 |


■後藤弘茂のWeekly海外ニュース■不明点の多いNVIDIAの「SLI」 |
●ロードバランシングを打ち出したSLI
 |
NVIDIAが、マルチGPUアーキテクチャ「NVIDIA SLI(Scalable Link Interface)」のデモを公開し始めた。NVIDIAの現在のSLIは、2枚のグラフィックスカードを専用インターフェイスで接続、3Dグラフィックス描画処理を分散させる。ポイントは、広帯域のポイントツーポイントインターフェイスでGPU同士を接続できること、分散化のアルゴリズムを柔軟に変更できること、接続したGPU間でのロードバランシング(負荷分散)ができること。
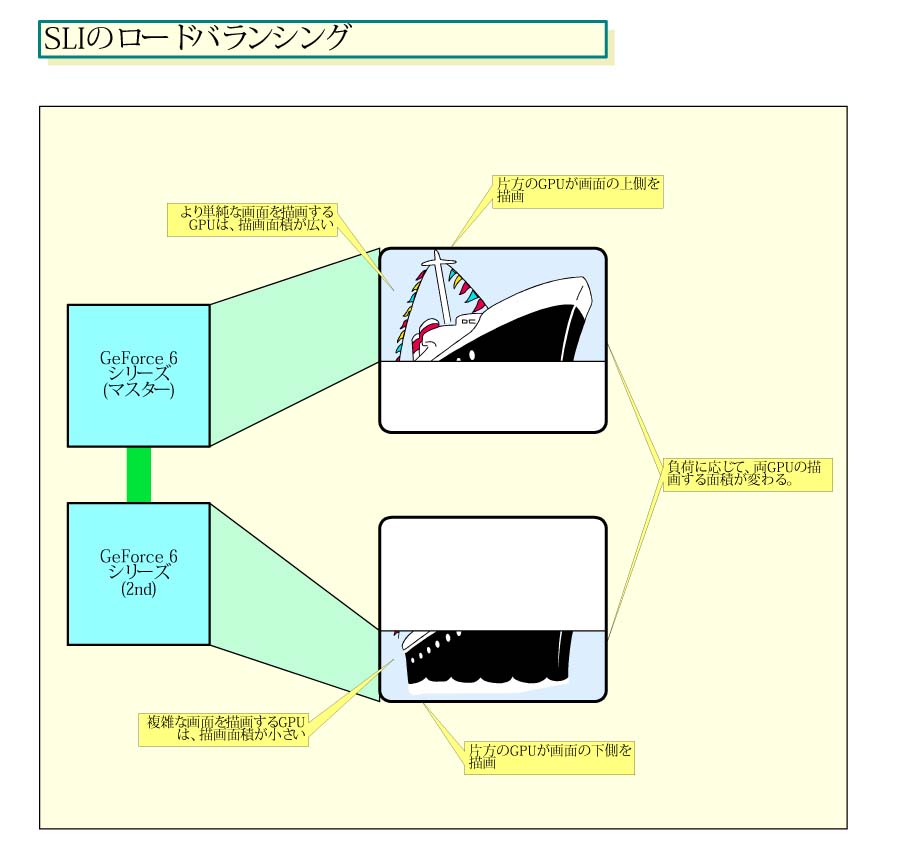
特に、注目を集めているのは、SLIを使ったロードバランシングで、NVIDIAは各フレームを切り分けて2つのGPUで描画するデモを行なった。具体的には、フレームの上側を描画するGPU 0とフレームの下側を描画するGPU 1の、描画の境目が負荷に応じて動的に上下する様子を見せた。画面上のグラフィックスの複雑度によるGPU負荷に応じて、GPU 0とGPU 1の描画エリアが動的にどんどん変わる。これまでの、デュアルGPUとは全く異なる、インテリジェントなデュアルGPUのアプローチを示したわけだ。
 |
 |
もっとも、NVIDIAはSLIテクノロジの肝心の部分については、まだほとんど明かしていない。例えば、SLIでGPU同士を接続するデジタルリンクである「ハイスピードデジタルインターフェイス」の技術的な詳細は一切明らかになっていない。帯域、方式、全てが謎のままだ。詳しい内容は、全てSLIのホワイトペーパー待ちだ。
また、過去2カ月で、NVIDIAのSLIについての説明も微妙に変わってきた。当初、NVIDIAはSLIの手法としてフレームインターリービングを説明、ロードバランシングもできるというニュアンスだった。ところが、SLI発表直前になると、説明はロードバランシング中心へと移り、デモを公開し始めるとロードバランシングだけを表に出し始めた。NVIDIA自身も、説明が変化したことを認める。こうした背景を考えると、NVIDIAがロードバランシングで行けると確信を持つようになったのは、SLI発表が近くなってからだと思われる。
●オーバーヘッドの少ないロードバランシング
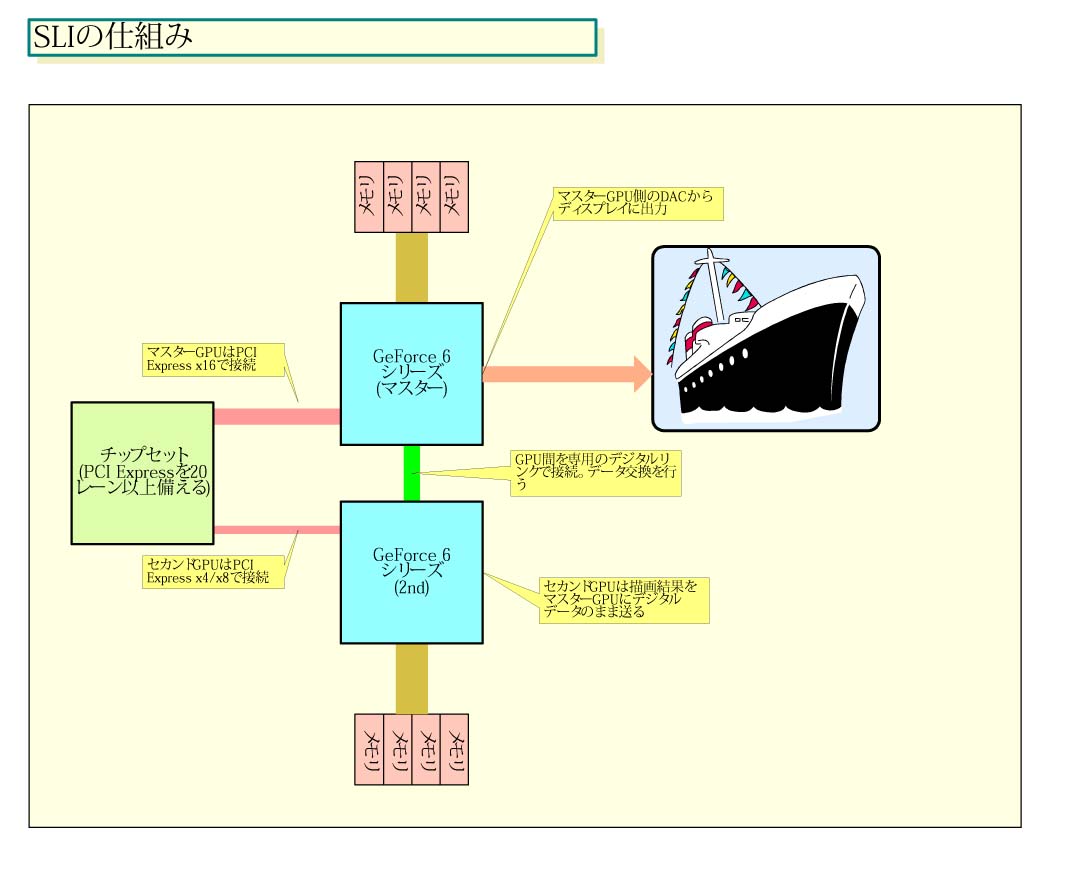
SLIテクノロジでは、フルデジタルでGPU間にグラフィックス処理を割り当てるため、分散化の方式をフレキシブルに変更できる。複数GPU間の描画結果をマスターGPUがフレームバッファに描画して、それをマスターGPUのDACから出力する。そのため、マスターGPUがフレームバッファをコンポーズする前までは、どんな分散方式でも採ることができる。
