
【短期集中連載】大原雄介の最新インターフェイス動向
~PCI Express 3.0編その4
●Atomic Read-Modify-Write
今回取り上げるのはAtomic Read-Modify-Writeである。これはCPUとデバイス間、将来的にはデバイス同士の間で調停を取るためのメカニズムである。従来、こうした仕組みはCPU側で、それもOS内部でクリティカルセクションなどを用意し、特権命令で排他制御をしながら実装されるのが普通だった。もっともこれは当然ながらプロセス間やプロセス-OS間の同期が目的だ。デバイスとの同期は通常ドライバが取るのが普通だし、デバイス同士で同期を取るというケースは殆ど考える必要が無かったからだ。
ところがPCI Expressの高速化もあって、ある種のアクセラレータを使う可能性が非常に高まりつつある。手近なところではGPGPUがその最右翼だろう。OpenCLなどの追い風もあり、さまざまなアクセラレータをPCI Express経由で利用するというケースは今後どんどん増えてくると思われる。AMDはStream Computingと銘打ち、1台のマシンに複数枚のATI FireStreamを搭載した事例を既に紹介している。こうしたケースでは
・常にCPUが全てのアクセラレータの実行を監視/制御すれば排他制御などの問題は発生しにくいが、オーバーヘッドは大きい
・各アクセラレータが勝手に動いて処理を進めていく方がオーバーヘッドは少ないが、CPU側との同期、あるいはアクセラレータ間の同期を取る手法が無い
といった問題がある。そんな訳で現状は効率が悪いのを覚悟の上で、CPU側からアクセラレータを完全にコントロールする形でアクセラレータを利用している。
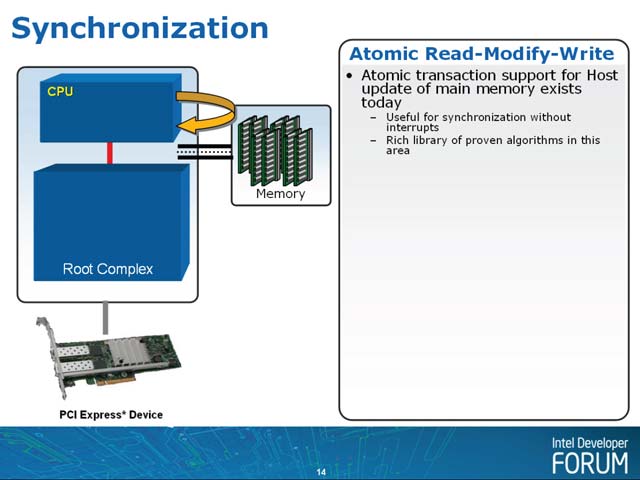
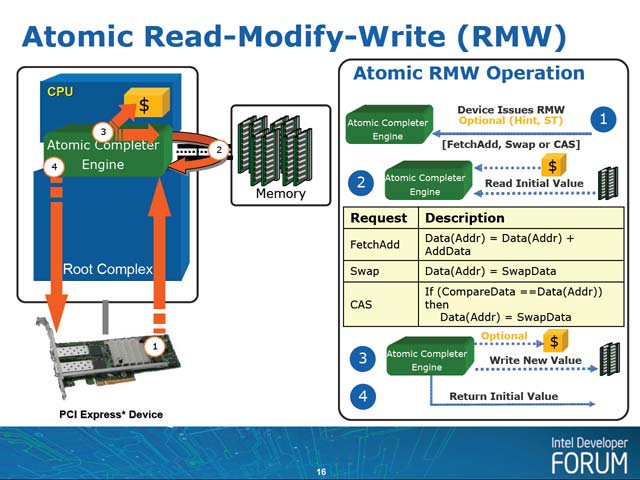
Atomic Completer Engineはこうしたケースでの問題の解決に繋がるメカニズムである(写真1)。ルートコンプレックス上にAtomic Complieter Engineを搭載し、CPUとPCI Expressデバイスの両方からアクセス可能な排他制御に使えるもので、これによりCPU-PCI Expressデバイスの同期と、PCI Expressデバイス同士の同期の両方が可能になる(写真2)。現時点で想定されるトランザクションはFetchAdd、SwapとCAS(Compare And Swap)の3種類で、これでBinary SemaphoreやSpin Lock系カウンタが構成できることになる(写真3)。これを応用する事で、キュー構造も作成できるとしており、かなり複雑な同期がAtomic Complieter Engine上で構成できることになる(写真4)。
 |
 |
