 |


■後藤弘茂のWeekly海外ニュース■WGF2.0世代GPUのカギを握るスケジューラとUnified-Shader |
●CPUとは異なるGPUのスケジューリング
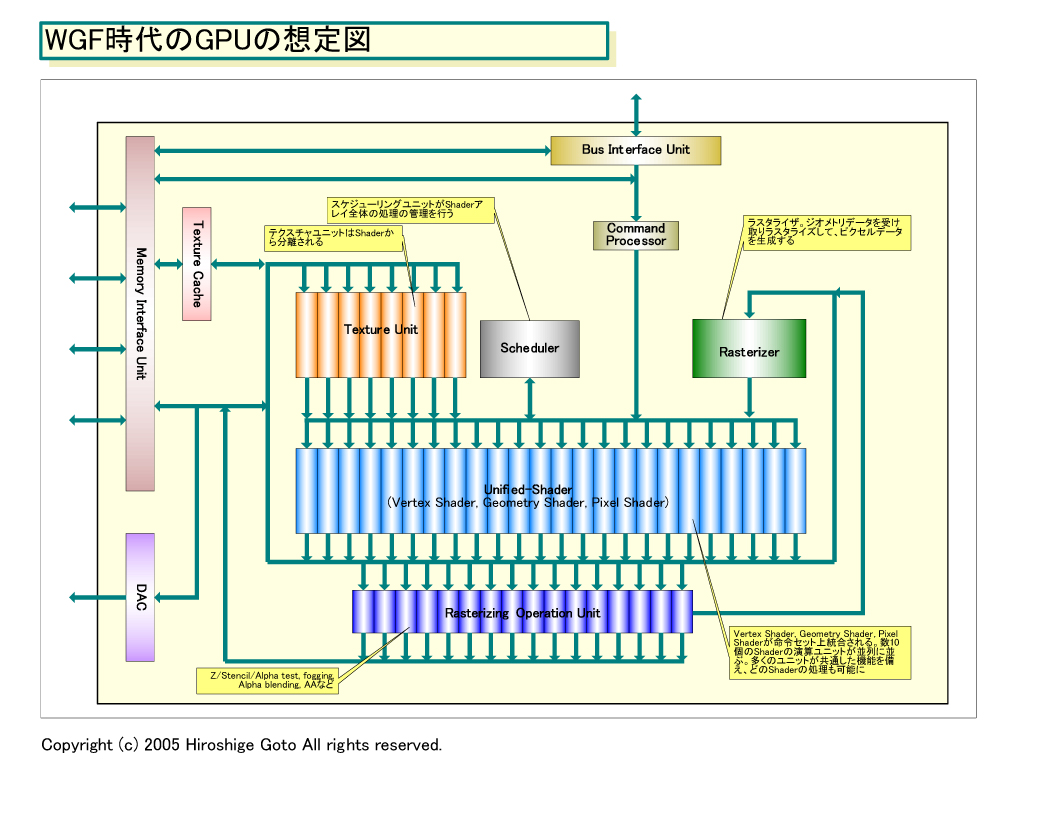
プログラマブルGPUの次のステップは、「WGF(Windows Graphics Foundation) 2.0世代GPU」だ。前回レポートしたように、近未来のGPUは、MicrosoftのWGF2.0に合わせて内部アーキテクチャを大きく革新する。GPUは、より汎用ベクタ並列プロセッサに近くなる。その変化を象徴するのが、WGF2.0世代GPUの、スケジューラとUnified-Shaderアレイだ。
 |
| WGF時代のGPUの想定図 PDF版はこちら |
WGF2.0世代GPUでは、ダイアグラム上にグローバルスケジューラが登場する。スケジューラはCPUにも搭載されているが、次世代GPUのそれは役割が異なる。CPUのスケジューラは、基本的に命令レベルのスケジューリングを行なう。Pentium 4やAthlon 64などのout-of-order型スケジューリングでは、命令の実行順序を並べ替えて実行できるものから実行する。また、条件分岐命令の分岐方向を予測して実行する。
基本的には、スケジューリングは1スレッド内の命令群に対して行ない、命令レベルの並列性(ILP)を上げる。Hyper-Threadingのような「Simultaneous Multithreading(SMT)」では、複数スレッド間の命令もスケジューリングするが、焦点はILP向上にある。
それに対して、GPUではILPの向上にはそれほどフォーカスせず、ダイナミックな命令レベルのスケジューリングは行なわない方向にある。その代わり、頂点やピクセル単位のタスクの動的なスケジューリングを行なう。「GPUでは、命令単位ではなく、スレッドのスケジューリングが重要となる」とATI TechnologiesのAndrew B. Thompson氏(Director, Advanced Technology Marketing, ATI Research)は、昨年語っていた。
