 |


■後藤弘茂のWeekly海外ニュース■x86 Macintosh移行のカギを握るTransitive |
●前々回のレポートの間違い訂正とx86へのトランスレーション
Apple Computerは、x86ベースのMacintoshアーキテクチャで、レガシーソフトのサポートのためにPowerPCトランスレータ「Rosetta」を提供する。これは、PowerPCへの移行時に提供した「Mac 68Kエミュレータ」と似たような役割のシステムだが、今回は、新興のTransitive Technologiesの技術がベースになっていると言われている。これが本当だとすれば、Transitiveは、一体なぜAppleに採用されたのか。
その本題に入る前に、まず、前々回のコラムで、Intel命令セットにバイト並びの変換命令がないように書いたが、実際にはbyteswap命令がある。コロっと忘れていたというミスで、こういうのはまさしく“底が見える”というパターンだ。申しわけない。
なので、x86 ISA(命令セットアーキテクチャ)でも、1ステップ命令を加えれば変換はできる。というわけで、前々回の話は、変換付きロード/ストア命令があった方が、RISC系ISAのエミュレータにはより都合がいいかも、という程度の話になる。RISC系では、基本的にはメモリアクセスは演算系命令からロード/ストア命令へと分離されている。だから、ロード/ストアにバイトの入れ替えがあれば、変換時に命令数を増やしてステップを増やしたくない場合に便利という話になる。
もっとも、RISC→x86トランスレーション時に、ロード命令やストア命令を、演算命令と融合させて、命令数を減らそうとすると話はややこしくなる。しかし、元のコードの方が、コンパイラでの最適化時に、レイテンシのあるロード命令をできる限り前へ出しているはずなので、ランタイムで簡単に融合はしにくいだろう。手間をかけて、融合させてコード密度を高めても、それほど益はないかもしれない。そもそも、Intel CPUをよく考えてみると、そこでロードと演算を融合させても、デコーダでもう一度分解されてしまう。
ここから先はデータではなく、命令コードの変換の話になる。Intel CPUのx86デコーダは、実際にはx86→uOPs(Micro-Operations)のハードウェアトランスレータで、内部命令であるuOPsは、固定フォーマットで、ロード/ストア型(メモリアクセスをロード/ストア系命令に分離した)アーキテクチャを取ると言われる。言ってみれば、RISC風命令ということになる。そうすると、RISC系からのトランスレーションは、RISC→CISC→RISCライクuOPsという無駄なプロセスを経ることになる。
このムダを解消する方法の1つは、x86デコーダのステージは飛ばして、RISCコードから直接uOPsに変換すること。すでにNetBurst(Pentium 4)アーキテクチャだと、x86デコーダはパイプラインの前に出ており、L1命令キャッシュであるトレースキャッシュに格納するのはuOPsなので、不可能ではないかもしれない。
しかし、uOPsへ直接変換する手法には問題がある。それは、各CPUアーキテクチャでuOPsが異なること。NetBurst系とBanias/Dothan系(Pentium M)で異なるのは当然だが、NetBurst同士ですら世代によってuOPsがある程度異なるという。現在のx86 CPUは、マイクロアーキテクチャを進化させるために、uOPsも小刻みに変えており、x86 ISAは、そうしたuOPsの差異を抽象化する役割を果たしている。ちなみに、これは、GPUのShaderがそれぞれ異なるISAを持つのに、APIとランタイムで抽象化しているのと似ている。そのため、x86への変換は、おそらく避けて通ることができない。
そうすると、RISCコードをCISCのx86に効率的に変換するにはどうすればいいのかという話になる。というわけで、冒頭のTransitiveの話に戻るわけだ。AppleがTransitiveを使うかどうかは正式には発表されていないようだが、これは、ごく自然な流れに見える。というのは、高パフォーマンスのトランスレーションテクノロジで、現在“買える”のは、ほぼTransitiveだけだからだ。
●Transitiveはソフトウェア版Transmeta
Transitiveは、ダイナミックトランスレーションソフトウェア技術をひっさげ、2001年10月のMicroprocessor Forumに登場した。Transitiveの技術は、TransmetaのEfficeonのソフトウェア層CMS(Code Morphing Software)でやっているような高効率のコード変換を、一般的なCPUアーキテクチャ上で実現する。ソフトウェア(オンリー)版のTransmetaと考えればわかりやすいかもしれない。
