 |


■後藤弘茂のWeekly海外ニュース■高効率CPUを目指すEfficeonのアーキテクチャ |
●最大8命令を並列実行するEfficeon
 |
| Efficeonのレイアウト |
ついにベールを脱いだTransmetaの次世代CPU「Efficeon TM8000」。その思想は、名前の通り、効率の高い(efficient)コンピューティングを実現することにある。つまり、消費電力/クロック/トランジスタ数当たりのパフォーマンスを上げ、無駄な電力消費を抑えることに徹したアーキテクチャとなっている。
そして、これはTransmetaだけでなく、今やCPU業界全体のトレンドとなりつつある。CPUやGPUが、相次いで消費電力の壁にぶち当たっているからだ。
CPUの処理性能は、動作周波数×IPC(instruction per cycle:1サイクルで実行できる命令数)で決まる。Transmetaは効率を高めるため、CPUの処理の並列度をより高めてIPCを高める方向へとCPUを進化させた。つまり、動作周波数を上げる方向へはアーキテクチャは向かっていない。
ちなみに、現在のIA-32系CPUのIPCは2.x命令/サイクル程度と言われている。Transmetaは2年前に、Efficeonが目指すIPCは5.x命令/サイクルだと説明していた。つまり、同クロック時に2倍の性能(効率)のCPUを作ろうとしているわけだ。
では、Efficeonはどうやって並列度を高めようとしているのか。まず、EfficeonのCPUコアは、命令長を現在のCrusoeの128bitから256bitへと拡張した。Transmetaアーキテクチャでの命令セットは「VLIW(Very Long Instruction Word:超長命令語)」型で、1つの長い命令語の中に複数の命令をパックする。
CPUのソフトレイヤであるコードモーフィングソフトウェア(CMS)が、x86命令をRISCライクな単純命令「atom」(32bit固定長)に分解。その後、その単純命令のうち並列に実行できる組み合わせをスケジューリングして、256bitのVLIW命令「molecule」にパックする。Efficeonは32bit命令を256bit命令の中に8個パックする。これは、同じVLIW系のIA-64の6命令スロット(2バンドル)より多い。
●ちょっと変わった構成の11個の演算ユニット群
8命令スロットに対して、Efficeonでは内部の実行ユニットは11個の構成になっている。つまり、実行ユニット数も、Crusoeの5ユニットより倍増している。11個という数は、IA-64のItanium 2(McKinley/Madison)系CPUと同じで、非常に多い。しかし、演算ユニットの区分けは、ちょっと変わっている。
