 |


■森山和道の「ヒトと機械の境界面」■
|
3月2日、産業技術総合研究所 臨海副都心センターにて、日本ロボット学会主催・ロボット工学セミナー「ヒューマノイド インタラクション テクノロジー」が開催された。ヒューマノイドで物理的・心理的インタラクション・対話・統合アーキテクチャなどの研究を行なっている企業・大学から4人の講師が講演を行なった。
オーガナイザーはソニー株式会社情報技術研究所の澤田務氏がロボット学会員の1人として務めた。最初の講演も澤田氏によって「人とロボットとのインタラクションを実現する行動制御アーキテクチャ」と題して、ソニーの二足歩行ロボット・QRIOの要素技術,それらを統合する行動制御アーキテクチャ、アプリケーションについて解説されたのだが、ソニーが新規開発中止を発表したあとでもあり、残念ながら取材はできなかった。
そこで本記事では、2番目に行われた株式会社本田技術研究所 和光基礎技術研究センター・坂上義秋氏による「人・ロボットインタラクションのためのプランニングアーキテクチャ」という講演から内容をレポートする。
●人や社会を活性化するロボットを
 |
| 本田技術研究所 和光基礎技術研究センター 坂上義秋氏 |
まず坂上氏は、ホンダはこれまでハードウェア的にも制約を抱えているロボットがどのように役に立てるようにするか検討してきたが、一般の人が希望する介護用途などは時期尚早と述べた。現状では支援といっても物理的なものではなく「人や社会を活性化する」という形で支援するのが現実的であるという。
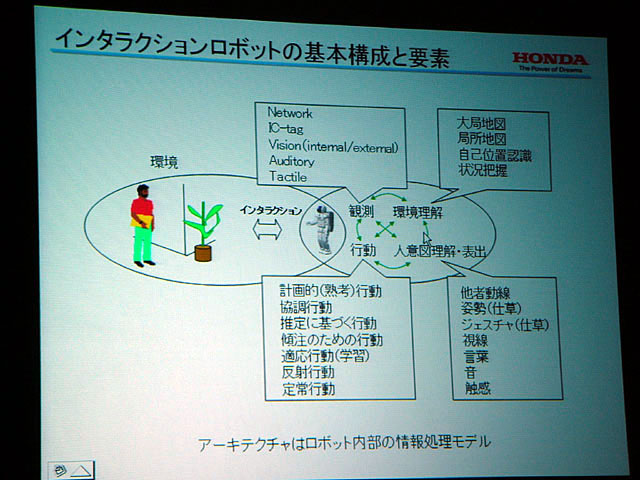
そして「インタラクションとはロボットと環境(人、空間、他のロボット、情報なども含む)が相互作用すること」とし、アーキテクチャとは「ロボット内部の情報処理モデル」であるとした。
対話は、人間とロボットとのインタラクションにおいて重要な手段である。特にヒューマノイドにおいて対話は人間側からも期待されている能力だ。アプリケーションのベクトルは2つある。1つはロボット主導型。もう1つは人間主導型である。
ロボット主導型においては、ロボットは基本的に勝手にふるまい、人間がロボットに感情移入し、引き込まれることでやりとりが成立している。
一方、「人間主導型」では、ロボットには本来の意味での会話能力が要求されるが、現時点ではロボットとのやりとりは成立せず、一般人からは「使えない」と思われている。
