 |


■後藤弘茂のWeekly海外ニュース■モバイルに最適化された「Turion X2 Ultra(Griffin)」の実像 |
●プラットフォームを打ち出したAMD
 |
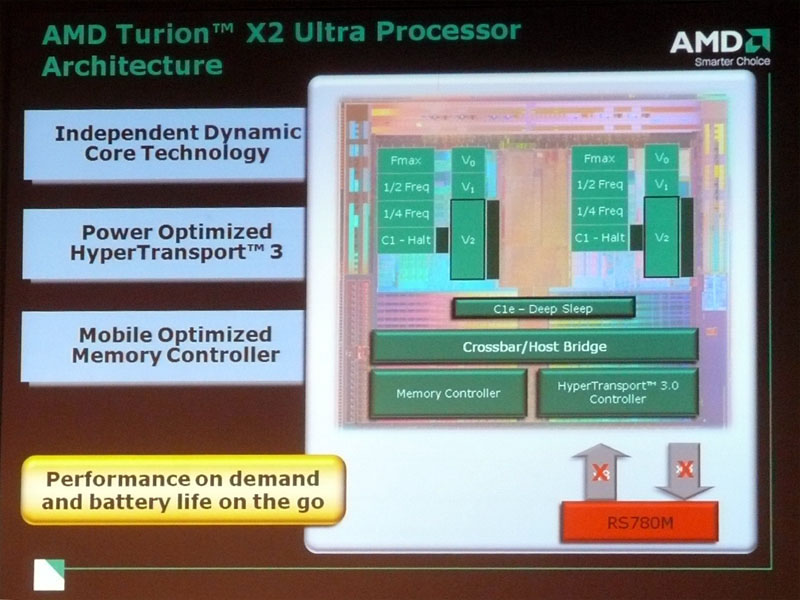
Griffinは、AMDが初めてモバイルに最適化した設計を行なったCPUで、AMDの今後のモバイル戦略の礎となるCPUだ。Pumaは、Griffinに、AMD 7シリーズ・チップセット「AMD M780G(RS780M)」と「AMD SB700」を組み合わせる。
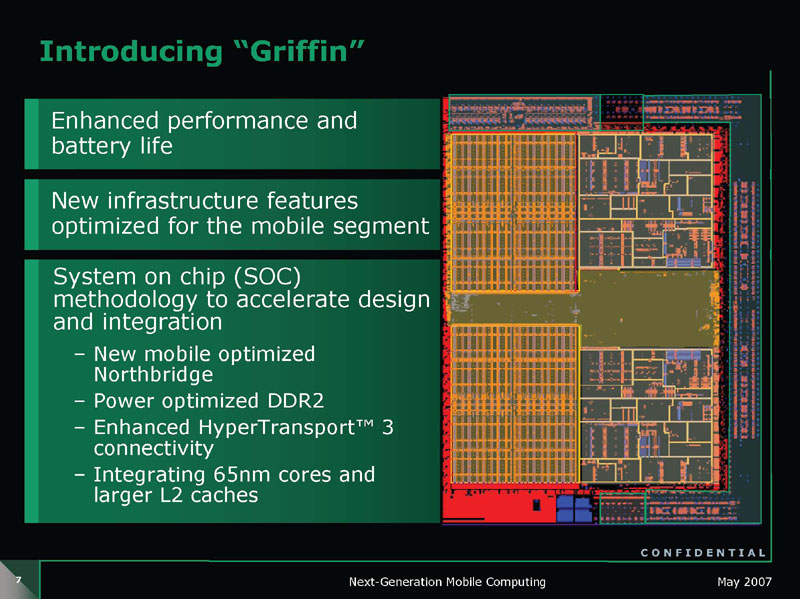
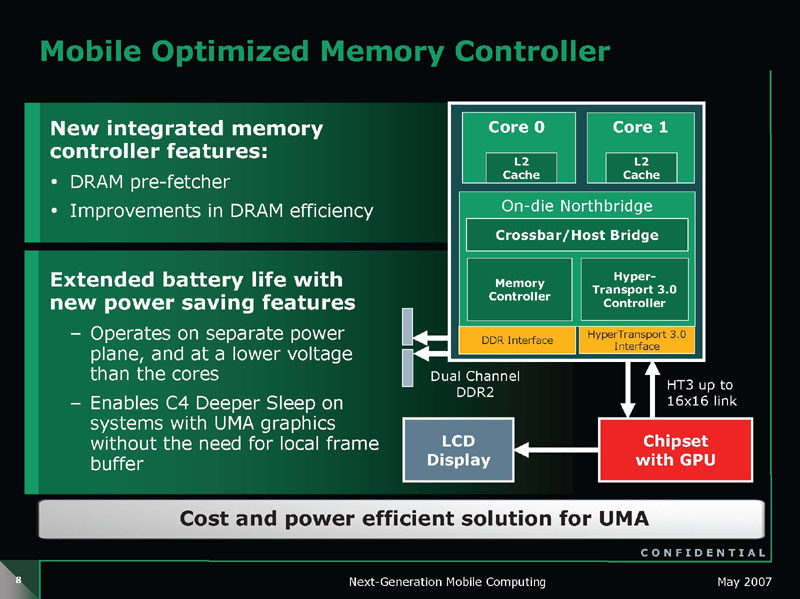
GriffinはデュアルコアCPUで、65nmプロセスで製造され、K8 Rev. Gとほぼ同じCPUコア、新設計のモバイルに最適化されたノースブリッジとデュアルチャネルDDR2メモリインターフェイスとHyperTransport 3インターフェイスを備える。キャッシュは各コア1MBずつの専用L2キャッシュを持つ。
AMDは、Intelと異なり、今回のプラットフォーム自体にはブランド名をつけなかった。ブランド名を冠しているのはCPUだけだ。しかし、ブランディング戦略とは裏腹に、発表時にはCPUの特徴を強く打ち出すことは避けているように見えた。Griffinの特徴は列挙するものの、デモを含めて強く謳ったのはプラットフォームとしての3Dグラフィックス性能だった。これは、AMDの置かれている難しい状況を反映している。
AMDにとって、対Intelで、現在差別化がしやすいのは、CPUの方ではなく、旧ATI TechnologiesのGPUとグラフィックス統合チップセットだ。GPUベンダーとして経験の深い旧ATIのGPUコアは、Intelの統合グラフィックスに対して明確なアドバンテージを持っている。エンドユーザーに対しても、「Intelだとここが描けないのに、AMDだとここを描くことができる」と、わかりやすく打ち出すことができる。こうした事情から、AMDはGriffinではなく、Pumaを前面に押し出したものと思われる。
もともと、GriffinについてはOEMから周回遅れという声も上がっていた。昨年(2007年)5月のGriffinの概要発表の後、あるメーカー関係者は「これが、今あれば強力な製品として通用する。しかし、1年後では、IntelのPenryn(ペンリン)とMontevina(モンテヴィーナ)プラットフォームがあるから、勝負をするのは難しいだろう」と語っていた。
