
|


Baniasの目的は、CPUの効率を高め、消費電力あたりのパフォーマンスを高めることにある。そして、CPUの効率を良くする大きなポイントは、余計な命令実行を増やさないことだ。そのため、Baniasのマイクロアーキテクチャ(内部アーキテクチャ)では、効率化のための様々な仕組みが取り入れられている。
Intelは、9月10日から開催されている開発者向けカンファレンス「IDF(Intel Developer Forum) Fall 2002」の技術セッションで、Baniasのマイクロアーキテクチャの概要をかいつまんで説明した。
Baniasのアーキテクチャのポイントは大きく分けると4つある。
(1)ムダなマイクロOPs(Micro-OPs)の削減
・マイクロオプスフュージョン(Micro-Ops Fusion)
・スタック専用マネージャ(Dedicated Stack Manager)
(2)ムダな投機実行や分岐予測ミスの削減
・分岐予測の強化
・投機実行の最適化
(3)強力な電力管理
・細分化されたハードウェアクロックゲーティング
(4)拡張されたデータ供給
・低消費電力のFSB(フロントサイドバス)
・低消費電力の大容量L2キャッシュ
・改良されたプリフェッチ
この中でまず目立つのはBaniasがムダなMicro-OPsを徹底して削減していることだ。今のPC向けCPUは、x86命令をいったんデコードして内部命令(マイクロOPs:Micro-OPs)を生成する。CPUの実行ユニットが実際に実行するのは、そのMicro-OPsだ。Baniasでは、このMicro-OPsを減らす、つまりムダなMicro-OPsを発生させないことで省電力化を図る。
「それぞれのMicro-OPsがマシンリソースと電力を消費する。だからMicro-OPsを減らすことで効率を上げ、電力消費を抑える」と、IntelのOfri Wechsler氏(Director of CPU Architecture, Mobile Platform Group)は説明する。ムダなMicro-OPsがなくなれば、スケジューラや実行ユニットといったCPUリソースの消費が減り、その結果、パフォーマンス当たりの電力消費が抑えられるというわけだ。そのため、Baniasは今分かっている限りでは2つの技術を採用する。
・マイクロオプスフュージョン(Micro-Ops Fusion)
・スタック専用マネージャ(Dedicated Stack Manager)
 |
| Micro-OPs Fusion概念図 |
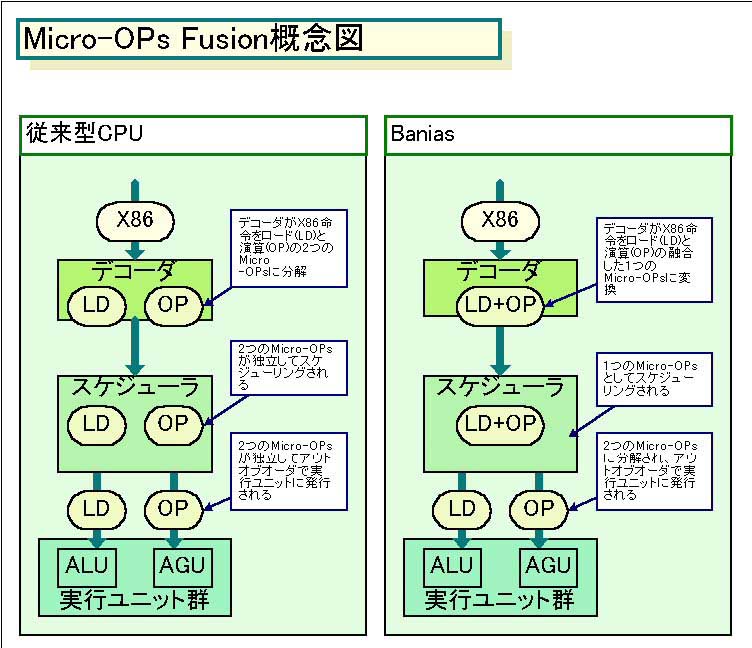
今のPC向けCPUは、RISCアーキテクチャの影響を受けており、x86命令をロードストア型アーキテクチャのMicro-OPsに分解するCPUが多い。つまり、x86命令には、メモリアクセスをともなう演算命令があるが、それをCPU内部でメモリアクセスMicro-OPsと演算Micro-OPsに分解してしまう。例えば、加算命令で、オペランドの片方がメモリ、もう片方がレジスタである場合、CPUはメモリからデータをロードして、それをレジスタの値に加算する処理を行う。そのため、今のCPUは、この命令を、ロードMicro-OPsと、加算Micro-OPsに分解する。
分解する目的は、並列化された演算ユニットで実行するスーパースカラ実行をする時に、円滑に処理できるようにするためだ。ロードストア型アーキテクチャのMicro-OPsに分解してしまえば、演算Micro-OPsは演算ユニットで、ロードやストアMicro-OPsはロードストアユニットでといったように、実行ユニットを役割ごとに単純化できる。各ユニットに対して、Micro-OPsを実行できる順番に発行するアウトオブオーダ(Out-of-Order)制御を行うことで、並列実行を行う。
この方法は非常に有効なのだが、難点もある。それは、x86命令を分解することでMicro-OPsが増えてしまうため、CPU内部のリソースやMicro-OPs帯域がより消費されてしまうことだ。つまり、ムダが多いわけだ。
