 |


■後藤弘茂のWeekly海外ニュース■ラディカルなAMDの「Radeon HD 2000」アーキテクチャ |
●革新的で飛躍の大きなR600アーキテクチャ
AMD(旧ATI Technologies)が野心的な「Radeon HD 2000(R6xx)ファミリ」を発表した。フラッグシップのハイエンドGPU「Radeon HD 2900(R600)」は、NVIDIAのGeForce 8800(G80)系と拮抗する野心的なGPUだ。アーキテクチャ的には多くのチャレンジがなされており、前世代の「RADEON X1000(R5xx)」系からの飛躍は大きい。「Xbox 360 GPU(Xenos)」から継承されたフィーチャもあるが、多くはR600から導入された新テクノロジで占められている。
以下が3Dグラフィックスと汎用コンピューティング面で目立つR600のフィーチャだ。
○DirectX 10サポート
○ユニファイドシェーダ型アーキテクチャ
○320個の積和算ユニットの並列実行による475 GFLOPSの演算性能
○VLIW(Very Long Instruction Word)型のシェーダプロセッサ
○ドライバワークを実行するコマンドプロセッサ
○シェーダの動的マルチスレッディングの強化
○デュアルシーケンサによる2スレッドのカスケード実行
○64-bitフィルタリングに最適化されたテクスチャユニット
○高スループットジオメトリシェーダ
○ハードウェアテッセレータ
○大容量キャッシュメモリ
○ライタブルキャッシュによるスレッド間のデータコミュニケーション
○ハードウェアコンテクストスイッチング
○新アンチエイリアシングモード「Custom Filter Anti-Aliasing」
○メモリリード&ライト両方向のリングバス
○512-bit幅メモリインターフェイス
○「Close to the Metal(CTM)」によるローレベルとミッドレベルのプログラミングインターフェイスの公開
R600とG80はどちらも革新的なアーキテクチャで、DirectX 10世代とその先を見越した設計となっている。ただし、設計思想とアプローチは大きく異なる。R600とG80は、それぞれがアーキテクチャ的に相手を先取りした部分を持ち、方向性が異なっている。特に、設計思想が異なるのはシェーダプロセッサだ。シェーダプロセッサの構成では、両社のアプローチは見事なまでに対照的だ。
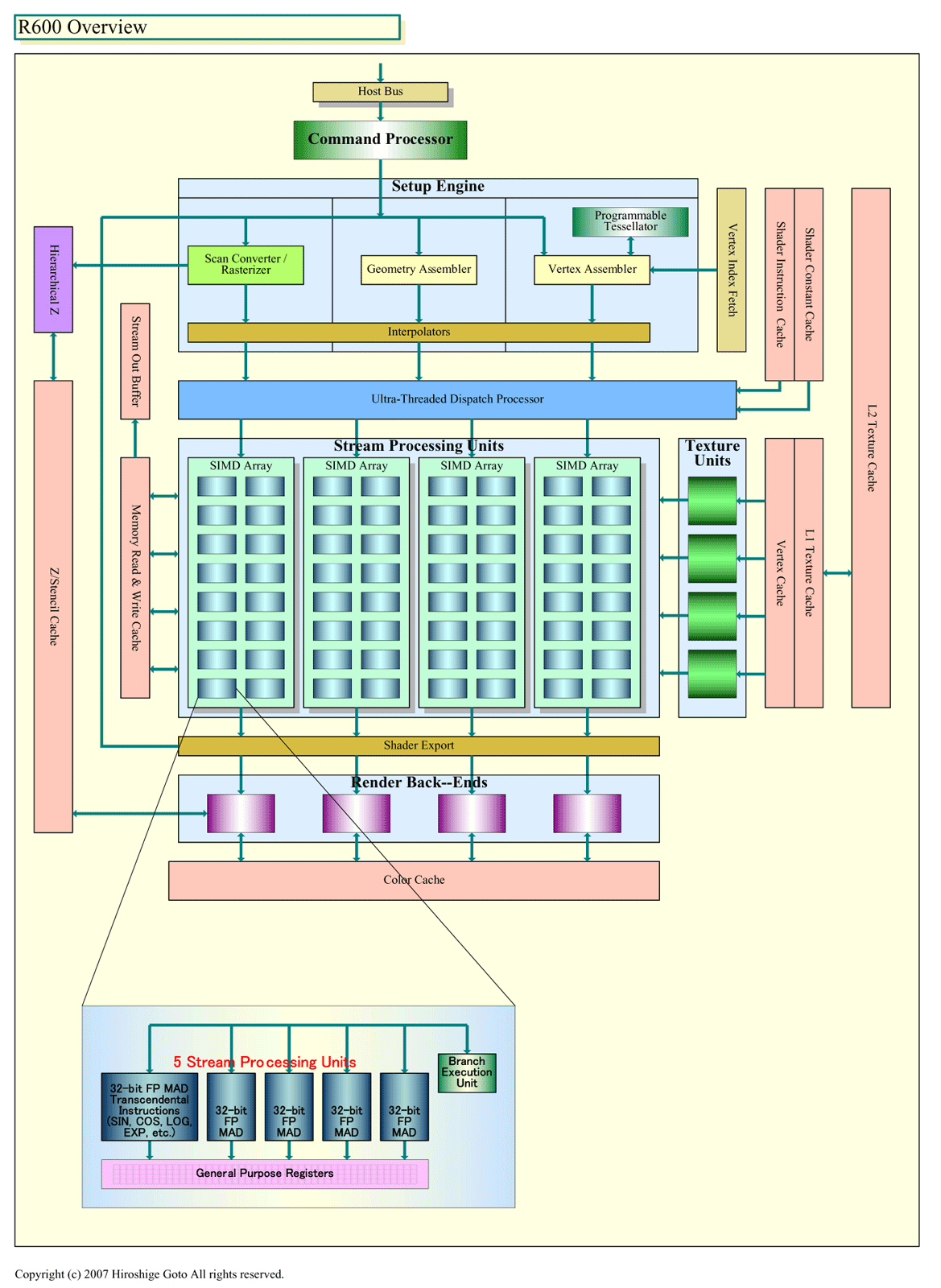 |
| 「Radeon HD 2900」(R600)のブロック図 PDF版はこちら(別ウィンドウで開きます) |
R600はシェーダプロセッサの演算リソースの数を増やして並列度を高めている。それに対して、G80は相対的に少ない数のシェーダプロセッサをより高速に走らせることで性能を上げている。つまり、R600は“より多くのプロセッサ”を、G80は“より速いプロセッサ”を追求している。
