 |


■後藤弘茂のWeekly海外ニュース■GeForce 6600登場で見えてきたGPU業界のトレンド |
●1年前のハイエンド製品をミッドレンジに
GeForce 6600(NV43)で、NVIDIAは公約通り1年前のハイエンドGPUの性能を、ミッドレンジGPUに持ってきた。1年間で、同じ価格帯のビデオカードは2倍の性能に上がったことになる。
しかし、そのためにNV43のトランジスタ数は1億4,300万と、ついにミッドレンジでも1億を突破した。ダイサイズ(半導体本体の面積)は推定150平方mm前後で、これも前世代のGeForce FX 5700(NV36)よりやや大きくなったと思われる。
NV43の登場により、半導体デバイスとして見た場合のGPUのトレンドは明確になってきた。
(1)GPUはハイエンド(エンスージアスト)が16ピクセルパイプ、ミッドレンジ(パフォーマンス)が8パイプ、メインストリーム&バリューが4パイプと構成が倍々になる3階層へと移行する。
(2)ダイサイズは、ハイエンドは天井知らずだが、ミッドレンジGPUが90~150平方mm程度、メインストリーム&バリューGPUが100平方mm以下を維持する。
(3)NVIDIAとATI TechnologiesのGPUのトランジスタ数の差がますます拡大する。
(4)微細化のペースは再び1年サイクルに戻りつつある。
これらのトレンドが示すのは、次のようなGPU業界の傾向だ。
(1)ハイエンドGPUとローエンドGPUの差がますます開く。
(2)ミッドレンジ以下のGPUが一定コストを維持する一方、ハイエンドGPUの高コスト化が進む。
(3)NVIDIAが熱設計やコスト面できつい状況がしばらくは継続される。
(4)GPUのハイペースの進化は来年以降も継続される。
●パイプライン構成がきれいに分かれたGPU階層
NV43の構成は、Vertex Shaderとジオメトリパイプが3、Pixel Shaderとピクセルパイプが8、メモリインターフェイスが128bit。これは、いずれも上位のGeForce 6800(NV40)系の基本構成の半分だ。乱暴に言えば、NV40を半分に切ったのがNV43となる。ATIが今秋に投入するミッドレンジGPU「RV410」も、ほぼ同じ構成だと見られており、この構成がトレンドと見られる。
一方、メインストリーム&バリューGPUは、ATIのRADEON X300(RV370)を見るとジオメトリ2、ピクセル4、メモリインターフェイスは64/128bitとなっている。つまり、NV43/RV410をさらに半分に切った構成だ。NVIDIAのNV44も似たようが構成が予想されており、これもトレンドだと推測される。
こうして見ると、2004年後半~2005年前半のGPUは、きれいな階層構成になりそうだ。基本的にはカテゴリが1段上がるとともに、実行パイプラインとメモリインターフェイス幅が倍々になっていくと推定される。並列性の強いグラフィックス処理を専門に行なうGPUの場合、パイプライン構成の差はイコール性能の差となる。そのため、パフォーマンスも、GPUコア毎にきれいな階層をなすことになる。
2003年後半のGPUは、ハイエンドが4~8ピクセルパイプ、ミッドレンジが4パイプ、メインストリーム&バリューが2~4パイプの構成だった。つまり、ピクセルパイプライン構成だけだと、ミッドレンジとその下の差別化がしにくかったことになる。それに対して、2004年後半のGPUはよりきれいな階層化がされることになる。その結果、パイプライン構成上は、ハイエンドGPUとメインストリーム&バリューGPUの差が広がることになる。
