
|
Fall Microprocessor Forumレポート
Sun Niagara2の詳細が明らかに
 |
カンファレンス会期:10月10日~11日(現地時間)
会場:米カリフォルニア州サンノゼ DoubleTree Hotel
Fall Microprocessor Forum 2006のカンファレンスで、Sun MicrosystemsのPrincipal Architect Robert Golla氏は、UltraSparc T1の後継となるNiagara2の詳細について語った。
現在Sun MicrosystemsのSun Fire T1000/2000に採用されているのがNiagaraこと、UltraSPARC T1プロセッサである。UltraSPARC T1は、簡単にいえばシンプルなコアを多数使ってシステム全体の性能を向上させようというもの。現在のUltraSPARC T1は、4スレッドをSMTで実行するコアを8個搭載し、最大32スレッドの同時実行が可能なプロセッサ。コアは、SPARC V9準拠のシンプルコアで、パッケージ全体で最大73Wという低消費電力となっている。
UltraSPARC T1の基本になる考え方は、CoolThread、あるいはThroughput Computingなどと呼ばれている。半導体技術の進歩により、プロセッサの実行速度は向上したものの、メモリのアクセス速度やレイテンシとの乖離が進んでいる。
これを解決するために、多層キャッシュやアウトオブオーダー実行、インテリジェントなプリフェッチといった技術が使われてきたが、これらは、達成される性能向上と比較すると必要とされるトランジスタ数が大きくなる。つまり、大量のトランジスタ(あるいはそれが占有するダイサイズ)の増加に比べると、性能向上部分はあまり大きくないといえる状態になっている。
