 |


■後藤弘茂のWeekly海外ニュース■Intel CPUの未来が見える80コアTFLOPSチップ |
●オンチップネットワークの研究のためのCPU
Intelは2月11日から米サンフランシスコで開催されている半導体学会「ISSCC(IEEE International Solid-State Circuits Conference) 2007」で、1チップでテラフロップ(TFLOPS)の演算パフォーマンスを実現する実験チップ「Network-on-Chip(NoC)」の技術詳細を発表した。
NoCは、80個のCPUコアをオンチップの2Dメッシュネットワークで結合。ターゲットとする動作周波数は4GHz。ラボでは62Wの消費電力で、1.01TFLOPSのパフォーマンスを達成したという。パフォーマンス/消費電力が異常に高いことになる。
NoC自体はそのまま製品化されるチップではないが、そのアーキテクチャからは、Intel CPUが向かう次のアーキテクチャの方向が明瞭に見える。
特に重要なことは、Intelがこの実験チップで、オンチップネットワークの設計にフォーカスしている点だ。NoC(ネットワークを載せたチップ)という名称からも、同社がオンチップネットワークを、数10コア世代のマルチコアCPUのカギとなる技術と考えていることがわかる。
もっとも、Intelは以前からこうした方向を示唆している。Intelの研究開発を統括するJustin R. Rattner(ジャスティン・R・ラトナー)氏(Intel Senior Fellow, Director, Corporate Technology Group)は、2年半前のインタビューで次のように語っていた。
「従来のプロセッサ研究は、マイクロアーキテクチャにフォーカスしてきた。スーパースカラ、アウトオブオーダ、投機実行……。しかし、プロセッサがマルチコア化すると、課題は、どうやってプロセッサコアをインターコネクト、協調、同期、コミュニケーションさせるか、といった事柄になる。これらは、伝統的にはシステムの課題だったが、マルチコア/メニイコアではプロセッサの課題となる」
今回のNoCからは、Intelがかなり以前からオンチップネットワークについて研究を重ねてきたことが覗える。
Intelは、このNoCの概要を2006年秋の「Intel Developer Forum(IDF)」で発表している。今回のISSCCでは、その技術的な詳細が一部明らかにされた。ベールがはがれるにつれて、見えてきたのは、Intelが実験とは思えないほどこのチップの開発に注力していること。その一方で、IDF時に華々しく謳ったスペックと、現実のチップの差も見えてきた。
例えば、IDF時には、NoCチップにはSRAMチップを重ねるダイスタッキングでメモリを接続。オンチップルーターも、3次元接続でSRAMチップに接続されているといった説明がなされた。しかし、現実のNoCでは、ダイスタッキングは行なっていない。スタックドメモリのサポートは将来になるという。オンチップネットワークとダイスタッキングの2つを同時に試すリスクは冒さなかったことになる。
