 |


■後藤弘茂のWeekly海外ニュース■コプロセッサへの分散が進むAMDの次世代CPU |
●AMDのCPU開発と密接に絡むコプロセッサ戦略
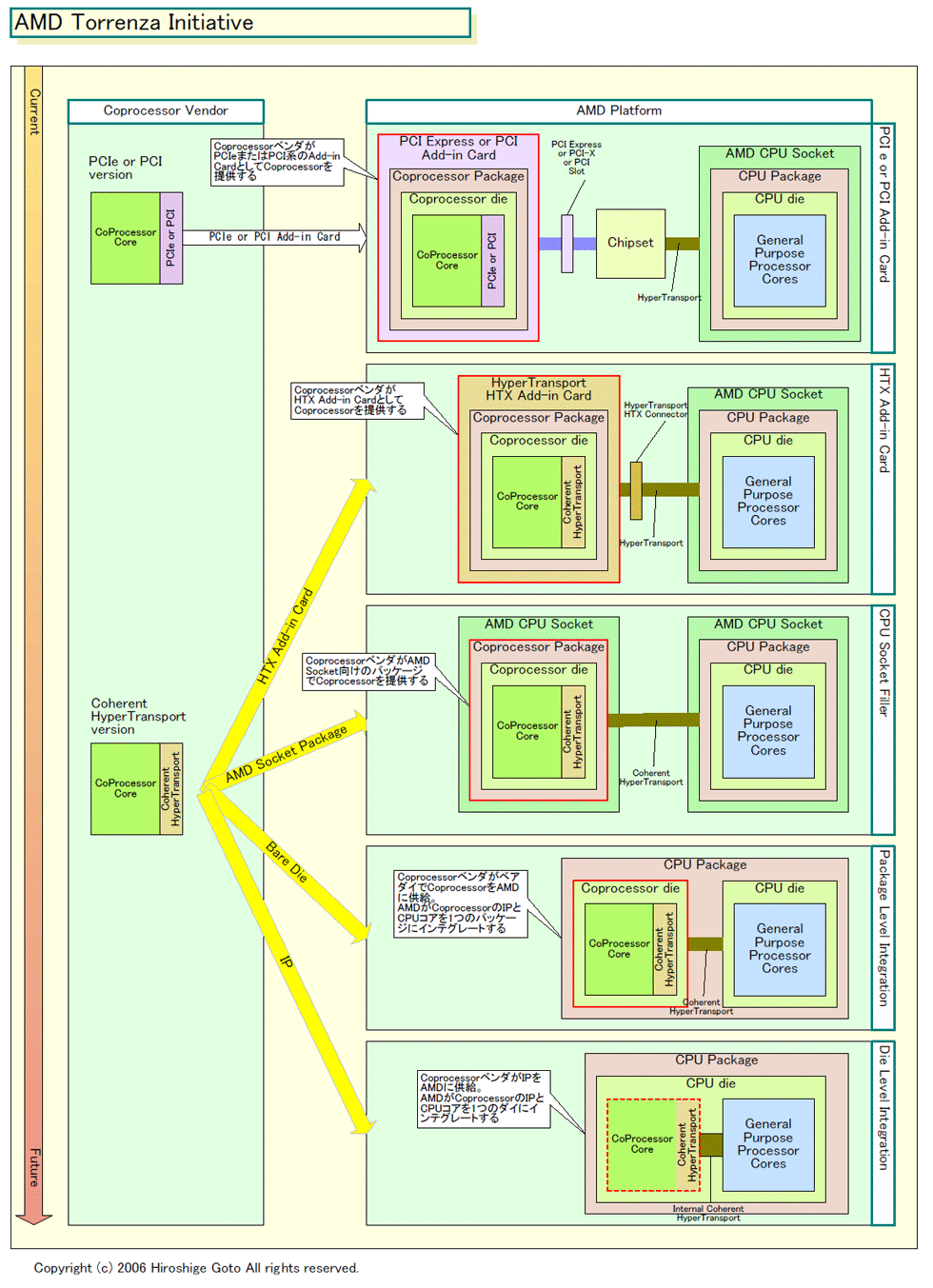
汎用CPUを補佐する、特定アプリケーション向けのアクセラレータである「コプロセッサ」に注力し始めたAMD。AMDは、コプロセッサのオープン化を進め、「Coherent HyperTransport」によるタイトな統合を実現しようとしている。AMDの思惑通りに進めば、AMDプラットフォーム上でコプロセッサのエコシステムが回り始めることになる。コプロセッサベンダーは、Coherent HyperTransportインターフェイスを自社のコプロセッサコアに実装、HTXアドオンカードやソケットフィラーのコプロセッサを出して行くというシナリオだ。
しかし、AMDのコプロセッサ戦略の真の狙いは、そうしたシステムレベルのコプロセッサの統合にはない。最終的には、CPUパッケージまたはCPUのダイ(半導体本体)そのものにコプロセッサを統合することがゴールだ。これは、複数の汎用プロセッサコアと、複数の特定用途向けコプロセッサコアを統合した、一種の「ヘテロジニアスマルチコア(異種混合マルチコア)」のCPUを作ることを意味する。つまり、コプロセッサ戦略は、AMDがCPUそのもののアーキテクチャをどうするのか、という基本部分に深く関わっている。
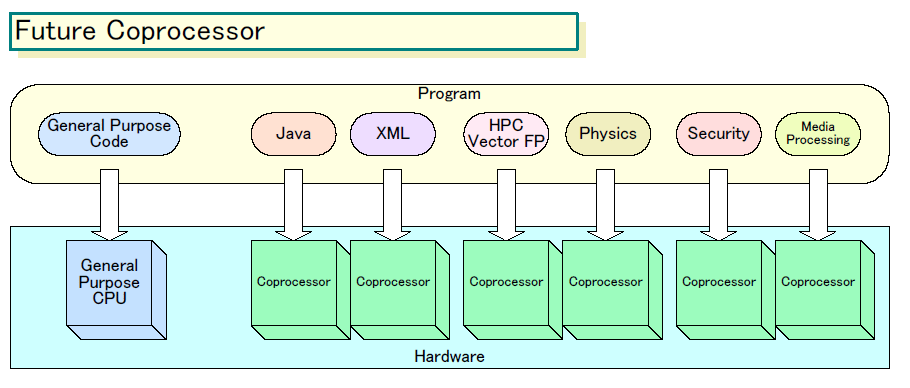
将来的なAMDのCPUは、下のように、複数の大型のAMD設計の汎用プロセッサコアと、それを取り巻くコプロセッサコア群で構成されるようになると推定される。汎用コードはメインのプロセッサコアで実行し、アクセラレートするコードはコプロセッサに渡すという構図だ。コプロセッサのISA(命令セットアーキテクチャ)はメインのx86/x64プロセッサコアとは異なるが、それはライブラリレベルでカバーする。
 |
| AMD Torrenza Initiative (※別ウィンドウで開きます) PDF版はこちら |
汎用プロセッサコアと、特化したコプロセッサコアという構成は、「Cell」に似ている。また、Intelの「Many-core」も、大型の汎用プロセッサコアと、サブのコア群という構成との類似する。基本的な構想はいずれも同種だが、もちろんかなりの違いがある。
●各社で異なるサブプロセッサの統合の仕方
Cellでは、汎用プロセッサコアである「PPE(Power Processor Element)」は、単にCPU全体を制御しOSコードなどを走らせるだけの、比較的非力なコアに留めている。データ演算は、コプロセッサコアである「SPE(Synergistic Processor Element)」に任せるというのが基本の発想だ。これは、レガシーのソフトウェアを持たないからこそ取れる戦略だ。
それに対して、AMDは、汎用プロセッサコア自体は、依然として強力なout-of-order型のコアを使うと推測される。少なくとも、汎用コアを弱体化させるという路線は、AMDからは聞こえてこない。これは、依然としてレガシーのソフトウェアも高速に走らせなければならないからだ。
