 |


■後藤弘茂のWeekly海外ニュース■マルチチップを前提に開発されたXGIの新GPU「Volari」 |
●ユニークなXGIのアプローチ
ATI TechnologiesとNVIDIAの2強が争うPC向けGPU市場。そのナンバー3のポジションを狙って、新興XGIが新GPU「Volari」ファミリでステージに登場した。XGIは、SiSとTrident Microsystemsの両社のグラフィックス部門を吸収して誕生したが、同社のGPU「Volari」は、どちらの既存製品の流れも引いていない。もっとも異なるのは、マルチチップ構成を前提としてアーキテクチャ開発を行なっている点だ。
XGIのVolariでは、デュアルチップのボード構成をラインナップに備える。同社のハイエンド製品「Volari Duo」シリーズは2個のGPUチップをビデオカードに搭載する。デュアルチップ構成で、3DMark2003スコアで4,500~5,500レンジを狙う。ちなみに、メインストリームからバリューセグメントの製品はシングルGPUチップだ。
 |
 |
 |
| COMPUTEXで展示されたXGIのボード | ||
XGIのケースが面白いのは、GPUの派生的なソリューションとしてマルチチップが出てきたのではないことだ。最初からマルチチップを前提としてアーキテクチャを開発し始め、その最初のステップとしてVolariがあるといったイメージだ。これである程度うまくいくなら、将来、XGIはもっとアグレッシブなマルチチップアーキテクチャを取ってくる可能性がある。
とはいえ、今のところXGIのアプローチはイロモノに見られがちだ。PC向けビデオカードでは、マルチチップ構成はこれまで成功を収めることができなかった歴史があるからだ。シングルチップで性能を高めた方が、結局はパフォーマンスでもコストでも勝利を収めた。また、XGIの現在のアーキテクチャがマルチチップに最適化されていて、十分な性能を発揮できるかどうかはまだわからない。
しかし、マルチチップ自体は、もしかすると合理的なアプローチになるかもしれない。というのは、GPUを巡る状況が、以前とは大きく異なるからだ。というのは、マルチチップ構成が理にかなう(かもしれない)背景が、半導体製造技術とグラフィックス技術の両面にあるからだ。
●ダイサイズの増大がマルチチップ化を促す?
 |
| GPUの世代とトランジスタ数の変遷 |
マルチチップが理にかなう可能性が高いのは(1)ハイエンドGPUのダイサイズ(半導体本体の面積)が巨大になりつつあること、(2)マルチチップに合わせたハードウェアを備えること、(3)GPUの処理がシェーダ中心へと移りつつあること、の3点があるからだ。
じつは、SiSのグラフィックス部門はXGIへとスピンアウトする前、今年1月のPlatform Conferenceの段階で、すでにこのアイデアを明かしていた。同社は、この時「Go Multiple」と題したプレゼンテーションで、マルチチップ構成がGPUにとって最適になることを説明している。
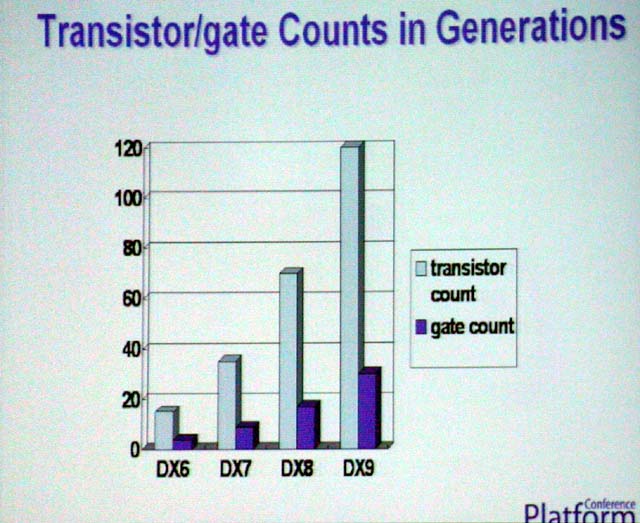
現在のハイエンドGPUのダイは、NVIDIAとATIの両社とも約200平方mmに達している。これは、PC向けCPUとしてもかなり大きい(0.18μm版Pentium 4クラス)。これは、半プロセス世代毎にGPUの性能を3倍にするために、GPUのトランジスタ数を2倍にしてきたからだ。DirectX7世代GPUは0.18μmで約2,500~3,000万トランジスタ、DirectX8世代は0.15μmで約5,000~6,000万、DirectX9世代は0.13μmで約1億2,000~3,000万。同じトランジスタ数のチップのダイサイズ(半導体本体の面積)は、半世代毎に約60~70%にしか縮小しない。だから、半世代でトランジスタが倍々になっていくと、チップのサイズは30~40%づつ大きくなっていってしまう。つまり「プロセス技術がGPUの発達に追いつかない」(SiS)が現在のGPUの抱える大きな問題となっている。
