
|


●RADEON 9700の後続に5つのDirectX 9世代GPU
NV30ファミリで巻き返しを狙うNVIDIA。しかし、ATI Technologiesにこれだけ水を開けられたそのハンディキャップは大きい。逆に、ATIにとっては首位を奪う千載一遇のチャンスとなる。では、ATIの次の手はどうなっているのだろう。
DirectX 9世代GPUでは、ATIの戦略もNVIDIAに負けずアグレッシブだ。ATIは、今年末から来年中盤にかけて、「RADEON 9500」「R350」「RV350」「M10」「R400」の5つのDirectX 9.x世代GPUの投入を計画していると推測される。その結果、メインストリーム(ビデオカード価格価格99~199ドル)市場へもDirectX 9世代が急速に浸透するだろう。
まず、ATIは現在、RADEON 9700系(R300)の派生品(derivative)「RADEON 9500」を今年第4四半期に投入することを公式に明らかにしている。ATIは、RADEON 9500がハイエンドのRADEON 9700よりやや下の層を狙うと説明している。おそらく、ボード価格が200ドル台で、RADEON 9000との間のギャップを埋める製品と推測される。RADEON 9700とATIロードマップについては、現在発売中の「DOS/V PowerRoport 10月号」でも詳しく説明している。
RADEON 9500は、RADEON 9700発表前にはウワサがなかったGPUであり、0.15μmであること以外、内容はわからない。しかし、位置づけからするとRADEON 9700の機能削減版である可能性が高い。いずれにせよ、RADEON 9500は、ATIの次の本命ではなく、中間解なのは確かだ。
●ATIは来年前半に0.13μm世代へ
ATIのメインストリーム向けDirectX 9 GPUの本命は、次の0.13μm世代だ。「0.13μmは、次の世代、次のリビジョンとなるだろう。来年前半なら可能になると考えている」とATIのK. Y. Ho(KY・ホー)会長兼CEOは説明する。
ATIはNVIDIAと同じファウンダリTSMCをメインに使っているが、常にNVIDIAよりプロセス技術については慎重だ。下の図「ATIとNVIDIAのハイエンドGPUのプロセス技術」のように、ハイエンドGPUでの最先端プロセスの導入は1~3四半期遅れとなる。今回も0.13μmはNVIDIAの方が早いと思われるが、以前と比べると差は詰まっている。これは、NVIDIAの計画が後ろへずれ込んだためだ。
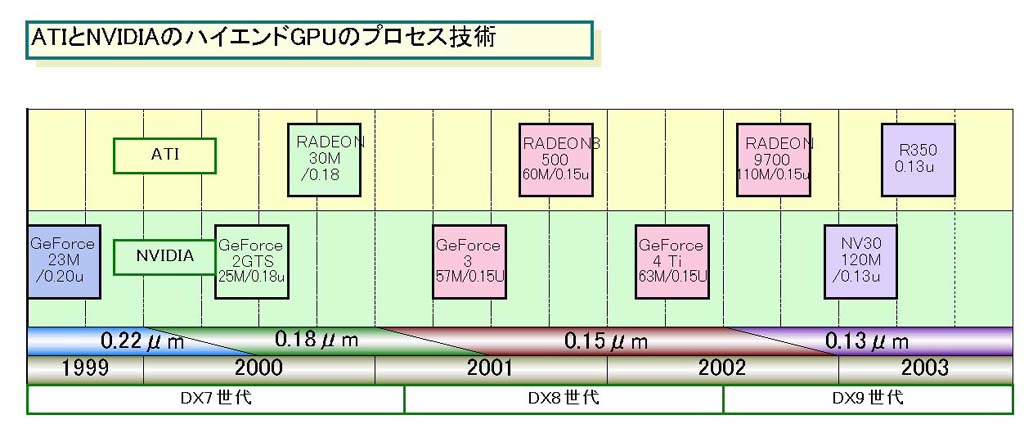 |
| ATIとNVIDIAのハイエンドGPUのプロセス技術 |
