 |


■後藤弘茂のWeekly海外ニュース■なぜEfficeonはCrusoeよりも効率が高いのか |
●より効率的になったコードトランスレーションシステム
Transmetaの切り札「Efficeon TM8000」。その性能の秘密は、Crusoeよりも格段に向上した効率にある。つまり、効率がいい(efficient)ことがEfficeonの特性だ。そして、Efficeonの高効率の秘密は、そのコンパイラアーキテクチャにある。
Transmetaアーキテクチャでは、x86命令をソフトウェアレイヤ「CMS(Code Morphing Software)」のリアルタイムコンパイラ/スケジューラで、CPUコアのVLIW命令に変換して実行する。Transmetaでは、この変換をモーフィングと呼んでいる。CrusoeもEfficeonもこのモーフィング原理は同じだが、中身は大幅に変わっている。
「CMSのアルゴリズムは大幅に変わり、はるかに効率が向上している。また、VLIW命令も完全に一新され、全ての命令がCrusoeとは異なるものになっている。そのため、実行ユニットの構成も、新命令に合わせて大きく変わった」とTransmetaのDavid R. Ditzel氏(創業者兼CTO)は説明する。
まず、CMSでは何が変わったのか。
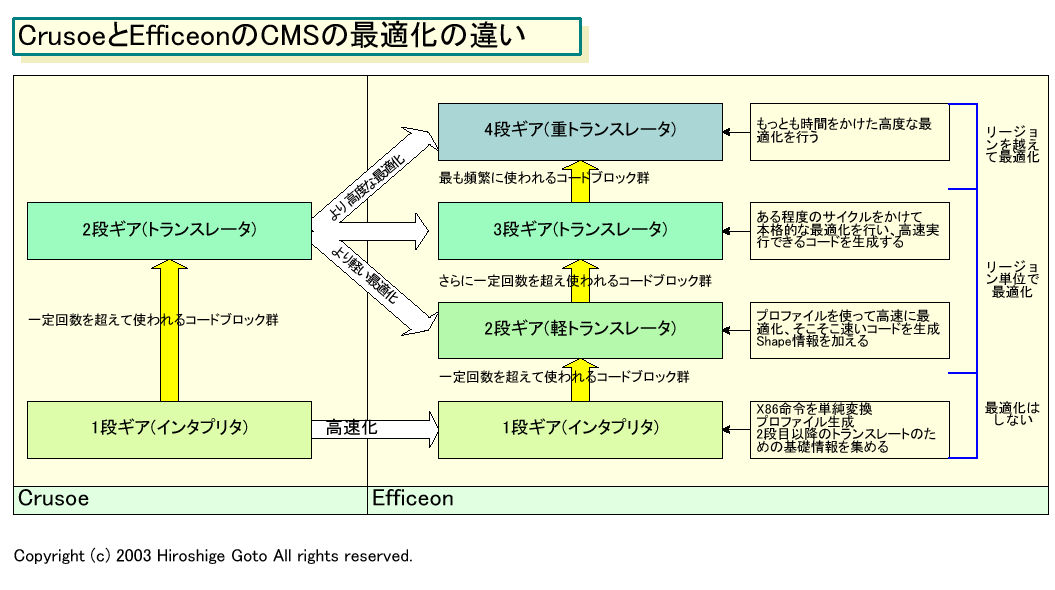
(1)Crusoeでは2段だったモーフィングを4段にした。
(2)コードのプロファイリングを行ない、さらに分岐のトレースなども記録できるようにした。
(3)より多くの不要な命令を削除できるようにした。
(4)より広域のコードをスケジューリングできるようにした。
(5)VLIW命令セットの改良により、インタプリタの効率を大幅に向上させた。
 |
| CrusoeとEfficeonのCMSの最適化の違い PDF版はこちら |
●トランスレータを3段階に展開
EfficeonのCMSは、x86命令をRISCライクな単純命令「atom」(32bit固定長)に分解。その後、atomをスケジューリングして、256bitのVLIW命令「molecule」にパックする。この過程がモーフィングで、Transmetaではこれを複数のステップに分けて行なう。このステップを、Transmetaはギア(gear)と呼んでおり、このギアがCrusoeとEfficeonでは大きく違う。
「Crusoeは2ギア、つまり、1段ギアは“インタプリタ”で、2段ギアは“トランスレータ”。最適化を行なうトランスレーションはたった1段しかなかった。Crusoeでは、1段ギアではできるだけ速くx86命令をatomに置き換える。そして、同じコードが再度使われる時は、2段ギアで、変換済みのコードを最適化する。2段目ではよく最適化されたコードが生成されるが、これには非常に時間がかかった」
「そこで、Efficeonでは4段ギアに分けた。1段ギアはCrusoeと同じインタプリタだが、これもCrusoeと比べると劇的に高速になっている。2段ギアは“軽い最適化”を迅速に行なう。そして3段ギアでより本格的な最適化を行ない、4段ギアになると、これまでよりずっと高度な最適化を行なう」
イメージとしては、Crusoeより軽い最適化とヘビーな最適化の2つのギアを加えたことになる。つまり、速く変換できるが実行は遅いコードと、速く実行できるが変換に時間がかかるコードの2つしかなかったのを、よりきめ細かな4レベルに分けたというわけだ。軽い最適化が加わったため、頻繁に使われる度合いの少ないコードも、これまでより高速に実行できるようになったという。
●最適化を行なうコードブロックを拡大
 |
| Shapeインフォメーション PDF版はこちら |
