 |


■後藤弘茂のWeekly海外ニュース■CPUはイノベーションの時代に |
●マルチコア時代の課題の克服がCPU業界のトピック
「ますます明確となる、マルチコアCPUへの潮流」
8月20日から米スタンフォードで開催されたハイパフォーマンスチップのカンファレンス「HotChips 18」では、マルチコアへ向かう流れが、奔流になりつつあることが浮き彫りとなった。
カンファレンスのキーノートスピーチでは、IBMが伝統的な半導体スケーリングが鈍化した、現在のプロセス技術のトレンドを説明。その結果、CPUパフォーマンスの向上は従来のように半導体スケーリングに頼るのではなく、イノベーションが必要となると示した。IBMは、イノベーションとしてさまざまな方向性を示したが、そのカギの1つはチップレベルのマルチコアだった。
カンファレンスのもう1つのキーノートスピーチでは、IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Intel Senior Fellow, Director, Corporate Technology Group)が登場。数10から100個のCPUコアを集積するメニイコア時代に向けたソフトウェアプラットフォームの取り組みを示した。Intelはメニイコアに最適化したプリミティブソフトウェア層を整えてゆく。また、IntelはスレッドサポートハードウェアなどをCPUに実装することで、マルチコアでスケーラブルにパフォーマンスを上げやすくなることも説明した。
一方、HotChipsのチュートリアルではマルチコアのソフトウェア開発の課題と、今後の方向性がテーマとなった。そこでは、マルチコアプログラミングでは、言語、コンパイラ、ツール、ライブラリ、OS、プログラミングプラクティスといったあらゆるレベルで課題が山積みになっていることが示された。
セッションでは、CPUアーキテクチャ研究で有名なUC Berkeley大学のDavid Patterson(デイヴィッド・パターソン)教授が登場。メニイコア時代の最大の問題がソフトウェアにあると指摘。CPUハードが実際に開発されるまでソフトウェア側の開発がスタートしないという、開発のズレを埋める必要を説いた。その上で、Patterson氏らが進める、FPGAベースでメニイコアプロセッサのソフトウェア面の研究ができるリサーチアクセラレータを提供しようとする「RAMP (Research Accelerator for Multiple Processors)」プロジェクトの概要を説明した。
つまり、過去2年の技術カンファレンスでは、マルチコア化の技術的な必要性などが説かれたのに対して、今回のHotChipsでは、マルチコア時代に現実的にどう対応するかがトピックスとなった雰囲気だ。ただし、マルチコアで本当にアプリケーションパフォーマンスが上がるのか、という根本的な疑問については、まだ業界全体のコンセンサスは取れているようには見えない。