WGF2.0世代GPUの場合は、Shaderユニット群に対して、動的にタスクを割り振るスケジューリングを行なう。実際には、現在のGPUもタスクのスケジューリングを行なっているが、WGF2.0世代では、それがより高度化され、多数のShaderが効率的に稼働できるようにする。後述するロードバランシングなどもスケジューラが制御する。
●数百万のタスクを並列実行できるGPU
GPUのスケジューリングがCPUと異なるのは、実行するソフトウェア環境が異なるからだ。PCのソフトウェア環境だと、インテンシブに実行されるタスクの数は限られる。しかし、GPUには無数のタスクがある。
「スレッドレベルの並列性を高めることはGPUにとっては非常に容易だ。なぜなら、我々には並列に実行できる多数のタスクがあるからだ。CPUの場合はメインワークのタスクは1個か、多くても2個だろう。しかし、GPUレンダリングの場合、1,600×1,200ドット表示なら、200万のタスクがある(笑)。しかも、それぞれのピクセルには依存性がない」、「CPUにとっては2~4の並列性が大きな数だが、GPUにとってはそんな小さな数であったことはない。CPUとGPUでは、並列化のフィロソフィが異なる」と語るのはNVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)。
CPUは、メインのタスク数が限られている。そのため、マルチコア/マルチスレッド化してスレッド並列性を高めて、2~4並列程度でちょうど釣り合っている。それに対してGPUでは、依存性がなく並列に実行できるタスクが無数にある。だから、Shader数を増やし、Shaderをマルチコンテクスト化することで、並列性を高めることができる(CPUのようなマルチコア化は必要がない)。そして、マルチスレッドで高い並列性を維持するためにタスクスケジューラを高度にする必要がある。
CPUとGPUでスケジューリングが異なるのは、レイテンシの影響の違いもある。CPUでは、個々のスレッドを速く実行しないと性能が上がらないから、投機実行やプリフェッチなどでレイテンシを短くしようとする。それに対して、GPUは、個々のスレッドのレイテンシはそれほど問題にならないため、スレッディングでレイテンシをカバーしようとする。NVIDIAのKirk氏は次のように語る。
「GPUは依然としてストリームプロセッサだ。ストリームプロセッシングでは、プロセッサをビジーに保つために、(CPUとは)異なるソリューションが必要となる。ストリームプロセッサがCPUと異なるのは命令フロースルーだ。我々はマルチプルコンテクストを一度に走らせることでレイテンシをカバーする。
