 |


■後藤弘茂のWeekly海外ニュース■並列コンピューティングの大物を
|
●人材を引き入れて変身を繰り返すNVIDIA
NVIDIAの技術的な方向性は、同社にどんな人物が加わったかによってわかる。NVIDIA GPUの最大の転機となった「GeForce 8800(G80)」の背後には、並列コンピュータのアーキテクトであるJohn Nickolls(ジョン・ニコルズ)氏(現Director of Architecture, Nvidia)がいた。Nickolls氏は、超並列SIMD(Single Instruction, Multiple Data)スーパーコンピュータ「MasPar Computer」のアーキテクトだった人物。MasParのアーキテクチャを、部分的にGPUに持ち込んだ。「(MasParとG80には)違う部分も色々あるが、元になっているアイデアは非常に似ている」とNickolls自身も語っていた。
NVIDIAの人材集めはGPUハード絡みだけではない。NVIDIAの最大の武器であるプログラミングフレームワーク「CUDA」の背後には、スタンフォード大学でストリームプログラミング言語「BrookGPU」の開発を手がけたIan Buck(イアン・バック)氏が、技術リーダ(NVIDIA CUDA Software Manager)として控えている。NVIDIA GPUのプログラマブル化の第一歩となったシェーディング言語「Cg」の背後には、スタンフォード大学でリアルタイムシェーディング言語のプロジェクトを率いたWilliam(Bill) R. Mark(ビル・R・マーク)氏(現Intel)がいた。
このように、NVIDIAは、技術面でのキーパーソンを、大学の研究室などから同社に引っ張ってくることで、GPUを進化させてきた。同時に、NVIDIAの技術戦略も大きく変わってきた。
そして今回、NVIDIAは、GPUの汎用化に向けて、大物をスカウトした。同社の研究部門のトップ(Chief Scientist and Vice President of NVIDIA Research)として、William(Bill) James Dally(ビル・ダリー)氏を迎えた。この人事も、NVIDIAに大きな変化をもたらすことは間違いがない。それは何故か。
 |
 |
 |
| William James Dally氏 | Ian Buck氏 | John Nickolls氏 |
●並列コンピュータ畑の大物を研究部門のトップに
