 |


■後藤弘茂のWeekly海外ニュース■2年サイクルでアーキテクチャを刷新するIntel |
●オレゴンとイスラエルの2チームで平行して開発
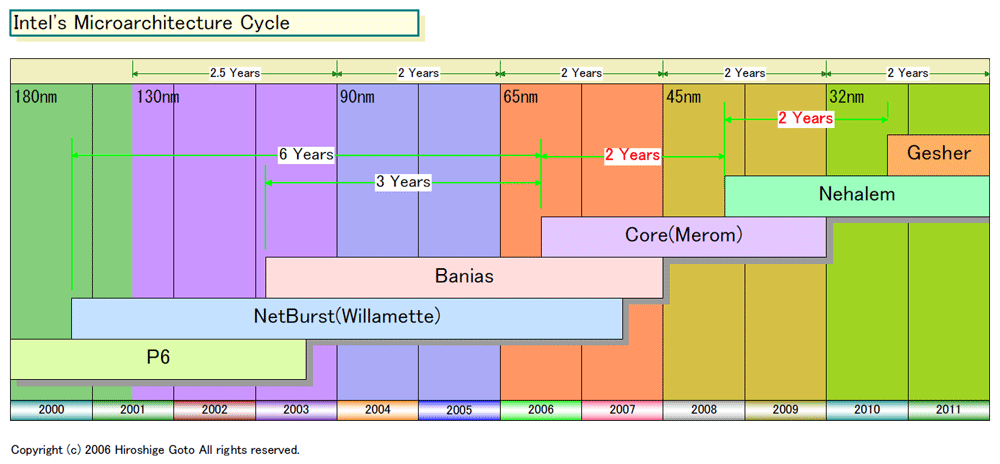
Intelは、今後は2年サイクルで新CPUマイクロアーキテクチャを投入していく。今年(2006年)中盤に投入する「Core Microarchitecture(Merom:メロン)」を皮切りに、2008年頃に「Nehalem(ネハーレン)」、2010年頃に「Gesher(ゲシャー?)」が登場する。Core Microarchitectureが65nmプロセス、Nehalemが45nmプロセス、Gesherが32nmプロセスとなる。IntelのPaul S. Otellini(ポール・S・オッテリーニ)氏(President & CEO)は、4月27日に行なった「Intel 2006 Spring Analyst Meeting」のWebcastで、2年置きに、プロセス技術とマイクロアーキテクチャを刷新する戦略を説明した。
 |
| Intel's Microarchitecture Cycle(別ウィンドウで開きます) PDF版はこちら |
2年毎のプロセスサイクルは従来通りだが、2年毎のマイクロアーキテクチャ刷新は、従来の刷新プロセスより大幅に短い。NetBurst(Willamette:ウイラメット)アーキテクチャは2000年に登場、デスクトップではCore Microarchitectureに置き換えられるまで6年続いてきた。いきなり、アーキテクチャ刷新が急加速されたことになる。
加速された理由は明白で、Intelが現在2チームでx86系のPC向けCPUマイクロアーキテクチャの開発を行なっているためだ。通常のCPUアーキテクチャ開発サイクルは4年以上だが、2チームがオーバーラップして開発を行なうことで2年刻みの新マイクロアーキテクチャの投入を実現する。Intelのイスラエル開発チームが、Banias(バニアス)アーキテクチャ系を成功させ、実績を積んだことで2チーム体制が確立した。
今回のロードマップでは、Core MicroarchitectureとGesherがイスラエル、次のNehalemがP6(Pentium Pro/II/III)とNetBurst(Pentium 4)を開発した米オレゴンチームとなる。元々のロードマップでは、NehalemがNetBurstの後継アーキテクチャとなるはずだった。しかし、CPUアーキテクチャ開発が、パフォーマンス重視からパフォーマンス/消費電力(Performance/watt)重視へとシフトしたため、モバイル系CPUを担当していたイスラエルのCore Microarchitectureが間に入った。そのため、Nehalemは当初の予定より2~3年遅れての登場となった。
●プロセスとアーキテクチャの刷新を半サイクルずらす
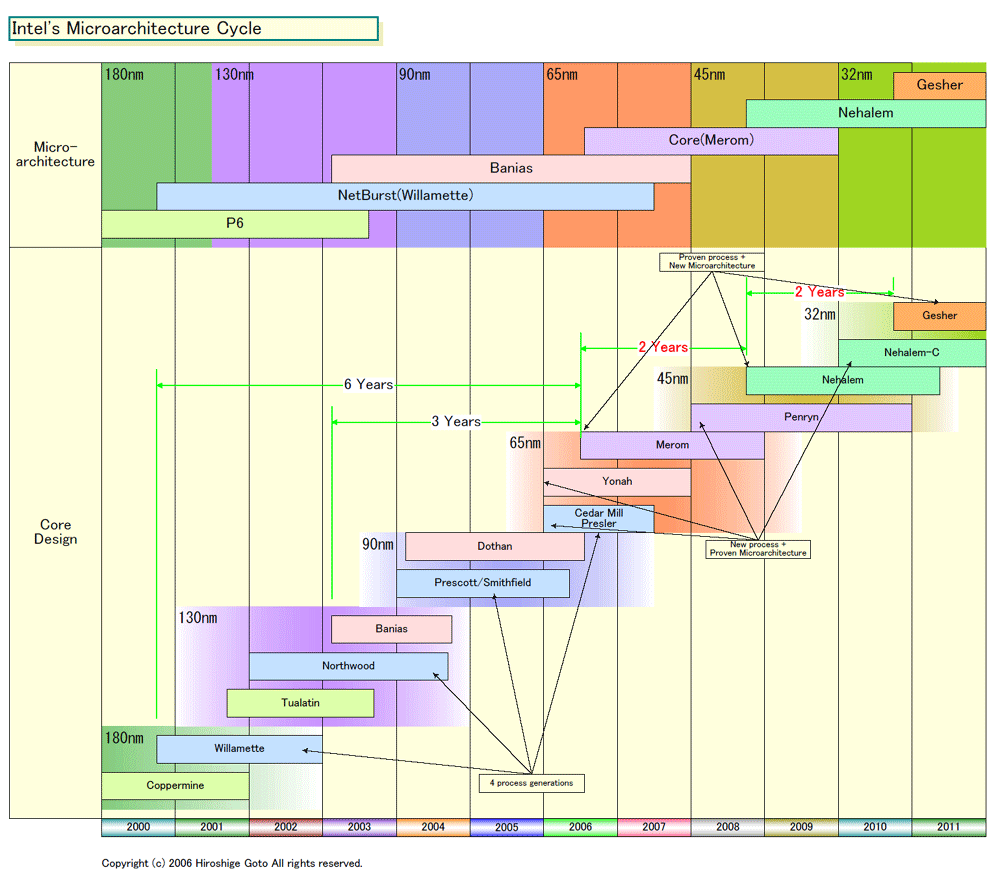
2年サイクルでのプロセスとマイクロアーキテクチャの刷新を、Intelは周期をずらすことでより効率的にすると説明する。Spring Analyst Meetingで、IntelのOtellini氏は次のように説明している。