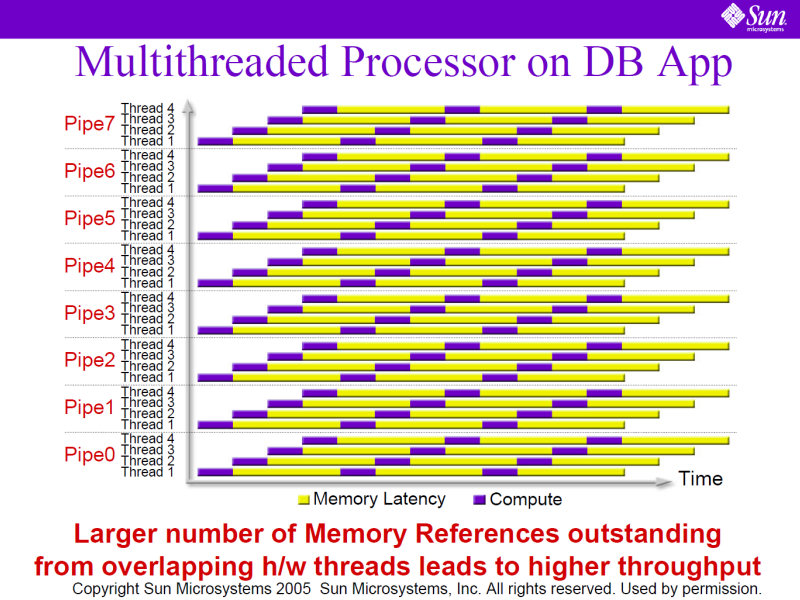
CoolThread技術では、メモリレイテンシが大きいという前提で設計され、命令のメモリアクセス待ちの間に、ほかのスレッドの命令を実行するようにした。つまり、多数のスレッドを同時実行すれば、1つのスレッド内の命令がメモリレイテンシにより次の命令に進めなくても、他のスレッドの命令が実行できるわけだ。
この構造では、CPU側でメモリレイテンシを隠蔽する必要がなく、コアはシンプルなままでいい。つまり、メモリレイテンシを隠蔽するために大量のトランジスタを使う必要がなく、より多くのコアを同じ面積に搭載できるわけだ。また、アウトオブオーダーのような機能を省略したとしても、性能低下は僅かにとどまる。
多数のサーバーを配置するデータセンターやそれを利用する企業にとって、システムの消費電力は大きな問題となっている。単に電力を消費するだけでなく、その冷却などでデータセンター全体として大きな電力を使うことになってしまうからだ。UltraSPARC T1は、シンプルなコアを使うため、この点でも有利。
ちなみに、UltraSPARC T1の基本的なコンセプトは、Sun Microsystemsのオリジナルではなく、2002年にSunに買収されたAfara Websystemsのものだ。といっても、この会社はSunでUltraSPARCを設計したLes Kohn氏や、HydraマルチプロセッサのKunle Olukotun氏などが設立したもの。UltraSPARCベースのマルチプロセッサを開発していて、Sunとまったく無関係ではない。
 |
 |
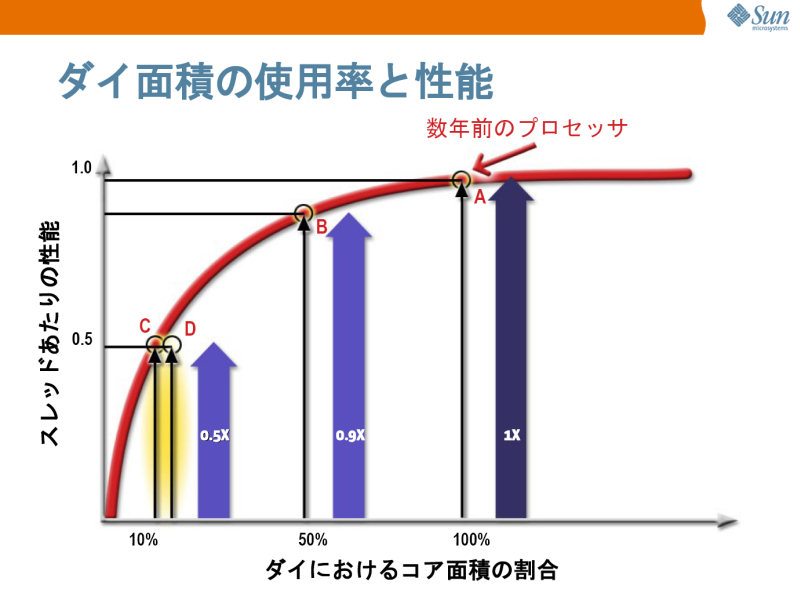