もっとも、実際には最終製品のパフォーマンス差は変わらない可能性が高い。GPUベンダーは市場を4カテゴリに分け、基本的には各カテゴリ間で2倍の3Dグラフィックス性能差が出るように構成している。そのため、GPUコアやメモリのクロックを調整して、性能とコストのバリエーションが生じるようにしている。
これを単純化すると次のようになる。GPUベンダーは、ハイエンドGPUの相対性能を800とすると、ミッドレンジは400、メインストリームは200、バリューは100以下になるように配置している。そのためにも、ミッドレンジGPUは8パイプ構成にする必要があったというわけだ。
実際には、市場の状況で変わるため、厳密にこのパフォーマンス構成が守られているわけではない。しかし、目安としては2倍間隔だ。
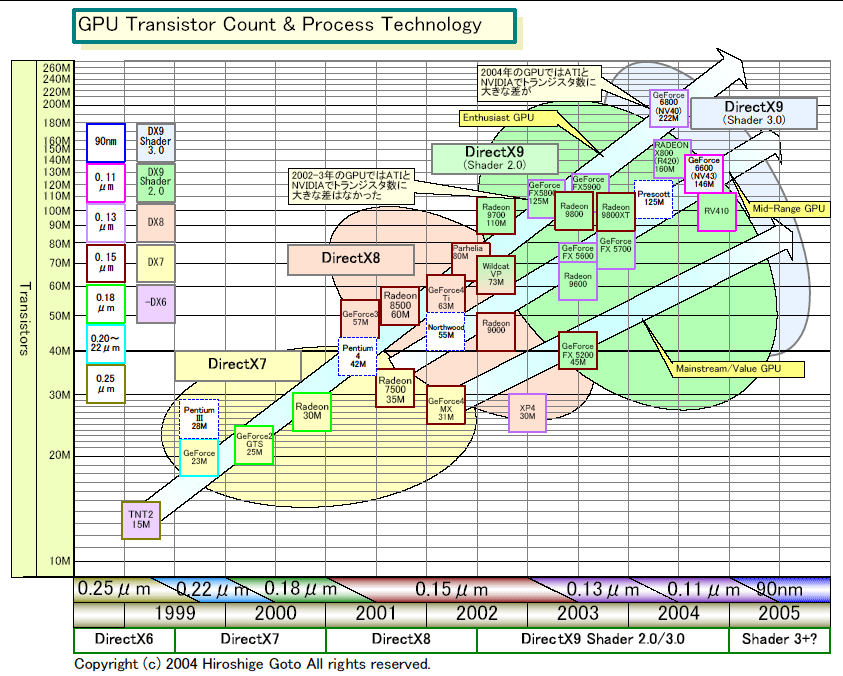
●ミッドレンジGPUは1億超のトランジスタ数に
NVIDIAは、ハイエンドのNV40では2億2,200万トランジスタを搭載した。そして、パイプラインを半分に削ったNV43ではトランジスタ数は1億4,600万となった。パイプが半分になったのだから、トランジスタ数も半減してよさそうだが、実際には約65%にしか減っていない。これは、半分になっていない部分もあるからだ。
例えば、NV43のビデオプロセッサは、逆にNV40より機能強化されている。さらに、NV40はAGPインターフェイスを内蔵しているが、NV43はPCI Express x16インターフェイスを内蔵する。PCI Expressでは、パラレル-シリアル変換が入るために回路規模が大きくなる。通常、ハイエンドGPUをミッドレンジ向けに半パイプにアレンジすると60%程度のトランジスタ数になるため、NV43の1億4600万は妥当なラインだ。
ちなみに、ATIの同クラスのGPU「RV410」も1億トランジスタを超えると見られる。つまり、ミッドレンジのGPUは、2003年の6,000~8,000万トランジスタ台から、1億~1億4,000万トランジスタレベルへと一気にトランジスタ数を増やしたわけだ。これは、4パイプから8パイプへと移行したことを考えると、妥当な数字だ。
また、2004年のミッドレンジGPUの構成は、2003年のハイエンドGPUに近いのだから、2003年のハイエンドGPUの1億1,000万~1億3,000万クラスのトランジスタ数になるのも当然だろう。
ただし、2003年と2004年では、トランジスタ数のトレンドで大きく異なる点もある。それは、ATIとNVIDIAの差だ。NVIDIAのNV4X世代はトランジスタ数が多い。フラッグシップ同士を比べると、NV40が2億2,200万トランジスタなのに対してRADEON X800(R420/423)は1億6,000万と発表されている。これは、ほぼ同じパイプライン構成で、NVIDIAの方が演算ユニットの内部演算精度を高めているためだ。つまり、同等のパイプライン構成の場合、NVIDIA GPUの方が、必ずATI GPUよりもトランジスタ数が多くなってしまうことになる。
ATIがShader 3.0サポートを避けた理由はここにある。Shader 3.0では、Pixel Shaderに32bit(128bit)精度が求められるからだ。ATIとNVIDIAの選択肢は3つあった。