「現在出荷している65nmプロセスの製品は、いずれも前世代の製品の微細化版か派生版だ。Presler(プレスラ)とDempsey(デンプシ)はNetBurst製品ラインで、2つ目のコアを加えた。YonahはCentrino製品ラインを微細化して、2つ目のコアを加えた。だから、65nmの利点を活かしながら、非常に迅速な立ち上げができた。そして、この夏に新マイクロアーキテクチャを65nmプロセスで導入する。」
「我々は次のサイクルもこれを続ける。45nmも同じモデルで、最初はCore製品ラインをベースにした微細化版か派生版を投入。プロセス技術が立ち上がった後で、次期マイクロアーキテクチャNehalemへと移行する。32nmでも同じモデルだ」
つまり、まず新プロセスの立ち上げ期には、すでに実証済みのマイクロアーキテクチャかその派生アーキテクチャのCPUを生産。プロセスを迅速に立ち上げる。プロセスがある程度立ち上がった段階で、新マイクロアーキテクチャのCPUを導入するというステップだ。新マイクロアーキテクチャの場合は、サンプルチップが完成してから検証にかなりの時間がかかるため、これは合理的な移行計画だ。
 |
| Intel's Microarchitecture Cycle w/Core Design(別ウィンドウで開きます) PDF版はこちら |
具体的には次のようになる。45nmプロセスはMeromの微細化/派生版となる「Penryn(ペンリン)」で、まずプロセスをドライブし、その後、おそらく2008年中にNehalemを導入する。32nmはNehalemの微細化/派生版となるNehalem-C(Nehalem Compaction)でプロセスを立ち上げ、Gesherで引き継ぐ。
NetBurstは、Willamette(180nm)→Northwood(130nm)→Prescott/Smithfield(90nm)→Cedar Mill/Presler(65nm)と4プロセス世代に渡った。しかし、今回の説明を見る限り、Core Microarchitecture以降は、基本的に2プロセス世代で移行していくことになりそうだ。
Intelは、現在、派生CPU全てに異なるコードネームをつけ始めており、そのため、コードネームの数が異常に増えている。例えば、Meromのデスクトップ版がConroeで、Conroeから機能制限版「Allendale(アレンデール)」とバリューCPU版「Millville(ミルヴィル)」が派生するといった具合だ。以前なら同じコードネームがついたようなCPUにも、異なるコードネームが割り当てられている。しかし、重要なのは、核となる製品のコードネームで、それが今回示されているコードネーム群だ。
●Intel内部でCPUアーキテクチャの統一化で合意?
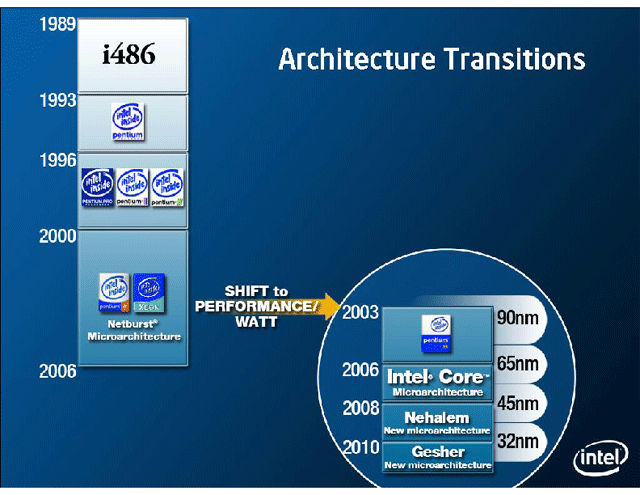
2チームでのx86 CPUマイクロアーキテクチャ開発は、Intelは以前にも行なっていた。'90年代初め頃は、P5(Pentium)は米カリフォルニア州のサンタクララ、P6がオレゴンでオーバーラップ開発を行なっていた。しかし、サンタクララがIA-64開発にシフトしたため、オレゴンチーム単独でx86系CPUマイクロアーキテクチャ開発の重責を担うことになった。今回の布陣は、その当時に戻したと見ることもできる。
