 |


■多和田新也のニューアイテム診断室■
OCRソフト「読取革命 Ver.8」を試す |
スキャナなどを購入すると当たり前のように付属してくるソフトウェアの1つが「OCR」と呼ばれるものである。スキャナで読み込んだ画像データを読み取って“文字”を認識し、テキストデータに変換してくれるソフトウェアである。ところが、このOCR。どのぐらいの人が活用しているだろうか?
また、スキャナなどの付属ソフトではなく、パッケージとして販売されているOCRソフトを購入した経歴の持ち主となると、さらに少なくなるように思う。
実は筆者もスキャナ付属のOCRソフトは持っているものの、あまり活用していないユーザーの1人なのだが、今回、OCRソフトとして有名な、松下電器産業の「読取革命 Ver.8」を触る機会を得たのでレポートしてみたい。
●OCRソフトの使い道
 |
| 【写真1】松下電器産業の「読取革命 Ver.8」 |
今回試用する「読取革命 Ver.8」は、エー・アイ・ソフトの「読んde!!ココ」シリーズや、メディアドライブの「e.Typist」シリーズに並ぶ、パッケージ販売されているOCRソフトとしては3本の指に入る有名なソフトといって差し支えないだろう。
読取革命という名前の製品が初めて登場したのは、(ちょっと記憶があいまいなのだが)筆者がサラリーマンになりたての時期だったように思い出されるので、'97年前後ということになるだろうか。それから6~7年かけて熟成されてきたソフトということになる。
とはいえ、冒頭のとおり筆者は普段からOCRソフトというものを使っているわけではない。過去には何度か触る機会もあったのだが、思い通りの識字をしてくれず閉口することのほうが多かったからだ。
また、そもそもOCRソフトを必要としていない、という理由も挙げられる。例えば、メモ代わりにデジカメで写真を撮ったとしたら、その画像データのまま利用しており、それで何ら不都合を感じていないからだ。
ビジネスユースであれば、FAXで送られた資料をスキャンして文字データに変換し再編集、などのシチュエーションも考えられ、多用している人も多いと思うが、個人ユースであれば、OCRソフトを必要とするシチュエーションはあまりないと思われる。
このように、OCRソフトに対してはポジティブな印象を持っていなかったのだが、この読取革命を使ってみる気になったのは、製品資料にあった「識字率:98.6%」という数字を見たからというのが1点。また、デジカメで撮ったスナップなどを識字して、テキストデータ化し活用する、という新しい使い方を提案しているというのも興味を引かれた。
先ほども述べたとおり、現在筆者は、デジカメで撮影したメモを画像データとして参照・活用している状態である。しかし、量が多くなると、どの写真にどんなデータが書かれているか分からなくなる。その点において、“検索”というテキストデータならではの便利な機能を使えるというメリットも見逃せないのである。
そこで、個人用途も意識しつつ、デジカメ画像のテキストデータ化がどの程度手軽に、そして現実的に行なえるかをチェックしてみることにする。