Dally氏は、スタンフォード大学のコンピュータ部門の重鎮(Chairman, Computer Science Department, Stanford University)で、プロセッサ研究者としては、それなりの有名人だ。スタンフォード大学やMIT(マサチューセッツ工科大学)やCaltech(カリフォルニア工科大学)で、さまざまなプロジェクトを率い、あるいは関わってきた。特に、超並列コンピューティングとインターコネクトで知られている。
MITでは初期の実験的な超並列コンピュータ「J-Machine」、「M-Machine」の開発を指揮。最近では、汎用型のストリームプロセッサを商用化するStream Processors Inc.(SPI)を立ち上げている。また、プロセッサコアとメモリをペアにしたリコンフィギュラブルな演算ノードのタイル「Smart Memories」プロジェクトも、Mark Horowitz(マーク・ホロヴィッツ)氏(Director of Computer Systems Laboratory, Stanford University)(Rambusの共同創業者)とともに推進していた。
並列型のコンピュータの話題では、頻繁に名前を見かける人物だ。「ISSCC」や「Microprocessor Forum」といった半導体やCPUのカンファレンスでも、何回か講演を行なっている。つまり、グラフィックス畑ではなく、コンピュータ畑のキーパースンだ。
プロセッサ研究の大物であるDally氏がNVIDIAに加わったことは、ある意味で象徴的だ。NVIDIAは、グラフィックスハード系の人材だけでなく、並列コンピュータの人材を集めることで、GPUの汎用化を進めてきた。今回、R&Dのトップも替えることで、汎用コンピューティングへの傾斜を、ダメ押し的に決定づけるように見える。
これまで、Dally氏のポジションであるChief Scientistは、かつてDavid B. Kirk(デビッド・B・カーク)氏が占めていた(Kirk氏はNVIDIA Fellowとなる。健康上の理由という噂がある)。どちらかと言えばグラフィックス畑出身だったKirk氏から、並列コンピューティング畑のDally氏へと変わったことになる。NVIDIAがグラフィックス専用プロセッサの会社から、汎用プロセッサの会社へと脱皮する流れが、ますます加速されると見られる。
