 |


■後藤弘茂のWeekly海外ニュース■正反対の方法論で対決するATIとNVIDIA |
●コンサバNVIDIAとラディカルATIで対峙するDirectX 10世代
AMDによるATI Technologiesの買収で、GPU業界は大きく変動を始めた。
この変動の結果、将来的には、GPUの姿も大きく変わる可能性がある。しかし、当面のATIの製品プランは合併前から既定の路線で動いており、少なくともDirectX 10世代の「R600」ファミリについては、大きな変更はなさそうだ。GPUの製造も、しばらくはアジアファウンドリベースで、AMD Fabへ移るのは、当分先の45nm世代あたりだと推定される。
ここで、大まかにNVIDIAとATIのDirectX 10の製品プランをまとめておこう。GPUメーカー各社は、現在、DirectX 10世代の最初となるGPUの設計を完了しており、サンプル段階に入ったか、入ろうとしている。DirectX 10の最初の波に乗るのは、ATI、NVIDIA以外ではS3 GraphicsとIntelだ。NVIDIAは「G80」、S3は「Destination 1(D1)」、Intelは「Bearlake(ベアレイク)」チップセットとなる。
最初のDirectX 10世代GPUで面白いのは、NVIDIAとATIが完全に対照的なアプローチを取ることだ。
NVIDIAのG80は80nmプロセスで従来通りの独立型Shaderアーキテクチャを採用し、今年(2006年)後半の投入を目指していると言われる。プロセスが90nmの可能性もまだ残っているが、Shaderアーキテクチャは確実に独立型だ。それに対してATIのR600系は65nmプロセスで統合化されたUnified-Shaderアーキテクチャを採用し、投入は来年(2007年)になると言われている。つまり、NVIDIAとATIは、異なる内部アーキテクチャとプロセス技術とスケジュールで対決する。
構図は、コンサバティブなNVIDIA対ラディカルなATIで、DirectX 9の時とは完全に逆転する。最初の世代のDirectX 9 GPUでは、ATIが従来型アーキテクチャに成熟したプロセス、NVIDIAが斬新なアーキテクチャに新プロセスという組み合わせだった。この構図には、過去3~4年で逆転した両社の技術戦略が象徴されている。
●既存パイプラインを拡張するG80のアプローチ
DirectX 10世代GPUの内部アーキテクチャとプロセス技術は、密接に結びついている。
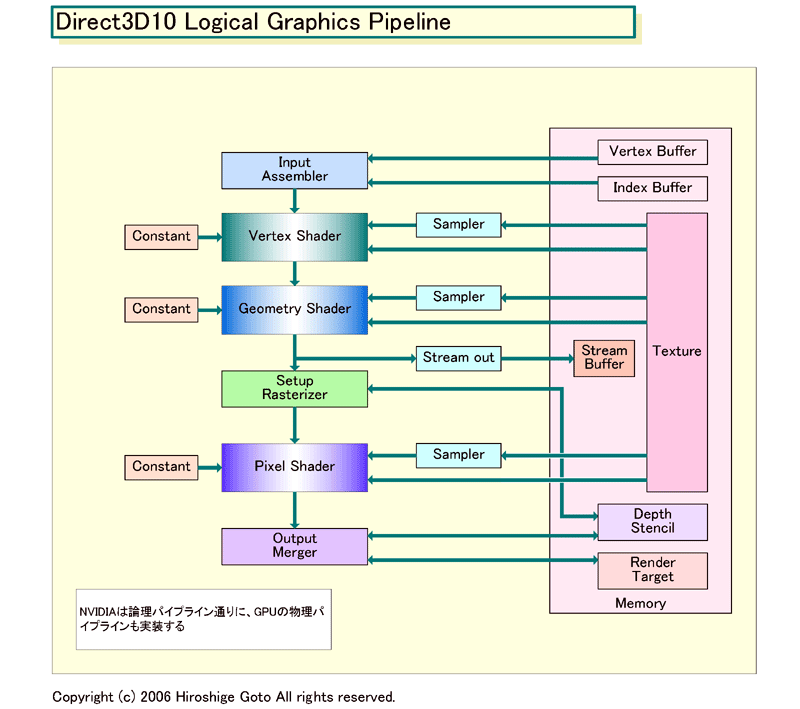