今回のAMDのアプローチは、こうした状況をAMDが認識していることを示している。CPU単体では、Intelに対して強く出ることができるだけのインパクトはない。しかし、グラフィックスならIntelに対しての優位を謳うことができるという判断だ。
 |
 |
 |
 |
●FUSIONへと続くステップ
しかし、AMDの技術の流れで見ると、今回のPumaでは、CPU自体もかなり重要だ。なぜなら、Griffinは、AMDにとってモバイルに特化した最初のCPUであり、FUSIONと呼んでいた「Accelerated Processing Unit(APU)」へのマイルストーンであるからだ。
IntelがモバイルCPUとデスクトップ&サーバーCPUを同一アーキテクチャに統合したのとは対照的に、AMDはモバイルとデスクトップ&サーバーにCPUアーキテクチャを分化させる。最終的には、パフォーマンスデスクトップ&サーバーCPUと、モバイル&メインストリームデスクトップCPUへと分化させる構想だと考えられる。だとすると、AMDのボリュームゾーンのCPUの将来は、Griffinの延長にあることになる。
そして、それはFUSIONの構想とも絡む。AMDは、来年(2009年)後半を予定している最初のFUSIONである「Swift(スィフト)」には、Griffinのノースブリッジ機能を統合すると発表している。Swiftは、複数の第3世代STARS(K8系)CPUコア、既存のハイエンドディスクリートGPUをベースにしたGPUコアを実装し、DDR3メモリインターフェイス、キャッシュメモリ、PCI Expressインターフェイスなどで構成されるという。ノースブリッジ部分は、Griffinの発展系となる。
実際にはSwiftは、MCM(Multi-Chip Module)技術を使うことで、CPUダイ(半導体本体)とGPUダイを、1つのパッケージに統合した製品になると言われている。Swiftでは、CPUダイとGPUダイはHyperTransport 3で接続されると見られている。これは、IntelのGPU統合CPU「Havendale(ヘイブンデール)」と似たような構造だ。SwiftのCPUダイには、STARS系CPUコアを備えたGriffinの発展系が使われると推測される。そのため、Griffinのフィーチャは、来年のFUSIONを占う重要なポイントとなる。
●CPUコア自体は穏当にK8世代コアを選択
 |
K8マイクロアーキテクチャを拡張した「K10(Barcelona:バルセロナ)」コアを備えるデスクトップCPU「Phenom」系と異なり、GriffinではK8 Rev. Gとほぼ同じCPUコアを備える。CPUコアアーキテクチャから言えば、K8系のモバイル最適化CPUがGriffinだ。AMDは昨年、K8コアを使った理由を次のように説明していた。