行動ベースのインタラクションは、特にヒューマノイドの有用性が生かされる表現形である。状況を限定すれば、ロボットがただ黙々と働き、サービスを提供するだけで、たとえ人間がロボットに従わざるを得ないだけであっても、人間は、サービスを受けて満足したり関心したりすることもある。
現在のASIMOによる案内や給仕などがこれに相当する。ASIMOに案内をされても、実際には人間はただ従うしかない。しかしながら現段階では、ASIMOに案内をしてもらうことそのものが、サービス受給者の喜びに繋がる。
インタラクションロボットは、外部の情報の観測、環境理解、人の意図の理解、行動などがバランス良くないと人間の社会のなかでうまく動くことができない。世間に衝撃を与え、現在のロボットブームの潮流を作ったホンダのヒューマノイドロボットも、P3までは人とのインタラクション機能はなかった。インタラクション機能を持ったのは、ASIMOからだ。これにより、ASIMOは、コミュニケーション、移動、そして作業をこなせる数少ないロボットの一つとなった。
ではASIMOはどんなアーキテクチャーになっているのだろうか。
 |
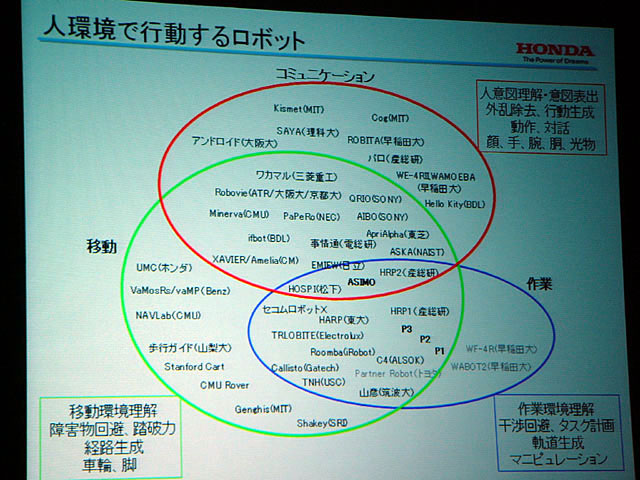 |
| インタラクションロボットの基本構成と要素 | 人環境で行動するロボットの分類と技術的要素 |
●ASIMOのアーキテクチャ
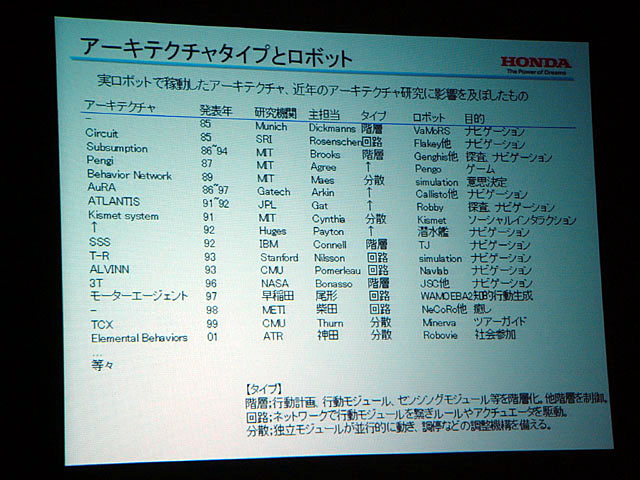
まず坂上氏は、これまでのロボットで稼動したさまざまなアーキテクチャのうち代表的なものを、階層タイプ、回路タイプ、分散タイプの3つに分けて紹介したあと、ASIMOのアーキテクチャについて概略を解説した。
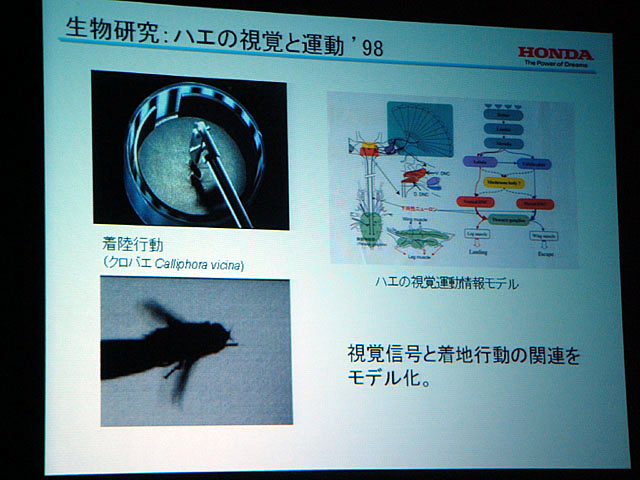
発表では、かつてホンダが「ハエの視覚と運動」の研究など、生物を参考にする研究もやっていたこと、分散エージェントアーキテクチャを搭載してセンシングされる情報が欠けた場合でも適応的に行動を変化する多足ロボットの研究、反射的行動を行なう「反射階層」と行動のプランニングを行なう「熟考階層」を持つ分散階層型アーキテクチャを搭載した移動ロボットによる実験の例などが示された。
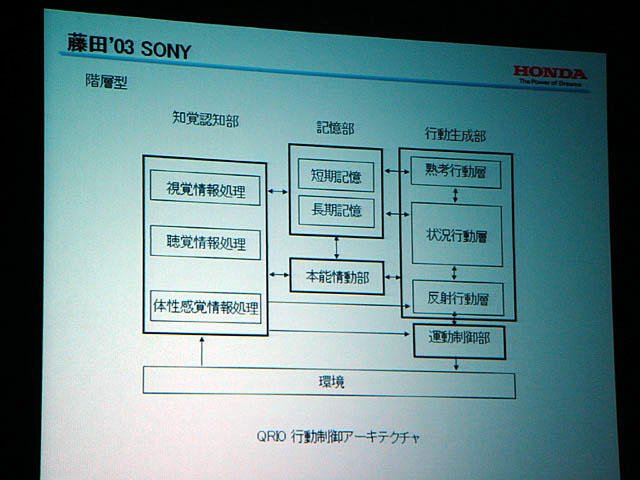
