 |


■後藤弘茂のWeekly海外ニュース■SSEとは根本的に異なるLarrabeeのベクタプロセッサ |
●Larrabee CPUコアとPentiumコアを比較
Intelは、新命令『Larrabee NI(New Instructions)』の最初の実装であるCPUアーキテクチャ「Larrabee(ララビ)」では、シンプルなIA-32(x86)系CPUコアをベースに開発した。すでに知られているように、IntelはLarrabee CPUコアを、Pentium(P5)をスタート地点として開発したとしている。Intelが、SIGGRAPH、Intel Developer Forum(IDF)、Hotchipsなどで公開したLarrabeeのアーキテクチャチャートを見ると、Pentiumをベースにしたことがよくわかる。
下の図は、LarrabeeのCPUコアをPentiumと比較したチャートだ。図の中で、ブルーの部分はPentiumに由来するユニット群、グリーンの部分はLarrabeeで新たに加えられたり拡張されたユニット群だ。最大のポイントはLarrabee NIのベクタ命令に対応するベクタユニットとベクタレジスタが加えられたこと。実際にはスカラユニット側にも、ベクタロード/ストア命令やキャッシュ制御命令などのLarrabee NIのいくつかの新命令が追加されている。
スカラレジスタもマルチスレッディングのサポートのために4倍に拡張され、L1データキャッシュとL1命令キャッシュも、それぞれマルチスレッディングのために4倍のサイズとなった。レジスタ本数もマルチスレッディングのために拡張されているはずだ。また、スレッドディスパッチャがL1命令キャッシュの前に追加された。PentiumではオンチップになかったL2キャッシュが内蔵され、FSBではなく、CPUコア内コミュニケーションのためのリングストップが加えられた。
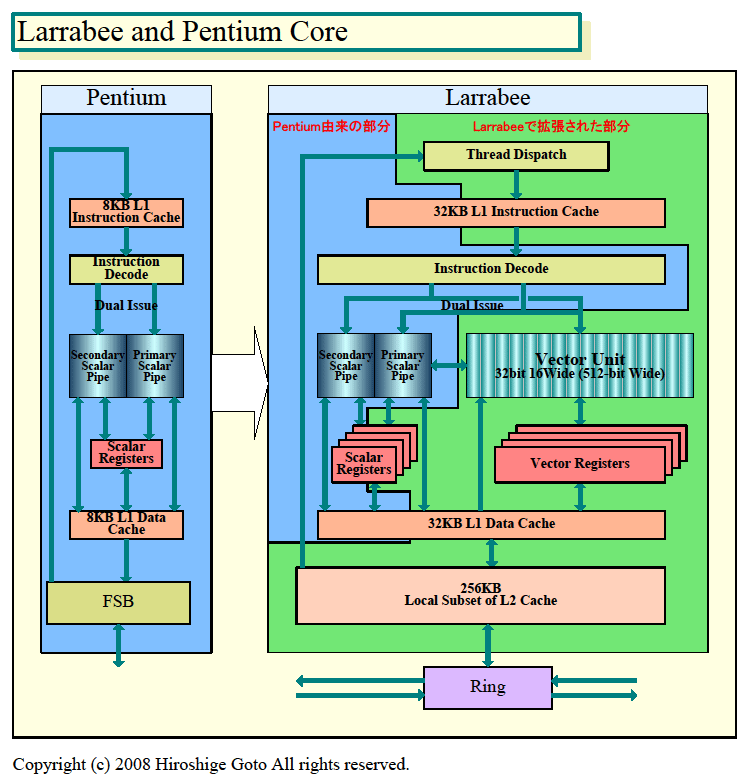 |
| LarrabeeとPentiumのコアの比較
PDF版はこちら |
●Pentiumを継承するLarrabeeの基本構造
こうしてみると、Larrabee CPUコアは、形は大きく変わっているが、骨格はPentiumを継承していることがよくわかる。例えば、CPUアーキテクチャの根幹である命令発行の仕組みは、Pentiumの2命令発行のIn-Order実行を継承している。