また、NVIDIAは、これまでもスタンフォード大学から人材を引っ張ってきたが、今回は、Computer Science DepartmentのトップであるDally氏を迎えたことで、スタンフォード大学人脈がより流入することも予想される。
●フォンノイマン(von Neumann)型アーキテクチャの終焉
象徴的なDally氏の起用だが、技術的な流れで見ると、Dally氏がNVIDIAに加わることに、それほど違和感はない。Dally氏の最近の焦点である汎用ストリームプロセッサのプロジェクトは、NVIDIAが進めているGPUの汎用化と完全に軌道が一致するからだ。SPIは、技術的な意味ではNVIDIAのライバルでもあった。
2007年夏に、NVIDIAのJen-Hsun Huang(ジェンセン・フアン)氏(Co-founder, President and CEO)と話をした際にも、SPIの話題が出た。その時、Huang氏は、SPIの目指している技術的方向がNVIDIAのそれと似ていることを認め、SPIには関心を持っていると語っていた。
Dally氏のプロセッサ研究の哲学は、過去4年間にISSCCやMicroprocessor Forumなどで行なった講演を見るとよくわかる。要約すると、次のようになる。
逐次処理するフォンノイマン(von Neumann)型アーキテクチャは終焉を迎えようとしている。効率が高く低消費電力で優れたパフォーマンスを発揮するためには、シングルの高速なCPUでは難しい。多数のシンプルなプロセッサを使い、コントロールオーバヘッドを減らすSIMDコントロールで、効率を上げた方がいい。
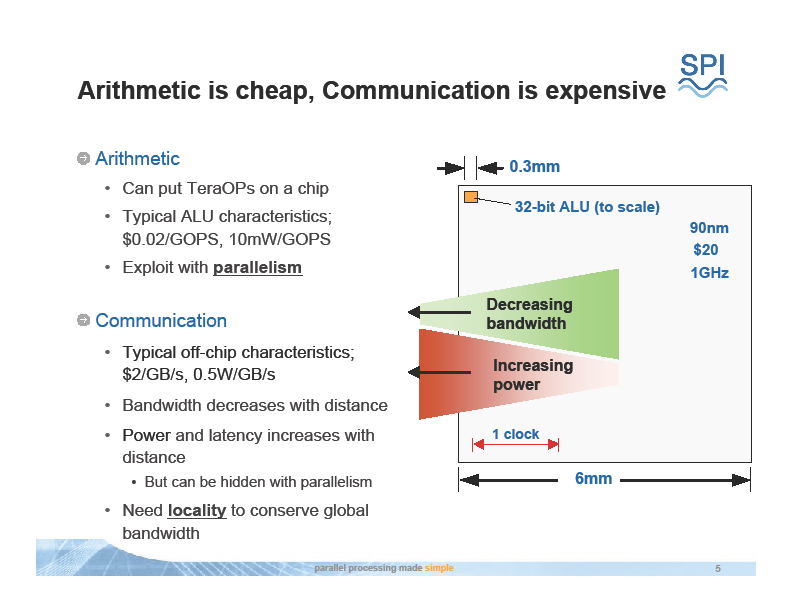
また、コンピューティングのコストと消費電力はどんどん低くなって行くのに、オフチップのコミュニケーションのコストと電力は下がらない。そこで、オンチップのメモリを使ってデータの局所性(Locality)を活用することで、オフチップのメモリ帯域を節約するべきだ。
下はこうしたDally氏の主張を示すスライドだ。Microprocessor Forum 2007と、2004年8月に開催された汎用コンピューティングGPUのカンファレンス「GP2」で示されたものだ。
 |
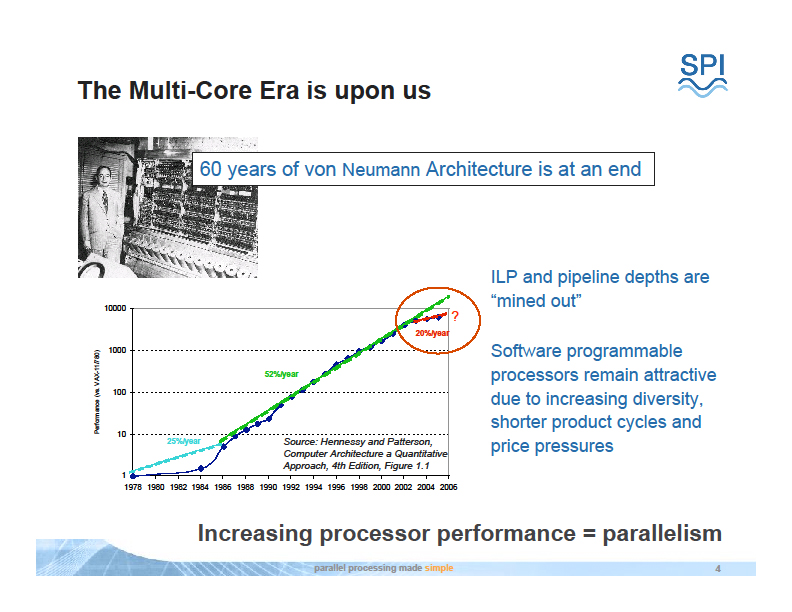 |
| コンピューティングとコミュニケーションのコスト | フォン・ノイマンアーキテクチャの終焉 |
 |
 |
| その理想型 | 概略 |
