
【短期集中連載】大原雄介の最新インターフェイス動向
~PCI Express 3.0編その2
●Signal Simulation
現在のPCI Express Gen2の配線にGen3の信号を通すとどうなるかというシミュレーションの結果が、2008年秋のIDFの技術セッションの中で幾つか示されている。
まず1つ目は、既存のマザーボードや拡張カードを模した組み合わせで、E2E(End to End)での信号のEye Heightを見たものだ(写真1)。結果はこちら(写真2)。全部で48パターンのシミュレーションを行なった結果、Eye Heightがとりあえず正というものが約半分。大雑把に言えば、実際には半分以上のケースで、そのままでは8GT/sの信号は流せないということになった。
 |
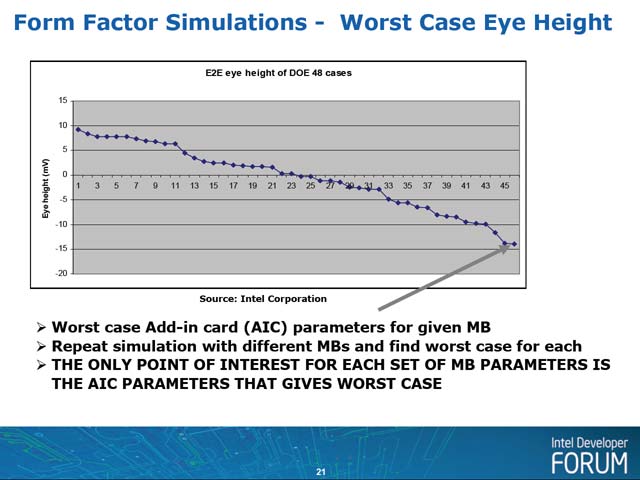 |
| 【写真1】マザーボード上のコネクタ経由で拡張カードが装着されるというケースで、配線長や配線インピーダンスその他を変えながら、各々のケースでEye HeightとEye Widthがどうなるかをシミュレーションするというもの。このケースでは、送信側からの信号が受信側でどう受け取られるかをシミュレーション。ちなみにシミュレーション結果は最悪の場合である | 【写真2】実際にはEye Heightが0Vでは話にならないわけで、もっと明確な電位差が必要になる。PCI Express Gen2の場合、伝達パラメータにもよるが、4.3.3.7の「Voltage Level Definition」によれば2本の信号線の電圧振幅がどちらも400mVPP(Voltage Peak to Peak)程度あることを想定しており、De-Emphasisを行なった後でもEye Heightが0.2V以上になる例が示されているから、実はほぼ全てのケースでEye Height不足という結果に |
では中間地点ではどうか(写真3)ということで、同じモデルでコネクタ部における信号のBER(Bit Error Rate)をシミュレーションした結果がこちら(写真4)である。縦軸はBERの絶対値というよりは、BERの目標値(=10^-12)に対しての指標ではないかと思われるが、とりあえずこれを満たせるケースはまだそう多くはないようだ。あくまでこれは最悪値だから、条件がよければ通信できる可能性はあるのだが、かなり通信エラーが続発することになりそうである。
 |
 |
| 【写真3】テストの構図は全く一緒であるが、今度はコネクタ部での信号をシミュレーション | 【写真4】桃色がコネクタ部、青が拡張カードの先の結果。縦軸はBERに変わっている |