| アウトオブオーダーやレジスタリネーミングなど、高速化のための技術が高度になるにつれ、必要となるトランジスタ数が増え、性能向上分は僅かになっていく。このため、同じアーキテクチャで見ると、トランジスタを9割削減しても性能は半分程度にしか落ちない。CoolThreadはこの原理を利用して、シンプルなコアを多数搭載する | CPUの実行速度に比較してメモリレイテンシが大きくなっても、多数のスレッドを同時実行させることで、メモリアクセスが完了するまでの間に他の命令を実行できる |
●シングルスレッド性能の低いUltraSPARC T1
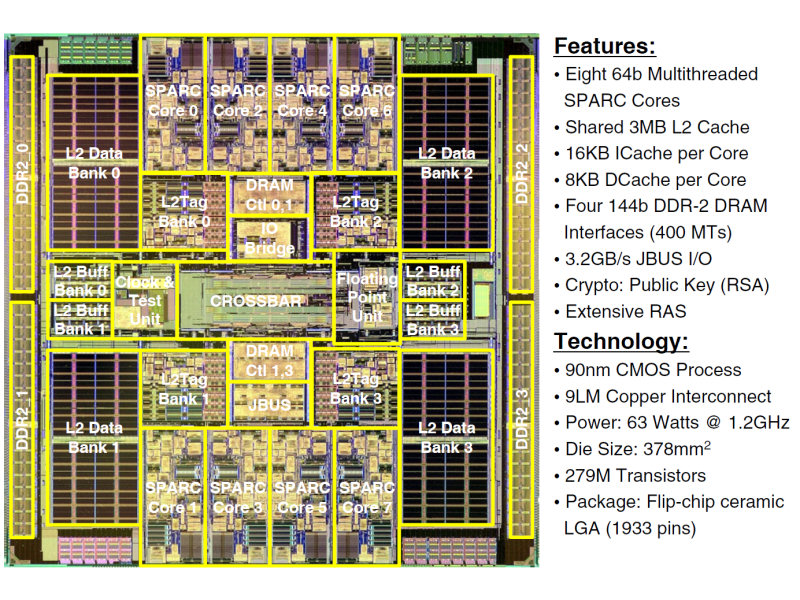
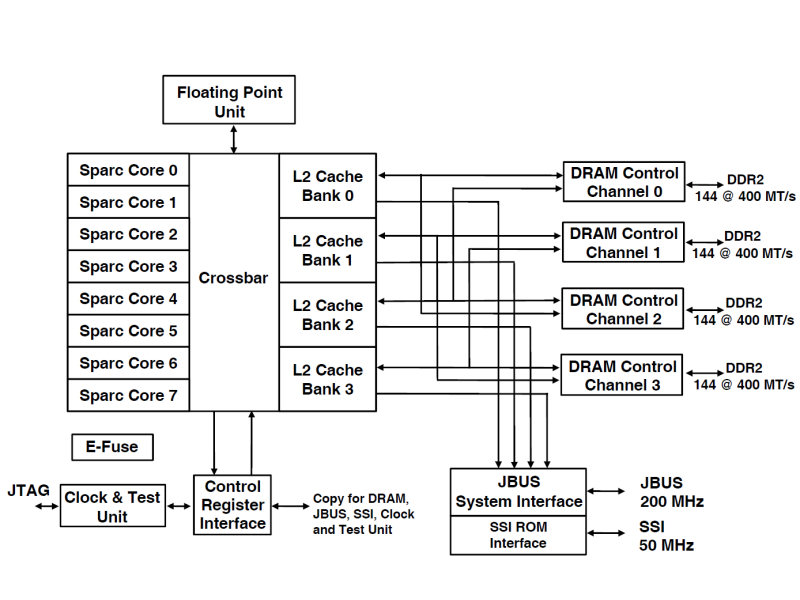
UltraSPARC T1は、8コアをクロスバーで4つの2次キャッシュ、FPUユニット、システムバスと接続している。4つの2次キャッシュには、それぞれメモリコントローラが接続されていて、DDR2メモリに対応。90nm CMOSプロセスで作られ、2億7,900万トランジスタを搭載している。
コア部分は6段の整数演算パイプラインをマルチプレクサで切り替えて、4スレッドを実行できるようにしてある。
UltraSPARC T1は、用途によっては高い性能を発揮するものの、あまり性能の出ない用途もあり、主にネットワーク関連アプリケーションのエッジ部分などに使われることが多い。原因の1つは、整数演算性能に比べて浮動小数点演算の性能が低いことである。
もう1つは、スレッドの数とその平均的な処理時間の関係によって、性能を発揮できない場面があることだ。UltraSPARC T1は、最大32スレッドの同時実行が可能だが、シングルスレッド性能はそれほど高くない。シングルスレッド性能を高くしないで、同じ面積により多くのコアを詰め込めるというのが基本原理だからである。
