 |


■後藤弘茂のWeekly海外ニュース■アーキテクチャの改革を“急ぎすぎない”NVIDIA |
●いつUnified-Shaderがリーズナブルになるのかがカギ
前回レポートした通り、DirectX 10世代GPUでは、決して実装面の足並みが揃うわけではない。その背景には、GPUアーキテクチャについての論争がある。
ATI TechnologiesなどがUnified-Shaderへ向かう理由は、これまでも何度もレポートしてきた通り。GPUのフレキシビリティと一貫性を高め、よりプログラマブルにしようとする。GPUを、より汎用性の高いプロセッサへと持って行こうという発想がそのバックグラウンドにある。
しかし、NVIDIAの思惑はこのところレポートしていなかった。今回は、NVIDIAのビジョンを中心に説明しよう。
 |
| NVIDIAのDavid B. Kir氏 |
NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、同社のGPUのDirectX 10サポートについて、まず次のように釘を刺す。
「当社のDirectX 10対応GPUはUnified-Shaderかもしれないし、そうでないかもしれない。みな、私が『いや、そっち(Unified-Shader)へは行かない』と言ったと思っている。しかし、私が言ったのは、(我々のGPUが)登場するまでは、知ることはできないと言っただけだ」
このように、Kirk氏は、同社のDirectX 10サポートがUnified-Shaderにならないとは明言していない。しかし、Kirk氏は、続けて、GPUの各ユニットの統合化には時間とコストがかかることを強調する。その口ぶりからは、どう考えてもUnified-Shaderにすぐに移行するとは思えない。
「Unified-Shaderハードウェアはいつ頃が適切なのか、それが問題だ。私も、将来は、GPUがよりシンプルな設計となり、より少ない種類のプロセッサになるだろうと思う。Vertex Shader、Pixel Shader、ROP(Rasterizing OPeration)、フロントエンドプロセッサやテッセレータ(Tessellator)といった異なるハードウェアピースが、いつかは、1つで全てができるピースへと変わるだろう。しかし、それには時間がかかり、一度にはできない。変化は漸進的に起こるだろう」
つまり、Unified-Shaderへの革新は、一気に進むわけではないとNVIDIAは見ているわけだ。ちなみに、ここでKirk氏はDirectX 10のさらに先、ピクセル処理をするROPのプログラマブル化や、平面分割を行なうテッセレータの実装などにも触れている。そこまでの地平を含めて、対応には時間がかかり漸進的になるだろうと言っているわけだ。
●急進的な進化の危険を指摘するNVIDIA
Kirk氏は、簡単に行かない理由として、Unified-Shader化にはハードウェアコストがかかり、GPUの効率を落としてしまう点を指摘する。
「(Unified-Shaderにすると)コストが大きい。例えば、G71(の発展系のアーキテクチャ)で“Unified”プログラミングモデルをサポートできるだろうが、(その場合も)実行はUnifiedではない。G71のパフォーマンス/平方mm(ダイサイズ)は非常に高い。それに対して、(Unified-Shaderである)Xbox 360 GPU(Xenos)のパフォーマンス/平方mmは、より少ない。だったら、どちらがいいか? 」