Efficeonでは1段ギアの時にCMSがプログラムをプロファイリングしてしまう。つまり、コードの振る舞いを分析して、パターンに当てはめ、そのプロファイルデータを元に2段ギアでの最適化を高速に行なうという手法を取るという。これも、CrusoeのCMSにはなかったフィーチャで、これによって2段ギアでの高速最適化が容易になったという。
また、2段ギアからは、多数のx86命令を含むコードブロックをひとつのスケジューリング単位(リージョン:Region)として扱う。このリージョンはCrusoeでは最大でも数10命令だったのがEfficeonでは最大100命令に拡張された。
「最大の頭痛のタネは、ほとんどのプログラムではコンパイラはベーシックブロック内でしか最適化を行なわないことだ。ベーシックブロックは分岐内のシーケンスで、最小では3命令、つまりload, comp, branchだったりする。これではまず最適化なんてできない。しかし、最適化する範囲をベーシックブロックを超えて大きくすると、より多くの命令から多くの最適化をできるようになる。Efficeonでは最大100命令の中で最適化を行なう。そうすると、例えば、コモンサブエクスプレッション(Common sub-expression)などを見つけて削除しやすくなる」とDitzel氏は言う。
さらに、4段ギアでは今度はリージョンを融合させ、複数リージョン内でのスケジューリングを行なう。「コンパイラにとってもっとも重要なのは、どれだけ多くの命令の中で最適化できるかだ。4段ギアでは重要なパスを、広い範囲で最適化することで、もっとも効率のいいコードを生成する」(Ditzel氏)
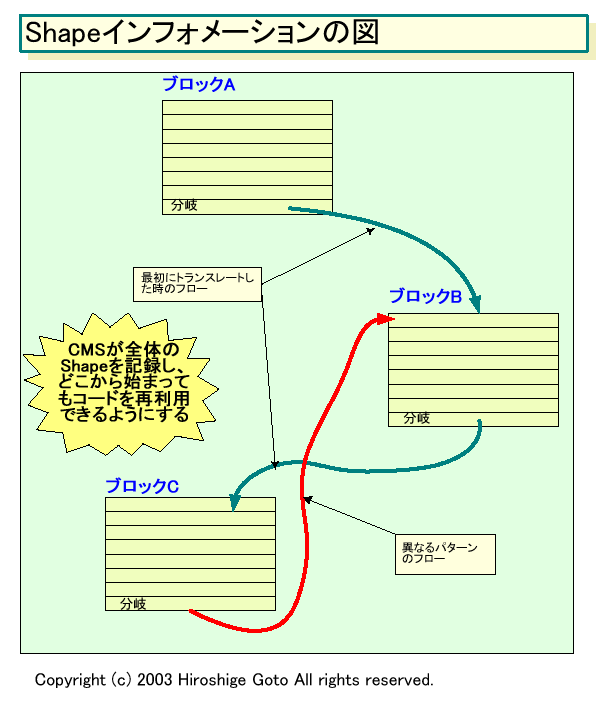
また、2段ギアでは今度は「シェイプ(Shape)」インフォメーションと呼ばれる、分岐フローの情報が変換コードの付加情報として加えられる。これは、リージョン内のベーシックコードブロック間のフローの情報だ。例えば、下の図のように3ブロックがあり、ブロックAから条件分岐でブロックBへ、そしてまた分岐でブロックCへと流れる場合。A→B→Cへと常に流れている場合は、CMSが変換したコードはそのまま使うことができる。
「ところが、もしコードがブロックCから始まって次にブロックBへと分岐するような場合、Crusoeではもう一度トランスレートをやり直さなければならなかった。つまり、同じコードを2回トランスレートすることになってしまうわけだ。これは非常に効率が悪い。 そこでEfficeonのCMSでは、分岐の流れ、これをシェイプと呼んでいるが、これを記録できるようにした。これによって、今言ったようにフローの途中から始まってしまうような場合でも、トランスレート済みのコードを使えるようになった。これは大したことではないように聞こえるかもしれないが、実際には、莫大な効果がある。コードシェイピングを記録すると、場合によっては10倍も効率化を図ることができる。
●メモリ命令のリオーダリングも強化
3段ギアでは、さらに進んだ最適化が行なわれる。コモンサプエクスブレッションの削除やメモリアクセス命令の並べ替えもこの3段ギアで行なわれる。メモリのリオーダリングは、Crusoeでもやっていたが、Efficeonではこの最適化に必要なエイリアス(alias)ハードウェアを独立ユニットにして、さらに機能を強化したという。
Transmetaアーキテクチャでのメモリ命令のリオーダリングは下のように行なう。
| load | a→r1 |
| store | r2→b |
| load | c→r3 |
a、b、cはメモリアドレスで、r1、r2、r3はTransmetaアーキテクチャでのレジスタだ。