「Griffinで目指したモバイルへの最適化は革新的なので、設計上のリスクがある。例えば、モバイルへの最適化のため、ノースブリッジ回りは新しく設計し、他にも多くの労力をかけた。そのために、CPUコア自体は安定したものであることが望ましかった。設計上のバランスから、安定したCPUコアを採用した」
AMDの弱点は、Intelと比較した場合の開発リソースの薄さだ。そのために多数のCPUプロジェクトを平行して走らせることができない。現在、メインのCPU開発チームは2つで、2チームが交替でデスクトップ&サーバーCPUを開発する一方、別なチームがモバイル向けとFUSIONの開発を行なっていると言われる。
おそらく、現在の開発リソースでは、GriffinのCPUコアをいじるような手間のかかることはできないと判断したと推測される。もっとも、AMD CPUコアはBarcelona系から電力消費が上がってしまったため、この設計判断は、結果として省電力のモバイルCPUを作る点で利点がある。
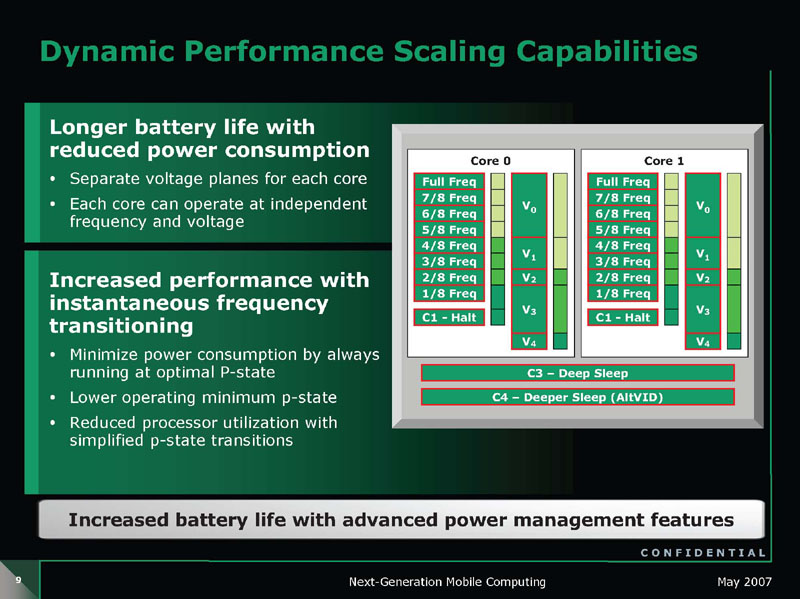
Griffin CPUコアはRev. G世代と大きくは変わらない。しかし、Griffinでは2つのCPUコアを異なる電圧&周波数で制御できるようになった。CPUコアの負荷に応じて、それぞれのコアの動作周波数を変動させるだけでなく、電圧も変動させる。そのため、Griffinでは、電圧をそれぞれ独立して可変できる電圧プレーンがそれぞれのCPUコア用に2つ用意されている。
VDD0がCPUコア0(L2キャッシュを含む)に対して、VDD1がCPUコア1に対して電圧を供給する。消費電力のうちアクティブ成分は、電圧の2乗×周波数に比例するため、2乗となる電圧の方が消費電力に与える影響がより大きい。そのため、電圧も下げることで、原理的には各CPUコアの電力を、より大きく抑えることが可能になる。しかし、ボルテージレギュレータがより複雑になり、コストがかさむという難点がある。
 |
 |
●優れたGriffin CPUコアの電力制御機構
CPUコア単位の電圧のホッピングは、IntelのモバイルCPUでも実装していない。Intelは、増え続けるCPUコアに合わせたコア単位の電圧制御には、チップサイズのCMOSボルテージレギュレータのような新しい技術が必要だと見ている。同じAMD CPUでも、デスクトップ&サーバー向けの「Barcelona(バルセロナ)」系は、Griffinと異なりCPUコア全体で同じ電圧で制御している。Barcelonaでは、4個のCPUコアには、単一のVDDCORE電圧プレーンで電力を供給される。そのため、4個のCPUコアは、例えアイドル状態のCPUコアがあっても、全て同じ電圧で動作する。