また、今のCellのコプロセッサSPEは、ゲームやメディアプロセッシング向けの単精度浮動小数点SIMD(Single Instruction, Multiple Data)演算に特化している(将来は変わる可能性もある)。それに対して、AMDは、どちらかというとエンタープライズ寄りの、複数の異なる種類のコプロセッサを、CPUに統合する可能性が高い。これは、アクセラレートするアプリケーションの違いである。
一方、Intelは、ISAの考え方がAMDとは異なる。Intelは、Many-coreではプロセッサコアの実装自体はヘテロジニアスになるが、ISAはあくまでもホモジニアスだと説明していた。IntelがISAの一貫性にこだわるのは、多くのCPUコアを使って、投機マルチスレッディングを実現することを考えているからだ。しかし、AMDからは、そうした構想は聞こえてこない。また、IntelはAMDよりも、もっと汎用性の高いサブプロセッサコアを想定していると説明していた。
こうした構成やアーキテクチャ上の大きな違いとともに、コプロセッサコアのビジネスモデルもAMDは異なる。Cellは独自のコアを統合しているし、IntelのMany-coreも自社で開発したコアを統合すると見られる。それに対して、AMDはCPUに統合するコプロセッサですら、全て自社で開発しようとは思っていない。自社で開発したコプロセッサコアだけでなく、サードパーティのコプロセッサも統合して行くつもりだ。つまり、自社のCPUに、他社が開発したコプロセッサコアも取り入れるレベルにまでオープンにしようと構想している。
 |
| AMD Coprocessor Integrated Core Example (※別ウィンドウで開きます) PDF版はこちら |
●他社のコプロセッサもAMD CPUに統合する
AMDの自社コプロセッサの研究については、まだ見えてこない。AMDがATI Technologiesを買収といった情報が飛ぶのも、AMDのコプロセッサ戦略が背景があるからだ。ベクタプロセッシングに特化したGPUベンダーは、いいコプロセッサ供給源になる可能性がある。現状では、AMDにとって、限られた開発リソースはコプロセッサ開発の制約だ。
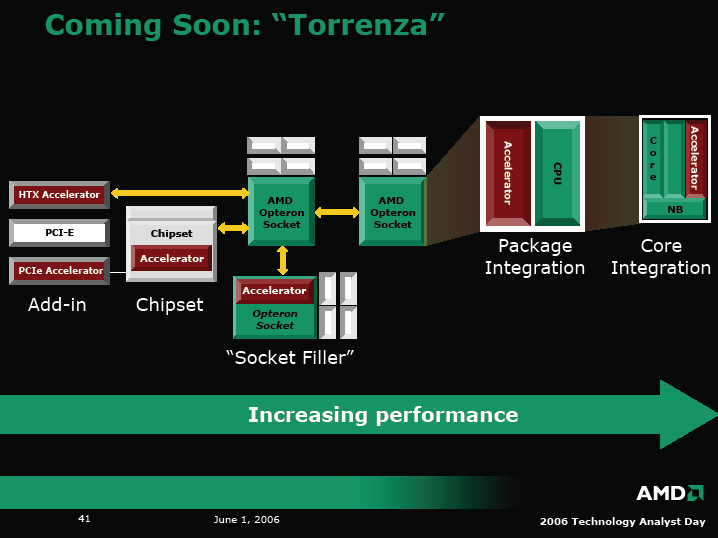
そのため、AMDはTorrenzaというレールを敷くことで、コプロセッサベンダーを集約しようとしている。まず、システムレベルで統合するコプロセッサを開発してもらい、それを、さらにAMDのCPUパッケージやCPUダイに取り込もうという戦略だ。
パッケージレベルの統合では、AMDはサードパーティからコプロセッサをベアダイで購入、CPUダイとコプロセッサのダイを、マルチチップモジュール技術を使い1個のCPUパッケージに統合する。その場合、AMD以外のFab(製造工場)で製造したコプロセッサダイも統合するという。
 |
| AMDのPhil Hester(フィル・へスター)氏 |
