
MicroProcessor Forum 2007レポート
【自動車向けプロセッサ編】
車1台には6インチウェハ分の半導体が搭載
 |
| Session 3の基調講演を行なったデンソー IC技術1部IP開発室長の石原秀昭氏 |
会期:5月21日~23日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
今回のMPFの特徴は、特定業界向けという絞込みを始めた事。初日午後のSession 3は“Processor on the Move”と題し、自動車向けプロセッサを集中して取り上げた。そこで基調講演の内容と、製品を2つほどまとめてご紹介したい。
●基調講演
Session 3の基調講演はデンソーの石原秀昭氏。“An Overview of Automotive Electronics and Future Requirements for Microprocessors”と題し、現在のカーエレクトロニクスの概観を示した。
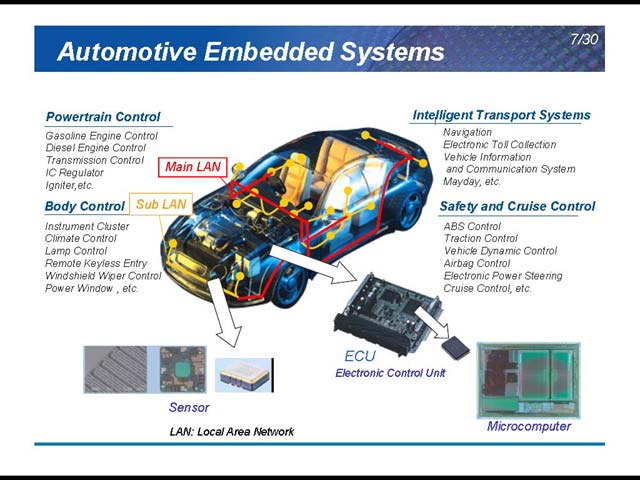
この40年で車載ECU/センサーは膨大な数になっている(図2)。その内訳の概観を示したのが図3で、さまざまな分野でニーズが増えつつあることがわかる。初期の車は、これらの電子部品を直接配線していたが、最近はLANを構成して、そこにデバイスをぶら下げる形がメインになってきている(図4)。このMain LANに関しても、最近の自動車の機能は非常に多い。図5はその一部だが、特に安全性確保のためのVDIM(Vehicle Dynamics Integrated Management)やDriving Supportの機能増加が著しい。
 |
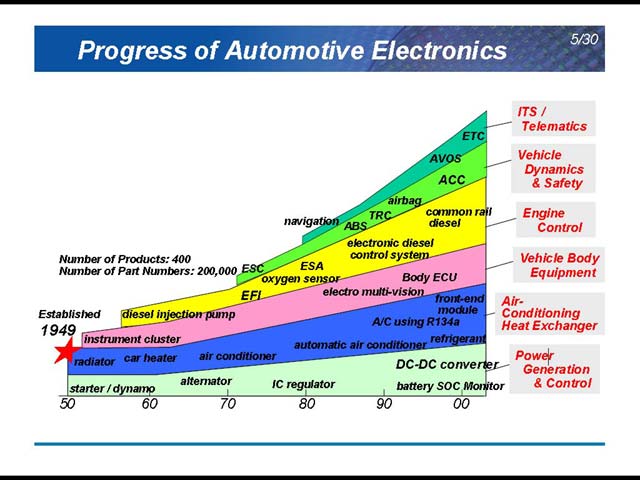 |
| 【図2】そりゃまぁ左側には何も入ってないであろう。この頃だと、たとえばウィンカーもリレーだったりするから、半導体が入る余地はない | 【図3】:Vehicle Body Equipmentというのは、たとえばドアミラーやパワーウィンドウの類。こうしたものは内容は更新されてゆくにしても、数が増えることはあまりないから、結果として数量がStableになっているのだと考えられる |
 |
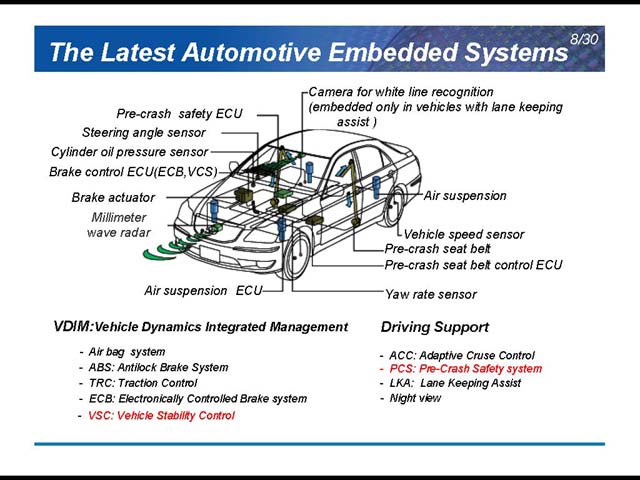 |
| 【図4】これはあくまでも概観だし、Main LANとSub LANといっても、用途が異なるから「MAINだけ生きてればいいや」というわけにはいかない。単純に言っても、パワーステアリングやエンジンコントロールなどが属する主制御系(これがMAIN LAN)、パワーウィンドウなどが属する副制御系(これがSub LAN)と、最近ではカーナビやエンターテイメントをつなぐ情報系が入ってきている | 【図5】本題と関係ない話だが、こうしたサポートはむしろドライバーの状況認識能力を削ぐことにならないのか? というのは前から疑問なところだ。次に説明するVSCがあればサイドスリップの可能性を極力減らせるのだろうが、その代わり限界を超えると一気に横転までいってしまいそうな気も。このあたりをどう考えているのか、機会があれば聞いてみたいところだ |
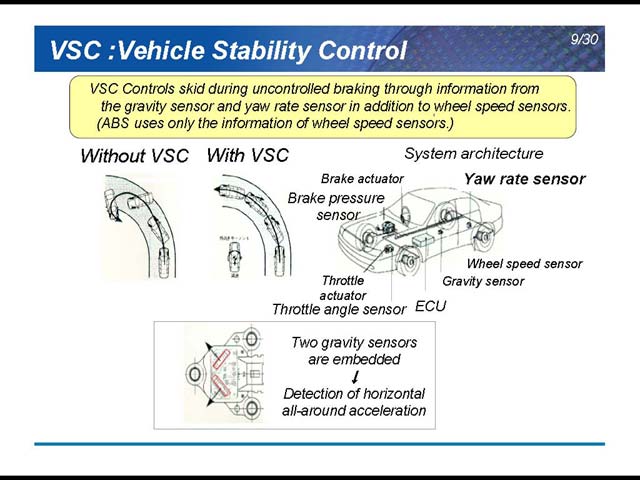
その一例がVSS(Vehiecle Stability Control)だ(図6)。急激にハンドルを切って横滑りしたりしないようにするというもので、こうしたシステムは当然さまざまなセンサーとECUの組み合わせで成立する。もう1つはPre-Crash Safety System(図7)で、衝突が免れないというときに、フルブレーキを掛けてなるべく車速を落として衝撃を減らすと共に、シートベルトを引っ張る事で人体への影響をなるべく軽減しようというものだ。
 |
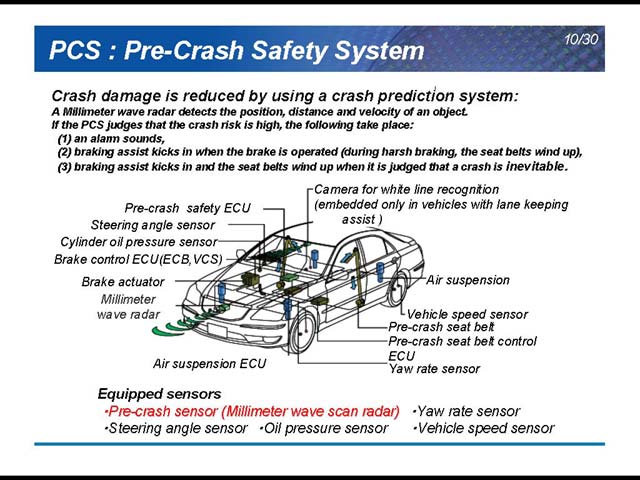 |