更に、実際の配線条件に近いパラメータを考慮したケースが3番目のモデルである(写真5)。こちらのケースの結果が写真6で、多少改善されてはいるが、まだ問題は多いことが判る。
 |
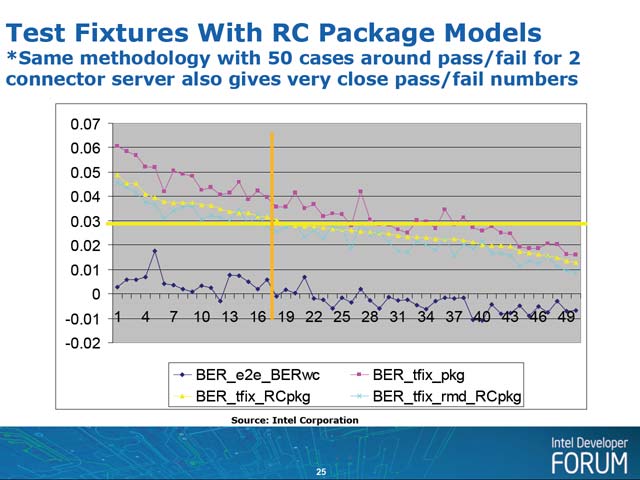 |
| 【写真5】どんな基板を使って配線しても、寄生容量を0にすることは出来ない。特に実際に使われるFR-4ベースの多層基板においては、8GT/sもの信号となると、この寄生容量による配線遅延が馬鹿にならないほか、配線抵抗と組み合わされたRC回路の影響も考える必要がある | 【写真6】表中にもあるが、同様に2コネクタを使うサーバーのバックプレーンのシミュレーションでも、ほぼ似た結果が出たとしている。もっともこのバックプレーン向けの場合、最大20インチという長さが極めて難しいという話があり、あくまでも予備的に2インチ程度の長さで2コネクタのバックプレーンをモデリングした場合の話ではないかと思う |
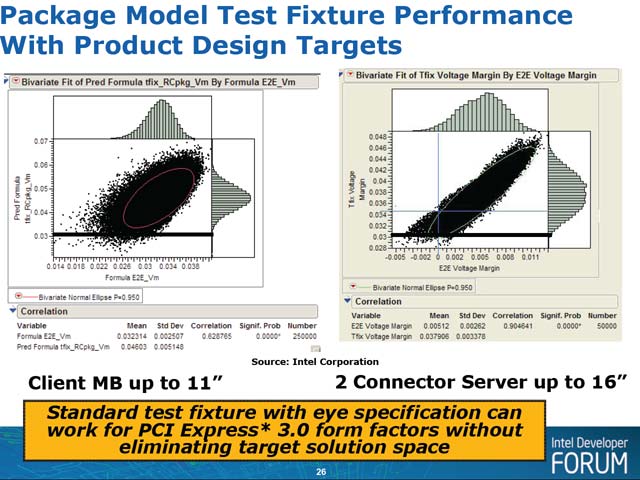
ただ、ここまでの結果はいずれも送受信の両側で何の対策もせずに、そのまま8GT/sの信号を流した場合の話である。写真1~6はIntelでの評価結果だが、PCI-SIGのAl Yanes氏にこのプレゼンテーションを確認したところ「確かに同じデータを我々も得ており、これは概ね正しい。ので、現時点ではまだGen3の伝達にハードルが多いことは判っている。ただこれはあくまでも初期のシミュレーションであり、Equalizationを始めとするさまざまな信号補正の技法を何も加味していない。今後は、TX/RX Equalizationや新しいScramblingなど、さまざまな技術を利用することで、こうしたハードルを越えられると考えている」という返事であった。実際、何もEqualizationを施さない状態でも、一応Eye Height/Widthを確保できる目処が立っているというのが公式な見解だそうだ(写真7)。
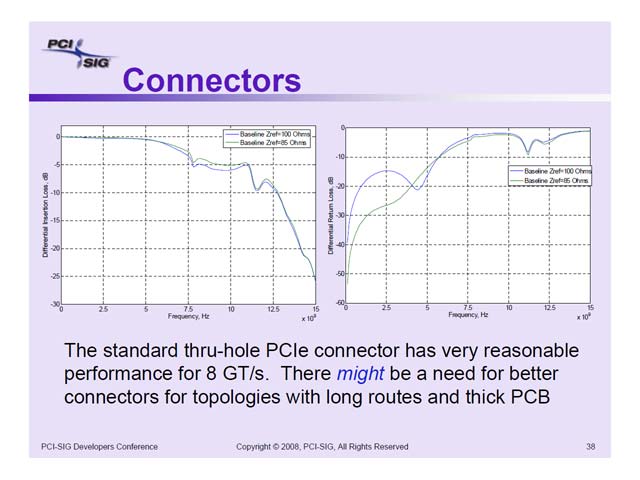
ちなみに基本的なコンポーネント、例えばコネクタについては早くからシミュレーション結果が出ており(写真8)、既存のGen2用のコンポーネントでGen3の利用に大きな問題が無い事が確認されている。またGen3に関しては、シミュレーションの方法を少し変えた事も明らかにされている(写真9)。
 |
 |
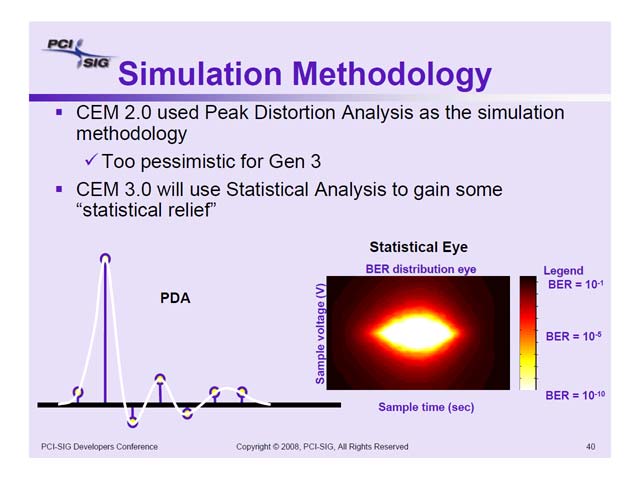 |