Efficeonの11個のユニットの内訳は下の通り。
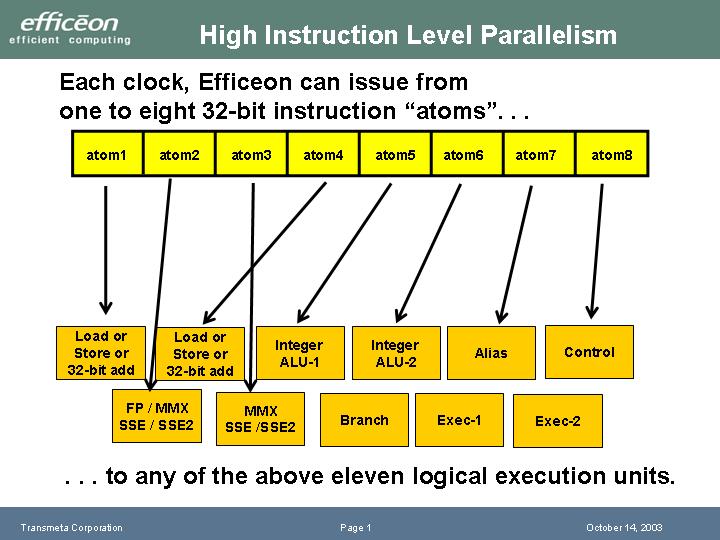 |
| 11個の演算ユニット |
- 整数演算ユニット(Integer ALU) 2個
- ロードストア(&add)ユニット(Load/Store/32bit add) 2個
- エイリアス(Alias) 1個
- コントロール(Control) 1個
- FP/MMX/SSE/SSE2 1個
- MMX/SSE/SSE2 1個
- 分岐(Branch) 1個
- 実行?(Exec) 2個
これに対してCrusoeのユニット数は以下の通り。
- 整数演算(ALU) 2個
- ロード/ストア 1個
- 分岐 1個
- 浮動小数点演算/SIMD 1個
- 分岐ユニット 3個
- 整数演算ユニット 2個
- 整数演算&メモリユニット 4個
- 浮動小数点演算ユニット 2個
その他のユニットでは、エイリアスはTransmeta独自の「Address Alias Checking Hardware」で、メモリアクセス命令が参照するアドレスのチェックを行なう。これは、ストア命令より前にロード命令をスケジュールできるようにするためのもので、IA-64などもロード命令をストア命令の前に出せる仕組みを持っている。今回のEfficeonでは、これを専用ユニットに分離したようだ。
その他のExecやControlなどのユニットの詳細はわからない。しかし、見た限りでは汎用的なユニット数を増やすのではなく、専用処理ユニットを増やすことで、トランジスタ数を抑えながら並列度を高めようとしているようだ。これは、汎用ユニットを増やしてたItanium 2と比べると歴然としている。こうした方向は、低消費電力&高効率というEfficeonの目的とは合っている。
●パイプライン構造は基本的にはCrusoeと同じ
Efficeonのパイプラインは整数6段、浮動小数点演算8段、ロード/ストア6段。
整数パイプのステージは下の通り。
- IS: 命令発行(Instruction Issue)
- DR: 命令デコード(Instruction Decode)
- RM: レジスタリード(Register Read for ALU operands)
- EM: 実行(Execute ALU operation)
- CM: コンプリーション(ALU Condition flag completion)
- WB: ライトバック(Write Back results to integer register file)
命令発行で1ステージを取っているのは、命令スロットより実行ユニット数が多いため、命令発行ステージに各ユニットに割り振る(ディスパッチネットワーク)機構があるためと考えられる。