(1)Shader 3.0をサポートする代わりに8パイプに止めてトランジスタ数を1億数千万にする
(2)16パイプにする代わりにShader 2.0に止めて1億6,000万トランジスタにする
(3)Shader 3.0をサポートし、さらに16パイプに拡張して2億数千万トランジスタにする
(1)の場合はパフォーマンスで水を開けられてしまう可能性がある、(2)の場合はアーキテクチャで先進性を維持できない、(3)は製造コストが跳ね上がってしまう。ATIの選択は手堅い(2)で、NVIDIAの選択はチャレンジングな(3)だった。NVIDIAは、そのツケを払う必要がある。
 |
| GPUトランジスタ数推定ロードマップ PDF版はこちら |
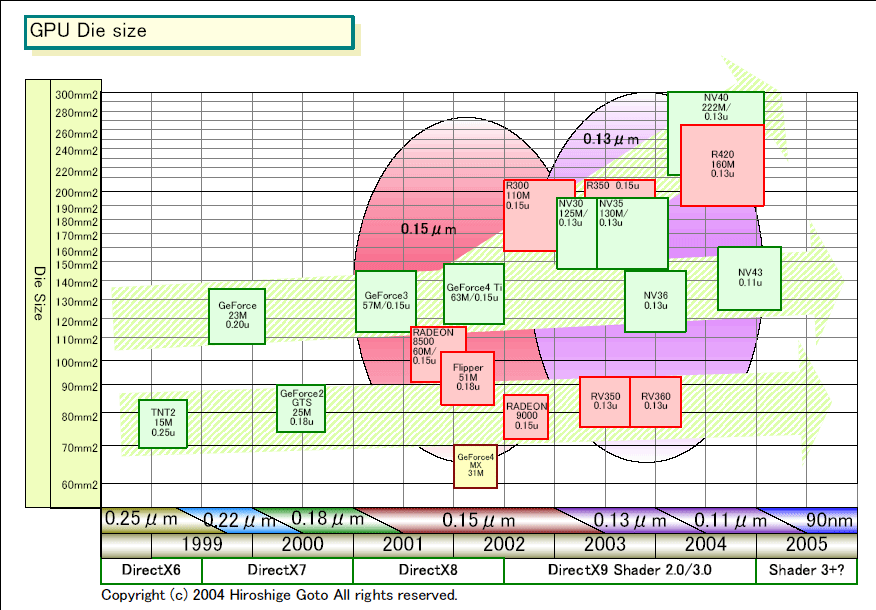
●0.11μmプロセスへの移行でダイサイズを維持
もっとも、プロセス技術の微細化によって、同じダイサイズのチップに搭載できるトランジスタ数は増えていく。2003年のミッドレンジは0.13μmプロセスで製造されていたが、2004年のミッドレンジは0.11μmプロセスへと移行しつつある。ATIのRV410も0.11μmだと見られている。
プロセスルールは1世代で約70数%に微細化する。リニアに70数%だから、面積にすると約50%に縮小することになる。つまり、同じトランジスタ数のGPUなら、1世代進んだプロセス技術で製造すれば半分のダイサイズになる。しかし、ハーフ世代では、その半分なのでリニアに80数%の縮小にしかならないし、そもそも、ハーフ世代の場合はそこまでも減らないケースが多い。
今回の場合はどうかというと、NV43はTSMCの0.11μm Low-kプロセスで製造される。同クラスの旧コアGeForce FX 5700(NV36)はIBMの0.13μmプロセスなので、プロセスノードからいくとハーフ世代へと微細化したわけだ。
しかし、ダイサイズは、NV36が140平方mm台だったのに対して、NV43は一回り大きい。まだ実チップで正確に測定ができていないので、写真からの見積もりだが150平方mmは軽く超えており、160平方mmクラスのようだ。同じミッドレンジGPUで、ダイがやや大きくなったのは、トランジスタが70%以上も増えたからだ。微細化で吸収できるのは計算上40数%なのに、それを超えたトランジスタをNVIDIAは積んだので大型化したわけだ。
それに、このクラスのダイサイズは、NVIDIAの歴史ではそれほど珍しくはない。じつは、NVIDIAのパフォーマンスクラスのGPUは初代GeForce 256(NV10)の頃から約130~150平方mm台のダイサイズだった。NV10→NV20(GeForce 3)→NV25(GeForce 4Ti)→NV36→NV43というNVIDIAの一連のGPUのダイサイズを比較すると、やや右肩上がりだが、それでもほぼ同一ライン上に並ぶことがわかる。
つまり、NVIDIAは、パフォーマンスGPUのダイについては、多少の増加はあっても同程度に抑え続けているのだ。130~160平方mmというのが、NVIDIAのパフォーマンスGPUのダイのターゲットサイズということになる。同様に、NVIDIAは、コストセンシティブなメインストリームGPUのダイサイズは100平方mm程度かそれ以下に抑えている。つまり、製造コスト自体は、この両ラインはそれほど増えていないことになる。