また、AMDはIntelの共有L2キャッシュの「Dynamic Smart Cache Sizing」のように、キャッシュを段階的にフラッシュする制御は行なっていない。CPUコアのキャッシュのプローブの際にはCPUコアをウェイクアップしなければならないが、その場合は最低の周波数&電圧のPステイトで起動し、電力消費とスリープステイトに戻るレイテンシを最小に抑える。また、AMDは、Intelの45nm版Core 2 Duo(Penryn:ペンリン)のような、最終的にSRAMのリテンションレベル以下にCPU電圧を下げる「C6(Deep Power Down)」型の制御は行なっていない。そのため、Griffinは、原理的にPenrynほどは最低電圧を下げることができない。
Griffinでは、複数のチップ上の温度センサ「オンダイ(On-Die)サーマルセンサ」を組み込み、動的な周波数と電圧のホッピングの制御を支援している。サーマルセンサは、浮動小数点演算ユニットなど、CPU上で特に熱くなるホットスポット近くに設置されているという。そのため、Griffinでは、今までより正確にCPU温度を検知できるようになった。センサーで検知する温度が、あらかじめ設定したしきい値を越えた場合には、自動的にCPUのPステイトを切り替え、周波数と電圧を下げる仕組みだ。従来は、温度を正確に検知することが難しかったため、余裕を持たせて制御を行なっていた。しかし、Griffinでは、正確な検知によって、温度の制約ぎりぎりまでパフォーマンスを上げやすくなった。
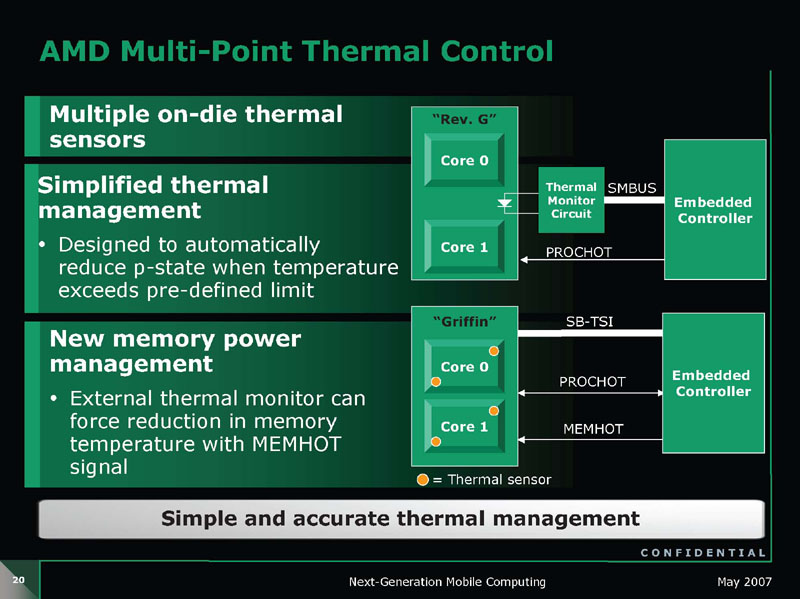 |
●ノースブリッジ部の電圧プレーンを分離
GriffinとBarcelonaのどちらも、CPUコアの電圧プレーンとは分離されたノースブリッジブロック向けの電圧プレーンVDDNBを備える。BarcelonaではL3キャッシュへの電圧もVDDNBで供給される。
CPUコアとノースブリッジの電圧プレーンを分離したことで、GriffinではCPUコアのスリープ時に、効率的な電力制御ができるようになった。下の図の1のようにCPUコアがアクティブなステイトから2のアイドル状態に移行、3のDeep Sleepモードに入るとCPUコアとノースブリッジ回りを含めてCPUの全部のユニットが省電力ステイトに入る。その状態で、外部からメモリへのアクセス要求があった場合、4のようにGriffinではノースブリッジ部分とメモリ&I/Oインターフェイス部分の電圧だけを上げてアクティブにすることができる。
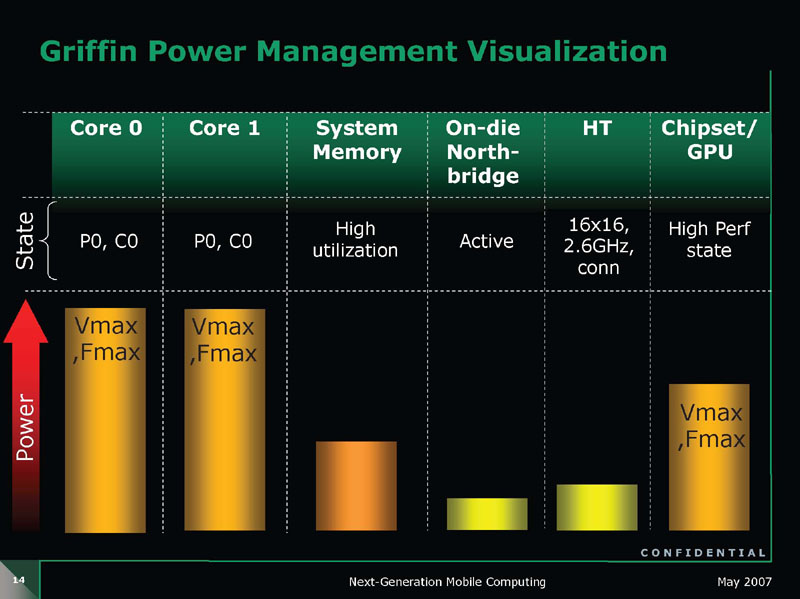 |