つまり、同じプロセス世代のGPUで比較すると、Independent-Shader型のG71は、Unified-Shader型のXbox 360 GPUより効率が高いとKirk氏は指摘している。だから、Independent-ShaderでDirectX 10をサポートしても、効率は高いだろうと言っているわけだ。同じ規模で、同じAPIをサポートするGPUを作ったとしても、Independent-Shader型の方が、Unified-Shader型よりもパフォーマンスが高くなる可能性が高いというのが主張だ。
Unified-Shader型実装が、コストが高いことは、同アーキテクチャを取るGPUベンダーも認めている。例えば、ATIのRick Bergman(リック・バーグマン)氏(Senior Vice President, PC Business Unit, ATI Technologies)は「DirectX 10をサポートするには、30~40%程度のロジック(回路)が余計に必要となるだろう」と語っていた。
ATIのUnified-Shaderはオーバーヘッドがあるわけだ。それに対して、Kirk氏は、Independent-Shader型の方がオーバーヘッドが少ないことを示唆している。実際、Unified-Shaderへ向けてさまざまな要素を実装しつつあるATI GPUは、ダイサイズが肥大化しつつある。これは、ATIにとって重荷になっているはずだ。
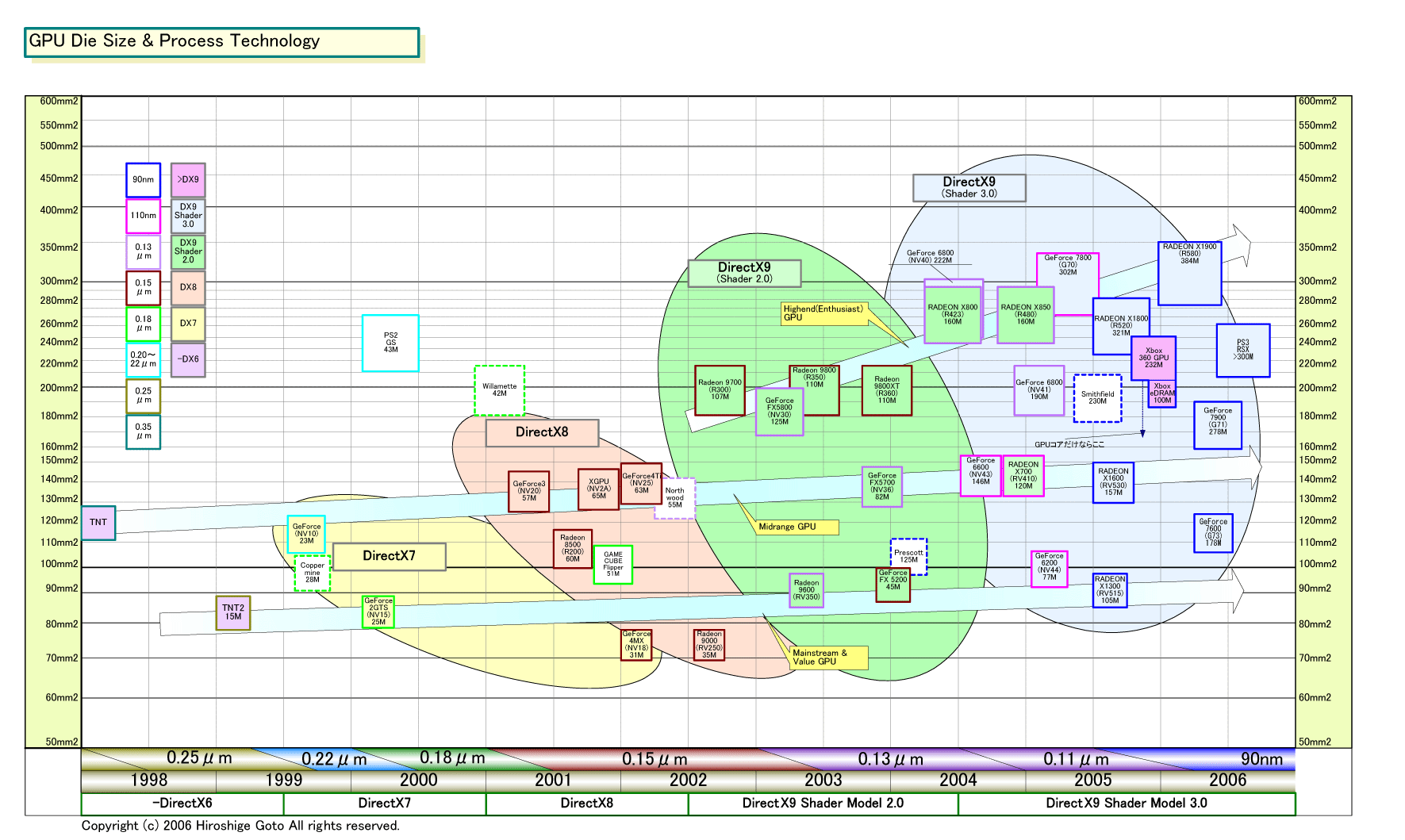 |
| GPUダイサイズ図 PDF版はこちら |
要約すると、NVIDIAはGPUの急激な進化が決していいばかりではないと指摘している。これは、NVIDIAの過去2年間の定まったスタンスで、NVIDIAの方向性はぶれていない。例えば、2005年8月に行なわれたカンファレンス「Graphics Hardware 2005」のNVIDIAのプレゼンテーションには、この方向性を象徴する、少し笑える1枚のスライドがある。
 |
| 「Graphics Hardware 2005」でのスライド |
過度の急激な進化は、まずい結果をもたらすことがあると、NVIDIAは言っているわけだ。
●フレキシブル過ぎる? Unified-Shaderアーキテクチャ
Kirk氏は、現状ではUnified-Shader化によるフレキシビリティが不要であると語る。
「確かに、Unified-Shaderはフレキシブルだが、必要以上にフレキシブルだ。200インチ(約5m)の長さのベルトのようなものだ。200インチもあればあなたがどんなに太っていても合うが、太っていなければ意味がない。
Unified-Shaderがいいといわれる理由の1つは、よりよいロードバランスが可能になる点だ。ピクセルプロセッシングが必要な時はShaderをそちらに割り当て、頂点プロセッシングが必要な時はそちらへ割り当てることができるからだ。しかし、結局のところ、ほとんどの場合必要なのはピクセルプロセッシングだ。例えば、1億ピクセルをレンダリングすることはあっても、1億ポリゴンをレンダリングしない。もちろん、セットアップユニットが1億ポリゴンを描画できたとしても」
Unified-Shaderでは、実装にもよるが、ShaderリソースのどれだけをどのShaderに割り当てるかを動的に変更できる。そのため、各ステージのShader数が固定されているIndependent-Shaderよりも自由度が高い。だが、Kirk氏は、ニーズのほとんどはピクセルプロセッシングの増強にあるため、そうした自由度の意味は薄いと指摘している。