行動制御アーキテクチャは「センス-プラン-アクト型(SPA)」と呼ばれるタイプと、「行動規範型(BBA)」と呼ばれるタイプに分けられることが多い。SPAはセンシング、プランニング、アクションが直列に接続されているので、処理に時間がかかってしまうことがあり、現実世界で動かすには今ひとつ現実的ではない。一方、BBAはプランを間に挟み込まない。昆虫の足のように、ある状況に対しては必ず決まった行動を出すようになっている。ソニーがAIBOにおいて採用したことでも知られるサブサンプション・アーキテクチャ(SA)は、BBAの一種である。
両者を組み合わせたのがハイブリッド・アーキテクチャだ。最近、ソニーのインテリジェンス・ダイナミクス研究所のメンバーが著した『脳・身体性・ロボット』(シュプリンガー・フェアラーク東京)によれば、ソニーのQRIOもハイブリッド・アーキテクチャを採用している。ホンダのASIMOも基本的に同様だ。
ホンダのアーキテクチャ研究の流れは、認識主体から行動ベースへと移行しているそうだ。これはホンダだけではなく、ロボット研究全体に共通する流れである。ただし一方、最近では行動ベースに加えて認識主体の研究も見直しの流れがあるとも付け加えた。
 |
 |
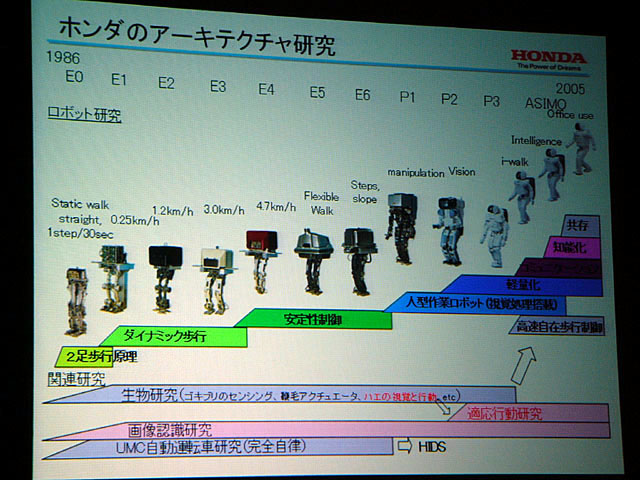 |
| さまざまなロボットのアーキテクチャ。多くのアーキテクチャが、基本的に人がいない環境で障害物回避を行ない行動することを目的としている | コミュニケーション・ロボット、ソニー「QRIO」の階層型アーキテクチャ。詳細は本文でも触れた書籍『脳・身体性・ロボット』(シュプリンガー・フェアラーク東京)に掲載されている | ホンダのアーキテクチャ研究の歴史 |
 |
 |
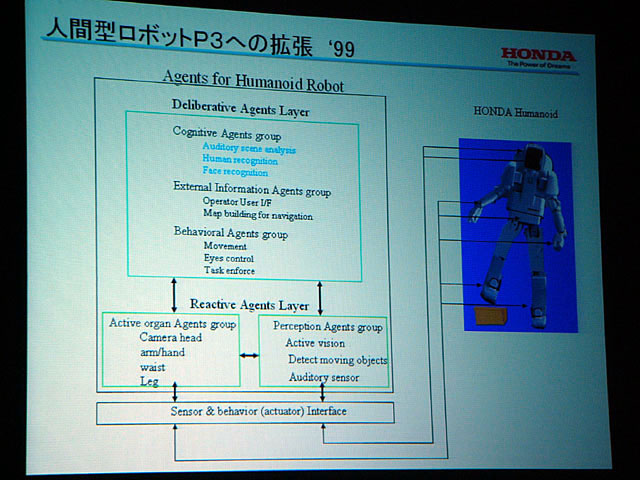 |
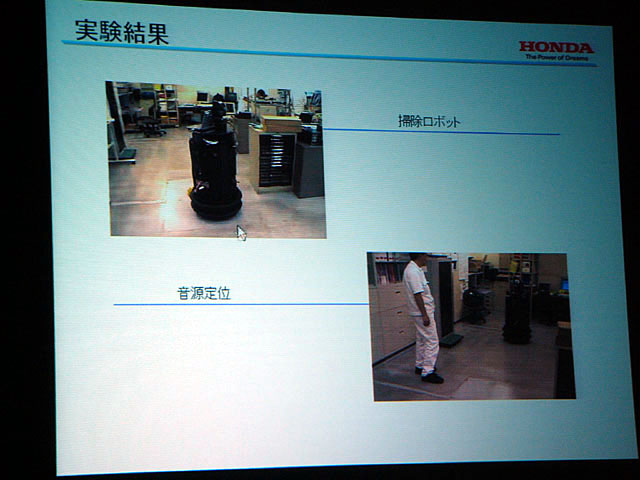
| ハエの視覚信号と足の動き(着地運動)の関連をモデル化する研究 | 研究開発用によく用いられていた移動ロボット「Nomad」を使った階層型アーキテクチャ研究の実験の様子。アプリケーションは掃除ロボットと音源定位など | ヒューマノイド「P3」のアーキテクチャ |
●接客ロボットの浸透には社会全体の意識改革も必要
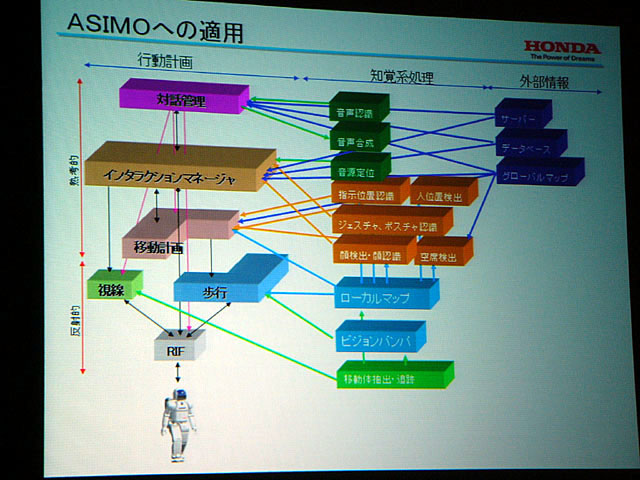