UltraSPARC T1の場合、現在の多くのアプリケーションに対して、シングルスレッド性能が少し低すぎた。正確にいうと、同時実行できるスレッド数とシングルスレッド性能のバランスが現状のアプリケーションからみると悪かった。
 |
 |
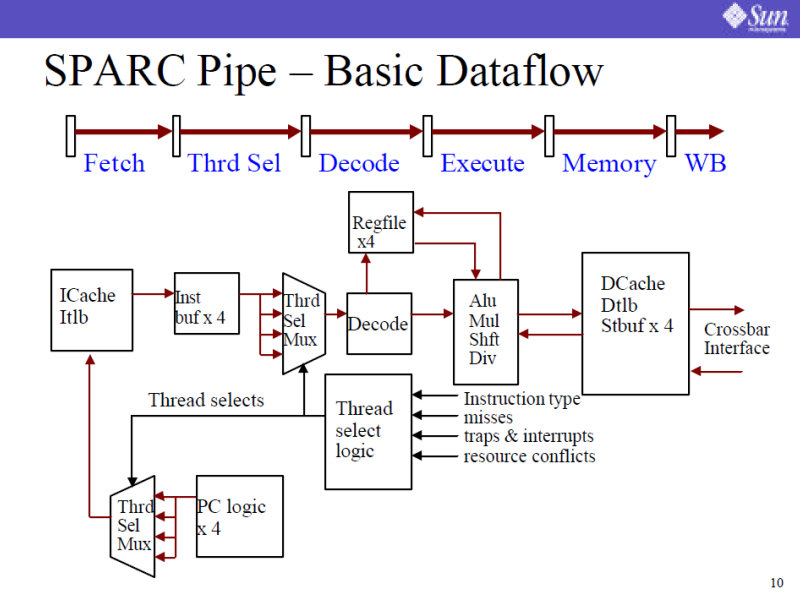 |
| UltraSPARC T1のダイ写真。上下左右が対称な構造になっている | UltraSPARC T1のブロックダイアグラム。4スレッド同時実行可能な8コアをクロスバーで4バンクの2次キャッシュと接続。2次キャッシュには、DDR2メモリコントローラが接続されている。また、1つの浮動小数点演算ユニットを8つのコアで共有している | UltraSPARC T1のコアパイプライン。シングルイシューの整数演算パイプラインのみを持ち、4つのスレッドを順次切り替えて実行していく |
●UltraSPARC T1の2倍の性能を目指すNiagara2
これを解決するためにSun Microsystemsが開発しているのがNiagara2である。Niagara2は、UltraSPARC T1の2倍の性能を達成することを目標に開発された。
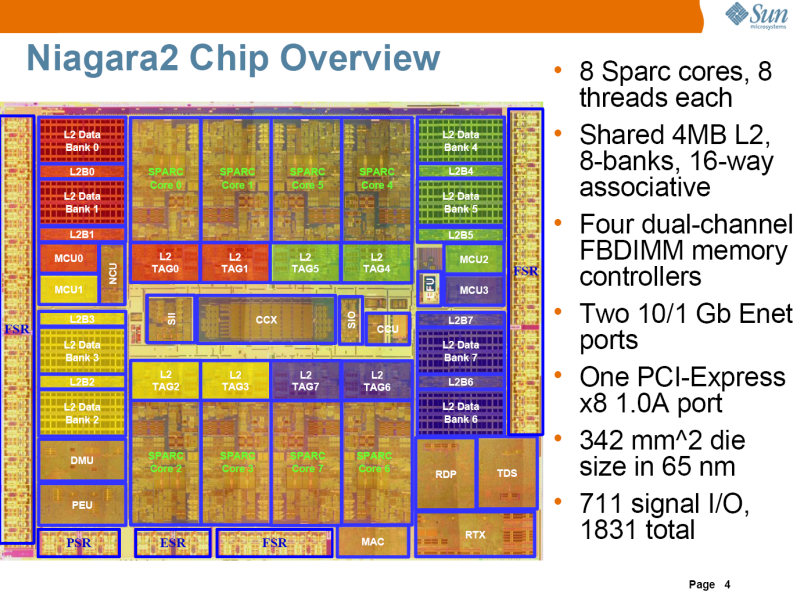
コア数は、UltraSPARC T1と同じく8つだが、1コアあたり8スレッドの同時実行が可能になった。コア数を16に増加することも検討されたが、そうなるとコア部分の面積が増え、浮動小数点演算ユニットなどを入れる余地がなくなってしまう。このため、コア数はそのままに、同時実行できるスレッド数を増やすことにしたようだ。
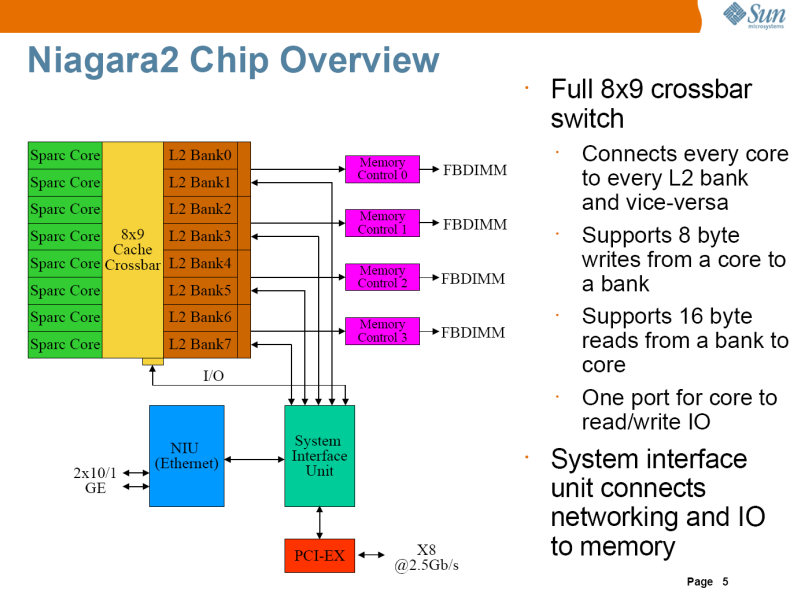
クロスバーで2次キャッシュやシステムバスを接続する点は同じ。ただし、2次キャッシュは8バンクになり、メモリコントローラは、FB-DIMM対応である。