ただし、これは異論が多い部分で、そうでないと考えるグラフィックス関係者も多い。一例を挙げると、GPU上でのアニメーションやジオメトリの変成をガンガンやろうとすると、Vertex/Geometry Shaderの方のリソースがより欲しくなる。NVIDIAの主張は、これまでのアプリケーションのトレンドを考えた場合という条件つきでの話だ。おそらく、NVIDIAはそうした方向へとソフトウェア側が向かう時には、Unified-Shader型あるいはUnified-Shaderライクなアーキテクチャへと転換するつもりなのだろう。
また、Kirk氏は、Unified-Shader型の実装のコストが大きくなる理由をいくつも挙げている。
「D3D 10の論理ダイアグラム上では、Vertex Shader、Geometry Shader、Pixel Shaderが並んでいる。これらを同じボックスに納めるとどうなるか。それぞれのShaderは異なったパーツだ。それを統合したら、無駄が生じてしまう。
また、メモリとの接続も全てそのボックスに集中するため、より多くのI/O(の配線)が必要になる。レジスタとコンスタントも1つのボックスに納めることになる。ロードバランシングしている時でも、全ての頂点ステイトとピクセルステイトとジオメトリステイトを一緒に、保持しなければならないからだ。より大きなレジスタアレイには、より多くのポートが必要になる」
それぞれのShaderは異なるデータを処理するため、現在は、それぞれの処理に最適なアーキテクチャを取っている。例えば、演算ユニットの構成は、Vertex ShaderとPixel Shaderの間で大きく異なっている。そのため、統合すると、どちらにも適した内部アーキテクチャにしなければならなくなるため、冗長な部分を含むようになり、実装が重くなる。
GPU設計上のもう1つのチャレンジは配線だ。GPUはCPUと比べてより広くて高速な内部バスを多数持つ。そのため、配線が複雑で設計上のボトルネックになりやすい。Kirk氏が指摘しているのは、Unified-Shader化によって、その複雑度がさらに増して、設計が難しくなるという点だ。
●パイプライン化を進めてきたGPUの進化の歴史
Kirk氏は、Unified-Shader化が、パイプライン処理によって効率を上げてきたGPUやCPUの軌跡にも反することを指摘する。
「コンピュテーションの流れを見てみよう。20年前のシンプルなCPUは1個のファンクションユニットしか持っていなかった。つまり、Unified-Shaderだった(笑)。しかし、今はIntelも、そんなCPUは設計していない。
複雑な処理は、常に、多くの処理を並列化できる可能性を与えてくれる。そこで、我々は、パイプラインアプローチで、異なるピースを同時にビジーにさせることで、GPUを進化させてきた。(パイプラインを)20の処理に分ければ、各ピースが平行に処理することで20の処理をできる。ところが、全てをUnifiedにすると、20の処理を、20のプロセッサ(Shader)で行なわなければならない。
私は、Unified-Shaderがいいアイデアではないと言っているわけではない。しかし、(1つのShaderで)全てをできるようにすることは、考えているよりずっと難しい。だから、漸進的に進むだろうと考えている」
IntelなどのCPUも、内部のユニットはパイプライン化され用途別の演算ユニットを複数並べる構成となっている。486までのCPUのように、全ての処理ができる演算ユニットを持っているわけではない。Independent-Shaderは、言ってみれば現在のCPUに近い考え方だと言っているわけだ。全てをカバーできるフル機能のShaderを搭載しようとすると、どうしてもコストがかさむことになる。
