
|


●モバイルのM10はRV350の兄弟チップ
ATI Technologiesは、来年、4種類のDirectX 9.x世代GPUを計画していると推定される。うち2つは、前回のコラム「DirectX 9世代のGPU戦略~来年中盤までに5つのDirectX 9 GPUを投入するATI」で紹介した「R350」と「RV350」、そして残る2つはモバイル向けの「M10」と次世代GPUの「R400」だ。
まず、モバイルへの展開はATIにとっては当然の路線だ。というのは、ATIは通常、メインストリーム向けGPUをハイエンドモバイル向けにも投入するからだ。「新アーキテクチャは、最初ハイエンドで登場し、次にメインストリームにその派生品を展開、それをモバイルへも展開、その次に統合チップセットへも展開する」「RADEON 9700はハイエンドなので、モバイルは来年になる」とATIのJewelle Schiedel-Webb(ジュエル・シドルウエッブ)氏(Desktop Marketing)は説明する。例えば、7月に発表したDirectX 8世代のメインストリームデスクトップ向けGPU「RADEON 9000(RV250)」と8月に発表したモバイルGPU「MOBILITY RADEON 9000(M9)」は基本的にコアは同じだ。違いはLVDSのインターフェイスが載っているかどうかだけで、ダイ(半導体本体)もそこが違うだけという。
DirectX 9世代でも、このパターンは踏襲されるようだ。つまり、M10は、メインストリームデスクトップ向けのDirectX 9世代GPU「RV350」と、基本的に同じコアになると見られる。全体の流れは下の「ATI Technologies推定ロードマップ」図の通り。RV350と同様にM10は、次世代の0.13μmプロセスで、RV350に続いて登場する見込みだ。
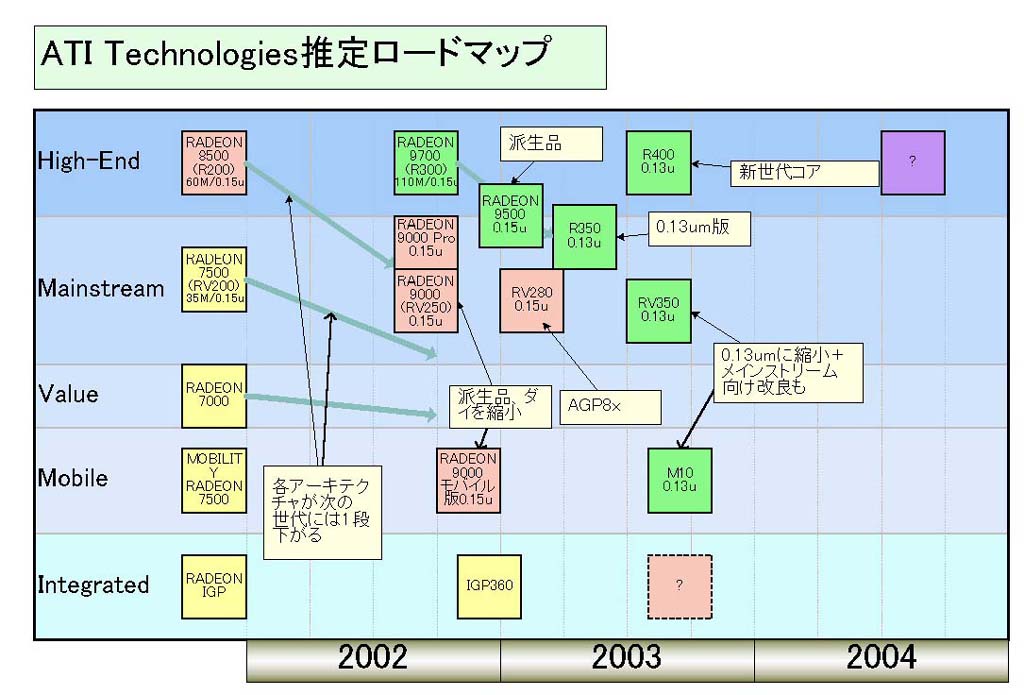 |
| ATI Technologies推定ロードマップ |
●モバイルで問題となる消費電力
モバイルGPUがメインストリームGPUと同じコアなのは、消費電力的にハイエンドノートPCに搭載できるぎりぎりがそのラインだからだ。一般に限界は、ピークで6~7W程度と言われる。その枠に対しては、トランジスタ数が多いハイエンドGPUだと、消費電力が高くなりすぎる。例えば、RADEON 9700(R300)は、Pentium 4(Northwood:ノースウッド)の2倍のトランジスタ数(約1億1,000万)なので、いくらPentium 4よりクロックが低い(1/8)と言っても消費電力は高い。
前回のコラムで説明したように、RV350/M10はR300よりパイプなどを削ってトランジスタ数をかなり減らすと見られる。さらに0.13μmプロセスに縮小することで、消費電力を下げ、ようやくモバイルにも持ってこれるようになると見られる。つまり、RV350/M10コアは、コストのためだけでなく消費電力のためにも、機能ユニット数をR300より減らしてトランジスタ数を削減しなければならないわけだ。
もっとも、M10でR300よりトランジスタ数を減らすといっても、M10のトランジスタ数はMOBILITY RADEON 9000(M9)よりは多くなる。またクロックも上がる。GPUのピークの消費電力は「電圧の二乗×クロック×キャパシタンス(+アクティブ時のリーク電流)」で決まるため、トランジスタ数とクロックの増加は、消費電力を押し上げることになる。
しかし、0.15μmから0.13μmへの移行で電圧とトランジスタ当たりのキャパシタンスが下がるため、この程度のトランジスタ数とクロックの向上なら、ほぼ相殺できることになる(ただしTSMCのハイスピード0.15μmプロセスの標準電圧は0.13μmと同じ)。