●ASICの1,000倍も非効率なPC向けCPUアーキテクチャ
Dally氏は、Cellプロセッサが発表された2005年2月の「ISSCC(IEEE International Solid-State Circuits Conference) 2005」で行なわれた「When Processors Hit the Power Wall」と題されたパネルディスカッションで、「Low-Power Architecture」と題した講演を行なっている。
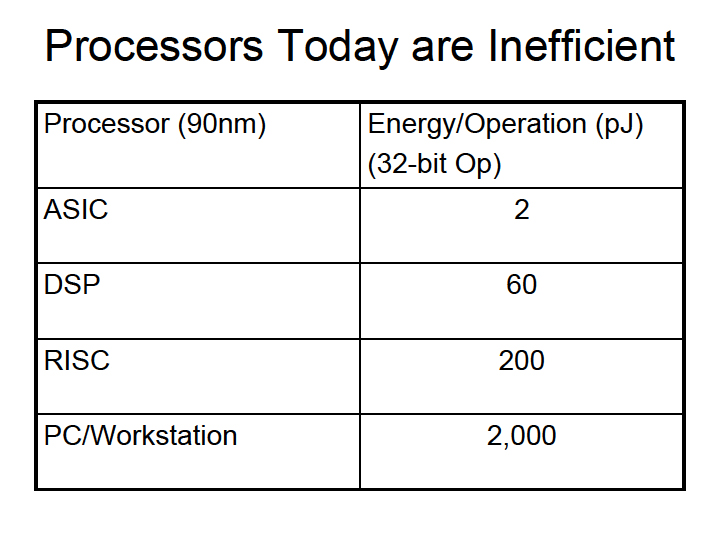
その中で、Dally氏は、プロセッサアーキテクチャによるオペレーション当たりのエネルギー消費を比較。32-bitオペレーション当たりのエネルギー消費(90nmプロセス)は、ASICが2pJ(pico-Joule)であるのに対して、DSPは60pJ、(組み込み系)RISCプロセッサは200pJ、PC/ワークステーションは2,000pJになると説明している。つまり、PC向けCPUは、固定機能のASICと比べると1,000倍もエネルギー効率が悪いことになる。
PCプロセッサの非効率の原因となっているのは、長い配線、アレイアクセス、コントロールオーバーヘッド、オフチップへのデータムーブメントなどだ。Dally氏はオペレーション毎のエネルギー消費の内訳も解析。演算自体によるエネルギーは大したことがなく、データトランスファで膨大なエネルギーが消費されると説明した。
 |
 |
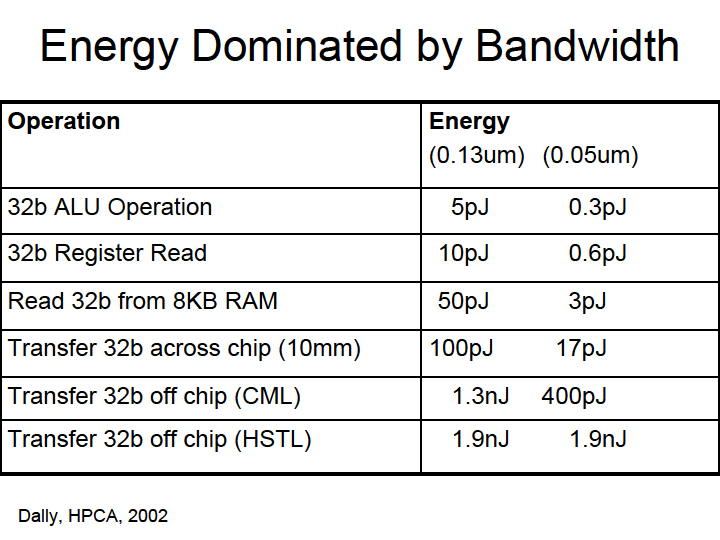 |
| PCプロセッサは非効率的 | エネルギーはどこで浪費されている? | エネルギーは帯域幅に支配されている |
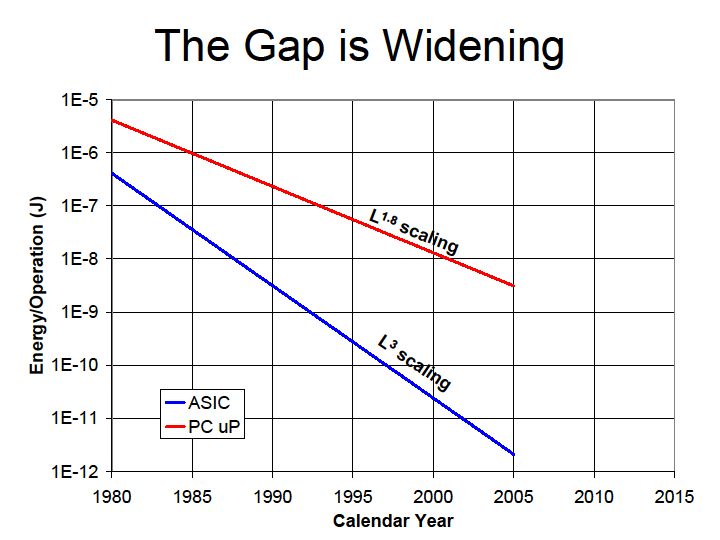
しかも、Dally氏によると、そのギャップは年々開く一方だという。さらに、近年ではリーク電流が加わることで、PC向けCPUでは、オペレーション当たりのエネルギーが年々減るどころか、増える傾向にあると説明した。下の赤いラインがPC向けCPUで、青いラインがASIC。年々、オペレーション当たりのエネルギー消費は下がるのだが、PC向けCPUはリーク電流のため下げ止まってしまう。
 |
 |
| 広がっていくギャップ | リーク電流の影響 |
●コンピューティング効率を上げる3つの方法