| 【写真1】希に、PCIカードのエンコーダからデータを直接GPUに転送するケースがあったが、これにしてもそうした転送はデバイスドライバからのリクエストで行なわれていた(=エンコーダが勝手にGPUにデータを送りつけたりしない)から、調停メカニズムは不要だった | 【写真2】もちろん今度はCPUから同期を取りに行くのはややコストが増えることになっている。なので、CPU同士での同期を取るのにはまるっきり向いていない。そのため複数プロセス(なり複数スレッド)と複数のPCI Express デバイスで同期を取りたい場合、まずプロセス/スレッド間の同期をOS側で取り、ここで優先順位最高のものが今度はAtomic Completer Engineにアクセスするといった手法になると思われる。もっともEngineはメインメモリを使って構成する形なので、これをCPUから参照するという事はできるだろうが |
 |
 |
| 【写真3】まずPCI Express デバイスがAtomic Completer Engineに対してRMWできる領域を作成し(写真中(1))、次に初期値をメモリあるいはキャッシュから設定(写真中(2)、これはドライバの作業となるだろう)、あとは必要に応じてデバイスからリクエストを出せば、その結果はメインメモリに反映され(写真中(3))、デバイスにも返される(写真中(4))という訳だ | 【写真4】こちらはTPHに使われるキャッシュと異なり、メインメモリを使うから容量の制限はほぼ無い。あるにはあるのだが、メモリが余ってさえいれば良いので、制約は非常に緩い。そのため、結構複雑な構造が取れる。ただ、この作業は誰がやるのかというと、デバイスが直接やるというよりは、デバイスドライバの形でCPUがルートコンプレックス経由で操作することになると思われ、そろそろI/O専用プロセッサを別に用意したほうがいいんじゃないかとも思う |
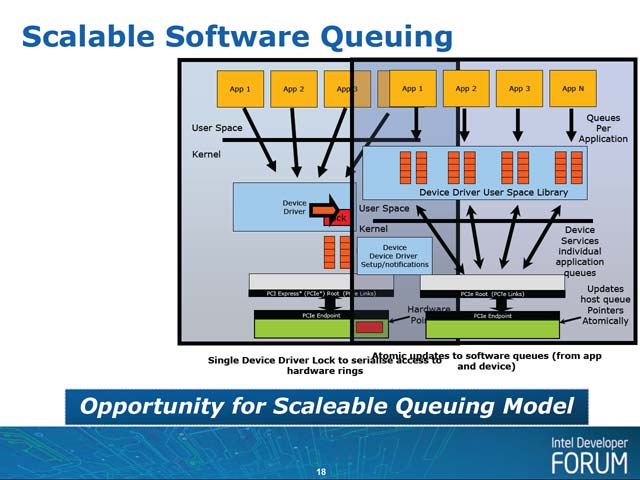
更にこれを発展させると、デバイスドライバのキューの持ち方を替える事が可能になる。これまでのOSでは、複数のアプリケーションからのリクエストは、まずカーネルモードで動くデバイスドライバがキューし、それを順次PCI Expressエンドポイントに送り込むという形でリクエストを管理していた。ところがAtomic Completer Engineを使う場合、ユーザー空間にI/Oキューを置き、これを各PCI Expressデバイスが勝手に取り込んで処理するといった方法を実装することも可能になる(写真5)。
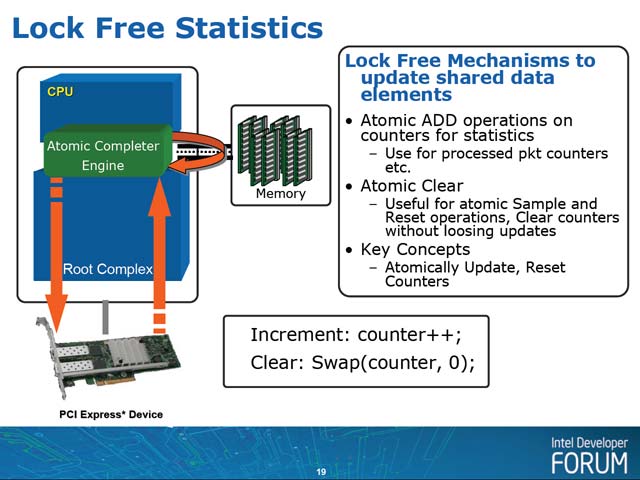
この仕組みは、例えば複数のタスクがあり、それを複数のアクセラレータで実装しようといった場合には非常に効果的だろう。先のFireStreamなどがその代表例である。あらかじめ処理させたいタスクをCPU側からキューしておき、後は各アクセラレータが勝手にタスクをキューから取得し、処理した結果をまたキューし、ついでにCompletionのイベントを上げておけば、CPUは結果をキューから入手してポストプロセスするといった仕組みだ。こうすればCPU側でいちいちアクセラレータの動作を監視する必要もなくなり、上に挙げた問題が綺麗に解決することになる。ちなみにデバイスからのアップデートに関しては、Add/ClearがAtomicに可能な事が保障されるため、単純な操作は最小限のオーバーヘッドで済むとされている(写真6)。