このように、従来ATIのモバイルGPUは、プロセス移行やトランジスタ数削減で消費電力を減らしてきた。例外はこのあいだ発表されたMOBILITY RADEON 9000(M9)で、ハイエンドだったRADEON 8500(R200)と比べて、それほどトランジスタ数は減っていないし、プロセス世代も同じ0.15μmだ。
RV250/M9のトランジスタ数は、ATIでも人によって5,000万台から6,000万までと説明に幅があるため、じつはよくわかっていない。RADEON 8500の6,000万以下であることだけは確かで、従来のMOBILITY RADEON 7500(M7)の3,500万と比べてかなり多い。プロセス世代は同じなので、原理的には消費電力は増大するはずだ。ただし、RV250/M9はRADEON 8500(R200)と比べるとダイ(半導体本体)がかなり小さくなっている。そのため、同じ0.15μmでもトランジスタサイズが小さい(キャパシタンスが小さい)ため、消費電力が減っている可能性がある。
GPUは平均消費電力に関しては、下げる余地がいくらでもある。というのは、消費電力を食うロジック部分のほとんどが3Dグラフィックスパイプだからだ。そのため、ブロック単位のクロックゲーティングとダイナミックな電圧&クロック切り替えで、かなりのところまで減らすことができる。
●まだ見えないR400の姿
ATIの次世代のDirectX 9.x GPU「R400」については、まだほとんどわかっていない。ほぼ明らかなのは、RADEON 9700(R300)を拡張したアーキテクチャで、RADEON 9700の1年後に登場することだ。より多くのトランジスタを費やすデザインになり、開発チームも交代する。
ATIは現在2チームが交代でGPUを開発する体制を敷いている。RADEON 9700(R300)やFlipper(ゲームキューブのGPU)を開発したのは西海岸のWest Team。RADEON 8500(R200)を開発したのは東海岸のEast Teamで、このチームがR400を担当すると見られている。基本の開発サイクルは24カ月ということになる。
R400のアーキテクチャ的な拡張でポイントとなるのは、NVIDIAのNV30のCineFXアーキテクチャ、つまりDirectX 9.1に相当する拡張を行なうのかどうかだ。GPUの開発サイクルは通常18~24カ月で、各メーカーともオーバーラップして開発している。そのため、1社が水面下で拡張を行なっていると、他社がそれに気が付いた時は、対応しようにも時間的に間に合わないケースが出る。DirectX 8.1の時のATIの独走がそれに当たる。アーキテクチャの拡張は、実際にはMicrosoftではなくGPUベンダーが引っ張っているため、場合によっては、2社で異なる拡張になる可能性もある。
R400は次世代と言っても、まだDirectX 10ではない。これにはふたつ理由がある。ひとつは、DirectX 10自体がまだ議論の最中で決まっていないことと、DirectX 10はおそらくさらに飛躍したトランジスタ数を必要とすることだ。そのため、DirectX 10は、プロセス技術も次のメジャー世代である90nm(0.09μm)にならないと難しいと推測される。
R400自体は時期を考えると0.13μmだと推測される。アーキテクチャもメジャーチェンジではないため、トランジスタ数とダイサイズもそれほどは増えないと思われる。ただし、この先のバージョンではプロセス縮小版(0.11xμmに相当)も出てくる可能性がある。
●2世代のギャップがある統合チップセットコア