問題は、ダイサイズ=製造コストだけの話ではない。トランジスタ数の増大に応じて、発熱は増えるため、冷却機構のノイズなどの問題が発生する。また、冷却機構でもコストがかかる。ゲート数が増えると、テスト工程も増えて、製品化に時間もかかる。こうした問題があるため、SiSは今年頭の時点で、GPUの巨大化は200平方mm程度で、限界に差し掛かったと分析していた。
ファウンドリの状況を見てみると、さらに事態は深刻だ。0.13μm以降、プロセスの移行の速度は落ちてきている。昨年の段階では、今年末には0.11μmにこぞって移行すると見られていたのが、0.11μmは来年が本番になり、90nmは2005年が本番と言われる状況になっている。そのため、GPUの肥大化を抑えるのが難しくなりつつある。
XGIがマルチチップへ向かうのは、そのためだ。つまり、大きくて高速なワンチップのGPUを作ると、コストと発熱と期間が必要になる。だったら、そこそこのサイズでそこそこの速度のGPUを作って2個載せる方が合理的というわけだ。実際には、パッケージやボード実装、粒度の増えるDRAMチップなどのコストは増えるわけだが、それでも200平方mm以上の巨大チップよりはいいだろうという話だ。
これは、特にハイエンド製品がどれだけ売れるかわからない下位メーカーにとってはベネフィットが大きい。メインストリーム向けチップとは別に、高コストなハイエンドチップを開発・製造する必要がないからだ。メインストリーム向けチップを2個並べれば、ハイエンド製品になるなら、製造も管理もずっと容易になる。
●マルチチップ接続専用のバスを設ける
また、XGIは3D時代のマルチチップに合わせたアプローチを取ると説明する。
「我々は、マルチチップでも3Dfx Interactiveのようなラインインターリーブは行なわない。彼らのでは、スキャンライン毎に交代に異なるチップが描画した。それに対して、我々のフレームインターリービングでは、画面1フレーム毎に交代に異なるチップが描画する。マスタチップがフレーム1全体を描画し、次にスレーブチップがフレーム2を描画、次にマスタチップがフレーム3を描画するといった具合だ。ラインインターリーブはレンダリングとしてはいい手法だが、この方法ではVertex Shader側のボトルネックは解決できない。しかし、我々の手法では両方のボトルネックを回避できる」とXGI TechnologyのChris Lin氏(President)は説明する。
両チップがそれぞれのバッファにフレームを交代に描画するというイメージだ。もっとも、このアイデア自体は斬新なものではない。
 |
| XGIのVolariアーキテクチャ ※PDF版はこちら |
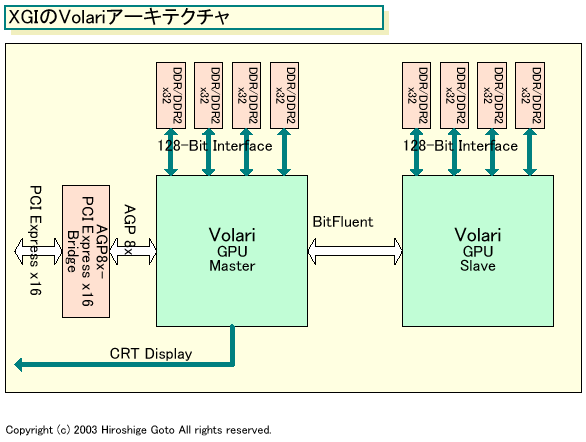
現在のXGIのアーキテクチャでは、マスタGPUがAGPバスに接続され、スレーブGPUはマスタGPUと高速な専用インターフェイス「BitFluent」で結ばれる。BitFluentは32bit幅、133MHz駆動、4bit/クロックで、最大2.13GB/secとAGP 8xと同等の帯域を実現する。AGP経由でロードしたデータはマスタGPUからBitFluent経由でスレーブGPUへ送られる。スレーブGPUのフレームバッファは、BitFluent経由でマスタGPUに送られ、そこからディスプレイへ出力される。
「VooDooのSLIではバスリンクが非常に遅かった。それが性能を大きく向上できなかった原因だ。そこで、我々はバスに専用リンクを設けることで、制約を取り去り、よりスケーラブルに性能をアップできるようにした」とLin氏は説明する。
