
ISSCC 2007レポート
Intel、80コアの並列プロセッサで1.81TFLOPSを達成
 |
カンファレンス会期:2月12日~14日(現地時間)
会場:米国カリフォルニア州サンフランシスコ
Marriott Hotel
米Intelは、80個の演算ユニットを内蔵した並列プロセッサを試作し、5.67GHzの高い周波数で動かすとともに1.81TFLOPSと非常に高い性能を達成してみせた。半導体回路技術に関する国際会議ISSCCで、その詳細を発表した(講演番号5.3)。
Intelが80個の演算ユニットを内蔵した次世代高性能並列プロセッサを開発していることと、演算性能として1TFLOPSを狙っていることは、2006年9月末のIDF(Intel Developer Forum)で明らかになっていた。今回は開発中の並列プロセッサが実際に1TFLOPSを達成したことと、並列プロセッサの技術内容が初めて公表された。
演算性能(単精度浮動小数点演算性能)は、摂氏80度の環境下で動作周波数が約1GHz(電源電圧約0.65V)のときに0.32TFLOPS、約3.1GHz(電源電圧約1V)のときに1TFLOPSである。最高性能は1.81TFLOPSで、動作周波数は5.67GHz(電源電圧1.35V)。
消費電力は、温度が摂氏110度のときに動作周波数5.67GHz(電源電圧1.35V)で230W、この条件下での演算性能は1.33TFLOPSである。演算性能を考慮すると、消費電力は相当低く抑えられているといえる。動作周波数がもう少し低い4.27GHzのときには消費電力が97W、演算性能は1TFLOPSとなる。1W当たり約10GFLOPSという性能をたたき出している。
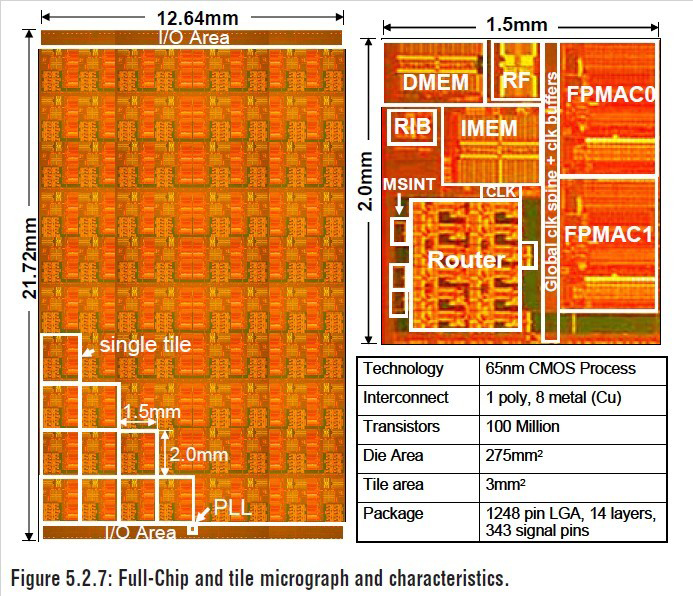 |
| 80個の演算ユニットを内蔵した並列プロセッサのチップ写真。ISSCCのTechnical Digestから引用(講演番号5.2)。左がチップの全体像。右が演算ユニット部分を拡大したところ。右下は製造技術の概要 |
開発した並列プロセッサのチップ写真は2006年のIDFレポートですでに紹介されているが、ISSCCでもチップの全体写真が示された。なおチップ寸法はIDFのときは13.75×22mm(幅×奥行き)だったが、ISSCCでは12.64×21.72mm(同/275平方mm)となっている。
{kind=link}
演算ユニット(PE:Processing Engine)は、2個の単精度浮動小数点演算ユニット(FPU)と命令メモリ、データメモリ、ルーターなどで構成される。FPUは96bitのVLIWアーキテクチャを採用しており、9段のパイプラインで動く。1クロックサイクルで最大8個の命令を同時に処理できる。命令メモリは3KBの容量があり、FPUは1サイクルで命令メモリにアクセスできる。データメモリの容量は2KBである。ルーターは5ポートの入出力インターフェイスを備えており、隣接する演算ユニットとデータをやり取りする。各ポートは最大データ転送速度16GB/secの性能を有する。
この演算ユニットを8×10の2次元マトリクス状に並べて各演算ユニットをルーターで結んだ。チップ全体では、160個のFPUを内蔵していることになる。