Larrabeeでは、実行パイプライン自体は、スカラユニットが2個にベクタユニットが1個と、合計3パイプがある。しかし、同時発行できる命令は、Larrabeeでも依然として2命令までとなっており、ベクタユニットは1命令/サイクルのスループットだ。スカラ命令は2命令を並列実行できるが、ベクタ命令はできない。
「同時に実行できる命令は2命令までで、ベクタユニットは1命令しか実行できない。ただし、ベクタユニットがベクタ演算命令を実行するのと平行して、スカラユニットがベクタロード命令を実行する。そのため、ベクタ演算の際も、実際には2命令をほぼ実行する形となる」とIntelでLarrabeeアーキテクチャの開発を担当するLarry Seiler氏(Senior Principal Engineer - Graphics System Architect, Intel)は説明する。
ベクタユニットへの命令発行ポートは、スカラユニットへの命令発行ポートと共有されているという。2個のスカラユニットのうち、片方はフルセットで、もう片方はサブセットとされている。一般的に考えれば、フルセットのプライマリスカラパイプとベクタユニットを並列に動作できるように、命令発行ポートを配置するはずだ。そのため、ベクタユニットとセカンダリスカラパイプの命令発行ポートは共有されていると推測される。しかし、HotChipsでの説明の図では、プライマリとセカンダリの両方の命令発行ポートが、ベクタユニット側に伸びているように描かれていた。そのため、図では、2つのポートがそれぞれベクタユニットと命令発行ポートを共有する形に描いている。
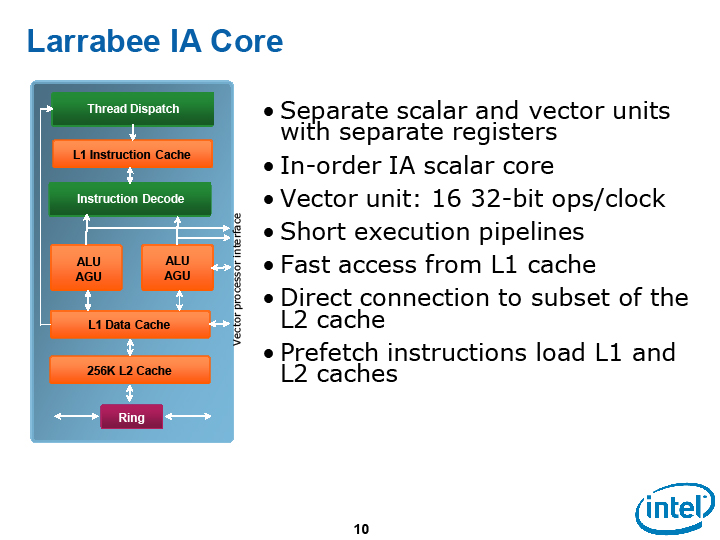 |
| LarrabeeのCPUコア |
●SSEとは異なるLarrabeeのベクタユニット
スカラユニットは、オリジナルのPentiumと非常によく似ている。Pentiumと同様に、パイプライン段数が浅く、トランジスタ数の少ない構成だという。また、パイプラインはPentiumと同じくデュアル構成になっている。そのため、最大2個のスカラ命令を同時に実行できる。
ただし、2つのパイプは同じものではなく、プライマリパイプとセカンダリパイプとして役割分担をする。プライマリパイプは、Larrabeeのスカラ命令を全て備えるが、セカンダリパイプは比較的単純な命令のみをサポートするサブセットとなっている。Larrabeeのベクタロード/ストア命令などは両方のパイプに実装されているようだ。
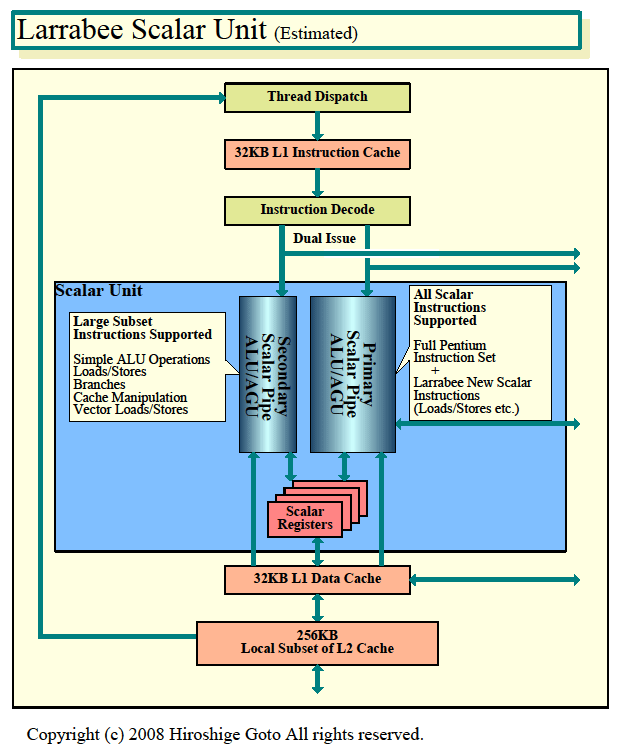 |
| Larrabeeのスカラユニット
PDF版はこちら |