●A4ドキュメントのテキストデータ化をチェック
OCRソフトのニーズを考えた場合、ビジネス文書のテキスト化というのは見逃せない。と書くとちょっと堅い印象を受けてしまうかもしれないが、会議などで見せられた書類をメモ代わりに撮影し、それをテキストデータ化する、といった用途を考えると分かりやすい。
要するに、紙に印刷された文書を撮影するということだが、これは個人用途でも十分にあり得るシチュエーションだ。例えば、駅や電車内などの広告で気になる部分を撮影。それをテキストデータに変換して、スケジューラなりメモ帳などに貼り付けておくという使い方だ。
 |
| 【画面1】読取革命 Ver.8を起動した直後。まずは入門ウィザードが実行される |
また、紙に限った話ではなく、電車の時刻表などの看板の類でも活用できる。電車の時刻表を携帯電話のデジカメ機能で撮影したとしても、液晶画面は解像度が低いことで一覧性には欠ける。これをテキストデータにしておけば使いやすさは増す。
そこで、こうした用途も意識して、文字と図版を含むカラー印刷原稿をデジカメで撮影して、それをテキストデータ化する作業を試してみることにしたい。サンプルは読取革命 Ver.8のカタログの2ページ目を利用している。
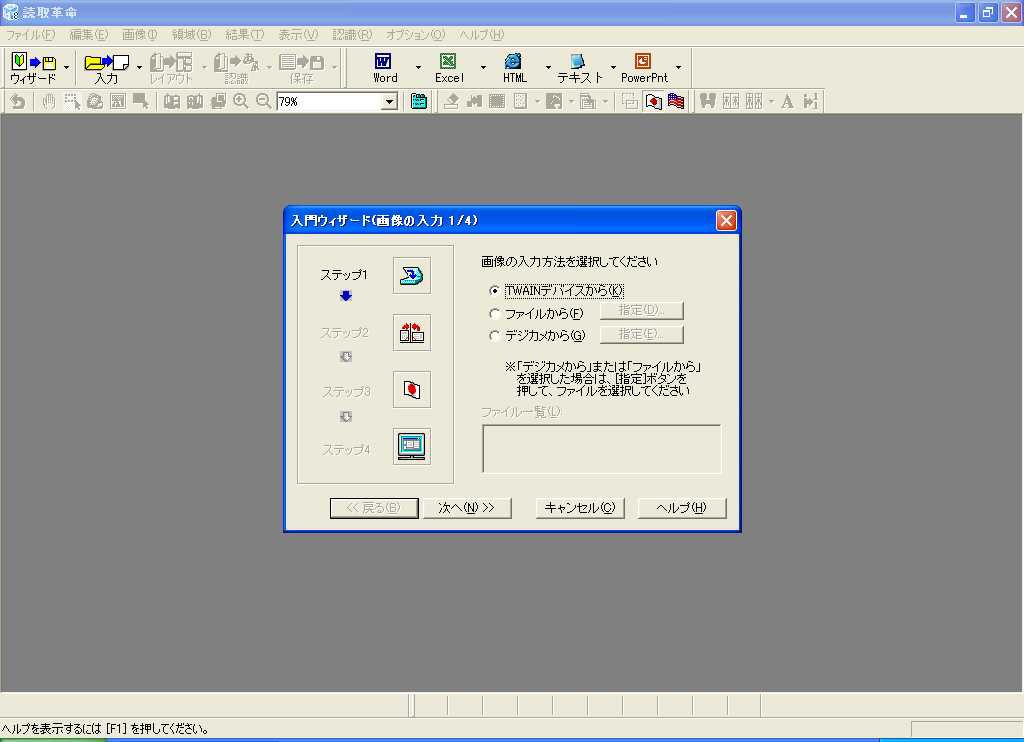
実際に識字テストを行なうまえに、簡単に読取革命 Ver.8の使い方を紹介しておこう。まず起動すると表れるのが画面1で、ここから入門ウィザードという機能を利用することができる。この機能を使うと、
1. 入力ソースの選択(画面2)
2. 画像の回転や補正方法の選択(画面3)
3. 原稿の言語種別選択(画面4)
4. 必要に応じて出力先アプリケーションの選択(画面5)
の4ステップを踏むだけで、自動的に識字が始まる。デジカメ写真の向きや色の補正を自動的に行なってくれるのは非常に便利である。ただ、これがどの程度あてになるかは気になるところである。
 |
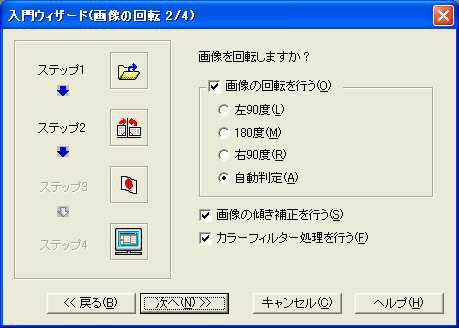 |
| 【画面2】ウィザードのステップ1。画像の入力元を選択する。画像ファイルの場合もここで指定する | 【画面3】ウィザードのステップ2。画像の補正に関する指定。回転の自動判定やカラー補正などを自動で行なってくれるのは便利 |
 |
 |
| 【画面4】ウィザードのステップ3。認識する原稿の種類。こうした選択肢があるということは、おそらく英語と日本語で認識エンジンを切り替えているものと思われる | 【画面5】ウィザードのステップ4。認識結果の出力先の指定。結果を画面表示するだけでなく、Microsoft OfficeアプリケーションやAdobe Acrobatなどに転送することもできるのだ(もちろんこうしたアプリケーションがインストールされた環境でしか利用できない) |
 |
| 【写真2】読取革命 Ver.8のカタログ。白地に黒という普通の文字データやカラーの図版などを含むサンプルである |
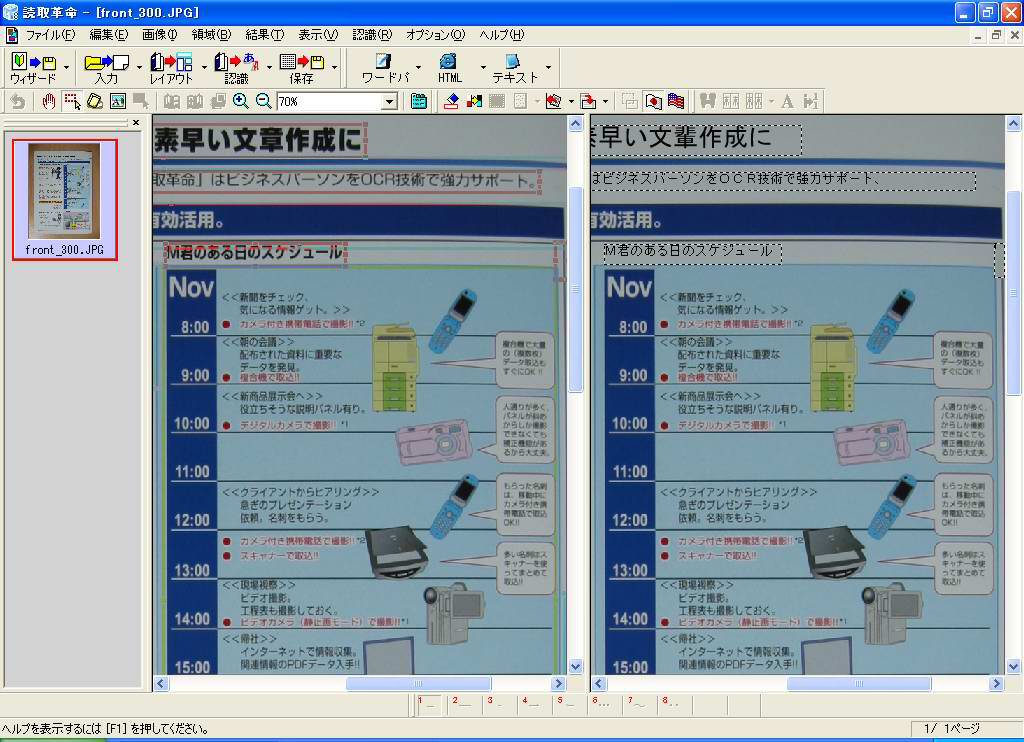