Transmetaの場合、x86コードを、独自の「VLIW(Very Long Instruction Word:超長命令語)」のISAに変換している。Transitiveは、Power/PowerPCやMIPSなどのコードをx86やIA-64、Opteronで走らせたり、x86やMIPSをPower/PowerPCで走らせるソリューションを提供している。つまり、x86をPowerPCに、PowerPCをx86にバケさせるといったことができる。
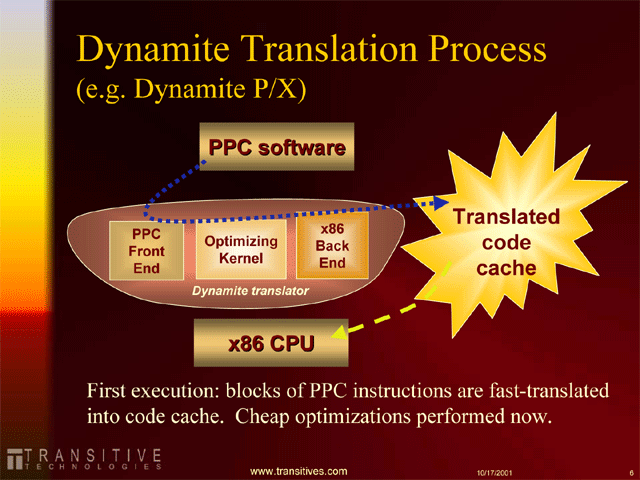 |
| Transitiveのダイナミックトランスレーションソフトウェア技術(2001年10月、Microprocessor Forum) |
2001年秋の発表当時、Transitiveはかなり話題になった。それは、同社がこうしたバイナリトランスレーションを、極めて高パフォーマンスで行なう技術を発表したからだ。
Transitiveのテクノロジ「QuickTransit」の核の部分は、変換したコードを最適化するオプティマイジングカーネル(Optimizing Kernel)と、変換済みコードキャッシュにある。同社のテクノロジでは、変換済みのコードをメモリ上にキャッシュしておき、次に同じブロックが使われる時は、変換済みのコードをロードすることでトランスレーションのオーバーヘッドをなくす。これは、TransmetaのCMSのモーフィングキャッシュと同じアイデアだ。
また、Transitiveではキャッシングする際に、プログラムの中で実際に使われるコードのトレース(実行されるパス)をキャッシュする。これも、モーフィングキャッシュやIntelのNetBurstのトレースキャッシュと基本的には同じ仕組みだ。トレースをキャッシュするのは、キャッシュを効率化して、キャッシュメモリスペースと帯域を節約するだけでなく、もっと積極的な意味がある。
Transitiveのテクノロジでは、単純にコードをトランスレートするだけでなく、コードを最適化して、同じタスクをより短時間に実行できるようにする。この際に、コードトレースに沿って最適化を行なうため、キャッシュされたトレースを再利用することは、最適化した結果も再利用できることを意味している。また、Optimizing Kernelは頻繁に使われるブロックを検出して、集中的に最適化する。
QuickTransitのこの手法は、いわゆる“90/10ルール”にのっとっている。プログラム中の10%のコードセグメントがCPUの実行時間の90%を占め、残りの90%のコードは実行時間の10%程度しか占めないという経験則だ。通常のアプリケーションでは、ごく一部のコードセグメントが、何度も反復して実行される。これは、コードの“局所性”として知られており、頻繁に使われるコード部分は“ホットスポット”と呼ばれることが多い。
90/10ルールに従えば、10%のホットスポットを最適化すれば、90%の実行時間をかなり短縮できるために効果が大きい。最適化に時間がかかっても、それに見合うだけの実行時間の短縮が得られる。残りの90%のあまり頻繁に使われないコードは、最適化せずに、そのまま逐次トランスレートして実行する。当然、この部分の実行には、パフォーマンスペナルティがあるが、全体のワークロードの10%しか占めていないため、影響はそれほど大きくない。また、最適化しても意味が薄い。
●段階的にコードの最適化を行なう
TransmetaのCMSも、90/10ルールを使う点はQuickTransitと同じ。CMSも、90/10ルールでホットなブロックだけを最適化して高速化を図る。TransmetaのCMSは数ステップで段階的に最適化するが、Transitiveも同じ方法を採る。最初は、ベーシックブロック(コントロールトランスファ系命令(CTI)で終わるコードシーケンス)の中で、デッドコードの削除などを行なう。例えば、重複したロードのように、簡単に見つかるデッドコードはここで削除してしまうと見られる。
TransitiveのQuickTransitカーネルは、次のフェイズでは、実際に実行されるコードのトレースを見て、複数のベーシックブロックをまとめたグループブロックを作り、その中での最適化を行なう。こうした処理を行なうのは、コードの最適化を、より大きなコード範囲の中で行なえば、それだけ効率が上がるためだ。大きなコードトレースの中なら、潜在的に最適化の幅が広がる。Transmetaも、Efficeonからはこの手法を使い、最大100命令のブロック中で最適化を行なっている。こうした最適化は、実際のソフトウェアの振舞いをランタイムで見ながらでないとできないため、スタティックコンパイラでは難しいという。