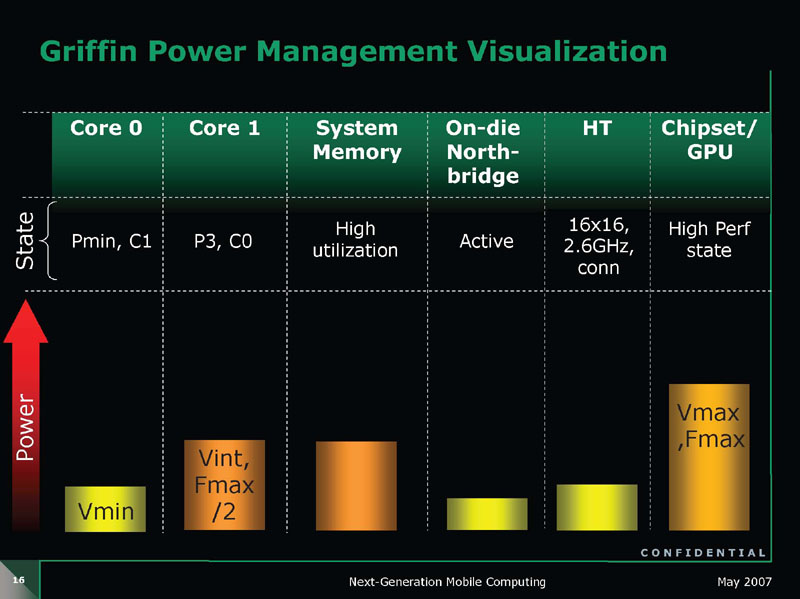 |
 |
 |
メモリアクセスがある毎にCPUコアをウェイクアップさせる必要がないため、GriffinではCPUの平均消費電力を低く抑えることができる。これは、グラフィックス統合チップセットを使う場合に重要な仕様だ。CPU側に、GPUとの共有メモリとしてメインメモリを接続しているAMDアーキテクチャの場合、グラフィックス統合チップセット側のGPUコアが共有メモリに頻繁にアクセスするからだ。従来は、グラフィックス統合チップセット側にビデオバッファを持たないと、CPUがアイドルに入ることができず、電力消費が増大してしまっていた。Griffinはこの問題を解決した。
Griffinには、VDD0/VDD1/VDDNBの他に、アナログ系とI/O向けの電圧プレーンが4系統ある。HyperTransportリンクに供給されるVLDT 1.2V、DDR2 I/Oに供給されるVDDIOとVTT、オンダイPLLに供給されるVDDA 2.5Vで、いずれも電圧は固定されている。
●HyperTransportリンクを動的に制御
電圧制御以外にもGriffinは多くの省電力フィーチャを実装している。HyperTransport 3インターフェイスには「ダイナミックHyperTransportリンクパワーマネージメント」を実装。これは、リンク幅を動的に切り替えることで、必要な帯域を確保しながら電力消費を最小にする。
Griffinは片方向16-bit、双方向で32-bitのHyperTransport 3インターフェイスを1リンク備える。Griffinの実装では、上りと下りそれぞれのリンクの幅を動的に非対照に切り替えることができる。例えば、CPUからチップセットへのダウンストリームデータはそこそこ多いが、CPUへ向かうアップストリームデータは少ない場合は、ダウンを8-bit幅、アップを2-bit幅に調整する、といった仕組みだ。
トラフィックが検知されない場合にはリンクをOFFにして0-bitにすることができる。リンク幅は、x0/x2/x4/x8/x16の5段階で切り替えることができる。使われないリンクは電力供給されないため、HyperTransport 3リンクの電力消費はミニマムに押さえられる。このほか、DRAMインターフェイスでは、DRAMセルフリフレッシュステイトの自動ハードウェア制御を備える。
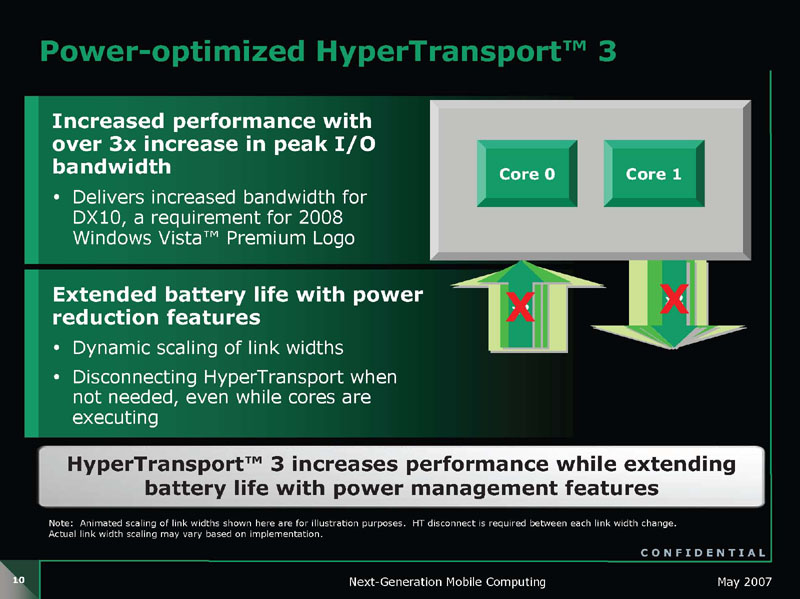 |
 |
 |
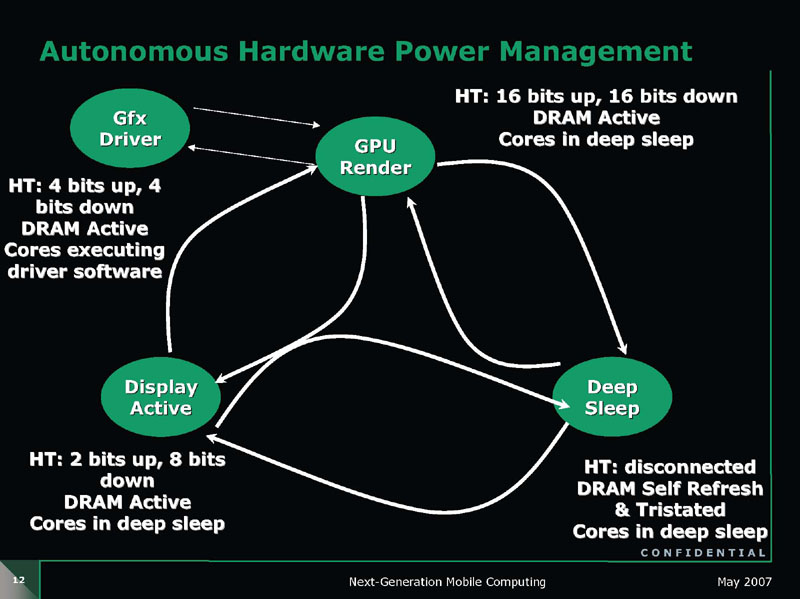