●伝統的なCMOSスケーリングが終わった
 |
| Bernard Meyerson (バーナード・マイヤーソン)氏 |
HotChipsでIBMのキーノートスピーチ「Collaborative Innovation: A New Lever in Information Technology Development」を行なったのはBernard Meyerson(バーナード・マイヤーソン)氏(IBM Fellow; VP Strategic Alliances and Chief Technologist, IBM Systems & Technology Group, Development)。Meyerson氏は、まず、伝統的なCMOSのスケーリングが、もはやこれまで通りには働かなくなった技術的な背景を説明した。
Meyerson氏は、1年10カ月前の2004年10月「Fall Processor Forum」のキーノートでも、似たような内容のスピーチを行なっている。また、IBMは2006年2月のISSCCのキーノート(Plenary Session)でも「Where CMOS is Going: Trendy Hype vs. Real Technology」(Tze-Chiang Chen氏, IBM Fellow, VP of Science and Technology, T.J. Watson Research Center)と題して、半導体のCMOSプロセス技術のスケーリングが鈍化したことを説明している。つまり、IBMは過去数年の技術カンファレンスで、半導体スケーリングの直面した問題について警鐘を鳴らしてきた。今回のMeyerson氏のスピーチは、そのリピートとともに、イノベーションがどのように結実しつつあるかを語るものだった。
IBMのキーノートの前半部分で指摘しているCMOSスケーリングの問題は、ここ数回、このコーナーでレポートしてきた、マルチコアへと向かう流れの最大の根本原因だ。Meyerson氏は「伝統的CMOSスケーリング(Classical CMOS Scaling)の死」という表現をしている。ただし、2004年のプレゼンテーションでは、これをムーアの法則と混同しないようにとも指摘している。スケーリングは、ムーアの法則よりもっと複雑な事柄だからだ。
ムーアの法則自体は、12~18カ月で同じ面積に載せられる半導体のデバイス集積度が2倍になるというもの。実際には、過去10数年間のCMOSは、プロセス1世代でプロセスノードがリニアに0.7倍スケールダウンして集積度が2倍になるペースで推移している。プロセス1世代の移行は約2年前後だった。そして、CMOSスケーリングでは、デバイスのサイズだけでなく、駆動電圧やゲート酸化膜厚といった要素もスケールダウンしてきた。下のスライドの左の図が伝統的スケーリングを示している。
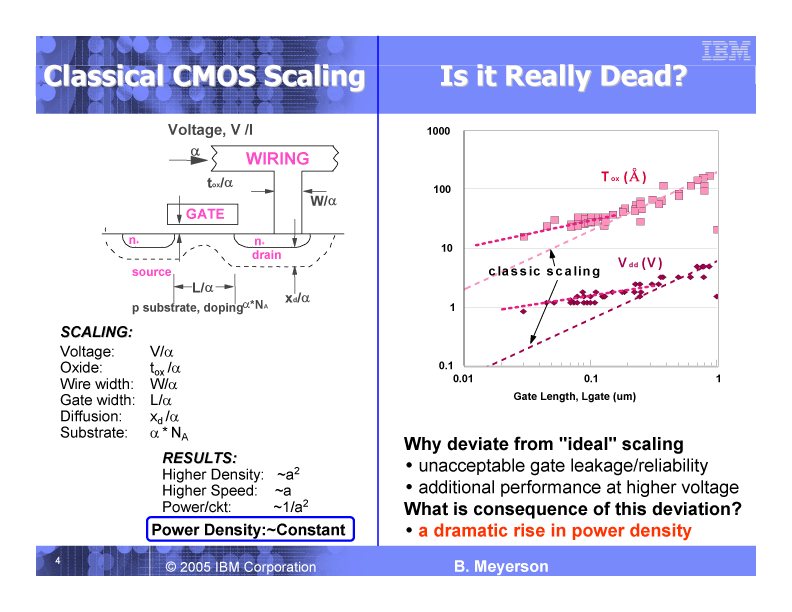 |