この点は、アナログ出力のスキャンラインをインターリーブしていた3Dfx InteractiveのSLIとは異なり、はるかに自由度がある。例えば、ユーザー側は、フィルレートにフォーカスするかジオメトリアクセラレーションにフォーカスするか、SLIのメソッドを選択することができるという。
SLIのロードバランシングスキムで最大の疑問は、どうやって負荷を分散しているかだ。ロードバランシングでは常にそうだが、負荷の正確なアナライズがカギとなる。負荷のアナライズで大きなオーバーヘッドが生じたり、レイテンシが発生してしまうと、SLIによってパフォーマンスを引き上げるという本来の目的が削がれてしまう。本末転倒だ。かと言って、負荷の分析精度が十分ではないと、片方のGPUがビジーなのに、もう片方のGPUが遊んでいるといった無駄が発生して、リニアに性能が上がらなくなってしまう。
そのため、SLIではオーバーヘッドが小さな負荷アナライズが必須となる。NVIDIAはSLIロードバランシングで、1 GPU時に比べて1.87倍のパフォーマンスを発揮できると言っている。理論値は2倍だが、実際にはDACやフレームバッファなどはマスターGPU側のリソースを共有しているためオーバーヘッドがある。それを割り引くと、1.87倍という性能向上は、実質2倍。つまり、負荷分析などのオーバーヘッドがほとんどないことを示している。NVIDIAは、効率のいいロードバランシングの手法を見つけたと推測される。
 |
| □SLIの仕組み □PDF版はこちら |
●疑問が残るロードバランシングの方式
ただし、これには疑問もある。複雑な3Dグラフィックス処理の負荷を予測するのは極めて難しいからだ。しかも、シェーダ時代になって、シンプルなパイプライン処理ではなくなってきたため、さらに難しさは倍増している。それに、もし、実際に3Dグラフィックスパイプにデータを流す前に分析ができるのなら、そもそも描画上の無駄な処理を事前に省くことができるはずだ。それができないことが、3D描画過程で無駄が生じる原因のひとつとなっている。そう考えると、ドライバとGPUで、負荷分散が可能なほど高度なアナライズが可能とは思えない。
想定できる論理的な解決策の1つは、直前のフレームの描画結果をもとに、負荷を測定する方法だ。直前フレーム上での負荷が均等になるように、次のフレームを分割して2個のGPUに割り当てる。それによって、画面分割位置を決めるわけだ。この方式は、シーンが大きく切り替わると、全く役に立たないという問題はあるが、画面の動きが少なければ有効なはずだ。
しかし、それにしても、ドライバ側がフレーム毎にGPU側の負荷を把握する必要がある。1フレームの描画が終わる度に、GPU側からCPU側のランタイムに、画面描画の複雑度のデータをバックする必要がある。これも余計なオーバーヘッドとなり、レイテンシを増やしてしまう。それから、シーンの変化が激しいと効率が落ちるはずだ。