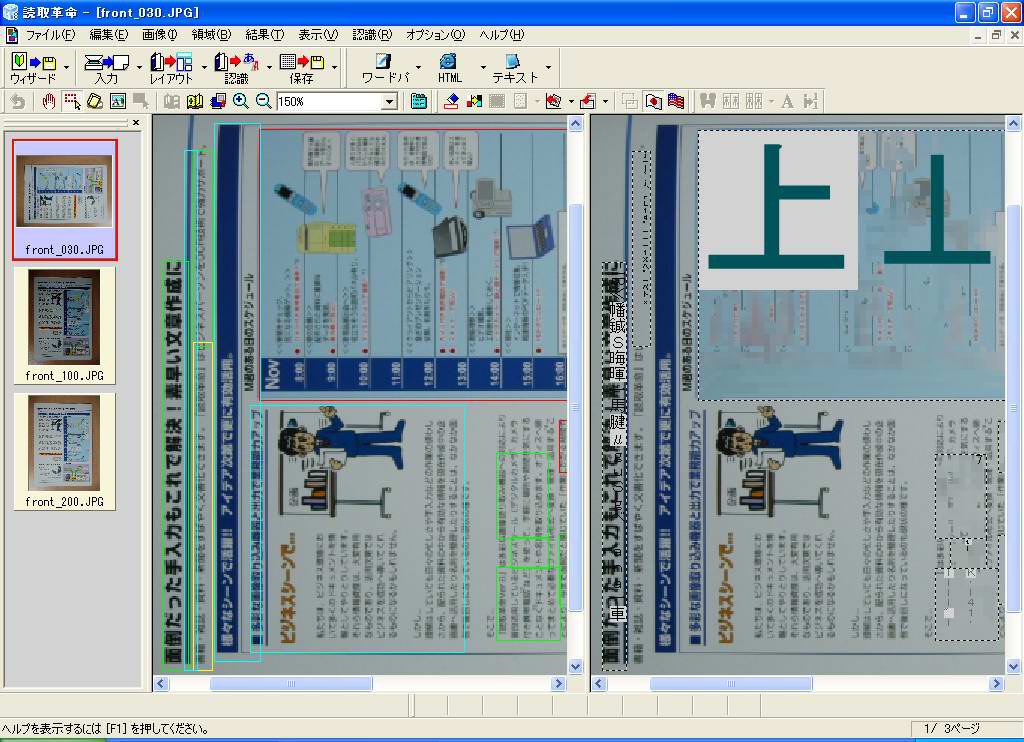
とりあえず、このウィザードを使って300万画素デジカメで撮影したデータ(写真2、元データは2,048×1,536ドット)を認識させてみた結果が(画面6~8)である。
まず、それを時計回りに正しく回転できている点は評価できる。文字の向きを正しく捕らえられている証拠だ。認識にかかる時間に関しては、画像の回転や補正、認識まですべて含めて5~6秒程度であり、いっさいストレスは感じない。
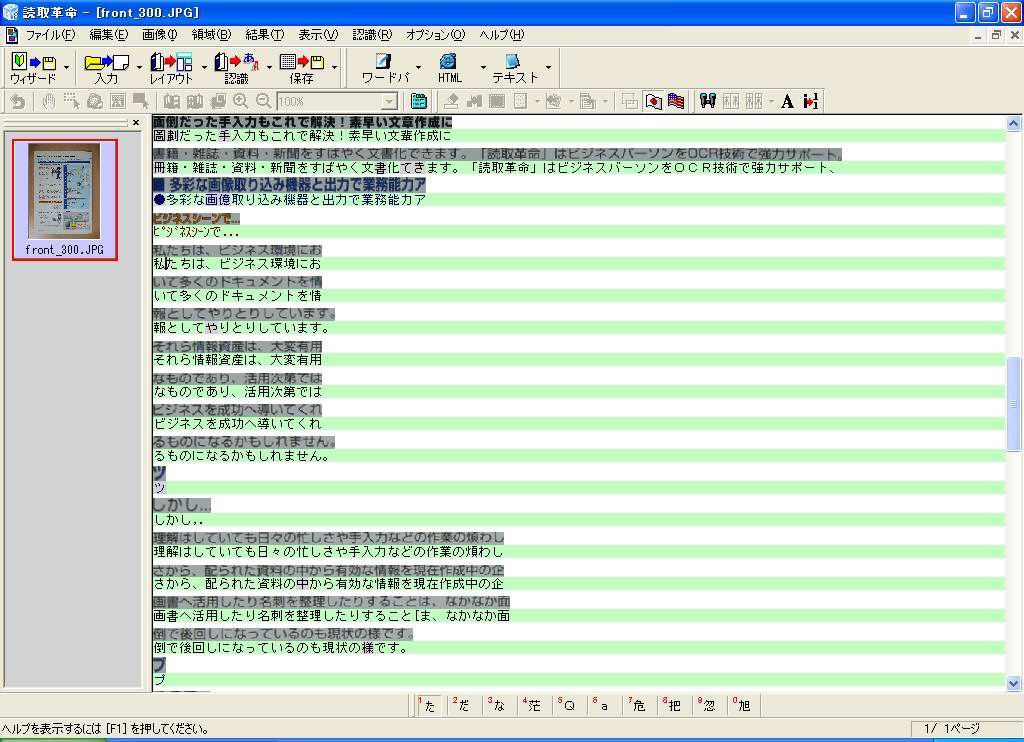
肝心の文字の認識は、というと画面6のように白地に黒文字というごく一般的な文字データに関してはかなり高い識字率である。そうした条件の部分だけなら識字率が95%を超えており、ここまで認識してくれれば「あとは手動で直そうかな」という気にさせてくれる。
ただ、画面6内の青地の白抜き部分の個所、画面7のように青地に黒文字と図版が混じるような個所だと文字データを認識せずに“すべて図版”と解釈してしまっている。また、画面8のように完全な図版の個所については、どっちつかずの結果になってしまっている。
「文字である」と認識すれば高い識字率を発揮するが、そこの判断力がやや不足している感がある。とはいえこの結果は、今回のサンプルであるカタログのように図版が多い文書だと不利なのは確かだが、文字だけで構成される典型的なビジネス文書であれば十分に実用的であることを示している。
ちなみに、誤認識した部分の修正に際しては、表示方法が複数パターン用意されており便利である。1つは(画面6~8)で示したような、実際の画像の上に認識したテキストデータを重ね合わせる表示方法で、「カラーリアル表示」と名付けられている。
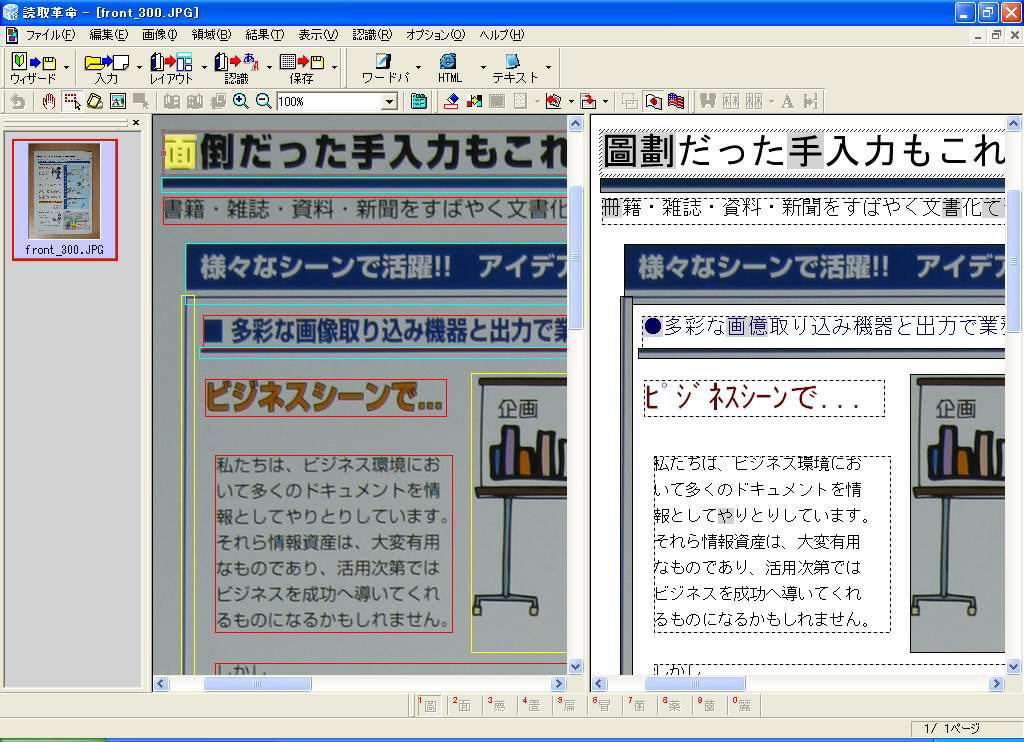
そのほか、「ハイパーチェッカー」呼ばれる元画像とテキストを上下に並べて表示するパターン(画面9)、実際のレイアウトに沿ってテキストデータや画像、図などを配置するパターン(画面10)、テキストだけを抽出したパターン(画面11)が用意されている。
また、画面11でも分かるように、テキストデータのカーソル位置に合わせて、どの部分を認識した結果かを元画像の文字部分を反転表示してくれるのも分かりやすい。
 |
 |
 |
| 【画面6】300万画素相当のデータを認識させた結果。白地に黒文字という部分はかなり高い識字率である。青地に白抜きという部分は文字としてすら認識しなかった | 【画面7】文字量は多いが、青地のために図版的イメージとなっている個所は文字として認識されていない | 【画面8】完全に図版の部分は判断に迷っているのか、文字として認識した部分と図版扱いとなった部分が中途半端な結果に |
 |
 |
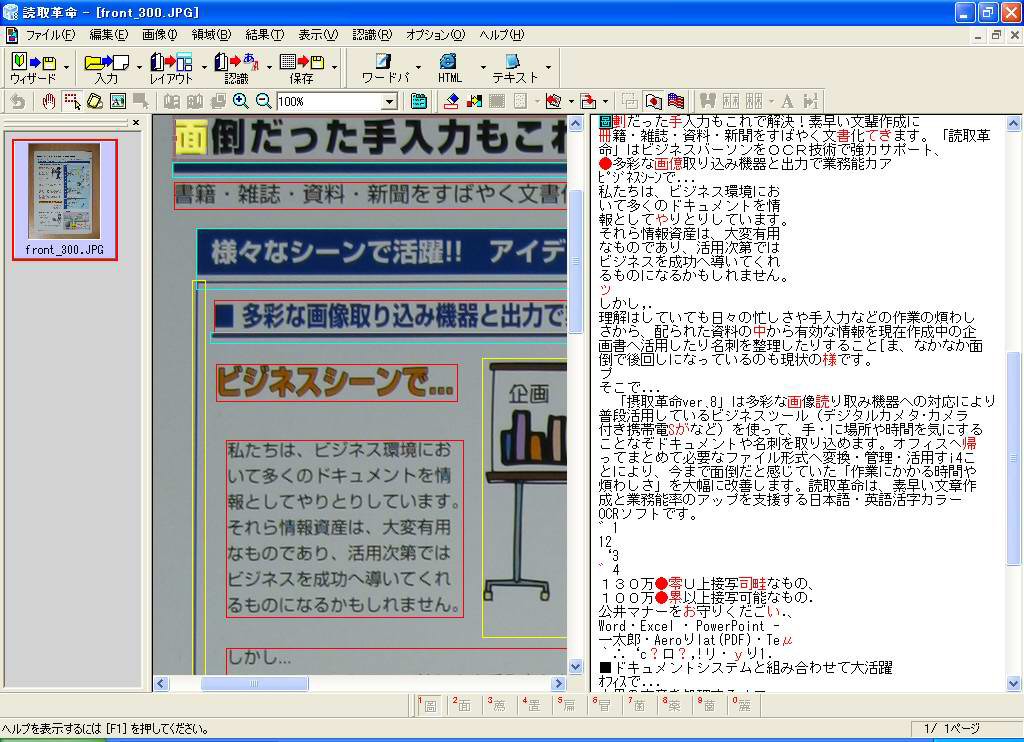 |