Dally氏は、この問題を解決する方法として3つのアプローチを示した。(1)多くの小型プロセッサを集積することで並列性を高める、(2)SIMD型処理と明示的なコードマネージメントによってコントロールオーバヘッドを減らす、(3)分散型で階層型のレジスタによってデータ移動を減らす。つまり、ストリーム型処理に向いた構造を持ったSIMDプロセッサを多数集積することで、非常にパフォーマンス/電力効率の高いプロセッサを作れるというわけだ。
下のスライドは、(1)の組み込み向けの小型のCPUコアを並列化した場合の例。下のグリーンのラインが組み込み系プロセッサだ。大型CPUコアと比べると、オペレーション当たりのエネルギー効率がずっと高いため、電力消費は抑えられる。
 |
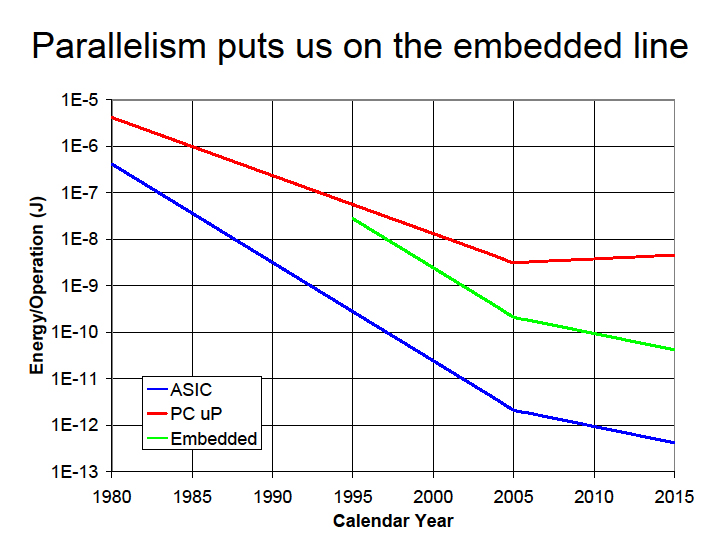 |
| 複数の単純なプロセッサを組み合わせた方がシングルコアの速いプロセッサよりも効率的 | 組み込み向けの小型のCPUコアを並列化した場合 |
次に、(2)でDally氏が挙げたのは、エネルギー消費の大きな部分を占めているコントロールオーバヘッドを減らすこと。命令をシーケンスして、フェッチ、デコード、パイプライニングする、こうしたオーバーヘッドをなくせば、エネルギー効率が大きくアップする。そのために一番いい方法が、SIMDコントロールだという。下の黒いラインが、SIMD制御を行なった場合で、グリーンの組み込みプロセッサよりさらに下がることがわかる。
 |
 |
| 制御によるオーバーヘッドを削減する | SIMD制御を行なった場合 |
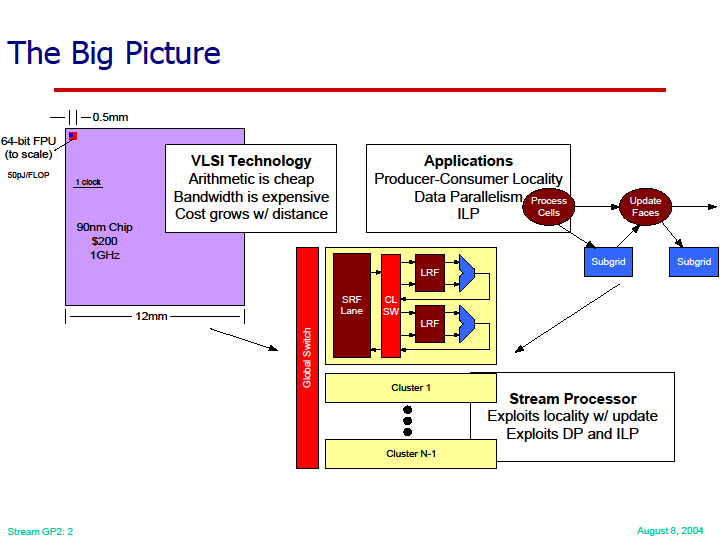
そして、(3)の要素は、エネルギー消費で最も大きな部分を示すデータムーブメントの削減だ。オンチップのメモリを明示的に有効に使うことで、データムーブメントを大きく削減できるとDally氏は語った。具体的には、分散型で階層型のレジスタによってデータムーブメントを減らす。下の紫のラインがそれだ。この時点では、Dally氏はSPIに注力していたため、ここではこのアーキテクチャをStream Processorと呼んでいた。
 |
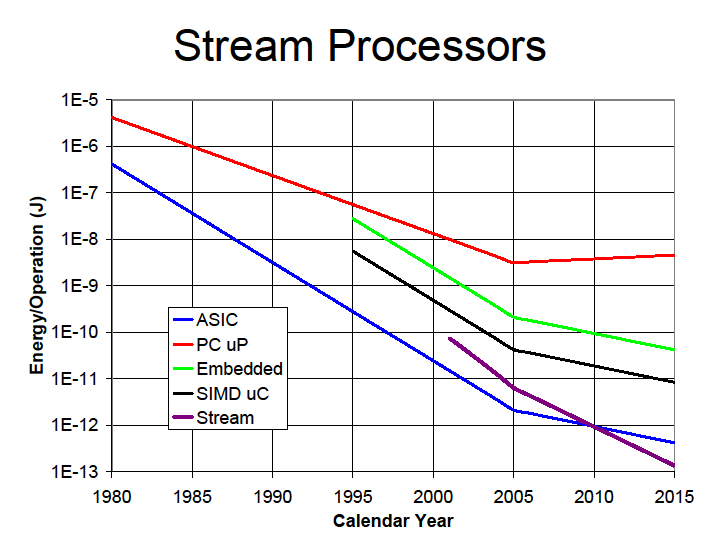 |
| データの移動を削減する | 分散型/階層型のレジスタを用いた場合 |
●Dally氏でNVIDIAアーキテクチャはどう変わる
