 |


■後藤弘茂のWeekly海外ニュース■Xbox 360から見えるUnified-Shader時代のGPUの姿 |
●Xbox 360はGPUアーキテクチャがポイント
一言で言えば、PlayStation 3はCPUがより革新的で、Xbox 360はGPUがより革新的だ。NVIDIAが開発したPS3のメディアプロセッサ「RSX」が、従来の延長線のアーキテクチャであるのに対して、ATI Technologiesが開発したXbox 360のGPUは新アーキテクチャである「Unified-Shader(ユニファイドシェーダ)」やインテリジェントeDRAMを採用している。革新的なアーキテクチャは、性能や機能を大きく伸ばす可能性を持つと同時に、リスクもある。
PS3とXbox 360のGPUアーキテクチャが分かれたことは、ATIとNVIDIAが、PC向けGPUアーキテクチャで、明確に2派に分かれたことを意味している。つまり、2005~6年のGPU戦争は、再びアーキテクチャの戦いとなる。もし、ATIが主張するようにUnified-Shader型アーキテクチャが、柔軟性と性能のどちらでも優れているなら、ATIが優位に立てる。しかし、NVIDIAが主張するように、Unified-Shader型アーキテクチャでは性能向上が難しいなら、NVIDIAが優位に立つ。
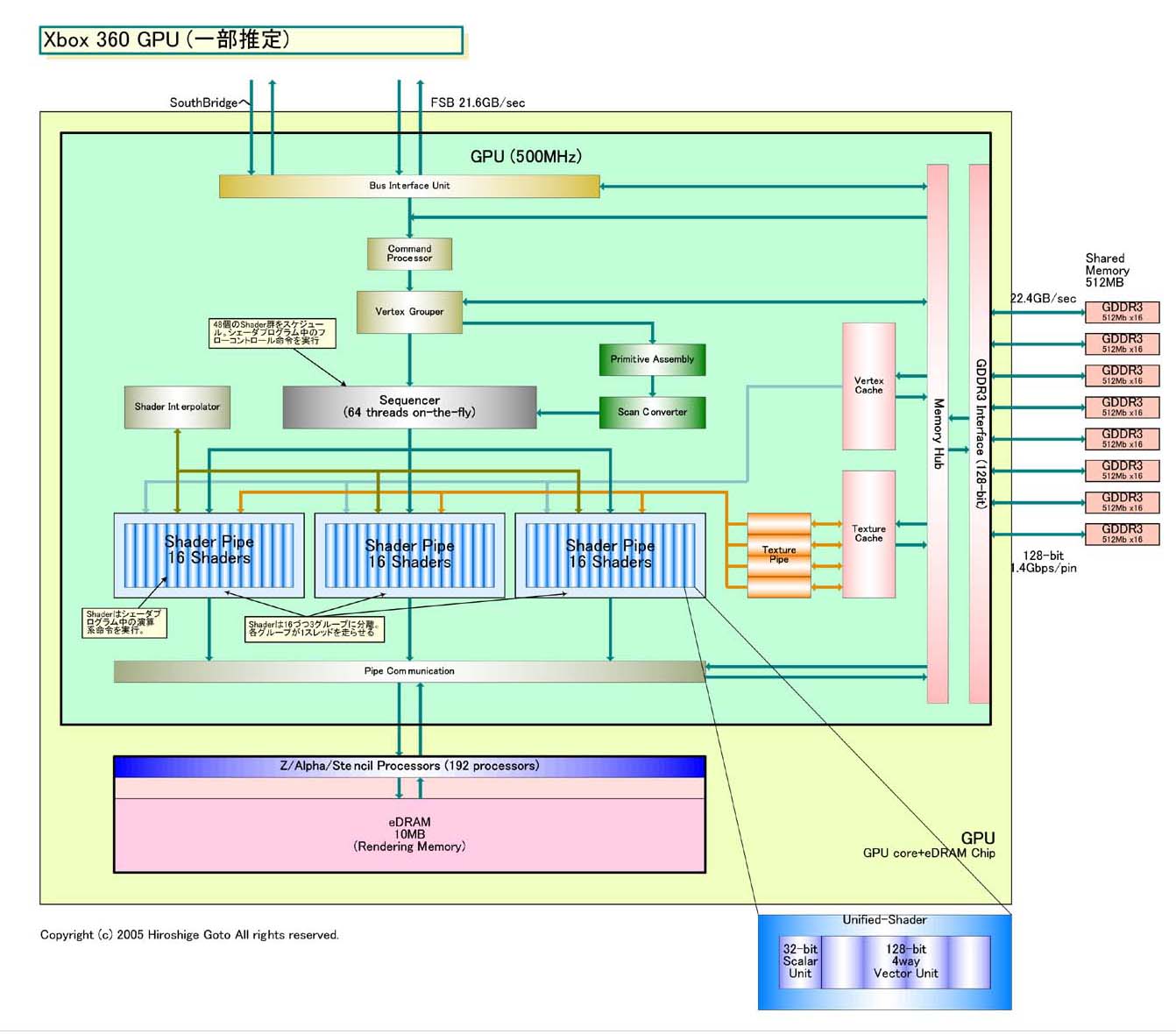
最終的に明らかになったXbox 360 GPUの姿は、かなり面白い。基本的な構成は、この連載で想定したWindows Graphics Foundation 2.0世代のUnified-Shader型GPUの通り。Shaderは、Vertex ShaderやPixel Shaderといった区分けがない、統一アーキテクチャのUnified-Shaderになり、アレイ状に並ぶ。従来は、Vertex ShaderとPixel Shaderの間にあった、ラスタライズまでを担当するPrimitive AssemblyやScan Converterが、Shaderからは分離されている。テクスチャフェッチもShader群からは独立した。
だが、こうした予想されたアーキテクチャ以外にも、ATI独特の工夫が随所にこらされている。まず、48のShaderは3ユニットにグループ化されている。これは、後述するが、Shaderのスケジューリングに深く関連する。また、Shaderのスケジューリングを司る「シーケンサ(Sequencer)」が、Xbox 360 GPUでは強力なユニットで、一部のシェーダ命令の実行も行なう。そして、Xbox 360 GPUでは、ポストシェーダのピクセル処理は、GPUパッケージの中に搭載されたeDRAMチップに混載したロジックで行なう。Xbox 360 GPUは、GPUコアのダイ(半導体本体)と、eDRAMのダイの、デュアルダイ構成となっている。
 |
| Xbox 360 GPU(一部推定) PDF版はこちら |
●48個のShaderを16個ずつ3ユニットに分割
Xbox 360 GPUでは、48プロセッサのShaderを、3グループにまとめて管理している。「我々は、(Shader)プロセッサを、16プロセッサずつで構成される3ユニットに分解した」とATIでXbox 360 GPU開発を担当したRobert Feldstein氏(ATI Technologies, Vice President - Engineering)は説明する。Shaderに対する様々な制御を、この16プロセッサのユニット単位で行なうと推定される。
Unified-Shader型アーキテクチャでは、Shaderにさまざまなタスクを自由に振り分けられる。Vertex ShaderとPixel Shaderに固定された実装とは異なり、処理に応じて動的にShaderのロードバランスを取ることができる。もっとも、実際にはどれかの処理に占有されるケースが多いという。