この場合、メモリアクセスのレイテンシを考えると、load命令はできる限り前へ持ってきた方がいい。しかし、通常は、loadをstoreの前に持って来ることができない。storeでloadの読み出すメモリアドレスの内容が変わってしまう可能性があるからだ。この例だと、storeのアドレスbは、次のloadのアドレスcと同じかどうかはstoreを実行しないとわからない。
「それに対してTransmetaのアーキテクチャでは、loadを上に持って来ることができる。その代わりにstore命令にcheck aliasを加える。store実行時にチェックして、もし、loadとstoreのアドレスが同じだった場合にはやり直し、そうでなければ継続する。これで、ほとんどのケースではloadのメモリレイテンシを隠蔽できるようになる」(Ditzel氏)
| load | a→r1 |
| load | c→r3 |
| store+check | alias r2→b |
「こうした処理は、aliasハードウェアがないと実現できない。Crusoeにもaliasはあったが、Efficeonではよりaliasを強化した。より多くのaliasレジスタを加え、より多くのケースでloadを前へ出せるように改良した」とDitzel氏は言う。
●不要な命令の削除で高速化
また、3段ギアではアグレッシブに余計な命令の削除も行なう。この場合にもaliasが役に立つ。例えば、下のようなコードシーケンスだった場合。
| load | a→r1 |
| store | r2→b |
| load | a→r3 |
load命令が同じアドレスaから重複してデータを読み出している。
「これも、Transmetaのアプローチでは、ちょっとプログラムを変えて、時間のかかるloadを、短時間で実行できるmoveに変えることができる。レジスタ間の移動のmoveの方が、メモリアクセスが必要なloadよりずっと実行が簡単だ」とDitzel氏は説明する。
| load | a→r1 |
| store+check | alias r2→b |
| move | r1→r3 |
この場合も問題になるのは、アドレスaとアドレスbが同じかどうかだ。storeでアドレスaが書き変わってしまう場合にはアドレスaから再びloadする。そうでなければ、moveを実行するわけだ。
「この手法なら、ある程度のloadは削除できる。ハードウェアソリューションでは、常に“速く実行する方法”を探すが、ソフトウェアデザイナは違う視点から考える。彼らは“命令を消す方法”を探す。loadを非常に高速に実行できるCPUハードウェアがあったとしても、0サイクルのloadにはかなわない(笑)。コンパイラによる最適化は、常にハードウェアによる最適化よりも高速となる。0サイクルloadは最速だ」とDitzel氏は笑う。
同様に、分岐命令もEfficeonでは削除できる。
「条件分岐でほぼ100%分岐するような場合には、分岐命令を削除してしまうことができる。チェック命令でチェックを行ない、プログラムの振る舞いが変わった場合には、再トランスレートを行なう。通常、そうしたケースは少ないために、これも効果がある」とDitzel氏は言う。
こうした動的な分岐の最適化を行なうため、Efficeonは1個の分岐ユニットしか持たない。これは、同じVLIWでも、3個の分岐ユニットを備えるIA-64系アーキテクチャとの大きな違いだ。
「IA-64は静的コンパイルだから、全ての分岐命令を実行しなければならない。だから、彼らは3分岐ユニットがあるわけだ。もっとも、Efficeonも実際にはselect命令などに置き換えるので、実質的には1サイクルで複数分岐を行なうことができる」とDitzel氏は説明する。
●命令幅の拡張はスケジューリング