| 【画面9】これは「ハイパーチェッカー」と呼ばれるパターン。上段に元画像、下段に識字結果、という並びで表示され比較がしやすい。ビジネス文書などで活躍しそうな表示方式である | 【画面10】「領域表示」と呼ばれる表示方法で、元画像のレイアウトに沿って、認識結果を切り貼りしてくれるパターンである | 【画面11】「テキスト表示」と呼ばれるパターンで、テキストだけを抽出している |
さて、本製品のカタログによると、デジカメデータの読み取りに関して、「デジカメで130万画素以上、カメラ付きケータイで100万画素以上で、接写ができるもの」という条件がつけられている。先のテストでは、300万画素デジカメのデータを使っているので条件に合致しているが、カメラ付きケータイなどで使うことを考えると、もっと低い解像度でもテストしておく必要がある。
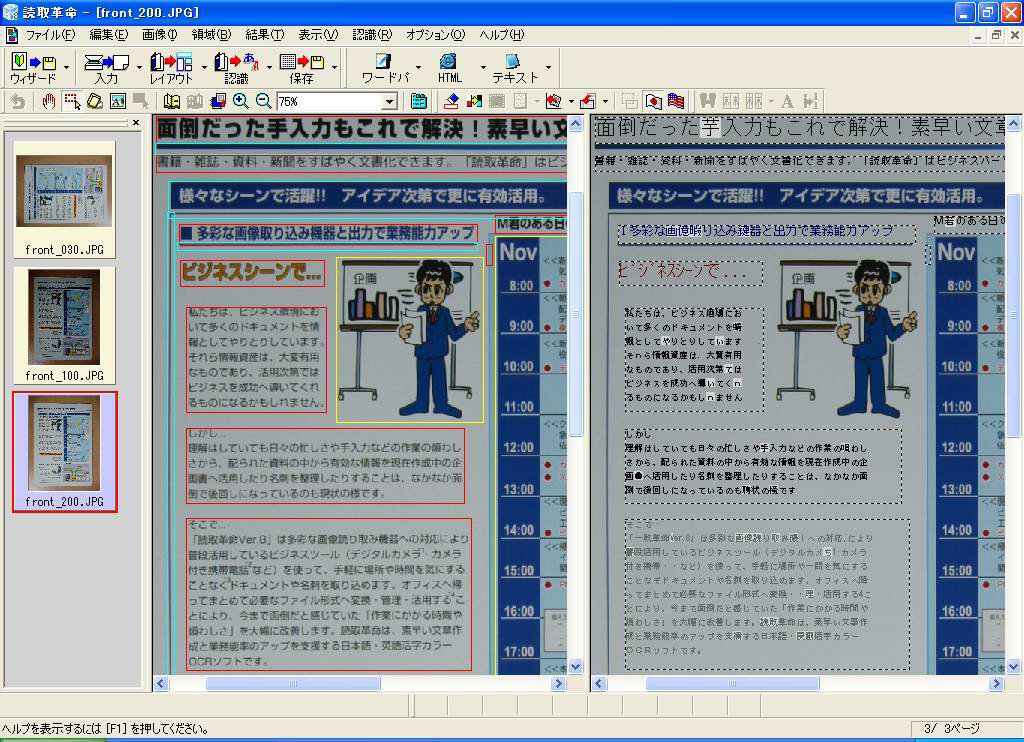
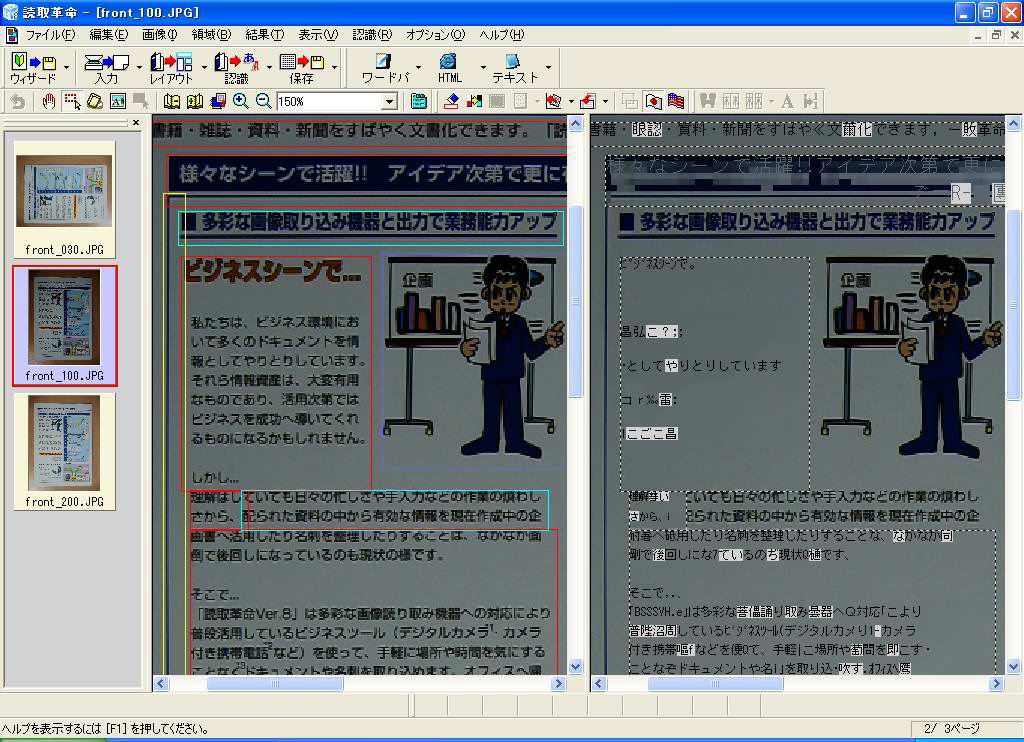
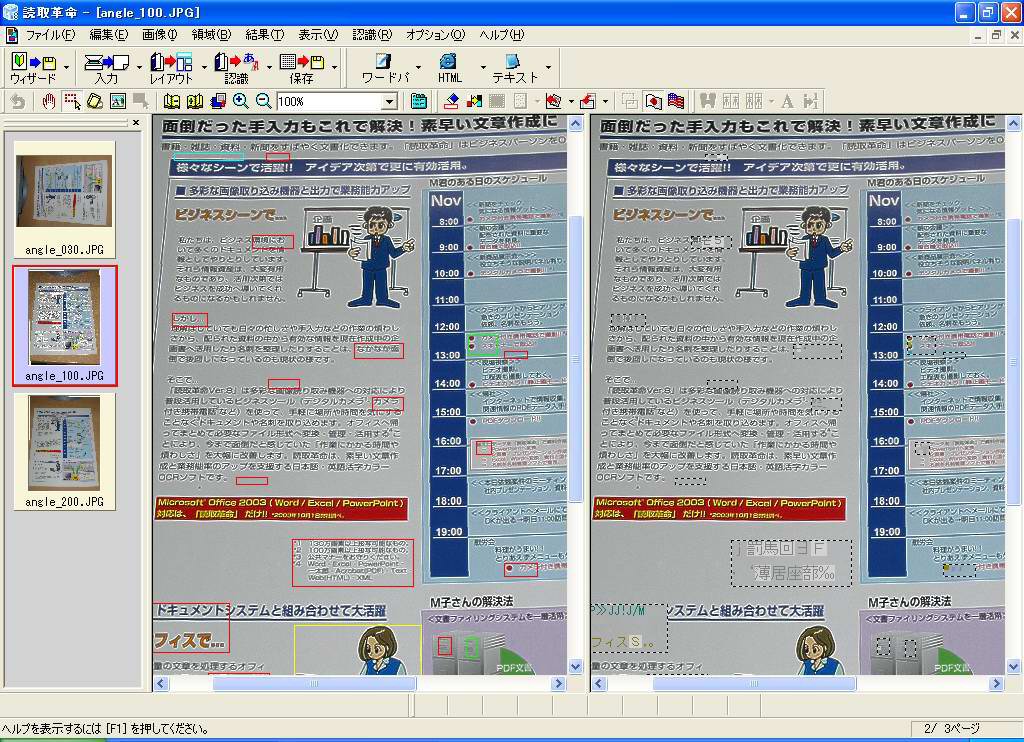
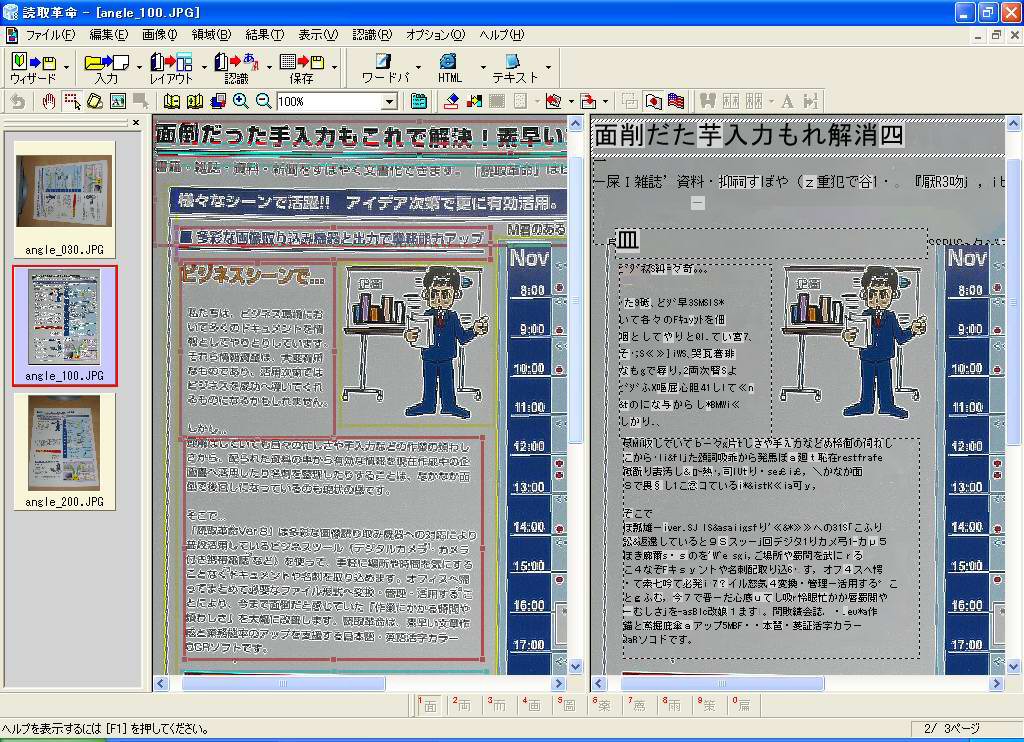
そこで、200万画素相当(1,600×1,200ドット)、100万画素相当(1,024×768ドット)、30万画素相当(640×480ドット)で、同カタログを撮影し、認識させてみることにした。結果は画面12~14に示したとおりで、いずれのデータも先に紹介したウィザードを実行して、自動的に認識させた結果である。
 |
 |
 |
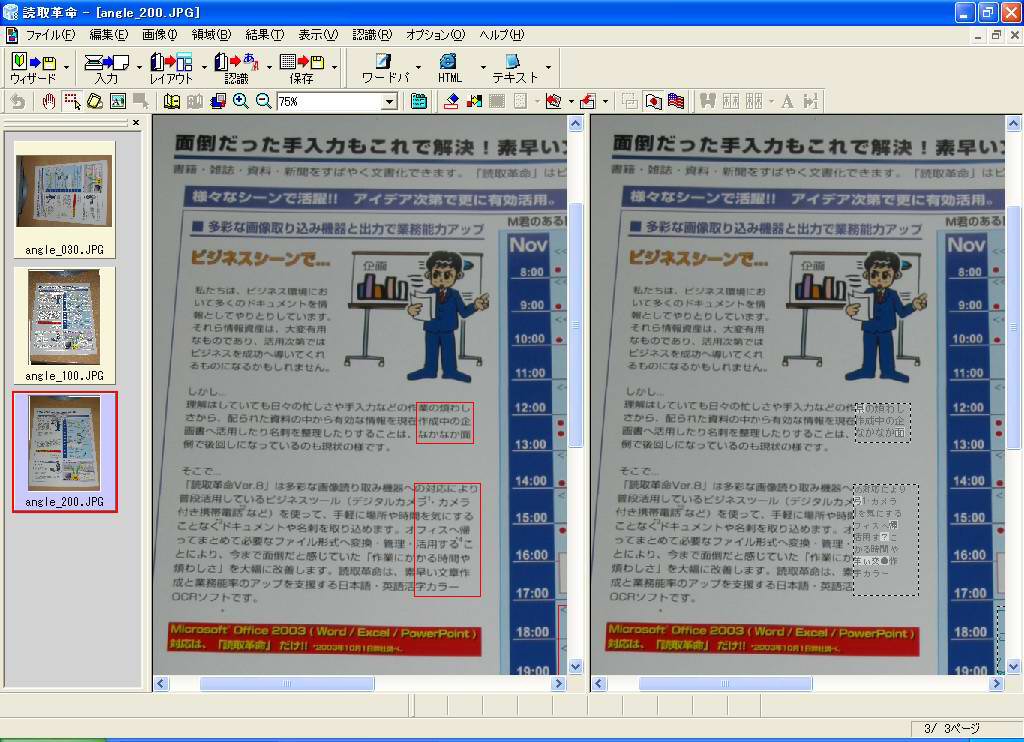
| 【画面12】200万画素相当のデータを認識させた結果。一部に不可解な識字が見られるものの、かなり正確に認識できている | 【画面13】100万画素相当のデータを認識させた結果。これだけ白抜き文字を正しく認識できているあたりは不思議だが、トータルで見るともう少し識字率が上がってくれるとうれしいところ | 【画面14】30万画素相当のデータを認識させた結果。これは向きの判断を正しく行なえず、一切の識字ができていない。ただし、これはメーカーの要求スペック以下のサイズなので致し方ないところ |
まず200万画素のデータについて見てみると、300万画素にはやや劣るものの、かなり高い識字率で、白地に黒文字という文字部分だけを見れば90%を超える識字率を発揮した。これなら十分だろう。
ただ、100万画素になると一気に認識率が下がる。ちなみにこの結果だけ写真が暗く見えるが、この補正も読取革命側で行なったもので、元データはすべて同じ露出で撮影してある。文字部分の識字率を見ても、60~70%程度といったところ。このぐらいの識字率だと、直そうと思うか、直す気をなくすかが人によって分かれそうである。
30万画素のデータに関しては、写真の向きすら判定できていない。つまり、文字を認識できないために、文字の向きを判定できないことになる。