「マルチチップモジュールで統合する場合は、ダイの製造Fabは、全く異なっていて構わない。リストに挙げた(コプロセッサの)ベンダーは、我々に対して『TSMCやUMCといった、自分たちが望むFabで(コプロセッサを)製造できることが重要だ』と語った。我々は、パートナーに我々のFabを使うように強制するつもりはない」とAMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer)は語る。
コプロセッサベンダーにとっては、コプロセッサをパッケージやボードで販売する代わりに、ベアダイをAMDに販売することになる。ダイ自体は、コプロセッサパッケージ向けに設計したものと基本的には同じものが使えるはずだ。また、ダイの製造も、依然としてコプロセッサベンダー自身がファウンドリなどで行なう。ダイをどう売るかが変わってくるだけだ。
CPUダイへの統合でも、AMDは、同じ戦略を取る。自社CPUに、サードパーティが開発したコプロセッサのIPを統合する方向を考えている。
「我々は、当社のIPであろうとパートナーのIPであろうと統合できるようにアーキテクチャを設計した。パートナーがコアを(我々に)ライセンスすることでビジネスができるようにする。我々は、その(サードパーティの)コアを統合したCPUを製造する。これは一種のシステムオンチップだ」とHester氏は語る。
AMDはコプロセッサベンダが開発したコプロセッサのIPのライセンスを購入。CPU設計段階でコプロセッサIPを統合したCPUを設計する。CPU内部で、AMDのプロセッサコアとコプロセッサコアは、Internal Coherent HyperTransportで接続するという。AMDは、次のニューコアからCPU全体をモジュラー設計にするため、他のベンダーのコアも容易に統合できるという。
コプロセッサベンダがCoherent HyperTransportインターフェイスベースで設計したコプロセッサは、それほど大がかりな設計変更をしなくても統合ができると推測される。コプロセッサベンダは、一種類の設計で、AMDのさまざまなソリューションに対応できることになる。Torrenzaは、そこまでを視野に入れた戦略ということだ。
 |
| Coming Soon,“Torrenza” (※別ウィンドウで開きます) PDF版はこちら |
●CPUに統合するコプロセッサは市場が決める
汎用プロセッサコアとコプロセッサコアを集積する将来のAMD CPU。ここでクエスチョンは、いつどんなコプロセッサをCPUに統合するかだ。Hester氏は次のように説明する。
「例としては、286(CPU)に対する287(浮動小数点演算コプロセッサ)を挙げることができる。286/287の時は、浮動小数点演算コプロセッサのためだけのソケットを設けていた。それは386/387でも続き、アプリケーションソフトウェアの数が、浮動小数点演算を統合するのに十分な水準に達した。そこで、486では浮動小数点演算コプロセッサを統合した。平均的なユーザーに対して、もっともコストエフェクティブに浮動小数点演算能力を提供する方法は、分離されたコプロセッサではなく、統合してしまうことだったからだ。
