
【短期集中連載】大原雄介の最新インターフェイス動向
~PCI Express 3.0編その3
●TLP Processing Hints
ここまでは、PCI Express Gen3の基本仕様(Base Specification)に関する話題であったが、ここからは追加仕様(Supplemental Specification)の話である。元々PCI Expressは、基本仕様が上がるたびに、追加仕様といった形で、次々に新機能を追加してきた。といっても、1.0の場合は機械的/電気的な追加が主であり、Expressモジュールとかビデオカード向けの150W仕様、Mini CEMとかPCI Expressケーブル、あるいはPCI Express→PCI/PCI-Xブリッジといったあたりが、後から追加として列挙された。では、PCI Express Gen2はというと、メジャーなものはI/Oの仮想化である。
まず2007年3月にATS(Address Translation Services)がリリースされた。これは仮想マシンの環境で、複数のOSがデバイスにアクセスする際に「若干」処理を高速化するものである。従来、PCIにせよPCI Expressにせよ、デバイスから見たメモリのアドレスというのは一意に決まり、デバイスはDMAなどで自分が使うメモリの物理アドレスをOSに通知し、それをOSがハンドリングしてデバイスドライバなりアプリケーションなりに仮想アドレスとして通知する。そのため、仮想マシンの環境だと複数のOSが同時に動くので、もう1段変換が必要になる。ATSを使うとこのもう1段の変更が高速になるという話である。
CPUの世界で言えば、AMDのAMD-VがNested Pageというアドレス変換技法をサポートし、IntelがNehalem世代でEPT(Extended Page Tables)をサポートして追従したわけだが、これのPCI Express版がATSということになる。
これに続き、2007年10月にはSR-IOV(Single Root I/O Virtualization)がリリースされた。これは1台のマシン(つまりルートコンプレックスが1つ)の環境で、複数のOSが動作する場合に、I/Oデバイス自体の仮想化をハードウェア側でサポートするという話である。
今まで、これはHypervisorの仕事であった。例えば1つのマシンの上で、Windowsでも何でもいいがOSが2つ走り、それが同時にHDDにアクセスしようとした場合、HypervisorがこのHDDへのI/Oリクエストを1度受け取り、要求を一本化した上でHDDに対して発行、結果をそれぞれのOSに配分し直すという作業を行なっていた。
ところがSR-IOVの環境だと、それぞれのOSがあたかも自分専用のHDDが出現しているように扱う事ができる。実際にはSR-IOVが両方の命令をうまくまとめて実行し、結果を再配分しているわけだが、これがハードウェア的に実施できるようになったのだ。
更に2008年5月、MR-IOV(Multi Root I/O Virtualization)がリリースされた。こちらは名前の通り、複数のマシン(つまりルートコンプレックスが複数)ある環境で、デバイスを仮想的に共用するといった仕組みである。こちらは、例えば高密度ブレードサーバーなどでSANのインターフェイス(FiberChannelやInfini Band、最近だと10/40GbpsのEthernetあたり)を共用するといった目的で作られたもので、ATSやSR-IOVなどとは毛色が異なるものだ。もっとも、仕組みとしてはSR-IOVの上に作られている。端的に言ってしまえば、
・ATS=仮想化のために、ルートコンプレックスにMMUを少変更
・SR-IOV=ルートコンプレックスとエンドポイントデバイスの両方を仮想化のために変更
・MR-IOV:ルートコンプレックスと途中のPCI ExpressスイッチをMR-IOVのために変更。Endpointは(SR-IOVから)少々変更
といった感じだ。
I/Oの仮想化以外では、225W/300Wの電源スペックが、やはりPCI Express Gen2における追加となるだろう。細かいところでは、PCI ExpressケーブルについてもGen2対応の仕様が追加されている。
ではGen3世代ではどんなものが予定されているかということで、最初に挙げられているのがTPH(TLP Processing Hints)である。TLPというのはTransaction Layer Packetの略で、PCI Expressで実際にやり取りするデータパケットのうち、デバイスドライバなどで取り扱うのがTLPとなる。では、TLP処理のヒントとは何か?