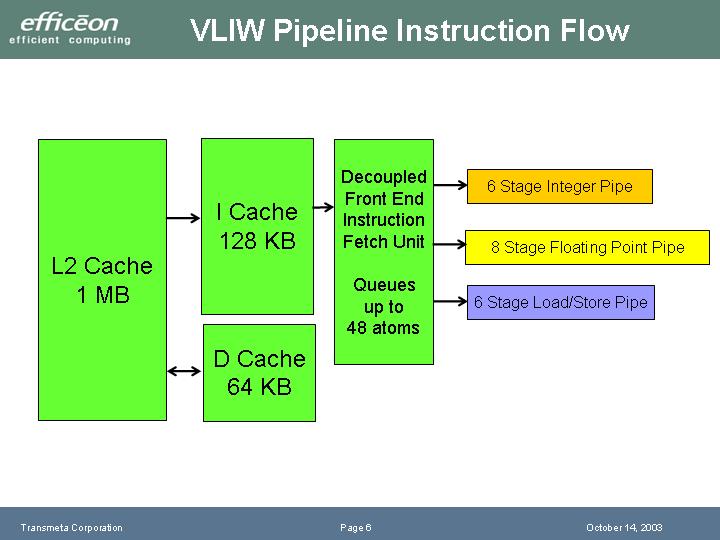 |
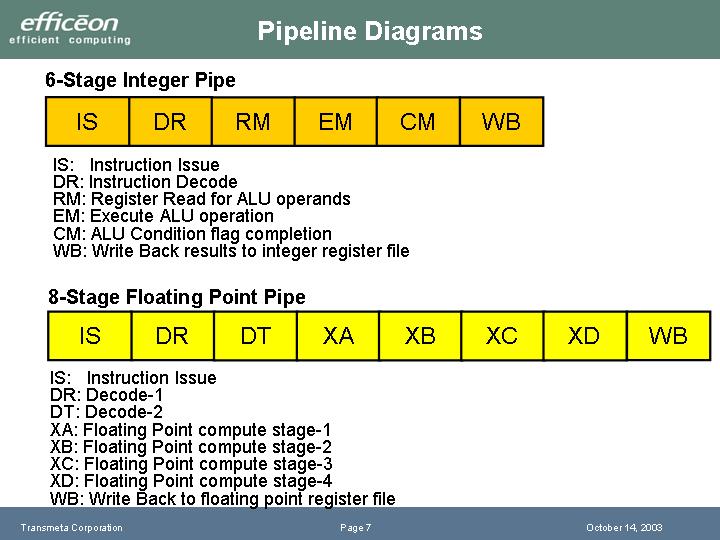 |
| パイプラインのフロー | パイプラインのダイヤグラム |
レジスタは32bitの汎用レジスタを64本、80bitの浮動小数点レジスタを64本持っている。x86アーキテクチャでのレジスタは、これらのレジスタにマップされる。また、それぞれ48本がシャドウレジスタとなっている。演算結果はシャドウレジスタにも書き込んでおき、例外処理が発生した場合は表のレジスタに書き戻す。
汎用レジスタ数はCrusoeと同様だが、浮動小数点レジスタ数はEfficeonでは2倍に増えている。また、面白いことにSSE/SSE2をサポートするにもかかわらず、SSE/SSE2用の128bitレジスタ(XMM0~XMM7)に対応した128bitレジスタは備えない。80bitの浮動小数点レジスタを組み合わせて、SSE/SSE2データを格納すると推定される。
しかし、演算も同様に演算ユニット内部で、64bitずつ分割演算しているのか128bitで演算しているのか、そこはまだわからない。演算も2分割している場合には、SSE/SSE2のスループットが落ちることになる。
●4段階で最適化を行なうEfficeonのCMS
また、EfficeonではCMSのダイナミックコンパイラも新規に開発した。これはターゲットのCPUのVLIWの構成が大きく異なるから当然だが、それだけではなく、最適化の手法も改良している。もっとも大きな点は、4段階で最適化コンパイルを行なうこと。
Transmetaのアーキテクチャでは、x86命令を動的にVLIW命令に変換している。この変換のオーバーヘッドを抑えることが、もっとも難しく、テクニックが必要な部分だ。
Crusoeでは、第1段階では、CMSがx86コードをRISCライクな単純命令のatomに変換する。例えば,メモリからのロードオペレーションをを含む整数演算命令は整数演算atomとロードatomに分解する。この段階では、複雑なスケジューリングは行なわず、できるだけ速く命令を変換して実行する。処理の並列化は、この段階ではほとんど考慮しない。変換ずみのコードは、メインメモリ上にキャッシュしておく。
そして、変換済みのコードが再び使われる場合には、変換済みのコードを読み出して、CMSのオプティマイザがatomの最適化を行なう。それによって、atomを並列化して実行効率を高めていた。Transmetaによると、Crusoeでは2~3段階で最適化を行なっていたという。
今回のEfficeonでは、この変換・最適化を4段階で行なう。最初の「1st Gear」では、まず単純にx86命令をatomに変換して実行する。変換に時間はかからないが、並列化されていないので、実行には時間がかかる。この時にプロファイルを作り、命令フローの解析などを行なえるようにする。
