 |


■後藤弘茂のWeekly海外ニュース■1GHz以上の動作が可能になるWGF2.0世代のGPU |
●固定機能とプログラマブルユニットの分離が進む
WGF2.0世代GPUでは、Shaderの一貫性が高まり、物理的にもアーキテクチャが統一されたShaderアレイが実装される可能性が高いことを前回説明した。このアーキテクチャの利点のひとつは、Shaderロードバランシングだ。だが、それだけではない。GPUの高クロック化によるパフォーマンス向上も、重要なポイントだ。
WGF2.0世代GPUでは、理論的にはGPUを大幅に高速化できる。それは、GPUのShaderコアを今までより容易に倍速化できるからだ。そのため、内部1GHz以上で動作するGPUが近いうちに登場する可能性がある。
今のDirectX 9世代GPUは、固定機能部分とプログラム性のあるProgramable Shader部分が入り組んだ構造になっている。DirectX 9世代では固定機能はある程度削減され、WGF2.0世代ではさらに固定機能部分を減らすが、依然として固定機能は残る。これは、固定機能の方が、プログラマブルユニットよりずっと効率的な処理があるからだ。
Programable ShaderはCPUと同じプログラマブルな演算ユニットで、速く回せばそれだけ性能が上がる。また、演算ユニット自体は、複雑なロジックをハードワイヤドで実装するのではなく、汎用性のために基本的な演算ロジックを実装している。そのため、高速化もしやすい。CPUと同じような性格を持っている。
それに対して、固定機能部分は、特定処理のためのロジックをハードワイヤドとして実装している。ロジックが複雑になると、一般的に言ってクロック周波数を上げにくい。その反面、ロジックがそのままハード化されているため、高クロック化しなくても速く処理できる。「Shaderでは数サイクルかかる処理も、ハードウェア実装なら1サイクルで実行できる。プログラマビリティとサイクル当たりの性能はトレードオフの関係にある」とあるGPU関係者は語る。
つまり、固定機能部分は高クロック化は難しいが低クロックでも性能が出せる。一方、Shaderは同じクロックならハードワイヤドより性能は落ちるが高クロック化が容易ということになる。
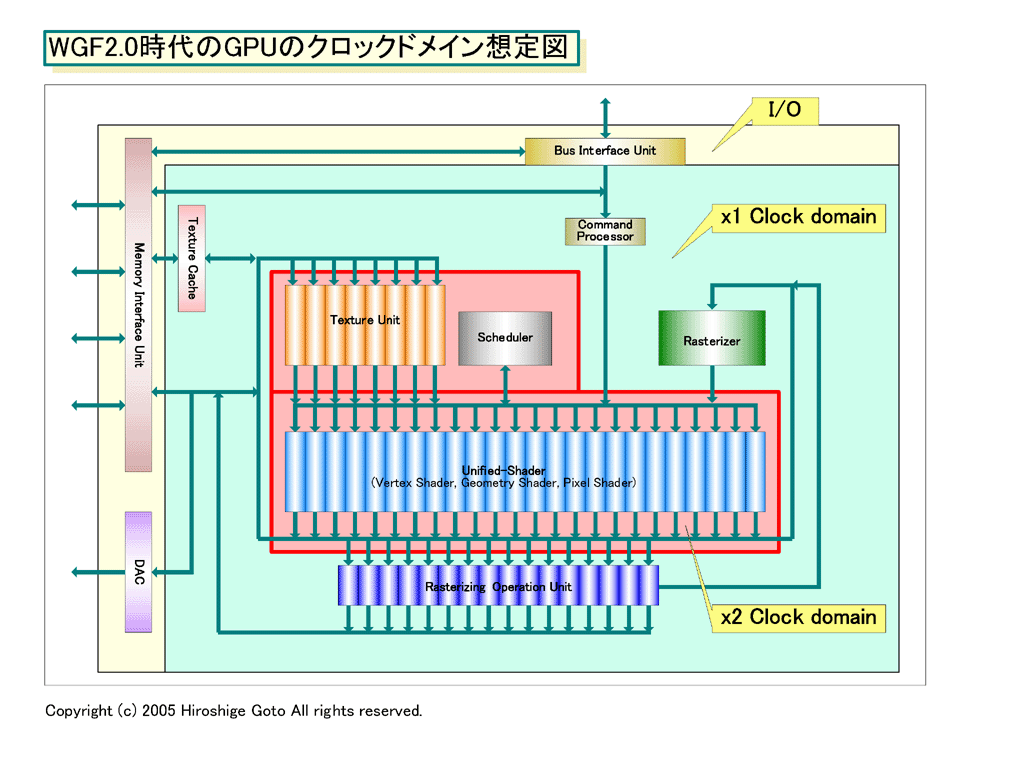
●Shaderコア部分のクロックドメインを2倍速にする
GPUはこのように、性格が異なるユニットを混載しており、これまでは固定機能部分に引きずられてクロックを上げることが難しかった。GPUは常にCPUの数分の1の動作周波数に留まり、並列性は高くても周波数では大きく引き離された。これは、DirectX 9世代GPUでも同じで、GPUはGHz台にはほど遠い。これは、せっかくのShaderが、本来の性能を発揮できないことを意味する。例えば、8個のSIMDプロセッサを4GHzで動作させることができるCellと同じ論理ピーク性能を、500MHzのGPUが達成しようとしたら64個のShaderを載せなければならない。
しかし、WGF2.0世代アーキテクチャになると、この問題は部分的には解決できるようになる。WGF2.0世代GPUでは、多くのGPUベンダーがプログラマブル演算コアであるShaderをコンピュテーションコアアレイとしてまとめると推測される。そうした実装では、Shaderをほかのユニットから分離しやすい。
すると、Shaderアレイだけクロックドメインを分離して、ほかのユニットの2倍のクロックで動作させるといったことが容易になる。例えば、GPU全体は600MHz動作でも、Shaderアレイは1.2GHzで動作させることもできる。飛躍的にShaderの演算性能は上がることになる。
こうしたクロックドメインの分離は、SOCタイプのデバイスではポピュラーに行なわれている。例えば、PSPチップはCPUコアがほかのユニットの倍速で動作している。