| 【図6】ヨーセンサーからの数字で、おそらくサイドスリップ率を検出して閾値を超えないようにアクセルとブレーキを操作するという話であろう | 【図7】ミリ波レーダーを使って相手との距離を常時測定するのが前提だ。おそらく、距離の変動から接近率なども常時算出しているのだろう |
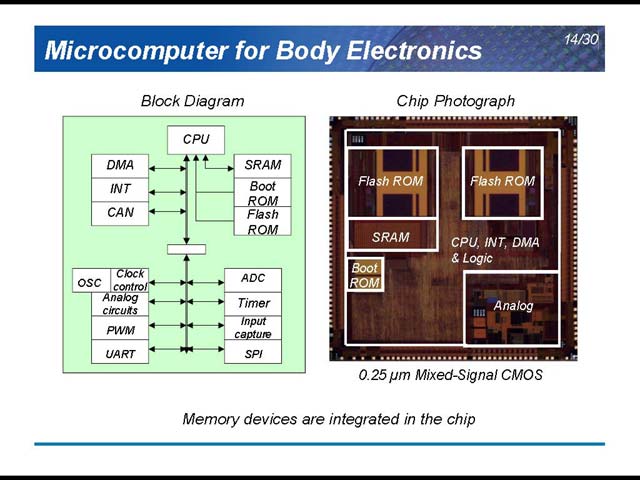
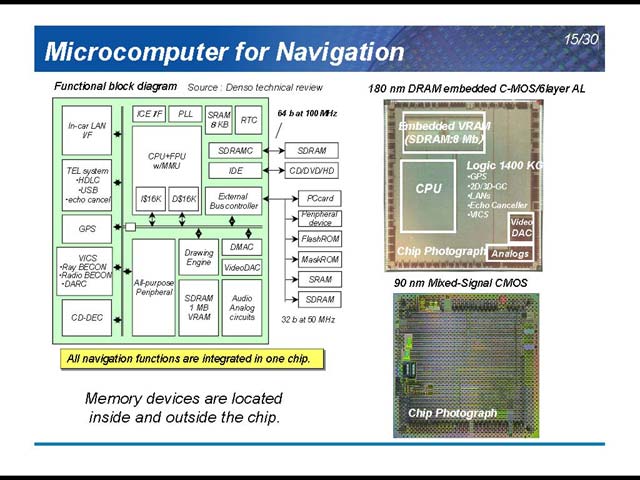
こうしたさまざまな技術が搭載される関係で、どうしてもECUの数は増える。面白いのは、現時点では必ずしも先端プロセスではないこと。たとえば車体制御用のものは0.25μmのMixed-Signalで(図8)、カーナビも0.18μmのCMOSだったりする(図9)。ただ、コストの削減は重要な課題であり、なるべく集積度を上げる必要があるとしている(図10)。
 |
 |
 |
| 【図8】アナログセンサー類をそのまま接続できるようにするためか、アナログ回路を統合しており、結果としてMixed-Signalなので大きめのプロセスとなっている | 【図9】eDRAMを搭載していることからもわかるとおり、製造はNECだとか。90nmの方はこれを作り直したものならしい | 【図10】ただ微細化にあたり、Bipolar CMOSを使うという選択肢が非常に興味深い。理由は駆動電流。Bipolar CMOS w/SOIでは10Aを超える電流を直接ハンドリングできるとしている。従来だとCMOSベースのLSIの外に、パワートランジスタなりリレーなりの駆動回路を外付けしており、これが部品点数増加の要因の1つだったわけで、こういう解もあるという良い例といえる |
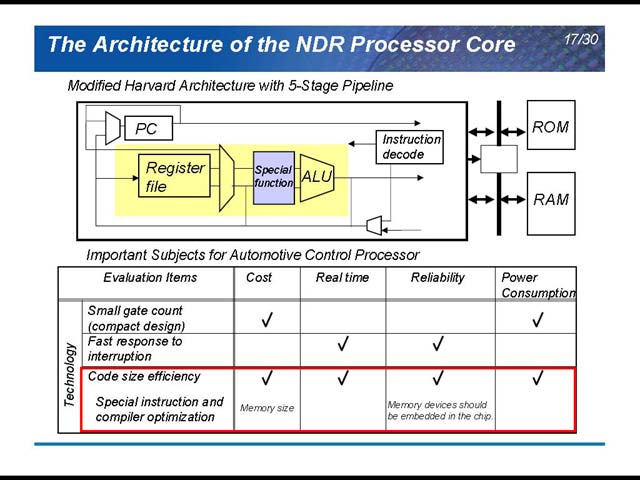
さて、話はここからMCUのアーキテクチャになってくる。図10でも出てきたNDR Processorの詳細が図11だが、非常にシンプルな構成のアーキテクチャだ。ここで「なにを重要視して開発するか」を判断したときに、Code size efficiencyが全ての要求を満たす解だ、という結論が示されているのは非常に興味深い。そのNDRだが、これはデンソーが独自に開発したMPUだそうだ。構造的にはかなり単純だが、Special instructions for Automotiveという点がちょっと目を引く(図12)。
 |
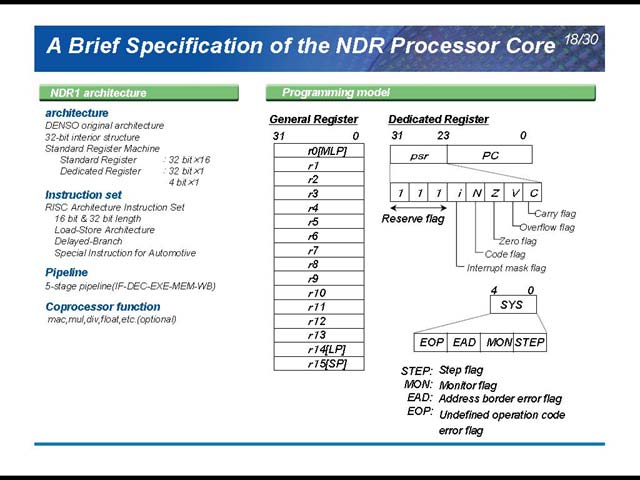 |
| 【図11】絶対性能というものは、重要視されないようだ。もっとも、処理そのものは単純(バスの制御やはBIUが行なうから、CPUがこれを直接ハンドリングするケースは少ない)なので、割り込みのタイミングで必要な処理ができさえすればよく、あとはCode Densityが高い方が好ましいという判断なのだろう | 【図12】MACやMUL/DIVなどは全部コプロセッサだそうだから、かなり思い切ってシンプルにしていることが伺える。もっとも車載部品内蔵MCUともなれば、この位割り切らなくてはならないのだろう。PC(Program Counter)が24bitしかない、というあたりも非常に面白い。16MB扱えれば十分、ということなのだろう |
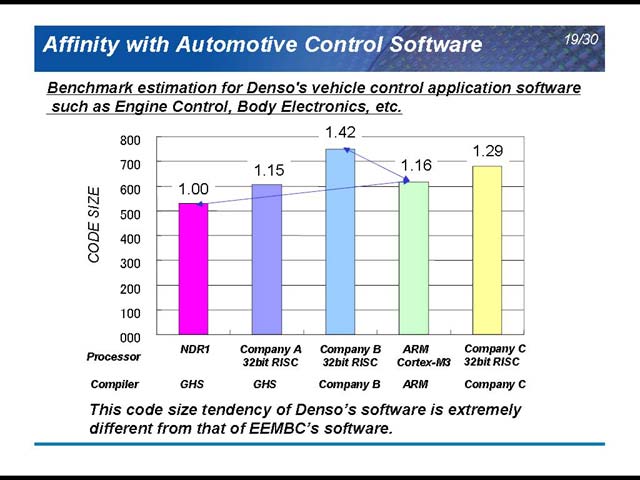
さて、ここで面白いのがコード密度の比較だ。メーカー名は不明だがA/B/Cという3つのRISC、ARMのCortex-M3とNDRという5つのプラットフォームにデンソーのソフトウェアを載せて、それぞれコードサイズを比較したのが図13だ。どうも当初はCompany BのRISCで作っており、それをCortex-M3に載せ換え、最後にNDRに移ったようだが、随分コードサイズが変わってくるのがわかる。注意書きにある“EEMBC(のベンチマーク)ソフトとはだいぶ違う”とあるように、一般的ではないことがうかがい知れる。