これによる性能向上はという観点のシミュレーションが写真7である。ちょっと図が潰れてしまって見にくいが、2種類の処理があり、途中で1度同期を取る必要があるというケースで、アクセラレータの数を増やしていく際に、性能がどれだけ上がるかをグラフにしたものである。横軸(problem-size)、つまりアクセラレータに行なわせる処理量が多いと、Atomic Completer Engineを使おうが使うまいが、ほとんど性能に差はない。ところが処理量が少なくなると、最大14倍もの性能差が出てくる。要するにバリアを経由する頻度が多いほどオーバーヘッドが如実に効く様になり、性能差が明確になるという話だ。
 |
 |
 |
| 【写真5】基本的にはAtomic Completer Engineが使うメモリはPCI ExpressのI/O空間にマップされた形になる(そうしないとキューの内容をデバイスがアクセスできなくなる)はずで、これを各プロセスにもマップする形でキューを実装する事で、オーバーヘッドを最小にしようという仕組み。確かにオーバーヘッドは減るのだろうが、これだと悪意を持ったアプリケーションとか、悪意は無いにせよ間違ってキューを破壊したりするアプリケーションが出てきた瞬間にOSがクラッシュしかねないと思う。何かしら信頼のあるアクセスをコミットする方法が用意されるのか、それともまだ何か筆者に見落としがあって実際にはそんなことは起こりえないのか、現時点では断言しかねる。実装時には何かあってしかるべきだろう | 【写真6】カウンタの追加はFetchAddを、クリアはSwapを使いそれぞれ実装することを想定していると思われる | 【写真7】グラフ横軸の単位はcycle。つまり1回リクエストを出すと51,200cycleも処理にかかるようなケースでは、スコアは1(つまりAtomic Completer Engineを使おうが使うまいが、性能差が無い)となる。ところが100cycleや200cycleだと、最大14倍近くまで性能向上がみられる。ちなみに青はアクセラレータが2つ、ピンクは3つ、黄色は4つでのテストで、多数のアクセラレータを使うケースでも性能が上がりやすい事を示している |
●電力管理
最後は電力管理である。もともとPCI Expressにもそれなりに電源制御に関する機能は装備されている(写真8)。PCI Expressの場合L0~LDn(Link Down)までいくつかの電力ステートが定義されており、L3では0 Power、LDn名前の通りLink Downするからそれなりに省電力ではある。もっともPCI Expressはあくまでバスの仕様だから、その上でどういうアプリケーションが動作するかまでは関与していなかった。Gen3では、このあたりをもう少しなんとかしたいというのが機能拡張の趣旨のようだ。