もちろん、そのためには、Shaderを、よりパイプラインを細分化した設計に変更する必要がある。また、高速化されるのはShaderの演算性能だけで、他の性能は上がらないので、ボトルネックが他にある場合は全体の性能も上がらない。しかし、少なくとも理論上の演算性能は、より容易に上げることができるようになる。WGF2.0世代GPUの最初の世代で倍速コアが登場するかどうかはわからないが、WGF2.0世代中にはShaderが1GHz以上で動作するGPUが登場するだろう。
 |
| WGF2.0時代のGPUのクロック PDF版はこちら |
●中長期的にはGPUの設計が変わる可能性
Shader演算性能が上がると、GPUの設計フィロソフィも変わってくる可能性がある。これまでのGPUは、比較的低いクロックでも性能を上げられるように、処理の並列度を上げる方向へ向かって来た。Pixel Shaderの数は、4→8→16と倍々で増えており、そのためにGPU自体が肥大化していた。
しかし、今後、最も求められるのがShader性能で、Shader性能自体はコアの倍速化で上げることができるとしたら、Shaderの数自体を増やす必然性は薄れる。例えば、現状のミッドレンジGPUと同程度のShader個数12個でも、倍速で動作させれば、1クロック当たり24 Shader分のオペレーションが可能になる。そのため、ミッドレンジ以下のGPUでは並列性を増やす勢いは鈍る可能性もある。もっとも、ハイエンドだけは天井知らずの性能要求のために、依然として並列性を高めて行く可能性が高いが。
GPUの設計のアプローチ自体も変わる可能性がある。現在のGPUの設計期間はCPUの半分で、開発スタートから18~24カ月で市場に製品が出る。設計に時間がかからないのは、GPUでは、カスタムな回路設計で高速化にチューンしないからだ。例えば、3年前にNVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、その理由を次のように語っていた。
「カスタム設計でチューンすれば、(GPUが)もっと高速になるのは確かだ。問題は設計に時間がかかることだ。例えば、IntelなどのCPUでは、アーキテクチャデザイナが仕事を終えてから、約1~2年もトランジスタチューニングに時間をかけている。同じことをGPUでしたら、2002年に、2GHzのTNT2を出すことになる」
つまり、GPUではハードウェア仕様の追加とアーキテクチャの変化がCPUよりも激しい。そのため、設計を短サイクルで回す必要があり、そうすると、高速化のためにカスタム設計でチューンなんてしていられなかったというわけだ。
しかし、GPUの技術トレンドは大きく変わりつつある。新しい仕様はハードウェアで加えるのではなく、Shader上のソフトウェアで実現する。そのために、Shaderをできるだけフレキシブルで汎用に作り替えようとしている。そして、GPU性能は、Shaderの高速化にかかるようになりつつある。そうすると、原理的にはGPUメーカーは汎用性の高いアーキテクチャなら設計に時間をかけ、高クロックにチューンしても見合うようになる。従来とは異なる開発サイクルに変わって行くかもしれない。
そうなると、CPUメーカーのように高速なプロセッサコアを設計し慣れた開発陣も、GPU開発に乗り出す可能性が出てくる。実際、以前、あるCPUベンダーの関係者は、そうしたアイデアを語っていた。CPU設計のアプローチを導入すれば、より高速なGPUを作ることが可能なので、親会社に提案していると言っていた。
また、次世代PlayStationでも、CellプロセッサをベースにしたGPU開発のプロジェクトもあった。SPEベースでProgramable Shaderを作り、ラスタライザやポストシェーダ処理ユニットなどを固定機能で実装すれば、それはそれで画期的なGPUになったはずだ。今後は、ますます、こうしたCPUとGPUの設計のシームレス化が進む可能性がある。
●Shaderの共通ハード化を前提としたGeometry Shaderの実装?