次に、「2nd Gear」ではatomを最大100のx86命令分のブロック(Regon)単位に分けて、その中で並列に実行できるatomを並列化するスケジューリングを行なう。この段階では、まだ、最適化にそれほど時間をかけない。Crusoeでは数10命令分のブロックと説明されていたのが、Efficeonでは100命令分のブロックと拡張されている。
 |
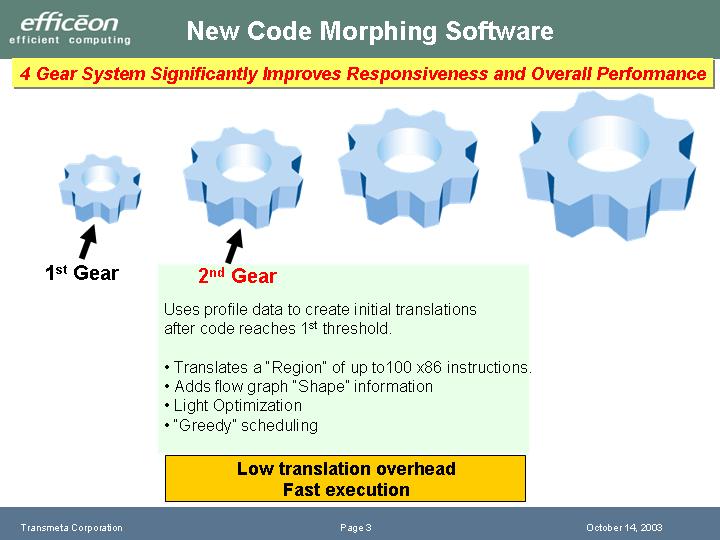 |
| Efficeonの最適化過程(1st~2nd) | |
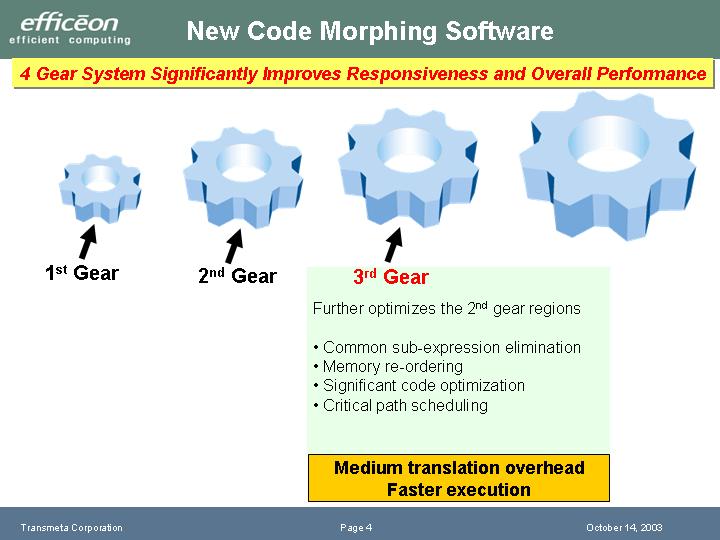
その次の「3rd Gear」では、2nd Gearで切り分けたブロック内での最適化をもっと行なう。この段階では、スケジューリングに時間をかけて、高速に実行できる最適化されたVLIWコードを生成する。頻繁に使われるコードなら、最適化に時間をかけてもその方が、結果として実行が速くなるというわけだ。
ここまでは、従来のCrusoeのCMSでも行なっていたわけだが、Efficeonではさらに4段階目の最適化を行なう。「4th Gear」では今度は2nd Gearで分けたブロックを超えてスケジューリングを行なう。より広域のコード内でスケジューリングすることで、もっと並列度を高めようというアプローチだ。つまり、EfficeonではCrusoeよりもさらに深い段階で最適化スケジューリングを行なうことになる。
これは、Efficeonのアーキテクチャを考えると当然の方向だ。というのは、実行リソースが増える分、最適化の余地も増えるからだ。こうした最適化を効率良く行なうことで、平均5.x命令/サイクルを目指すと思われる。
しかし、このことは、Efficeonが、コードの局在性の高さに依存していることを意味している。つまり、実際に実行されるコードが局所的に偏在しているほど、高い性能が出るというアーキテクチャの傾向が、より強められるわけだ。このことは、逆を言えば、コードの局在性が崩れていくと性能が出にくいという危険性もはらんでいる。
 |
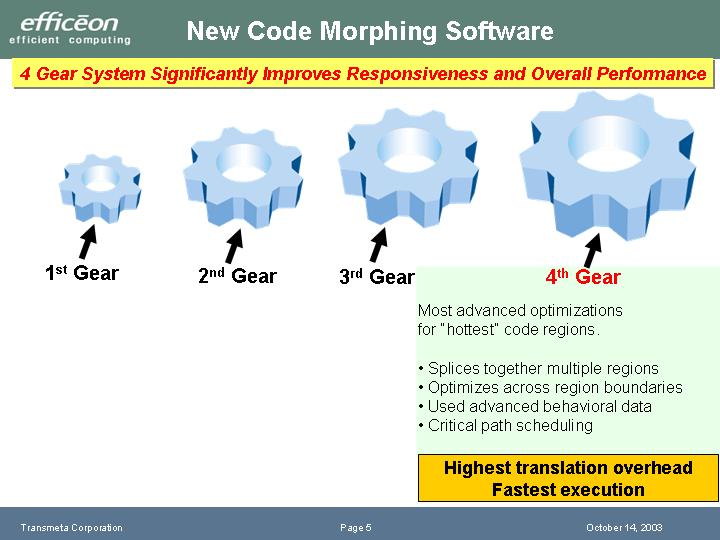 |
| Efficeonの最適化過程(3rd~4th) | |
□関連記事
【10月15日】【MPF】ついにベールを脱いだTransmetaの秘密兵器Efficeon!
http://pc.watch.impress.co.jp/docs/2003/1015/mpf01.htm
(2003年10月16日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.