この2要素はトレードオフの関係にある。シェーダプロセッサを高速にすると深いパイプ構成となり、シェーダプロセッサ当たりに必要なリソースが増えて、プロセッサ個数が減ってしまうからだ。トレードオフの中で、全く対照的な選択を行なったのがR600とG80だ。
また、R600はシェーダプロセッサを大きなバンドルで構成している。対するG80はシェーダプロセッサを細粒度のバンドルにしている。そのためG80の方がシェーダプロセッサの制御機構が複雑となり、G80のシェーダプロセッサ個数が少ない原因となっている。R600は相対的にシェーダプロセッサの制御が簡素となり、プロセッサ個数を増やしやすいが、分岐粒度がやや大きい。AMDは実際のアプリケーションの用途に合わせてアーキテクチャを選択したという。
R600はシェーダプロセッサの命令セットをVLIW(Very Long Instruction Word)にすることで、命令レベルの並列性を追求した。つまり、異なる命令を1サイクルに並列実行することに力点を置いている。
それに対して、G80は並列実行ではなく、シェーダプロセッサを速くすることにフォーカスした。プロセッサの性能は、「並列性×周波数」に比例する。R600は並列性を、G80は周波数をとったと見ることができる。命令レベルの並列性にここまで力点を置いたGPUアーキテクチャは、おそらくR600が初めてだろう。その意味で、R600はよりチャレンジが大きい。
 |
| スレッド並列性を追求したR600 |
●性能を引き出すのに時間がかかるR600のアプローチ
両社のアプローチにはそれぞれトレードオフがある。ハードウェア設計面では、R600の多数の演算ユニットアレイは、GPUの設計上の最大のハードルである配線複雑度をさらに上げてしまう。一方、G80の倍速シェーダプロセッサには非同期設計や深いパイプライン、より大きなメモリレイテンシのペナルティといったチャレンジがある。
ソフトウェア面では、R600のVLIWシェーダプロセッサでは、ドライバの中のリアルタイムコンパイラによる命令スケジューリング(並べ替え)の効率に性能が大きく依存する。命令並べ替えが効率よくできないと、命令スロットが空いてしまい、演算ユニットがアイドルになってしまう。そのため、多くのVLIWプロセッサと同様に、最初は演算性能が期待ほど発揮できない可能性が高い。
R600では、この構成でなぜ性能がG80のトップエンドに匹敵しないのかが話題となる。しかし、シェーダのマイクロアーキテクチャを見る限り、当初、性能が引き出しにくいのは不思議はないように見える。Transmeta CPUやIA-64 CPUといったVLIW型CPUを考えてみれば、これはよくわかる。
逆を言えば、R600はVLIW型CPUのように、コンパイラの改良によって後から性能が上がる余地が大きいとも言える。実際、AMDはR600ではドライバとGPU内の制御機構のチューンに膨大な時間をかけており、今後もチューンナップによって性能が上がる可能性があると説明する。つまり、パフォーマンスを引き出すのに時間がかかるアプローチを、AMDは採用したわけだ。現状では、それがNVIDIAのG8xアーキテクチャに対する不利となっている。
