
|
|
2月5日(現地時間)発表
会場:Palace of Fine Arts Museum
米NVIDIAは、2月5日(米国時間)にサンフランシスコ市内で記者会見を開催し、これまでコードネーム“NV25”で知られてきた次世代ビデオチップをGeForce4 Tiとしてハイエンド市場へ、さらにコードネーム“NV17”で知られてきたビデオチップをGeForce4 MXとしてメインストリーム市場へ投入することを明らかにした。本記事ではGeForce4 TiとGeForce4 MXで採用された新機能、およびチップの詳細などについて紹介していこう。
●「前世代に比べて4倍以上のパフォーマンスゲインがある」とNVIDIAのタマシ氏
 |
| NVIDIAの社長兼CEOのジェンスン・フアン氏 |
最初に壇上に登場したのはNVIDIAの社長兼CEOのジェンスン・フアン氏で、「NVIDIAが設立されてから7年になる。この間我々のビジネスは成長を続け、歴史上最も早く売上高が10億ドルに達した半導体メーカーとなった。我々の次のゴールは20億ドルを達成することだ」と述べ、NVIDIAのビジネスが好調に推移ししていることを強調した。
続いてラインナップについて言及し「昨年我々は、デスクトップPC向けのGeForce3ファミリー、GeForce2 MXファミリー、ワークステーション向けのQuadoraファミリーに加えて、モバイル向けのGeForce2 GO、さらにはプラットフォームとしてnForceを投入した。これによりすべてのセグメントのユーザーにビジュアルコンピューティング環境を提供できるようになった。今日発表する新製品は、それをさらに加速してくれるだろう」と述べ、GeForce4ファミリーにより、ユーザーにより高いレベルの3D描画能力を提供できるようになると語った。
 |
| NVIDIAデスクトップ製品関連の責任者であるデスクトッププロダクトディビジョンジェネラルマネージャのトニー・タマシ氏 |
続いて、NVIDIAデスクトッププロダクトディビジョン ジェネラルマネージャのトニー・タマシ氏が壇上にあがり、GeForce4ファミリーに関する詳細を説明した。その中でタマシ氏は「GeForce4ファミリーは前世代のGeForceに比べて4倍のパフォーマンスゲインがある。さらに、新しいアンチエリアシングはより自然な高いクオリティの3Dを提供可能にし、さらに新しいマルチディスプレイの機能であるnViewはユーザーの使い勝手を大きく改善する」と述べ、GeForce4ファミリーが、前世代のGeForce3やGeForce2 MXなどに比べて大幅な性能改善が図られているとアピールした。
●バーテックスシェーダーを2つ搭載したnfinite FX IIエンジン
今回発表されたGeForce4ファミリーには“nfinite FX II”、“Lightspeed Memory Architecture II”、“Accuview AntiAliasing”、“nView”という4つの新しい技術が搭載されている。
nfinite FXエンジンとはGeForce3で導入されたプログラマブルなバーテックスシェーダとピクセルシェーダ機能のことで、DirectX 8でサポートされた新しいファンクションだ。ゲーム開発者は、このプログラマブルバーテックスシェーダ、ピクセルシェーダを利用することで、よりリアリティのある3D画面を作り上げることができる。今回、NVIDIAはnfinite FX IIエンジンを採用するに当たり、2つの点を強化している。
まず、バーテックスシェーダのエンジンを2つ搭載したことにより、nfinite FXエンジンに比べて性能が2倍になっている。また、ピクセルシェーダもZコレクトバンプマッピングなどの新しい機能に対応することで、前世代に比べて50%の性能向上が見られるという。なお、このnfinite FXエンジンはGeForce4 Tiシリーズにのみ搭載されており、GeForce4 MXにはDirectX 8でサポートされるソフトウェアによるバーテックスシェーダのみがサポートされ、ピクセルシェーダはサポートされない。
Lightspeed Memory Architecture II(LMA II)とは、GeForce3で搭載されたLightspeed Memory Architecture(LMA)の改良版だ。最近のビデオチップでは、Zバッファなどの効率を改善することにより、ビデオメモリの帯域幅の実効レートを上げようというアプローチがトレンドになっている。その理由は、現代のビデオチップのボトルネックが、ビデオメモリの帯域幅にあるからだ。
