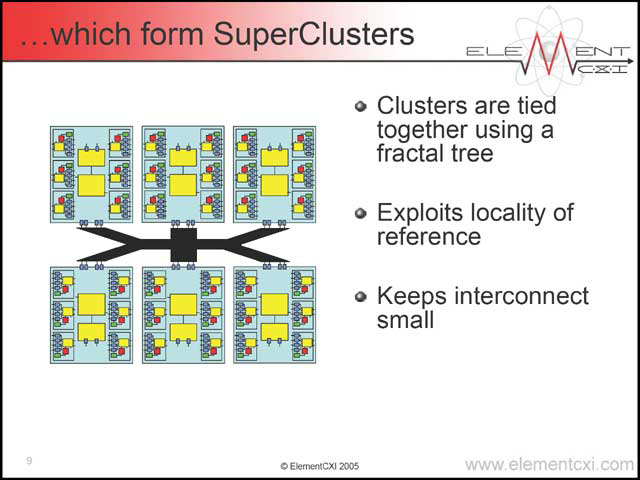
こうした構図を取るからには、Elementを複数同時に走らせることで高スループットを稼ぐのだろう、というのが普通の考え方で、実際その通りである。まず6つのElementを集積し、そこにメモリブロックをまとめたClusterというものがある。これをさらに6つ繋げたのがSuperCluster(写真26)で、このSuperClusterをさらに6つ繋げた例がこちら(写真27)である。
 |
 |
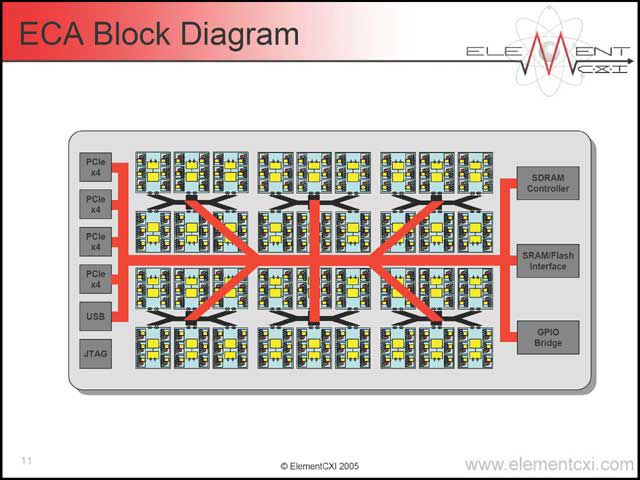 |
| 【写真25】条件分岐はCluster単位で行なう、というのが面白い。確かに個別のElementで処理をさせていたら大変だからだ | 【写真26】Cluster間は高速Interconnectで繋がるだけで、そのほかの要素は入らない | 【写真27】現実問題として、これを超える構造にする場合、メモリインターフェイスやI/Oインターフェイスを複数分散して持たせないと間に合わないような気もする |
この段階で6×6×6=216個のElementが集積されている計算だが、これが最大値というわけではない。必要ならこれをさらに6つ(この6つ、というのがキーワードらしく、3つとか4つを集積できるのかどうかは不明である。多分できると思うが)とか、さらにその先に集積することも可能になっている。写真28が216個で済んでいるのは、単にこの程度で通常の処理には十分だから、ということらしい。
実際にこれがどう動くかはIDCT(逆離散コサイン変換)を例に示した。IDCTはJPEGやMPEGなどではおなじみの技法で、簡単にいってしまえばテーブルを使って一次元→二次元に変換を行なうものだ。これも色々スマートな技法はあるが、今回は力業でのケーススタディである(写真28)。
これを1つのElementで実行する場合、写真29のような構図になる。このままだと、8サイクルで1回のループ処理が終わる計算だ。
 |
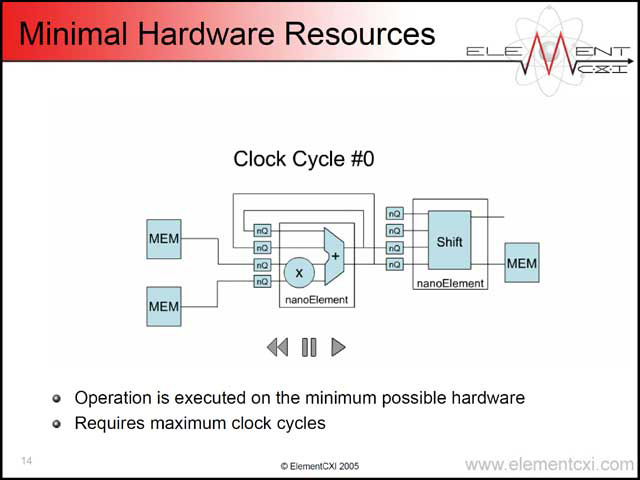 |
| 【写真28】JPEGやMPEGでは、IDCTテーブルを使い64個の一次元データを8×8の二次元データにする。単純に処理すると前半部が64回のループ(更に厳密に言えば8×8なので、1回のループは8)、後半部は「前半部」を64回ループするという仕組み | 【写真29】最初のnanoElementの出力がフィードバックされて再び入力される形になり、これを8回まわすと1つの処理が終わる計算 |
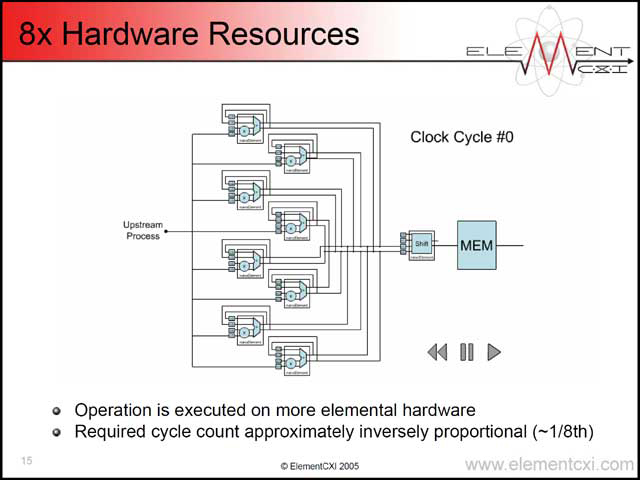
ところがこれをClusterなり、もっと大きな単位で行なえば、1回のループ処理をもっとすばやく終わらせることも可能だし、あるいは複数のピクセルの処理を同時にループで回すこともできる(写真30)。面白いのは、複数のプロセスで1つのElementを共用することもできることで(写真31)、利用効率を上げることもできるというものだ。
 |
 |
 |