しかし、R600の設計全体は非常に論理的で、同GPUの課題をうまく解決できるように設計されている。例えば、R600の採用したリングバスは、演算リソースの増大により激増する配線複雑度を軽減する役割を果たす。R600は、コマンドプロセッサの強化によってGPU上でドライバを走らせている。これは、VLIWの命令スケジューリングのために重くなるR600のドライバには有効だ。アーキテクチャ的には非常に練られており、整合性は高い。
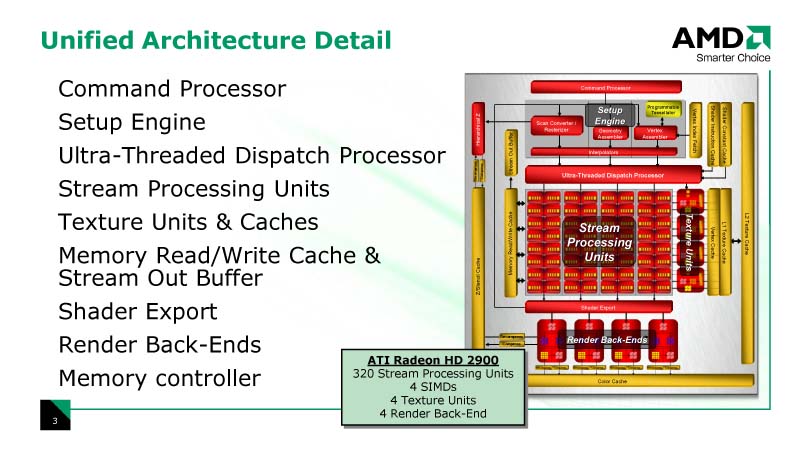 |
| 統合シェーダアーキテクチャの詳細 |
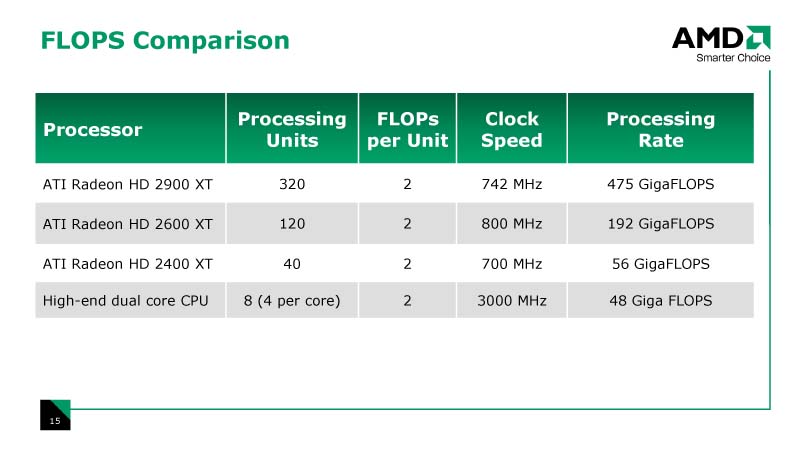 |
| R600は475 GFLOPSの演算性能を持つ |
 |
 |
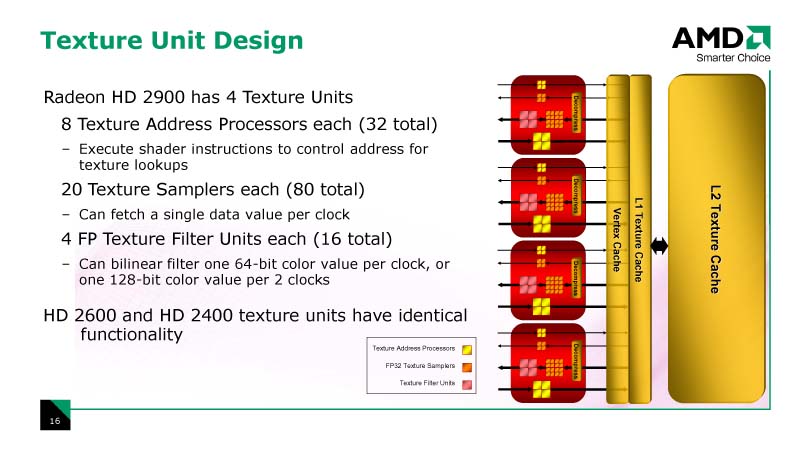
| テクスチャユニットの設計 |
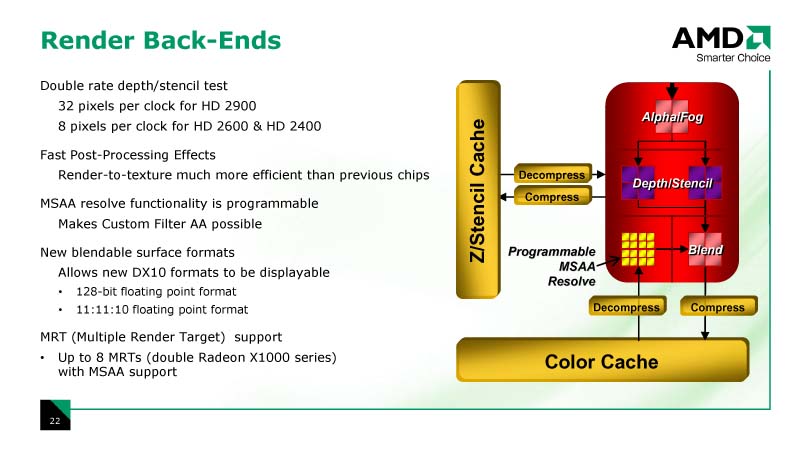 |
| レンダーバックエンドの構造 |
●汎用コンピューティング指向
R6xxアーキテクチャで特に目立つのは、汎用(General Purpose)コンピューティングを強く意識した拡張だ。R5xxアーキテクチャまでのAMD(旧ATI) GPUでは、汎用コンピューティングに向けた機能は、グラフィックス向け拡張の副産物的な要素が強かった。これはNVIDIAも同様で、G70世代まではグラフィックス中心の設計だった。しかし、R6xxアーキテクチャではG80と同様に、明瞭に汎用コンピューティングにフォーカスしたアーキテクチャ拡張が行なわれている。ライタブルなキャッシュメモリなどは、明確に汎用的な利用を前提とした拡張だ。R600とG80は、どちらも汎用コンピューティングに明確に踏み出した最初のGPUアーキテクチャだと言える。
もっとも、R600には、汎用化を進めるAMD GPUの今後の大きな流れまでは見えない。AMDはGPUの命令セットのCPU命令セットへの統合も含めて、CPUとGPUの統合化を模索している。AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は、GPU機能を、x86命令セットの中にユーザーモード命令セットとしてビジブルにすることを構想していると、昨秋(2006年秋)に語っていた。
しかし、R600のマイクロアーキテクチャにはこうしたAMD路線と矛盾する部分もある。これは、R600がATI時代にアーキテクチャが固められたGPUであるためだと推測される。つまり、AMDの目指す究極のGPUアーキテクチャは、まだR600からは知ることができない。あくまでも、旧ATI路線の行き着いた究極のGPUがR600アーキテクチャだ。
●64シェーダプロセッサ相当のR600のシェーダアレイ