接客の基本機能を実環境で実証した現在のASIMOは、分散モジュールを階層的に構成しており、各センサモジュールは並列処理となっている。反射階層と行動のプランニングを行なう熟考階層があり、それぞれは並列で処理が行なわれていて、各モジュール間で調停を行なって行動を決定するようになっている。たとえば視線や歩行は反射的だ。
では、ASIMOが人とインタラクションするための知覚技術はどのようになっているのだろうか。ASIMOは、人社会で簡単な作業や支援をすることを目的としている。そのためには、画像処理、画像認識、音声処理、接触センサ処理、近接センサ処理などを使った環境理解、自己位置認識、人の意図の理解、人への働きかけ、意志表示などの技術が必要だ。ハードウェア、システムとも、高い信頼性がいる。
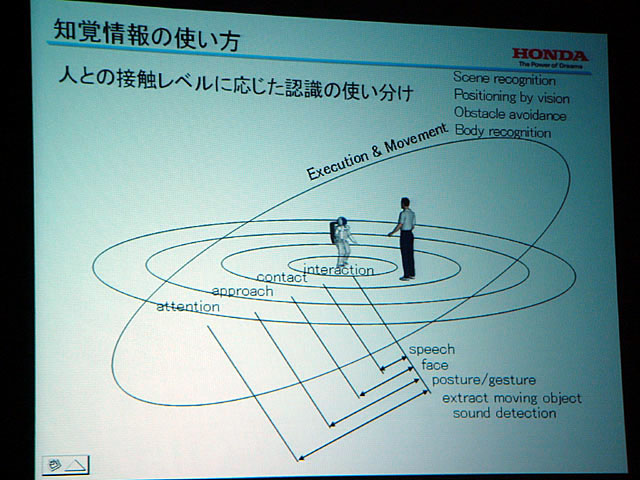
また、常に全部の認識システムを動かすのは非現実的なので、距離で使い分けているという。各モジュールの調停における優先度の重みづけも、設計者が書いたルールをベースにしつつ、それぞれの状況に応じて切り替えているようだ。そのほか、たとえば首を音源方向に向けると同時に一方でジェスチャーを続けるといったような2つのタスクを同時にこなすことも、コマンドを書けば可能になっているという。
アプリケーション紹介では、最近の接客デモの様子のほか、ソファに座っている人を見つけてニュースを配信するASIMOの様子などもビデオで紹介された。移動ロボットが人を相手にサービスを提供する場合、ASIMOのようなヒューマノイドであっても、人とロボットの間の距離の取り方が非常に難しいそうだ。
あまり近すぎると人間がひいてしまうのである。おまけに、ASIMOが話しかけ始めると、初めてASIMOに接する人の多くはどうすればいいか分からず、硬直してしまう。このあたりはより広い面でロボットサービスの設計を考える上では重要なポイントだ。技術面だけではなく、社会全体のロボットに対する意識変化を促すような啓発活動も必要なのかもしれない。
 |
 |
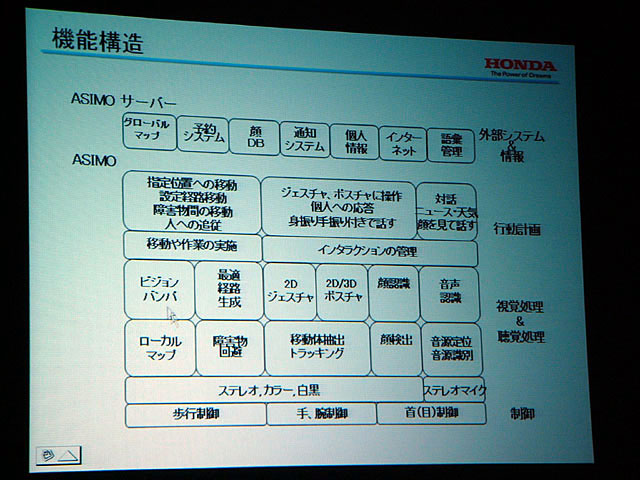 |
| ASIMOのアーキテクチャ | ASIMOは人との距離に応じて目的別にセンサを切り分けて使っている | ASIMOのサービスを支える基本構造。外部サーバーと連携しながら各モジュールが機能を発揮するように統合されている |
●実用化は10年後?