100万画素相当がもう少し頑張ってほしい印象はあるものの、おおよそカタログにうたわれている100/130万画素デジカメクラスがギリギリ使えるかなという感じではある。ただ、これは単純にデジカメの画素数で判断できるものではない。例えばビジネス文書ではA4やB5サイズの用紙が使われることが多いが、ちょっとした資料だと、それを半分に裁断して見せられることもあるだろう。逆にもっと大きなサイズの文書もある。
つまり、認識率を左右するのは、「1文字当たりの解像度」である点に留意しなければならない。ちなみに、今回のカタログでもっとも多い文字のサイズである、「私たちは~」で始まる文章の一文字当たりの解像度はおよそ、
300万画素:17×17ドット
200万画素:14×14ドット
100万画素:9×9ドット
30万画素:6×6ドット
である。先の結果から100万画素でもう一頑張り欲しいと思ったわけだから、分かりやすさも考慮して10ドット以上が識字率をアップさせるための最低ラインと考えてみよう。30万画素の横方向の解像度は640ドット。10ドットの文字なら64文字分ということになるが、文字間などもあるので、横方向の文字数は50文字程度が無難なところといえる。撮影時に液晶モニタで確認し、この文字数までに抑えるよう撮影しておけば、OCRで利用するさいに高い識字率を期待できることになる。
もちろん「接写に強い製品」という条件はつくだろうが、必要な部分だけをメモするという用途なら、30万画素クラスのデジカメも出番があるというわけだ。
●歪んだデータを正す長方形化機能
 |
| 【写真3】先のカタログを斜めから撮影したカット |
さて、先のサンプルは(目視によるものなので多少のズレはあるが)、正面から撮影したデータを認識させている。しかし、どんなシチュエーションでも正面から撮影できるとは限らない。例えば、ストロボを発光させないと露出が足りないような場合、紙質によっては正面だとストロボが反射してしまうので、少し斜めから撮影して避ける場合もある。
そんな斜めから撮影したデータだと、文字も歪んでしまい識字率が下がることが予想されるが、読取革命 Ver.8にはこの点に配慮した機能が搭載されている。
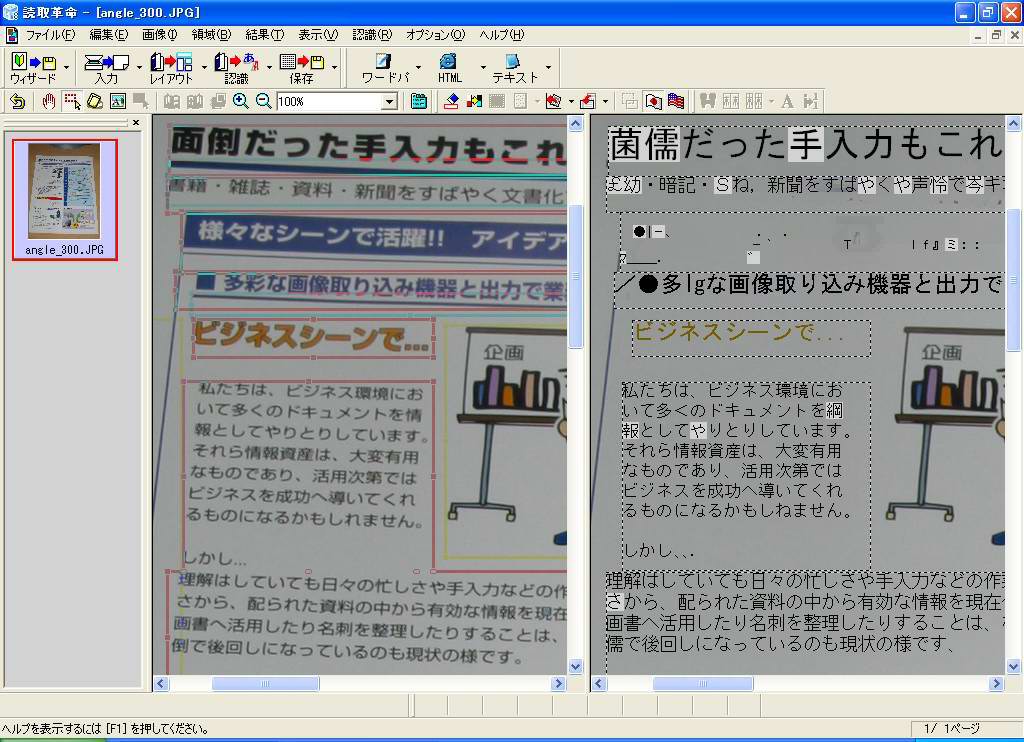
まず、先のカタログを写真3のように斜めから撮影した場合、どのように認識されるかというと、画面15のようになる。これは300万画素相当で撮影しており、これでも十分なほど正しく認識できているが、やはり正面から撮ったときよりは識字率が落ちている。
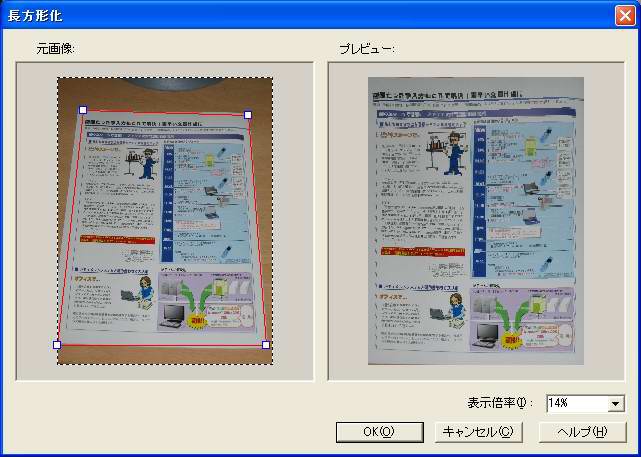
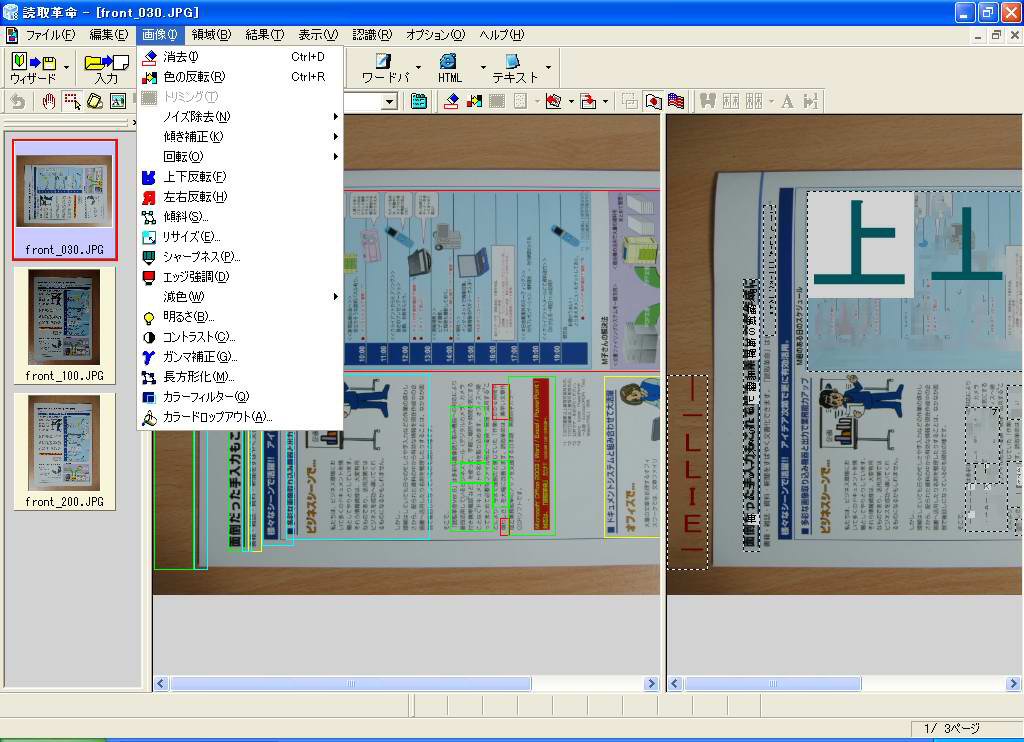
そこで、登場するのが本製品の長方形化機能だ。四角形の頂点としたい個所を指定することで、画像の歪みを修正できるツールである(画面16)。
歪みを修正したのちに認識させた結果が画面17だ。誤認識が完全になくなったわけでないのと、歪んだ状態でも高い識字率だったせいで「劇的」な感じはしないが、正確さは増していることが分かるだろう。
 |
 |
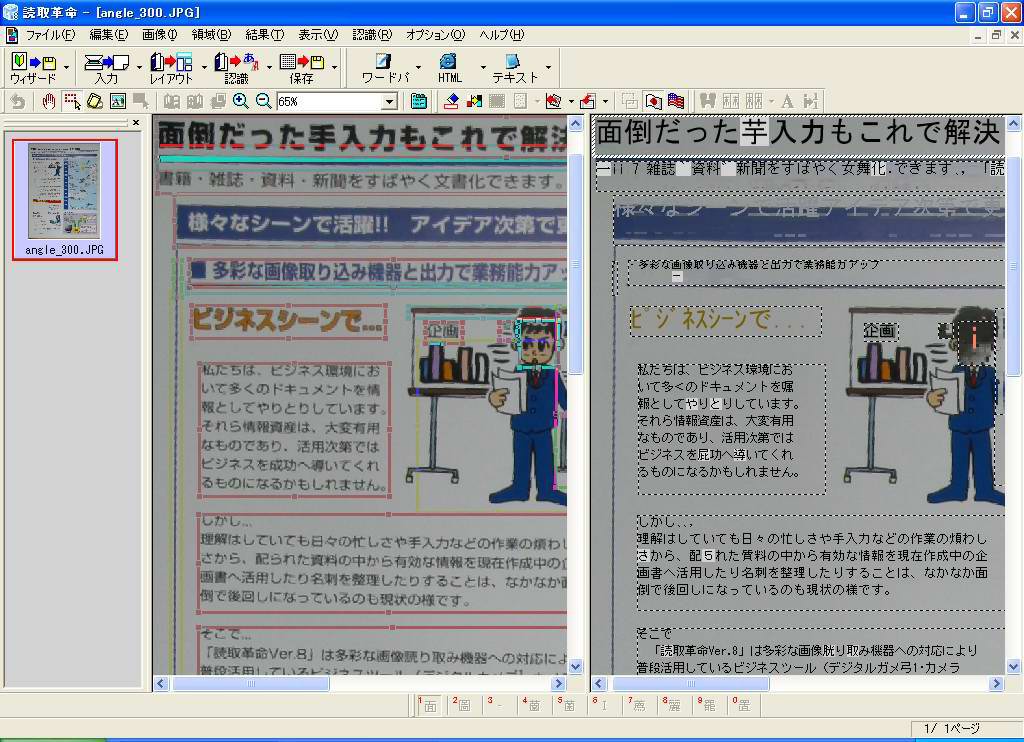 |