R600のシェーダのプロセッサ(プログラマブル演算ユニット=ALU)は全部で320個。実際には、5個の演算ユニットが1バンドルとして構成されている。このバンドルをAMDは「5-wayスーパースカラシェーダプロセッサ」と呼んでいる。これが、旧来「シェーダプロセッサ」または「プログラマブルシェーダ」と呼ばれていたユニットだ。
5-wayスーパースカラシェーダプロッサには、4個の積和算スカラユニットと、1個の積和算兼超越関数ユニット、分岐ユニットの合計6ユニットが含まれる。R600では、320の演算ユニットが、64個の5-wayスーパースカラシェーダプロッサとして構成されている。
 |
| 5-wayスーパースカラのシェーダプロセッサ |
旧来の呼称で表現するなら64シェーダプロセッサ構成のGPUだ。320個のプロセッシングユニットと言われると驚くが、64シェーダプロセッサなら、RADEON X1900(R580)の48ピクセルシェーダからそれほどかけ離れてはいない。以前流れていた64シェーダ構成と言う情報通りの構成だ。
さらに、この64個のシェーダプロセッサが、R600では4つの「SIMD(Single Instruction, Multiple Data)アレイ」に構成されている。SIMDアレイというのは、従来の表現なら「シェーダクラスタ」となる。つまり、1個の命令ユニット(命令シーケンサ)から発行される同じ命令を実行するシェーダプロセッサのアレイだ。旧来の表現で言えば、16個のシェーダプロセッサで1シェーダクラスタを構成しているのがR600だ。
AMDはR600から各要素の呼称を変えているため、ちょっと分かりにくい。しかし、下のように置き換えるとわかりやすい。
○ストリームプロセッシングユニット = 演算ユニット(ALU)
○5-wayスーパースカラシェーダプロッサ = シェーダプロセッサまたはシェーダ
○SIMDアレイ = シェーダクラスタ
つまり、R600でも、基本的な演算ユニットの構成方法は、実はR5xx世代と変わっていない。R600では、シェーダの構成は大きくいじらずに、シェーダの中の命令発行の仕組みを革新した。これが、シェーダの構成の方を変えたG80との違いとなっている。R600で変更されているのは名称と制御の方法であって、大きな構成に変化は少ない。
●スカラ命令の効率を高めるためVLIWアーキテクチャを採用
AMDもNVIDIAも、どちらもDirectX 10で直面した課題は同じだった。それは、シェーダプログラムのスカラコード化だ。従来のシェーダは、1命令で複数データを処理するSIMD型の演算命令が中心だった。しかし、シェーダプログラムが進化するにつれて、1命令で1データを処理するスカラ命令が急増しつつあるという。
AMDとNVIDIAのどちらもこの点をDirectX 10世代GPUの設計の課題として指摘している。SIMD構成の従来のシェーダプロセッサでは、スカラ命令中心のコードは効率よく走らせることができないからだ。そして、出した答えは全く正反対なものだった。AMDはシェーダプロセッサにVLIW命令セットを採用、各演算ユニットがそれぞれ異なる命令を実行できるようにした。