「アプリケーションを分析すると、多くの頂点処理と多くのピクセル処理が同時に行なわれることが決してないことがわかる。そのため、自然に、どちらかの処理に占有されるようになる」とATIのAndrew B. Thompson氏(Director, Advanced Technology Marketing, ATI Research)は説明する。
つまり、実際のアプリケーションでは、時間軸によっては頂点処理に偏ったり、ピクセル処理に偏ったりする。そのため、動的にShaderに、頂点やピクセルのタスクを割り振ることができるUnified-Shaderが、効率よくShaderを動作させることができるというわけだ。
すでに以前の記事で説明した通り、各Shaderはそれぞれ、1基の4way ベクタFPUと1基のスカラFPUを備え、両ユニットに対して同時に命令発行ができる。これはATIが以前から採用しているShaderアーキテクチャだ。
ちなみに、前のレポートでは、Microsoftからの情報をもとに、ベクタFPUが1サイクルで積和算の2オペレーション、スカラFPUが1サイクルで加算の1オペレーションで、1 Shaderで1サイクル当たり最大9の浮動小数点演算オペレーションで、Shader演算性能は最大216GFLOPSと性能について書いた。しかし、Microsoftが後に出した資料では、最大で5wayベクタで1サイクル2オペレーション、Shader演算性能は最大240GFLOPSと修正されている。
Unified-Shaderの強みは、Shaderがより汎用化されたことで、プログラマブルな処理がさらに柔軟にできるようになることだ。ATIは、それを具体的なモデリングエンジン(Modeling Engine)としてXbox 360 GPUに実装する。モデリングエンジンは、実際にはUnified-Shader上で実現され、APIの形で開発者には提供される。ATIは、ハイヤーオーダーサーフィスイズ(Higher Order Surfaces)やトーンマッピング(Tone Mapping)、グローバルイルミネーション(Global Illumination)といった機能を提供する。全般的に言えば、Shaderの柔軟性が増したことで、よりプログラム性が必要な処理もGPU側でできるようになった。
Xbox 360 GPUのテクスチャパイプはShader群からは分離されている。これは、テクスチャフェッチが長レイテンシの処理だからだと言う。テクスチャフェッチはCPUのデータロードと同じで、メモリアクセスが入るためレイテンシが非常に長い。テクスチャフェッチでShaderが待たされる場合には、Shaderの方はスレッドを切り替えて別なタスクを実行する。そのために、テクスチャのフェッチパイプは分離した方が合理的というわけだ。
Xbox 360のテクスチャパイプは、Microsoftの資料では16 textures/cycleのフェッチ能力となっている(ATIは4 textures/cycleと説明していた)。ただし、レイテンシが非常に長いため、問題は1サイクル当たりのスループットよりむしろ、どれだけのフェッチをオンザフライで制御できるかになると推定される。また、「テクスチャマニピュレートのための命令セットはShader側で備えており、分離していない」(Feldstein氏)という。つまり、レイテンシの長い処理パイプだけを分離したことになる。
●Cellによく似たプロセッサ構成
非常に面白いのは、ATIのシーケンサ(Sequencer)だ。これは、当初想定していたようなスケジューリングだけを行なうユニットではなく、ジャンプ命令などの命令フローを制御する系統の命令も実行できるプロセッサとなっている。「フローコントロール命令はシーケンサで、コンピュテーショナル命令はShaderで実行する」とFeldstein氏は役割分担を説明する。Microsoftの資料では、1サイクルに32のコントロールフローオペレーションが可能となっている(これは2ユニット=32 Shaderに対するフロー制御が可能という意味かもしれない)。