実際にベンチマークなどをしてみるとわかるのだが、低い解像度ではビデオチップがフルに性能を発揮できるのだが、ビデオメモリの帯域幅を消費する高解像度では、ビデオメモリの帯域幅がボトルネックとなってしまい、一定以上になると性能が上がらなくなる。つまり、ビデオチップの持つ本来の性能が発揮できなくなるのだ。そのため、ビデオチップベンダは、メモリの帯域幅を上げるために競って高いクロックのメモリチップを採用しているが、それもある一定で限界があり、それをソフトウェア側で補う必要がある。それがLMAのようなアプローチだ。
これはNVIDIAに限ったことではなく、ATI TechnologiesはHYPER Z、HYPER Z IIなどの似たようなアプローチをRADEONシリーズで採用している。NVIDIAのLMAもHYPER Zと同じようにZバッファの圧縮を行なったりするなどしてメモリの帯域幅の消費を押さえるアプローチが試みられている。GeForce4に搭載されているLMA IIでは、複数のコントローラが複数のメモリチップにアクセスすることでより実行帯域幅を高める改良版CrossBarなどにより効率が高められており、GeForce3に比べて50%の効率改善、GeForce2に比べると実に100%の効率が改善されているという。
●改良されたアンチエリアシングのAccuview Antialiasingでクオリティを大きく改善
また、Accuview Antialiasingでは、アンチエリアシングの改良により3Dクオリティの向上を狙う。3D画面は、ピクセルとよばれる点の集合で描かれている。このため、斜めの線を描画するとそれが階段状に見えたりしてしまう。いわゆるジャギーと呼ばれるギザギザな画面になってしまうのだ。言うまでもなくジャギーが発生すると不自然な画像になってしまうため、これにエフェクトをかけてジャギーがでないように処理を行なう。これをAntiAliasing(AA)と呼んでいる。
 |
| GeForce4でアンチエリアシングをオンにしても、アンチエリアシングをオフにしたGeForce3を上回る |
これまでのビデオチップでもAAのエンジンは搭載されていたが、たいていのユーザーはAAをあまり使わずに利用しているのではないだろうか? その理由はAAをオンにすると、処理が重たくなり3Dアクセラレータとしてのパフォーマンスが低下するからだ。
例えば、AA処理のテクニックでスーパーサンプリングという手法がある。簡単に言えば、実際に目に見える解像度よりも高い解像度でピクセルを描画し、ジャギーなどの発生を抑えるというものなのだが、例えば2倍の解像度で行なう2xのスーパーサンプリングの場合、2倍のフレームバッファやメモリ帯域幅を消費するし、4xモードではもちろん4倍になる。これでは、GPUがどんなに高速でも、ビデオメモリの帯域がどんなにあっても、グラフィックスサブシステム(GPUやビデオメモリ)の性能は1/2や1/4になってしまう訳で、グラフィックスサブシステムの性能が高くなければ実用にはならない。
そこで、Accuview Antialiasingではマルチサンプリングと呼ばれる手法を利用している。マルチサンプリングとは、各フレームで複数のサンプルをレンダリングし、それらをサブピクセルレベルで組み合わせ、そのサブピクセルをフィルタリングすることで、AAを実現する方式のことだ。これにより、スーパーサンプリングに比べてリソースの消費が少なく、性能的にもメリットがある。
マルチサンプリング自体はGeForce3も備えており、2x、4x、Qunicunxというモードを持っていたが、今回のAccuview Antialiasingエンジンで4XSモードというモードが追加されている。4XSサンプリングモードではAAの最後のステージで、グラデーション処理を行なうことにより、より自然なAA処理が可能になるモードで、より3D描画品質をあげることができる。
NVIDIAによれば、これらの新しいアーキテクチャにより、GeForce4ファミリーはAA有効時の性能が特に優れているという。例えば、GeForce4 TiのAA有効とGeForce3のAA無効を比較した場合、AAが有効であるにもかかわらず、GeForce4 Tiが大きく上回るという。
●改良されたマルチディスプレイのソリューションのnView
 |