 |
| IDF 2006 Fall時のプレゼンテーションでは 微妙にチップサイズなどが異なっている (※別ウィンドウで開きます) PDFはこちら |
●極めて小さなコアを80個集積したプロセッサ
今回発表されたNoCのダイ(半導体本体)は下のようになっている。
 |
| NoC Die Overview(※別ウィンドウで開きます) PDFはこちら |
チップ全体はタイル状に80個のプロセッサが並んでいる。横が8個、縦が10個の8×10のメッシュ構成で、チップの上辺と下辺の2つのエッジがI/Oエリアとなっている。製造プロセスは65nmプロセスで、Core 2ファミリと同じ。ダイサイズは275平方mm(12.64×21.72mm)と、65nmプロセスのクアッドコアx86 CPUと同程度だ。つまり、x86 CPUが4コア収まる面積に、20倍の80コアを納めたことになる。
チップの総トランジスタ数は100M(1億)。チップサイズの割にトランジスタ数が極めて少ないのは、トランジスタ密度の高いSRAMが少なく、大半がロジック回路で占められているからだと推測される。
NoC状の80個のプロセッサはタイル(Tile)と呼ばれている。各タイルは3平方mm (1.5×2mm)と極めて小さく、トランジスタ数はわずか1.2M(120万)。これはx86 CPUで言えば486DXクラス。小さいCPUコアで知られるCell Broadband Engine(Cell B.E.)のSPE(Synergistic Processor Element)ですら7M(700万、Local Memoryを除いた数字)だ。
タイルのダイエリアの中を見てみると、なぜここまで小さいのかがよくわかる。タイルの中は極めてシンプルで、2つの浮動小数点演算ユニット(FPMAC)と、命令を格納する「Instruction Memory (IMEM)」、データを格納する「Data Memory (DMEM)」、そしてオンチップネットワークのルーター、レジスタファイルなどで構成されている。FPMACはどちらも単精度浮動小数点用のスカラ演算ユニットだ。命令のスケジューリング機構や整数専用の演算ユニットは持たず、演算だけに特化している。
●2個の浮動小数点演算ユニットを各タイルに搭載
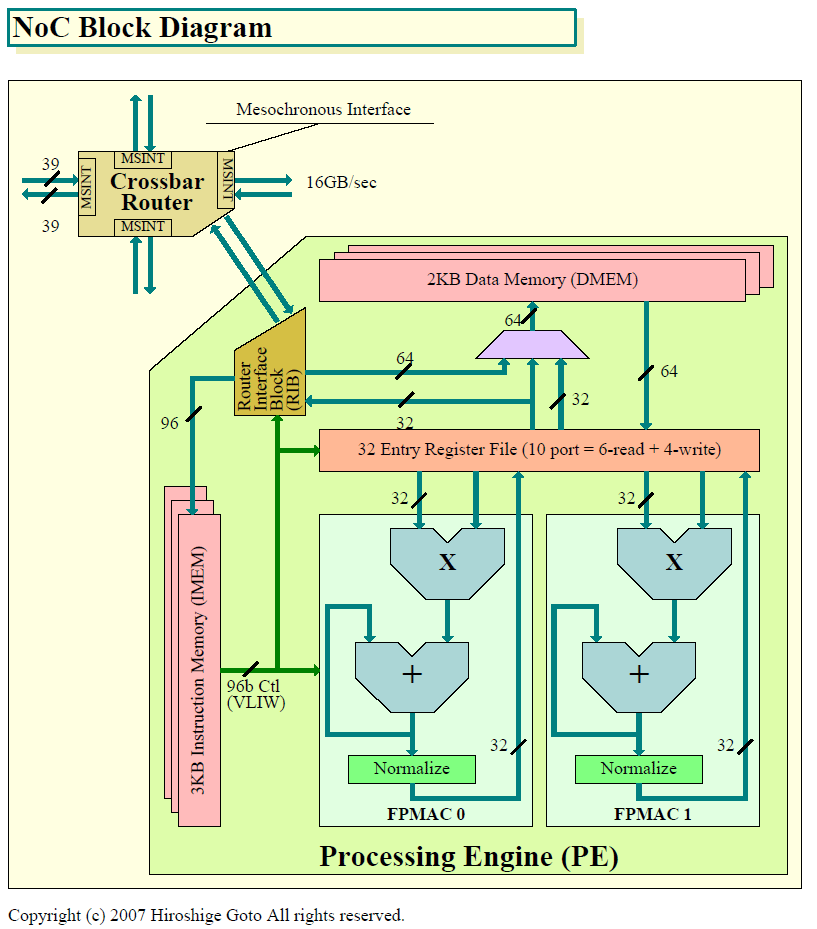 |
| NoC Block Diagram(※別ウィンドウで開きます) PDFはこちら |
NoCのタイルのブロック図はこのようになっている。各タイルは、「プロセッシングエンジン(PE)」とクロスバールーターの対で構成されている。クロスバールーターは5wayのルーターで、上下左右の隣接するタイルのルーターと、「メソクロノスインターフェイス(Mesochronous Interface)」で結んでいる。メソクロノスつまり位相のずれを許容(補正)できるネットワークとなる。ネットワークのトポロジはメッシュで、ルーターの各ポートは、ポイントツーポイントで隣のタイルのルーターと接続している。
