
ISSCC 2008レポート
Sunがサーバー向けハイエンドプロセッサ「Rock」の概要を公表
 |
| 「Rock」(開発コード名)のチップ写真。4億1,000万個のトランジスタを集積した。チップ面積は396平方mm。製造技術は65nmのCMOSプロセス、11層金属配線。チップの中央にクロスバースイッチ(写真での表記はData Switch)、その上下に2次キャッシュ(写真での表記はL2 data)を配置した。なお2次キャッシュの隣にMCUとあるブロックは、メモリコントロールユニット |
カンファレンス会期:2月4日~6日(現地時間)
会場:米国カリフォルニア州サンフランシスコ市
半導体回路技術に関する世界最大の国際会議「ISSCC 2008」のメインイベントであるカンファレンスが、2月4日(米国時間)午前に始まった。
4日の朝はカンファレンスの開催に先立ち「Formal Opening of the Conference」と題した15分ほどのセッションがあり、ISSCC 2008の概要をISSCC実行委員会の議長が紹介した。ISSCCの規模や国際色などが分かるので、少しだけ紹介したい。
ISSCCの参加者は非常に多く、3,000名を超える。実行委員会の予測では3,450名前後が参加する。ちなみに2007年の参加者は3,586名、2006年の参加者は3,538名である。両年とも会場は今回同様にSan Francisco Marriott Hotelだった。ISSCCの開催期間中は、休憩時間ともなると講演会場の通路やホテルのロビーなどは人だかりが凄く、歩くのに困るほどになる。今回は会場のホテルが一部工事中のためにロビーが狭くなっており、4日の講演が終了した段階では前年よりも混雑しているように感じた。
講演発表の件数は例年、200件を超える。今回は3日間で237件の講演を予定している。地域別では北米が101件と最も多く、欧州が69件、アジアが67件である。例年と同様に北米の発表件数が多い。企業と大学で分けると、企業の発表件数が125件、大学の発表件数が112件と、大学よりも企業の発表件数がやや多い。かつては企業の発表件数が大学の発表件数をはるかに上回っていたが、最近は大学の発表が増えて半分ずつを占めるようになってきた。
それでは技術講演の紹介に移ろう。前日レポートでも記したが、4日の午前は招待講演で、一般講演は午後に行なわれる。午後の一般講演では米Sun Microsystemsが、新規に設計したサーバー向けハイエンドプロセッサを公表したので、その概要をまずレポートする。
●16個のCPUコアでマルチスレッディング
米Sun Microsystemsは約4年前に、1個のCPUコアで複数のスレッドを処理するマルチスレッディング技術(Sunはchip-multithreadingと呼称)を搭載した複数のマルチコアSPARCプロセッサファミリを開発するとのロードマップを公表した。そしてこれまでに開発コード“Niagara”や“Niagara2”などのマルチスレッディング対応マルチコアSPARCプロセッサを開発してきた。
ISSCC 2008で4日にSunが発表したマイクロプロセッサ(講演番号4.1および講演番号4.2)も、マルチスレッディング技術を採用した。これは、2007年1月に設計の完了を発表し、2008年に量産予定のマルチコアハイエンドプロセッサ「Rock」(開発コード名)とみられる。なお学会であるISSCCは製品の宣伝につながる内容の発表を原則禁じているため、講演タイトルや講演論文集(名称は「Digest of Technical Papers」 )などにRockの名称は入っていない。本レポートでは発表チップが“Rock”であることを前提に、講演概要を紹介する。