| 【写真30】ここではループを分散させる形での実装例。理論上最大1/8になる、というのは1回のループの単位が8だから | 【写真31】このケースでは、ShiftのElementが共用されている。ところで発表でもnanoElementという言葉が唐突に出てきたが、これは要するに写真24で言うElementのことである | 【写真32】このあたりは数字のマジックで、実際にここまでの性能が出るかどうかはまた別の話だと思うが |
この方式が面白いのは、各Elementが勝手に処理をする(写真24で言うContext Schedulerが管理する)ことで、いわゆるArray Processorよりも各ノード(ここで言うElement)の自由度が高いことだ。また単位が4とか8でなく6、というのも目新しい。各ElementはCycle単位に処理を変更できるので、例えばClusterで今のIDCTの処理をする場合、300MHz駆動なら5.7GOPS、SuperClusterを組めば34.2GOPSということになる(写真32)。
この5.7GOPSという数字の評価は難しいかもしれないが、一般にGPUでIDCTを行なった場合、SIMD演算命令などをフルに使っても1GHzのプロセッサで1GOPSはなかなか出ない。DSPだともう少し性能は出しやすいが、それでも1個のDSPでこれだけのものを出せるものはそう多くない。
しいて分類すればDSPというカテゴリーにはいるCXIだが、そうは言っても製品が皆無という状況なので、今はまだ何とも……という感じではある。ただ同じハイパフォーマンスを目指す2つのDSPが、全く違う方向を向いたインプリメントで出てくるあたりは、相変わらず面白いと感じた。
□Spring Processor Forum2006のホームページ(英文)
http://www.instat.com/spf/06/
□Freescaleのホームページ(英文)
http://www.freescale.com/
□StarCore LLCのホームページ(英文)
http://www.starcore-dsp.com/
□ElementCXIのホームページ(英文)
http://www.elementcxi.com/
□CXI Architecture Overview(英文)
http://www.elementcxi.com/technology.htm
□関連記事
Spring Processor Forum 2006レポートリンク集
http://pc.watch.impress.co.jp/docs/2006/link/spf.htm
【2005年9月13日】【FTF】ARMコアを使ったシステムオンチップ
http://pc.watch.impress.co.jp/docs/2005/0913/ftf03.htm
【2005年9月12日】【FTF】PowerPCとPowerQUICC
http://pc.watch.impress.co.jp/docs/2005/0912/ftf02.htm
(2006年5月24日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2006 Impress Watch Corporation, an Impress Group company. All rights reserved.