| 伝統的なCMOSスケーリング (PDF版はこちら) |
●VddとToxが従来のスケーリングからずれ始めた
伝統的CMOSスケーリングは、CPUにとっていいことづくめだった。下のスライドは2004年のもので、スケーリングによってトランジスタが小型化すると、CPUにとって以下の利点があることが示されている。
・CPUがより高速になる
・CPUがより低コストになる
・CPUがより低消費力になる
・CPUにより多くの機能を搭載できるようになる
 |
| 伝統的なCMOSスケーリングの利点 |
そして、スケーリングは確実に予測できるため、業界はそれを軸に発展してきた。
しかし、過去数年間はこの伝統的CMOSスケーリングから逸脱しつつある。Meyerson氏は、スケーリングのうち何が変わったかを上のスライドの右の図で説明した。
従来は、トランジスタが微細化し、ゲート長が短くなると、それと同じスケーリングで駆動電圧(Vdd)が下がり、ゲート酸化膜厚(Oxide Thickness:Tox)が薄くなった。ゲート酸化膜が薄くなると,トランジスタのスイッチングが速くなりやはり高速動作が可能になる。しかし、130nm以降は、実際のVddが伝統的スケーリングから乖離し始め、続いてToxも乖離した。つまり、ゲート酸化膜厚は薄くならなくなり、電圧は下がらなくなった。言い換えると、トランジスタの高速化と、消費電力の低減がぐっと鈍化したことになる。
ちなみに、下が同じ図の2004年のFPFのもので、これを見るとしきい電圧(Vt)が下がらなくなったことでVddのスケーリングが鈍化したことがよくわかる。
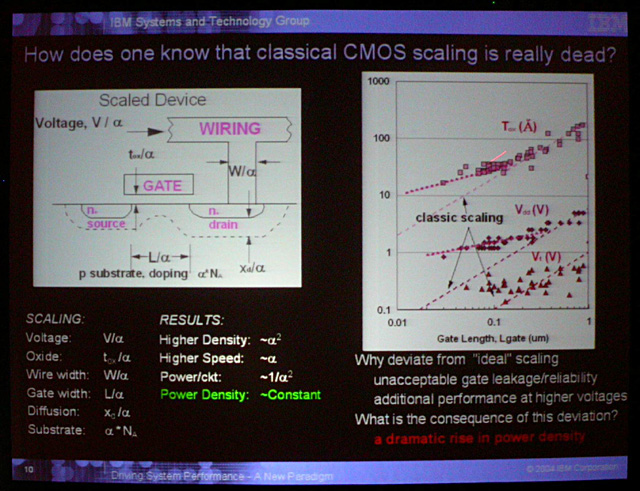 |
| Vddのスケーリングが鈍化 |
スケーリングが鈍化した理由について、Meyerson氏はゲートのリーク電流(Leakage)が許容できないほど増大し、信頼性が低下し始めたことを指摘する。ゲート酸化膜の素材を改善しないで膜厚を薄くすると、リーク電流が劇的に上がってしまう。また、パフォーマンスを上げるために電圧を上げる傾向に向いていることも触れた。
結果、現在のCMOSスケーリングでは、スケールダウンする毎に、ダイ面積当たりの消費電力である「電力密度(Power Density)」が劇的に上がるようになってしまっている。
●原子より細かくすることができない
Meyerson氏は、その根本原因として、トランジスタが微細化した結果、原子レベルにまでスケールダウンしたと説明している。「原子はスケールできない(Atoms don't scale)」、つまり、原子より小さくすることはできないため、限界に近づいてしまったわけだ。ISSCCのキーノートでは、これを「原子論的、量子力学的な限界に近づいた」と表現していた。
例えば、現在のトランジスタは、ゲート絶縁膜が5~6原子分程度の厚みしかない。そのため、原子1個分のばらつき(厚みの増減)が膜の表面で発生すると、膜の上下で合計原子2個分、最大で33%(原子6個時)のばらつきになってしまう。そうなると、ばらつき部分では、リーク電流が他の部分より10~100倍も多くなってしまう。