PEの中の2個のFPMACは、どちらも乗算と加算が可能な積和算(MAD:Multiply-Add)ユニット。1サイクルスループットで乗算と加算の2オペレーションを実行できる。演算レイテンシは9サイクルと短い。レジスタファイルは共用で32エントリ。ポート数は10で、2つのFPMACに対して4つのリードと2ライト、DMEMからのロードとストア、ネットワークからのパケットのセンド/レシーブを同時にスケジュールできる。4GHzをターゲットとするため、パイプラインは15 FO4(Fanout-Of-4)設計と比較的ディレイの短い設計にされている。
各PEのFPMACがそれぞれ2オペレーション/サイクルスループットで動作するため、1タイルの性能は4 FPオペレーション/サイクルとなる。タイルは80個あるので、NoC全体では320 FPオペレーション/サイクル。NoCが4GHzで動作すれば320×4GHzで1.28TFLOPSとなる。1TFLOPSは3.16GHzで達成できる。ちなみに、ラボでは最高5.67GHz、1.81TFLOPSで動作したという。この性能は、データパラレルで演算に特化しているGPUの、シェーダ演算性能に勝る。
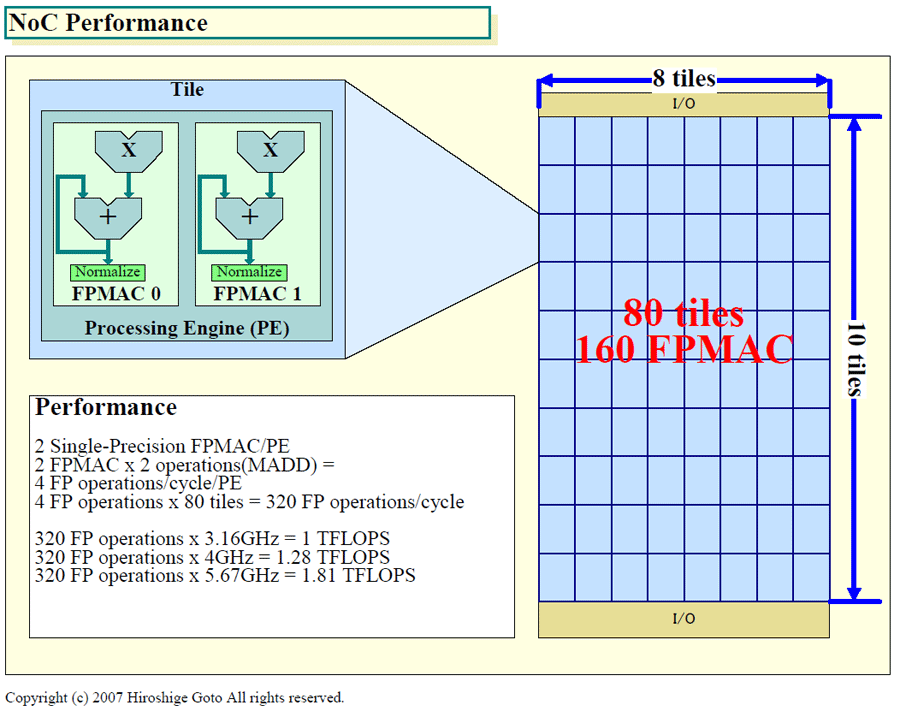 |
| NoC Performance(※別ウィンドウで開きます) PDFはこちら |
高パフォーマンスは、NoCが演算だけに特化した結果だ。NoCは単体で動作するCPUというより、汎用CPUと組み合わせることを前提としているように見える。各PEも独立したプロッサというより、ソフトウェア制御されタイルベースで並列に演算を行なうプロセッシングユニット的なイメージだ。
●96bitの特殊なVLIW型命令セット
NoCの命令セットは、IA-32命令とは全く異なる。複数のオペレーションを1命令語に格納するVLIW(Very Long Instruction Word)形式を取っている。VLIWである点はIA-64と同様だが、命令フォーマットは大きく異なる。NoC命令は96bit長のVLIW命令で、最大8オペレーション/サイクルをエンコードできる。96bit長で8オペレーションと多くのオペレーションを格納できる理由は、特定命令の命令スロットを備えているためだ。下がNoCの命令フォーマットだ。
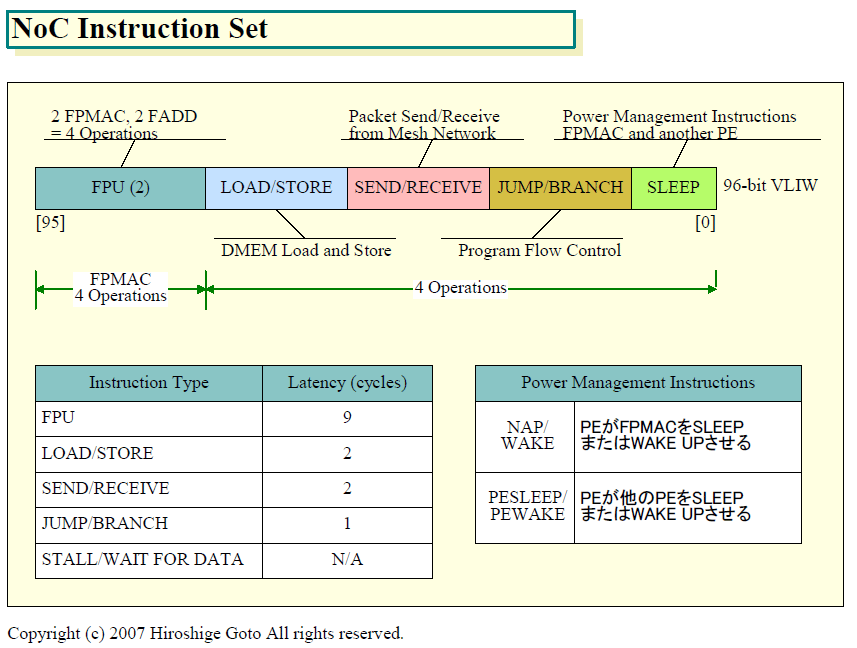 |
| NoC Instruction Set(※別ウィンドウで開きます) PDFはこちら |
96bit長命令の中には、2ユニットのFPMACに対する演算命令のスロットの他に、命令スロットが4つある。データメモリに対するロード/ストア命令のスロット、メッシュネットワークに対するパケットのセンド/レシーブ命令のスロット、命令フロー制御のジャンプ/ブランチ命令のスロット、そしてパワーマネージメントのためのスリープ/ウエイク命令のスロット。