 |
| 【写真1】ちなみにPIOであれば、そもそもPIOによるオーバーヘッドが無茶苦茶大きいので、これによるオーバーヘッドなんて考える必要がない |
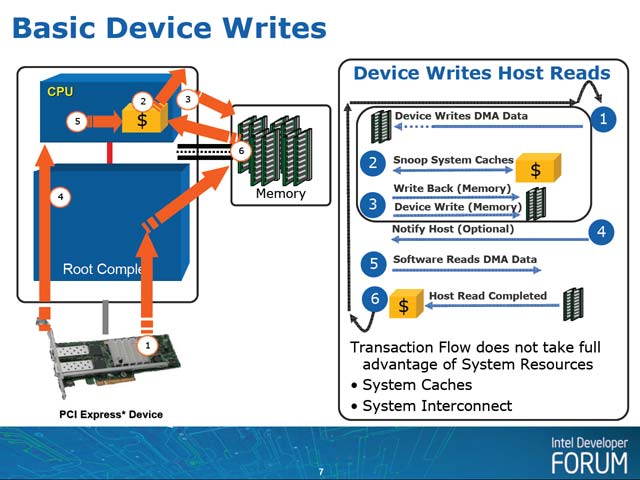
写真1は、現在のPCI Expressにおけるデバイスからの読み出しの一般的な処理フローである。これはデバイスからホストにデータを送るケースであるが、
(1) デバイスからルートコンプレックスにデータをDMA転送する
(2) DMA領域をCPUがキャッシングしていた場合に備え、スヌーピングが発生してCPUの当該エリアのキャッシュ破棄が行なわれる
(3) ルートコンプレックスからメモリにデータが書き込まれる。
(4) 必要ならデバイスから割り込みがルートコンプレックスに送られ、ルートコンプレックスがCPUにデバイス割り込みを通知する
(5) ソフトウェアがDMA転送された結果をメモリに読みに行く
(6) デバイスに対して転送完了が通知される
といったシーケンスを経る事になる。1回のデータ転送量が多い(HDDアクセスなどこの良い例であるが、ほかにもEthernetでJumbo Packetを使ってる場合もこれに相当するだろう)場合には、このシーケンスのオーバーヘッドはそれほど大した事は無い。ところが、1回のデータ転送量がそれほど多くない場合は、このオーバーヘッドが無視できないものになる。
 |
| 【写真2】もっともこの図で、(2)で直接CPUに書き込みが出来るのは今のところごく一部の製品だけだし、ルートコンプレックスのキャッシュから直接コピーできるものもかなり限られるような気がする。x86系では外部から直接キャッシュ操作(キャッシュ破棄は簡単に出来るが)を許すアーキテクチャになってなかったと思うのだが…… |
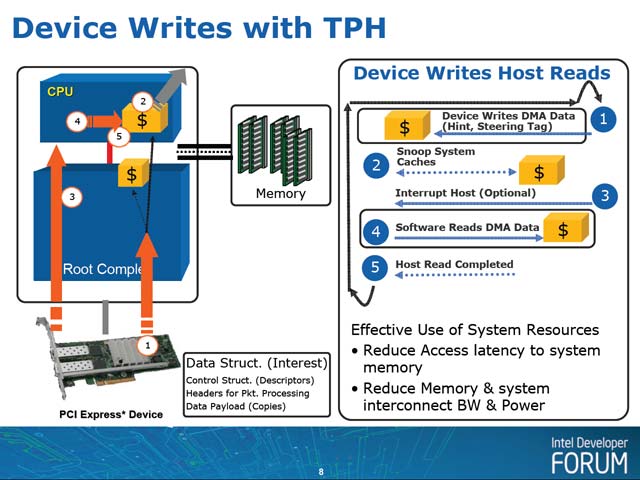
そこで、このオーバーヘッドを削減するのがTPHとなる(写真2)。具体的には
(1) デバイスからルートコンプレックスにヒント情報とステアリングタグ付きでデータをDMA転送する。ただし転送先はメモリではなく、ルートコンプレックス内のローカルキャッシュとなる。ここから、直接CPUのキャッシュに転送が行なわれる
(2) メモリは更新されていないので、スヌープは原則として発生しない
(3) 必要ならデバイスから割り込みがルートコンプレックスに送られ、ルートコンプレックスがCPUにデバイス割り込みを通知する
(4) ソフトウェアがDMA転送された結果をキャッシュに読みに行く
(5) デバイスに対して転送完了が通知される
といった動きとなる。要するにDMAでデバイスから直接CPUにデータを送り込む事で、メモリアクセスを省き、レイテンシの削減とスループット向上を両立しようというものだ。
この技法は、一般にはキャッシュスタッシングと呼ばれている。実際FreescaleのPowerPCの一部、最近だとe500とかe500MCが、L2キャッシュのスタッシングを可能にしており、このために専用レジスタまで用意されている。ただ当然ながら、これはアプリケーション(というか、PCI Expressの場合であればデバイスドライバ)がキャッシュのある領域をがっちりロックしておく必要があり、CPU側にもこうしたメカニズムが必要になってくる。
TPHは当然読み込みの場合も役に立つ。写真3はやはり一般的な、PCI Expressデバイスへの書き込みである。順序としては
(1) DMA転送すべきデータをキャッシュ経由でメモリに書き込む
(2) 必要ならルートコンプレックス経由でデバイスに対してコマンド発行
(3) デバイスはルートコンプレックスに対してDMA要求
(4) (3)のDMA要求がメモリに書き込まれる場合、そこでスヌープが発生
(5) メモリからデバイスにDMA転送
(6) デバイスからルートコンプレックスに転送完了を通知
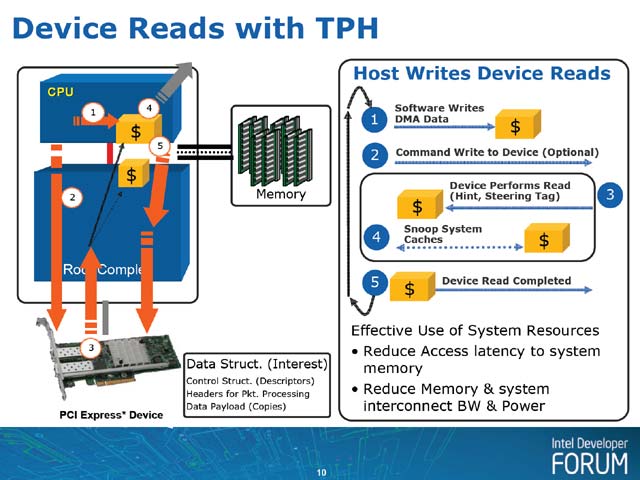