| nViewのデモ。Windows Media Playerでウインドウ内に表示されているビデオを、セカンダリディスプレイではフルスクリーンで再生している |
また、使い勝手の点で拡張された機能としてマルチディスプレイ機能「nView」がある。GeForce4には、マルチディスプレイを容易に実現する機能がいくつか追加されている。例えば、デジタル信号をCRTのアナログ信号に変換するDAC(Digital-Analog Converter)は2つ内蔵されており、アナログRGB出力が2つというビデオカードを、特にチップの追加などを行なわずに実現することができる。理論的には最大で16台までのディスプレイを接続することが可能であるとしている(もちろん、ボード上にそんなにディスプレイ出力をつけるのは不可能であるから、あくまで理論的にはということだ)。
ユニークなのはソフトウェアによるファンクションで、例えばセカンダリのディスプレイに、Windowsのダイアログだけを出力させるようにしたり、セカンダリ側のウインドウを透明化して、プライマリ側のウインドウと重ねるように表示したりとユニークな機能が特徴となっている。
●ハイエンド向けのGeForce4 Ti、メインストリーム向けのGeForce4 MX
さて、昨日の速報でもお伝えしたとおり、GeForce4には、ハイエンド向けのGeForce4 Tiシリーズ、メインストリーム向けのGeForce4 MX、ノートPC向けのGeForce4 GOという3つのシリーズが用意されている(なお、ノートPC向けのGeForce4 GOに関しては別の機会で詳しく解説したい)。
表1は各製品に用意されているモデルのコア、メモリなどの仕様だ。速報記事では、GeForce Ti 4600のコアクロック仕様を330MHzとしていたが、これは誤りで、正確には300MHzとなっている。お詫びして訂正させていただきたい。また、上記で紹介した新機能が、各ファミリーでどのようにサポートされているかを示したのが表2だ。
【表1】
| グラフィックスコア | ビデオメモリ | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| コアアーキテクチャ | パイプライン/パイプラインあたりのテクスチャユニット | コアクロック | フィルレート | メモリクロック | メモリ | メモリバス幅 | メモリ帯域幅 | メモリ最大容量 | |
| GeForce4シリーズ | |||||||||
| GeForce4 Ti 4600 | NV25 | 4P/2T | 300MHz | 2.4Bテクセル/Sec | 330MHz | DDR SDRAM | 128bit | 10.4GB/Sec | 128MB |
| GeForce4 Ti 4400 | NV25 | 4P/2T | 275MHz | 2.2Bテクセル/Sec | 275MHz | DDR SDRAM | 128bit | 8.8GB/Sec | 128MB |
| GeForce4 MX 460 | NV17 | 2P/2T | 300MHz | 1.2Bテクセル/Sec | 275MHz | DDR SDRAM | 128bit | 8.8GB/Sec | 128MB |
| GeForce4 MX 440 | NV17 | 2P/2T | 270MHz | 1.1Bテクセル/Sec | 200MHz | DDR SDRAM | 128bit | 6.4GB/Sec | 64MB |
| GeForce4 MX 420 | NV17 | 2P/2T | 250MHz | 1Bテクセル/Sec | 166MHz | SDRAM | 64bit | 2.7GB/Sec | 64MB |
| GeForce4 440 GO | NV17M | 2P/2T | 250MHz | 1Bテクセル/Sec | 250MHz | DDR SDRAM | 128bit | 8GB/Sec | 64MB |
| GeForce4 420 GO | NV17M | 2P/2T | 200MHz | 0.8Bテクセル/Sec | 200MHz | DDR SDRAM | 64bit | 3.2GB/Sec | 64MB |
| 前世代のチップ | |||||||||
| GeForce3 Ti 500 | NV20 | 4P/2T | 240MHz | 1.92Bテクセル/Sec | 250MHz | DDR SDRAM | 128bit | 8GB/Sec | 64MB |