FPMACがSIMD型制御でないとすると、FPMACの命令スロットは両FPMACそれぞれに対する2つで、合計6命令スロットということになる。VLIW内の各命令は固定長ではないと推測される。おそらく、FPMAC向けの通常命令スロットは32bitなど標準的な長さで、後半の特殊命令スロットは短いと推測される。つまり、CISC(Complex Instruction Set Computer)的な可変命令をVLIW式に詰め込んだ可能性が高い。
そのため、NoCでは、2個のFPMACに演算命令を発行しながら、同時にロード/ストアユニットと「Router Interface Block(RIB)」、ブランチユニットに命令を発行することができる。パワーマネージメント命令も並列にできるのは、ほかのPEに対するパワーマネージメントのための命令も含んでいるため。
NoCには、その命令を実行するPEのFPMACをスリープステイトに移行させたりウエイクアップさせたりするNAP/WAKE命令の他に、他のPEをスリープ状態にしたりウエイクアップさせたりするPESLEEP/PEWAKE命令が含まれる。ネットワーク経由で、他のPEをウエイクアップして、タスクを渡すことができる。
ルーターとPEの間の「Router Interface Block (RIB)」は、オンチップネットワークのパケットをハンドルする。ルーターは5ポートで、PEへのポートのほか、上下左右のタイルのルーターと結ぶ。将来はダイスタックするSRAMチップへのポートも設けられ、3Dルーターになるという。
80GB/sec(4GHz時)の帯域のノンブロッキングクロスバースイッチを備える。ルーター内部は論理レーンがあり、「FLIT (FLow control unIT)」のキューとアービター、フロー制御ロジックを備える。NoCのパケットは複数のFLITで構成されている。ヘッダーには最大10個のデスティネーションID(Destination ID (DID))が格納でき、10ホップが可能となっている。パケットサイズには制限がないという。
 |
| NoC Packet Format(※別ウィンドウで開きます) PDFはこちら |
●パフォーマンス/消費電力に最適化されたコア
IntelはNoCではTFLOPSクラスのパフォーマンスにフォーカスするだけでなく、パフォーマンス/消費電力を高めることにもかなり力を注いでいる。
粒度の小さなクロックゲーティング制御を行ない、スリープトランジスタとボディバイアスによる電力制御も備えている。各タイルは21のスリープリージョンに分割されており、リージョン単位でスリープさせることができるという。FPMACは90%がスリープが可能、ルーターはトラフィックをパスしながらスリープで10%の低消費電力が可能、IMEMは56%、DMEMは57%のスリープによる電力削減が可能という。タイル全体がスタンバイに入った場合は50%の低消費電力化が、タイル全体がフルスリープに入った場合は80%の低消費電力化が可能だという。
NoCの消費電力とパフォーマンスは以下の通り。パフォーマンス/消費電力ではGPU(のプログラマブルな演算性能)に勝っている。
| 周波数 | 性能 | 電圧 | 消費電力 |
|---|---|---|---|