ベクタユニットのチャートは、IntelでもSIGGRAPH/IDF時のスライドと、HotChips時のスライドが大きく異なっていた。左がIDF時、右がHotchips時だ。両スライドを参照しながら、スカラユニットと対照できるように暫定的に作ったのが下の図だ。
 |
 |
| ベクタユニットのチャート。左がIDF時、右がHotchips時のもの | |
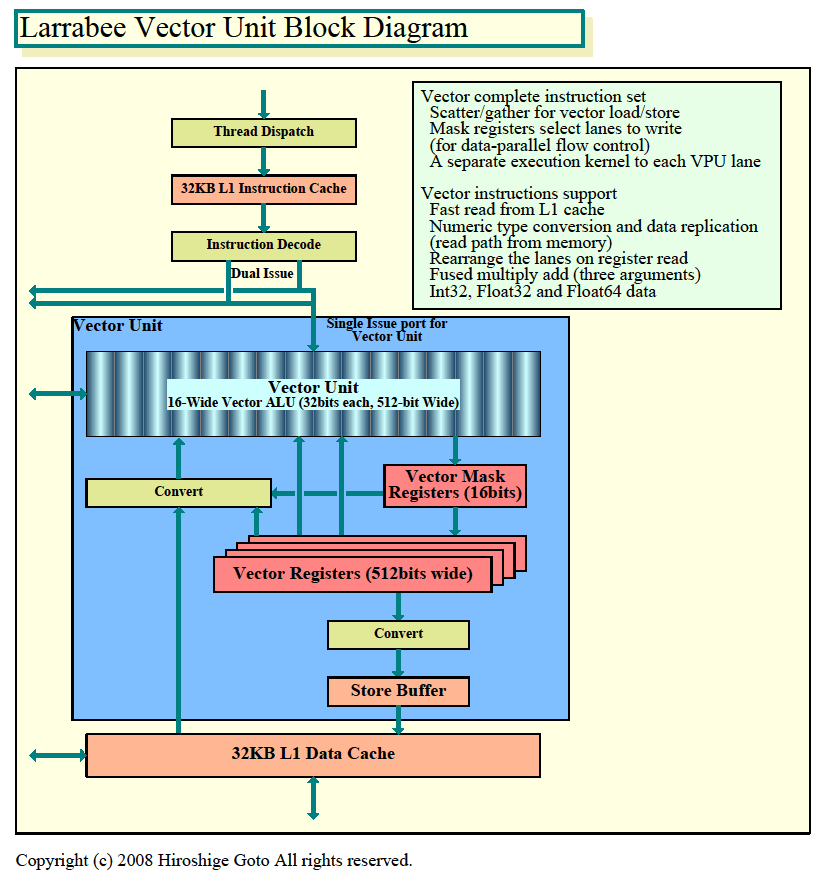 |
| Larrabeeベクタユニットのダイアグラム
PDF版はこちら |
Intelは、これまでもSSEなど短いベクタユニットをCPUに実装して来た。Larrabeeのベクタユニットはベクタ長としてはSSEの4倍版だが、根本的な違いも多い。特に目立つのはマスクレジスタを備えていることだ。マスクレジスタは、ベクタプロセッサの各レーンに1bitづつ対応する16-bit幅のレジスタだ。これが、重要な役割を果たしている。
●マスクレジスタでベクタ条件分岐とロード/ストアが可能に
Larrabeeのベクタユニットは、ベクタ条件分岐命令を実行した場合に、マスクレジスタによってレジスタやメモリへの書き込みをレーン単位でマスクできる。例えば、Larrabeeの16レーンのうち、レーン0はベクタレジスタに書き込むが、レーン1は書き込まないといった制御ができる。512-bit幅でのベクタレジスタ(またはメモリ)は、16個の32-bitデータスロットで構成されるが、各レーンに対応する32-bitのデータスロット単位で書き込みを制御できる。
そのため、プログラムの中にベクタ条件分岐があると、ベクタユニットの各レーンで、それぞれ条件判定によって異なる分岐パスを実行できる。「if-then-else」型のコントロールをレーン単位で実行できる。レーン0は条件が成立して命令パスBに分岐するが、データ1は条件が成立しないので命令パスAをそのまま実行するケースが発生したとする。ベクタユニットは、条件判定によってマスクレジスタの中の各レーンに対応するbitを立てる。マスクレジスタによって、有効なパスの結果だけをレジスタに書き込みできるようにする。例えば、レーン0はマスクが1であるため命令パスAの結果はレジスタに書き込まれないが命令パスBの結果は書き込まれるといった具合だ。そのため、16レーンそれぞれが、異なる命令パスを実行できる。また、マスクレジスタが16レーン全て0または1の場合は、片方の命令パスだけが実行され、必要ない命令パスはスキップされる。