 |
| 現在のトランジスタのゲート絶縁膜 (PDF版はこちら) |
結果として、プロセッサの電力密度はここへ来て跳ね上がりつつある。電力密度の上昇は、チップが局所的に膨大な熱を発することを意味している。これは、Intelも2001年のISSCCのキーノートスピーチで指摘していた。つまり、CPUの消費電力が上がるのと同時に、電力密度が上がるために、冷却できる限界を超えてしまう、それが問題になるわけだ。
また、電力消費では、アクティブ電力だけでなく、リーク電力の増大によるスタティック電力の増大も大きな問題となりつつある。下の図のように、微細化につれてパッシブ、つまりスタティックな成分が激増している。
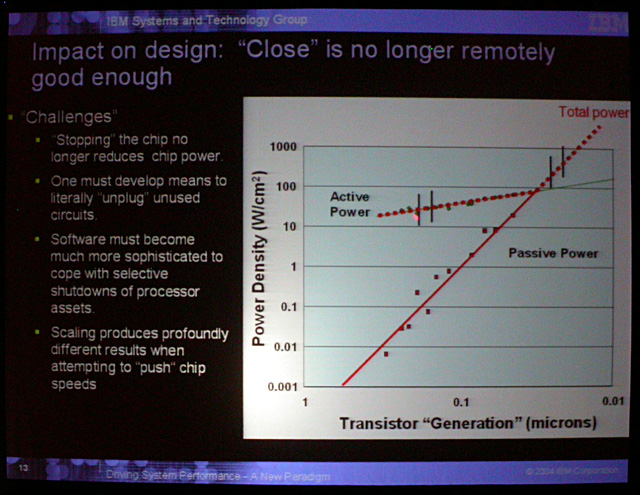 |
| スタティック電力の増大 |
また、ISSCCのIBMのキーノートでは、電力の問題とともに、ばらつき幅の増大も大きな問題として指摘されていた。
もっとも、Meyerson氏はこうしたプロセス技術の危機は過去にも発生したことがあると指摘した。それは、バイポーラプロセスで製造していたメインフレームプロセッサで、'80年代に同様の電力密度の爆発的な増大の危機を迎えたという。しかし、この時は、より消費電力の少ないCMOSプロセスへと移行することで、問題を解決できた。遅延は3~4倍に上がったが、電力は1/15に下がり、密度は50倍に上がった。
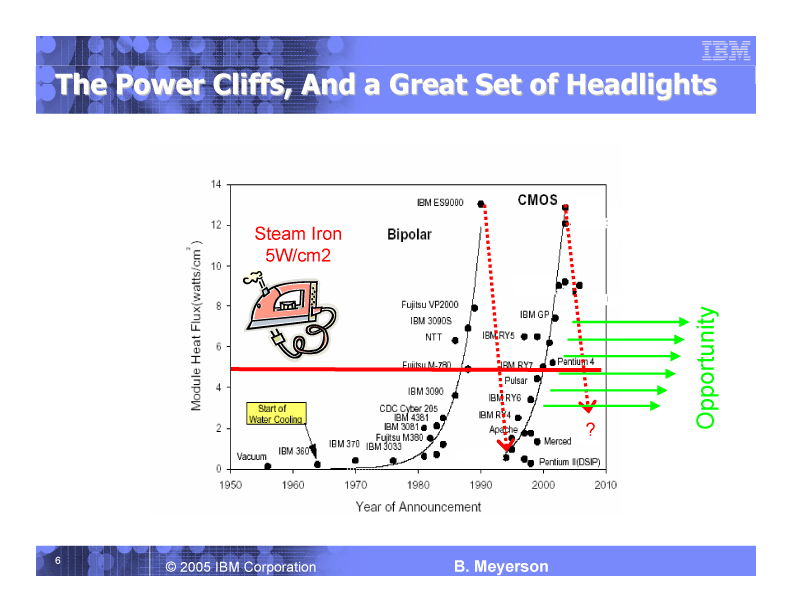 |
| '80年代はバイポーラプロセスからCMOSへの移行で電力密度の問題を解決した (PDF版はこちら) |
今回の問題がより解決困難なのは、その時のような抜本的な代替技術がすぐには見あたらないためだ。ちなみに、ISSCC 06のIBMのキーノートでは2010年以降のあたりに「Ultra-Low Vdd, 3-D Integration?」と書かれていた。3-D Integrationはダイを立体的に統合する技術だ。クエスチョンマークがつけられているということは、新技術の可能性はあるものの、まだブレイクスルーになるかどうか不鮮明ということだ。
●パフォーマンスはイノベーションで向上
では、伝統的CMOSスケーリングが終焉を迎えたことで、CPUにとって何が変わったのか。Meyerson氏は、それを下のように要約した。
| これまで(~2003) | 現在(2004~) |
| パフォーマンスはCMOSスケーリングがドライブ | パフォーマンスはイノベーションがドライブ |
| CMOSスケーリングがコストを下げる | CMOSスケーリングがコストを下げる |
| 制約されたパフォーマンス | 制約された電力 |
| アクティブ電力が支配的 | スタンバイ電力が支配的 |
| プロセッサパフォーマンスにフォーカス | システムパフォーマンスにフォーカス |