そのほか坂上氏は講演の合間に余談として、自動運転の研究が終わったあとにHiDS(Honda intelligent Driver support System。高速道路運転支援システム)という形で製品になるのに10年かかったことからロボットが製品化されるのにもまだ10年以上はかかるだろうという見解を個人的意見として述べた。
また、ヒト型ロボットのデモではときどき、手を叩いてロボットを呼ぶデモが行なわれるが、ASIMOに対しては手を叩いたりしない、ということになっているそうだ。「鯉じゃないんだから」というのが理由だという。滅多に聞けない技術的な詳細もさることながら、こういうこぼれ話が聞けるのも講演の面白いところだ。
●RNNを使った能動的知覚経験の模倣
 |
| 京都大学大学院情報学研究科助教授 尾形哲也氏 |
講演は、京都大学大学院情報学研究科助教授の 尾形哲也氏による「人間とロボットの相互適応と原始シンボルによるインタラクション」へと続いた。尾形氏は、RNN PB、すなわちパラメトリックバイアス(PB)付きのリカレントニューラルネットワーク(RNN)を使って、ロボットに能動的知覚経験をさせて模倣をさせる試みについて述べた。
尾形氏は、各種動作をRNNPBでパラメータにコード化し、そのコードを「擬似的なシンボル」として解釈し、擬似シンボルを使って人間機械協調の研究を行なっている。擬似的なシンボルを使うことで、学習時の動作以外の動作を生成可能であり、また学習時に利用されなかった擬似シンボル(パラメータ)が独自の動作を表現していることがあるという。
尾形氏は理研の谷氏と5年前から共同研究を行なっている。谷氏の基礎研究を尾形氏がロボット上に具現化する、というスタイルが多くなっているという。発表では、その具体的な効果の検討や、ロボットへの応用実験の様子が紹介された。
通常、ロボットに模倣させるときには「プリミティブ」と呼ばれる動作の基本単位で動きを分節化して表現することが第一歩だとされている。尾形氏は本来の「プリミティブ」とはパターンや軌道そのもののことではなく、パターンを生成した力学系の機構やダイナミクスのほうなのではないかという視点を提供し、そのほうが多様なパターンを予測・生成できるとした。
従来の考え方では、シンボルとは「対象や動作の静的特徴をコード化したもの」と考えられているが、尾形氏らは、シンボルとはそのようなパターンをコード化したものではなく、「そのパターンを生成した機構」につけられるラベルだと考えている。そのように捉えることで、「情報」やその「汎化」ということのより深い意味に迫れるのではと期待しているという。
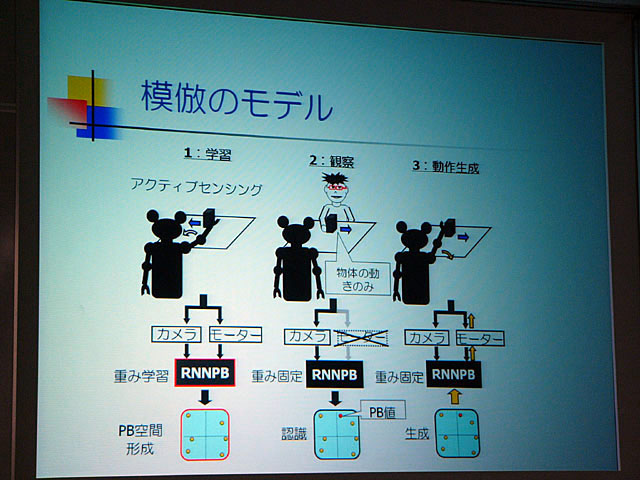