NVIDIAは、できる限り既存技術の流れの中で、冒険をしないでDirectX 10に対応しようとしている。DirectX 10の3DグラフィックスAPIである「Direct3D10(D3D10)」では、下のようなグラフィックスパイプの変革が求められている。
(1)コモンシェーダモデル(Common Shader Model)
(2)ジオメトリシェーダ(Geometry Shader)
(3)ストリームアウト(Stream out)
(4)直交型(Orthogonalized)のフレームバッファ
NVIDIAは、G80では既存のパイプラインを拡張、プリミティブプロセッシングを行なうGeometry Shaderと、ジオメトリパイプからの出力であるStream Outなどを実装。Shaderの命令セットをCommon Shader Modelに拡張し、フレームバッファ管理をフラットに変更するなどして対応すると見られる。
G80のShader構成は情報が錯綜しているため、まだ明確ではないが、Pixel Shaderが現行の24ユニットから32ユニット程度に増強されるだけでなく、Vertex Shaderの数もかなり増やされるという。この情報の裏は取れていないが、これは論理的だ。
従来はVertex Shaderに必要とされるパフォーマンスはホストバス(CPU FSB-PCI Express)に制約されていた。そのため、必要なVertex Shaderの最大値は、固定されていた。しかし、Geometry Shaderを搭載すると、頂点数をGPU内で増やすことができるようになる。そのため、頂点データ爆発が起こる可能性があり、Vertex Shaderを増やす必要が出る。
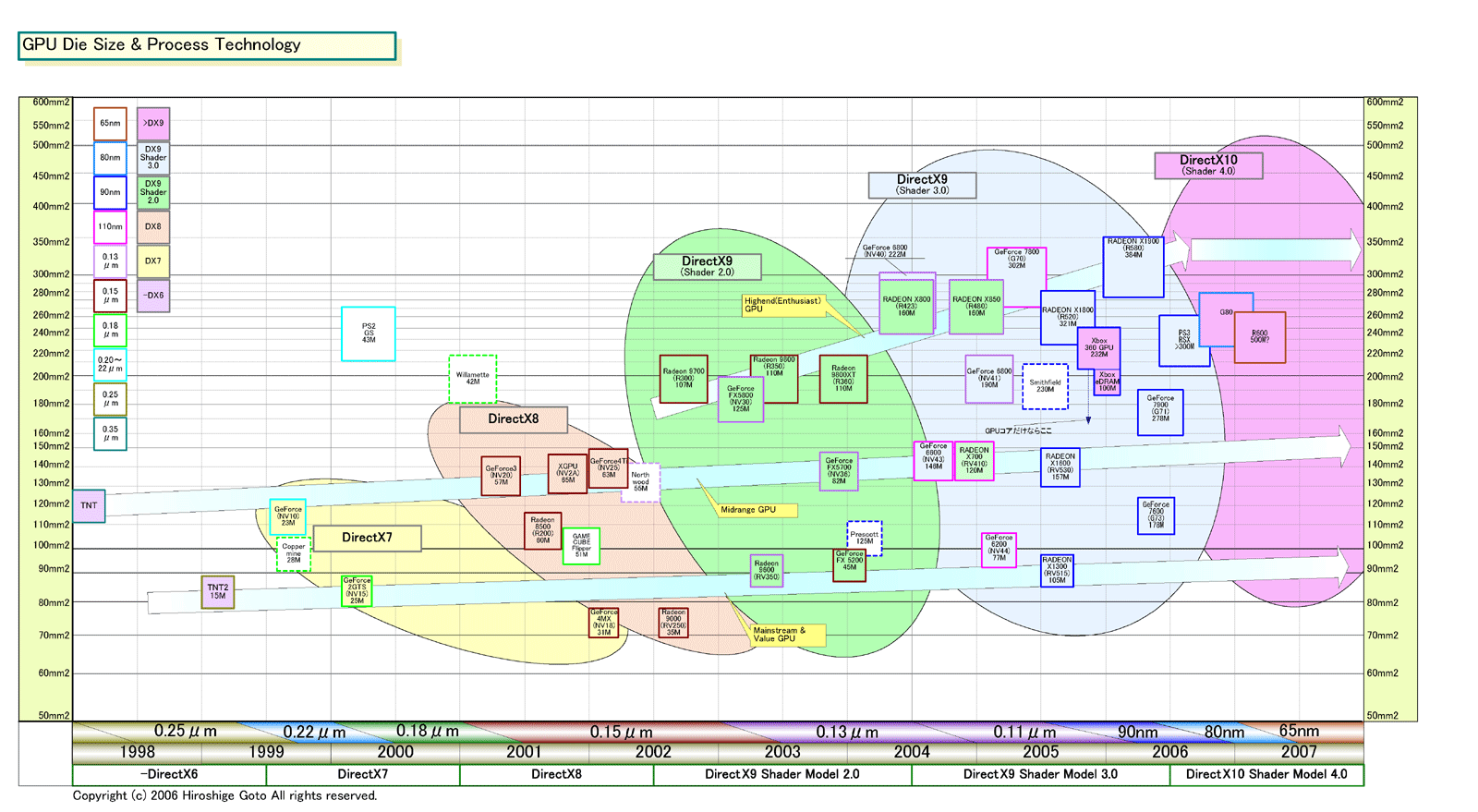
G80はこうした拡張が加わるものの、アーキテクチャを根本的に変えるATIほど、トランジスタ数を必要としないと推定される。NVIDIAは、それなら80nmプロセスで製造できると判断したと考えられる。90→80nmでは、あまりGPUダイサイズ(半導体本体の面積)を小さくできないが、穏当なアーキテクチャでトランジスタ数をある程度抑えているため、許容範囲に収まると判断したと思われる。
80nmは90nmプロセスのハーフノードであるため、新プロセスノードの65nmと比べると技術上のハードルが低い。しかも、すでに昨年(2005年)からリスクプロダクションがスタートしている。歩留まり上の問題が少なく、今年(2006年)後半なら比較的高い歩留まりの量産が確実なプロセスだ。まず、80nmでスタートさせて、65nmが安定したところで移行するという戦略だ。もしG80が90nmだとしたら、NVIDIAはさらに安全パイへと走ったことになる。