Rockは16個と数多くのCPUコアを内蔵するSPARCアーキテクチャのプロセッサだ。16個のCPUコアで最大32個のスレッドを並列に実行する。この部分だけを見ると、CPUコア当たりで同時実行するスレッド数は2個となり、SPARCプロセッサとしてはそれほど高い性能を発揮するようには感じられない。
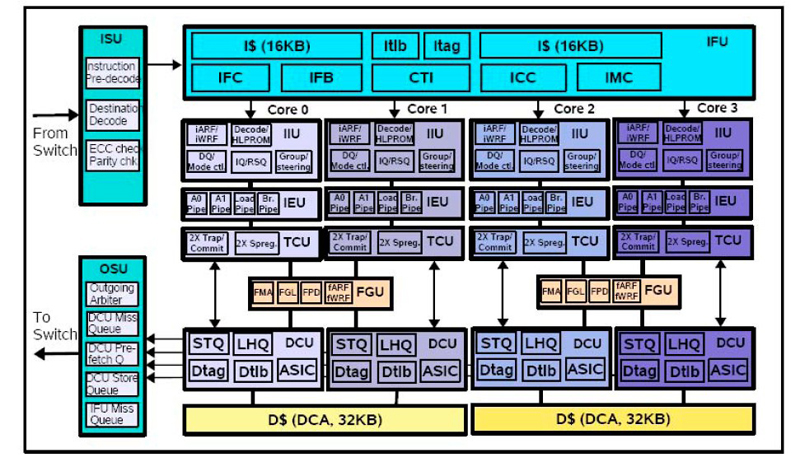 |
| 4個のCPUコアで構成されるクラスタの内容。CPUコア(図中のCore0~Core3)の上に命令フェッチユニット、下にデータコントロールユニットを配置した。図中にFGUとあるのは浮動小数点演算ユニット |
例えばSunがこれまでに開発してきたNiagaraは4スレッド、Niagara2は8スレッドを同時に実行できる。Niagara2は8個のCPUコアを内蔵しており、最大で64スレッドを並行して処理する。一方、Rockはその半分の最大32スレッドしか同時に処理できない。にも関わらず、Rockは非常に高い性能の実現を狙っている。設計思想がNiagara(およびNiagara2)とは、かなり違う。
RockがNiagaraおよびNiagara2と異なる点は大きく3つある。1つは、アウトオブオーダを初めて採用したことだ。Sunはこれまで、回路規模および消費電力の増大を主な理由としてアウトオブオーダの採用を見送ってきた。Rockではアウトオブオーダを採用して実効的な演算性能を高めている。しかも命令順序を元のインオーダに戻さず、リオーダーバッファを省いた。このため単純なアウトオブオーダに比べると回路規模と消費電力が抑えられた構造となっている。
2つ目は、実行スレッドの前に「スカウトスレッド(Scout-Thread)」と呼ぶスレッドを走らせてデータをプリフェッチし、あらかじめ命令を実行してリタイアしておく機能(スカウトスレッディング)を備えたことだ。最先端のマイクロプロセッサではメモリアクセスの待ち時間が演算の実行性能を低下させており、待ち時間をどこまで減らせるかが工夫の見せ所となっている。Rockでは1個のCPUコアが2個のスカウトスレッドを実行できるので、最大で32個のスカウトスレッドが走ることになる。メモリアクセスの遅れを考慮すれば、アプリケーションによっては実効的な性能が著しく向上することになる。
そして3つ目が、動作周波数を2.3GHzに高めたことである。Niagara2の動作周波数は1.4GHzなので、CPUコア当たりの演算性能は単純計算で1.6倍に向上する。
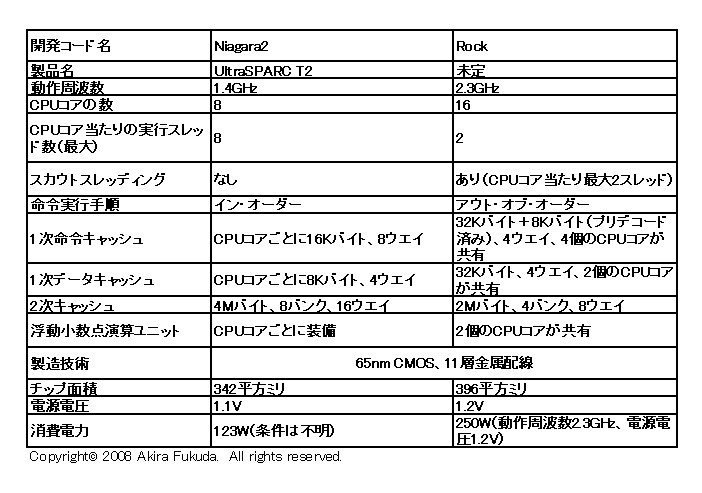 |
| Niagara2とRockの比較 |
Sunは講演で、シングルスレッドの処理でも高い性能が得られることをRockの設計目標にしたと述べた。上記の3点はいずれも、CPUコアが単一のスレッドを処理したときにも性能が向上する工夫である。
それではRockの実際のチップについて少し見ていこう。65nmのCMOSプロセスで製造したチップの面積は396平方mmで、ほぼ20mm角に近い。CPUコア1個の面積は約14平方mmなので、16個のCPUコアだけで224平方mmを占める計算になる。動作周波数2.3GHz/電源電圧1.2Vのときの消費電力は250Wである。CPUコア1個の消費電力はおよそ10Wなので、16個のCPUコアすべてが動くと、CPUコアだけで160Wを消費することになる。
これらの数値をNiagara2と比較しよう。Niagara2のチップ面積は342平方mm、CPUコア1個の面積は12平方mm、消費電力は123Wである。Niagara2の製造技術はRockと同じ65nmのCMOSプロセス、11層金属配線を採用した。両者を比較すると、CPUコアの数がNiagara2の8個からRockの16個と2倍に増加したのに対し、RockはNiagara2と比較してチップ面積がそれほど増えていないことが分かる。