RNN PBとは、RNNにPBニューロンを加えたものだ。PBニューロンはRNNの中間層にある一定のバイアスを加える。それによって、PBニューロンはパラメータのような働きをし、その値に応じてRNN全体の出力がガラッと変わるようなシステムができる、というものだ。
面白いのは、RNN PBを学習させるときに、あるPB値に対応するモジュールでの学習結果が、他のPB値に対応するモジュールにも影響を与える、つまり相互作用する点だ。たとえば、物体を回転させる動作と平行移動させる動作をRNN PBに学習させ、それぞれに対応するパラメータを求める。するとRNN PBはこれらを“汎化”して情報を獲得し、平行移動させながら回転するといった表現を、2つの中間のパラメータ値によって生成できるようになる。そしてこのニューラルネットワークは断片的な情報からの類推、つまりある程度の予測能力を持つ。
尾形氏は実際にロボットを使った実験の様子を披露した。さらにこの仕組みを応用することによって、ロボットに擬似的なシンボルを獲得させ、これまで経験したことのない動作を生成させることもできるという。
 |
 |
 |
| RNN PB | RNN PBを使った模倣のモデル | 実際のロボットを使った実験 |
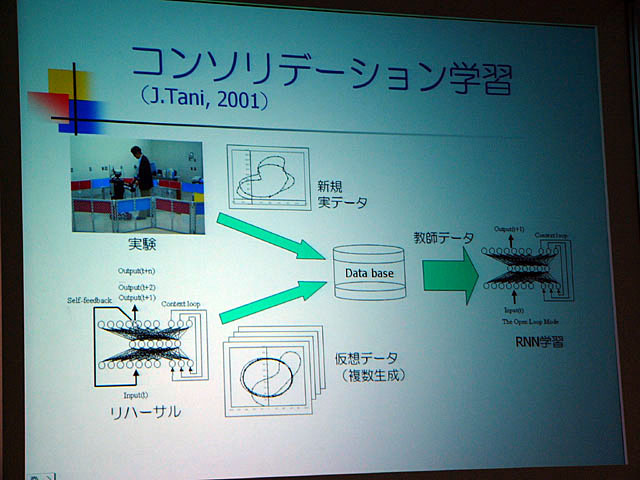
また尾形氏は、通常のニューラルネットワークによる学習では過去の記憶が壊されてしまうが、それを避けるための「コンソリデーション学習」という手法の有効性を示した。consolidationとは「統合・定着」という意味だ。これは人間が睡眠しているときの脳の活動(つまり夢)が脳の追加学習、リハーサルなのではないかという考え方をベースにしたもので、新しい学習データを追加学習するときに、ニューラルネットによる連想データ(これが「夢」に相当する)と一緒に再学習するというものだ。
この「追加修正学習」を行なうことで、人間と機械の相互作用を実現し、多様で飽きがこず、なおかつ安定した人間機械協調システムを構築することが尾形氏らの研究の目的だという。
ロボット自身が世界を理解するために疑似シンボルをいかに獲得するか、時空を超えた再現性を持ち常に同じ意味を持つ「記号」の力学系と、二度と同じことは起こらない「現実」世界の力学系をどのようにカップリングするか。人工知能の新しい潮流としても面白いテーマだ。
 |
 |
| コンソリデーション学習 | ナビゲーション課題を使った実験の様子 |
●「パラ言語」を実装して人との円滑なコミュニケーションを
