 |


■後藤弘茂のWeekly海外ニュース■NVIDIAからハイエンドGPU「G70」が登場 |
●GeForce 6800(NV40)の拡張強化版
NVIDIAが次世代ハイエンドGPU「GeForce 7800 GTX(G70)」を発表した。
G70は、以前はNV47と呼ばれていたGPUで、旧コードネームから分かる通り現在のGeForce 6(NV4x)系と、共通のアーキテクチャをベースにした発展版だ。対応するShader APIは、Programmable Shader 3.0のまま。プロセス技術を0.13μmから0.11μmに微細化し、Programmable Shaderの数と性能を強化した。特に、Pixel Shaderのパフォーマンスを増強したGPUだ。
 |
| G70のイメージキャラクタLuna |
G70のホストインターフェイスはPCI Express x16で、メモリは256bit幅のGDDR3。1.2GbpsのGDDR3を搭載した場合には、メモリ帯域は38.4GB/secとなる。Shaderの演算性能では、NV40の約2倍。動画再生支援機能PureVideoの改良版が搭載され、NVIDIA SLIにも対応する。
G70コアのトランジスタ数は3億200万で、製造はTSMCの0.11μmプロセス。ダイサイズ(半導体本体の面積)は、目測では300平方mmを超えて330平方mmクラス。過去最大のモンスターGPUだ。
G70コアの製品で、最初に登場するボード製品はハイエンド向けのGeForce 7800 GTX。GPUコア430MHz、メモリは256bit/256MBのGDDR3で転送レート1.2Gbps、シングルスロットソリューションだ。市場価格は599ドル。
G70は、PCグラフィックスだけでなく、ゲームコンソールの世界から見ても重要だ。というのは、G70の兄弟GPUである「RSX」が、PLAYSTATION 3に搭載されるからだ。現在の情報を見る限り、RSXの内部アーキテクチャは、ほぼG70と同じだと見られる。PS3の開発ツールに現在搭載されているGPUも、G70だ。
では、G70の構造を上から見ていこう。
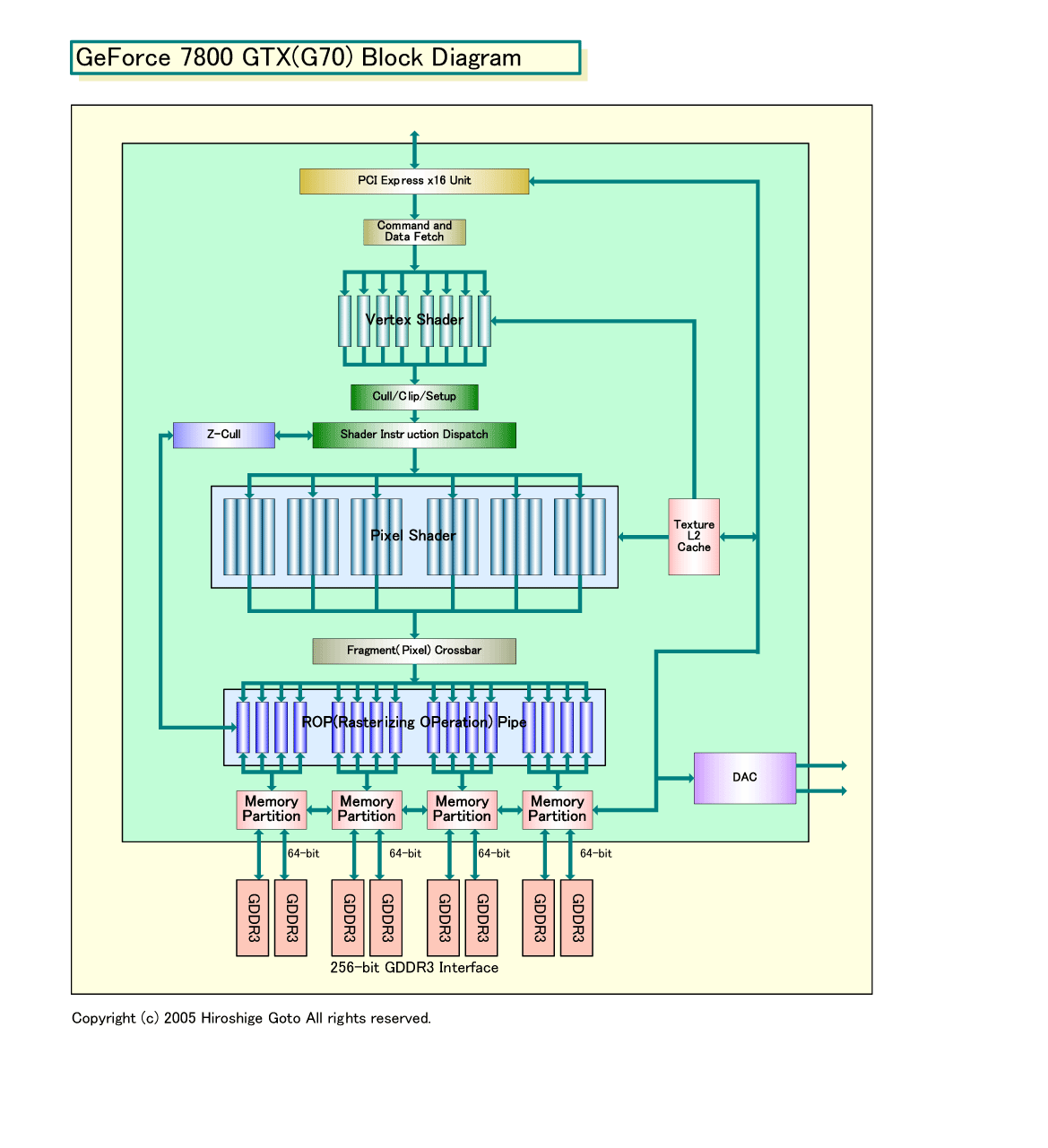 |
| G70 Block Diagram PDF版はこちら |
G70のVertex Shaderの構造は、驚くほどNV40に似ている。おそらく、機能的には大きな変更はなく、Shader数だけが増強されたと推測される。Vertex Shaderの数は、NV40の6ユニットから、G70では8ユニットへと33%増やされた。