もっとも、NVIDIAのアーキテクチャならもっと簡単な方法もある。3Dグラフィックスに詳しいライターの西川善司氏は「片方のGPUが画面の上から、もう片方のGPUが画面の下から描画すれば、簡単に負荷分散ができるはず」と指摘する。
つまり、GPU 0がフレームの上から下へ描画し、GPU 1がフレームの下から上へ描画して行くなら、フレーム上のどこかで両GPUの描画ラインが自然にぶつかる。この方式なら、SLIのGPU/ソフトウェアが調停しなければならないのは、両GPUの描画ラインが接した時に描画を終了させることだけだ。それだけで、自動的に負荷分散が可能になる。例えば、フレームの上部のグラフィックスが複雑で下部よりも時間がかかるなら、GPU 1の方がGPU 0より速く描画が進む。そのため、自動的にフレームの真ん中より上の方で両GPUの描画ラインが接する=GPU 1の方が描画するフレーム面積が広くなる。
このアプローチを採れば、事前にドライバソフトが負荷を解析する必要は一切ない。そのため、GPUとソフトウェアのオーバーヘッドは最小ですむ。コロンブスのタマゴ的だが、少なくとも2wayならこの手法で負荷分散の問題は解決できる。NVIDIAからの説明はないものの、この方式は、論理的に理想的な解法の1つだ。
 |
| □SLIのロードバランシング □PDF版はこちら |
●NVIDIAとVIAのチップセットがサポート可能
 |
| PCI Express x16スロットが2つ必要 |
SLIの実装面でも、まだ疑問が残る。SLIでは、2枚のPCI Express x16ビデオカードをマザーボードに挿し、カード間を専用コネクタで接続する。つまり、スロットとしてはPCI Express x16スロットが2基マザーボード上に必要なわけだ。ただし、PCI Expressのレーンは両方がx16である必要はない。マスターになるGPUはPCI Express x16で接続するが、セカンドGPUはPCI Express x4またはx8で接続でいい。
こうした構成であるため、SLI対応マザーボードとするためには、PCI Express x16+x4の合計20レーンのPCI Expressインターフェイスと、2基のPCI Express x16スロットが必要となる。実際には、マザーボードでは通常2基のPCI Express x1も用意する。そのため、チップセットには合計で20レーン以上のPCI Expressが必須で、実用的には22レーンあるのが望ましい。
NVIDIAは現在、Intelのワークステーション用チップセット「Intel E7525(Tumwater:タムウォータ)」をSLIのデモに使っているが、これはTumwaterがノースブリッジに設定を変更できるPCI Expressレーンを24本備えているからだ。