従来のピクセルシェーダプロセッサは4-way SIMD構成を基本としていた。これは、ピクセルのデータがRGBAの4データエレメントで構成されており、4エレメントに対して同じ命令を実行するSIMD型の処理に最適化した方が効率的だったからだ。実際には、4-way SIMDを分割して2命令を実行できるようにもなっていたが、スカラ命令が連続するケースには最適化されていなかった。
DirectX 10世代でスカラ命令への最適化が必要になったことで、R600では5個の演算ユニットと1個の分岐ユニットの合計6ユニットに並列に命令を発行できるVLIW型構成を取った。VLIWでは、1つの命令語の中に多数の命令をパック化することができる。
そのため、1スレッドの命令ストリームの中のスカラ命令を、並列に並べ替えて実行することができる。1クロックで多数のスカラ命令を実行できるため、スカラ命令が連続した場合の性能が上がるというわけだ。
VLIWへの命令並べ替えとパックをリアルタイムコンパイラで行なうというR600の特徴は、TransmetaのCPUと基本的には似ている。それに対して、G80では1個1個の分離されたスカラ演算ユニットが、それぞれスカラ命令をシリアルに実行する。全く設計思想が異なる。G80の方式には命令スケジューリングが必要ないという利点があるが、その反面、より多くのスレッドの制御というオーバーヘッドがある。AMDとNVIDIAのアプローチには、それぞれトレードオフがある。
●VLIW命令をSIMD発行するR600アーキテクチャ
シェーダプロセッサの命令がVLIW型で、SIMDアレイ(シェーダクラスタ)の命令発行がSIMD型というR600のアーキテクチャは分かりにくいかもしれない。しかし、原理は簡単だ。命令シーケンサが発行し、各シェーダプロセッサが実行するのはVLIW命令。しかし、1個の命令シーケンサが、同じVLIW命令を16個のシェーダプロセッサに同時に発行する。同じVLIW命令を複数のプロセッサが異なるデータアイテムに対して実行することを、AMDではSIMDと呼んでいる。シェーダプロセッサの命令自体はVLIWフォーマットで、シェーダプロセッサに対する命令発行がSIMDイシューだ。
R600のシェーダプロセッサのマルチスレッディングは、R5xxやXbox 360 GPU(Xenos)の方式と似ている。R5xxのピクセルシェーダプロセッサでは、各プロセッサが1命令で4サイクルに渡って4ピクセルを処理。1スレッドの中の4ピクセルに対する処理をカスケードすることで演算レイテンシを隠蔽していた。
R6xxアーキテクチャでもこの基本は変わらない。各シェーダプロセッサが4サイクルに渡って同じスレッド内の4つのデータエレメントをカスケードで処理する。1つのSIMDアレイは16シェーダプロセッサで構成されるため、16×4=64データアイテム(ピクセル/頂点/プリミティブ)がスレッドバッチの粒度となる。これはXenosと同じだ。