こうした構造を持つLarrabeeのベクタユニットの各レーンは、NVIDIAアーキテクチャで言うスカラプロセッサ「SP(Streaming Processor)」の役割を果たしている。NVIDIAのGeForce 8800/GeForce GTX 200(G80/GT200)系アーキテクチャの場合、各プロセッサクラスタ「Streaming Multiprocessor(SM)」がそれぞれ8個のスカラプロセッサを内蔵する。8個のスカラプロセッサはベクタとして制御されており、同じ命令を実行する仕組みだ。だから、NVIDIAアーキテクチャは、ベクタ条件分岐ができる8レーンのベクタユニットを内蔵したプロセッサだと表現することもできる。この点で、LarrabeeとG80/GT200は非常によく似ている。
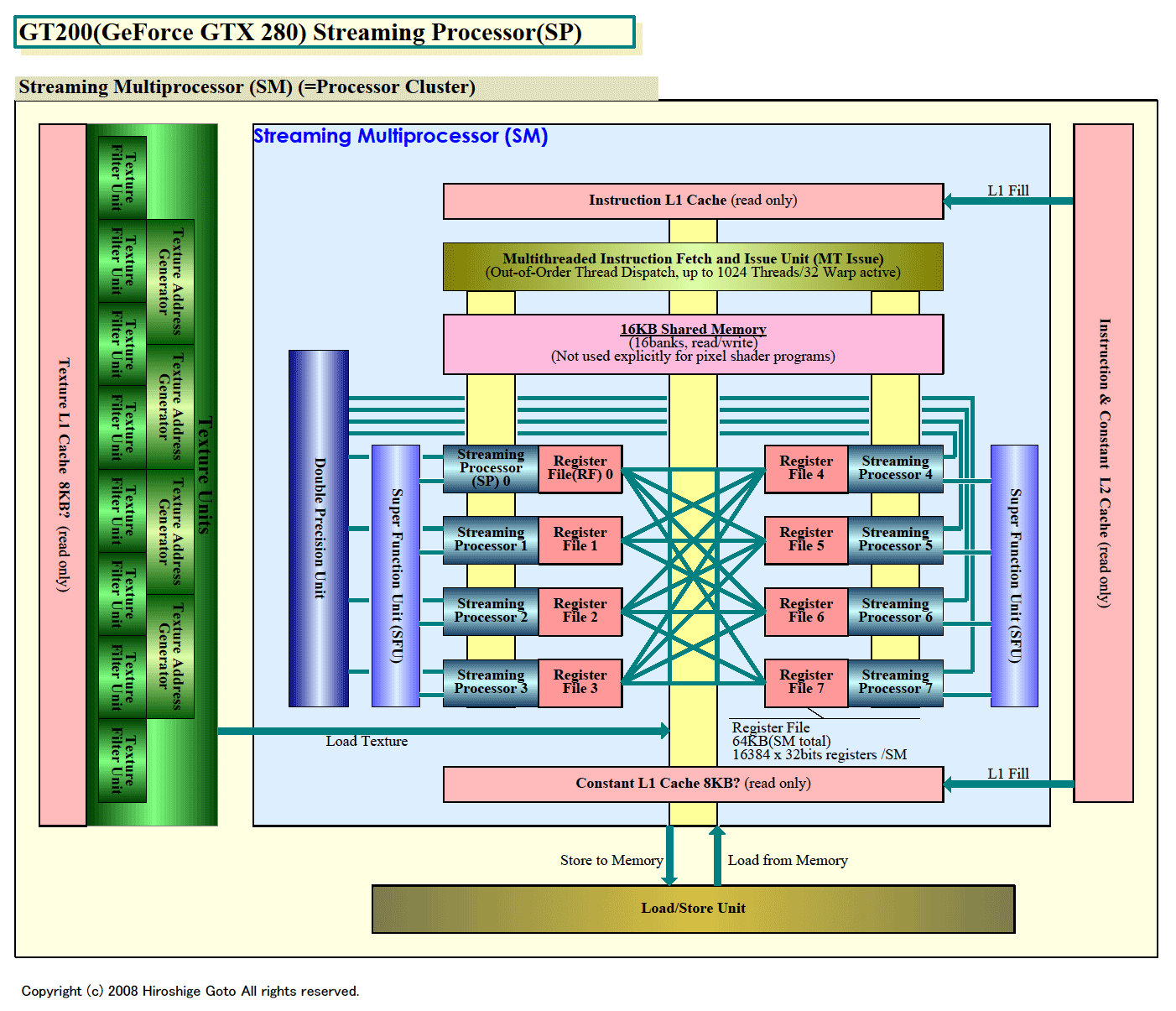 |
| GT200のStreaming Processor
PDF版はこちら |
また、ベクタロード/ストアにもマスクレジスタは使われる。例えば、16-wideのベクタレジスタの各データブロックに対してのデータのロードの際に、ロードするデータ要素をマスクによって選択することができる。
従来のIntelのベクタユニットであるSSEユニットでは、ベクタの各レーンが異なる命令パスを実行することはできなかった。そのため、厳密に同じ命令を実行するデータをパック化する必要があった。例えば、グラフィックスならRBGAの4カラー要素をパックした4-wideベクタなどに限定されていた。
しかし、Larrabeeなどのベクタユニットの場合は、その必要がない。分岐を含んだより幅広いプログラムに適用できる。「ループベクタライゼーションに適用できるため、Cで書いた通常のループコードでも16倍速くなる。プログラマ側が意識しなくても高速化できる」とゲームプログラマとして有名なTim Sweeney氏(CEO, Founder, Epic Games)は語る。
シリアルコードの中のループを、コンパイラレベルで展開して、ベクタ化してベクタユニットに割り当てることで16倍の高速化が可能になるという。Sweeney氏は、こうした利点を持つLarrabeeのベクタユニットなどは、従来のSSEタイプのベクタユニットと異なることから「New Vectors」と呼んでいる。
●動的にレーンの再構成が可能なアーキテクチャ