もっとも、ATIの場合はNVIDIAよりさらにダイサイズが小さい。チップ写真から判断すると、ATIのミッドレンジGPUはNVIDIAの同クラスより通常2回りほど小さい。同じファウンダリ(委託半導体製造メーカー)で同じプロセスを使っても、ATIの方がダイが小さい場合が多い。そのため、トランジスタ数がNV43より少ないと見られるRV410は、ダイサイズでも利点があると推定される。
 |
| GPUダイサイズ推定ロードマップ PDF版はこちら |
●無差別級のハイエンドGPU
NVIDIAのダイサイズの推移を見ると、GeForce FX 5800(NV30)以降の200~300平方mmクラスのダイサイズのGPUは、例外的に大きいことがわかる。これはATIも同じことで、両社ともミッドレンジ以下のGPUのダイサイズは抑えたままで、最上位のハイエンドGPUだけを突出して肥大化させつつある。ダイサイズの観点から言えば、今のミッドレンジGPUが、2年前までの最高峰クラスのGPUだ。
もっと正確に言えば、両社は、従来のパフォーマンスGPUとメインストリーム&バリューGPUに加えて、ハイエンドGPUという新しい枠を設けて、ダイサイズに制約をつけない新コアを開発し始めたことになる。従来のダイサイズの流れでいけば、本流はミッドレンジのNV43やR410であって、NV40やR423ではない。言ってみれば、従来は体重制限があるクラスしかなかったところへ、R300/NV30からは無差別級を新設したわけだ。
DirectX9以降の無茶苦茶な競争がなければ、まだ両社とも130~150平方mm程度のパフォーマンスGPUと、100平方mm以下のメインストリーム&バリューGPUの2コア態勢のままだったかもしれない。しかし、DirectX9で火がついたGPU戦争の結果、両社はダイを巨大化させ続けるハイエンドGPUを加えた3コア態勢へと移行したわけだ。
ハイエンドGPUのダイが肥大化する理由は簡単だ。プロセス技術上は2年に2倍のペースでしか搭載トランジスタ数が増えないのに、GPUメーカーは1年に2倍の性能向上を維持しようとしているからだ。1年に65~100%づつGPUのトランジスタ数を増やし続けるなら、プロセスの微細化は追いつかない。
では、GPUベンダーは無差別級ハイエンドについては今後もダイを巨大化させ続けるのだろうか。ATIのDavid E. Orton(デビッド・E・オートン)社長兼CEOはジョークを交えながら次のように答える。
「振り返ると、ATIとNVIDIAはここ数年、ダイサイズを増やし続けてきた。2002年には200平方mm台に達し、今日は250~300平方mmになりつつある。今後も増やし続けることができるのか、というのは当然の疑問だ(笑)。
我々はトライするだろうというのがその答えだ。それは、我々が現在の技術曲線(1年で2倍の性能アップ)を維持し続けようと考えているからだ。ただし、市場が価格面でそれに見合う動きをしなくなったら、話は違って来る。つまり、我々が(ダイを)大きくし続けようとしても、市場が動かなくなったら、それが自然の天井となるだろう。
もうひとつの自然の天井は、純粋に技術上のものだ。1枚のウェハから1個のダイも採れなくなったら、もちろん、それ以上はダイを大きくできない(笑)。それから、熱と(冷却機構の)ノイズも、もうひとつの天井だ。
我々は、トライし続けるが、実際には(ダイサイズの)リミットに近づいているとは思う。しかし、パフォーマンスと革新という面ではリミットはない」