UltraSPARC T1では、4スレッドを切り替えてパイプラインで処理していたが、Niagara2では、実行ユニットが2つあり、8スレッドを2つにわけてパイプラインを構成している。ただし、ロードストアユニットは、2つのパイプラインで共有している。
また、UltraSPARC T1では、浮動小数点演算ユニットは1つしかなく、これを8つのコアで共有しているため、浮動小数点演算性能を落とす原因となっていた。Niagara2では、各コアが個別に浮動小数点演算が可能になった。
また、コア内に暗号処理用のストリームプロセッシングユニット(SPU)を配置し、DESやAESなどの暗号化処理や、ハッシュ計算などをコアのパイプラインと並行して行なわせることができる。またNiagara2は、Ethernetインターフェースを内蔵していているが、SPUにより、10GbitのEthernetポートからのパケットをワイヤスピードで処理できる。
これらにより、整数演算はシングルスレッド性能でUltraSPARC T1の1.4倍以上となり、浮動小数点のシングルスレッド性能は5倍、プロセッサ全体では10倍以上となるようだ。
Niagara2は、5月にファーストシリコンが完成、すでにSolarisが動作している状態だという。製品としての出荷は2006年後半だが、年内には試作機を一部ユーザーに提供できるという。
 |
 |
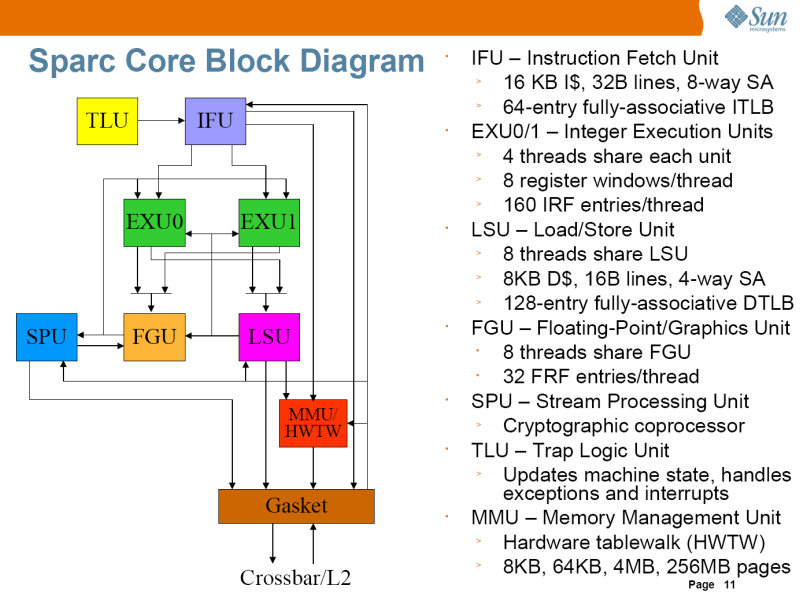 |
| Niagara2のダイ写真。中央部分がクロスバーになっている。65nmプロセスで、ダイサイズは342平方mmと、UltraSPARC T1とほぼ同じ大きさ | Niagara2のブロックダイアグラム。8つのコアが8バンクの2次キャッシュとクロスバーで接続され、その先に4つのメモリコンロトーラが接続されている。