| 【写真7】左が配線長11インチのクライアント向け、右が配線長16インチのサーバー向けのモデル。横軸がEnd to EndのEye Height、縦軸がコネクタ部のEye Heightである。どちらも一応相関が取れており、適切な補正技術さえあれば、基本的には既存の配線を使って8GT/sの転送が行なえる目処は立ったとしている | 【写真8】これはコネクタの減衰特性をシミュレーションした結果。青がGen1互換のインピーダンス100Ωの場合、緑がGen2の85Ωの場合で、どちらも8GHz付近で5dB程度のロスとなっている。逆に言えば5dB程度のロスで済んだという言い方もできるのだが | 【写真9】従来はPDA(Peak Distortion Analysis)と呼ばれる方法で分析してきたが、Gen3からStatical Analysisに方法を変えたとしている。PDAは最悪のコンディションを正確に見積もるのには適しているが、問題はそれがどの程度の確率で発生するかということで、このあたりを踏まえたのだろう。というよりも、Gen3にPDAを使うと、そもそも転送が成立しないのかもしれない。ただPCI Expressに限らず、先端的な分野ではモデリングに統計的手法を使うことが最近の流行のようなので、これもその1つなのかもしれない |
●PIPE 3.0
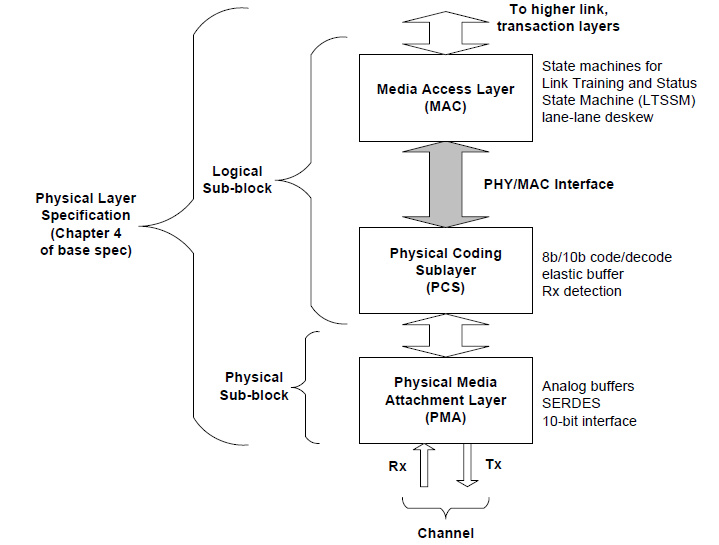
厳密に言えばこれはPCI Expressの仕様には入らない内容だが、重要なのがPIPEである。PIPEとは「PHY Interface for the PCI Express」の略である。何のインターフェイスかというのは写真10を見ていただくのが早い。PCI Expressの物理層と論理層のうち、MACとPCSの間のインターフェイスがこのPIPEとなる。このPIPEはPCI-SIGではなく、Intelが独自に仕様を策定しているもので、以前は「Intel Developer Network for PCI Express Architecture」という開発者組織に加盟したメンバーにのみ公開されていた(*1)のだが、Gen2がリリースされる前あたりで方針が変わったらしく、今は誰でもアクセス可能となっている。
(*1)そしてここに加盟するためには、PCI-SIGへの加盟が必須であった。なので、PCI-SIGに加盟していないメンバー企業や個人では、この仕様が参照できなかった。
PIPEの目的は、物理層というより電気層と論理層を切り離し、そこのインターフェイスを策定することで、デバイスを自由に構成できるようにするというものだった。実際、Gen1がリリースされた直後は、PCI Express PIPE PHYが各社からリリースされたりしている(写真11)。これを使うことで