ATIの0.13μm世代については、以前のコラムでも推測を書いたが、今では複数のプランがあることがほぼ明らかになっている。下の図「ATI Technologies推定ロードマップ」にあるR350、RV350、M10、そしてR400だ。ATIのDavid E. Orton(デビッド・E・オートン)社長兼COOは次のように語る。
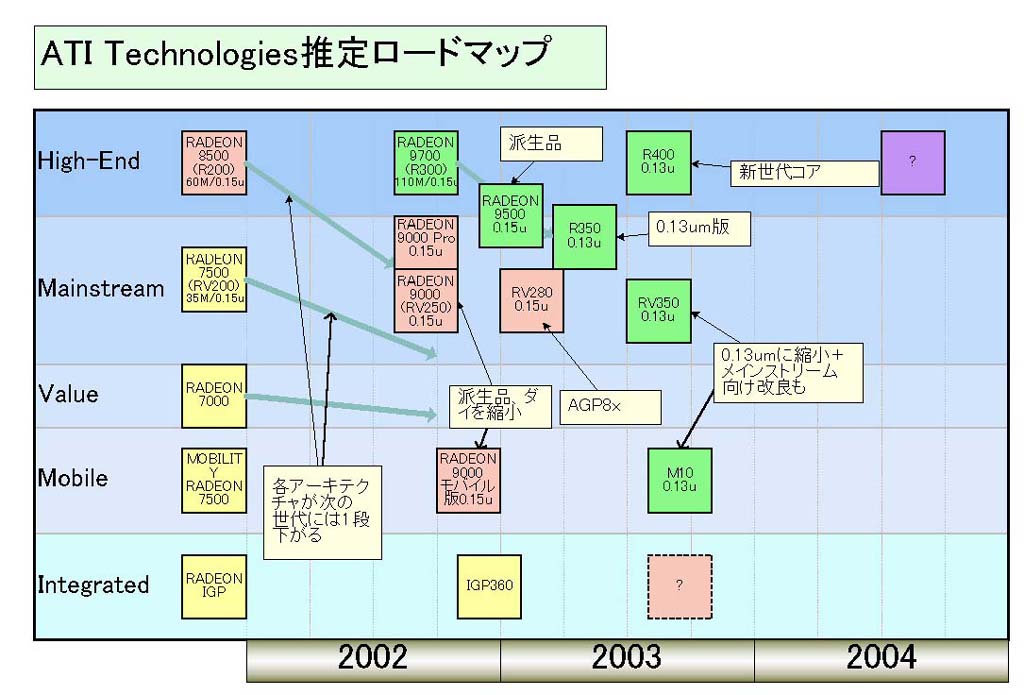 |
| ATI Technologies推定ロードマップ |
「我々は次世代、R350とか(kinda)の製品で0.13μmへ移って行く。RADEON 9700をメインストリームへ持って行くためにはおそらく0.13μmが必要だからだ。もう1つ考えているのは、RADEON 9700の一種の拡張バージョンを実現することで、これも実質的なチャンスは0.13μmへ移行する時になるだろう。RADEON 9700は、新世代グラフィックスの土台であり、今後、さらに機能を加えたり、高速化するなど成長の余地がある」
以前のコラムではR350はメインストリーム向けのアーキテクチャになると推測していたが、どうやらR350自体はRADEON 9700を、ほぼそのまま0.13μmに移行したバージョンらしい。理由の1つはATIのコードネーム規則の場合、ハイエンド製品が“Rxxx”で、メインストリーム向け製品は“V”がついた“RVxxx”になるからだ。つまり、メインストリーム製品ならRV350でなければならない。
また、ATIはどうやら0.15μmと0.13μmの物理設計をかなりオーバーラップさせて走らせていた形跡がある。つまり、0.13μmプロセスが安定したら、すぐに移行できるように準備しているようだ。
●0.13μm化でダイサイズは約150平方mmに
ATIが0.13μmを急ぐ最大の理由はダイサイズ(半導体本体の面積)だ。0.15μmで製造するR300(RADEON 9700)は、約14.6mm角で約200平方mmの巨大チップとなっている。コンシューマ向けGPUでは、おそらく過去最大のサイズだ。チップサイズは歩留まり(同じDefect Density[欠陥密度]のウエーハならダイが大きいほど歩留まりが悪くなる)に影響するため、R300はかなり高コストだ。「チップサイズが2倍になると、コストは2倍ではなく4倍になる」とTrident MicrosystemsのLe Trong Nguyen氏(Assistant Vice President, Graphics Marketing)は語る。
では、R300をそのまま0.13μmに移行したらダイサイズはどうなるか。計算上は0.15μm→0.13μmではリニアに87%に縮小するため面積では75%に縮小することになる。そうすると、R300の0.13μm版と推測されるR350のダイサイズは約150平方mmとなる。これは、下の「ATI GPUのダイサイズ推定図」のように、NVIDIAのハイエンドGPUよりちょっと大きい程度のサイズで、0.13μmの欠陥密度が下がれば、ハイエンドからメインストリームの高価格帯向けGPUとしては十分利益を上げられるレベルだ。