 |
| NVIDIA G80のパイプライン PDF版はこちら |
●DirectX 10を活かすことができるUnified-Shaderアーキテクチャ
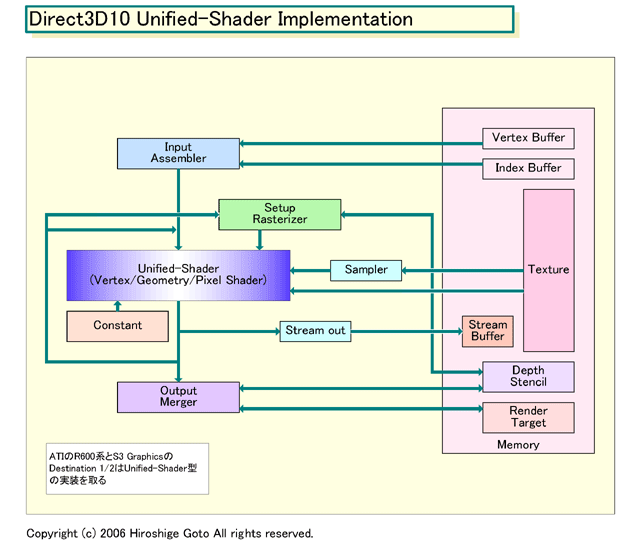
穏当路線のNVIDIAに対して、ATIはDirectX 10に最適化するために、R600系でGPUアーキテクチャを根本から変える。ATIはR600世代も、ハイエンドからメインストリーム&バリューまで3レイヤーのGPUファミリを一気に投入する。ハイエンドのフラッグシップモデルの正確な名称がR600かどうかはまだわからない。しかし、アーキテクチャ自体はR600系で統一されるはずだ。
R600系ではShaderを単一アーキテクチャのUnified-Shaderとして実装、スレッドコントローラによって各Shaderに、Vertex/Geometry/Pixel Shaderの役割を割り当てる。Shader間のロードバランシングが可能になるため、DirectX 10パイプラインの柔軟性をフルに活かし、理論上はGPUを効率的に稼働させることができる。
 |
| ATI R600をはじめとしたUnified-Shaderの実装 PDF版はこちら |
 |
| ATI TechnologiesのDavid E. Orton(デビッド・E・オートン)社長兼CEO |
ATIを率いるDavid E. Orton(デビッド・E・オートン)社長兼CEOもCOMPUTEXで次のように語っていた。
「我々のアーキテクチャ上のゴールは、よりパワフルなグラフィックスエンジンを、ベストなバランスの中で実現することだ。我々が、Unified-Shaderを検討し始めた時、最初に考えたのはパフォーマンス効率だった。DirectX 10の場合、ジオメトリとピクセルのアーキテクチャ上のパーティショニングは、いくつかの問題を発生させる。しかし、Unified-Shaderを採れば、DirectX 10に、より効率的に対応ができる」
ATIは、Unified-ShaderのフレキシビリティがDirectX 10を活かすと確信する。それに対して、NVIDIAは、Unified-ShaderではShader制御などが難しいため、想定通りのパフォーマンスが出ない可能性があると指摘する。また、Unified-Shaderでは、GPUの回路規模が大きくなり、トランジスタが膨大に必要となる。そのため、GPUのパフォーマンス効率が落ちることも問題だと指摘する。