CPUの場合は1つのプログラムを走らせるので、命令1の直後に命令2を実行する必要がある。しかし、Shaderでは、ピクセルAに対する命令1の後に、ピクセルBに対する命令1を実行、次にピクセルCに対する命令1といった形で(複数のコンテクストを混在させて)実行できる。そうすると、命令2を実行するまでにレイテンシがあるから、分岐命令で(分岐先の)フェッチにレイテンシが必要になってもカバーできる」
こうして考えると、WGF2.0世代のグローバルスケジューラは、膨大な数のスレッドの管理をする必要がある。スケジューラは各スレッドにIDを振って管理、実行ユニット群に割り振る。Shaderによって処理にかかる時間が異なるため、出力はばらばらになるが、スケジューラが最終的に揃えてラスタライザやテクスチャユニットや固定ラスターオペレーションユニット群に送ると見られる。
●Shader間のロードバランシングが可能に
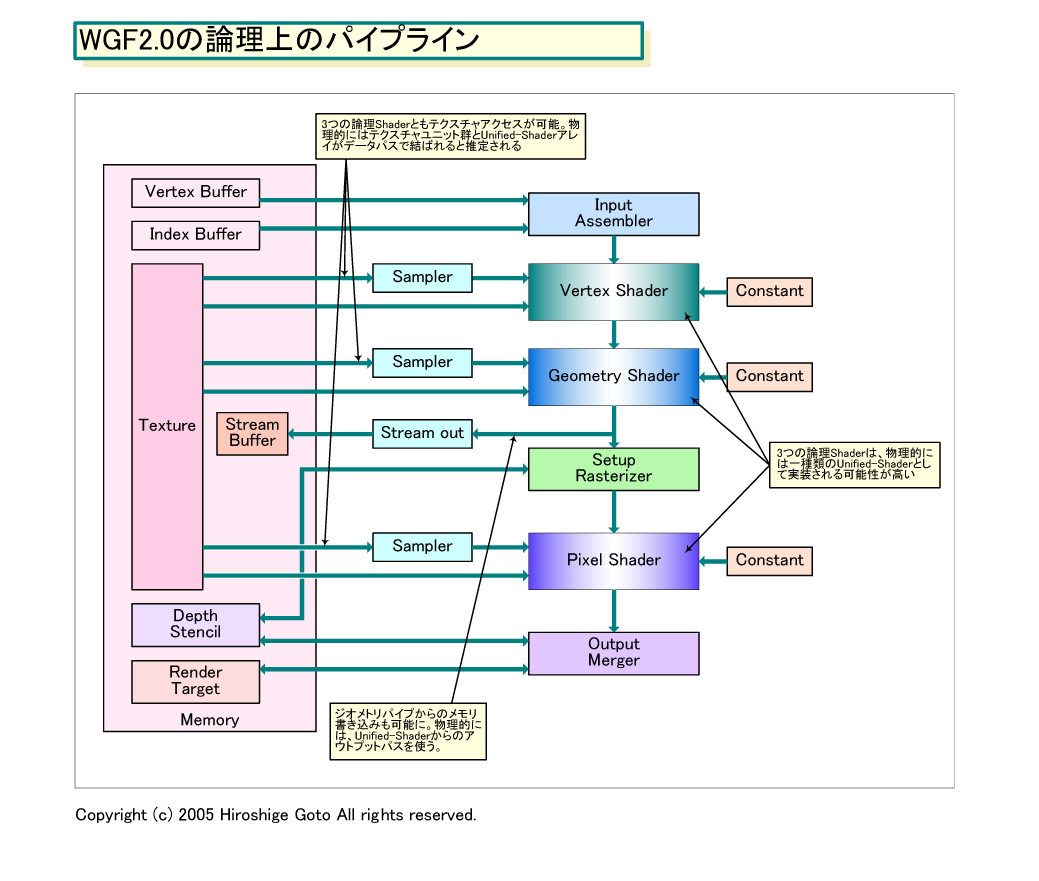
WGF2.0世代では、Shaderの共通化が進み、Unified-Shaderへと向かう。これは、どんなベネフィットを産み出すのか。まず、GPUとしての利点は、Shader間のロードバランシングが容易になることだ。
ATIのDavid E. Orton(デビッド・E・オートン)社長兼CEOは、過去のインタビューで次のように語っている。
「Vertex ShaderとPixel Shaderは、コモンプロセッシングユニットに向けて統合が始まっている」、「時間とともに、Shaderは共通アーキテクチャの、汎用浮動小数点ユニットになって行くと考えている。その結果、Shaderのロードバランシングが可能になる」、「プロセッサ内のフローのバランスを取ることが容易になる」
現在のGPUは、物理的に異なる2種類のShaderを搭載している。頂点処理のVertex Shaderとピクセル処理のPixel Shaderで、それぞれ役割も基本的には固定されている。だが、Unified-Shaderになり、各Shaderの論理上のアーキテクチャが統一されると、Shaderを固定しない実装が可能になる。現在のようなVertex Shaderが4個、Pixel Shaderが8個といった固定的な実装ではなく、スケジューラが各物理Shaderに、論理上のShaderを割り振ることができるようになる。