また、2つの10Gbit Ethernetユニットと、PCI Expressインターフェイスも内蔵されている | Niagara2コアのブロックダイアグラム。浮動小数点演算ユニットやストリーミングプロセッシングユニット、ロードストアユニットなどが追加されている。Gasketは、クロスバーとの接続部分。命令は、IFU(Instruction Fetch Unit)によりフェッチされ、2つの実行ユニットEXU0とEXU1で実行される |
 |
 |
|
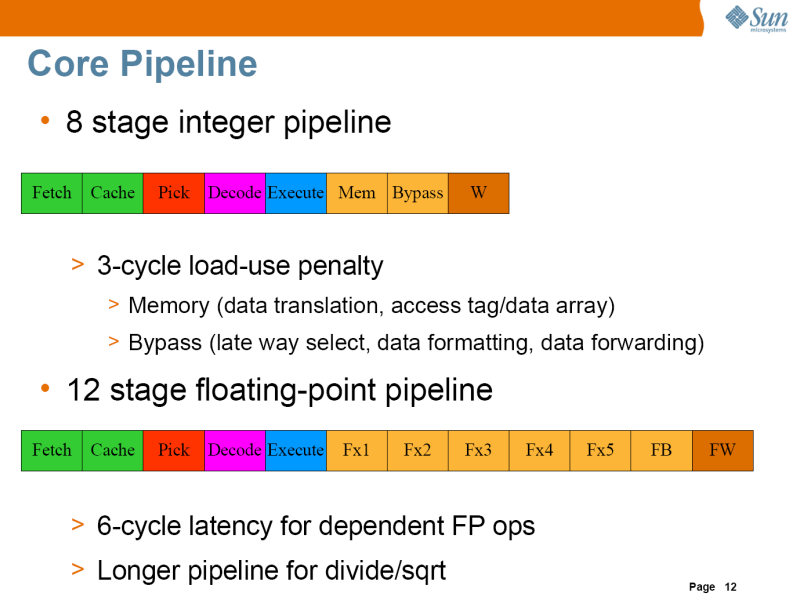
| Niagara2コアのパイプライン。整数で8ステージ、浮動小数点で12ステージになっている。ピックステージは、キャッシュされた命令を2つのグループに分けるステージである。1次命令キャッシュは、IFUにあり、16KB、1次データキャッシュは、ロードストアユニット(LSU)にあり、8KBである | コアが実行する8つのスレッドは、ピックステージで2つのグループに分けられ、整数実行ユニット以下のステージで処理されていく。メモリアクセスは、ロードストアユニット(LSU)で行なわれるが、LSUや浮動小数点/グラフィックスユニットは8つのスレッドで共有になっている |
□Fall Microprocessor Forumのホームページ(英文)
http://www.in-stat.com/FallMPF/06/
(2006年10月12日)
[Reported by 塩田紳二]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2006 Impress Watch Corporation, an Impress Group company. All rights reserved.