New Vectorsには、最新のGPUとLarrabeeが含まれるが、両者には大きな違いがある。NVIDIAやAMD(旧ATI)のGPUアーキテクチャでは、ベクタのスケジューリングなどの制御の多くはハードウェアで行なっているのに対して、Larrabeeはフルにソフトウェアで行なっている。そのため、条件分岐の効率化でも、いくつかのトリックを使うことができる可能性がある。Intelもその可能性を示唆している。
ベクタプロセッサの弱点は、コントロールフローの効率だ。分岐を実行する場合には、分岐パスAと分岐パスBの両方を実行しなければならないため、命令ステップ数が増えてしまう。そのため、条件分岐命令で扱うコンピュテーションの粒度「分岐粒度(Branch Granularity)」が小さければ小さいほど効率的となる。ところが、分岐粒度を大きくすると、プロセッサが複雑となり、ベクタユニットのシンプル性の利点が失われてしまう。プロセッサハードの効率性と、コントロールフローの効率性はトレードオフの関係にある。
現在、NVIDIAアーキテクチャは分岐粒度が32となっている。8個のスカラプロセッサが4サイクルに渡って同じ命令を実行するためだ。IntelのLarrabeeの場合は、ベクタ幅が16wayなので分岐粒度は16となるはずだ。しかし、Intelによると、実際には命令実行レイテンシを隠蔽するため4サイクル同じ命令を実行するようなソフトウェアスレッディング制御を行なう場合があるという(この場合各レーンのレジスタ本数も1/4のサイズになると考えられる)。その場合は粒度は64となり、Intelの方が粒度が大きくなる。
しかし、G80/GT200が完全にハードウェアでベクタ制御を行なっているのに対して、Larrabeeは完全にソフトウェアで行なっている。また、ベクタレジスタの各レーンをシャッフルできる機構も備えている。そのため、Larrabeeでは、アーキテクチャ上、分岐粒度を小さくする動的な制御を行なうことが可能だと推測される。
例えば、各16レーンの複数のブロック(Intel用語ではFiber)の中から、パスAに分岐するレーンを集めたブロックと、パスBに分岐するレーンを集めたブロックを動的に再構成する。新たに編成されたブロックは、それぞれパスAだけを実行するものと、パスBだけを実行するものとなる。そこで、新ブロックで、それぞれの分岐パスだけを実行すれば、分岐粒度に縛られない、効率的なコントロールフローが可能となる。
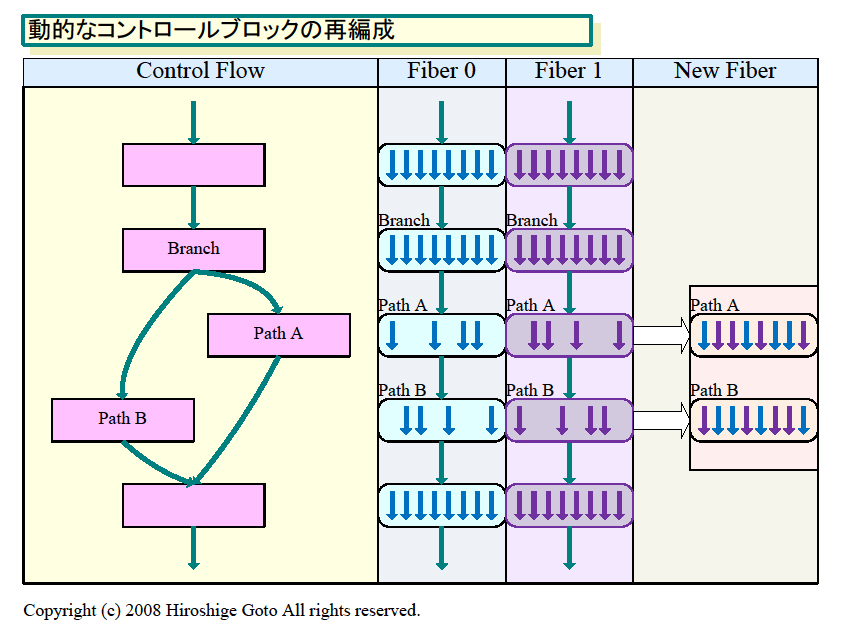 |
| ベクタ分岐条件 |
●コントロールフローの効率化がベクタプロセッサのポイント