WGF2.0のパイプラインには、Vertex Shader、プリミティブ処理のGeometry Shader、Pixel Shaderの3ステージのShaderがある。この3種類のShaderを、実際に実装しているUnified-Shader群に対して動的に割り当てることで、Shader間のロードバランシングが可能になる。
 |
| WGF2.0の論理上のパイプライン PDF版はこちら |
●動的なShaderのロードバランシング
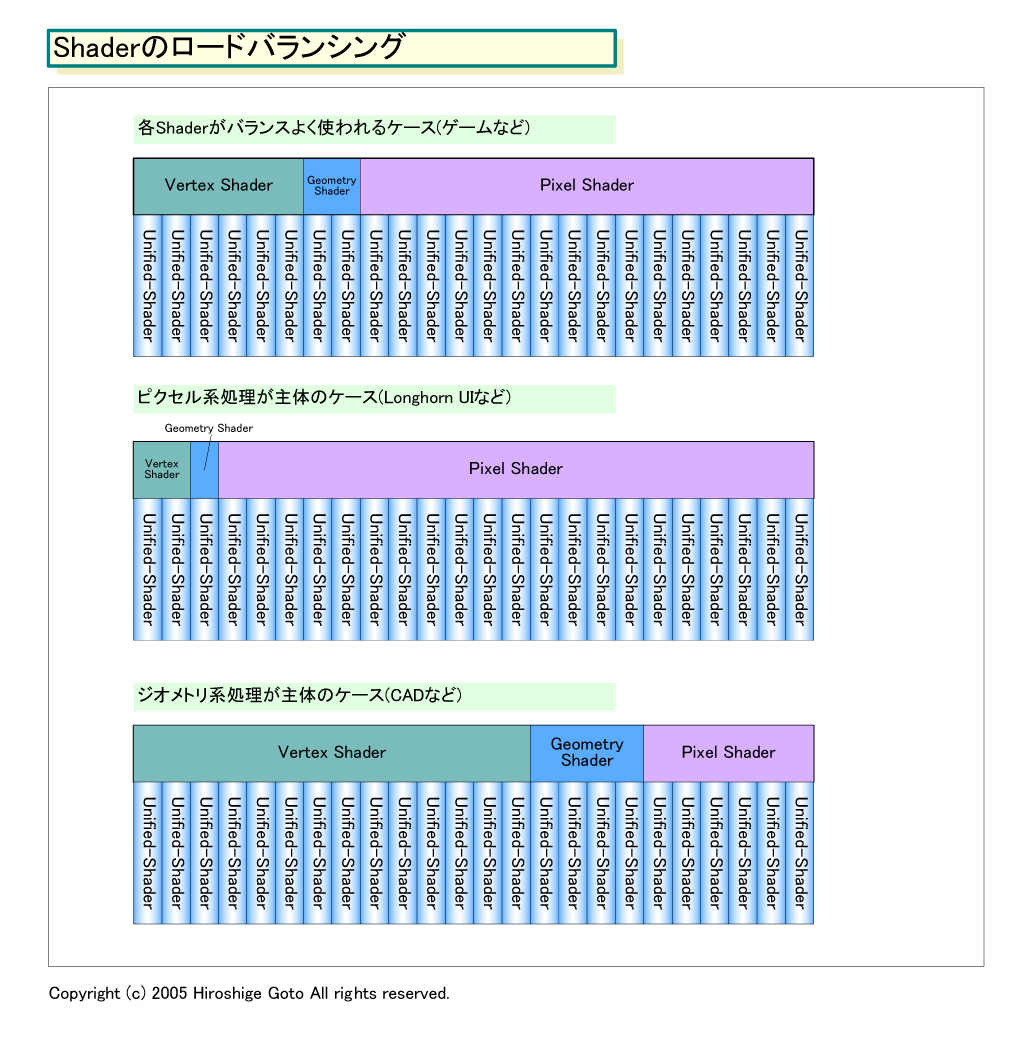
Vertex Shaderが6個、Geometry Shaderが2個、Pixel Shaderが16個で割り当てて稼働していて、ピクセル系処理の負荷が大きくなった場合は、動的にPixel Shaderの割り当てを20個に増やし、他のShaderを減らすといった制御ができる。あるいは「ボリューメトリックレンダリングのようなケースでは、ピクセル処理ばかりなので、全てをPixel Shaderに回すことで高速化できる」とある業界関係者は言う。
動的なShaderのロードバランシングによって、常にShaderを最適構成で働かせることで、GPU全体の処理パフォーマンスを最大に持って行くわけだ。現在のGPUは、ゲームをメインターゲットに最適化されたShader構成になっているが、ロードバランシングが可能になると、個々のアプリケーションに最適化されるようになる。
ロードバランシングは、ハイエンドGPUだけでなく、バリュークラスのGPUにとっても利点がある。例えば、Longhornのユーザーインターフェイス「Avalon」は、3Dパイプラインを使うものの、ジオメトリはほとんど使わない。
「Longhornは、Pixel Shaderオリエンテッドになる。ほとんどがピクセルの処理になるからだ」、「おそらくVertex Shaderの性能はそれほど必要とされない反面、Pixel Shaderの性能は非常に高いレベルが求められると考えている」とIntelで3Dグラフィックスを担当するKim Pallister氏(Senior Technical Marketing Engineer, 3D Graphics)は昨年語っていた。WGF2.0世代のバリューGPUでは、Unified-ShaderのほとんどをPixel Shaderに割り当てることで、Longhornをより快適に使えるようになるだろう。