・MACより上とPHYで、異なったデバイスにできる。例えばMACから上はFPGAを使って構築し、PHYだけ別に用意するといった事が可能になる
・SoCにおいてIPの自由度が増える
といったメリットがある。もっともGen1では図1-aのような2チップ構成も少なくなかったが、Gen2以降はあまりDiscreteのPIPE PHYは見かけなくなり、図1-bのような構成に切り替わっている(例えばPLX Technologyの場合、「Standard ProductとしてGen2用のDescreteのPIPE PHYは用意していないが、顧客から要望があれば用意する」と言っていた)。
 |
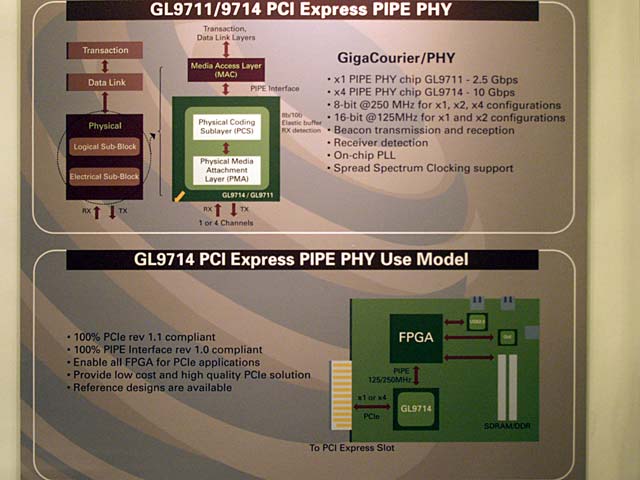 |
| 【写真10】PIPE Version 2.0の仕様より抜粋。PCS、つまり8b/10b変換をする部分とか、Lane Trainingなどの機能は論理的にはLogical Sub Blockに属するので、PHYとMACという分け方にならないのがちょっとややこしいところ | 【写真11】これはIDF Spring 2005におけるGenesis Logicの展示から。他にも何社かがこんな形でディスクリートのPIPE PHYチップをリリースしていた |
 |
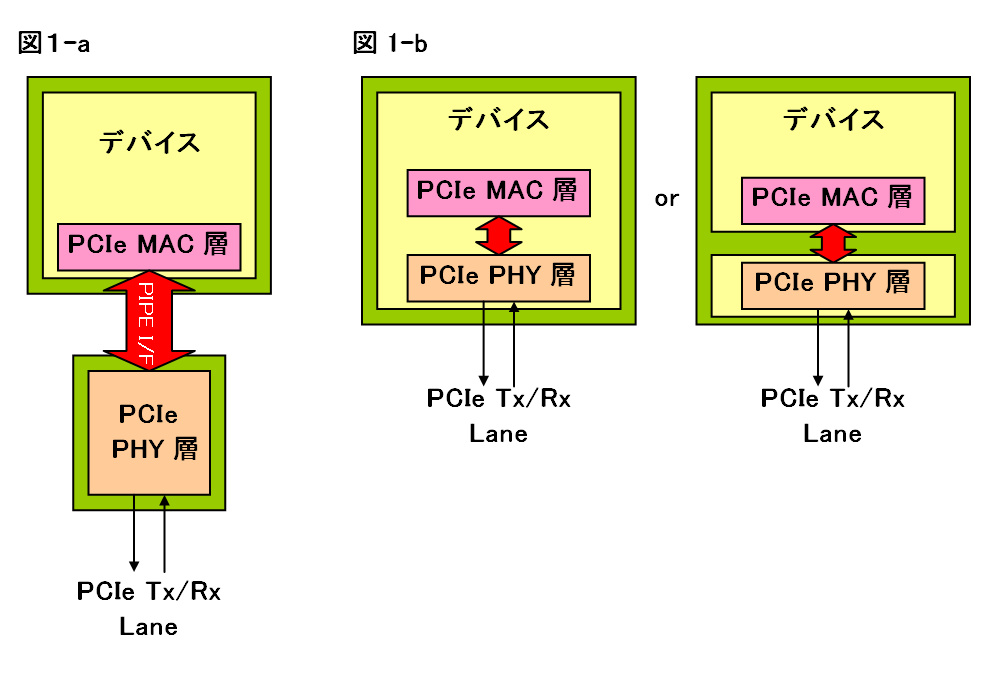 |
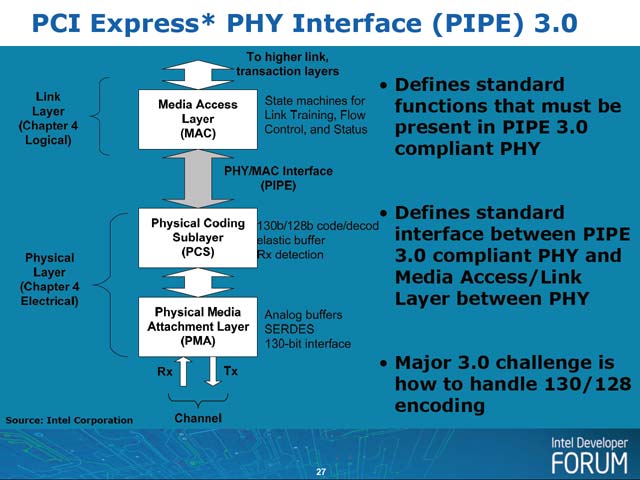
| 【写真12】写真10と見比べていただくと、構造的には全く同じであることが判る。問題はやはり130b/128bエンコード/デコードということか | 【図1-a/1-b】PIPEによるチップ構成の例 |
Gen2クラスになるとPCIやPCI-Xデバイスの置き換えというケースはかなり少なく(この規模であれば、Gen1で事足りるから)、新規にデバイスを作るという形になるので、それであれば無理に2チップ構成にしなくても、SoCあるいはSIPの形でワンパッケージ化したほうがコストを下げられるからで、こういうところを狙ってさまざまなIPベンダーやファウンダリがPIPE PHYをソフトコアあるいはハードコアとして提供するようになっている。
もう少し突っ込んで考えると、PCI Express自体は標準規格だから、これをサポートしないのは単なるデメリットである一方、PCI Expressの実装で差別化というのは非常に行ないにくい。勿論、実効転送性能を上げた実装とか、消費電力を下げた実装、あるいはローコストな実装というのは概念としてはありえるが、それはMACなりPHYのIPベンダーにメリットはあっても、PCI Expressを使うアプリケーションのベンダーにはあまり大きな関係はない。また、特にPHYに関してはソフトコアよりもハードコアの方が性能を出しやすい(というより、プロセスに最適化しやすい)が、そうなるとIPの使える範囲が限られてしまう。ところがPIPEが間に入ることで、例えばMAC層はソフトコアを使って実装し、PHYはファウンダリが提供するハードコアを使うといった事が可能になるわけで、この意味合いは大きい。