中央の1個のプロセッサがコントロールを担当し、多数のサブプロセッサがデータ処理を担当、コントロールプロセッサがサブプロセッサをスケジューリングする。これはどこかで似たようなスタイルを見たことがある…、そう、Cellプロセッサだ。このスタイルは、Cellと思想的には共通する部分がある。もちろん、細かく見ると両者には違いが色々あるが、同じ技術トレンドと言っていいかもしれない。
シーケンサにフロー制御命令を持たせた理由については、まだ取材が足りていない。CPUが走らせる汎用アプリケーションの場合、フロー制御命令は非常に頻繁に登場する。それに対して、グラフィックス向けのシェーダ(プログラム)の場合は、フロー制御はそれほど頻繁ではないように見える。そのため、フロー制御はシーケンサに分離して、Shaderは単純に演算処理だけをやらせた方が効率的と考えたのかもしれない。また、Shaderのスケジューリングは、命令フローの制御にも関わるため、スケジューラにフロー命令制御を行なわせるのは合理的でもある。
●強力なシーケンサの機能
Xbox 360のシーケンサでは条件分岐命令も実行する。条件分岐があると、分岐した場合に、後続の命令の読み込みをやり直さなければならなくなる。分岐すると、パイプラインの処理がストール(停止)してしまうわけだ。そのため、CPUでは90%以上の精度の分岐予測機能を搭載し、ストールを最小限に抑えている。
それに対して、ATIのシーケンサはCPUのような分岐予測は行なわない。Feldstein氏によると、その代わり、コンパイラによって、分岐ミスを事実上ゼロにすることもできるという。分岐の両方のパスを実行し、条件が成立した段階で、フラグが真になった方のパスの演算結果だけをレジスタに書き込む。これは、CPUでは「プレディケーション(Predication)」と呼ばれる手法で、IA-64アーキテクチャCPUなどに実装されている。Xbox 360 GPUでは、MicrosoftとATIが開発したコンパイラでこの機能を実現する(プロセッサの命令セットの対応も必要)。
プレディケーションは、2つのパスを並列に実行するため、2倍の実行リソースが必要となる。Xbox 360でのプレディケーションが現実的なのは、Xbox 360 GPUが合計で48 Shaderという膨大な実行リソースを持っているからだと推測される。トランジスタを消費する予測ハードは実装しない代わりに、豊富な演算リソースを活かして、分岐によるハードウェアのパイプラインの乱れを最小に抑えると見られる。ATIのように、Shaderから独立したシーケンサでフロー制御をしている場合は、2つの分岐パスを、2つのShaderハードに割り当てることが可能だと推定される。
あるGPUメーカーの元関係者は、「GPUのスケジューリングにはARM9クラスのCPUコアのパフォーマンスが必要では」と語っていたが、ATIのシーケンサを見る限り、それもうなずける。もっとも、現在わかっている限り、シーケンサはATI独特のアーキテクチャのようだ。他のGPUベンダーは、少なくともATIのシーケンサに相当するユニットは備えないらしい。スレッドレベルでShaderに割り振る、より単純なスケジューラしか持たないと見られる。
また、ATIのシーケンサは、スケジューリングタスクも完全にハードウェアだけで行なう。「デバイスドライバですら、Shaderの制御については何もしなくていい。だから、ドライバも複雑にしなくてすむ」とThompson氏は言う。
●レイテンシを隠蔽するマルチスレッディング
シーケンサはスレッド管理&スケジューリングも行なう。Xbox 360 GPUのShaderはマルチスレッド化されている。最大64スレッドをオンザフライで制御することが可能で、ソフトウェア側からは、仮想的に64スレッドのShaderハードを備えているように見える。