ではどんな風に一般的ではないのか? は次のスライド(図14)で大まかに見えてくる。これはCompany B RISCとCortex-M3、NDRの3つを比較し、どんな点がCode Size削減に有効だったかを示すものだが、かなり8bit/16bitの演算が効いてきている事がここから知れる。察するに、I/Oポートに接続されたセンサー類からのデータ取り出しやアクチュエータ類へのデータセットが、プログラムの少なからぬ量を占めているようだ。こうした低レベルのI/Oが多いところでは、Cortex-M3ですら十分ではない、ということだろう。実際にNDRが使われるケースは図15のような形になるのだそうで、確かにこうしたところでは絶対的なコードサイズを減らすのは至上命題であろうというのはわかりやすい。
 |
 |
 |
| 【図13】GHSはGreenHills Softwareの略。コンパイラオプションはいずれも“Optimized for size”だそうだ | 【図14】ただそれならばはじめから8bit/16bit MCUを使えば良いのでは? という気もしなくもない。ただ、今度はそれだと機器制御には良くてもその他の用途ではパフォーマンスが不足するのかもしれない。PCが24bit、というあたりが微妙に16bit MCUでは不足しているが32bit MCUほどの性能は要らないという現状の機器のニーズを示しているようで、ちょっと面白い | 【図15】ちなみにこれはパワーウィンドウのアクチュエータだそうだ |
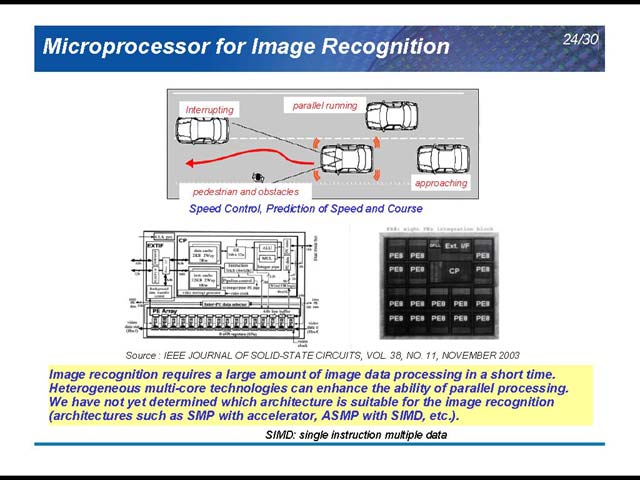
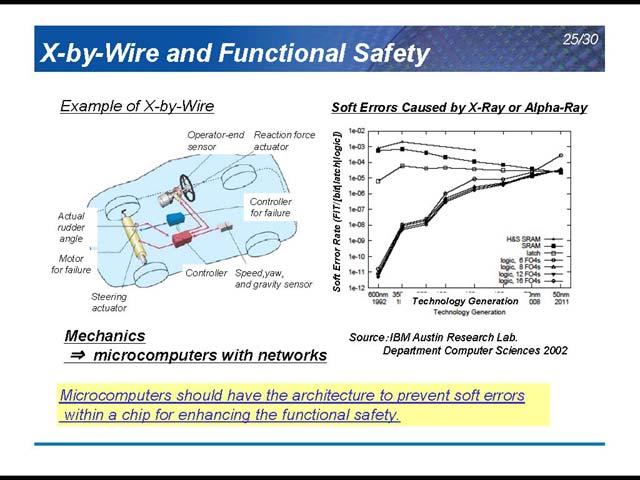
次に話は一転、未来に移る。NDRは図16であればLow-endにドメインに属するもので、ここではマルチコアはまるで不要だ。ところが、High-end、つまりNavigationの分野ではマルチコアが逆に必須ということになる。Navigationといっても、いわゆるカーナビではなく、運転席にカメラを置き、リアルタイムで運転状況を認識して判断するという、現在のものよりずっと先の話だ(図17)。こうした用途では膨大なCPUパワーが必要になるため、マルチコアが良い解ということになる。もう1つは、X-by-Wire(図18)。ブレーキやアクセル、ステアリング操作などをハイドロメカニカルではなくデジタル伝送で行なうという仕組みだ。ただ現在はX線やα線に起因するSoft Errorsが馬鹿にならず、これにどう対処してゆくのかが今後の課題だとしている。
氏の講演の締めくくりはは、図19のプレゼンテーションだ。現在の自動車は、1台あたり6インチウェハ1枚分に近い数の半導体を搭載しており、今後はさらにその数が増えるとした上で、これらを使ってシステムを構築してゆくためにはプロセッサコアの標準化による開発リソースの再利用、デバッグ環境の充実、さまざまなセンサー類を統合しやすいSoCの3つが重要だとした。
 |
 |
| 【図16】中間に属するのが、たとえばエンジンコントロールなどの分野 | 【図17】これは車線と周囲の車の動きを判断してオートクルーズに反映させる、という仕組みの話 |
 |
 |
| 【図18】ちなみに2008年には、一部にFlexRayを搭載した車が登場するそうだ。ただ大半の機器は引き続きCAN及びLINで接続するということになるそうだ | 【図19】今年のISSCCにおいて、トヨタ自動車の篠島靖氏が同じ内容の講演を行なったので、こちらでご存知の読者もいることだろう |
●ルネサステクノロジ SH-Navi2
石原氏の話を受けたわけではないと思うが、Session 3の最後の講演でルネサステクノロジの馬路徹氏は、Navigation向けとなる新しいSH-Navi2の発表を行なった。
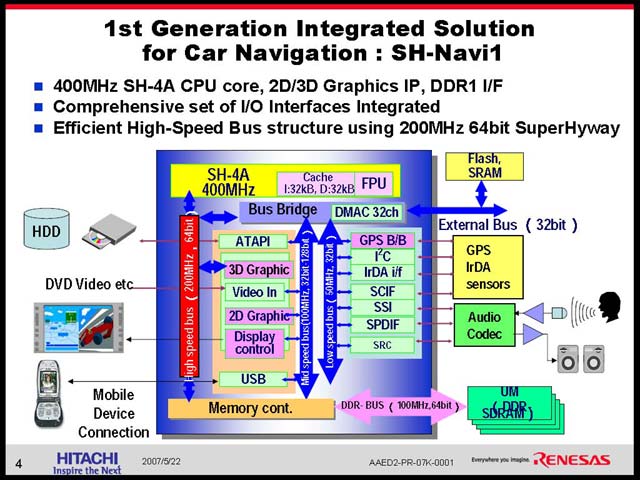