昨年のMicroprocessor Forumでは、こうした電力制御を組み合わせた例として次のようなパターンが示された。まず、CPU上で走るグラフィックスドライバがセットアップを行なっている間は、HyperTransportは上下とも4-bitずつアクティブにされ、CPUコアもDRAMインターフェイスもアクティブになっている。グラフィックス統合チップセットのGPUコアがレンダリングに入ると、HyperTransportは上下とも16-bitずつアクティブにされ、DRAMもアクティブに保たれるが、CPUコアはDeep Sleepに入る。
グラフィックスのアクティビティがなくなり、ディスプレイがアクティブに保たれた状態では、HyperTransportはCPUへの上りが2-bit、下りが8-bitとなる。フレームバッファ読み出しのためにDRAMはアクティブで、CPUコアはDeep Sleep。画面表示がOFFになると、HyperTransportはディスコネクトされ上下とも0-bitとなり、DRAMはセルフリフレッシュ、CPUコアはDeep Sleepとなる。
 |
アーキテクチャ面で多くの省電力機能を備えるGriffinだが、プロセス技術や回路設計面でも、リーク電流(Leakage)を下げることを主眼にしたモバイルへの最適化を行なっているという。MPF時のインタビューでは、ゲート絶縁膜厚などでモバイル向けの最適化を行なったほか、設計ライブラリなどもモバイル向けに用意したと説明していた。
●DRAMコントローラもモバイル向けに最適化
省電力機能以外の拡張点では、DRAMコントローラやDRAMプリフェッチャなどの拡張がある。K10系CPUのDRAMインターフェイスは、実際にはDDR2/DDR3両対応のPHYを実装している(DDR3はイネーブルされていない)が、GriffinはDDR2のみの対応となっている。2チャネルのDRAMコントローラは、Barcelona同様に2つのDRAMコントローラが独立して動作するモードと同期して動作するモードの両方を備える。
ハードウェアDRAMプリフェッチャは、必要なデータをメモリからキャッシュに先読みすることができる。Griffinのプリフェッチャは8つの異なる独立したストリームをトラックできる。ストリームプリフェッチでは、+1/+2/+3の間隔だけでなく、マイナス方向への-1/-2/-3パターンのほか、オルタナティブパターンも対応できる。8個のストリームプリフェッチャにはカウンタが設置され、特定のパターンのアクセスが一定のしきい値を超えると、プリフェッチリクエストが生成される。また、プリフェッチリクエストは、他のトランザクションとプライオリティが比較され調停される。より重要なアクセスが、投機的なプリフェッチアクセスで阻害されることがないようになっている。このあたりの仕組みはIntelとよく似ている。