Vertex Shaderに搭載されている演算ユニットは、4wayベクタユニットが1つと、スカラユニットが1つ。ベクタユニットは、3Dグラフィックスで多用される積和算などをサポートし、積和算は毎サイクル実行できる。スカラユニットは、三角関数や対数といった特殊オペレーション中心で使われるという。ベクタとスカラのどちらのユニットも、32bit単精度浮動小数点フォーマットをサポートする。NV40/G70では、両ユニットに、それぞれ命令を発行して、並列に処理を行なわせることができる。
GPUのShaderは、DirectXならAPIで、OpenGLならJITコンパイラで、Shaderの命令セットをシェーダプログラム隠蔽してしまう。そのため、GPUベンダは、Shaderのネイティブの命令セットは自由に設計することができる。つまり、命令セットレベルから、大きく革新したアーキテクチャを導入することができる。NVIDIAは、この点を利用して、NV40系ではVertex ShaderのネイティブISAは1命令で多数データを同時に処理できるSIMD(Single Instruction, Multiple Data)型ではなく、多数命令で多数データを同時処理できるMIMD(Multiple Instruction, Multiple Data)として実装した。
2004年8月のHotchips 16のNVIDIAのプレゼンテーションを見ると、NV40のVertex Shaderは、123bit長のVLIW型の命令セットを持つとなっている。G70のVertex Shaderも、構造やスペックがNV40と同じであることから、命令セットも共通していると推測される。ちなみに、NV40のShaderでもPixel ShaderはSIMD型の命令/データフォーマットを持つ。通常のGPUもSIMD型だ。
NV40系のVertex Shaderは、それぞれのShaderで最大3スレッドまでのマルチスレッディングが可能となっている。そのため、G70も同等かそれ以上のマルチスレッド機能を備えると見られる。Vertex Shaderも、テクスチャフェッチのようにレイテンシが長い処理が入ってきており、動的分岐でもパイプラインが乱れる可能性がある。パイプラインのストールを避けるために、マルチスレッド化が進んでいると見られる。
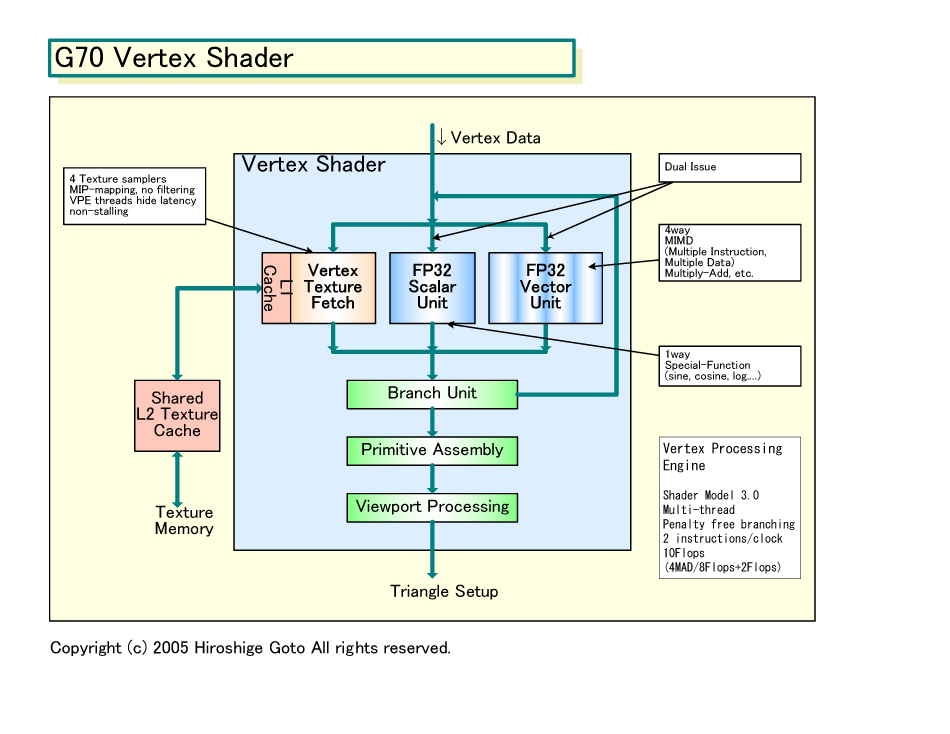 |
| G70 Vertex Shader PDF版はこちら |