R600は、汎用コンピューティングに向けて最適化されていると書いたが、むしろ、R5xx世代よりも揺り戻した面もある。それは、スレッドバッチのサイズだ。
R520のピクセルシェーダプロセッサではスレッドバッチのサイズは16ピクセルだった。それに対して、R600のスレッドバッチは64データアイテムと大きくなっている。スレッドバッチの粒度が小さくなればなるほど、条件分岐の効率が高くなる。R600で揺り戻したのは、R520の粒度では実装コストが高いわりにアプリケーションのベネフィットが小さかったためだという。GPUの汎用コンピューティングへの最適化は、まだ試行錯誤の最中にある。
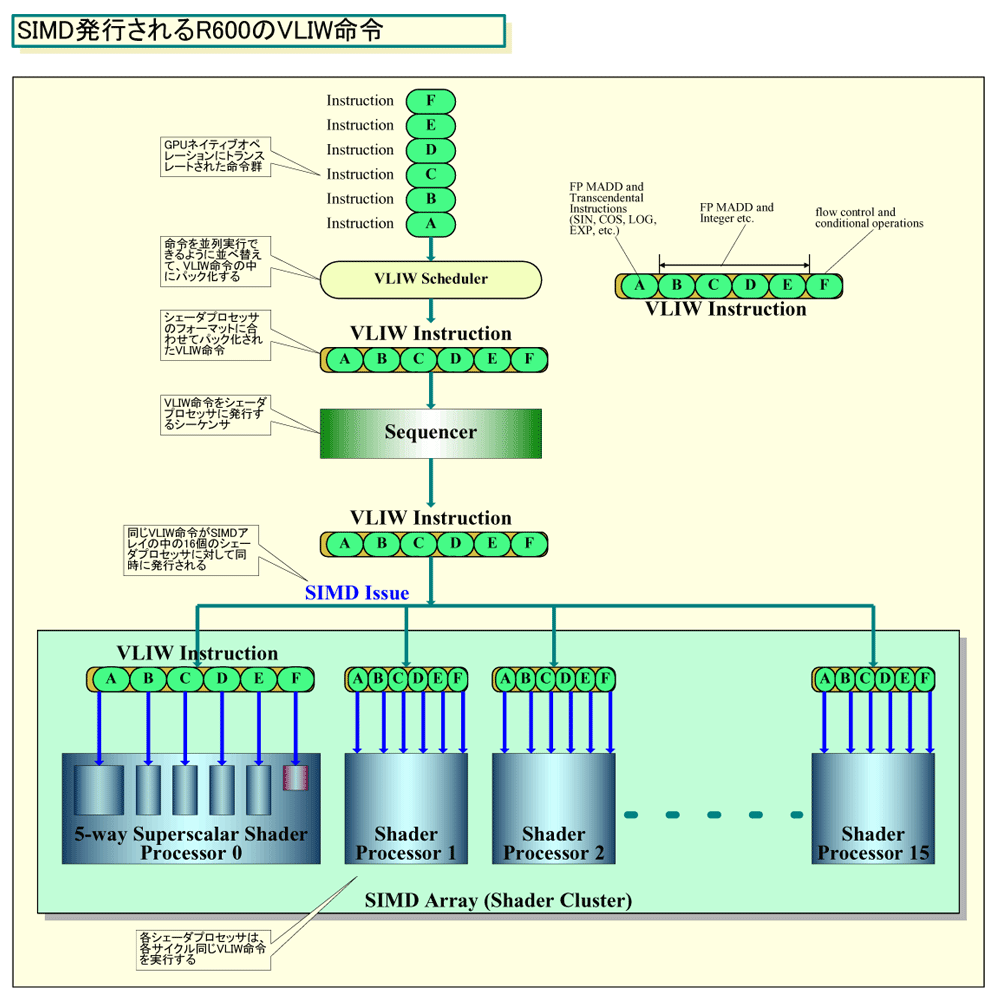 |
| SIMD発行されるR600のVLIW命令 PDF版はこちら(別ウィンドウで開きます) |
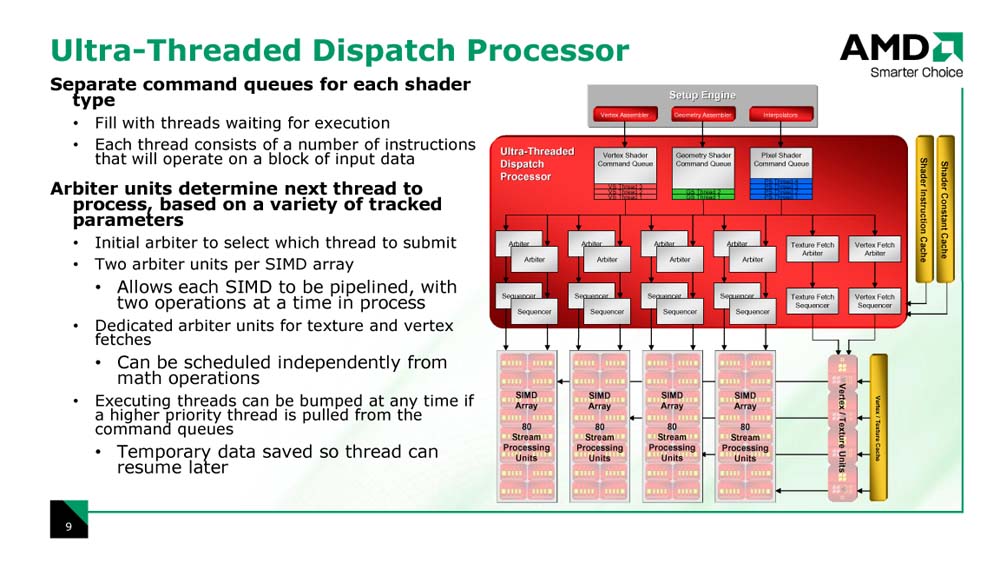
●2命令シーケンサが2スレッドをSIMDアレイに供給
さらに、R600アーキテクチャでは、2つの命令シーケンサが1つのSIMDアレイに対して命令を発行する。つまり、各SIMDアレイは同時に2つのスレッドバッチを実行する。実際には、スレッドバッチAを4サイクルかけて実行し、次にスレッドバッチBを4サイクルかけて実行する。そのため、各SIMDアレイの実行パイプは8サイクルレイテンシまで隠蔽できる。つまり、R600では、従来アーキテクチャより演算ユニットの物理的な実行パイプラインを深くできる。その分、高クロック化が容易になると推定される。この詳細は次のレポートで説明したい。
R600のこの2スレッドバッチのカスケード実行アーキテクチャは、実はG80と似ている。G80はスレッドバッチを「warp」と呼ぶ単位に分解。複数のwarpをカスケード実行することでレイテンシを隠蔽している。そのため、G80ではパイプラインを深くし、シェーダコアの動作周波数を上げることが容易になった。R600はG80よりは浅いものの、似通った方法で高速化を図っていると言える。この手法がGPUでは合理的であるためだと思われる。
また、R600は2個のシーケンサによる静的なスレッド切り替えの他に、R5xx同様に動的なスレッド切り替えもサポートする。スレッドがストールする場合には他のスレッドに切り替えて、シェーダコアをビジーに保つ。
伝統的なGPUでは、キャッシュメモリはリードオンリであるため、演算コアはデータの局在性をオンチップメモリ経由で利用できない。つまり、1つの演算コアが、別な演算コアの演算結果をオンチップメモリから読み出すことができない。グラフィックス処理の場合、データに依存性がないため、このアーキテクチャでも問題はなかった。しかし、GPUを汎用コンピューティングに利用しようとすると、これは大きな障壁となる。