 |
| Architecture Transitions(別ウィンドウで開きます) PDF版はこちら |
ただし、大きく異なる点もある。それは今回は2つの開発チームが、それぞれ異なる事業部に結びついていることだ。イスラエルチームはIntelのMobility Groupに、オレゴンチームはDigital Enterprise Groupに、それぞれ結びついている。ある業界関係者は、2005年末に、2チームがそれぞれマイクロアーキテクチャの開発を行なっているが、それぞれのアーキテクチャをIntel全体で使うとは決まっていないと語っていた。つまり、Nehalemはあくまでもデスクトップの後継アーキテクチャ、Gesherはモバイルの後継アーキテクチャという位置付けだったようだ。
しかし、今回の説明では、Core Microarchitecture→Nehalem→Gesherと移行すると明確にIntelは説明している。おそらく、Intel社内で、アーキテクチャの統一に対してのコンセンサスが確立されたものと見られる。
また、IntelはオレゴンチームのNehalemを含めて、今後のCPUは、パフォーマンス/消費電力を重視したアーキテクチャになるとも説明している。当初のNehalemは、高クロック型アーキテクチャだったと見られるため、コードネームは同じでもNehalemプロジェクトの内容は大きく変わったと推測される。
●Gesherについてヒントを与え始めたIntel
イスラエルチームの「Gesher」の存在がIntelから公式に明らかにされたのは、2月のIntelの開発者向けカンファレンス「Intel Developer Forum(IDF) Spring」。イスラエルの開発チームを率いるOfri Wechsler氏のプロファイルの欄に「Ofri WechslerはMobility GroupのIntel Fellowで、Mobility Microprocessor Architectureのディレクタ。その職務として、WechslerはYonah、Merom、Penrynファミリのアーキテクチャと、次世代Gesher CPUのアーキテクチャ開発の責任を負っている」とさりげなく告知されていた。
このプロファイルは、最初にIDF参加者サイトにアップされた時は、Gesherの記述がなかったのに、IDF期間中にわざわざ書き加えられていた。
Gesherというコードネームは、他のイスラエル開発のモバイルCPU同様にヘブライ語だ。Gesherの正確な発音表記はまだ確定できていない。直接聞いた感じではゲシャーだったが、発音的には「ゲイシャ(geisha)」に似ているという記述もあった。ただし、コードネームの常として、問題となるのは現地語で正確な発音かどうかではなく、Intel社内でどういう発音または綴りをしているかが重要となる。