 |
| CMOSスケールの終焉によるCPUの変革 (PDF版はこちら) |
簡単に言えば、CPUのパフォーマンス向上は、もうCMOSスケーリングに頼ることができない。2003年までのCPUは、技術的なイノベーションがなくても、スケーリングだけで自動的に性能がアップした。しかし、これからは、さまざまな革新を積み上げないとパフォーマンスのアップは得られない。また、プロセッサの設計では、これからは電力が大きな制約となる。それも、スタティック電力を減らすことに注力しなくてはならない。
こうした制約から、CPUパフォーマンスだけにフォーカスするのでは今後のパフォーマンスアップは難しい。システム全体で、どうやって効率よくパフォーマンスを上げるかを考える必要がある。Meyerson氏が伝えようとしているのは、大まかにいってこういったことだ。
ただ、チャートで指摘しているように、CMOSスケーリングがコストを下げる(集積度を上げる)という点は、依然として変わっていない。これはグッドニュースで、そのために、CPUアーキテクチャでは、まださまざまなイノベーションを行なう余地もある。
●イノベーションはプロセスからCPU、システム、ソフトまで全体にわたる
Meyerson氏によると、イノベーションが必要なのは、半導体のプロセス技術からCPUアーキテクチャ、ソフトウェア層まで全てに渡るという。つまり、ソフトまで含めたイノベーションを進めないと、パフォーマンスがアップして行かないという認識だ。Meyerson氏は、これを全体論的な(Holistic)設計と呼んでいる。
プロセス技術では、トランジスタとインターコネクトの両方について、新しい構造や新素材などが必要とされているという。下の図のように、IBMのプロセス技術では、130nmまでは伝統的スケーリングでトランジスタパフォーマンスをアップして来たが、90nm以降は半導体技術上のイノベーションによってトランジスタパフォーマンスをアップする方向にある。ちなみに、こうした事情から、現在では先端プロセスの開発は非常にコスト高になっている。
 |
| 性能向上はプロセスからイノベーションへ |
では、半導体技術以外では、何が全体論的な設計に当たるのか、HotChipsではサマライズされなかったが、FPF 04では、要約されている。下の図がそれを示したスライドだ。チップレベルでは、マルチコア、アクセラレータ(コプロセッサ)、スイッチファブリック、ハイスピードI/Oなど最近の話題となっている要素が並ぶ。システムレベルではHypervisorとクラスタマネジメントが挙げられている。
 |
| 性能向上にはマルチコア化やアクセラレータなどが必要になってくる |
●CellやPower6はIBMの新しい方向性の成果
2004年のFPFと、今回のHotChipsの最大の差分は、この全体論的な設計の成果にある。2004年秋の段階では、「Cell」も「Power6」も公開されていなかった。そのため、その時のプレゼンテーションは、PowerアーキテクチャのスパコンであるBlueGene/Lを例にとり、今後の方向を示すところまでで終わった。しかし、今回はより具体的な成果を示すことができた。