そこでR600では、ストリームプロセッシングユニット間で共有するリード&ライト可能なキャッシュメモリ「Memory Read/Write Cache」を搭載した。これはコヒーレンシを維持したキャッシュメモリで、汎用コンピューティングでの、スレッド間のデータ交換に使うことができるという。ちなみに、G80でも、シェーダクラスタであるStreaming Multiprocessor(SM)毎に共有の「16KB Shared Memory」を備えて、データ共有に利用できるようにしている。R600のMemory Read/Write Cacheは、SIMDアレイ間からも共有される。
●コマンドプロセッサでドライバの一部を走らせる
R600のコマンドプロセッサは、プログラマブルな高機能プロセッサで、現在CPU上のドライバで行なっている処理の一部分をGPU上のプロセッサで行なうことができる。GPUのドライバは、グラフィックスAPIやシェーダコードをGPUのネイティブコードにトランスレートする。これが非常に複雑な作業で、CPUパワーを消費し、GPUの性能を制約する「スモールバッチ問題」の源となっている。
そこで、R600では、ドライバの処理の一部をGPU側の専用プロセッサに移すことで、CPUをオフロードした。GPU上でドライバタスクの一部を走らせることは、NVIDIAも次のGPUアーキテクチャで計画している。「ドライバオンGPU」は、GPUの次の大きなステップだ。
AMDがNVIDIAに先んじて、R600世代に高機能コマンドプロセッサを搭載してきた理由は明瞭だ。1つは、R600のシェーダがVLIW命令セットアーキテクチャを採るため、ドライバのオーバーヘッドが従来よりさらに大きいこと。もう1つは、AMDが「Close to the Metal(CTM)」でGPUの“ローレベル”命令セットを公開しつつあること。CTMでの互換性を保って行くためには、AMDはコマンドプロセッサでのマイクロアーキテクチャの抽象化を高める必要がある。
ただし、CTMではシェーダ演算コアの命令セットアーキテクチャ(ISA)自体は、マイクロアーキテクチャに依存する。シェーダのISAが固定化されるのは、さらに先になると推定される。特に、AMDが構想しているようなx86命令セットとの融合を考えた場合、R600のVLIWネイティブ命令セットは考えにくい。ストリームプロセッシング機能を、CPUのコプロセッサとして融合させる段階では、GPUコアの命令セットはまた異なるものになっている可能性が高い。
ユニファイドシェーダであるR600のセットアップエンジン群は、同じくユニファイドシェーダであるNVIDIA G80のそれに非常に似ている。バーテックスプロセッシングのための「バーテックスアセンプラ」、ジオメトリプロセッシングのために「ジオメトリアセンプラ」、ピクセルプロセッシングのための「スキャンコンバータ/ラスタライザ」を備える。
NVIDIAアーキテクチャとの最大の違いはテッセレータ(平面分割)ハードウェアを備えること。この構成は、Xbox 360 GPU(Xenos)のアーキテクチャに近い。しかし、専用ハードで専用APIのXbox 360に対して、汎用のPC上でのテッセレータは、どれだけ有用性が高いかは、まだ未知数だ。特に、DirectX APIでダイレクトサポートされない段階では不鮮明だ。