さて前書きが長くなったがこのPIPE、2008年6月の時点ではGen3がどうなるか不明であった。Al Yanes氏などは「PIPEそのものはご存知の通りIntelが策定する規格だから我々がどうこう言えるわけではないが、多分Gen3にも似たようなものが提供されるんじゃないかと思っている」と、いまいち当てにならない返事だった。メンバー企業のみが参加できる技術(つまり秘密保守のセッション)の中では、「PIPEはどうなってる」と聞かれて、「それについては聞くな」という返事もあったそうで、この時点ではGen3対応のPIPEがどうなるか、非常に先行き不明であった。
 |
| 【写真13】Controlが13+、Statusが6+となっているあたりが、まだ仕様が詰めきれていない事を示している |
ところが2008年8月のIDFでは、既存のPIPE 1.0/2.0と同じ枠組みで、PIPE 3.0の仕様を策定中であることが明らかにされた。既存のPIPEとの違いは、遂に32bitのデータ幅がサポートされたことと、Control/Statusに信号線が追加される見込みである事だ(写真13)。例えば写真13のプレゼンテーションではControlが13本以上となっているが、同時期にリリースされたPIPE V3.0のRevision 0.5によれば
・RateがRate[1:0]で2bitになる
・TxSyncHandle[1:0]が追加
ということで、少なくともControlは16本になるようだ(Statusは今のところ一緒)。このあたりは今後まだ変更がかかっても不思議ではない。
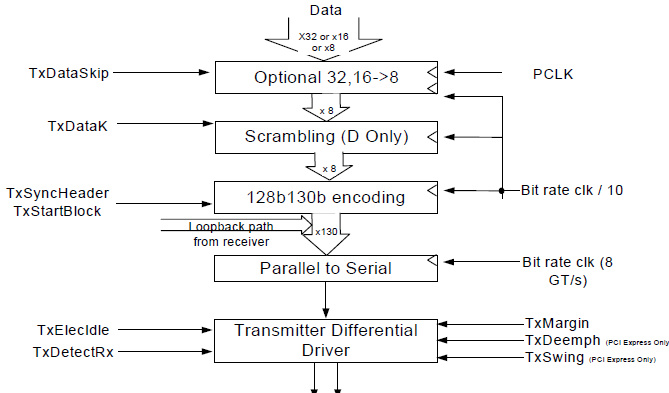 |
| 【写真14】これはPIPE 3.0 Specification Revision 0.5のFigure 4-3からの抜粋。130b/128bエンコーディングを使うことを考えれば、もっと別の選択があっても良さそうな感じではあるのだが。あくまでもペイロードの最小単位は1Byteに留めておきたいためかもしれない |