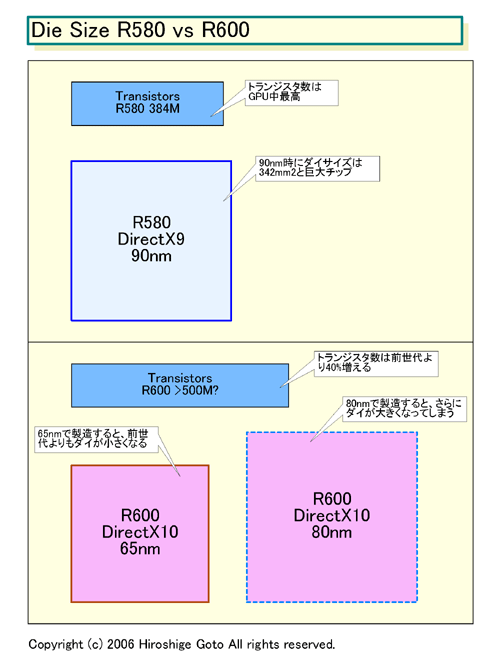
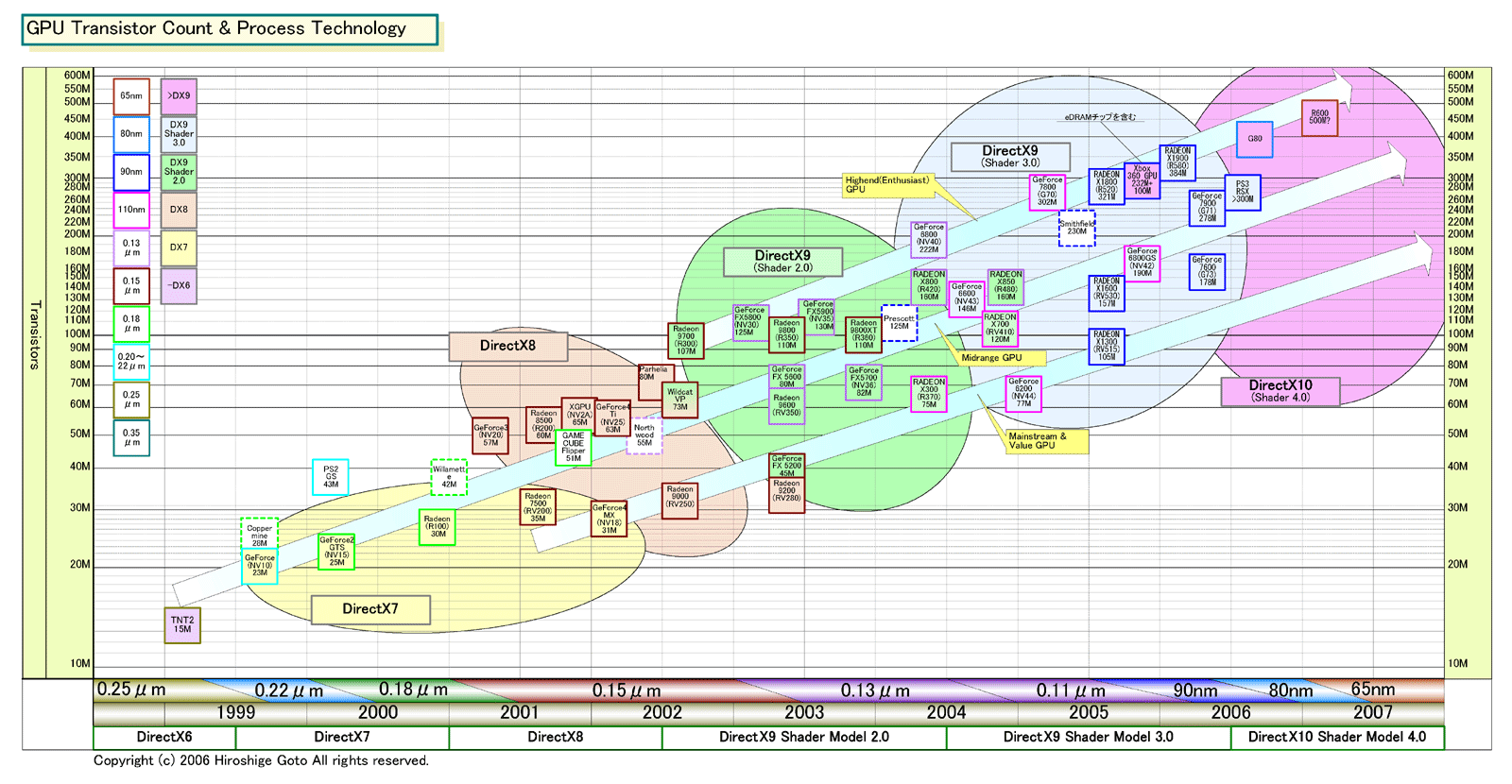
実際、ATIの課題は、膨大なトランジスタ数を必要とするUnified-Shaderのオーバーヘッドだ。ATIは、DirectX 10世代GPUでは、DirectX 9世代より約40%もトランジスタ数が増えると説明しているという。現行のハイエンドRadeon X1900(R580)は384M(3億8,400万)トランジスタなので、ハイエンドR600になると計算上500M(5億)トランジスタクラスの巨大GPUとなる。ATIの言う40%増が、Shader数の増加も含めているのかどうかはわからない。現在のウワサでは、R600のShader数は64ユニットに達すると言われている。
R580のダイサイズ(半導体本体の面積)は342平方mm。とすると、1.4倍の規模のGPUを80nmプロセスで製造すると単純計算でダイサイズは約380平方mmとなってしまう。実際には、90→80nmのハーフノードでは、そこまでシュリンクせず、もっと大きくなる場合も考えられる。極大であるR580よりさらに大きくなるわけだ。しかし、65nmで製造すればダイは計算上250平方mmとなる。これは、Radeon X1800(R520)より二回りくらい小さい。
 |
| R580とR600のダイサイズ PDF版はこちら |
●肥大化するUnified-Shader型GPUのために65nmが必要
ATIが65nmプロセスを必要としたのは、この膨大なトランジスタを経済的なダイサイズ(半導体本体の面積)に納めるためだったと推定される。そのため、ATIではDirectX 10=Unified-Shader=65nmプロセスをセットにすると見られる。
ATIは、80nm世代では、R500系アーキテクチャのGPUファミリしか投入しない。既存のR500系の後継となる「RV560」「RV535」「RV570」で、基本はシュリンク版だ。ATIの80nm世代はこの夏に出荷予定だ。その先は、65nmとなる。「今設計しているGPUは全て65nmプロセスだ。65nm製品も、上から1,2,3とフルラインナップで出てくる」とHeye氏は語る。つまり、R500系と同様に、R600系も上から下まで一気に65nmプロセスへと切り替える。