チップ面積があまり増えなかったのは、キャッシュメモリを複数のCPUコアが共有する構成を採用したことが大きい。4個のCPUコアをまとめたクラスタを1つの単位とし、1個のクラスタ内で1個の1次命令キャッシュ(32KB+8KB)を4個のCPUコアが共有し、1個の1次データキャッシュ(32KB)を2個のCPUコアが共有する。浮動少数点演算ユニット(FPU)も、クラスタ内で2個のCPUコアが1個のFPUを共有する構成とした。そして2次キャッシュは4個のクラスタが共有する構成でメモリ容量は2MBと、Niagara2の半分しかない。この結果、キャッシュとFPUの回路面積をRockでは大幅に節約し、チップ面積の増大を抑えている。
なお4個のクラスタと2次キャッシュ(4バンク構成)の間はクロスバースイッチで接続される。クロスバースイッチは5×5チャンネルのスイッチを2個内蔵した構成で、読み出しのバス幅は1チャンネル当たり298bit、書き込みのバス幅は1チャンネル当たり140bitといずれも広く、特に読み出しのバス幅を広く確保している。
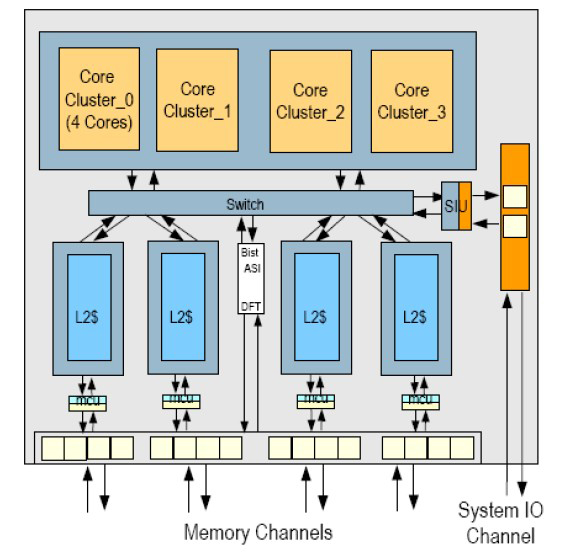 |
| Rockの内部ブロック。中央のクロスバースイッチ(図中での表記はSwitch)がクラスタと2次キャッシュ、システム入出力インターフェイスとの間を結んでいる。システム入出力インターフェイスは1チャンネル当たりの転送速度が2.67GbpsのSerDesで構成してあり、送信と受信にそれぞれ15チャンネルを割り当てている。図中の下端は外部3次キャッシュとデータをやり取りするメモリインターフェイスで、これも転送速度が2.67GbpsのSerDesで構成した。送信チャンネルが96チャンネル、受信チャンネルが160チャンネルと読み出し重視のチャンネル構成である |
□ISSCCのホームページ(英文)
http://www.isscc.org/isscc/
□関連記事
【2月4日】【海外】IntelがいよいよSilverthorneとTukwilaの概要を発表へ
http://pc.watch.impress.co.jp/docs/2008/0204/kaigai415.htm
【2月4日】【ISSCC】低消費プロセッサと低コスト不揮発性メモリ
http://pc.watch.impress.co.jp/docs/2008/0204/isscc01.htm
【2007年1月19日】米Sun、最新マルチコアプロセッサ「ROCK」の設計完了(ENTERPRISE)
http://enterprise.watch.impress.co.jp/cda/foreign/2007/01/19/9453.html
【2006年10月12日】【MPF】Sun Niagara2の詳細が明らかに
http://pc.watch.impress.co.jp/docs/2006/1012/fmpf03.htm
【2003年4月17日】サン、「チップ・マルチスレッディング」を推進
http://pc.watch.impress.co.jp/docs/2003/0417/sun.htm
□ISSCC 2007レポートリンク集
http://pc.watch.impress.co.jp/docs/2007/link/isscc.htm
(2008年2月5日)
[Reported by 福田昭]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2008 Impress Watch Corporation, an Impress Group company. All rights reserved.