まず最初に、現在製品化されているSH-Navi1の紹介があった(図21)。こちらはいわゆるカーナビ向けに、SH-4Aをコアに必要な部品を集積した、典型的なSoCだ。この製品は、GPSと連動した地図表示、オーディオ/DVD再生機能、電話との連携機能などを追加したもので(図22)、現在良くあるカーナビの枠からはみだしたものではない。
 |
 |
 |
| ルネサステクノロジ 自動車事業部 自動車応用技術第2部 部長の馬路徹氏 | 【図21】SH-4Aは、SH-4をベースにパイプラインステージを追加するなどして高速化を図ったもの | 【図22】これについては非常に理解がしやすいと思う。実際、それほど複雑なものではない |
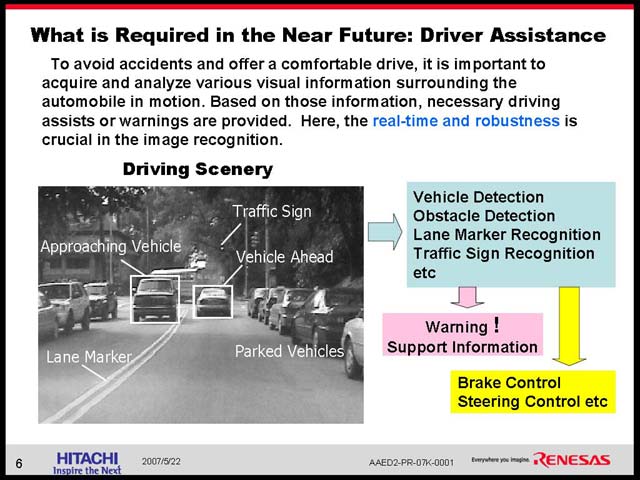
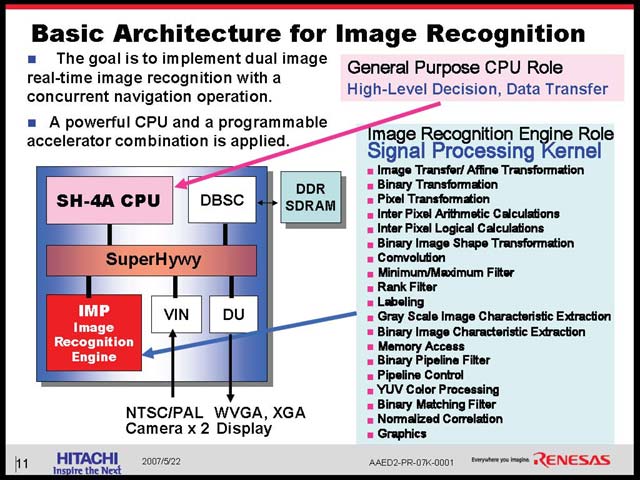
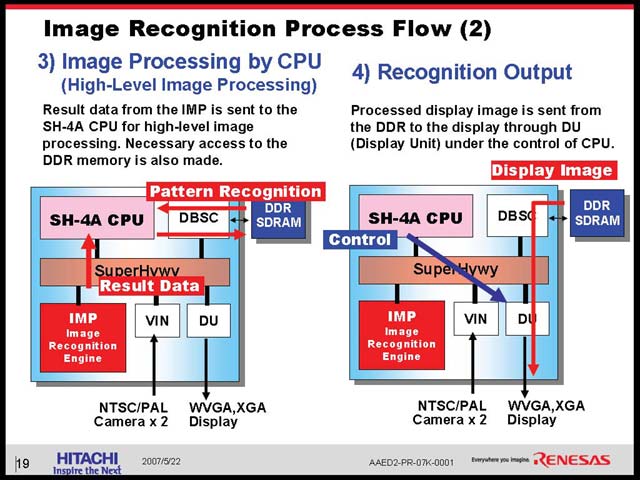
ところが、では次の世代のカーナビは? というと、いきなり激しく進化したものを想定している(図23)。先に石原氏が示した、周囲の車の状況をカメラを使って認識し、判断する仕組みだ。こうした画像認識とその判断が入る場合、必要とされる演算能力は急速に跳ね上がる(図24)。こうした処理を行なってゆくのに、汎用プロセッサベースのみの構成では到底不可能、ということでSH-NAVi2ではあらたにIMPと呼ばれる画像認識エンジンを追加することで、これをカバーする方策を採った(図25)。構成そのものを比較すると、細かく改良はあるものの、IMP以外は概ね同等で、動作周波数をやや引き上げたという程度に過ぎないことがわかる(図26)。
 |
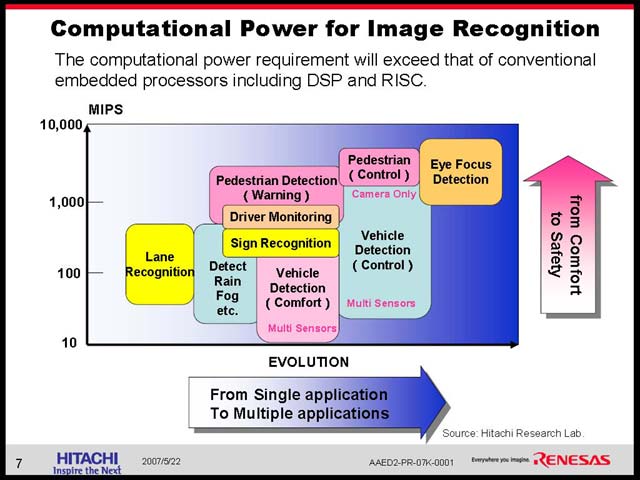 |
| 【図23】もっとも、Brake/Steering Controlまで今すぐ進むかはまた別の問題。とりあえず第一段階は認識して警告をカーナビに出す程度であろうが | 【図24】やはり歩行者の認識はかなり大変なようだ。ちなみにEye Focus Detectionになると、運転手の目をまず認識し、頭の位置からどこを向いているかを算出するという、気が遠くなりそうな手間がかかることになる。10,000MIPS近い演算が必須、といわれても納得できる |
 |
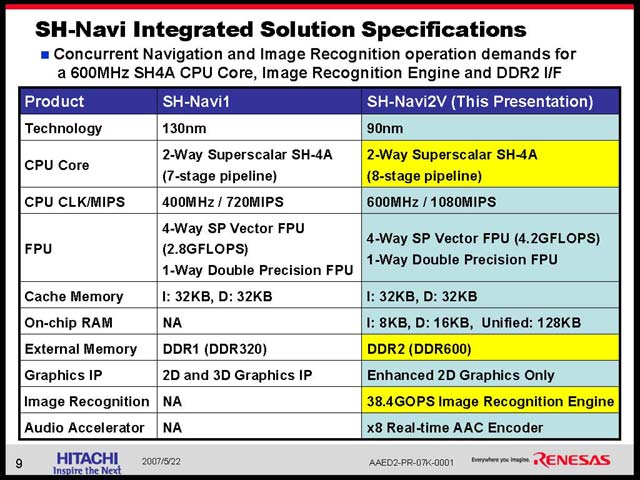 |
| 【図25】内部バス(SuperHyway)の向きが変わっているので分かりにくいが、概ね同等の構成。ただ以前は周辺I/Oまで統合していたが、今回これがPeripheral ASICという形で外付けにされたのは、やはりIMPの搭載の影響でダイサイズが苦しくなってきたためと想像される | 【図26】プロセスの微細化に加え、パイプラインを8段に引き上げたことで、600MHz駆動となったSH-4A。600MHzといえばかなりの速度ではあるが、講演の後で馬路氏に「これ、SH-5のコアにするという案は?」と伺ったら「いやいやまだまだ。次はマルチCPUです」と(それはそれで)恐ろしい返事が |
そんなわけで、SH-Navi1に比べて大きく増えた想定アプリケーションの負荷を担うのは、もっぱらIMPの仕事となる。ではこのIMPとは何か? という話だ。IMPは馬路氏によれば200あまりの機能があるそうで、代表的なものを図27に示したが、かなり多様な処理が可能になるとの事。
そのIMPの中は図28のようになっている。入力したカメラの映像はグレースケールの形で扱われる仕組みだ。図28のとおりLine Buffersを演算前段には持つが、結果を貯めておく場所がないので、たとえばフィードバックの場合でも一度メモリに戻す必要がある、という事になっている。IMPがかなりインテリジェンスなものであれば、Feedback Pathが無いと効率は悪いし、そのためには多少なりともローカルストレージが必要だから、逆に言えばIMPはFixed Functionでもっぱら構成されており、SH-4A側の介在がかなりの頻度で発生するものと見て良いだろう。
 |
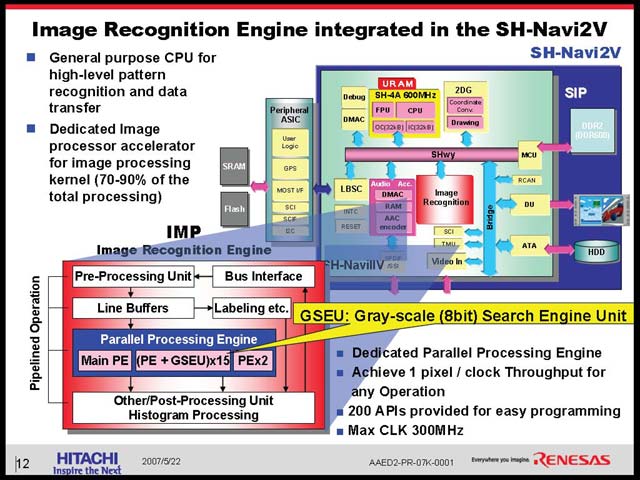 |