ただし、現在のXGIのアーキテクチャではメモリボトルネックは完全には回避できない。Volariは128-Bit幅のメモリインターフェイスを備えるため、デュアルチップでは256-Bitメモリインターフェイスとなる。しかし、両GPUのメモリ空間それぞれに、Zバッファやテクスチャバッファをコピーする必要がある。オンメモリのテクスチャに変更が加わる場合には、その変更を両方のテクスチャに反映させなければならない。そのため、無駄にメモリ量と帯域が制約される。
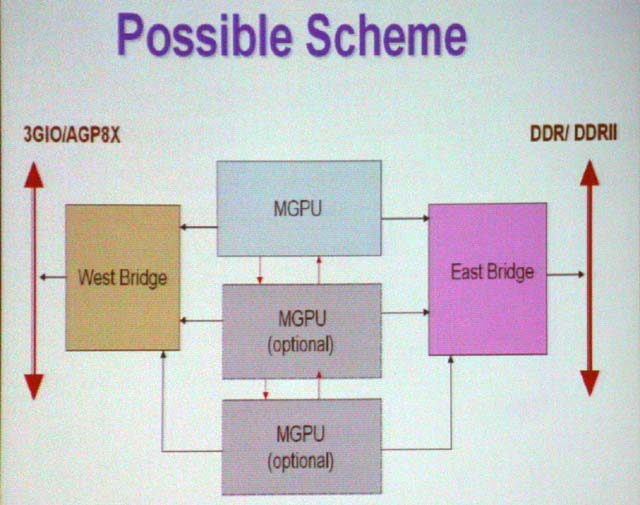
もっとも、Platform Conference時のSiSは、これも解決できるアーキテクチャを示していた。下のPossible Schemeの図がそれで、マルチGPUをはさんで2つのI/Oチップは配置されている。「CPUにノースとサウスのブリッジチップがあるように、ホスト側と接続するイーストブリッジと、メモリ側のウエストブリッジを置くこともできる」とSiSは説明していた。
このアプローチなら、マルチGPU間でメモリを共有することも原理的には可能になる。そうすると、メモリの無駄も減らすことができるかもしれない。ただし、チップ個数は増えるため、パッケージや実装上のコストは上がる。また、チップ間インターフェイスを高速化しなければならないという問題もある。
 |
| Possible Scheme |
●シェーダ中心になるとコンピューティングパワーが重要に
また、長い目で見ると、GPUの処理がシェーダ中心へ移ることもマルチチップ化を容易にする。以前のような固定ハードウェアでの処理の場合には、データをインプットして、それをパイプライン処理してピクセルをはき出すという流れだった。そのため、GPUの性能ではデータフローとコンピューティングパワーのバランスが重要だった。
しかし、GPU内部でのシェーダ処理が重くなると、GPUのデータフローよりコンピューティングパワーの方が比重として重要になっていくと推定される。もちろん、シェーダ処理は当然外部アクセスも要求するのだが、比重としてコンピューティングパワーの方がより要求されるようになる可能性が高い。そうすると、GPUのプロセッシングパワーを容易に増やすことができるマルチチップは理にかなった方法となってくる。
また、グラフィックス処理ではコンピューティングの並列性が高いこともマルチチップにとって有利だ。「グラフィックスは非常に並列性の面で有利だ。データの依存性が低いので、簡単に並列化できる。だから、まだまだ並列化のチャンスがあると考えている」とLin氏は言う。
こうしてみると、論理的にはXGIのようなマルチチップのビデオカードは可能性が開けているように見える。特に、ハイエンドソリューションでは可能性はある。また、XGIのような専用バスを設ける方式でなくても、広い双方向インターフェイスであるPCI Express x16になれば、PCI Express経由でGPU同士を接続したマルチチップ構成も考えられる。
●ピクセルパイプを2分割
XGIのVolariファミリは下のような構成となっている。
| 名称 | ピクセルパイプ数 | コアクロック | メモリ転送レート(DDR/DDR2) | シェーダ世代 |
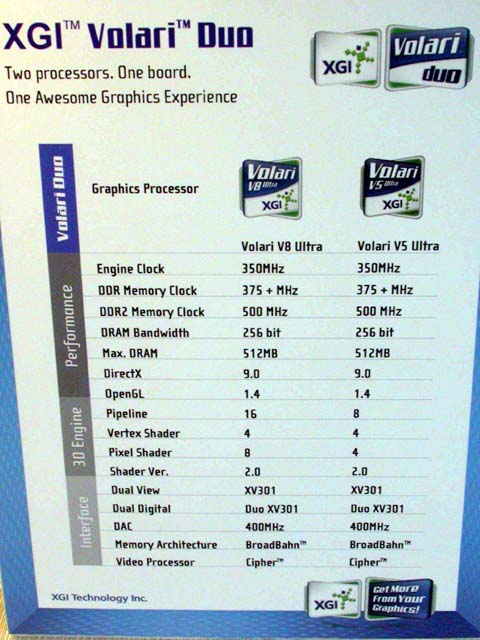
| Volari Duo V8 Ultra | 16 | 350MHz | 375/500MHz | 9.0 |
| Volari Duo V5 Ultra | 8 | 350MHz | 375/500MHz | 9.0 |
| Volari V8 Ultra | 8 | 350MHz | 375/500MHz | 9.0 |
| Volari V8 | 8 | 300MHz | 325/450MHz | 9.0 |
| Volari V5 Ultra | 4 | 350MHz | 375/500MHz | 9.0 |