こうした構成に対応できるその他のチップセットは、NVIDIA自身とVIA Technologiesのチップセットだ。AMD向けPCI Expressチップセットでは、NVIDIAの「CK8-04」とVIAの「K8T890」がどちらもPCI Expressを合計20レーン以上持っている。そのため、PCI Express x16の他にPCI Express x4を1基載せることが可能だ。高価格なTumwaterマザーボードより、低コストなSLI向けマザーボードを作ることができる。
SLIでPCI Express x16スロットが必要なのは、ビデオカードの物理形状と電力供給の問題からだ。SLIでは通常のGeForce 6系ビデオカードをセカンドGPUとして使うため、PCI Express x16のスロットとx16の75Wの電力供給(NV40では+外部電源も)が必要だ。PCI Expressでは、x4/x8のレーンでx16のスロットという構成も可能だ。
しかし、SLIで、信号側が最低でもx4が必要となるのはなぜか。NVIDIA側は、これについては、ホワイトペーパーが提供されるまで、詳しいことが説明できないという。専用のデジタルリンクだけでGPU間のデータ転送が可能なら、原理的にはPCI Express側はx1でもよさそうだが、現在の説明ではx4以上となっている。
ひとつ想定できるのは、バスの負荷も分散させようとしている可能性。例えば、セカンドGPUで必要であることが判明しているコマンドストリームと頂点データストリームだけでもPCI Express x4/x8を通じて転送すれば、GPU間を接続するインターコネクトの帯域を無駄に消費しないで済む。共有される可能性の低いデータは直接各GPUに送ってしまう方が合理的だ。
NVIDIAのSLIでこれも疑問なのは、専用の物理リンクを使わない構成が可能かどうかだ。例えば、PCI Express x16ポートが2つあるチップセットが登場すれば、両GPUともに双方向で8GB/secのホストバス帯域を持たせることができる。PCI Express x16の場合、データの上りと下りが別レーンに分離されているため、チップセットへの上りのデータ量が増えても、下りの帯域は一切圧迫されない。そのため、PCI Express x16が2ポートあるなら、SLIの物理リンクを使わなくてもGPU間の広帯域データ交換が可能で、デュアルGPU構成にできるようにも見える。
しかし、NVIDIAはSLIはハード+ソフトのソリューションでは、ハイスピードデジタルインターフェイスを使うことを前提としているという。SLIでは、あくまでも専用デジタルリンクでGPU間のコミュニケーションを取るわけだ。
●2個以上のGPUの接続は?