G70は合計24個のPixel Shaderを搭載する。図中でPixel Shaderが4ユニットずつのバンドルになっているのは、Pixel Shaderに対する制御を4ユニット単位で行なっているからだ。NVIDIAは、従来も4個の隣接するピクセルであるクアッドを1単位としてレンダリングパイプを制御してきたという。今回は、単にそれが図中で示されただけのようだ。おそらく、4ピクセルを揃えてインプットし、揃えてアウトプットするインオーダ型の制御を行なっているものと思われる。同種の制御は、ATIのRADEON 9700(R300)系なども行なっている。
NV40/G70アーキテクチャでは、Vertex Shaderはシンプルだが、Pixel Shaderは非常に複雑な構造となっている。特に、G70では、Pixel Shader数が16ユニットから24ユニットへと50%増えただけでなく、Shader内部も拡張された。そのため、Vertex ShaderとPixel Shaderの非対称性は、ますます強まっている。
NVIDIAの基本的な考え方は、Pixel Shader内の並列性を高めることで、シェーダの「命令レベルの並列性(Instruction-Level Parallelism:ILP)」を高める方向性だと推測される。NV40のPixel Shaderは、内部に2つのベクタ演算ユニットを持ち、4wayのベクタ演算を2つ並列に実行できた。しかし、NV40の場合は、片方のユニットしか積和算(MADD)ができなかったため、最も頻繁に使われる積和算の並列化ができなかった。G70では、この部分が改良された。G70のPixel Shaderでは、両Shaderユニットが積和算可能となった。
図中では、2つのShaderユニットが縦に並んでいるが、これはNVIDIAの図に従ったため。実際には2つのShaderユニットに対して、並列に命令を発行することができる。上のShaderユニットは、NV40ではテクスチャプロセッサと一部リソースを共有していた。G70が同じ構造だとすると、並列に演算できないケースがある。
Pixel Shaderの両ベクタユニットには、Mini-ALUと呼ばれるスカラ演算ユニットが付属している。Mini-ALUは、RSXのプレゼンテーションではSFU(Special Function Unit)となっていた。Vertex Shaderのスカラユニットと同種のユニットだと見られる。
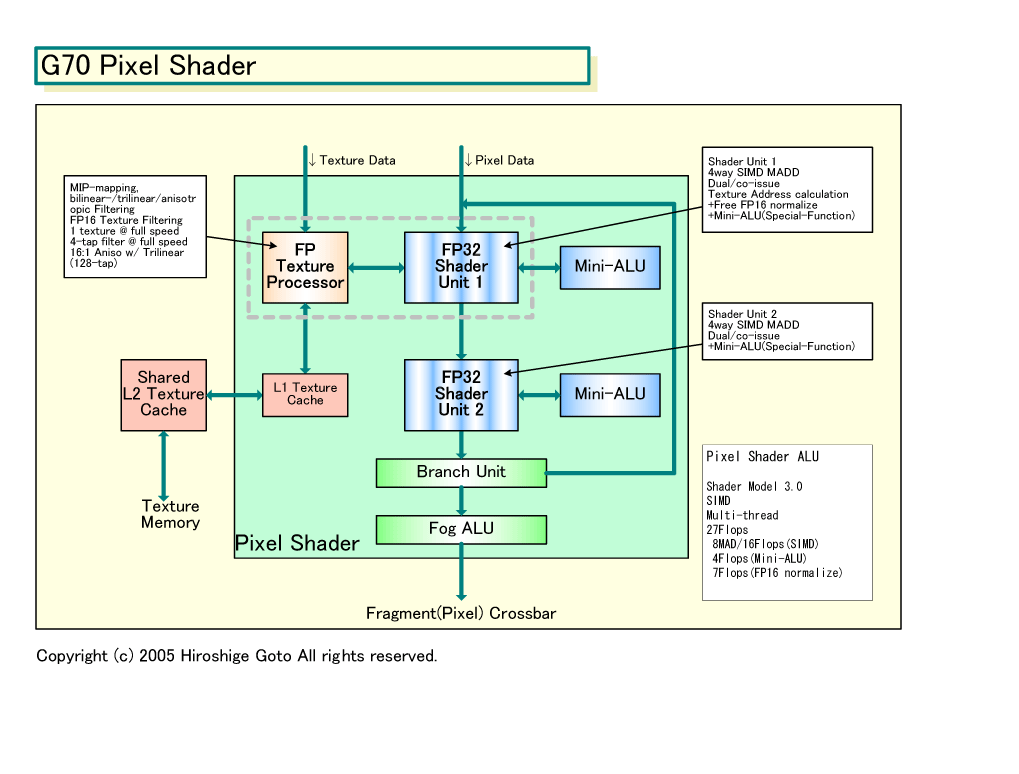 |
| G70 Pixel Shader PDF版はこちら |
NV40/G70では、Pixel Shaderから分離された「ROP(Rasterizing OPeration)」ユニットを備える。ポストShader処理と言われる、アンタイエイリアシングやカラーブレンディング、Z/ステンシルテスト、カラー&Z圧縮などを行なう、固定機能ユニット群のパイプだ。