最後に講演したのは早稲田大学理工学部の小林哲則教授。演題は「パラ言語の理解・生成機能によるリズムある対話コミュニケーションの実現」。小林教授は音声認識や音声合成をロボットを使って研究している。「ROBITA」や「ROBISUKE」などのロボットをメディアで見たことがある読者も多いはずだ。
話はまず「会話とはそもそもマルチモーダル」だということから始まった。つまり、単に言語として、この文章のような書き言葉にできるものだけが「会話」の要素ではない、ということだ。講演演題にもなっている「パラ言語」とは、言語に付随して出てくる言語以外の情報のことだ。
たとえば、「うーん」という言葉を例にあげて説明すると、同じ「うーん」でも「うーん……」と語尾を下げた言い方と、「う~ん?」と語尾を上げた言い方とでは全く意味が異なってくる。会話においては、このような言語外の韻律などに含まれる情報や、テンポなどが、書き起こされる言葉以外に、非常に重要になってくる。
 |
 |
| 早稲田大学理工学部 小林哲則教授 | 言語外情報の必要性 |
●相手の意図を理解しテンポのよい会話を実現
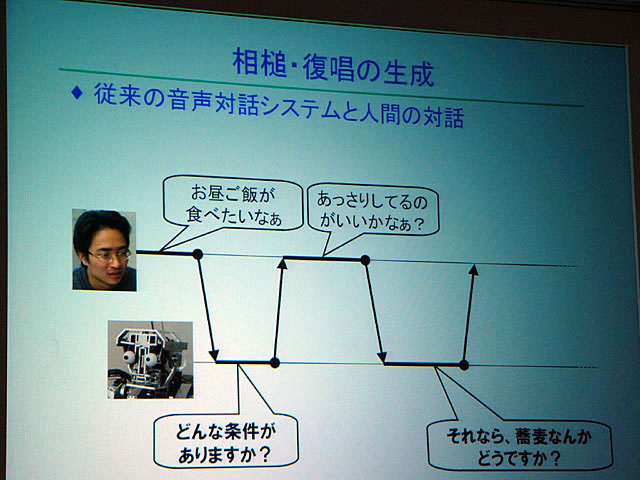
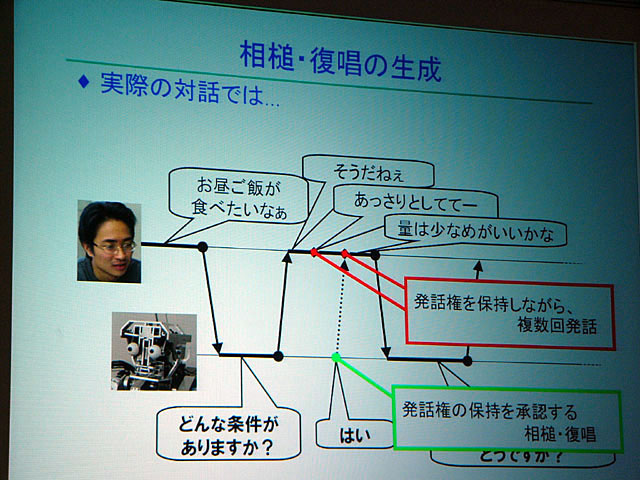
そこで小林教授らは「パラ言語」をロボットに実装して、円滑なコミュニケーションを実現しつつ、人間の意志決定支援を行なうことを試みている。講演では、たとえば昼食のメニューを選ぶときの、ロボットとのやりとりの様子などが示された。
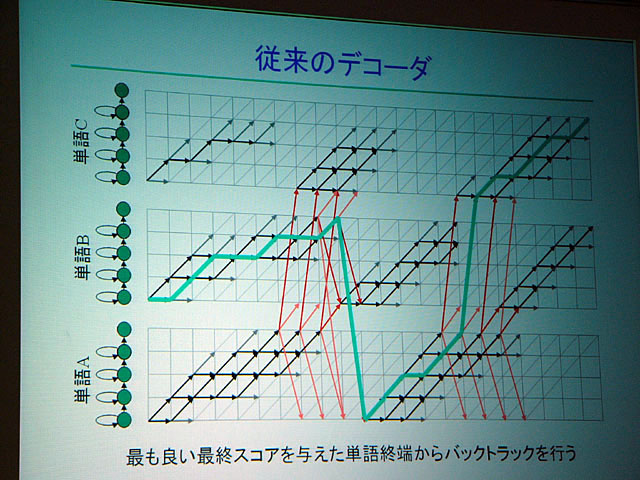
従来の音声認識では、基本的には最後まで話し手が喋り、しゃべりおわってから認識をするような仕組みになっていた。しかしながら人間は、相手の発話を最後まで聞かなくても意図が理解できるし、それに応じて相づちをうったり反論したりする。それが自然なやりとりだ。
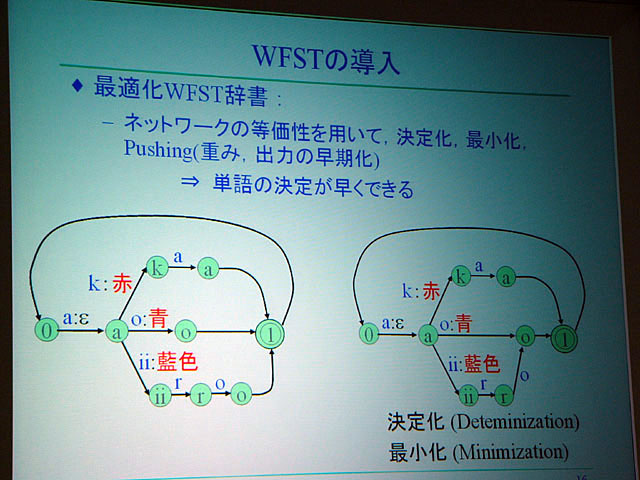
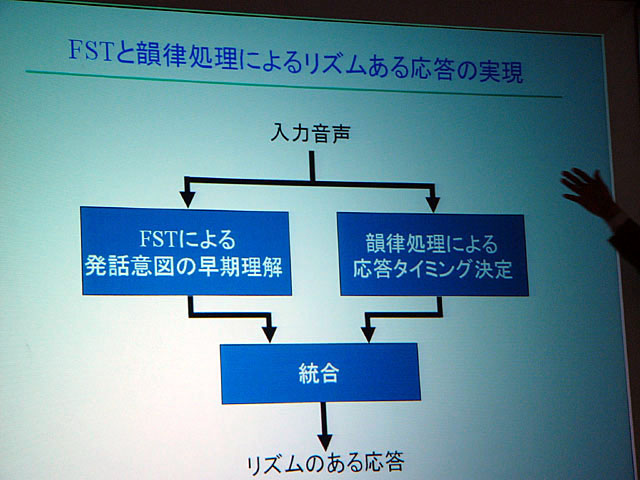
すなわち自然なやりとりを機械で実現するためには、発話システムが発話者の意図を早期に理解する必要がある。そこで小林教授らは最近の音声認識で用いられるようになってきている有限状態トランスデューサ(FST:Finite State Transducer、有限状態オートマトンに出力を付与したもの)を用いて、発話の最中に相手の意図をある程度予測し、相手の発話を早期に確定、適切なタイミングで応答できるように試みた。