| 【画面15】300万画素相当のデータを認識させてみたが、向きも正しく回転されているし、識字率もかなり高い。これでも十分と感じる人は多いだろう | 【画面16】本製品の「長方形化ツール」。頂点位置を指定して、その頂点を持つ長方形となるように画像を変形させることで歪みを修正する | 【画面17】修正後の結果。文字部分の認識率は確実に向上している。イラストに書かれている男性の顔を文字と認識したのは不思議(これはこれで愛嬌も感じるが) |
さらに顕著に効果が表れたのは、低い解像度で撮影した場合だ。画面18~19が200万画素相当、画面20~21が100万画素相当の認識結果であるが、こちらは歪んだ状態ではほとんど識字できていないのに対し、長方形化ツールを使って歪みを正した途端に一気に識字率が向上している。
歪みを補正するツールは、レタッチソフトでは珍しい機能ではないのだが、いちいちレタッチソフトを起動して補正をかけ、OCRソフトを起動しなおすのも面倒な作業である。本製品には、このほかにも多くの画像補正機能を持っており、シャープネスやエッジ強調などで文字部分を浮き立たせたりといったこともできるようになっている。さらにウィザードを使うと、このあたりの機能は自動的に実行されることもあるので手軽だ。
 |
 |
| 【画面18】200万画素相当のデータ。紙面中央より部分の一部は正しく認識できたが、それ以外は文字としてすら認識しない | 【画面19】長方形化ツールによる修正後の認識結果。画面18と比較しても大幅に識字率が向上。太字部分などは若干誤認識が多いものの、約80%の識字率であった |
 |
 |
| 【画面20】100万画素相当のデータ。文字として認識した部分の識字も、ほとんど正しくできていない | 【画面21】修正後の認識結果。先の正面から撮影したカットに比べると識字率は劣っているものの、長方形化ツールの効果ははっきり出ている |
 |
|
| 【画面22】本製品の画像補正メニュー。ちょっとしたレタッチソフト並みの充実度である |
●スキャナによる読み込みでも同様の傾向
さて、ここまでデジカメ画像の読み取りを試してきたが、最初のテストのところで触れたように、青地に白抜きの文字や、図版部分の文字の認識がイマイチである。これは、デジカメデータだからなのか、もしくは読取革命 Ver.8自体が苦手としているのか、ちょっと試しておきたい。
そこで、同じカタログデータをフラットベッドスキャナを使って読み取り、そのデータを認識させてみたい。スキャナによる読み取り解像度は300dpiに設定している。
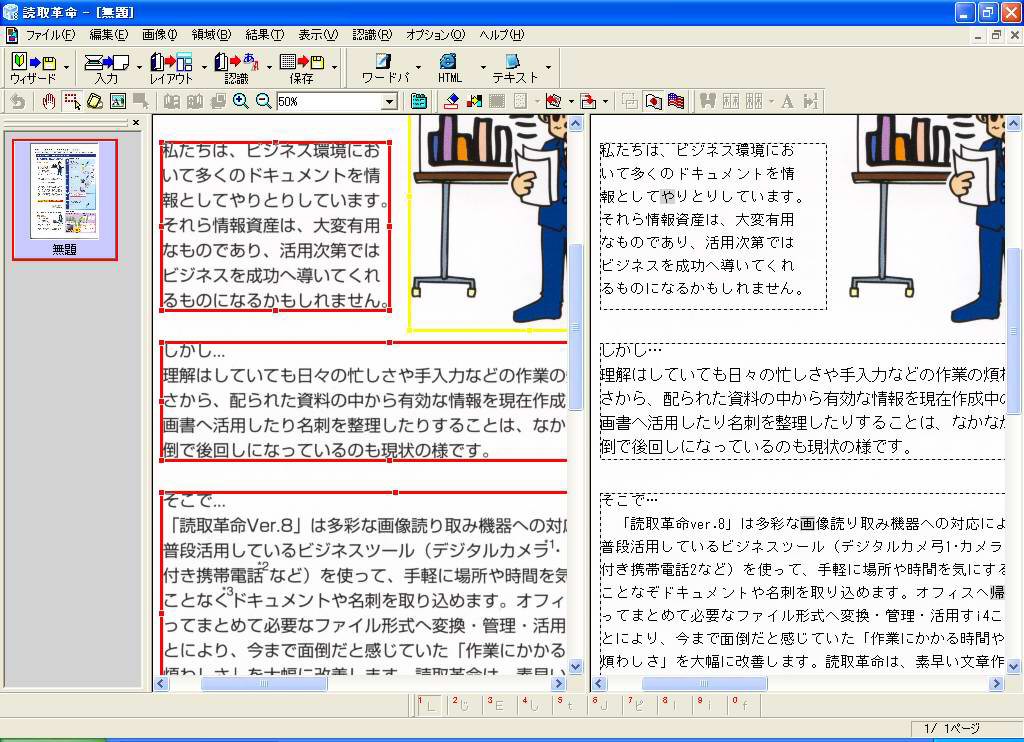
その認識結果を部分ごとに見ていこう。まず画面23だが、青地に白抜き文字の部分や、オレンジ色の修飾文字部分での誤認識が見られる。デジカメ画像の認識でも見られた誤認識だが、スキャナによる品質の高いデータであっても傾向は変わらない。
画面24に示した、白地に黒文字、つまり一般的な文字部分はカンペキである。この条件の個所だけであれば100%の識字率を発揮しており、ビジネス文書をスキャナで読み取れるシチュエーションでは文句なしの性能を見せるだろう。