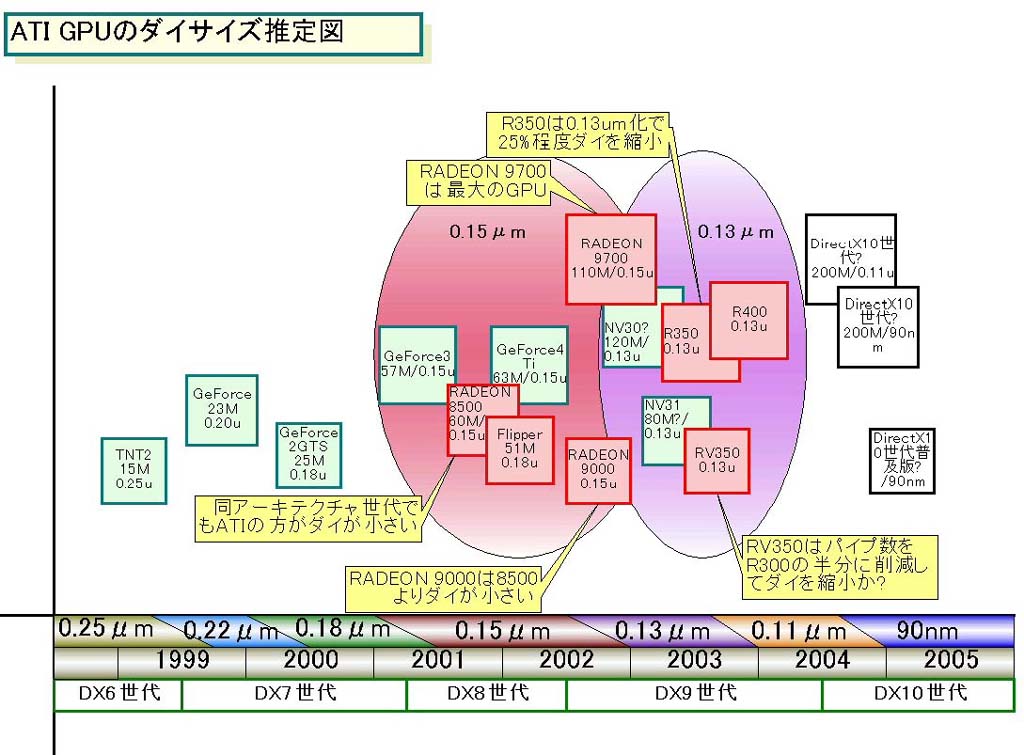 |
| ATI GPUのダイサイズ推定図 |
ちなみに、NVIDIAはATIより同じプロセスでもダイサイズが大きいため、NV30はR350より大きなチップになると推測される。もし、NVIDIAがNV30を0.15μmで設計していたら、200平方mmを超えるサイズになり、経済的に成り立たなかったと推測される。
だが、メインストリームGPUは、ボード価格で99~199ドルのレンジに納めるため、150平方mmクラスよりもさらに小さいダイサイズが求められる。例えば、現在のATIのメインストリームGPU「RADEON 9000(RV250)」のダイは、100平方mm程度かそれ以下と推測される。Orton氏は、「RADEON 9000は(ハイエンドの)RADEON 8500よりテクスチャユニットとVertex Shaderの数を削った。その結果、トランジスタ数は減り、面積は、RADEON 8500より約25%小さくなった」「RADEON 9000は、Flipper(ゲームキューブのGPU、109平方mm)よりも小さい」と説明している。単純計算でも、1億1,000万トランジスタのR300(RADEON 9700)が200平方mmなら、その半分程度で同じ0.15μmプロセス技術のトランジスタ数のRV250(RADEON 9000)は100平方mmクラスとなる。
●RV350のダイサイズはRADEON 9000と同程度か
メインストリームGPUが100平方mm以下のダイサイズを必要とするとなると、R300系アーキテクチャでメインストリームを狙うGPUは、ダイサイズを減らすため、必ずR300から何かを削減しなければならない。実際、ATIもその方向にあることを認めている。
「メインストリーム向け製品は99~199ドルのボード販売価格となる。そのため、ハイエンド製品の機能は保ちながら、メインストリーム向けにアーキテクチャを絞って行くことを考えている」とATIのJewelle Schiedel-Webb(ジュエル・シドルウエッブ)氏(Desktop Marketing)は説明する。
削るとしたら一番に考えられるのはピクセルパイプの本数だ。DirectX 9のピクセルパイプは、浮動小数点をサポートしたため巨大な面積(ダイ写真上では約40%)を取っている。R300の8パイプを、RV350で4パイプに減らせば、原理的には約20%程度ダイを縮小できる。さらに、Vertex Shaderも4個から2個に減らし、メモリインターフェイスを256bit幅から128bit幅にすると、60~70%程度にはダイを削れそうだ。そうすると、計算上は約100平方mm前後のダイサイズに納めることができるようになる。トランジスタ数的には7,000万程度だと推測される。