私がリストに挙げた、Java、XML、浮動小数点演算、メディアプロセッシングといったコプロセッサ。これらコプロセッサは、それぞれ異なる市場セグメントに異なる率で浸透してゆくだろうと、私は考えている。
これらのコプロセッサをCPUに統合することには、利点と不利がある。統合してしまえば、その機能を最低の追加コストで得られるようになる。しかし、不利な点もある。それは、(CPUを買うユーザー)誰もがその機能に対してコストを払わなければならない点だ。
 |
| Diversity of Workloads and Oppotunities for Specialized Processor (※別ウィンドウで開きます) PDF版はこちら |
だから、我々は何を統合するのが正しい回答かを、自分たちで決定しないことにする。それは、アプリケーションソフトウェアによって決まるだろう。
基本的な戦略は、3つか4つの条件を考慮することになる。その機能についてどれだけのパフォーマンスが必要とされているのか、どれだけのパーセンテージのアプリケーションがその機能を必要としているのか、どれだけ(コプロセッサの)実装が広がっているのか、といった条件だ。これらが、我々のビジネスを決める。おそらく、4~5年のうちには、リストの(コプロセッサの)うちから、統合するのが理にかなうものが出てくるだろう。その一方で、統合しない方がいいものもあるだろう」
4~5年先ということは、AMDはまだコプロセッサ統合の設計には入っていないことを意味している。今後のTorrenzaの展開を見て、2010年以降のCPUにコプロセッサを統合して行くと見られる。コプロセッサIPのライセンスを受ける場合には、コプロセッサベンダーとの共同作業も必要となる。
 |
| Future Coprocessor (※別ウィンドウで開きます) PDF版はこちら |
●不鮮明なAMDの汎用プロセッサコアの今後の発展
AMDは、コプロセッサコアの統合によって、汎用プロセッサでは負荷の高い処理をアクセラレートする。その結果、汎用プロセッサコアの負担は減ることになる。疑問は、AMDが汎用プロセッサコアの発展をもう諦めてコプロセッサに頼ることにしたのか、それとも汎用プロセッサコアも依然として発展させ続けるつもりなのかという点だ。もっとダイレクトに言えば、AMDは、ブランニューの汎用プロセッサコア「K10」を出すつもりがあるのか、それともK10は諦めたのか。
以前、このコラムでは、AMDが2007年の“ニューコア”で、プロセッサコアのマイクロアーキテクチャを抜本的に刷新すると推測した。しかし、実際にはそうではなかった。
ちょっとややこしいのは、AMDは、CPU内のプロセッサコアと周辺回路をひっくるめて“コア”と呼んでおり、厳密な意味でのCPU部分のコアは“プロセッサコア”といった言い方をしている。そして、2007年のニューコアである「Hound」と「Mobile Processor」のプロセッサコア部分は、K8マイクロアーキテクチャの延長にある。Houndのプロセッサコアは、大幅な拡張が加えられているものの、それでもベースとなっているのはK8だ。