そこで、Baniasでは、メモリアクセスをともなう演算命令を、デコーダの段階では2つのMicro-OPsに分解しない。メモリ操作と演算の2つのオペレーションを含むMicro-OPsを生成する。そして、実際に実行ユニットにMicro-OPsを発行する段階で、2つのMicro-OPsに分解して、実行する。つまり、デコーダから実行ユニットまでの間で、2つのMicro-OPsが占有するリソースを1つに減らすことができるわけだ(その意味で、Micro-OPs Fusionは、実際にはフュージョン(融合)というより、分解しないと言った方が合っている)。
Intelによると、これで10%のMicro-OPsを減らすことができるという。つまり、10%分、実行ユニットやスケジューラの効率が向上し、電力消費が減るわけだ。
Micro-OPs削減では有効なMicro-Ops Fusionだが、ある程度似たような技術はすでに存在する。それは、Athlon(K7)/Hammer(K8)系アーキテクチャだ。Athlon/Hammerも、メモリアクセスを含む演算命令は、ひとつのMicro-OPsに変換、実行時に2つのMicro-OPsに分解する。基本的なアプローチは非常に似ているように見える。
この手法のためにAthlon/Hammerでは、演算ユニットは整数演算ユニット(ALU)とロード/ストアアドレス生成ユニット(AGU)が1個づつペアになった、3組のユニットペアで構成されている。つまり、各ペアが演算Micro-OPsとメモリアクセスMicro-OPsの統合されたMicro-OPs1個に対応するようになっている。そして、各ペアの前に、Out-of-Orderのキュー(Hammerでは8段)があり、そこでMicro-OPsは待機する。
キューがあるのは、メモリアクセスMicro-OPsと演算Micro-OPsの間に依存関係がある場合があるからだ。先ほどの加算命令の例だと、ロードMicro-OPsを実行して、その結果を待って加算Micro-OPsを実行しなければならない。そのため、ロードMicro-OPsを実行したあと、実際にデータがロードされるまで、演算Micro-OPsはキューに待機している。
Athlon/Hammerはこの構造のため、ALUとAGUをそれぞれ3個づつ搭載するという冗長な構造になっている。では、Baniasの場合はどうなるのか。これについては、今回は何もヒントがない。しかし、Athlon/Hammerのような単純な構造ではないような気がする。
 |
| Dedicated Stack Manager概念図 |
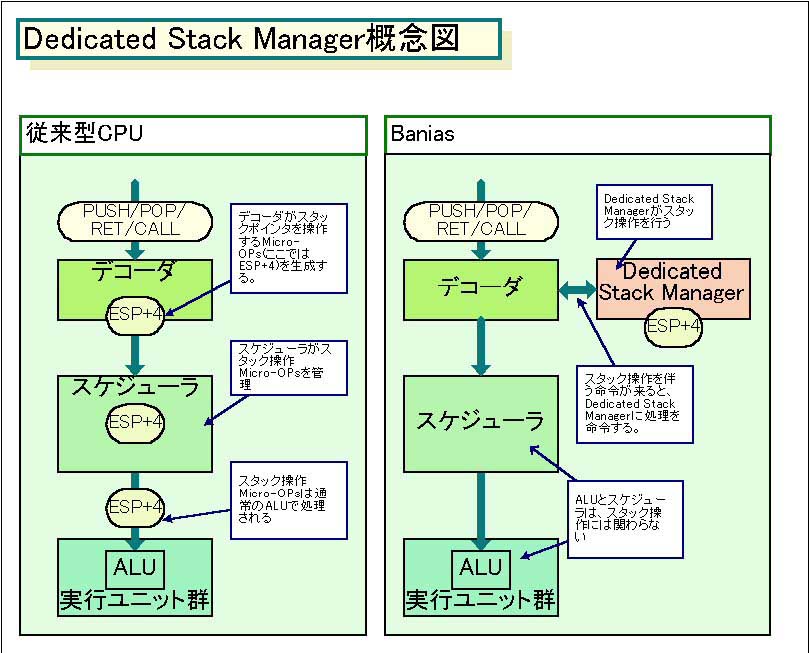
もともと、x86アーキテクチャの弱点は、煩雑なスタック操作のオーバーヘッドにあった。x86命令は、古い命令セットアーキテクチャであるため、スタック操作命令(PUSH、POP、RET、CALLなど)を多く使う。これらは、スタックポインタの操作を行う必要があるため、CPUの高速化上の妨げであるだけでなく、CPUの効率を下げていた。
「スタック操作は、典型的にはメインの実行ステップで処理されていた。デコーダはスタック操作のためのMicro-OPsを生成し、32bit ALUは、単にスタック操作のために動作していた。非常に非効率的なマシンリソースの使い方だった」とIntelのWechsler氏は説明する。
そこで、Baniasではスタック操作を専用に処理するハードウェアユニットを設けることで、この問題を解決する。つまり、スタック操作を伴う命令が来た場合、デコーダはスタック操作Micro-OPsを生成するのではなく、スタック操作専用に作られたDedicated Stack Managerと通信する。そして、Dedicated Stack Managerがスタック操作を行なうことで、ムダなMicro-OPs生成を削減する。また、Dedicated Stack Managerはスタック操作だけに特化して作られているため、ALUよりも消費電力が少ないというわけだ。
□関連記事
【9月12日】【海外】7,700万トランジスタを電力効率向上に費やす「Banias」
http://pc.watch.impress.co.jp/docs/2002/0912/kaigai01.htm
(2002年9月13日)
[Reported by 後藤 弘茂]