もっとも、最初のWGF2.0世代GPUが、完全なロードバランシングができるとは限らない。それは、実装コストが異なるからだ。例えば、Vertex ShaderとPixel Shaderは、データタイプが同じでも、実際の演算ユニットは異なる実装になっているという。Pixel Shaderには、特定処理のためのユニットが含まれているからで、両Shaderを比べるとPixel Shaderの方が大きいという。
そのため、Unified-Shaderとなっても、全ShaderがPixel Shaderとして十分な性能を発揮できるかどうかはわからない。それは、各GPUベンダーの実装方式に依存するだろう。また、各コンポーネント間のデータパスにもShaderは制約される。例えば、Vertex Shaderのスループットは、Command processorからの入力に制約される。
こうした制約は考えられるものの、WGF2.0世代アーキテクチャの狙いは、明らかにGPUの汎用プロセッサ化で、Shaderアレイを均質に扱えるようにすることだ。少なくとも、GPUで想定されている汎用コンピューティング(例えばシミュレーションやエンコーディング)の用途なら、Unified-Shaderは全て同等に使えるだろう。
 |
| Shaderのロードバランシング PDF版はこちら |
□関連記事
【4月26日】WGF2.0時代の次世代GPUのアーキテクチャはこうなる
http://pc.watch.impress.co.jp/docs/2005/0426/kaigai174.htm
【2004年4月26日】【海外】最新GPUのテーマはShaderの実行効率
http://pc.watch.impress.co.jp/docs/2004/0426/kaigai086.htm
【2004年1月15日】【海外】統合Shaderが次々世代のGPUアーキテクチャの鍵
http://pc.watch.impress.co.jp/docs/2004/0115/kaigai056.htm
(2005年4月28日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.