| 1GHz | 0.32TFLOPS | 0.6V | 11W |
| 3.16GHz | 1.01TFLOPS | 0.95V | 62W |
| 5.1GHz | 1.63TFLOPS | 1.2V | 175W |
| 5.67GHz | 1.81TFLOPS | 1.35V | 265W |
●テラスケールの重要なマイルストーン
NoCは、将来のテラ/ペタスケールコンピューティングのためのビルディングブロックという位置付けだ。研究目的のためだけに、膨大な開発コストをかけてチップを作ってしまう点がIntelらしい。しかし、Intelにしても、これだけのチップの開発は負担であるはずで、NoCのアーキテクチャや機能は、研究の結果、かなり絞り込まれたものと推定される。NoCの命令セットアーキテクチャやルーターとパケット構造などは、継続的な研究の成果のように見える。
Intelのテラスケールのマイルストーンでは、次のステップとしては、NoCに必要なメモリ帯域を解決するスタックドメモリが待っている。さらに、今回のような演算に特化した特定目的コアではなく、IAアーキテクチャコアを多数搭載したアーキテクチャも視野に入っているという。すでに、2006秋のIDFで、IntelはIAアーキテクチャの小型コアについてのビジョンも語っている。
もっとも、実際の製品では、どのようにテラスケールの研究が反映されて来るか、まだわからない。汎用CPUコアとNoCのような特定用途向けアーキテクチャの組み合わせ、またはハイブリッド型のCPUになる可能性が高い。いずれにせよ、Intelの次のビジョンが、NoCで見え始めた。
 |
| 次のステップはスタックドメモリ(※別ウィンドウで開きます) PDFはこちら |
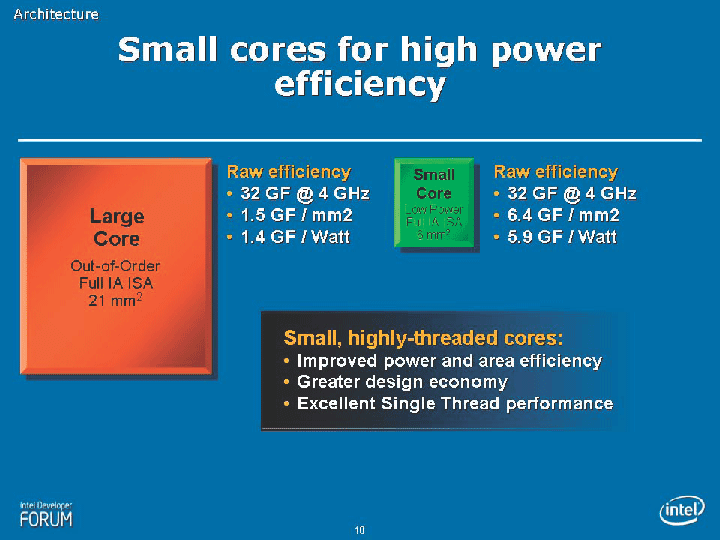 |
| Small cores for high power efficency(※別ウィンドウで開きます) PDFはこちら |
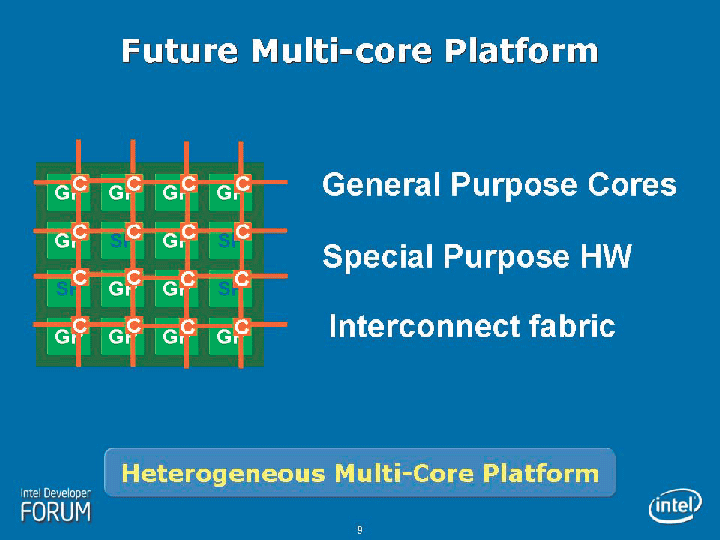 |
| Future Multi-Core Platform(※別ウィンドウで開きます) PDFはこちら |
□関連記事
【2月14日】【ISSCC】Intel、80コアの並列プロセッサで1.81TFLOPSを達成
http://pc.watch.impress.co.jp/docs/2007/0214/isscc02.htm
【2006年10月14日】【海外】SSE4命令とアクセラレータから見えるIntel CPUの方向性
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
【2006年10月2日】【海外】次世代CPUのヒントが出されたIDF
http://pc.watch.impress.co.jp/docs/2006/1002/kaigai306.htm
(2007年2月15日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.