Transitiveは、さらに上位のアナライズを行なって、特定のソフトウェア環境や条件に合わせた最適化も行なう。例えば、ライブラリルーチンの場合は、多くのケースに適合するようにフレキシブルにプログラムが書かれていることが多い。そのため、比較命令や条件分岐命令を多数含んでいる。しかし、Transitiveのランタイムは、特定のセッティングを検知したら、そのセッティングでは不要なフラグやパラメータを見る命令群や分岐を削除できるという。それによって、現在の条件に合った、カスタマイズバージョンのライブラリルーチンを作って走らせるという。
●コードの局所性へのフォーカスはCPU全体のトレンド
コードの局所性に注目した最適化は、現在、CPU&ランタイムコンパイラ開発ではホットなテーマとなっているらしい。TransitiveやTransmetaのように、ISAのトランスレーションに使うだけでなく、CPUの高速化手法としても注目されている。CPUのシングルスレッド性能を向上させるには、最も有効な手法の1つと考えられているからだ。
例えば、Intelが研究している、次々世代のCPUアーキテクチャ候補の1つ「Power AwaReness thRough selective dynamically Optimized Traces(PARROT)」も全く同じアプローチを取る。PARROTでは、10%のホットスポットを、バックグラウンドで高度に最適化し、最適化結果をトレースキャッシュに格納する。TransitiveやTransmetaと違うのは、ソフトウェアではなく、ハードウェア中心の実装にするアイデアである点だけだ。
つまり、Transitiveの向かっている方向は、CPU&コンパイラ業界の全体のトレンドに沿っている。
ソフトウェアでトランスレートするTransmetaとTransitiveの最大の違いは、TransmetaがターゲットとするCPUも開発したのに対して、Transitiveはソフトウェアソリューションを選んだ点。同社は、汎用のCPUで実行できるように代表的なISAに対して実装する道を取った(同社のテクノロジを使った新CPUアーキテクチャの開発も視野には入れている)。AppleがTransitiveを選択したとすれば、その点が魅力だったろう。
しかし、既存CPUのISAに変換するアプローチには性能面では難点もある。以前、TransmetaのDavid R. Ditzel(デビッド・R・ディツェル)氏(Co-Founder, Vice-Chairman and CTO)に、Crusoeを発表した年にインタビューした時、Ditzel氏は同社のアプローチの利点について次のように語っていた。
「x86命令をRISCでエミュレートすると、実行する命令数が増えてしまう。これでは速く実行することはできない。ところが、VLIWに変換すると命令数が逆に減る。だからx86コードを速く実行できる」。
VLIWは命令レベルの並列性を命令のバンドルで実現する。超長命令語の中に複数の命令を格納して並列実行させることで、1サイクルに多くの命令を実行できるようにできる。だから、コンパイラの最適化時に、自動的にタスクを実行する際のサイクルを減らすことができる。Transitiveの技術はさまざまな最適化を行なうものの、Transmetaのこの利点は、もちろん持たない。
しかし、5年前とは異なる要素がある。それは、x86 CPUがマルチコア化しつつあることだ。マルチスレッド性能が上がると、トランスレータソフトは性能を出しやすくなる。ラフに言えば、一方のCPUコアがトランスレーションと最適化のタスクで占められても、もう片方のCPUコアはフリーに使えることになる。マルチコアの使い道としては、最適かもしれない。
□関連記事
【6月15日】【海外】PCとゲーム機で鍵となるバイナリ変換技術とエンディアン変換
http://pc.watch.impress.co.jp/docs/2005/0615/kaigai190.htm
【6月10日】【海外】なぜゲーム機はPowerPCに、パソコンはx86に偏るのか
http://pc.watch.impress.co.jp/docs/2005/0610/kaigai188.htm
【6月7日】【WWDC】MacへのIntel製CPU搭載をジョブズCEOが宣言
http://pc.watch.impress.co.jp/docs/2005/0607/apple2.htm
(2005年6月21日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.