 |
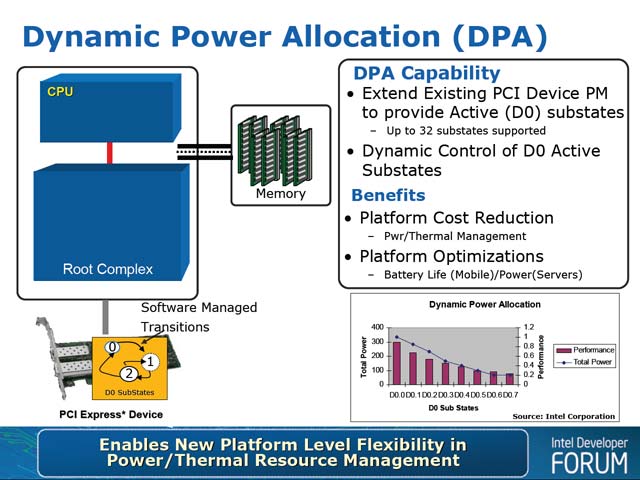 |
| 【写真8】誤解のないように書いておくと、PCI Expressには「動的に」Link WidthとかSpeedを変更する方法はない。厳密に言えば、ホットリセットを掛ける事で「電源を落とさずに」変更することは技術的には可能だろうが、そうした実装は聞いた事がない。このあたりは、WidthやSpeedを変えられるHyperTransport Linkとの違いの1つだ。ちなみに、これだけを読んでると「GPUの消費電力の過大さは、こういう電力管理でどうにかできる問題じゃないのでは?」と思わず突っ込みを入れたくなるが、話はもうちょっと深いレベルである | 【写真9】もっともステートで決めるといっても、無条件に一律でD0.0=300Wとかやっても意味がない訳で、いくつステートを持つか、あるいは各ステートがどの程度の消費電力を許すかというのは当然デバイス毎に設定することになるだろう。ただその場合、PCI Expressの電力管理は、例えば温度/電力が閾値を超えたらDPAのサブステートを1つずつ増やすといった単純な実装になるのか、それともあらかじめDPAサブステートにおける設定値の一覧を初期化時に取得して、その中で設定するようにするのかといったあたりはまだ不明である |
その機能拡張だが、まずはDPA(Device Power Allocation)である。これはPCI Expressデバイスの利用する(利用できる)消費電力をPCI Express側でハンドリングしようという話である。具体的には、既にPCI ExpressのデバイスステートであるD0を拡張して、D0.0~D0.31まで最大32のサブステートを定義できるようにしたという話だ。各々のサブステートで提供できる消費電力を決めておく事で、PCI Expressの電力管理でPCI Expressデバイスの消費電力や、それに伴う発熱をハンドリングできるようになるという仕組みだ。
次の拡張はLatency Tolerance Reportingである。上でちょっと書いたが、PCI Expressデバイスの場合、デバイスそのものには
D0:フル稼働状態(必須)
D1/D2:稼動しているが一部のパケットを処理しなくても良い(オプション)
D3hot/D3cold:待機状態(必須)
があり、またLinkには
L0:Full Active Link
L0s:Standby。L0にすぐ復帰可能
L1:Low Power Standby。L0には(L2/L3よりは)比較的高速に復帰可能
L2/L3 Ready:L2もしくはL3に移行準備。LDn経由でL0に復帰
L2:Low Power Sleep。LDn経由でL0に復帰
L3:0 Power。LDn経由でL0に復帰