NV40では、Pixel ShaderとROPはともに16ユニットづつだった。ところが、G70では、1.5倍に増えたPixel Shaderに対して、ROPユニット数は16に留められた。Kirk氏はその理由について「今後のソフトウェアでは、ピクセルシェーディングの負荷の方が急激に高まると判断した。ピクセルは、Pixel Shaderの中でもっともっとサイクルを費やすようになって来ている。そのため、必ずしも毎サイクルにピクセルは出てこない」と説明する。
つまり、Pixel Shader内部での処理に時間がかかるようになりつつあるため、サイクル当たりのPixel Shaderからのピクセルの出力は減る傾向にある。そのため、バランス上、ROPを増やさなくても問題はないと判断したわけだ。実際には、16という現在の数も、ピークのピクセル出力に対応する数だという。
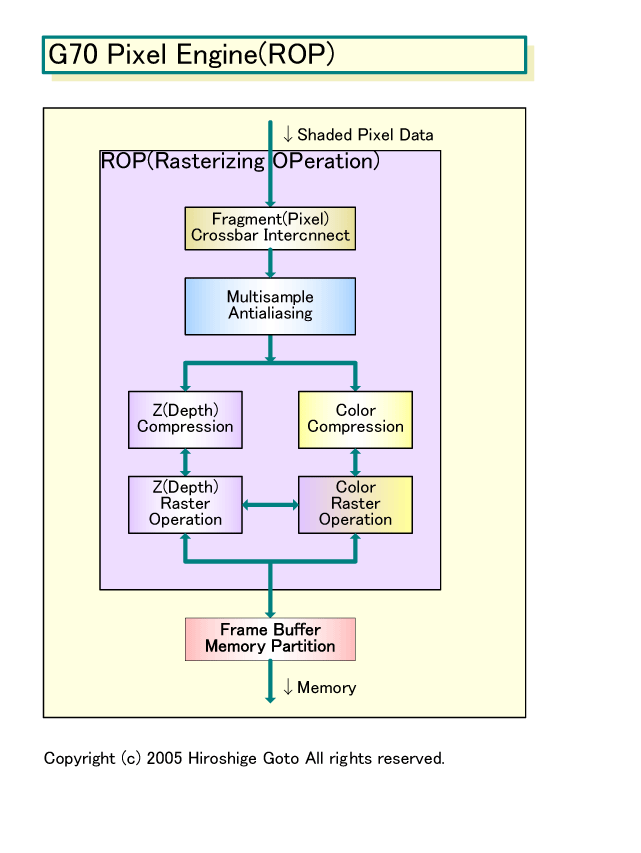 |
| G70 Pixel Engine(ROP) PDF版はこちら |
NVIDIAは、GeForce 7800 GTX(G70)世代では、トライアングルレートやピクセル(テクセル)フィルレートをスペックとして強くは打ち出さなくなりつつある。これは、当然の話で、シェーダ中心のグラフィックスへと移行するにつれて、従来の指標に意味が薄くなってきたからだ。相対的に重要性が増しているのはシェーダ性能だが、現在はまだ、シェーダ性能について、標準的な指標が確立していない。一応の指標としては、今はOperations(Instructions)/secやFLOPS(Floating Operations per Second)が比較されている。
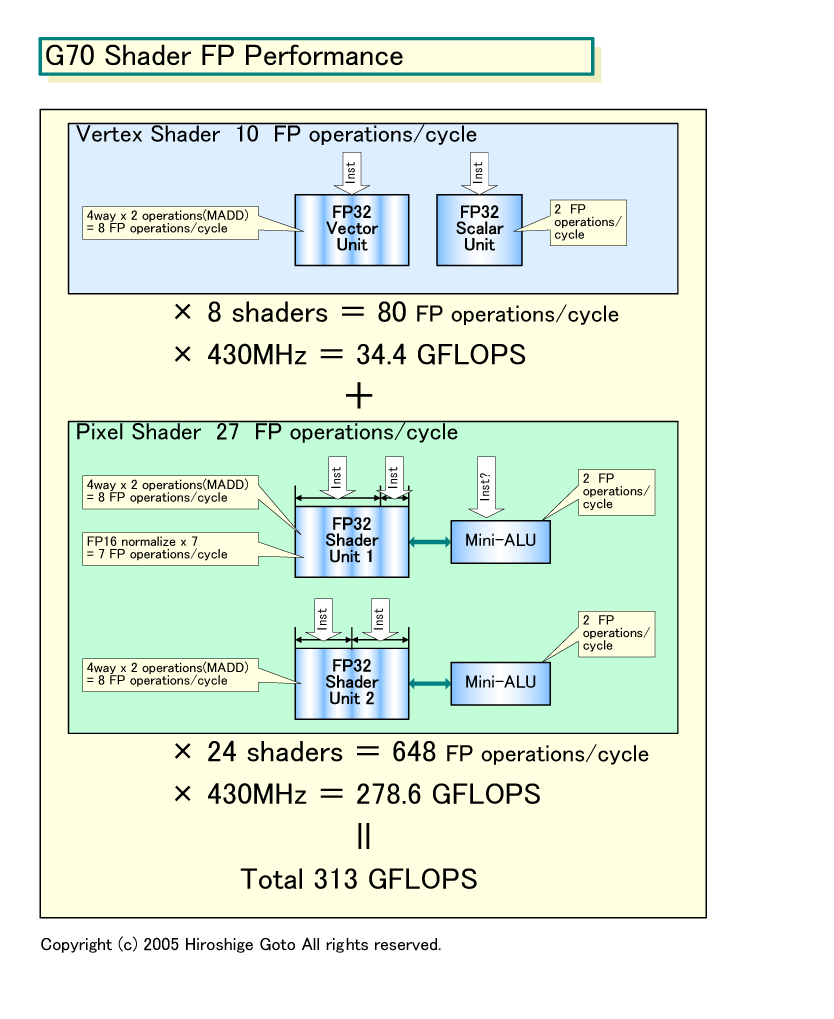
NVIDIAの発表では、G70のShader演算性能は、313GFLOPS(430MHz時)。これは、Microsoftが発表したXbox 360 GPUの240GFLOPSよりも大きい。NV40発表時のShader演算性能は120GFLOPSだったので、ここからも倍以上増えたことになる。なぜこんなに、G70のShader演算性能は高いのか。そこには、ちょっとトリックというか、浮動小数点演算の並列性を高める仕掛けがある。