一方バス幅だが、表1にPIPE 2.0の、表2にPIPE 3.0でのデータ幅とその場合のPCLK(転送のタイミングを取るリファレンスクロック。PIPE PHYから供給される)をまとめたが、面白いのはGen1用に32bit/62.5MHzが追加されたこと。この組み合わせは以前からニーズは少なくなかった(PCI Expressを使うようなデバイスであれば、内部バスは32bit以上であるのが普通で、x1レーンを出すためには、わざわざ16bitに変換する必要があったからだ。逆にx4レーンであれば、8bit×4で丁度32bitになるので、こちらはあまり問題が無かったようだ)のだが、やっとサポートされた形だ。また、PIPE 3.0の仕様を見ると(写真14)、一度16/32bitで入ってきたデータは8bitに変換された上で、Scramblingが掛けられているのが判る。Scramblingについてまだ詳細は不明だが、一応8bitベースのScramblingを使うことを現時点では想定していることがここから判断できる。
ちなみに外部(つまりPIPE インターフェイスの外側)から見ると、この1つでGen1/Gen2とGen3の両方をカバーできるようになっており、パラメータを切り替えるだけでどちらでも使える(PCI Expressの使い方からして、動作中にGen1/2とGen3を切り替えるなんて形はありえないだろうから、電源投入直後あるいはHot Plug後のデバイス初期化のタイミングで、この判断が行なわれる事になる)が、内部的には完全に分離された形になると思われる。
| PIPE 2.0 | データ幅 | PCLK |
| 2.5GT/s | 8bit | 250MHz |
| 16bit | 125MHz | |
| 5GT/s | 8bit | 500MHz |
| 16bit | 250MHz |
| PIPE 3.0 | データ幅 | PCLK |
| 2.5GT/s | 8bit | 250MHz |
| 16bit | 125MHz | |
| 32bit | 62.5MHz | |
| 5GT/s | 8bit | 500MHz |
| 16bit | 250MHz | |
| 32bit | 125MHz | |
| 8GT/s | 8bit | 1GHz |
| 16bit | 500MHz | |
| 32bit | 250MHz |
□関連記事
【3月10日】大原雄介の最新インターフェイス動向~PCI Express 3.0編その1
http://pc.watch.impress.co.jp/docs/2009/0310/interface01.htm
(2009年3月12日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2009 Impress Watch Corporation, an Impress Group company. All rights reserved.