| Volari V5 | 4 | 300MHz | 325/450MHz | 9.0 |
| Volari V3 | 2 | 300MHz | 300MHz | 8.1 |
Duoとついているのがデュアルコア。V8が8パイプ、V5が4パイプの構成だ。といっても、Volariの場合はピクセルパイプが2パスに分割されているため、単純には計算できない。
「我々のアーキテクチャでは2種類のパイプを備えている。ひとつは整数演算で、もう片方は浮動小数点演算だ。フィックスドパイプとプログラマブルパイプと呼んでいる。ひとつのパイプで両方の演算を行なおうとすると、性能が犠牲になる。そこで、既存のゲームの性能を考えて2つを分離した。だから、パイプラインは8本だが、Pixel Shaderとしては4基となる」とLin氏は言う。
このあたりのアプローチは、メインストリームから下を狙うメーカーらしい。ちなみに、Vertex Shaderは2基、浮動小数点演算Pixel Shaderの内部演算精度は24bitだ。ShaderアーキテクチャはDirectX9 Shader 2.0。製造はUMCで、0.13μmプロセス。2,000万ゲート(計算上は8,000万トランジスタ以上)で、NV30系の約2/3の規模だという。
同社は来年前半にはバリュー向けのDirectX9 GPUを、来年後半にはメインストリーム/ハイエンドでDirectX9 Shader 3.0 GPUを投入する。また、2004年末から2005年には「DirectX10、つまりShader 4.0対応GPUも出す」(Lin氏)という。計画上では、トップベンダーに追いついていこうとしている。
XGIはSiS/Trident時代と比べると開発リソースが2倍になったために、こうしたハイペースのアーキテクチャ開発が可能になるという。
「我々はSiSグラフィックスチームとTridentグラフィックスチームを集め、さらに外部からも人材を補強した。現在、我々には2つのグラフィックスアーキテクチャ開発チームがある。また、インプリメントチームも、新竹と上海に2つのチームがある。合計で250名の設計者がいる非常に強力な企業になった。R&Dが1チームではこの世界で生き残ることはできないが、我々は2チームが平行して開発を行なうことで競争力を維持できる」とLin氏は強調する。
同社はTrident製品系列もモバイル製品として残している。つまり、モバイル版Volariは、デスクトップ版Volariとは別アーキテクチャになっている。これも「DirectX10世代では、デスクトップ製品とアーキテクチャ的に融合させる」とLin氏は言う。同社はGPUコアを統合向けとしてチップセットベンダーにも提供して行く見込みだ。SiSやALi/Uliが採用すると見られる。ちなみに、SiSはXabre/Xabre II系コアをまだ持っていて、次の統合チップセットにも使ってくる。
同社の現在のチップはAGP 8xだが、PCI Express x16にもブリッジチップで対応する。これはNVIDIAと同じだ。ブリッジチップとGPU間をAGP 8xを高速化して結ぶことで帯域を高めることも考えているという。
XGIは現在ボード製品のパートナーと設計を進めている。少なくとも1社の台湾ボードベンダーが、XGI製品を採用する予定だと言われる。
□関連記事
【9月25日】【COMPUTEX】 XGIがデュアルGPU対応Volariシリーズを公開
http://pc.watch.impress.co.jp/docs/2003/0925/comp11.htm
【6月13日】Trident、PCグラフィックス事業から撤退
http://pc.watch.impress.co.jp/docs/2003/0613/trident.htm
(2003年10月8日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.