AMDは元々、2~3年おきのプロセッサコアチェンジを計画していた。しかし、次世代アーキテクチャである「K9」は2004年頃までにキャンセルとなった。その次の「K10」は2002~2003年にアーキテクチャの上流設計を行なっていたのはわかっているが、その後の状況は判然としない。そもそも、K8プロセッサコアそのものがK7プロセッサコアの大幅拡張だったので、AMDは'99年のK7からプロセッサコアのベース構造を維持していることになる。ちなみに、K8は、開発途中の'99年にアーキテクトが変わり、それに伴いプロセッサコアのマイクロアーキテクチャもK7発展型の姿に変わったという経緯がある。
K7/K8を発展させ続けているAMDに対して、Intelは、今後、プロセッサコア自体を短サイクルで刷新し続ける。Core Microarchitectureで大きくプロセッサコアのマイクロアーキテクチャを刷新し、さらに、その先、2008年頃の「Nehalem(ネハーレン)」と2010年頃の「Gesher(ゲッシャ)」と、2年毎にプロセッサコアアーキテクチャの刷新を続けてゆくと発表している。かなり戦略が異なる。
●プロセッサコアの改革はパーツ単位で行なってゆく
はたして、AMDはプロセッサコア自体の抜本的な刷新はもう行なわないのだろうか。それとも、ニューコアのあと、プロセッサコア部分の根本的なコアチェンジも計画しているのだろうか。この問いに、Hester氏は次のように答える。
「“コアチェンジ”という言葉は、人によって異なることを意味する。それを注意しなければならないだろう。
(コアが)ある世代から次の世代へ移行する際に、主要なエレメントは依然として非常に良好だとしよう。主要要素については、リエンジニアリングしても、それほど大きな利益が得られないとわかったとしたら、変更する意味がない。多くのピースをリエンジニリングすれば、それだけ時間がかかってしまう。
Intelの場合は、NetBurstを捨てることになり、全く作り直しとなった。しかし、我々は、初めに立ち戻って全てを完全に設計し直す必要がない。
しかし、その一方で、構造的な変化を起こす部分も出てくる。例えば、メモリ技術が変わると、分岐予測やキャッシュ階層を変更するのが、理にかなった判断となる。
社内では、こうしたエンジニアリング議論を常に行なっている。どこまでコアを変えなければならないのか、コアのどの部分を拡張するべきなのか。
ここで疑問は、もし、(コアに対して)ある程度の部分の変更を行なったら、そのコアは“ニューコア”と呼べるのかどうか、という点になる。結局、何をもってニューコアと呼ぶかという定義の問題となるだろう」
要約すると、次のようになる。AMDは、現行のCPUマイクロアーキテクチャのベースは非常に良好なので、全く作り替える必要はないと見ている。メモリなどの変更に応じて、プロセッサコア内外の必要なブロックだけを刷新すれば済むと判断した。つまり、プロセッサコア全体を作り替えるのではなく、プロセッサコアの部分部分を改良して行く路線だ。AMDでは、そのようにプロセッサコアの一部のピースを刷新した場合も、コアチェンジだと考えていると示唆している。
●汎用プロセッサコア集約からコプロセッサ分散へと変わる戦略