| GeForce3 | NV20 | 4P/2T | 200MHz | 1.6Bテクセル/Sec | 230MHz | DDR SDRAM | 128bit | 7.36GB/Sec | 64MB |
| GeForce3 Ti 200 | NV20 | 4P/2T | 175MHz | 1.4Bテクセル/Sec | 200MHz | DDR SDRAM | 128bit | 6.4GB/Sec | 64MB |
| GeForce2 MX 400 | NV11 | 2P/2T | 200MHz | 0.8Bテクセル/Sec | 166MHz | DDR SDRAM/SDRAM | 64bit/128bit | 2.7GB/Sec | 64MB |
| GeForce2 MX 200 | NV11 | 2P/2T | 175MHz | 0.7Bテクセル/Sec | 166MHz | SDRAM | 64bit | 1.36GB/Sec | 32MB |
| GeForce2 MX | NV11 | 2P/2T | 175MHz | 0.7Bテクセル/Sec | 166MHz | DDR SDRAM/SDRAM | 64bit/128bit | 2.7GB/Sec | 64MB |
【表2】
| GeForce4 Ti | GeForce4 MX | |
|---|---|---|
| nfinite FX II | ○ | - |
| Lightspeed Memory Architecture II | ○ | ○ |
| Accuview Antialiasing | ○ | ○ |
| nView | ○ | ○ |
| VPE | - | ○ |
・ハイエンド向けGeForce4 Ti
 |
| GeForce4 Ti 4600 |
NV20コアのGeForce3からNV25コアになったGeForce4だが、GPUそれ自体という意味ではあまり大きな手は入れられていない。レンダリングエンジンは、4パイプラインで、パイプラインあたりのテクスチャユニットは2ユニットで、都合1クロックで8テクセルとなっている。これはNV20と変更はなく、GPUとしての基本性能を大きく左右するコアアーキテクチャは大きな変化がないといってよい。
性能面に与える大きな変更点は、コア、メモリのクロックだ。最上位モデルのGeForce4 Ti 4600はコアクロックで300MHzと、GeForce3 Ti 500の240MHzから大きくあがっている。このため、GPUの性能の1つの指標であるフィルレートは、GeForce3 Ti 500が19.2億テクセルであったのに対して、GeForce4 Ti 4600は24億テクセルと処理能力が向上している。
また、同じようにメモリクロックもGeForce3 Ti 500が250MHz(DDR)で帯域幅が8GB/Secであったのに対して、GeForce4 Ti 4600は330MHz(DDR)に引き上げられており、帯域幅は10.4GB/Secと大きく改善している。特にビデオメモリの帯域幅が性能に与える影響が大きい高解像度におけるパフォーマンスが改善されている可能性が高い。また、メモリの容量が最大で128MBにすることが可能になったため、大容量のビデオメモリを必要とするAAの処理などでは前世代に比べて高いパフォーマンスを発揮する可能性が高い。
【GeForce4 Ti 4600の場合】
| フィルレート | メモリ帯域幅 | |
|---|---|---|
| GeForce3 Ti 500 | 19.2億テクセル/Sec | 8GB/Sec |
| GeForce4 Ti 4600 | 24億テクセル/Sec | 10.4GB/Sec |
| 上昇率 | 25%アップ | 30%アップ |
・メインストリーム向けGeForce4 MX
 |
| GeForce4 Ti 4600 |
NV17コアのGeForce4 MXも、レンダリングエンジン自体は2パイプライン、パイプラインあたり2テクスチャユニットで都合1クロックで4テクセルと、NV11コアのGeForce2 MXと変わりはない。Tiシリーズのように、プログラマブルなバーテックスシェーダやピクセルシェーダの機能であるnfinite FX IIエンジンが搭載されていないのも前述の通りだ。