また、Efficeonではインタプリタ自体も命令によっては、効率が大幅に向上したという。Efficeonは論理レジスタだけで整数64本、浮動小数点64本を持ち、x86のレジスタをその上にCMSがマップする。そのハンドリングを最適化することで、インタプリタを高速化するという。
「1段ギアでは、まだフルには最適化が行なわれていない。単なるインタプリタだ。問題は、インタプリタの場合、これまでは1個のx86命令を一連の命令シーケンスに変換しなければならない場合があったことだ。例えば、『add (esp+8), eax』という命令をatomに置き換えると、どうしても長いサイクルが必要になってしまっていた。
しかし、Efficeonでは、新たにエグゼキュート命令(execute instruction)という新命令とエグゼキュートユニット(execute unit)を設けることで、これを解決した。エグゼキュート命令で、Efficeonの内部レジスタを(同じサイクルで)ハンドルすることで、1サイクルで実行できる」とDitzel氏は言う。
エグゼキュートユニットは、整数演算用と浮動小数点演算用の2ユニットがある。ちなみに、Efficeonの11個のユニットの内訳は下の通り。
| 整数演算ユニット(Integer ALU) | 2個 |
| ロードストア(&add)ユニット(Load/Store/32-bit add) | 2個 |
| エイリアス(Alias) | 1個 |
| コントロール(Control) | 1個 |
| FP/MMX/SSE/SSE2 | 1個 |
| MMX/SSE/SSE2 | 1個 |
| 分岐(Branch) | 1個 |
| エグゼキュート(Exec) | 2個 |
こうして見るとEfficeonの11ユニットのうち3ユニット(2個のExecと1個のAlias)は、命令スケジューリングを助けるためのユニットであることがわかる。Efficeonでは、命令長を拡大して、Crusoeの4命令同時発行から8命令発行に変え、実行ユニットも5個→11個に増やした。しかし、その増加分の半分は、演算ユニットの増加ではなく、スケジューリング支援に費やしたわけだ。演算ユニットの拡張は最小限に抑え、効率を高める方向へと拡張したアーキテクチャだ。
そのため、Efficeonでは、並列性はCrusoeより大きく向上したと考えられる。つまり、同クロックでもCrusoeよりずっと速くなったと推測される。Transmetaが、EfficeonはCrusoeよりもIPC(instruction per cycle:1サイクルで実行できる命令数)が倍増したと主張するのも、根拠がない話ではない。
「Efficeonは、Crusoeよりはるかに進化した。8命令発行になっただけでなく、CMSがより効果的なトランスレーションができるようになった。また、インタプリタの段階から効率も向上した。
IPCはアプリケーションに依存するために明確には言えない。しかし、Centrinoとの比較を行なったところ、IPCではEfficeonの方が2.7倍も高かった。つまり、クロック当たりの性能はそれだけ高いということだ」とDitzel氏は語る。
□関連記事
【10月16日】【海外】高効率CPUを目指すEfficeonのアーキテクチャ
http://pc.watch.impress.co.jp/docs/2003/1016/kaigai033.htm
【10月15日】【MPF】ついにベールを脱いだTransmetaの秘密兵器Efficeon!
http://pc.watch.impress.co.jp/docs/2003/1015/mpf01.htm
(2003年11月4日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.