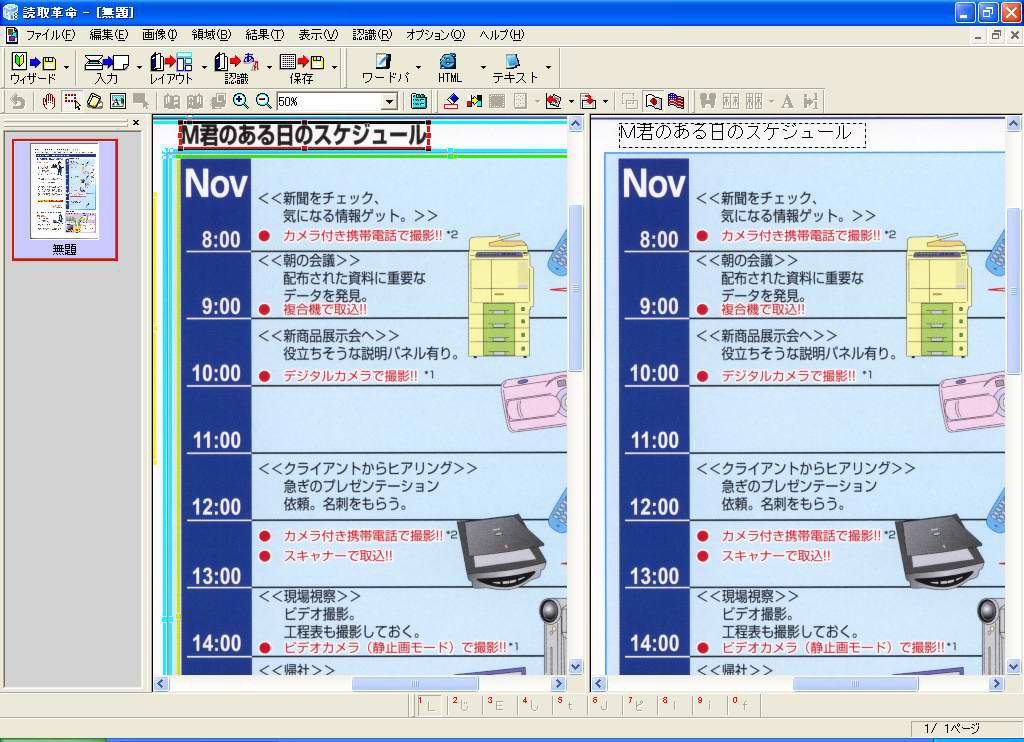
続く画面25は、図版のような印象を持つ青地に黒文字の部分だ。ここもデジカメ画像と同じ傾向で、やはり全体を1つの図版として認識してしまった。
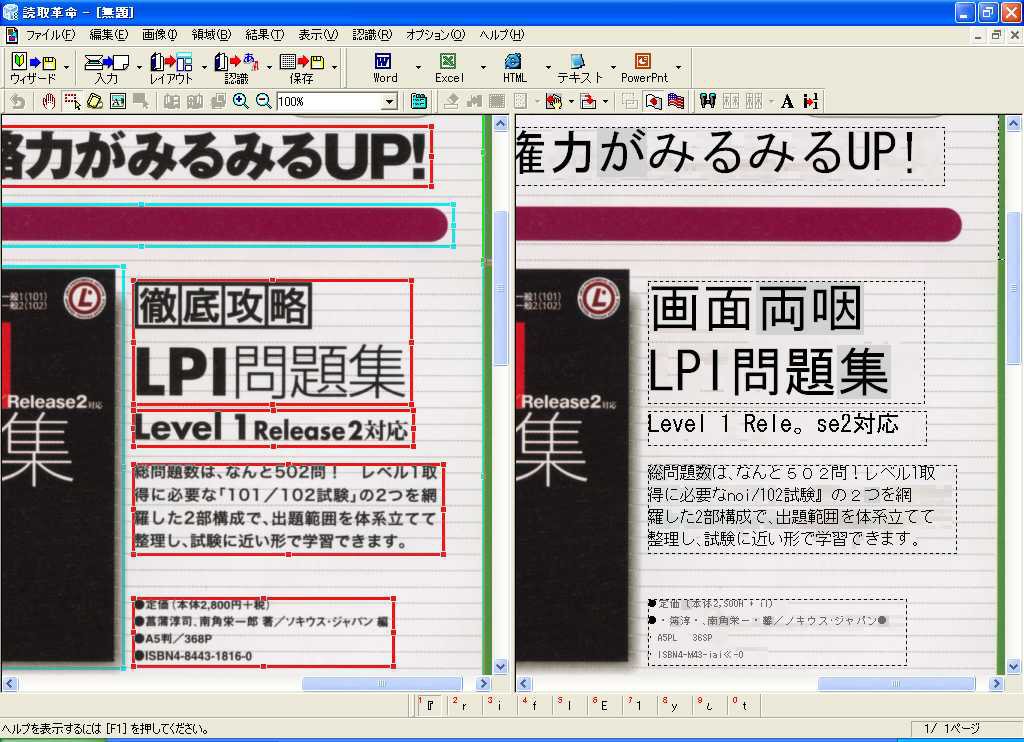
画面26は文字を含む図版だ。ここもデジカメ画像同様に、文字として認識した部分と、図版として認識した部分が入り混じる中途半端な状態になってしまった。さらに、普通の文字であれば正しく認識できているものの、白抜き文字のように修飾された文字は非常に識字率が低いのも気になる点だ
画面25の部分は文字として認識して欲しいし、画面26は全体を1つの図版として認識されても構わない、といった人間の持つイメージとはかけ離れた結果が出る傾向は、ちょっと残念である。
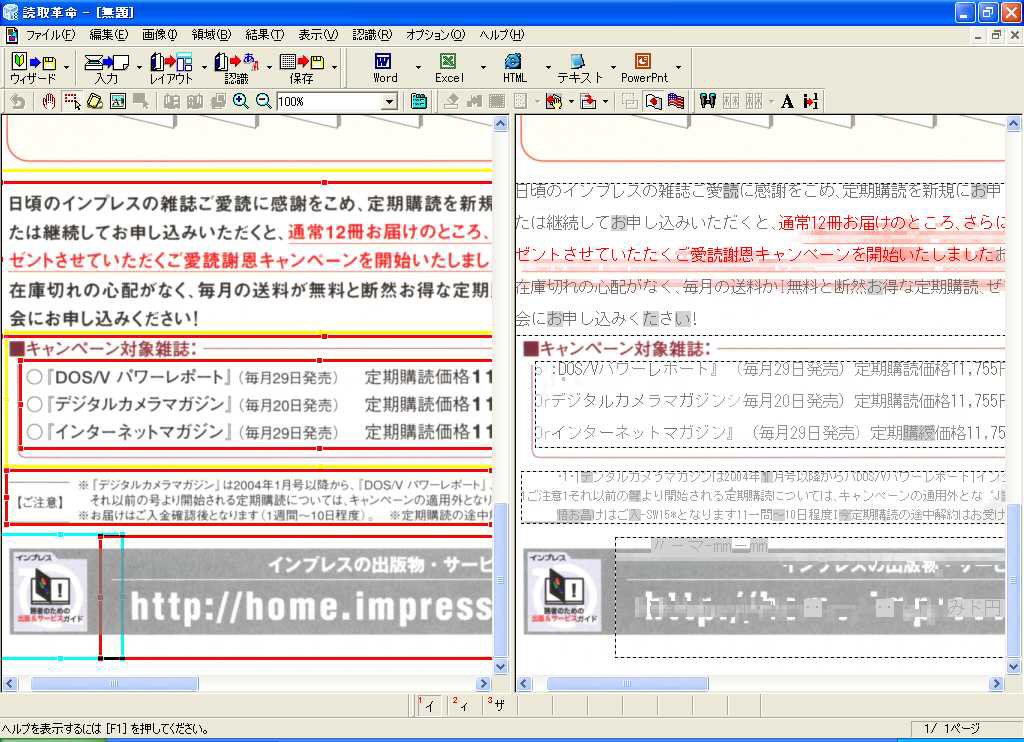
また、修飾された文字に関しては、そのほかにもいくつか試してみたが、かなり苦手なようである(画面27、28)。書体自体がゴシックや明朝といった一般的なものであっても、派手な修飾が入ると途端に認識率が落ちるのは、本製品の特性のようだ。
 |
 |
 |
| 【画面23】デジカメ画像の認識結果サンプルでも多用した冒頭部分。白抜き文字を図版として認識したり、縁取りされたオレンジ色の文字の誤認識が見られる傾向はデジカメと変わらない | 【画面24】白地に黒文字という典型的な文字部分では、実に100%の識字率である。これは見事であった | 【画面25】この部分もデジカメ画像と傾向が変わらない。普通の黒文字なのだが、青地部分全体を1つの図版として認識してしまう |
 |
 |
 |
| 【画面26】こちらは文字と図版の認識が入り混じる複雑な状況に。色が付いていてもベタの文字なら正しく識字されるが、修飾された文字に関してはほぼ全滅 | 【画面27】黒枠で囲まれた文字も誤認識してしまう。また、雑誌広告だと印刷解像度も低めなので小さな文字も誤認識が目立つが、これは背景の罫線も影響しているようだ | 【画面28】最下部のURL部分は、わりと大きな文字ではあり「文字」として認識したものの、正しく識字できていないる |
●識字率以外の面でも機能強化に期待
ということで、わりと厳しい条件も交えつつテストを行なってきた。数年前に使用したOCRソフトと比べれば識字率には格段の差があり、筆者のOCRへのイメージは、多少ポジティブなものへと変化しつつある。ただ、今後のアップデートに期待したい部分は多い。ここで、もう1つテストサンプルを紹介したい。
最初にウィザード手順を紹介したところで、認識結果をPowerPointなどへ転送できることに触れているが、複数枚の画像を一気に認識し、それをPowerPointに転送。画像1枚=スライド1枚、という具合にファイルを作成する機能だ。