 |
●将来のSoC化に備えたモジュラー設計
Griffinは、従来のAMDのデュアルコアCPUと比べるとCPUコア以外の部分の比率が増大している。その理由は、高速化するI/Oのために、バッファメモリの量を増やしたためだという。バスの無駄なアイドル状態を防ぎ、バス帯域をフルに実際の転送で埋めるために、バッファリングを強化している。これは、現在のCPUのトレンドであり、I/O回りの回路の占める面積が増大する一方、実際に演算するCPUコアの面積は相対的に小さくなって来ている。パフォーマンスボトルネックがコンピューティングよりデータの移動にあるケースが増えているからだ。
また、Griffinでは、将来のFUSION世代に備えるために、モジュラー設計が行なわれた。CPUを構成する各ブロックをモジュール化して設計、コンポーネントの組み替えが柔軟に行なえるようになっている。コンフィギュレーションの異なるCPUを、比較的迅速かつ低労力で開発できる。SoC(System on a Chip)では以前から行なわれていたアプローチだが、パフォーマンス重視のCPUでは、これまでは一般的ではなかった。
モジュラー化では、各モジュール間のインターフェイスを再設計して、コンポーネント間の接続をしやすい、クリーンなインターフェイスにする必要がある。しかし、インターフェイスのクリーン化は、オーバーヘッドを大きくしてパフォーマンスを削いでしまう場合がある。
そのため、AMDは、Griffinでは2つのレベルでの内部インターフェイスの標準化を行なっている。まず、パフォーマンスがクリティカルではないインターフェイスについては、簡素化して接続をしやすくした。しかし、CPUコアとノースブリッジ間のようにパフォーマンスクリティカルなインターフェイスは、シンプル化すると性能に影響が出る。そこで、そうしたインターフェイスについては、シンプル化を避け、インターフェイスの仕様の文書化とベリファイに集中したという。コンポーネントレベルでベリファイし、仕様を明文化することで、設計を容易に移すことができるようにしたという。
●性能や消費電力での違い薄いプロセス技術の差
Intelは45nmプロセスを前面に押し出してPenrynを売り込んでいる。そのため、65nmプロセスのGriffinは、数字の面では1時代遅れに見える。しかし、現在のプロセス技術のトレンドでは、プロセス世代の進歩は必ずしも高性能や低消費電力を意味しない。それは、ムーアの法則によるプロセス世代毎のトランジスタ数の倍増は続いていても、それ以外の要素のスケーリングがついて来なくなってしまったからだ。