ちなみに、IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Intel Senior Fellow, Cheif Technology Officer, Corporate Technology Group)はコードネームについて次のように笑っていた。「Intelは伝統的にコードネームに地名を使っている。ところが、コードネームをつける人が思い違いをしていて、間違えたスペリングにしてしまうことがある。そのため、実際には存在しない地名のコードネームができてしまったこともあった」
●8年かかるCPUアーキテクチャ開発チームの育成
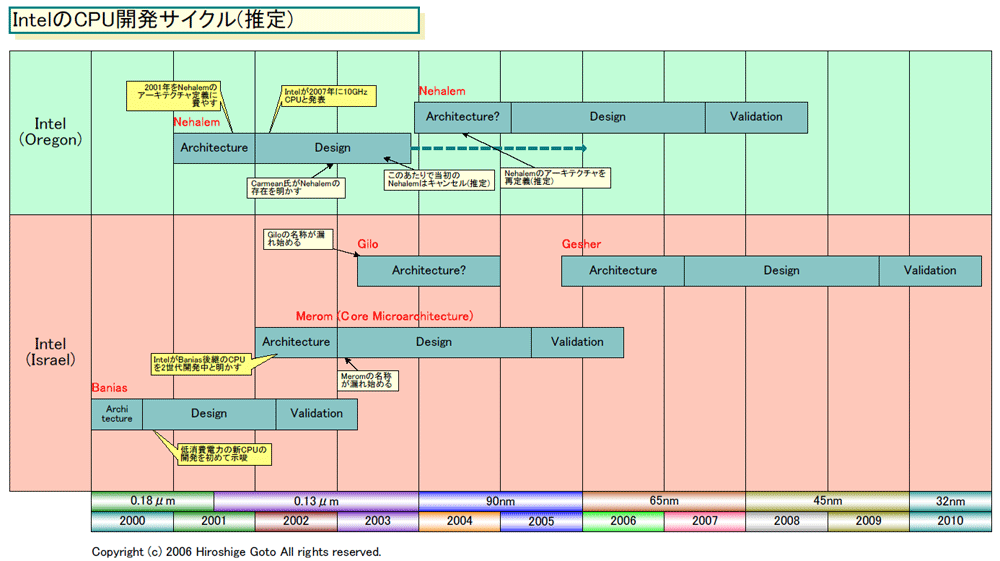
下が、推測されるIntelの2チームによるCPUマイクロアーキテクチャ開発サイクルだ。以前、このコラムで説明した、イスラエルの次世代CPU「Gilo(ギロ)」プロジェクトは、実際にはGesherに代わっていた。コードネームは間違えていたが、開発サイクルについての推測自体は、それほど違っていなかったようだ。
 |
| IntelのCPU開発サイクル(推定)(別ウィンドウで開きます) PDF版はこちら |
Intelは、NetBurst世代ではモバイルCPUを別アーキテクチャにしなければならなかった。そのため、デスクトップ&サーバーCPUをオレゴン、モバイルCPUをイスラエルが担当する分業体制となった。130nmと90nmプロセスでは、2アーキテクチャが並列することになった。
しかし、Intelのイスラエル開発センターが実績を積み、メインストリームのデスクトップCPUまでカバーできるアーキテクチャを開発できるようになったことで立場が変わった。元々モバイル向けにスタートしたMeromが、Core Microarchitectureとしてサーバーやデスクトップまでカバーすることになり、2チーム体制ができあがった。
IntelのRattner氏は開発チームの育成について次のように語る。
「CPU設計チームを育てるには8年かかる。2サイクルだ。イスラエルが成功例で、統率と連携が取れたいいチームだ。単に、チップエンジニアを集めても、いい設計チームはできない。チームの組織化が重要で、育つには8年が必要だ」
イスラエルチームの場合、「Tillamook(ティラムーク、0.25μm版MMX Pentium)」からスタートして、統合CPU「Timna(ティムナ)」などを経てBaniasで飛躍した。Tillamookの開発は'95~'96年頃なので、スタートから8年かけてBanias完成と、Merom開発のスタートまで行き着いたことになる。
ちなみに、Rattner氏によると、失敗例はインドの開発センターだという。
「インドではクアッドコアCPUを設計していたが、遅れ続けたため、結局、完成できないと判断して打ち切った。問題の1つは、情報の共有がうまく行かなかったことで、設計者同士の連携がうまくいかず、開発が難航した」
インドでは、Meromベースのクアッドコア「Whitefield(ホワイトフィールド)」を開発していたと言われるが、このプロジェクトは打ち切られている。うまく行けば、Intelは8年後にはもう1つ、インドに開発チームを持つことができたかもしれないが、それは失敗したようだ。
●ある程度予想ができるNehalemとGesher