LDn:L0への復帰
が設定されている。さて、問題はこのL2/L3である。PCI Express デバイスがD0であれば、当然LinkもL0ないしL0s、あるいはL1をホールドしているのが普通だから、これは問題ない。ところが省電力モードに入ると、Linkも相応に電力ダウンを図りたいところだ。ところがL2/L3の場合、今のPCI Expressでは必ずLDnを経由する。つまり1度Link Downして、再度初期化をかけてから接続を復帰させるという事になる。この結果、1度L2なりL3に入った場合、復帰までえらく時間がかかる事になる。この点は当初から問題になっていた話で、特にルートコンプレックスとエンドポイントが直接繋がっていれば問題ないが、間にスイッチが入ったりすると非常に面倒なことになる。
L2/L3を考慮に入れなくても、L1に入っているだけで実は結構面倒である。PCI ExpressにはASPM(Active State Power Management)という機能があり、L0s/L1に関してはExit Latency(L0s/L1からL0に復帰するまでのLatency)を保持しておく事ができるのだが、これが割りとおおざっぱである。例えばL1 Exit Latencyというフィールドは
000b 1μs未満
001b 1μs以上2μs未満
010b 2μs以上4μs未満
011b 4μs以上8μs未満
100b 8μs以上16μs未満
101b 16μs以上32μs未満
110b 32μs以上64μs未満
111b 64μs以上
となっていて、目安にはなるかも知れないが、精度という点では十分ではない。
これはGen3でアクセラレータを使っていると、更に問題である。例えばあるアクセラレータがD1/L1ステートにあって、そこに急にタスクがキューされたとする。この時に、実際にはD0/L0に復帰するまでタスクは開始されないのだが、タスクをキューしたほうはその状態がわからないから、下手をすると(D0/L0に復帰するまで)システムがハングアップに近い状態になりかねない。これを避けるには常にデバイスをD0/L0においておけばいいのだが、言うまでもなくこれでは全然省電力に貢献しない事になる(写真10)。
そこで行なわれた拡張が、LTR(Latency Tolerance Reporting)である(写真11)。これはPCI Expressデバイスが定期的にレイテンシをルートコンプレックスにレポートする仕組みだ。これを使う事で、タスクの割り振りの際にL1ステートに入っているデバイスをじっと待ったりする状態を回避できるし、デバイスも状況に応じてどんどんL1ステートに処理を落とす事ができるので省電力に繋がるというわけだ。
 |
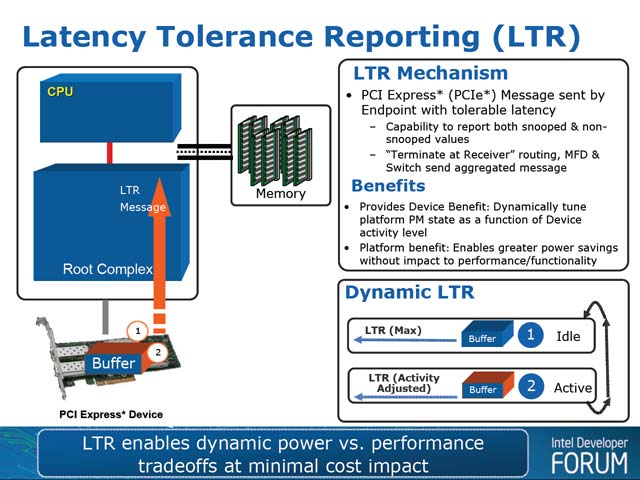 |