Dally氏は、コンピュータアーキテクチャの流れから、プロセッサを効率化するなら、SIMD制御のスモールコアを多数集積してオンチップメモリを活用するべきだという結論を導き出した。シングルストリームを処理するという、フォンノイマン以来の流れは、もはや限界に達したというのが認識だ。そして、その結果として、ストリームプロセッサが今後は有用であると主張していた。
こうして見ると、Dally氏のビジョンは、GPUコンピューティングのそれにかなり近いことがわかる。少なくとも、GPUの目指すゴールは、Dally氏のビジョンとかなり重なる。GPUも、シンプルなコアをSIMD制御することで、非常に効率よくパフォーマンスを稼いでいるからだ。
しかし、Dally氏が指摘した3つ目のオンチップメモリによる、データの局所性の活用は、GPUでは始まったばかりだ。Dally氏は、2004年のGP2で、当時のGPUの問題点として、GPUではデータの局所性を活用できない点を指摘していた。グラフィックスというアプリケーションの特性から、その方が都合がよかったからだ。
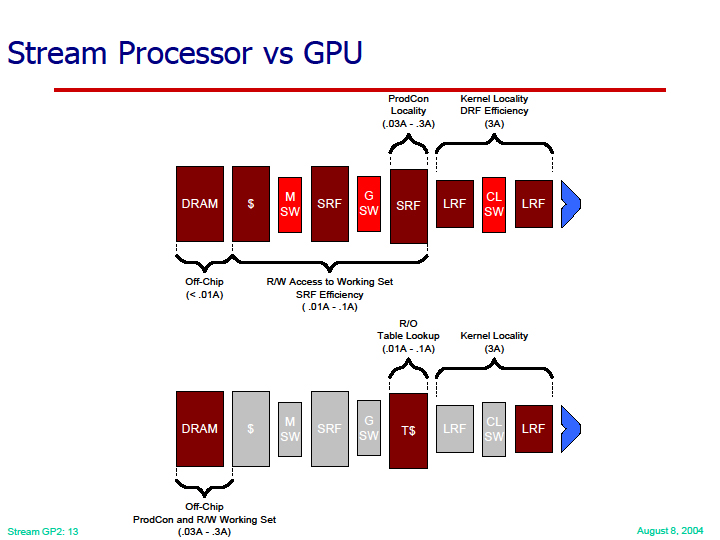 |
 |
| Stream ProcessorとGPUの比較 | 並列化と局所性 |
Dally氏は、極めて早い時点(J-Machineの頃)から、すでにデータムーブメントの制御が効率化のカギだと主張してきた。Smart Memoriesも、そうした流れにある。Dally氏が加わることで、NVIDIAアーキテクチャは、オンチップのメモリ階層やインターコネクトといったDally氏が得意とする部分の技術が発展することが予想される。現時点でも、CUDAコミュニティでの最大の不満の1つは、NVIDIA GPUのオンチップメモリ「Shared Memory」のサイズの小ささにある。
□関連記事
【1月29日】NVIDIAの新チーフサイエンティストにスタンフォード大のBill Dally氏
http://pc.watch.impress.co.jp/docs/2009/0129/nvidia.htm
【2,007年4月16日】【海外】スケーラブルに展開するNVIDIAのG80アーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
(2009年2月5日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2009 Impress Watch Corporation, an Impress Group company. All rights reserved.