●512-bit幅のメモリインターフェイス
膨大な演算ユニットは、膨大なデータを必要とする。R600では、演算アレイにデータを供給するため、512-bit幅のメモリインターフェイスを搭載した。DRAMインターフェイスのパッドはチップのエッジに配置する必要がある。従来のI/Oパッドの設計では、512-bit幅のパッドを配置するとチップの外周の使えるエッジ長を上回ってしまう。
そこで、AMDではパッド設計を大きく改良、従来の256-bit DRAMパッドと同じ面積に512-bit分のI/Oパッドを配置した。チップの物理設計の改良によって、512-bit幅メモリインターフェイスを実現した。
また、R600ではR5xxシリーズから採用したリングバスをさらに発展させた。GPUの場合、設計の最大の難関は配線だとAMDは説明する。広幅のインターフェイスが多数のユニットを結ぶため、配線地獄となる。特にクリティカルなのはメモリインターフェイス回りで、多数のメモリクライアントを結ぶため配線が非常に複雑になる。
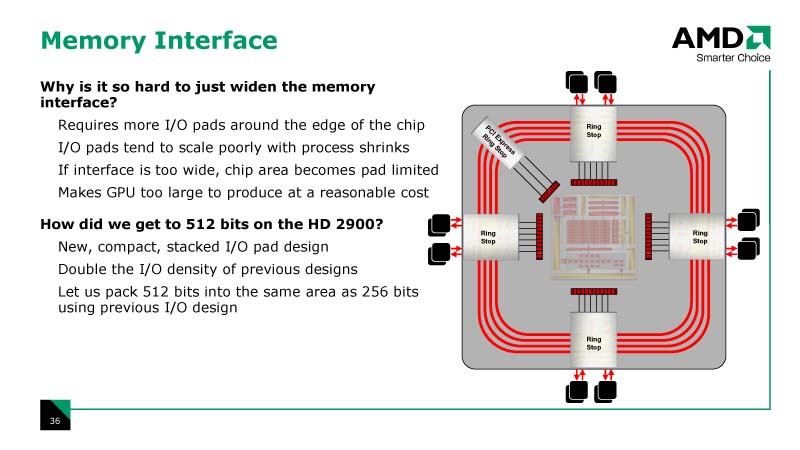 |
| 512-bit幅のメモリインターフェイス |
メモリアクセスするクライアントユニットの数が限られていた時は、AMD(旧ATI)もクロスバーでメモリコントローラとクライアントを接続していた。しかし、R5xxからはメモリリードにリングバスを採用した。リングバスでDRAMコントローラ群とメモリクライアント群を結ぶと、配線の複雑性を軽減することができる。R600ではこのアプローチを発展させ、メモリライトにもリングバスを採用した。これはユニファイドシェーダアーキテクチャとなって、メモリライトクライアントが増えたためだ。
こうして概観すると、R600アーキテクチャはラディカルだが、指向する方向性が明瞭であることがよくわかる。命令レベルの並列性やドライバオンGPUなど、革新性は極めて高く、アーキテクチャの整合性もとれている。AMDが今後もこうしたモンスターGPUを開発し続けるかどうかはわからない。しかし、R600がGPU進化の大きなマイルストーンであることは確かだろう。
□関連記事
【4月16日】【海外】スケーラブルに展開するNVIDIAのG80アーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
【2006年11月19日】【海外】これがGPUのターニングポイントNVIDIAの次世代GPU「GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
【2006年7月27日】【海外】正反対の方法論で対決するATIとNVIDIA
http://pc.watch.impress.co.jp/docs/2006/0727/kaigai291.htm
(2007年5月15日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.