| 【図27】データはもっぱらVIN(Video In)からIMPに入り、DU(Display Unit)に出されるという流れになり、これをSH-4Aがコントロールする形になる。ただIMPは図28にもあるように、大きなローカルストアは持たないので、実際にはかなりの頻度でDDR-SDRAMとの間でデータのやりとりを行なうと想像される。これを支えるのが後述するSuperHywayということだ | 【図28】最初これを見た時にはルネサステクノロジが開発中のリコンフィギュラブルプロセッサを使っているのかも、と思ったが(なにしろFunctionが200もあるのだと、それをStaticでインプリメントするのは大変だろう)話を聞いているとそういうわけでもないようだ |
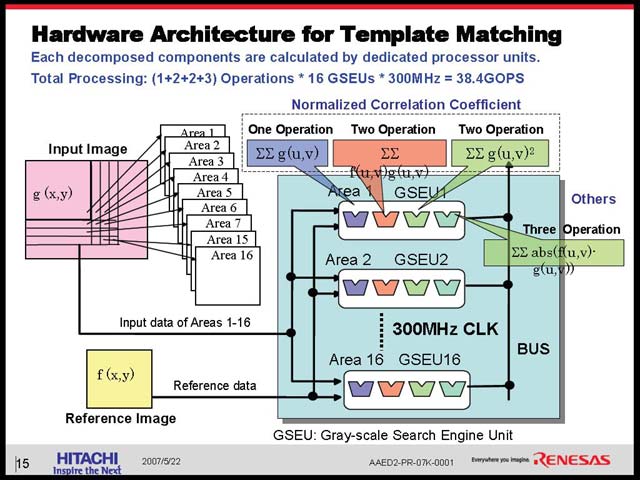
講演では次に実際の処理の説明があった。最初は画像認識、いわゆるTemplate Matchingと呼ばれるものだ(図29)。通常はテンプレートと実際の画像の間でCorrelation(相関)を取るが、普通にただ相関を取っただけでは、精度が悪く認識率が上がらないとした。そこでルネサスは値の正規化を行なって相関をとる形で精度を引き上げたそうだが、当然これは計算量が爆発的に増える。これを解決するのに、参照元と参照先はあらかじめ計算しておき、実際の各要素の相関をIMPで実施、最後のR2の算出はSH-4Aで行なうという形で、CPUとIMPが並行動作する方法が利用された(図30)。
その肝心のIMPの内部は、図31のようになっている。ここでの主役は、GSEU(Gray-scale Search Engine Unit)だ。16組のGSEUが図30に出てきた赤、青、緑の演算を1サイクルでそれぞれ完了するため、結果として1サイクルで16回分の計算が可能になる。これをどの程度まわせば1回のパターン検索が終わるかというのはブロックサイズに依存するから一概には言えないが、少なくともCPUでやるよりは大幅に速い事は疑う余地はない。ところで上にCPUとIMPが同時に動く、という話があったが、具体的には図31の形でパイプライン構造をとると説明された。
 |
 |
| 【図29】参照元と参照先のデータを先に正規化して、それから比較を行なうことで精度を上げようという仕組み。考えてみればその方が精度が上がるのは自明だが、当然計算量は大幅に増えることになる。まず参照元と参照先の両方について輝度の平均値を取り、その平均値と各ピクセルの差を比較して相関を取る事になるからだ | 【図30】黄色とオレンジはあらかじめ計算しておき、赤、青、緑はIMPが計算。この結果をCPUが受け取って最後に掛け算や平方根/掛け算などを行なう形になる。赤、青、緑は回数こそ膨大だが、演算そのものは単純なので、オフローディングさせやすいということだろう |
 |
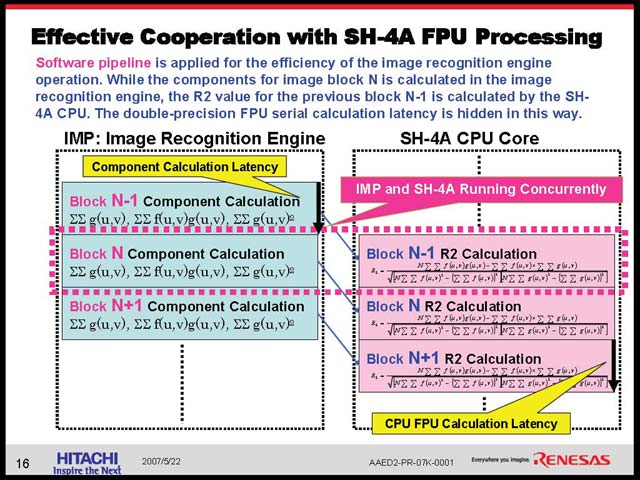 |
| 【図31】ところで図28には(PE+GSU)×15とあるが、この図を見る限り×16の間違いだろうと判断できる | 【図32】こうする理由は、CPU側でのレイテンシ(特に浮動小数点演算のレイテンシ)がかなり大きいためで、1回分ずらすことでうまくオーバーラップして動作できるという話だった |
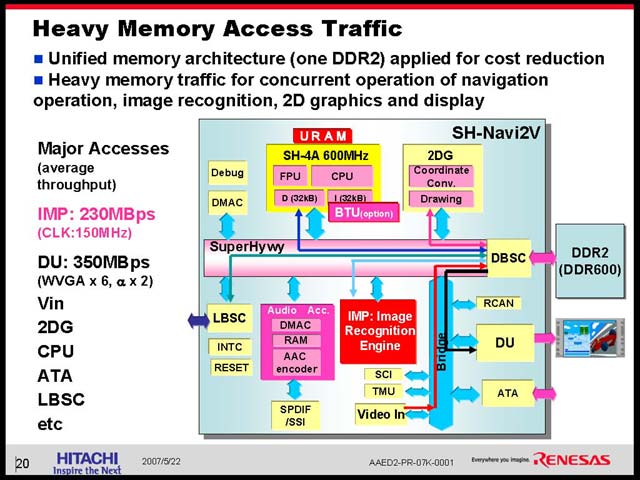
こうした処理を支えるためには、メモリが十分高速にアクセスできなければ当然まずい。図33、34は、実際にこの一連の処理の中のメモリアクセスの流れを示したものだが、常時メモリへの書き出しやメモリからの読み出しが発生する事も当然ながら、内部バスもまた激しく利用されていることがわかる。実際、主要なデバイスが一斉に動くことを考えると、IMPとDUだけで580Mbps程のスループットが必要になる。ここにVinからの入力映像や2DGG、CPUやHDDのアクセスなどが加わるから、DDR2-600でもいっぱいいっぱいというあたりだろう。ただここで、それ以前に内部バスがボトルネックになっては話にならないということで利用されているのがSuperHywayだ(図36)。