NVIDIAがSLIでロードバランシングをフィーチャした理由のひとつは、オフラインレンダリングやさらにその先への適用も見据えているためだ。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、1台のシステムに多数のGPUを搭載したGPUサーバーの計画が進行中であることを明らかにしている。Kirk氏は、そうしたGPUサーバーでもSLIが使われる可能性を示唆する。
GPUサーバーの最初の用途は、オフラインレンダリングをGPU上で実現すること。NVIDIAは、そのためのソフトウェアベースとして「Gelato」と呼ぶプラットフォームを発表している。GelatoではGPU上でCG映画などの最終レンダリングをできるようにする。そのため、複数ノードに対して、スタティックなジョブ割り当てを行なう。つまり、NVIDIAのソリューションの中では、Gelatoがスタティックなロードバランシング、SLIがダイナミックなロードバランシングとなっている。
そのため、理論的にはNVIDIAは2段階でロードバランシングを構築できる。階層としてはGelatoがスタティックにジョブをGPUノードに割り当て、各GPUノード内でSLIがダイナミックに複数GPUに処理を割り当てることが可能になる。これは、GPUノードが個別のサーバーやワークステーションではなく、1台のGPUサーバーに多数のGPUノードが載った構成でも可能だろう。GPUノードはグルーチップとPCI Expressで接続し、各ノードはSLIで2個のGPUを搭載するといった構成も原理的には可能だ。
もっとも、以前レポートした通り、NVIDIAはSLIが理論上は8GPUまでの構成が可能だと説明する。デジタルリンクを使わないSLI構成も可能なら、PCI Express x16とデジタルリンクの組み合わせで、4個以上のマルチGPU構成も理論上はできる。しかし、デジタルリンクが必須なら、デジタルリンクで3個以上のGPUを接続できるようにする必要がある。高速伝送のためにはポイントツーポイント接続が必須であるため、2個以上のポートでデイジーチェーン接続が必要となる。例えば、CPUで、似たようなCPU間の直接接続を実現しているOpteronでは、最大3ポートのHyperTransportを備えている。
また、多数のGPUの接続を実現するためにはデジタルリンクにより広い帯域も必要となる。高速伝送のためには、ディファレンシャルクロッキングやエンベデッドクロックといったアプローチが必要になるが、現在のNVIDIAのデジタルリンクがそうした技術を採用しているかどうかは明らかにされていない。
デジタルリンクの技術と帯域のスケーラビリティは、おそらく、今後のSLIのカギとなる。GPUの性能は1年で2倍になるため、デジタルリンクも1年で大幅な帯域拡張が求められるからだ。ビデオカード間接続の場合は、コネクタが2つも(各カードに1カ所ずつ)あるため、コネクタが1つのチップセット-GPU間接続よりもやっかいだ。NVIDIAがどうやってこの問題を解決しようとしているのかは、まだ見えていない。
GPU間接続のデジタルリンクを備え、ロードバランシングもするようになり始めたGPU。ますますCPU的な方向へと向かい始めたように見える。しかし、実際には、まだ技術的な詳細では不明点が多い。
□関連記事
【8月23日】NVIDIA、“DOOM3 GPU”こと「GeForce 6600」発表会
http://pc.watch.impress.co.jp/docs/2004/0823/nvidia.htm
【8月14日】NVIDIA、SLI対応のGeForce 6600 GT
http://pc.watch.impress.co.jp/docs/2004/0814/nvidia.htm
【8月10日】NVIDIA、SLI対応ワークステーション向けGPU「Quadro FX 4400」
http://pc.watch.impress.co.jp/docs/2004/0810/nvidia.htm
【6月29日】【海外】NVIDIAがデュアルGPUソリューション「NVIDIA SLI」を発表
http://pc.watch.impress.co.jp/docs/2004/0629/kaigai099.htm
(2004年8月30日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.