まず、Vertex Shaderから演算性能をカウントしてみよう。G70のVertex Shaderは、4way VLIWユニット+スカラユニットで、5データを並列に演算できる。それぞれに積和算が可能として、1サイクル当たりの浮動小数点オペレーションは10となる。Vertex Shaderは8個あって、動作クロックは430MHzなので計算は下のようになる。
(4way+1scalar) x 2 FPoperations(MADD) x 8 Shader x 430MHz = 34.4GFLOPS
またVertex Shaderでは、発行(issue)できる命令は2個なので、命令数は次のようになる。
2issue x 8 Shader x 430MHz = 6.88GInstructions/sec
次にPixel Shader。こちらは、4wayのSIMDユニットが2ユニットあって、どちらも積和算が1サイクル毎に可能だ。SIMDユニットだけで8データを並列に演算できる。そのため、下のような計算になる。
4way x 2 Units x 2 FPoperations(MADD) = 16 FPoperations/cycleとなる。
さらに、両ベクタユニットに、それぞれMini-ALUと呼ばれるサブ演算ユニットが付属している。NVIDIAによると、これらのユニットも並列動作が可能という。さらに、Tamasi氏によると、7個のFP16 normalize(正規化)処理も並列に可能だという。
2scalar x 2 FPoperations + 7 normalize = 11 FPoperations/cycle
そうすると、合計で、Pixel Shader 1ユニット当たりのShaderの浮動小数点演算は27オペレーションとなる。Pixel Shaderは合計24ユニットなので、ピークの演算性能は次のようになる。
27 FPoperations x 24 Shader x 430MHz = 278.6GFLOPS
Pixel Shaderでは、発行できる命令は最大5。まず、両SIMDユニットが、それぞれ最大2命令に分割可能となっている。つまり、4wayのSIMDを、3:1か2:2に分割して、それぞれのデータ要素に別な命令を発行することができる。カラーの4要素であるRGBAのうち、RGBとAlphaは個別に扱われる場合が多い。そのため、RGBとAlphaのそれぞれに対する演算を並列にできると、並列性を高められる可能性が高くなる。
Pixel Shaderでは、この他に、1命令を同時発行可能となっている。NV40では、テクスチャプロセッサとSFU(Mini-ALU)への命令発行を加えて、最大6命令/サイクルと説明なっていた。G70では5命令/サイクルとなっているが、これはテクスチャプロセッサの分を外したのかもしれない。いずれにせよ、5命令同時発行だとすると、Pixel Shader群全体での命令数は次のようになる。