だが、GeForce4 MXは性能面に影響を与える大幅な拡張がされている。それがDDR SDRAM利用時にメモリバス幅を128bitできるようになったことだ。これはパフォーマンスに与える影響は非常に大きい。GeForce2 MXでは、DDR SDRAMを利用した場合、メモリバスのバス幅は64bitに制限されていた(SDRAMを利用した場合には128bit構成にすることができた)。
このため、GeForce2 MXの最上位モデルのGeForce2 MX 400でも、166MHzのDDR SDRAM(実際には333MHz相当)を利用した場合、333MHz×64bit=2.7GB/Secという帯域幅と、上位モデルのGeForce3 Ti 500が8GB/Secを実現していたのに比べて帯域幅は十分とは言えなかった。ところが、GeForce4 MX 460では、270MHz(実際には540MHz相当)のDDR SDRAMを128bit接続することができるため、帯域幅は540MHz×128bit=8.8GB/Secとなり、かなりGeForce4 Tiシリーズに近づいている。前世代との比較を表にしてみると、GeForce4 MXがいかに性能が向上しているかがわかる。
【GeForce4 MX 460の場合】
| フィルレート | メモリ帯域幅 | |
|---|---|---|
| GeForce2 MX 400 | 8億テクセル/Sec | 2.7GB/Sec |
| GeForce4 MX 460 | 12億テクセル/Sec | 8GB/Sec |
| 上昇率 | 50%アップ | 196%アップ |
特にメモリの帯域幅に関しては200%に近い性能向上を見せており、メモリの帯域幅がきいてくる高解像度では、GeForce2 MXを圧倒的に上回る処理能力を示す可能性が高いといっていいだろう。
NVIDIAが記者会見で公開したデータによれば、GeForce4 MX 460のベンチマークのスコアは、QuakeIII Arena(1,280×1,024ドット、32ビットカラー、2×FSAAオン)で67.7とGeForce2 MX 400の15.5に比べて4.3倍、3DMark2001(1,280×1,024ドット、32ビットカラー、2x FSAAオン)で2,692とGeForce4 MXの821に比べて3.3倍となっている。
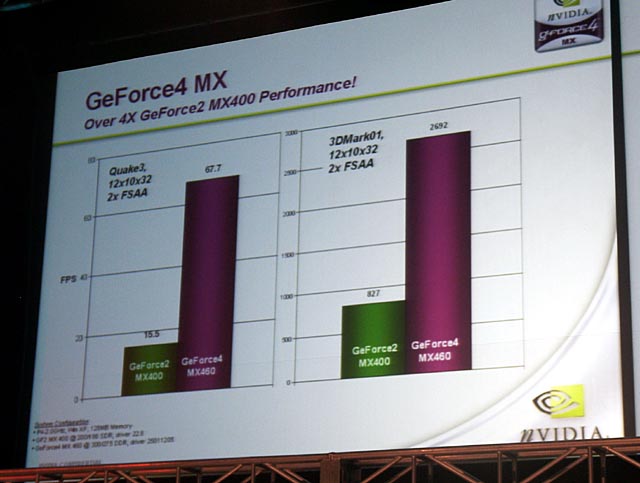 |
 |
| GeForce4 MX 460とGeForce2 MX 400を比較したグラフ | GeForce4 MXに採用されているNV17コアのブロック図 |
●どちらを買うかは何を重視するか次第
以上のように、見てくると、GeForce4 Tiシリーズはどちらかと言えば、AA時に高いクオリティを実現するのに振った、つまりFSAAを使わなければメリットが見えてこない製品、GeForce4 MXはビデオメモリの128bit化により総合的な性能が向上した製品という今回のGeForceファミリーの性格がわかってくる。
確かに、FSAA(Full Screen Anti Aliasing)を利用することで、描画クオリティは確かに高くなる。これまでは、GPU自体の性能も足らなかったので、あまりFSAAをオンにしているというユーザーも多くなかったと思うが、GeForce4 Tiでは、それをオンにしても性能が低下しないというところが売りになるだろう。ビデオカードのターゲット価格も、Ti 4600で399ドル(日本円で約5万円強)、Ti 4400で299ドル(同4万円弱)は決して安価ではなく、この点をどう評価するかがGeForce4 Tiを購入するかどうかの分かれ目となるだろう。なお、NVIDIAのOEMメーカー筋によれば、Tiシリーズの量産は2月末あたりから開始されるそうで、3月には流通が開始される可能性が高い。
これに対して、GeForce4 MXでは、すでに述べたように、大きな性能向上が期待できる。特に、メモリの128bit化は、高解像度においてメリットが大きい。ビデオカードのターゲット価格もMX 460で149ドル(日本円で2万円弱)、MX 440で129ドル(同1万7千円前後)はコストパフォーマンスが高く、多くのユーザーにとってはこちらがターゲットになる可能性が高い。既にMX 440を搭載したビデオカードは流通が開始されており、PCショップの店頭に並び始めている。MX 460搭載ビデオカードは1カ月近く遅れて3月以降の出荷となる模様だ。
□NVIDIAのホームページ(英文)
(2002年2月7日)
[Reported by 笠原一輝@ユービック・コンピューティング]