Shader中心に構造が変わるWGF2.0世代GPU。この変化は、より抜本的な機能が、Shaderで実現される形で実装されて行く可能性が高いことを意味する。それを示唆するのは、Geometry Shaderと「Tessellator(平面分割ユニット)」だ。
Geometry ShaderはWGF2.0で新たに加わったShaderステージだ。プリミティブを扱うジオメトリシェーダ(プリミティブシェーダと呼ばれることもある)プログラムを走らせる演算ステージとなっている。
同じジオメトリパイプにあるVertex Shaderとの違いは、Vertex Shaderはプリミティブ単位のプロセッシングを行なうこと。これまでの1頂点入力→1頂点出力の限界を破り、プリミティブの変成を行なうことができる。よくあるのは、CG映画のふさふさした毛皮をオフラインのジオメトリシェーダプログラムでプロシージャルに生成する例だ。それが、GPUハードウェアでも可能になる。
Geometry Shaderの問題は、Vertex/Pixel Shaderとは物理的に異なるハードウェアとしてこのステージを実装しようとすると、実装コストが増えてしまう点だ。Geometry Shaderとして必要と想定されるピーク性能分のShaderハードを載せるとなると、Shaderハードを数個増やさなければならない。パイプラインにプログラマブルステージが増えると、各ステージのShaderがボトルネックにならないようにバランスを取ることはますます難しくなる。
今でも、アプリケーションによってはVertex Shaderがガラ空きだったり、Pixel Shaderが遊んでいたりといったケースがある。Geometry Shaderが加われば、バランシングはますます難しくなり、GPUの無駄がさらに増えてしまう。
しかし、Shaderを物理的にも統合されたUnified-Shaderとして実装すれば、話は変わってくる。論理Shaderを動的に割り当てることで、ロードバランスを自動的に取ることができるので、新たにShaderステージを加えることが容易になる。GPUベンダー側は、バランスを悩まずに、Geometry Shaderを実装することができる。そのため、Geometry ShaderのWGF2.0への実装は、Shaderハード側の統合化/汎用化を前提としたものだと推測される。
●Tessellatorを専用ハードにするかShaderで実現するか
平面分割を行なうTessellatorも、Shaderを使ってプログラマブルに実現できる。実際、ある情報筋は「DirectX 10の時に提案されていたテッセレーションは、Shaderを使うものだった」と伝えている。昨年公開されたWGFのパイプラインにもTessellatorのステージはあったが、これも物理的にはShaderとして実装される計画だった可能性がある。
しかし、昨秋まであったWGFのTessellatorは、今春の「GDC(Game Developers Conference)」のMicrosoftのプレゼンテーションでは消えていた。もし、元々のWGFのTessellatorがShaderを使うものだったとすれば、これはハードそのものの変更ではなくなる。Tessellatorステージが消えても、専用ハードが削減されたのではなく、単に、Shaderにテッセレーションタスクを割り振ることが取りやめになったことになる。
WGF2.0からTessellatorが削除された、詳しい状況はわかっていないが、GDCの別セッションでは、MicrosoftはTessellationを、固定機能ハードとして実装するか、プログラマブルハードとして実装するか、まだ議論があることを示唆していた。固定機能ハードの利点は、実装コストに対しての性能が高いことだが、固定機能のTessellatorハードのスループットで性能が制限される問題がある。それに対して、プログラマブルハードなら、Shaderを使えばテッセレーション性能も自在に調節ができる。しかし、Shaderで実現すれば、固定機能ユニットよりも効率は落ちる。また、Microsoftは、プログラマブルな実装についてはスタンダード化されていないことも指摘していた。
この議論は、Shaderのパフォーマンスにも関連している。倍速化などで、ShaderがGPU内で性能を上げて行くことができるなら、TessellatorもShaderに実装しやすくなる。その場合は、WGF2.0世代GPUの基本設計は変えずに、多少の変更でShaderベースのTessellatorを実現できる。しかし、それでは効率が悪く十分な性能が得られないという議論になると、やはり固定機能ハードが欲しいという話になってくる。おそらく、そのあたりで、異論が挟まれて、WGF2.0へのTessellatorステージの実装が消えたのだと推測される。
いずれにせよ、Tessellatorの件のポイントは、GPUでは、まだ新しい仕様を、固定機能ユニットで実装するか、プログラマブルユニットで実現するか、議論があることを示している。汎用処理もできるグラフィックスプロセッサを目指すプログラマブルGPUにとって、一番の悩みのタネは、おそらくこの点だ。できる限りプログラマブルにして行きたいが、GPUとしての高効率も落としたくない。しかし、複雑な処理を、効率を追求して固定機能ユニットで持たせると、汎用性のないリソースにトランジスタを割かなければならなくなってしまい、GPU全体での汎用化率が落ちてしまう。GPUベンダーの悩みは、まだ続きそうだ。
□関連記事
【4月28日】【海外】WGF2.0世代GPUのカギを握るスケジューラとUnified-Shader
http://pc.watch.impress.co.jp/docs/2005/0428/kaigai175.htm
【4月26日】【海外】WGF2.0時代の次世代GPUのアーキテクチャはこうなる
http://pc.watch.impress.co.jp/docs/2005/0426/kaigai174.htm
(2005年5月2日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.