 |
 |
| 【図33】ビデオからキャプチャした映像がまずいったんメモリに入り、改めてIMPで読み出され、再度メモリに戻される。普通だと間違いなくローカルメモリをシステム内部に分散させて解決するであろうこの流れを、むりやり1カ所にまとめてしまっているあたりが流石だ | 【図34】演算結果がIMPからCPUに返されるが、同時にパターン認識の上位演算がCPUで行なわれ、最終的な結果がメモリに格納されたのち、DU経由で出力される。この一連の流れが、1フレーム分の画像を処理する間に(下手をすると)何千回のオーダーで行なわれるため、メモリコントローラは休まる暇が無い |
 |
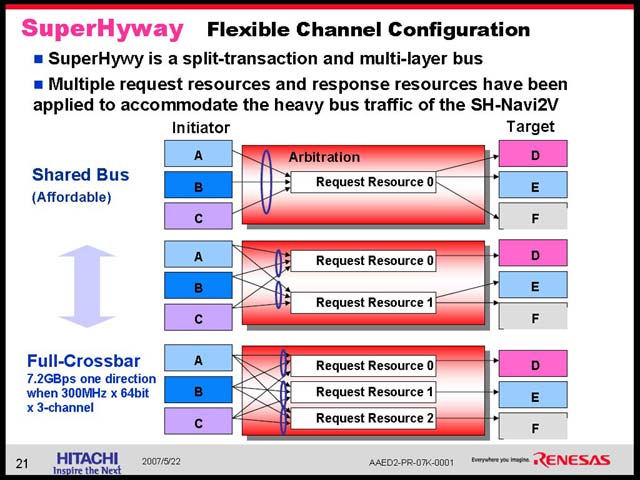 |
| 【図35】それでもコスト削減のためには、DDR2メモリ1個の構成が望ましい、という強い意志が感じられる。そしてまたそれを実現してしまうあたりが、隠れた技術力と言えるだろう | 【図36】内部構成をShared BusとCross Barの混在にできるという、かなり独自の構成 |
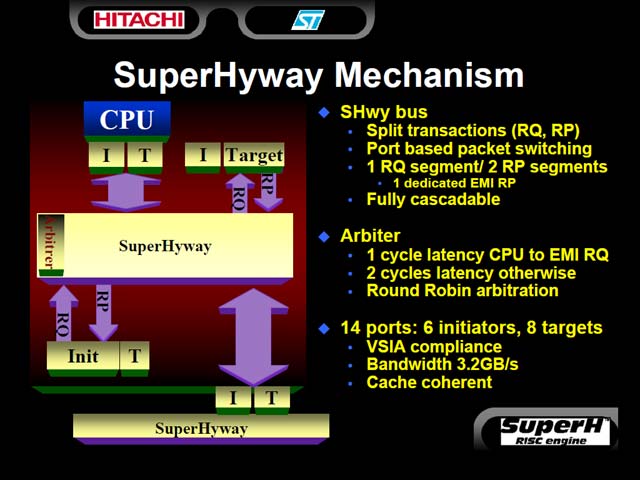
SuperHywayそのものは、筆者が知る限りでは同社の開発したSH-5の内部バス(図37)としてそもそもは開発されたはずで、その後汎用のIPとして広く利用されるようになったと記憶している。現在はIPとして提供されており、SuperHywayのページを見るとType 1~Type 3までが用意されているが、ルネサステクノロジ本体はType 3のみを提供しているようだ。
今回SH-Navi2に搭載されているのはType 3と想像されるが、動作速度は300MHzで、チャネルは片方向あたり64bit×3とかなり豪勢なものだ。これにつながるメモリコントローラもまた面白い仕組みになっている。リクエストをHard-RealtimeとNon-Hard-Realtimeの2つに分類した上で、おのおのの中でラウンドロビンでリクエストを割り振るという仕組みになっている(図38)。
 |
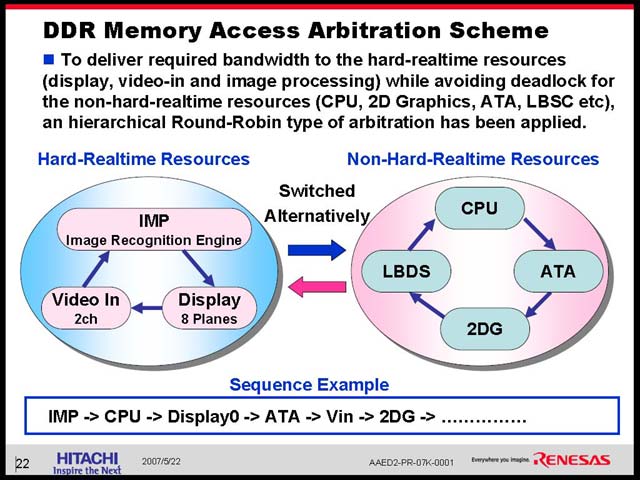 |
| 【図37】こちらは2000年のMPFにおけるHitachi Semiconductor America(当時)のKarl Wang氏の講演資料より。ちなみにこのときのお題は“First SuperH 64-Bit Core for SOC Design”。SuperHywayに限って言えばまだ多重化の要素はここに含まれていないようだが、Sprit Transactionなどはすでにこの時にある。しかもよく見るとRouter経由で最大3つのセグメントを持てるなど、この時点でかなり野心的なバスであることが見て取れる | 【図38】UMAを取る以上、たとえばDisplay Refreshなどに定期的なアクセスが発生するし、IMPは出力バッファを持たないので、これがメモリアクセスに間に合わないと最悪結果の取りこぼしがでる。リアルタイム性を非常に重視した面白い設計だ |
最後に、このIMPを使った画像処理の例が2つほど示された。まず1つ目は道路の白線のリアルタイム認識(図39)。まず輪郭抽出を行ない、次にその輪郭の動き方から白線部を認識して表示するのだという。次が画像認識で、これは速度標識を認識して、制限速度を画面に表示するというもの。今後のカーナビゲーションの方向性の一端が見えた講演であった。
 |
 |
| 【図39】右下の例で言えば、前の車は車間が前後するから輪郭そのものは行き戻りする。これらをフレーム間で比較することで、白線の条件にそぐわないとして排除することで、白線が抽出できるという話であった | 【図40】こちらは非常に典型的な例。パターン認識で道路標識をまず抽出し、そこから速度標識だけを選び出して文字認識を掛けているらしい |