「我々は、粒度の小さな(Fine-Grain)マルチスレッディングができる。我々は多くのステイトレジスタを持っているが、チップ上にステイトバッファを備えている。だから、オンザフライで64スレッドを切り替えることができる」(Feldstein氏)
通常、スレッドを切り替える場合には各ステイトをメモリに待避しなければならないため、時間がかかる。しかし、Xbox 360 GPUの場合は、高速にアクセスできるステイトバッファへと待避することで、短レイテンシでスレッドの切り替えができる。実際には、このバッファはシャドウレジスタになっているのかもしれない。そのため、Xbox 360 GPUでは、短いサイクルでスレッドを切り替える、Fine-Grainマルチスレッディングが可能になる。
GPUでマルチスレッディングが重要なのは、長レイテンシのテクスチャフェッチなどの処理が入るからだという。
「(GPUでは)常に(Shaderの)効率性が失われることが問題となる」「特にテクスチャは非常にレイテンシの長いパスだ。そのため、レイテンシの長いテクスチャフェッチが生じた場合には、他の命令ストリームへと切り替える。それによって、Shaderが止まることがないようにする」とFeldstein氏は言う。
ATIによると、スレッドはShader単位ではなくユニット(Shader群)単位で割り当てるという。「16プロセッサで構成するユニットが3つ、それぞれのユニットが異なるスレッドを走らせる。1スレッドがストールしても、他の2スレッド32 Shaderは動作し続ける」とFeldstein氏は語る。1スレッドで16プロセッサは、リソースの粒度が多すぎるように見えるが、その理由は、まだわからない。
ちなみに、Feldstein氏はCellプロセッサでグラフィックスパイプを実現する場合には、スレディングが問題になると指摘する。「我々は、レイテンシを扱うことに慣れている。それが、Cellプロセッサとの大きな違いだ。彼らは、(SPEに)レイテンシを隠蔽できるハードウェアを実装しなかった」。
●2ダイソリューションを採用
Xbox 360 GPUは、実際にはワンパッケージの中に2個のダイ(半導体本体)が納められたマルチダイモジュールとなっている。先週のレポートで、eDRAMがGPU混載と書いたのは間違いで、eDRAM部分は別チップとなっている。
実際には、このeDRAMチップは、eDRAMではなくインテリジェントDRAMと呼ぶべきチップとなっている。80Mbit(10MB)の、おそらくマルチバンク化されたeDRAMに、固定機能の演算ユニットを合計で192個混載している。すでに伝えられている通り、このユニットで、アルファ/Z/ステンシル/アンチエイリアシングといった、いわゆるポストシェーダ処理を行なう。これらの処理については、GPUコア側のリソースは使われない。GPUコア側から見ると、自動的に負荷なしに処理が行なわれるように見える。
eDRAMチップ側は内部256GB/secの広帯域で接続されている。アルファ/Z/ステンシル/FSAAといったメモリ帯域を消費する処理を行なっても、GPUコア側に接続されたメインメモリの帯域が消費されないという利点がある。「720pで4xアンチエイリアシングを行なっても負担がない」(Feldstein氏)。
この特殊なeDRAMチップについて、ATIのThompson氏は「三菱電機が以前開発した3D RAMと似たようなもの」と例える。3D RAMも、DRAMセルに、ラスタオペレーションプロセッサ(ROP)を組み合わせており、基本的な考え方はXbox 360 GPUのeDRAMチップに非常に似ていた。しかし、今回は、オンパッケージでGPUコアと接続、小容量をバッファとして使った点が異なる。
「3D RAMではチップ(この場合はパッケージ)の外に接続した。そのため、様々な問題があった。3D RAMの場合は、全てのメモリを3D RAMにすると非常に高コストだった。しかし、我々は、計算用に小さなチップを積んだだけだ。それを、(GPUコアと)同じサブストレートに載せて、高速に接続した。PC向けでは難しいが、ゲームコンソールにはよいソリューションだ」とFeldstein氏は語る。