5issue x 24 Shader x 430MHz = 51.6GInstructions/sec
 |
| G70 Shader FP Performance PDF版はこちら |
これで、Vertex ShaderとPixel Shaderそれぞれの命令数とオペレーション性能を合計すると次のようになる。
313 GFLOPS
58.5 GInstructions/sec
対する、同じ基準でのXbox 360 GPUのスペックは
240 GFLOPS
48 GInstructions/sec(ATIではOperations/secと数えているが内容は同じ)
つまり、スペック的にはNVIDIAのG70は、ATIのXbox 360 GPUを凌駕する。もっとも、両GPUのこの計算上のスペックは、単純に同列に並べることはできない。ATIの演算性能は4wayベクタ+スカラだけのスペックなのに対して、NVIDIAはPixel Shader内部の特殊機能の演算も含んでいる。ATIはUnified-Shaderで、Shaderのスケジューリングも全く異なる。あくまでもピーク値で、リアル性能ではない。
しかし、このスペックが、単純なShader数の比較では見えない、NVIDIAの技術方向性を示しているのも確かだ。Xbox 360 GPUのShader数は48ユニット、対するG70のShader数は32ユニット。Shader数だけなら両GPUには大きな差がある。しかし、Shader内部の演算ユニット数だけを見ればNVIDIAの方が多く、それはGFLOPS値にも反映されている。つまり、ATIはShader自体はシンプルに保ちながらShader数を増やす方向へ向かっており、NVIDIAはShader内部を複雑にしてShader内の並列性を高めようとしている。そうした方向性の違いが反映されている。
□関連記事
【6月22日】NVIDIA、新GPU「GeForce 7800 GTX」
http://pc.watch.impress.co.jp/docs/2005/0622/nvidia.htm
【6月22日】【多和田】約1年の沈黙を経て登場したNVIDIA「GeForce 7800 GTX」
http://pc.watch.impress.co.jp/docs/2005/0622/tawada54.htm
(2005年6月22日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.