Hester氏の発言からは、AMDが近い将来に汎用プロセッサコアの抜本的な刷新を行なうという様子は見えて来ない。もし、K10がニューコアのすぐ後に控えているなら、こうした発言にはならないだろう。このことは、AMDが汎用プロセッサコアの全面刷新を、当面は行なわないことを意味している可能性が高い。
AMDが長年K9/K10の開発を続けてきたことは明らかだ。その結果、AMDが汎用プロセッサコアの完全な刷新は行なわずに、コプロセッサを搭載することを選んだとすれば、その意味は大きい。背景として想像できるのは、汎用プロセッサコアを強化しても、プロセッサコアが肥大化する割に、期待ほどのパフォーマンスアップは得られないと判断したということだ。
汎用プロセッサコアの場合、「CPUの性能向上は、ダイサイズ(トランジスタ)の増加の平方根分にしかならない」というポラックの法則が働く。プロセッサコアを大きくしても、それに見合う比率ではパフォーマンスは上がって行かない。そのため、CPU全体のパフォーマンスを上げるためには、(プログラムさえ並列化できるなら)小さなプロセッサコアを多く集積した方が有利となる。それが、特定アプリケーションに特化したコプロセッサコアなら、さらに効果は大きい。つまり、コプロセッサを集積した方が、パフォーマンス効率では理論上は有利に働く。
こうした状況で、AMDは少なくとも当面は、汎用プロセッサコアの抜本的な刷新は行なわないと推測される。Houndでは、浮動小数点演算のパフォーマンスを2倍にし、アウトオブオーダ型ロード実行や分岐予測の強化などを行なった。このレベルの改革は行なって行くものの、完全にプロセッサコア全体をリエンジニアリングはしない。
しかし、AMDがプロセッサコアのマイクロアーキテクチャの改革を完全にストップしたとは思えない。汎用プロセッサコアのパフォーマンス効率を劇的にアップするアイデアが登場する可能性もあるので、R&Dはストップするわけには行かないだろう。少なくともIntelが追求し続けている以上、AMDも止められない。また、AMDは、過去1~2年でも、IBMやIntelからCPUアーキテクトを引き入れており、人材も強化している。
とはいえ、AMDのCPU開発の焦点となるポイントが、変わったのも確かだろう。汎用プロセッサコアの全般的なパフォーマンスアップだけにフォーカスしていたのが、サブのプロセッサコアを取り込むことでアプリケーションパフォーマンスをアップする方向へとシフトした。
□関連記事
【7月13日】【海外】コプロセッサの時代を開く、AMDの「Torrenza」イニシアチブ
http://pc.watch.impress.co.jp/docs/2006/0713/kaigai287.htm
【6月1日】【海外】拡大が進むAMDのコプロセッサ構想
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
【5月8日】DRC、Opteronソケットに実装するFPGAコプロセッサ
http://pc.watch.impress.co.jp/docs/2006/0508/drc.htm
(2006年7月21日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.