つまり、ダイを巨大化しても経済的に見合う=それなりの高価格でハイエンドGPUが売れ続ける限りは、ダイを大きくし続けることができると考えているわけだ。また、ハイエンドGPUは、フラッグシップとしてソフトウェア開発者の支持をとりつけ、ブランドイメージを高める価値もある。さらに、オフラインレンダリングなど新しい市場も見えている。そうした背景を考えると、ダイを大きくしても見合うという論理は納得ができる。
●プロセスの移行は再びスムーズに
GPUの進化よりはペースが遅いものの、プロセス技術の微細化も、GPUの進歩を助ける。そして、プロセス技術の発展では、GPUに追い風が吹き始めている。
ファウンダリの製造プロセスの微細化は0.13μmでつまづいた。0.15μmまでは、ファウンダリは1年に1回のペースで微細化を続けてきた。つまり、2年に1回プロセス世代が刷新され、その間に1回ハーフ世代の微細化が入るというペースだ。例えば、フル世代の0.25μm→ハーフ世代の0.22/0.20μm→フル世代の0.18μmの移行は1年サイクルで進んだ。ところが、0.13μmの立ち上げに手こずったために、0.15μmから0.13μmへの移行には2年かかってしまった。そのため、今後、先端プロセスの導入ではファウンダリがどんどん立ち後れてゆく、という観測まで一時は出た。
だが、2003年前半にGPU量産が軌道に乗り始めた0.13μmに続いて、2004年前半から中盤には0.11μm版GPUの量産出荷が始まった。そして、2005年前半に量産出荷の90nm立ち上げも順調だと言われている(いずれもファウンダリ側の量産は6ヶ月前には可能になっている)。少なくともATIは2005年前半に90nmプロセスのGPU投入を予定している。つまり、0.13μm→0.11μm→90nmは1年サイクルで微細化が進む。つまづきは、0.13μmへの移行での1年のロスだけということになる。
ファウンダリの好調を受けて、GPUベンダー側も楽観的な見通しを立て始めた。
「何が起こったかというと、我々はムーアの法則がコンスタントなペースで続くものだと考えていた。しかし、実際にはそうではなかった。あるプロセスは移行がスムーズだが、あるプロセスは遅いといった違いがある。実際、0.13μmプロセスでは多くの変更項目があったために非常に難しかった。しかし、90nmプロセスは、それと比べるとずっと容易だ。90nmと65nmは、すでに開発が進んでいる。90nmプロセスはすでにFab(半導体工場)で製造に入っているし、65nmはプロトタイプ製造に入っている。だから、この2つのプロセスの移行は、ずっと近接したものになるだろう」と、今年5月にNVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は語っていた。
Kirk氏の予想のように、今後のプロセス移行がすんなり進むなら、GPUはさらにトランジスタを増やし、急ピッチな進化を続けることができるだろう。
□関連記事
【8月23日】NVIDIA、“DOOM3 GPU”こと「GeForce 6600」発表会
http://pc.watch.impress.co.jp/docs/2004/0823/nvidia.htm
【6月24日】【海外】GPU戦争の次のフェイズは“NV48対R480”
http://pc.watch.impress.co.jp/docs/2004/0624/kaigai097.htm
(2004年8月26日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.