では、2つの異なる設計チームが開発するNehalemとGesherは、それぞれどのようなアーキテクチャになるのだろう。Gesherについては、ある程度の推測ができる。それは、イスラエルチームの研究者が発表した「PARROT(Power AwaReness thRough selective dynamically Optimized Traces)」と呼ばれる次世代アーキテクチャに、ヒントが満載されているからだ。PARROTの論文には、Core MicroarchitectureのMacro-Fusionも、先取りして記述されており、今後は、Macro-Fusionをさらに発展させる形でアーキテクチャ改良が行なわれることが容易に予測できる。
例えば、Core Microarchitectureで採用した比較命令(cmp)と条件分岐命令(jcc)の組み合わせのフュージョンだけでなく、例えば、「and/sub+cmp+jcc」の組み合わせのフュージョン、複数の演算命令やロード/ストア命令のSIMDパック化、重複するロードやストアの削除などが予想される。また、こうした複雑なフュージョンや最適化を効率的に行なうために、バックグラウンドで最適化のパスを持つことなども想定される。つまり、PARROTの採用が進んでゆくと推定される。
一方のNehalemについては、パフォーマンス/消費電力重視に変わった現在、予測が非常に難しい。Intelは、投機マルチスレッディングについて何度も言及しており、それを補助するためのバリュープレディクション(値予測)などについても語っていた。投機マルチスレッディングを可能にすると、コンパイラレベルでのスレッドの自動生成が容易になる。Intelのオレゴンチームがこの方向を模索しているのは間違いがないが、時期的に間に合うかどうかはわからない。また、効率重視に変わったNehalemで実装するかどうかも疑問だ。投機的なマルチスレッディングにより、無駄が発生するからだ。
ただし、4月に横浜で行なわれたCPUカンファレンスCool chipsでスピーチを行なった研究者Antonio Gonzalez氏(Intel Corp. and Universitat Politecnica de Catalunya)は、現在のCPUでは、ILP(Instruction-Level Parallelism)レベルでの投機実行ですでに多くの無駄が生じていることを指摘。電力効率の面ではTLP(Thread-Level Parallelism)の方が有効だと語った。パフォーマンス/消費電力効率の面でも、投機マルチスレッディングの方が優れているという結論が出てくるかもしれない。
□関連記事
【4月28日】【元麻布】シェア奪回を狙うIntelのプラットフォーム戦略
http://pc.watch.impress.co.jp/docs/2006/0428/hot422.htm
【2005年12月28日】【海外】ポストMeromとなる「Nehalem」と「Gilo」
http://pc.watch.impress.co.jp/docs/2005/1228/kaigai232.htm
(2006年5月9日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.