こうしたベクタプロセッサのコントロールフローの効率化についての研究は数多く行なわれている。例えば、昨年(2007年)のプロセッサアーキテクチャカンファレンス「Micro40」では、「Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow」と題してWilson W. L. Fung氏(University of British Columbia)が講演を行なっている。上の図は、同氏のプレゼンテーションを参考にしたものだ。
GPUベンダーも、こうした制御についての研究を行なっている。AMD(旧ATI)のR700シリーズのシェーダーアーキテクトであるMichael Mantor氏(Fellow Architect, AMD)は次のように説明する。
「グラフィックスでは分岐粒度は64で十分な粒度だと考えて(R6xx/R7xxを)設計した。しかし、分岐の効率性の問題は、汎用なコンピューティングでは重要となる場合もあると理解している。分岐の効率を上げる手法はいくつか研究されており、我々も以前から検討している。分岐ブロックを動的に組み替えることは、最も効率的だが複雑で課題も多く、もっとも遠い地点(将来)にあるだろうと考えている」
非グラフィックスアプリケーションでは、分岐粒度が効率性の重要な問題になるケースが発生する可能性がある。各レーンの分岐パスが頻繁に分かれ、複雑な分岐ツリーを持つプログラムが出てくる可能性があるからだ。そのため、より汎用的な方向へと進むにつれて、ベクタプロセッサの分岐効率は重要となって行く。GPUも、汎用性も強めるために、コントロールフローの効率の改善を進めて行く必要がある。
この点で、Larrabee型アーキテクチャの場合の利点は、アプリケーションによって制御を動的に変えることができる点だ。柔軟に、ブロックのフォーメーションや制御を変更できる。例えば、グラフィックスのように分岐粒度がそれほど問題にならない場合は大きな粒度で実行。汎用的なアプリケーションで粒度が問題となるような場合にだけ、分岐パスによって、ブロックの組み替えような特殊な制御を行なうことができる。
こうした柔軟性と可能性を持つことが、ソフトウェア制御でスケジューリングを行なうLarrabee型のアーキテクチャの利点だと考えられる。
□関連記事
【10月17日】【海外】2010年以降のIntel CPUが見えてくるLarrabee新命令
http://pc.watch.impress.co.jp/docs/2008/1017/kaigai472.htm
(2008年10月31日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.