統合チップセットのGPUコアに、ATIはバリュー向けGPUコアを使っている。つまり、世代的にはハイエンドGPUの2世代前に相当するアーキテクチャのコアを統合に使う。例えば、現在のRADEON IGPファミリはRADEON VE(RV100)相当のコアを使っており、RADEON 7500(RV200)相当コアに移行するのは今秋になる。そして、DirectX 8世代のRV250相当のコアを統合するのは来年になってからと推測される。
これには現実的な理由がある。バリュー価格帯で競争力のあるダイサイズ(半導体本体の面積)のチップセットにするには、そのクラスのコアでないと見合わないからだ。これは、メインストリーム向けGPUを統合チップセットのコアに使うNVIDIAと明確に戦略が分かれる点だ。ただし、NVIDIAは今年のメインストリームにDirectX 8世代GPUを持ってこなかったため、結果としてnForce2では2世代ギャップが開くようになってしまっている。
いずれにせよ、ATIの戦略は明確で、ハイエンドに最新アーキテクチャ、メインストリームとモバイルに1世代前のアーキテクチャ、ローエンドと統合チップセットに2世代前のアーキテクチャを持ってくる。この路線は2003年も継続され、「A5」に当たる統合チップセットでDirectX 8世代になると見られる。統合チップセットにDirectX 9が入ってくるのは、2004年になってからとなると推測される。
こうして、現在見えている限りのATIのロードマップを見ると、そこにはアグレッシブな戦略をじつに慎重に進める企業の姿が見えてくる。例えば、NVIDIAは以前のコラム「NVIDIAがDirectX 9世代のGPU NV30を今秋発表」でレポートしたように、DirectX 9世代へ一気にラインナップを塗り替えようとしているが、ATIは段階的に導入する。ATIの戦略は、典型的なウォーターフォール方式で、階段を1段づつ下りるように、テクノロジが1段づつステップして下の価格帯に降りてくる。これまでと違うのは、ステップダウンするスピードを速める点だけだ。
プロセス技術の移行も慎重で、無理なジャンプはしない。それよりは、チップの物理設計をチューンして、ダイサイズを小さくする方向へと進む。「RADEON 8500は、GeForce3より25%ほどダイサイズが小さいため、コスト上の利点がある。これだけダイを小さくできたのは、チップの物理設計を効率よくする努力をしてきたからだ。我々は非常にいい物理設計のチームを持っており、NVIDIAよりダイサイズを小さくできる」とATIのDavid E. Orton(デビッド・E・オートン)社長兼COOは語る。NVIDIAとは色々な意味で対照的な企業だ。
□関連記事
【9月9日】【海外】DirectX 9世代のGPU戦略
~来年中盤までに5つのDirectX 9 GPUを投入するATI
http://pc.watch.impress.co.jp/docs/2002/0909/kaigai01.htm
【9月6日】【海外】DirectX 9のスーパーセットとなるNV30
http://pc.watch.impress.co.jp/docs/2002/0906/kaigai01.htm
【9月5日】【海外】DirectX 9世代のGPU戦略
~0.13μmに賭けるNVIDIA
http://pc.watch.impress.co.jp/docs/2002/0905/kaigai01.htm
【9月4日】【海外】プロセッサ化へと向かうシェーダアクセラレータ時代のGPU
http://pc.watch.impress.co.jp/docs/2002/0904/kaigai01.htm
【8月6日】【海外】NV30はまだ設計完了していないとATIが指摘
http://pc.watch.impress.co.jp/docs/2002/0806/kaigai01.htm
(2002年9月10日)
[Reported by 後藤 弘茂]