といった具合だ。で、これがTPHを使った場合は、写真4の様に
(1) 転送すべきデータをキャッシュに書き込むと、必要に応じてそれがルートコンプレックスのキャッシュに転送される
(2) 必要ならルートコンプレックス経由でデバイスに対してコマンド発行
(3) デバイスはルートコンプレックスに対してDMA要求を掛け、キャッシュから直接転送される
(4) メモリは更新されていないので、スヌープは原則として発生しない
(5) デバイスからルートコンプレックスに転送完了を通知
となる。こちらもメモリを使わない分、オーバーヘッドが減る。
 |
 |
| 【写真3】別にPCI/PCI Expressに限らず、DMA転送を行なう場合はこんな形になるのは、必然とも言える | 【写真4】この手の話はAGPの頃からあった。描画命令をGPUに対して発行する際に、細かくコマンドを分けて発行していると、そこがオーバーヘッドになるので、描画命令と頂点座標の山をまとめて1回で発行するように工夫することで性能を上げようといった事柄だった。これはある意味リーズナブルというか当然の話なのだが、逆に言えば、まとめられない場合には性能が落ちるのを覚悟せよという事であって、それを何とか改善したいと思うと、こうしたトリッキーな手法が必要になるのかもしれない |
これらは理屈は簡単だが、実装するとなると色々問題は多い。最大のものはキャッシュスタッシングのメカニズムで、CPU側にこれを実装していない場合は外部にメインメモリより高速にアクセスできるエリアを設け、これを使う形になるだろう。それが写真2/4に出てくるルートコンプレックス内のキャッシュということになる。
ただこうした実装の場合、CPUからルートコンプレックス内のキャッシュはメモリとして扱われるから、スヌープが発生することになってしまい、本当に高速になるかちょっと微妙な感じではある。また、複数のI/O要求がある場合とか、デバイスが複数ある場合の管理、複数種類のI/Oが混在する場合などの使い分けも難しい。このあたりはPCI-SIGでも「検討課題」としており、詳細はもうちょっと待たないと出てこなそうだ(写真5)。
TPHが性能に与える影響のシミュレーション結果は写真6である。左がアクセラレータカード、右はネットワークカードの場合の結果である。右を見ると、特定の処理では大幅なオーバーヘッド削減に繋がるようだが、左を見るとその削減度合いは当然システムキャッシュ(この場合はルートコンプレックス内のキャッシュなのだろう)の容量で決まるようだ。このあたり、実装がどうなるのかちょっと興味ある部分だ。
 |
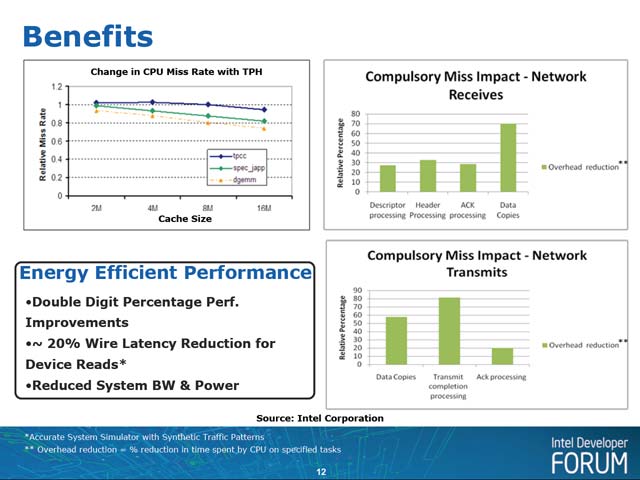 |
| 【写真5】ヒントはこのTPHを使う/使わないを示し、ステアリングタグが具体的なデバイスやらI/Oの種類やらを示す形になりそうだ。ステアリングタグはシステム上で最大256とされている | 【写真6】左右共に縦軸はCPU Miss Rateとなる。つまりシステムキャッシュが無くてページフォールトを起こし、メモリからキャッシュフィルを行なう率で、これが削減されるほど当然性能は上がる。なぜ、左でアプリケーションがTPCC/SPEC_jpp/DGEMMというHPC向けなのかという話は後述 |
□大原雄介の最新インターフェイス動向
【3月10日】PCI Express 3.0編その1
http://pc.watch.impress.co.jp/docs/2009/0310/interface01.htm
【3月12日】PCI Express 3.0編その2
http://pc.watch.impress.co.jp/docs/2009/0312/interface02.htm
(2009年3月16日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2009 Impress Watch Corporation, an Impress Group company. All rights reserved.