また、メインストリームGPUでは、メモリインターフェイスはダイサイズ以外の理由からも128bit幅でなければ成り立たない。「200ドル以下のメインストリーム向けGPUは、128bitインターフェイスに今後も長期間留まるのは確実だろう。そうしないと、メモリコストとGPUのパッケージコストが高くなってしまう」(MatroxのDan Wood副社長、Technical Marketing) からだ。
まず、パッケージはピン数が増えるとコストがぐっと上がる。「RADEON 9700では、フリップチップ実装にしなければならなかった。1,100ピンになったためだ。電力と信号速度を考えたら、インダクタンスを減らすためにフリップチップにする必要があった。つまり、電気的な理由だ」とOrton氏は語る。
メモリは、インターフェイス幅が2倍になると、必要な最小チップ数も2倍になってしまう。そのため、ローコストボードがつくりにくい。例えば、R300だとx32の128Mbit DRAMチップを使っても8個構成で最小128MBになってしまう。4個構成の64MBのボードができない。
このRV350は、ダイサイズ/市場的にはNVIDIAのNV31と競合することになる。また、DirectX 9世代では、このレンジに、SiS(Silicon Integrated Systems)やTrident Microsystems、S3 Graphicsなども製品を来年投入してくる。そのため、厳しい価格競争にさらされることになる。ATIは真剣にコスト削減を図ってくるだろう。
では、ATIのDirectX 9世代のモバイルと統合チップセットはどうなるのだろう。それは次のコラムで説明したい。
□関連記事
【9月6日】【海外】DirectX 9のスーパーセットとなるNV30
http://pc.watch.impress.co.jp/docs/2002/0906/kaigai01.htm
【9月5日】【海外】DirectX 9世代のGPU戦略
~0.13μmに賭けるNVIDIA
http://pc.watch.impress.co.jp/docs/2002/0905/kaigai01.htm
【9月4日】【海外】プロセッサ化へと向かうシェーダアクセラレータ時代のGPU
http://pc.watch.impress.co.jp/docs/2002/0904/kaigai01.htm
【8月6日】【海外】NV30はまだ設計完了していないとATIが指摘
http://pc.watch.impress.co.jp/docs/2002/0806/kaigai01.htm
(2002年9月9日)
[Reported by 後藤 弘茂]