また発話においても、今までの音声合成は最初から最後まで読み上げてしまうが、人間は、相手がこちらの言うことが分かったと思ったら途中で発話をやめる。それと同じような「発話計画の変更」機能を盛り込み、リズム感のある会話の実現を目指した。ロボットによる対話においてはもちろん、顔認識なども組み込まれている。
 |
 |
 |
| 従来の音声対話システムと人間のやりとり。一問一答で不自然 | 実際の対話の一例。こちらのほうが自然だ | 従来の音声認識のデコーダの仕組み |
 |
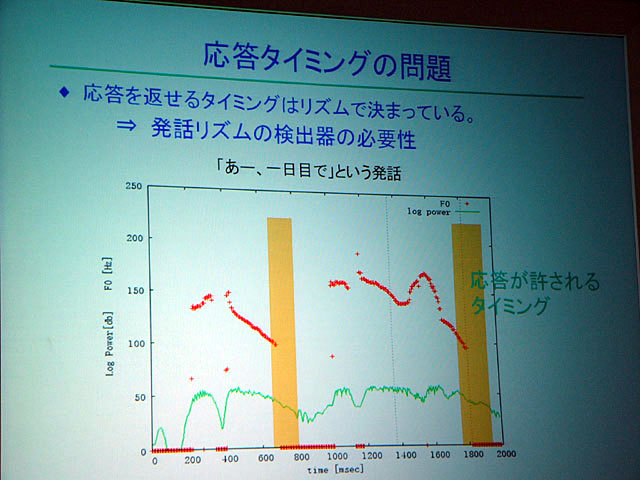 |
| WFSTの仕組み | 応答タイミングはリズムで決まっているので、それを発見する検出器も必要 |
 |
 |
| リズムある応答の実現に必要な要素 | 対話の様子 |
デモビデオを見ると現状ではまだやはり不自然なところがあるものの、これまでの音声認識・合成による対話システムよりもはるかに人間っぽいやりとりができていることが分かる。小林教授は「一問一答の対話から、ニュアンスのわかる対話へと変わりつつあると思っている。だがタイミングをとるところや相づち判定は難しい。しかしながら方向性は正しいのではないかと考えている」と語った。
もちろんこのようなコミュニケーションを可能にする背景には、音源分離と音源定位技術があることは言うまでもない。小林教授らは、マイクはロボット側に持たせた状態で、いろんなところに座った人とのコミュニケーション、すなわちグループコミュニケーションを実現している。ロボットの頭部ではごく近いところから反射が入ってくるため、従来の自由空間上での理論は使えず、別の方法論が必要だったという。
 |
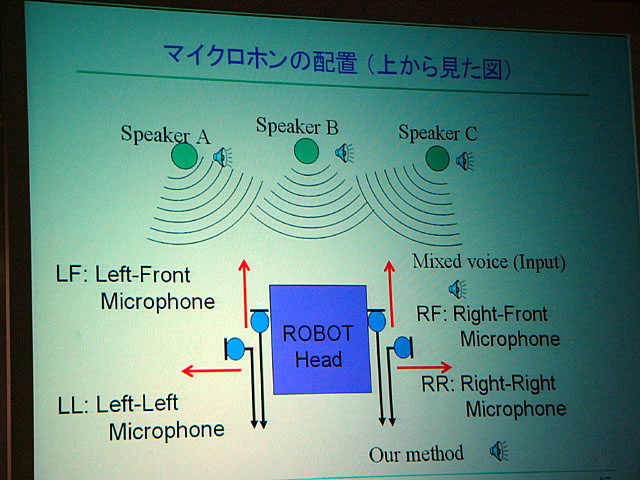 |
| ロボットを含むグループコミュニケーション | マイクロホンの位置 |
「ヒューマノイド・インタラクション技術」と言いながらも、これらの技術は実際にはヒューマノイドのみならず、幅広く、今後の機械と人間がインタラクションするために必要なテクノロジーである。
残念ながら、ロボットの研究者たちと、いわゆるインターフェイス技術の研究者間の交流はまだまだ不足しているように筆者には感じられる。両者がお互いの研究領域を知れば、より優れたシステムが開発される能性は高いと思う。今後に期待している。
□日本ロボット学会
http://www.rsj.or.jp/news.htm
(2006年3月10日)
[Reported by 森山和道]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Corporation, an Impress Group company. All rights reserved.