つまり、必要なバッファ分を全て持つのではなく、ローカルでの処理に十分なだけの容量に止め、それをGPUパッケージ内に納めることで、高速にアクセスができるようにしたわけだ。eDRAMで処理した結果は「自動的にGDDR3メモリに転送される」とFeldstein氏は言う。大容量メモリが必要なアンチエイリアシング処理なども、局所的に必要なデータだけをeDRAM側に持ち、動的にメインメモリに転送することで、対応する。Xbox 360 GPUにはパイプコミュニケーションと呼ばれるユニットがあり、これが、Shaderからのデータをどこに転送するかを管理する。
●プロセス技術のために2ダイソリューションを
ATIは、今回、GPUコアとeDRAMの2チップに分離した理由は、プロセス技術のためだと説明する。「eDRAMプロセスと一緒にするより、ロジック部分はロジックだけのプロセスで製造した方が性能を出しやすい」(Feldstein氏)という。
今回の場合、eDRAMはNEC、GPUコアはTSMCで製造している。プロセスはおそらく90nmだ。ATIとしては、慣れたTSMCの90nmロジックプロセスの方が、性能を引き上げるのに安心だと考えたのだろう。あるいは、GPUはもともとTSMCだったが、NEC側が提案したインテリジェントDRAMのアイデアに載ったという可能性もある。ただし、現在は2ダイだが、時間とともに、プロセス技術が進歩すれば、チップが統合される可能性も示唆する。
Xbox 360 GPUのトランジスタ数は約3億3,000万。現在のハイエンドであるRADEON X800/850系は1億6,000万なので2倍に増えたことになる。製造プロセスは、0.13/0.11μmから90nmへとシュリンクしたと見られている。90nmになると、0.13μmと同じダイサイズ(半導体本体の面積)に2倍のトランジスタを搭載できる。計算上では、Xbox 360 GPUのダイは、0.13μmのRADEON X800/850の293平方mmと同等クラスということになる。チップ規模が大きいため、熱(消費電力)的には厳しいはずだが、Xbox 360ではGPUは空冷パッシブヒートシンクで対応しているという。
ちなみに、PlayStation 3に搭載されるNVIDIAのメディアプロセッサRSXは3億トランジスタ。NVIDIAの方がShader数が少ない(30数個)と見られているのにトランジスタ数では差が小さい理由の1つは、Shaderアーキテクチャだ。RSXにも採用されるNVIDIA型Pixel Shaderでは、Shader内部に2つの4wayベクタユニットを備えて並列に処理ができるようになっている(様々な制約がある)。つまり、Shader自体が、ATIよりファットな構成になっており、演算能力は高いが、その分Shader当たりのトランジスタは多い。
□関連記事
【5月20日】【海外】予想を超えるモンスターだったXbox 360のGPU
http://pc.watch.impress.co.jp/docs/2005/0520/kaigai181.htm
【5月16日】【海外】Xbox 360のGPUはUnified-Shaderアレイを実装
http://pc.watch.impress.co.jp/docs/2005/0516/kaigai179.htm
【4月28日】【海外】WGF2.0世代GPUのカギを握るスケジューラとUnified-Shader
http://pc.watch.impress.co.jp/docs/2005/0428/kaigai175.htm
【4月26日】【海外】WGF2.0時代の次世代GPUのアーキテクチャはこうなる
http://pc.watch.impress.co.jp/docs/2005/0426/kaigai174.htm
(2005年5月26日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.