ATIが現在、先端GPUを製造委託しているTSMCでは、65nmのハイスピードロジック向けプロセス「CLN65HS」のリスクプロダクションを始めつつある。GPUの場合、シリコンが完成してから量産までミニマム3カ月、通常のサイクルで6カ月かかる。「製品をテープアウト(設計完了)してからサンプルが出るまで6週間、サンプルを評価するのに1カ月半から2カ月。通常は、このサイクルを2回繰り返すため、テープアウトから製品まで6~7カ月はかかる」とATIの元会長兼CEOだったK. Y. Ho(KY・ホー)氏は、以前のインタビュで語っていた。
そのため、ATIがTSMCの65nmの立ち上げに沿って最初のシリコンの設計を進めると、2007年の頭には65nm GPUを出荷できることになる。実際、ATIは90nmではTSMCの立ち上げに沿って製品を開発、最初は2005年の前半に出荷する予定だった。しかし、さまざまなトラブルでR520の開発は遅れ、その結果、90nm投入はずれこんだ。ATIが65nmで同じようなスケジュールで動いているとすれば、65nmプロセスは2007年前半をターゲットとしていることになる。
もっとも、新プロセス技術の早期の採用は、かなりリスキーだ。プロセスの立ち上がり期は歩留まりが悪く、歩留まり向上が予定通りに行くかどうかは一種の賭けだからだ。過去にも、新プロセスを使ったために、リリースが遅れたGPUは数多くあった。そのため、ATIの65nmプロセスを使うという決定は、かなり冒険のように見える。
 |
| GPUのダイサイズとプロセス技術 PDF版はこちら |
 |
| GPUのトランジスタ数とプロセス技術 PDF版はこちら |
●消費電力面で有利な65nmプロセス
ATIのOrton氏は、65nmプロセスが比較的早期に立ち上がることを確信する。
「65nmは比較的早く立ち上がるだろう。その理由の1つは、携帯電話市場が65nmを牽引していることだ。ファブレス(半導体工場を持たないベンダー)の世界では、150nmから130nm、90nmまでのプロセスは、グラフィックスエンジンが引っ張ってきた。しかし、65nmでは、携帯電話系、例えば、FPGAベンダーや、ベースバンドを含むASICの企業などが先行している。彼らは、我々グラフィックスベンダーよりも先に、新プロセス技術に向かっている。だから、我々が(65nmを)使う段階になった時は、技術の基本的な部分はすでに実証されているだろう。