画面29は、こちらの説明会のプレゼンテーションをデジカメで撮影したもので、これをまとめて認識させPowerPointに出力してみてみると画面30のように、歪んだままでは文字の認識が正しく行えなかったことが分かる。画面30はまだ頑張っているほうであり、画像がそのままだったり、無理やりテキスト化して散々な結果で転送されたものもある。
 |
 |
| 【画面29】発表会などで提示されるプレゼンテーションを一括して認識させ、1つのファイルにまとめられるのは便利なのだが…… | 【画面30】正面から撮影できないシチュエーションでは、本製品の自動補正が実用的でないのが悩みどころ |
仕事柄、プレゼンテーションという恰好のサンプルがあったので紹介したが、もう少し一般的な用途では料理のレシピ本や辞書から必要なページの写真を撮影し、それを一括して識字させ1つのファイルにまとめるといったことも考えられる。製本されたものをデジタルデータ化する場合はオートシートフィーダーが利用できず、複数枚を取り込むにはデジカメを利用するほうが手っ取り早いからだ。
この複数枚のデータを一括で転送する機能を積極的に利用することを考えると、現状では物足りない点も多いのだ。
例えば、本製品は画像補正機能が充実しているのが1つの魅力であるが、画像の傾き(横位置→縦位置化)はできても、画像の歪みなどは手動補正が必要である。上記サンプルのように、真正面から撮影できないシチュエーションでは、各写真に対して長方形化ツールを施さなければならない。
また、料理のレシピや辞書などを家で撮影するなら正面から撮れば歪みの補正を施す必要はないが、修飾された文字を「文字」として認識できなかったり、誤認識が増える点は気になるだろう。
本製品には「レイアウト」機能というものがあり、これを使うと指定の領域に含まれるデータを「文字」「図版」「画像」と明示的に指定することもできるのだが、これを細かく行なうのは、わりと面倒な作業である。画像からテキストデータを手入力する手間を省くためのOCRソフトで、こうした手間のかかる作業は避けたいところなのは筆者ならずともそうであろう。
手軽なメモ、デジタルデータ化の手段として認められてる「デジカメのデータをOCRでテキスト化する」というアプローチは非常に現実的だし、そのための機能を多く搭載しているのはOCRソフトユーザーを増やすきっかけにもなりそうで好印象である。
今回試した印象では、白地に黒文字といったビジネス文書などでの典型的なパターンであれば高い識字率を持っており実用性も高い。となれば、今後は自動的に画像補正する機能を強化したり、文字領域の判定をより正確に行なう、といった、本製品の識字率の高さを活かすような機能強化に期待したい。
□関連記事
【2003年11月6日】松下、カメラ付携帯電話からの読み込みにも対応したOCR「読取革命 Ver.8」
http://pc.watch.impress.co.jp/docs/2003/1106/pana.htm
(2004年1月20日)
[Text by 多和田新也]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.