そのため、Kirk氏は他社もUnified-Shaderと言いながらも、完全には統合されない可能性があると言う。
「彼らが、ユニファイド(Unified)パイプラインだと言っても、それはハイブリッドなものであって、完全にユニファイドではないと考えている。部分的には統合されていても、あるパートは共有するような、不完全なUnified-Shaderの可能性がある。
私はそれを証明できると言っているわけではない。ただ、その方が、彼らにとって正しい選択だろう。彼らは、賢いから、Unified-Shaderで無駄が生じさせてしまうことはないだろうと考えている」
つまり、完全に均質なUnified-Shaderを実装しようとすると実装コストが高くなる。だが、Unified-Shaderを取るベンダーも、賢いから、Unified-Shaderであっても完全な統合ではなく、一部を削るだろうという予想を立てているわけだ。Kirk氏の予想が当たるなら、Unified-Shaderも、完全とは遠いことになる。そうなると、真のUnified-Shaderとは何かという話にもなってくる。
●ハードウェアとソフトウェアの両輪の進化
汎用化を進めるGPUの最大のチャレンジは、汎用性と特殊性のバランスを取ることだ。ハードウェア実装している特定目的の機能を1つ削る度に、その機能をShaderでのソフトウェア実装にする必要がある。そうすると、ハードウェア実装ほどの高速性は望めなくなってしまう。汎用化を急いだ結果、グラフィックス処理が低速になってしまうと本末転倒になってしまう。
「我々は、特定目的の機能をGPUから取り去りたいと望んでいる。しかし、その一方で、(グラフィクスの特殊機能を)非常に速く走らせることも望んでいる。もし、GPUから全ての特定目的向けの実装を削ってしまったら、それは、単なるPentiumだ」(Kirk氏)
そのバランスを決めるのは、ソフトウェアの進化だ。グラフィックス処理も、ソフトウェア側のトレンドとして柔軟で汎用性のあるハードウェアを必要とするように変わりつつある、と信じられている。だとしたら、ソフトウェアの進化とともに、汎用化したハードウェアの方が性能を出しやすくなって行くはずだ。
グラフィックスが、ソフトウェアとハードウェアの両輪のバランスを取って進化するなら、見かけ上は性能のペナルティがなく革新ができることになる。問題はそのバランスで、その解釈が異なるから、GPUベンダーの実装が大きく異なってくる。GPUベンダー間ですら、予想がつきにくい状況にあるわけだ。
□関連記事
【4月18日】【海外】DirectX 10サポートで2派に分かれるGPUベンダー
http://pc.watch.impress.co.jp/docs/2006/0418/kaigai261.htm
【2月28日】【海外】2006年後半にサンプル出荷が始まるDirectX 10世代GPU
http://pc.watch.impress.co.jp/docs/2006/0228/kaigai245.htm
【2005年4月26日】【海外】WGF2.0時代の次世代GPUのアーキテクチャはこうなる
http://pc.watch.impress.co.jp/docs/2005/0426/kaigai174.htm
(2006年4月19日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.