これまでは、各プロセスノードは、ほぼ2年サイクルで移行してきた。130nmから90nm、65nmと、2年サイクルは継続されるだろう。90nmは、一見遅れたように見えるが、実はそうではない。我々が90nmプロセスの製品を市場に投入したのは2005年の10月だったが、実際には、我々が設計したXbox 360向けGPU(Xenos)の製造は、2005年の春夏から始まっていた。そして、2007年の春から夏には、65nmは確実に来るだろう。だから、90nmから65nmへの移行も、2年ということになる」
また、ATIは65nmプロセスが電力効率の面で優れているという。
「65nmでは消費電力がクリティカルな要素になっている。その点が、これまでのプロセスと大きく異なる。理由は、携帯電話向けデバイスが、65nmを引っ張っていることだ」(Orton氏)
ATIは、顧客に対して、65nmプロセスはモバイルフレンドリな低消費電力プロセスだと説明しているという。また、ATIはこの世代では省電力技術にかなりフォーカスしたと言われる。低リーケッジ(漏れ電流)のためのBack-Bias回路設計技術を全面的に採用、デマンドベースの周波数スイッチングをCPU同様にハードウェアで実装、GPUエンジンとメモリインターフェイスのクロックを個別に制御するといった技術を投入するという。また、オンチップサーマルセンサーによって、正確にチップ温度を測ることで、より安全にきめ細かくサーマル管理を行なえるようにするようだ。つまり、CPUが採用しているような、低消費電力技術を、本格的に取り入れ始めたわけだ。
こうしたプロセス/回路設計/アーキテクチャレベルの低消費電力化によって、R600ではかなり消費電力を抑えるとATIは伝えているという。例えば、先端プロセスの最大の課題であるリーケッジの抑制は25~50%向上する予定だ。R600は現行のDirectX 9 GPUと比べて、トランジスタ数が40%増えても、TDP(Thermal Design Power:熱設計消費電力)は逆に少なくなると伝えたらしい。
また、同社は、80nm版のDirectX 10 GPUは、現行モデルの1.6倍のTDPになると試算したという。1.6倍は、ATI側の勝手な試算だが、実際、NVIDIAはOEMベンダーに対して、G80ボードのマックス電力が175W程度になると伝えたと言われる。この数字は、製品では変わる可能性があるが、G80がGeForce 7900 GTX(G71)より電力食いであることは間違いない。
●Unified-Shaderへと急ぐか急がないかが両者の違い
こうして整理すると、ATIとNVIDIAのアプローチの対照が際だつ。