成果の1つはヘテロジニアスマルチコア型のCellだ。Meyerson氏はCellを、チップレベルの「スケールアウト」の具体例として紹介した。チップ上でコアをスケールアウトして、多数のコアを集積したという位置づけだ。
 |
| テロジニアスマルチコア型のCell (PDF版はこちら) |
それに対して、デュアルプロセッサコアのチップをシステムレベルで統合、131,000プロセッサのシステムを構成するBlueGene/Lは、システムレベルのスケールアウトの例という位置づけだ。
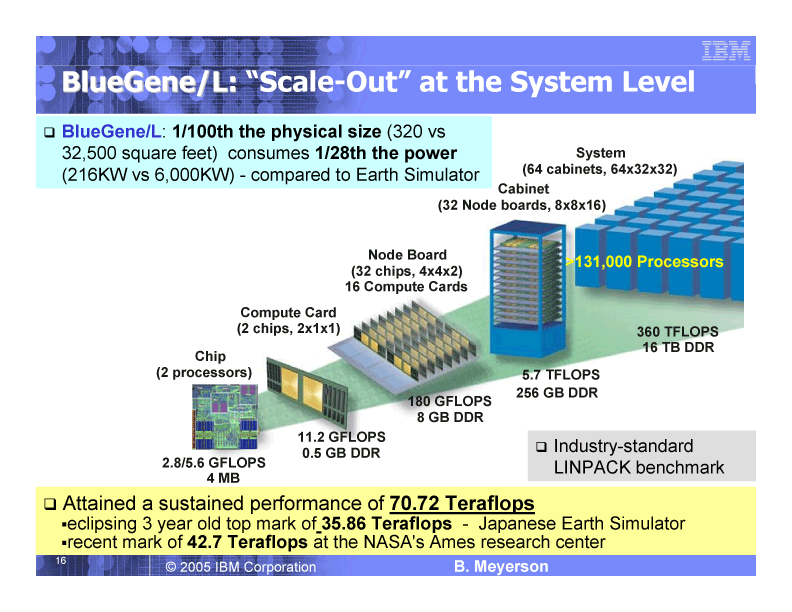 |
| IBMの「BlueGene/L」 (PDF版はこちら) |
また、Meyerson氏はIBMの次世代プロセッサ「Power6」も、全体論的な設計の成果として紹介した。Power6は、ISSCC 06で一部が公開されたプロセッサだ。他のCPUベンダーが、低周波数へと向かうのに対して、IBMはPower6ではウルトラ高周波数設計を取った。4~5GHzという動作周波数は、今のCPUのトレンドと完全に逆行する。これだけの周波数を可能にしたのは、従来型の高クロック化の手法は使わないことでだった。
従来のCPUアーキテクチャのセオリーでは、高周波数化を達成するためには、パイプライン段数を深くしたり、高速なダイナミック回路などを多用していた。ところが、Power6では、深いパイプラインは取らず、回路もスタティック回路で構成している。そのため、電力密度を下げながら高クロック化が可能になったという。あるCPU業界関係者は「Power6は、まるでマジックのよう。IBMの底力が見えた」と評していた。
Meyerson氏は、この他にも、仮想化から液冷システムなどさまざまなイノベーションの例を示した。要は、多方面からのイノベーションを統合しないと、システム性能を上げ続けることは難しくなったということだ。CPUアーキテクチャでの、マルチコアへの奔流も、その中の一部ということになる。
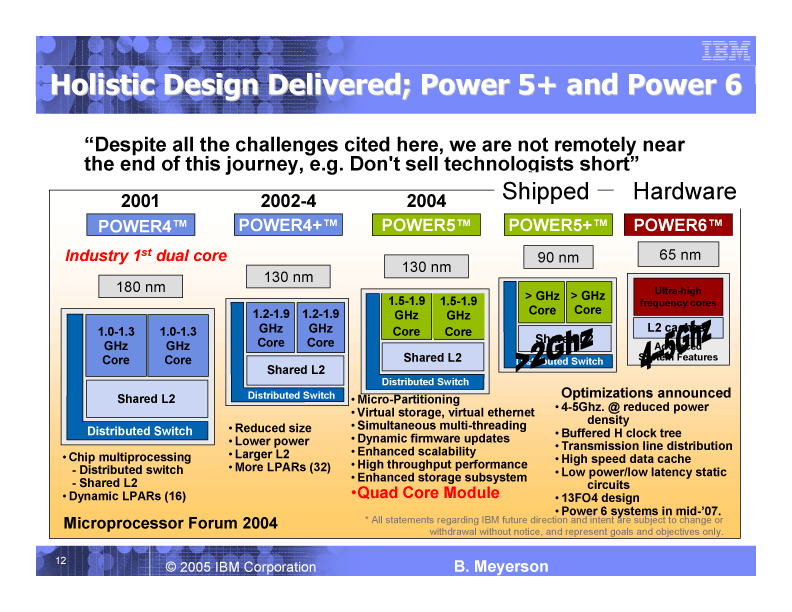 |
| IBMの「Power6」プロセッサ (PDF版はこちら) |
□関連記事
【8月21日】【海外】“シンプルコア”に向かう次世代CPUアーキテクチャ
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
【8月18日】【海外】決定的となったヘテロジニアスマルチコアへの潮流
http://pc.watch.impress.co.jp/docs/2006/0818/kaigai295.htm
(2006年8月29日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.