伝統的な「CMOSスケーリング」では、微細化につれて、トランジスタのスイッチ速度が約140%速くなり、トランジスタ駆動電圧が約70%に下がった。理論上は1世代の微細化で、動作周波数は140%になり、消費電力は50%(周波数を上げた場合)になった。しかし、現在は電圧はほとんど下がらず、スイッチ速度もあまりスケールしなくなり、しかもリーク電流(Leakage)が増えてしまった。そのため、単純にプロセスを微細化しただけでは、消費電力の低減も、動作速度の向上も、それほど見込むことができない。つまり、現在では、65nmや45nmといった、プロセス世代の数字の違いは、それだけではコスト削減以上の効果をそれほどは意味していない。
現在では、プロセス微細化に伴う、電力低減や性能向上は、微細化そのものではなく、付帯するプロセス技術の改良に負うところが大きい。歪みシリコンやHigh-kゲート絶縁膜はその好例だ。Intelの45nmプロセスのスペックが優れているのは、こうした技術のおかげだ。しかし、トランジスタへの新材料の導入はリスクが大きい。製造歩留まりや信頼性に影響を与える可能性があり、ノーコストではない。Intelはかなりのリスクを背負って45nmでの性能向上を手に入れている。
こうした事情から、Griffinが65nmプロセスであることは、それだけでは競争上の不利を意味しない。しかし、大きなダイサイズ(半導体本体の面積)による高コストは、AMDにとってマイナスに働く。また、マーケティング上では、数字の違いは比較上の不利に働く。まだ、かつての伝統的なCMOSスケーリングがうまく働いていた時のイメージを持つ人が多いからだ。
□関連記事
【6月5日】【COMPUTEX】AMDプレスカンファレンス編
AMDがノートPC向け新プラットフォーム“Puma”を紹介
http://pc.watch.impress.co.jp/docs/2008/0605/comp12.htm
【2007年5月18日】AMD、次世代モバイルCPU「Griffin」とプラットフォーム「Puma」を発表
http://pc.watch.impress.co.jp/docs/2007/0518/amd.htm
【2007年5月24日】AMD初のモバイル専用CPU「Griffin」の正体
http://pc.watch.impress.co.jp/docs/2007/0524/kaigai361.htm
【2007年5月24日】【MPF】【AMD編】Griffinの詳細を発表
http://pc.watch.impress.co.jp/docs/2007/0524/mpf02.htm
(2008年6月9日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.