●Freescale MPC5121e
前の2つに比べるとはるかにコンサバティブに見えてしまうのが、Freescaleが発表したMPC5121e(図42)。テレマティック向けに特化したMulti-Processorだが、それがAsymmetric Multi-Processorという点が一味違っている。
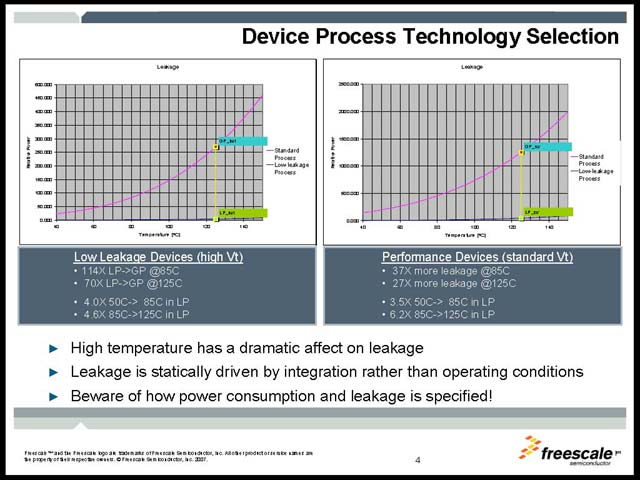
氏の講演はまず自動車向けと一般向けの違いを説明するところから始まっている。とにかく自動車は設計期間も長ければ使われる期間も長く、動作環境ははるかに厳しく、かつ生命の危険性にも密接に関係するため、欠陥への許容度がきわめて低い事が示された(図42)。また、プロセッサへの要望も、見かけは一緒でもその理由はかなり異なっていたりする(図43)。Low Leakageに関しては、図44に示すとおり、特に高温では劇的に変わる。いくらコンシューマデバイスよりも消費電力や放熱に関する条件が緩いとは言え、これを許容するのは難しい。そこで、Low-Leakage Processを使い、それほどコアの動作周波数を上げずに性能を引き上げる方法が、Asymmetric Multi-Processorということになる(図45)。
 |
 |
| Chief Architect, TSPG Infotainment Mulitmedia Telematics OperationのJeff Maguire氏 | 【図42】ここに挙げられていない項目をしいて言えば、性能に関して自動車向けはしばしば低くても許容されるが、コンシューマ向けはハイエンドがしばしば要求されることだろうか? ただこれに関しては、最近自動車向けも高性能が求められる(特にテレマティック向けはこの傾向が強い)ため、「頑丈だけど遅い」プロセッサでは次第に追いつかなくなりつつある。Freescaleが自動車向けにPowerPCを全面的に展開するのも、これが一因であろう |
 |
 |
 |
| 【図43】リーク電流に関しては次のプレゼンテーションを参照のこと。テレマティック向けには、特定用途向けスペシャルロジックを実装するのが適切、というのが彼の主張だ | 【図44】ちょっと文字が読みにくいが、両方のグラフとも赤がStandard Process、青がLow Leakage Processだ。左はこれらでLow Leakage Deviceを、右はPerformance Deviceを製造したケースで、摂氏125度における両者の消費電力を比較したものだ。Standard Processは、環境温度が高くなると恐ろしく消費電力が増えることがわかる | 【図45】もっともこのところ、Freescaleは一般にGPU+Acceleratorの組み合わせが非常に増えている気がする。昨年(2006年)登場した通信向けのPowerQUICC IIIに属するMPC8572もDual e-500にContent ProcessorなるAcceleratorを組み合わせたASMP構成だ |
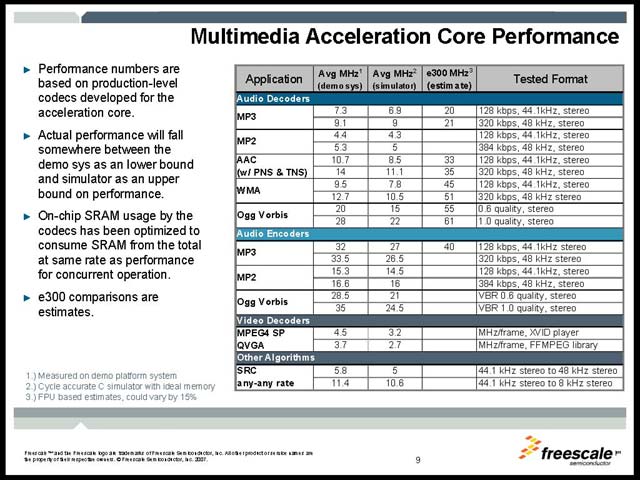
さてそのMPC5121eの内容をもう少し見てみる。CPUコアはe300ベースのもので、これをLow-Leakage Processで製造したものだ(図46)。これに組み合わせるAcceleratorの詳細がこちら(図47)になる。もっぱらオーディオの処理に特化したコアと言えるが、実際に音楽処理のベンチマークを行なうとこれは明確だ(図48)。映像に関しては、なつかしのPowerVRベースであるMBXを搭載しており、100MHz駆動で135Mpixel/sec程度のスループットが確保されている。これも高いビデオ性能というよりは、コストパフォーマンスやパワーパフォーマンスの向上を念頭においた選択と理解できる。