| 【写真10】これがCPUの場合、ACPI経由とは言え自分の負荷を自分で判断しているから、判断ミスによる性能への影響というのはそれほど考慮する必要がない | 【写真11】L2/L3の場合、ルートコンプレックスはそのデバイスをInactiveとして認識しているから、普通はそこにタスクを割り振る事はしないので考慮しなくていいと判断したと思われる。仮にそうしたデバイスもActiveにしたい場合、既にBeaconという信号が用意されており、これを使う事でLinkをL0ステートにすることが可能だ |
最後の拡張がOBFF(Optimized Buffer Flush/Fill)である。LTRは、ホストからデバイスをハンドリングするための仕組みだが、OBFFは逆にデバイスかホストをハンドリングするための仕組みとなる。
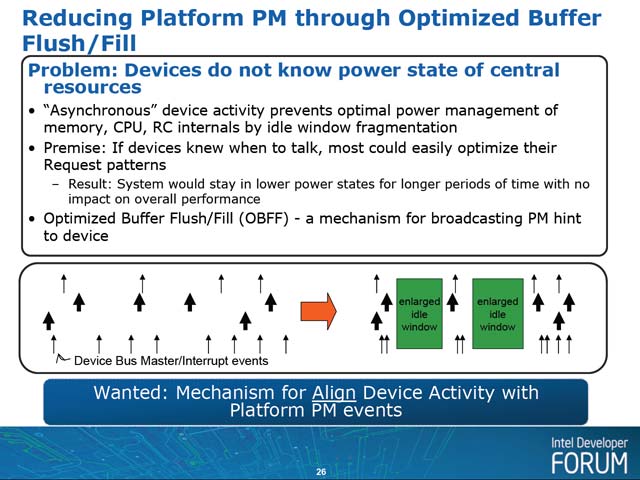
この拡張の動機は、デバイスの省電力性を高めることにある。要するにホスト側がそれほど動いてない状態であれば、デバイスも省電力モードに落としたほうが効果的であるが、それを知るための方法が今のところないことだ(写真12)。これを実現するために、
(1) 新たにWAKE#信号を追加する
(2) PCI Express MessageにOBFFを追加する
のどちらかを考慮しているとの事だ(写真13)。
 |
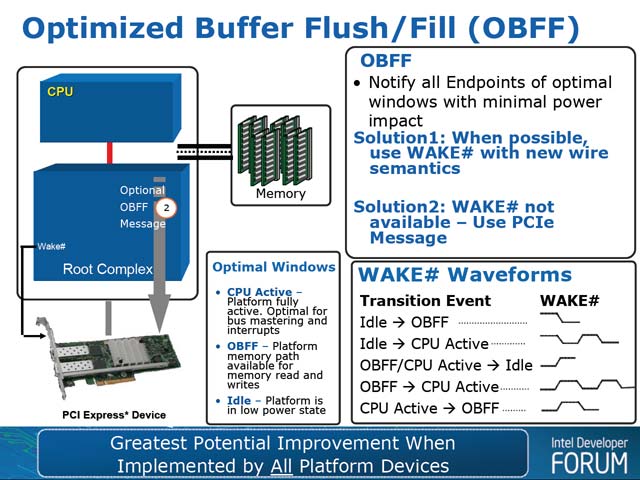 |
| 【写真12】現時点での実装は、デバイスは割り込みを上げるタイミングは自発的に判断しているし、いつホストから転送要求が出てもいいようにバッファを用意しておくといった配慮が必要になる。ところがホスト側の状態を知る事が出来れば、これを最適化できるという話。ホスト側が待機状態の時は転送要求に備える必要はないし、不急の割り込みを無理に上げる必要もなく、その分スリープ時間を長く取れる事になる | 【写真13】現実問題として信号の追加の方がインプリメントは楽だろうが、影響は広範囲に渡りそうに思える。WAKE#は現在デバイス→ホストの側に実装されているが、ホスト→デバイスの側には無い |
□大原雄介の最新インターフェイス動向
【3月10日】PCI Express 3.0編その1
http://pc.watch.impress.co.jp/docs/2009/0310/interface01.htm
【3月12日】PCI Express 3.0編その2
http://pc.watch.impress.co.jp/docs/2009/0312/interface02.htm
【3月16日】PCI Express 3.0編その3
http://pc.watch.impress.co.jp/docs/2009/0316/interface03.htm
(2009年3月18日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2009 Impress Watch Corporation, an Impress Group company. All rights reserved.