製造には65nmのCMOSプロセスを採用した。配線層は1層多結晶シリコン、8層金属(銅)配線である。第7層と第8層をクロック配線に割り当て、クロック信号の分配によるばらつきを減らしている。またクロック発生信号そのものの精度を高めるために、PLL回路を搭載する。チップの短辺側の端、中央にPLL回路を配置し、短辺全体に8層金属配線でクロック信号を分配する。そこから各演算ユニットの中央を貫くように、7層金属配線が長辺方向に伸びる。シミュレーションで見積もった演算ユニット間のクロックスキューは4psである。
消費電力の低減策としてはクロックゲーティングや基板バイアスなど、低消費電力設計のいわば常識とも言える技術が組み込まれている。1個の演算ユニットは21カ所の電力ドメインに分割されており、きめ細かに電力供給を停止できる。
このようにして設計、製造したチップ(ダイ)を1,248ピンのプラスチックLGAパッケージに封止し、評価ボードに実装して性能を測定した。パッケージの大きさは66mm角。パッケージ内の配線層数は14層である。パッケージ基板にはダイをフリップチップ接続してある。
そして測定の結果、1TFLOPSの演算性能や動作周波数、消費電力などを確認できた。消費電力の内訳で最も大きいのはFPUで、全体の36%を占める。次でルーターの消費電力が大きく、全体の28%である。それから命令メモリおよびデータメモリが21%を占めている。
 |
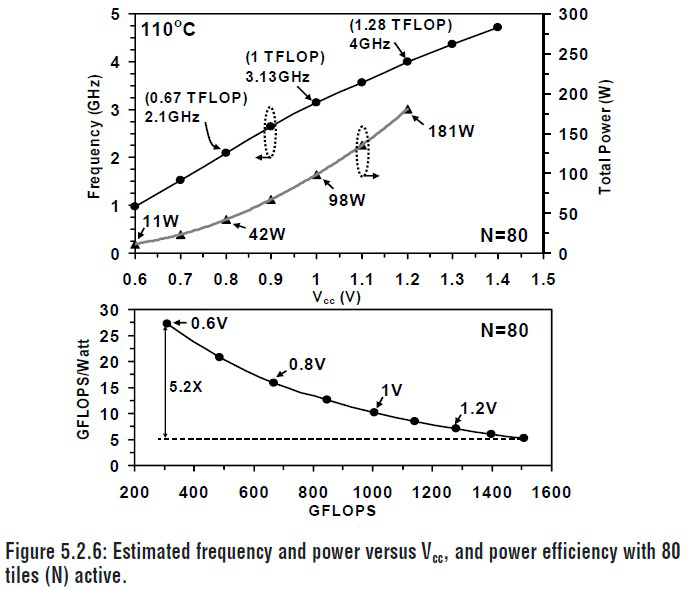 |
| 80個の演算ユニットを内蔵した並列プロセッサを評価ボードに搭載したところ。Intelのプレスキットから引用。なおISSCCの講演では、並列プロセッサをプラスチックLGAに封止して評価ボードに搭載した写真が示されていた。放熱の手間や信号の周波数などを考慮すると、プレスキットの写真の方が実際の測定セットアップに近そうだ | 並列プロセッサの動作周波数と電源電圧。ISSCCのTechnical Digestから引用(講演番号5.2)。講演で実際に見せた数値は、このグラフから少し変化があった。テキスト本文中の数値は講演内容から引用しているので注意されたい。なお図中に大文字で「N」とあるのは演算ユニットの数 |
□ISSCCのホームページ(英文)
http://www.isscc.org/isscc/
□Intelの80コア並列プロセッサに関するリリース(英文)
http://www.intel.co.jp/pressroom/archive/releases/20070204comp.htm
□関連記事
【2月13日】【ISSCC】最先端のプロセッサとメモリが続出
http://pc.watch.impress.co.jp/docs/2007/0213/isscc01.htm
【2006年9月28日】【IDF】ラトナーCTO基調講演レポート
http://pc.watch.impress.co.jp/docs/2006/0928/idf02.htm
(2007年2月14日)
[Reported by 福田昭]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.