ただ低価格向けとなると、当然メモリはUMA方式になるのが必須で、そうなるとメモリコントローラや内部バスに負荷がかかるのは先のSH-Navi2と同じだ。そこでメモリコントローラは160bytes分のPosted Write Bufferやら同時8ページまでのOpenをサポートする、3バンク構成というあまり類の無いものになっている(図50)。ちなみにUSBやSATAについてはPHYまで統合しており、低価格化に向けてかなり集積度をあげていることがわかる。
SH-Navi2とは大きくターゲットが異なる製品だが、こうしたところにも相応の配慮が必要なのがテレマティック向け製品だ、ということが良くわかる内容だった。
 |
 |
| 【図46】e300はPowerPC G3と同じもので、アーキテクチャ的にはPowerPC Classicに属する。「なぜPowerPC ISA 2.0のe500コアを使わなかったのか?」と聞いたところ、答えは互換性との話。すでにPowerPC Classicベースのソフトウェア資源が大量にあるから、PowerPC ISAに切り替えるのは難しいという話であった。それはわかるのだが、こうして新製品をPower PC Classicで出したら、さらにPowerPC ISAへの移行が困難になる気もするのだが。テレマティック分野は、あるいはPowerPC ISAに移行しないつもりなのだろうか? ちょっと気になるところだ | 【図47】内容を見ると、48bitのMultiplierという、非常に面白いものが入っているのがわかる。このあたりは、まさにMP3やAACの処理に対応したものだろう。ほかにDSPによる処理も可能になっているのがわかる。可変長シングルパイプラインと固定長デュアルパイプラインの両方を切り替えられるというのも、面白い仕組みだ |
 |
 |
 |
| 【図48】デコーダに関してはe300で行なう場合の3分の1~5分の1程度の負荷で、エンコードでも半分以下の負荷で済ますことができる。ビデオのデコードにも対応しているが、MPEG-4 SP QVGAというあたり、本格的なビデオ再生は考えていない事がわかる。ここから、MPC5121eのターゲットは比較的安い車のテレマティックシステム向けと想像される | 【図49】OpenGL-ES1.1というあたりで、本格的な3D映像の再生は考えていない事が明白だ。もともとカーナビについても、日本は異様に進化してかなり映像への負荷が高いが、アメリカではシンプルに地図だけ出せればOKみたいな程度であり、こうした低価格帯向けに性能を調整していることが良くわかる | 【図50】よく見るとバスの構成もかなり不思議だ。大体Processor BusとAHB Busの間にBus Bridgeが入らず、Memory Controllerがこの役を果たしているとか、Processor BusにPCIがぶら下がる(普通はAHBにぶら下がる気がする)などだ。このあたりも、低価格化のためにかなり機能を絞り込み、最適化を図った構成であることがうかがい知れる |
●最後に
実はSession 3ではもう1つ講演があったのだが、これはもはや車載向けという代物ではなくなっていた。もともとの用途はデンソーの講演に近い内容だったのに、実装ははるか斜め上を高々と登ってゆく感じであり、そういうわけでこちらは別のレポートでご紹介したいと思う。
□Microprocessor Forum 2007のホームページ(英文)
http://www.in-stat.com/mpf/07/
□関連記事
【2006年9月14日】【FPF】プロセッサの組み込み応用を立て続けに披露
http://pc.watch.impress.co.jp/docs/2006/0914/freescale.htm
【2006年5月24日】【SPF】高性能DSPに対する2つのアプローチ
http://pc.watch.impress.co.jp/docs/2006/0524/spf06.htm
(2007年5月25日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.