NVIDIAは、とりあえず、DirectX 10をフルに活かすことより、最初の世代では安全パイでDirectX 10に早く対応することを選んだと見られる。NVIDIAも、Unified-Shader関連の特許を出願しており、Unified-Shaderの開発は進めている。65nmプロセスにしても、当然準備はしている。ATIとの違いは時期だ。
この判断はある意味で正しい。DirectX 10のランタイムを積んだWindows Vistaはスリップしており、アプリケーションのDirectX 10対応はさらにその先だ。それなら、DirectX 10に最適化するのは次のフェイズに持ち越しても、クリティカルではない。
しかし、DirectX 10へのシフトが勢いよく進むと、ATIのアプローチの方が有利になる。Unified-Shaderが期待通りの性能を発揮できるなら、DirectX 10ではR600の方がパフォーマンスを出せる可能性があるからだ。また、NVIDIAが指摘するUnified-Shaderの難しさも、ATIは段階的にクリアしつつある。
ATIは、Xbox 360向けに開発したGPU「Xenos」からUnified-Shaderを採用。また、R500シリーズでは、Unified-Shaderで重要となる高並列のマルチスレッディングや粒度の小さいスレッドの制御を実装。Unified-Shader化によって増大するメモリクライアント数に対応しやすい、リングバス経由のメモリコントローラアクセスなども備えた。段階的にUnified-Shaderへの対応を進めており、ジャンプの幅は小さい。
はたしてどちらのアプローチが正しいのか。その答えは、市場が出す。しかし、1つだけ確実なのは、CPUにベクタプロセッサコアとして統合する場合には、ATIのアーキテクチャの方が有用だという点だ。
□関連記事
【4月19日】アーキテクチャの改革を“急ぎすぎない”NVIDIA
http://pc.watch.impress.co.jp/docs/2006/0419/kaigai262.htm
【4月18日】DirectX 10サポートで2派に分かれるGPUベンダー
http://pc.watch.impress.co.jp/docs/2006/0418/kaigai261.htm
【7月25日】AMDとATIのプロセッサは1つに融合する
http://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
(2006年7月27日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.